计算机视觉Transformer是指利用Transformer结构替代以往计算机视觉领域常用的卷积结构CNN进行视觉类的任务,关于Transformer结构介绍可以看我的:深度学习基础-5 注意力机制和Transformer,卷积神经网络介绍可以看我的:深度学习基础-3 卷积神经网络。这篇文章介绍一些常用的视觉Transformer基础结构,一般称为Backbone,一定要确保自己已经清楚Transformer结构了,要不然会不知道这些Backboen到底在干什么,后续会写计算机视觉Transformer在目标检测、图像分割、自监督领域的重要工作介绍。
一 ViT
原论文:《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
论文题目就很有意思,直接翻译过来是"一个图像等于16*16个词语",作者为什么要这么说呢?
最初Transformer是为了解决自然语言处理中的问题而提出的,当时自然语言处理中最常使用的是RNN结构,Transformer从另外一个角度重新审视RNN结构存在的问题,提出了一种完全基于注意力机制的新架构-Transformer,替代以往翻译任务中常用的RNN、CNN结构,Transformer可以并行训练,相比于RNN训练更快




Transformer的输入是一句话,如"今天天气真好啊",先利用分词器对这句话分词,获取这句话对应的词表ID序列,然后对词表ID序列进行词嵌入,生成词嵌入矩阵,具体过程可见大模型基础理论-BPE/DeepNorm/FlashAttention/GQA/RoPE。词嵌入矩阵的维度是N,d-model,其中N是输入序列的长度,可以简单理解为就是一句话中有多少个词语(但实际上是小于一句话词语个数的,因为分词器未必一定会一个词一分割,准确说是token数量的个数,但是这么理解不影响),d-model是词嵌入向量的维度。
自然语言处理中的一句话可以像上述过程变换,输入到Transformer中进行处理,那么计算机视觉中的图像呢?如何将图像输入到Transformer中进行处理?
ViT提出的解决方案是:既然Transformer处理的是一个序列,那么我们就要想办法将图像进行序列化,ViT的序列化方式很简单,将图像切割为不同的块(论文中叫Patch),块的大小是16*16,将一幅图像类比为一句话,这些分割出来的块就是这句话中的词语,然后就可以利用Transformer对图像进行处理了,这就回答了论文题目中所说的"一个图像等于16*16个词语"。
很自然的一个问题(这个问题想清楚才能理解ViT它的成功之处在哪里),我们不从输入的序列性角度看,而是从形式上看,自然语言处理输入的是N,d-model维度的词嵌入矩阵,一幅图像是一个c,H,W维度的矩阵,其中c是图像的通道数,彩色图像c=3,灰度图像c=1,H和W是图像的高度、宽度。既然输入都是一个矩阵,我直接将c,H,W变形为N,d-model形式的矩阵不就可以了,还至于分块吗?


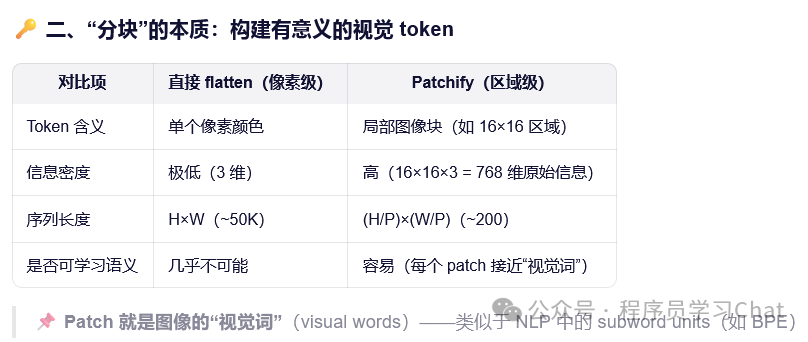


ViT将图像分割为多个16*16大小的子图,将这些子图展平为一维的向量,输入到嵌入层,模仿自然语言处理中词嵌入的过程。举例来说,假设输入的图像大小是3,160,160,那就会分割为10个3,16,16的子图,将这些子图展平为一维向量,则变为10,3\*16\*16大小的矩阵,这个矩阵再输入到嵌入层进行嵌入表示,得到10,96大小的图像块嵌入矩阵,其中96是图像嵌入表示向量的维度。
因为最后要进行图像分类任务,ViT模仿Bert的做法,在10,96的图像嵌入矩阵上添加了一个1,96的行向量,这个行向量符号标记是cls,这个cls向量通过Transformer的注意力机制会融合其它图像块的特征信息,也就是可以将cls看做以往卷积神经网络中提取到的特征图(Feature map),最终ViT是利用这个cls向量,将其输入到一个前馈神经网络中进行图像分类的。
同样因为Transformer对位置信息不敏感,需要添加位置编码信息到图像嵌入矩阵中,ViT的做法是直接学习一个10,96大小的位置编码矩阵加到图像块嵌入矩阵上,这个位置编码矩阵随着Transformer的训练会逐渐自己学会应该给每个图像块添加什么编码信息,并且ViT通过实验发现这个位置编码矩阵很关键,如果不给图像块嵌入矩阵添加位置编码信息,最终模型性能会大打折扣。
接下来ViT就是利用Transformer的Encoder结构对图像块进行特征提取,整体过程和以往的Encoder没有太大区别,这里就不介绍了,如果对于Encoder特征提取过程不清楚可以看:深度学习基础-5 注意力机制和Transformer。但是有一个细节需要注意,ViT将原来Encoder的正则化层移动到了每层的开始,原来Transformer的Encoder的正则化层是在每层输出之后的,
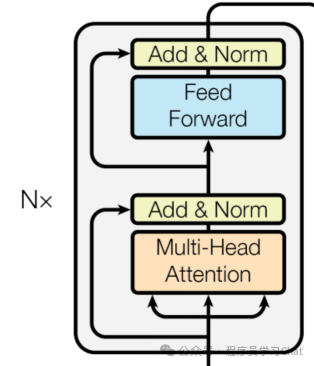
这是原Transformer中Encoder正则化层(Norm)的位置
这是ViT中正则化层的位置
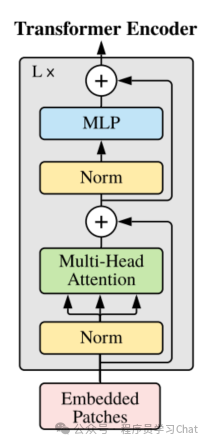
我们现在把正则化层放在层输入之前称为Pre-LN,放在之后称为Post-LN

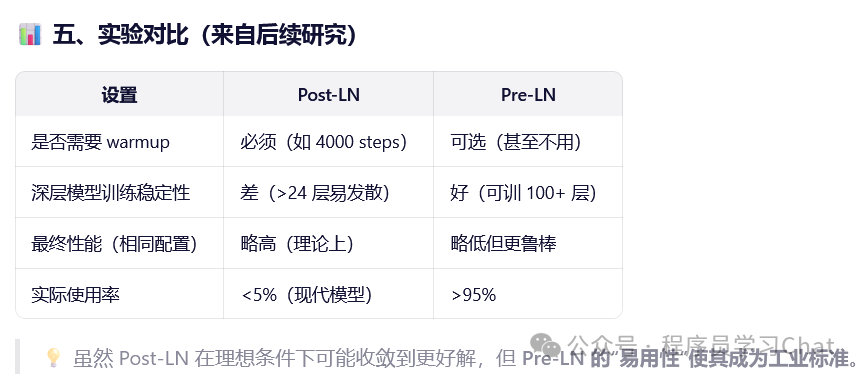
还有一个问题,现在位置编码是一个固定大小的矩阵10,96,这对于一个10,96的图像块嵌入矩阵没有问题,可以直接相加,但是如果我输入的是一个100,96的图像块嵌入矩阵怎么办,ViT的做法是对10,96的位置编码矩阵进行2D插值



ViT整体网络结构如下:
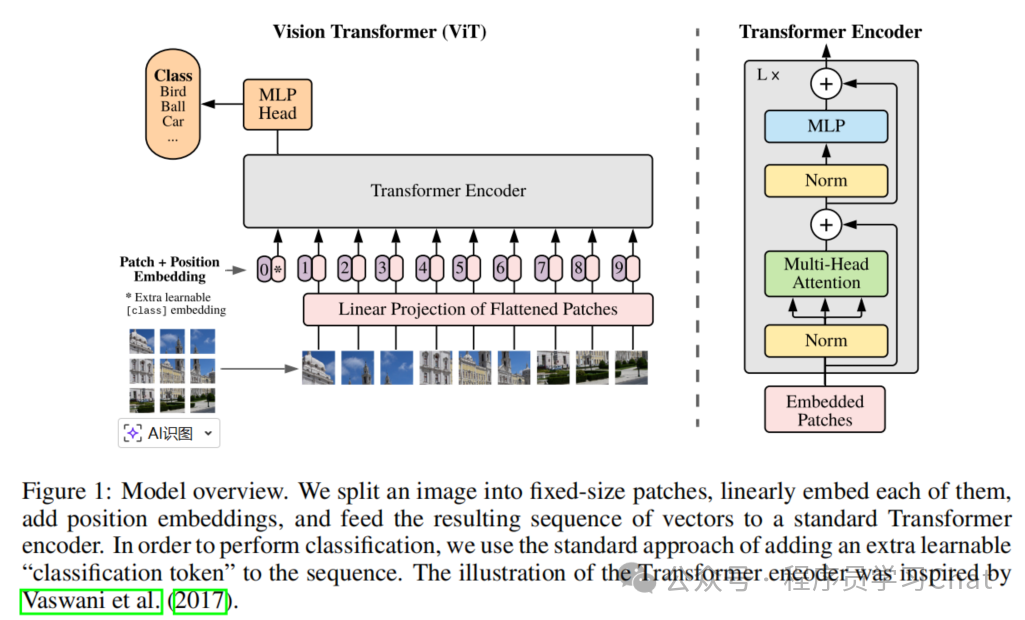
左侧是图像分块、添加cls标记的过程,最终Transformer Encoder的输出中的cls对应的向量输入到MLP Head中进行图像分类,右侧是Encoder中每个模块的结构示意图,注意Norm放在输入之前这个改动
如果我们想在自己的图像分类数据集上训练ViT应该怎么办呢,论文中的建议是将MLP Head替换为我们自己的分类头,但是要用全0进行初始化

以上就是ViT的整体流程介绍,我们现在看来没什么新的,但是在当时ViT模型的提出,打通了图像-文本之间的界限,可以都使用统一的Transformer架构进行处理,这也是后续多模态领域能够发展的前提,至今多模态领域中ViT依旧是最常使用的图像编码器,因其处理简单、结构简单。
但是ViT作者也承认,ViT没有像CNN网络那样引入局部信息相关的先验归纳偏置,效果依赖大规模的训练数据,数据量少时不如ResNet这些传统的视觉网络
二 PVT
原论文:《Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions》
ViT只能做图像分类任务,而计算机视觉里常见的检测、分割任务直接套用ViT效果很差,很差的原因是ViT最后输出的特征是一个全局语义特征,缺少图像细粒度的特征表示,PVT将传统计算机视觉领域中的特征金字塔搬到了Transformer架构上,让Transformer架构的视觉模型能够解决检测、分割等视觉问题
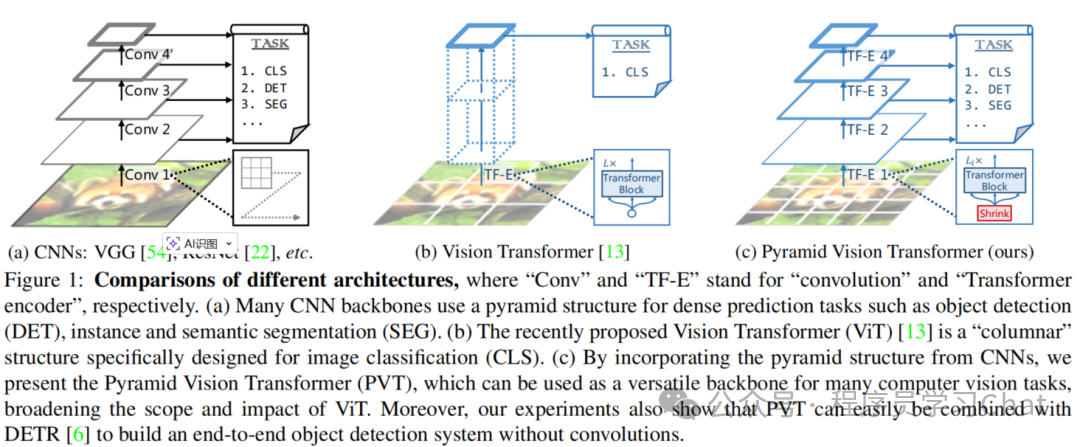
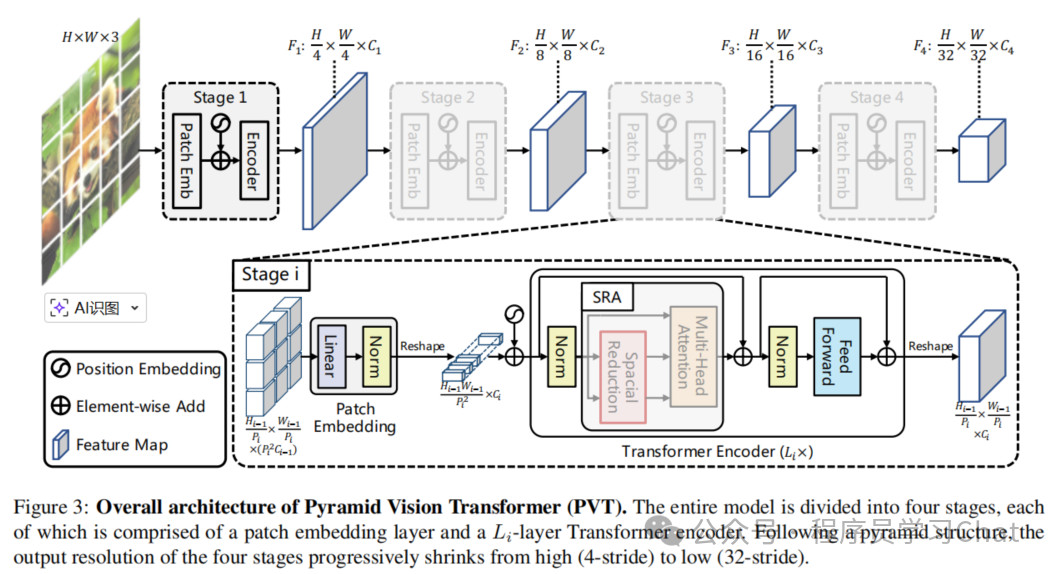
具体过程如下:


是否融合多个stage输出的特征可以自由选择

简单理解多尺度就是堆叠Transformer的Encoder层,利用这些不同的Encoder层对输入图像进行不同层次的特征提取,从而实现不同尺度的特征输出。
注意力机制的复杂度是和输入序列长度的平方成正比的,多次这样Encoder特征提取非常耗时,PVT对以往的注意力机制进行改进,提出了SRA注意力计算策略
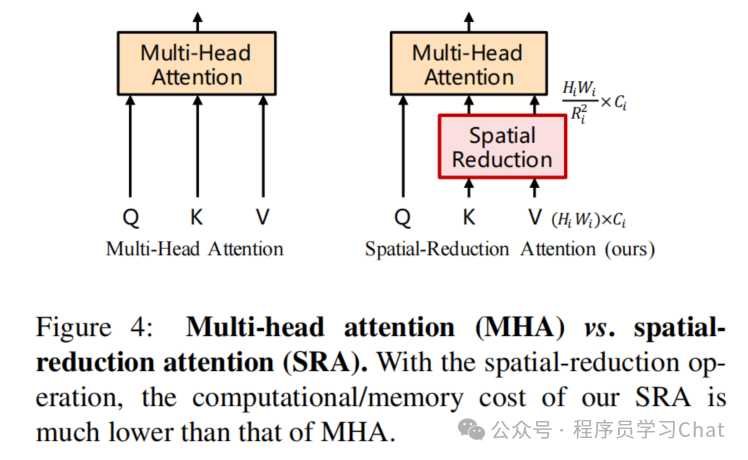


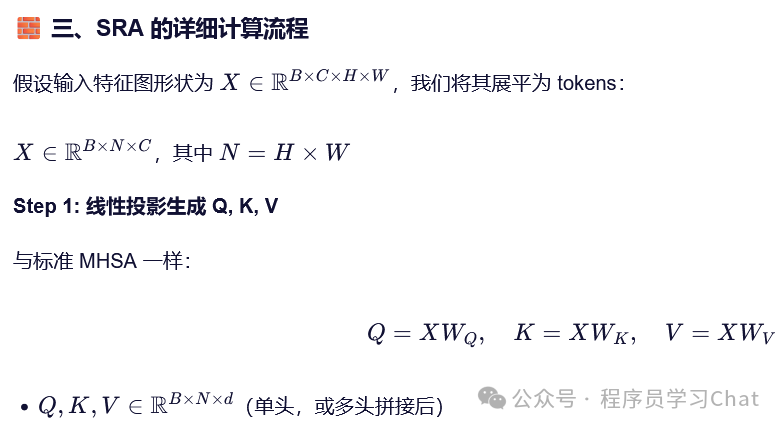


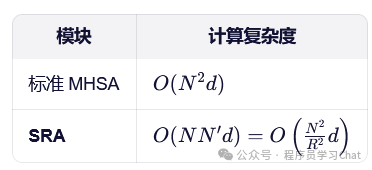
熟悉DeepSeek MLA的会感觉SRA有点像
三 Swin Transformer
原论文:《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
PVT是提出了多尺度这么一个事,真正将Transformer的多尺度特征推到顶点的是Swin Transformer
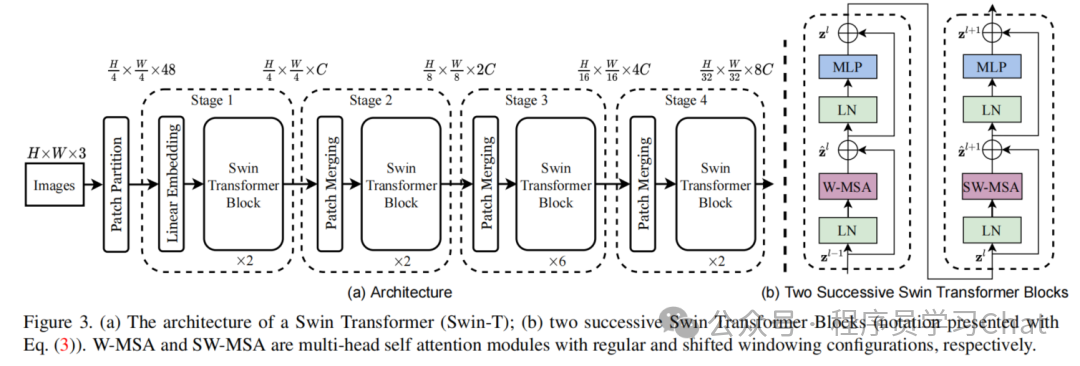
Swin Transformer整体流程类似PVT的多stage,PVT是利用SRA解决注意力计算过于耗时的问题,Swin Transformer提出了窗口注意力+移动窗口注意力解决注意力计算耗时这个问题,并且实验结果验证这种窗口注意力+移动窗口注意力的效果非常好,Swin Transformer提出时在各项计算机视觉任务上达到了SOTA。
Swin Transformer交替使用窗口注意力层+移动窗口注意力层的方式对输入图像进行特征提取,窗口注意力模仿卷积神经网络,关注输入的局部特征,并且大幅减小了计算复杂度(因为多个窗口的计算可以放到GPU上并行),移动窗口注意力本身也是一个窗口注意力计算,但是在计算之前,其会移动上一个窗口注意力层中的token序列,也就是改变token序列之间的排列位置,使得不同窗口之间的信息可以进行交互











论文中窗口注意力和移动窗口注意力示意图如下
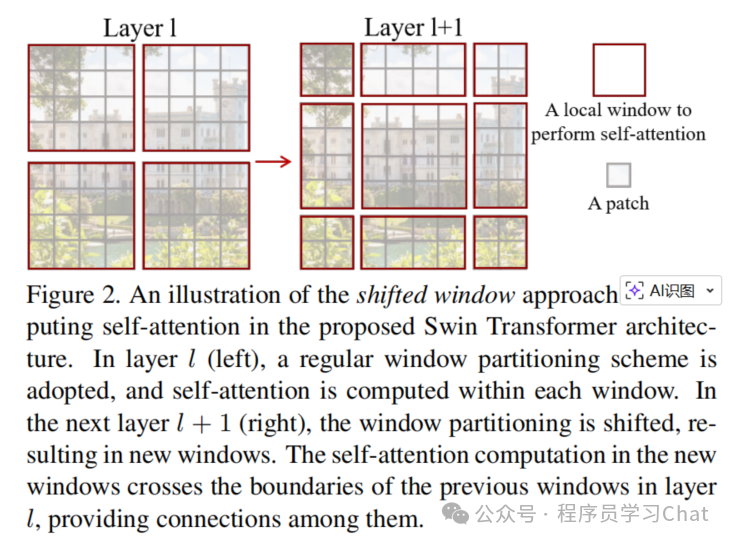
为什么会是这个样子呢,你手动画一下就知道了,假设输入是:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
然后每4个元素你框一个正方形做为一个窗口,也就是1,2,5,6是一个窗口、3,4,7,8是一个窗口,你可以手动将这些元素框在一起,元素整体循环右移一位变成
4 1 2 3
8 5 6 7
12 9 10 11
16 13 14 15
再整体上移一位变成
8 5 6 7
12 9 10 11
16 13 14 15
4 1 2 3
现在你再将原先在同一个窗口中的元素框出来,比如9 10 13 14是框在一起的,8就和原先窗口中的元素3 4 7分离了,所以单独用一个方框圈起来,其它位置同理,方框圈完之后就是论文里的样子,这个过程也是移动窗口的目的,"让原先不同窗口中的元素进行信息交互",移动窗口移动完再进行窗口注意力计算时,8 5 12 9就变为同一个窗口了,而最初它们彼此是属于不同窗口的。
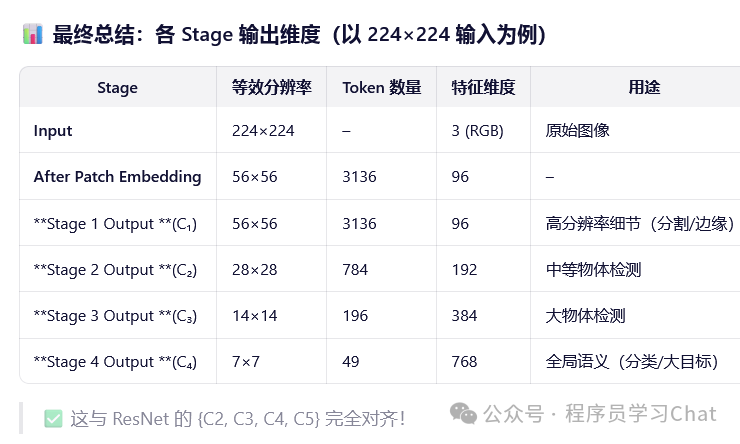
Swin Transformer不同stage的流程如下(以Swin-T的配置为例):







四 DeiT
原论文:《Training data-efficient image transformers & distillation through attention》
前面介绍ViT时说过ViT的效果依赖大规模训练数据,DeiT要解决的问题是如何让ViT在小规模训练集上也发挥出效果,具体是借助知识蒸馏方法,知识蒸馏方法介绍可见我的模型压缩-知识蒸馏
在ViT中引入了一个cls标记token





既然clstoken可以做分类,那么也可以引入一个disttoken进行知识蒸馏
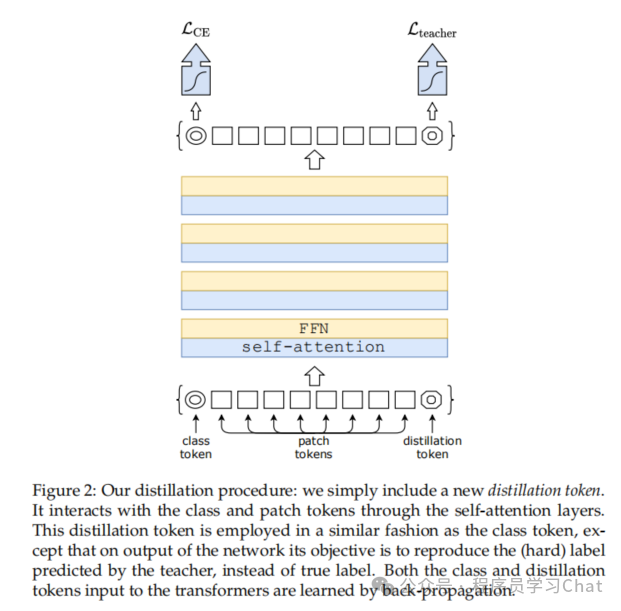
clstoken的训练还是用原先的分类损失,disttoken的训练用蒸馏损失,论文里提出了两种蒸馏损失
软标签信息蒸馏:


硬标签信息蒸馏


论文里通过实验发现最终cls的向量表示和dist向量表示很相似,但是不同,证明dist是一种来自教师神经网络的新监督讯号,推理的时候是将cls和dist的向量相加,求平均,送到FFN中进行分类