-
- [Deep Q-learning 引言](#Deep Q-learning 引言)
- [Deep Q-learning](#Deep Q-learning)
Deep Q-learning 引言
Deep Q-learning 是一种利用 深度学习 帮助机器在 复杂情境 中 做出决策 的方法。它在状态数量极大的环境中尤为有效,例如视频游戏或机器人领域。
-
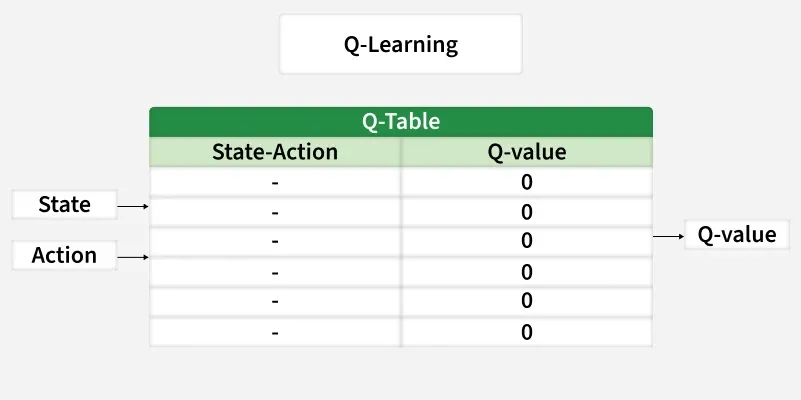
Q-learning 在 小规模问题 上表现良好,但在 图像 或 大量可能情形 等复杂问题上会捉襟见肘。
-
Deep Q-learning 通过使用 神经网络 来 估计价值 ,而不是使用庞大的表格,从而解决了这一问题。
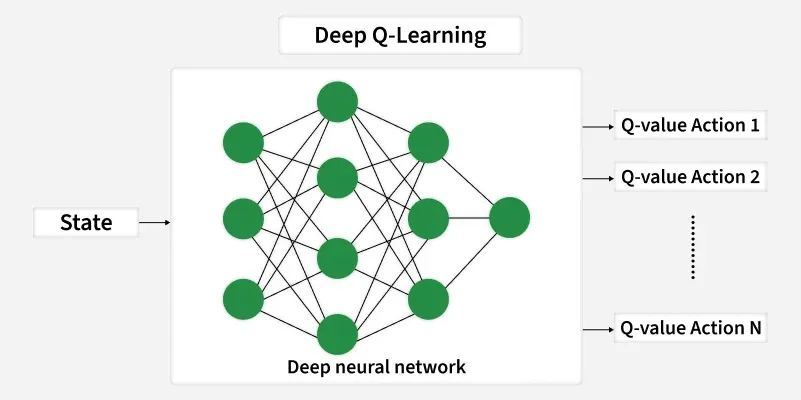
Deep Q-learning 用于编写在 离散动作空间环境 中操作的 AI 代理。离散动作空间指的是具体且 定义明确的动作(例如向左或向右、向上或向下)。
Atari 的《Breakout》展示了一个具有离散动作空间的环境。AI 代理可以向左或向右移动;每个方向的移动都有一定的速度。
如果智能体能够确定 速度 ,那么它就可以拥有连续的动作空间,拥有 无限多可能的动作(包括不同速度的移动)。
Deep Q-learning
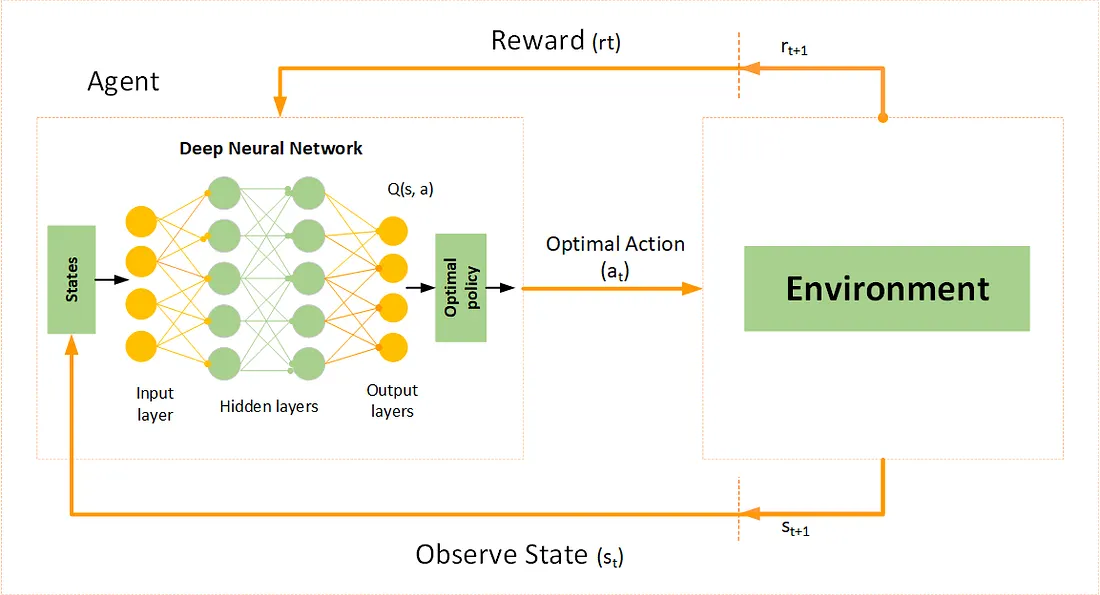
Deep Q-learning 是一种强化学习算法,源自 Q-learning 算法。它使用深度神经网络来近似 AI 代理在给定状态下(或每个状态-动作对)的 每个可能动作的 Q Q Q 值 。不同于使用 Q Q Q 表存储 Q Q Q 值的标准 Q-learning ------深度 Q-learning 使用深度神经网络,使 AI 代理能够处理 大规模 或 连续的状态空间。
-
Neural Network
网络近似 Q 值函数 Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ),其中 θ \theta θ 代表 可训练的参数。
例如,在游戏中,输入可能是来自游戏画面的原始像素,输出则是对应每个可能动作的 Q Q Q 值向量。
-
Experience Replay
为了稳定训练,DQNs 将 过去的经验 ( s , a , r , s ′ ) (s,a,r,s′) (s,a,r,s′) 存储在 回放缓冲区 中。在训练过程中,从缓冲区中 随机抽取小批量经验 ,打破连续经验之间的相关性,并提升泛化能力。
-
Target Network
使用具有参数 θ − \theta^- θ− 的单独目标网络在更新期间计算目标 Q Q Q 值。目标网络会定期使用主网络的权重进行更新,以确保稳定性。
-
Loss Function
损失函数度量预测的 Q Q Q 值与目标 Q Q Q 值之间的差异