flink3.4版本
K8S跑flink优势(基础设施级容错,避免 Pod / 节点故障)
Pod 故障自动重启
1 K8s 通过 Pod 的重启策略(默认 Always,对应 Flink Deployment 的重启策略),实现 Pod 故障后的自动恢复:
当 Flink TaskManager/JobManager Pod 因内存溢出、进程崩溃、容器异常等原因退出时,K8s 会自动重启该 Pod;
2 结合 Flink 的 Checkpoint 机制,重启后的 Pod 会快速恢复作业状态,不影响数据同步的连续性;
3 你配置中的 podTemplate 无需额外修改,K8s 原生支持该能力
节点故障自动调度
当 K8s 集群中的某个节点(Node)宕机(如硬件故障、网络中断),该节点上的 Flink Pod 会被标记为异常:
1 K8s 调度器会自动将这些 Flink Pod 重新调度到集群中的其他健康节点上;
2 新调度的 Pod 会通过 S3 中的 Checkpoint 快照和 HA 元数据,恢复作业状态,实现跨节点的故障转移;
3 该能力无需额外配置,由 K8s 原生提供,仅需保证集群中有足够的空闲节点资源。
存储持久化解耦(避免本地存储丢失)
Flink CDC 作业的关键数据(Checkpoint 快照、HA 元数据、Savepoint 快照)均配置为持久化到 S3 兼容存储(RustFS),而非 Pod 本地存储:
1 本地存储(emptyDir)会随 Pod 删除而丢失,而 S3 存储是独立于 K8s 集群的持久化存储,不受 Pod / 节点故障影响;
2 这是实现作业跨 Pod、跨节点恢复的前提,对应你配置中的 state.checkpoints.dir、state.savepoints.dir、high-availability.storageDir 均指向 S3 路径。启动你的集群
./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=jbk-first-flink-cluster \
-Dkubernetes.service-account=flink-cdc \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.operator.enabled=true \
-Dkubernetes.namespace=flink重新构建加入几个核心包放入镜像里
flink-cdc-pipeline-connector-mysql-3.4.0.jar
flink-cdc-pipeline-connector-starrocks-3.4.0.jar
mysql-connector-java-8.0.27.jar
flink-s3-fs-hadoop-1.20.0.jar
flink-s3-fs-presto-1.20.0.jar
# ll lib/
total 400972
drwxr-xr-x 1 flink flink 43 Dec 26 02:13 ./
drwxr-xr-x 1 flink flink 67 Dec 26 02:35 ../
-rw-r--r-- 1 502 dialout 36811008 Apr 29 2025 flink-cdc-dist-3.4.0.jar
-rw-r--r-- 1 root root 21368068 Nov 30 09:02 flink-cdc-pipeline-connector-mysql-3.4.0.jar
-rw-r--r-- 1 root root 13026309 Nov 30 09:02 flink-cdc-pipeline-connector-starrocks-3.4.0.jar
-rw-r--r-- 1 flink flink 198366 Jan 28 2025 flink-cep-1.20.1.jar
-rw-r--r-- 1 flink flink 563658 Jan 28 2025 flink-connector-files-1.20.1.jar
-rw-r--r-- 1 flink flink 102375 Jan 28 2025 flink-csv-1.20.1.jar
-rw-r--r-- 1 flink flink 125887715 Jan 29 2025 flink-dist-1.20.1.jar
-rw-r--r-- 1 flink flink 203636 Jan 28 2025 flink-json-1.20.1.jar
-rw-r--r-- 1 root root 31588060 Jul 25 2024 flink-s3-fs-hadoop-1.20.0.jar
-rw-r--r-- 1 root root 97259776 Jul 25 2024 flink-s3-fs-presto-1.20.0.jar
-rw-r--r-- 1 flink flink 21060644 Jan 29 2025 flink-scala_2.12-1.20.1.jar
-rw-r--r-- 1 flink flink 15714468 Jan 29 2025 flink-table-api-java-uber-1.20.1.jar
-rw-r--r-- 1 flink flink 38425605 Jan 29 2025 flink-table-planner-loader-1.20.1.jar
-rw-r--r-- 1 flink flink 3548905 Jan 28 2025 flink-table-runtime-1.20.1.jar
-rw-r--r-- 1 flink flink 208006 Jan 18 2023 log4j-1.2-api-2.17.1.jar
-rw-r--r-- 1 flink flink 301872 Jan 18 2023 log4j-api-2.17.1.jar
-rw-r--r-- 1 flink flink 1790452 Jan 18 2023 log4j-core-2.17.1.jar
-rw-r--r-- 1 flink flink 24279 Jan 18 2023 log4j-slf4j-impl-2.17.1.jar
-rw-r--r-- 1 root root 2475087 Nov 30 09:02 mysql-connector-java-8.0.27.jar构建
#https://repo1.maven.org/maven2/org/apache/flink/flink-s3-fs-presto/1.20.0/
# cat Dockerfile
FROM jpccr.ccs.tencentyun.com/test02/cdc:3.4
COPY flink-s3-fs-hadoop-1.20.0.jar /opt/flink/lib/flink-s3-fs-hadoop-1.20.0.jar
COPY flink-s3-fs-presto-1.20.0.jar /opt/flink/lib/flink-s3-fs-presto-1.20.0.jar公网镜像带有S3包
#公网镜像
jpccr.ccs.tencentyun.com/test02/cdc:ss3-3.40yaml模版
js
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: flink-cdc-pipeline-job
spec:
flinkConfiguration:
execution.checkpointing.interval: 600000
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 600000
execution.checkpointing.tolerable-failed-checkpoints: 100
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: s3://jbl/checkpoints/
s3.ssl.enabled: "false"
s3.access-key: rustfsadmin
s3.secret-key: rustfsadmin
s3.endpoint: http://rustfs-service:9000
s3.path.style.access: true
classloader.resolve-order: parent-first
state.checkpoints.dir: 's3://jbl2/checkpoints/'
state.savepoints.dir: 's3://jbl3/savepoints/'
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: s3://jbl4/flink-ha/
flinkVersion: v1_20
#image: 'jpccr.ccs.tencentyun.com/test02/cdc:3.4'
image: 'jpccr.ccs.tencentyun.com/test02/cdc:ss3-3.40'
imagePullPolicy: Always
job:
args:
- '--use-mini-cluster'
- /opt/flink/flink-cdc-3.4.0/conf/mysql-to-starrocks.yaml
entryClass: org.apache.flink.cdc.cli.CliFrontend
jarURI: 'local:///opt/flink/lib/flink-cdc-dist-3.4.0.jar'
parallelism: 1
state: running
upgradeMode: savepoint
jobManager:
replicas: 1
resource:
cpu: 1
memory: 2024m
podTemplate:
apiVersion: v1
kind: Pod
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/flink-cdc-3.4.0/conf
name: flink-cdc-pipeline-config
volumes:
- configMap:
name: flink-cdc-pipeline-configmap
name: flink-cdc-pipeline-config
restartNonce: 0
serviceAccount: flink-cdc
taskManager:
resource:
cpu: 2
memory: 2024m参数说明
js
"execution.checkpointing.interval": "600000", // 每10分钟触发一次检查点
"execution.checkpointing.mode": "EXACTLY_ONCE", // 检查点模式为精确一次
"execution.checkpointing.timeout": "600000", // 检查点超时时间为10分钟
"execution.checkpointing.tolerable-failed-checkpoints": "100", // 允许100次检查点失败
"state.backend": "rocksdb", // 使用RocksDB作为状态后端
"state.backend.incremental": "true", // 启用增量检查点
"state.checkpoints.dir": "s3://jbl/checkpoints/", // 检查点存储路径
"s3.ssl.enabled": "false", // 禁用S3 SSL
"s3.access-key": "rustfsadmin", // S3访问密钥
"s3.secret-key": "rustfsadmin", // S3秘密密钥
"s3.endpoint": "http://rustfs-service:9000", // S3端点
"s3.path.style.access": "true", // 使用路径样式访问
"classloader.resolve-order": "parent-first", // 类加载器解析顺序为父优先
"state.checkpoints.dir": "s3://jbl2/checkpoints/", // 重复的检查点存储路径
"state.savepoints.dir": "s3://jbl3/savepoints/", // 保存点存储路径
"high-availability": "org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory", // 高可用性服务工厂
"high-availability.storageDir": "s3://jbl4/flink-ha/" // 高可用性存储路径Flink CDC 数据同步原理
js
全量快照(首次启动)
作业启动后,CDC 连接器会先连接 MySQL 数据库,执行一次全量数据扫描,把 MySQL 中指定表的现有数据全部读取出来,同步到 StarRocks。
这一步是为了保证 "存量数据不丢失",相当于同步的 "起点"。
增量日志同步(持续运行)
全量快照完成后,CDC 连接器会切换到 binlog 监听模式:实时读取 MySQL 的 binlog 日志(记录了数据库的增删改操作)。
连接器会解析 binlog 中的操作事件(比如 insert/update/delete),转换成 Flink 能处理的数据流。
Flink 把这些增量数据事件,通过内置的算子(比如数据清洗、转换),最终写入 StarRocks 对应的表中。
并行度与数据分发
你的配置中 parallelism: 1 表示只有 1 个并行任务处理数据。如果改成 parallelism: 4,Flink 会把 MySQL 表的数据按分片规则(比如主键范围)分给 4 个任务并行处理,大幅提升同步速度。容错保障原理(核心是 Checkpoint + HA)
js
Checkpoint 快照:保证 "精确一次" 语义
execution.checkpointing.mode: EXACTLY_ONCE 是 CDC 作业的核心保障,它的工作流程是:
1 定期生成快照:按照 execution.checkpointing.interval: 600000(10 分钟)的间隔,JobManager 会触发一次 Checkpoint。
2 增量状态存储:因为配置了 state.backend: rocksdb 和 state.backend.incremental: true,TaskManager 不会全量保存状态,而是只保存与上一次 Checkpoint 的差异数据(比如新增的 binlog 位点、未写入 StarRocks 的数据)。
3 持久化到 S3:生成的 Checkpoint 快照会被上传到 state.checkpoints.dir 指定的 S3 桶(jbl2/checkpoints/),而不是存在本地磁盘。
4 故障恢复:如果 TaskManager 或 JobManager 挂了,Flink 重启后会从 S3 中拉取最新的 Checkpoint 快照,恢复到故障前的状态,从快照的 "位点" 继续同步 binlog,保证数据只处理一次,不会重复或丢失。高可用(HA):保证集群不宕机
js
high-availability 配置是为了应对 JobManager 单点故障,原理是:
1 HA 元数据存储:JobManager 的集群状态、选举信息会被持久化到 high-availability.storageDir 指定的 S3 桶(jbl4/flink-ha/)。
2 自动故障转移:如果当前的 JobManager 挂了,Flink Operator 会基于 S3 中存储的 HA 元数据,快速启动一个新的 JobManager 节点,并自动接管集群的调度工作,整个过程对 CDC 作业是透明的,不需要人工干预
3 当你需要升级 CDC 版本或修改配置时,Flink 会先触发一次 Savepoint(手动 Checkpoint),保存当前状态,升级后基于 Savepoint 重启,避免全量重新同步验证
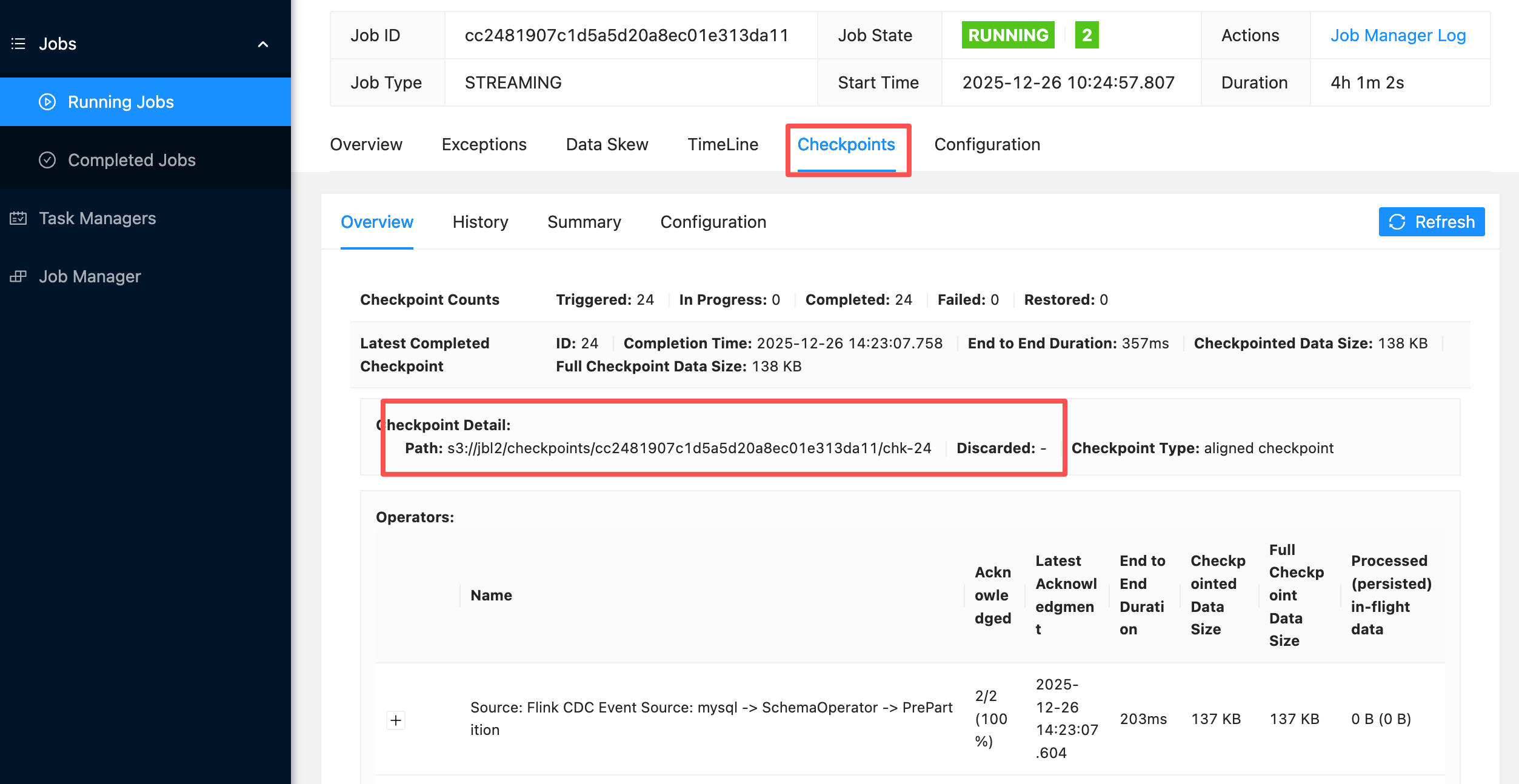
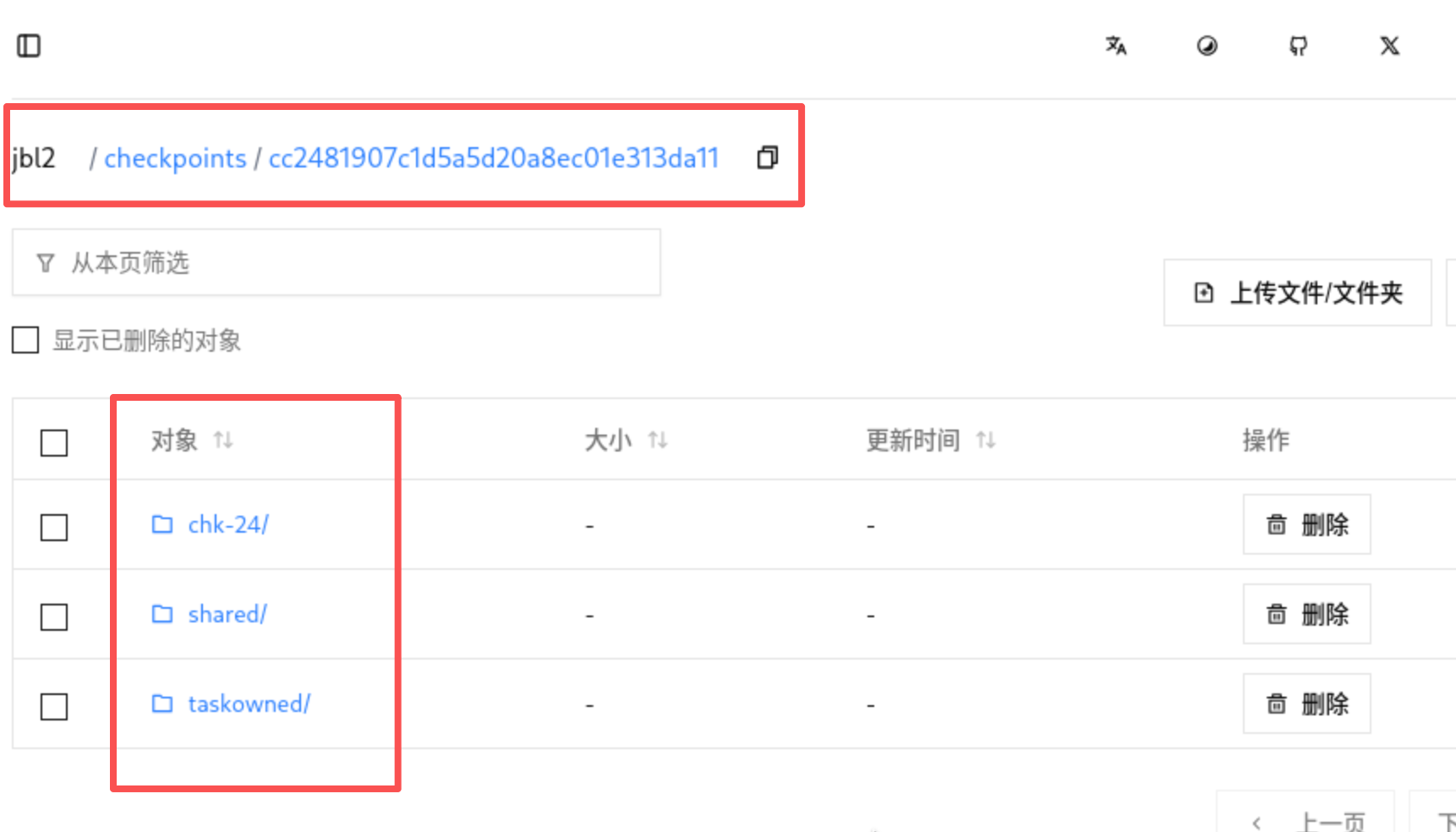
进入桶内的 checkpoints 目录,会看到以「作业 ID」命名的子目录(作业 ID 可从 Flink Web UI 中获取)
1该目录下存在 _metadata 文件(Checkpoint 元数据文件,核心标识)和 data 文件夹(状态数据文件);
2 随着时间推移,会生成新的 Checkpoint 子目录(按 Checkpoint ID 递增),说明快照正在持续持久化到 RustFS,即使 Pod 故障,快照也不会丢失。
3 若目录为空或无 _metadata 文件,说明 Checkpoint 未成功上传,需排查 S3 连接配置(如密钥、端点是否正确)。