Prometheus的docker (compose)安装
一、Docker是什么
Docker 是一个开源的应用容器引擎,基于Go 语言 并遵从 Apache2.0 协议开源
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
Docker从17.03 版本之后分为CE(Community Edition:社区版)和EE(EnterpriseEdition: 企业版),我们用社区版就可以了
应用程序部署方式的演变
在部署应用程序的方式上,主要经历了三个时代

。传统部署:互联网早期,会直接将应用程序部署在物理机上
1.优点: 简单,不需要其它技术的参与
2.缺点: 不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
。虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
1.优点: 程序环境不会相互产生影响,提供了一定程度的安全性
2.缺点: 增加了操作系统,浪费了部分资源

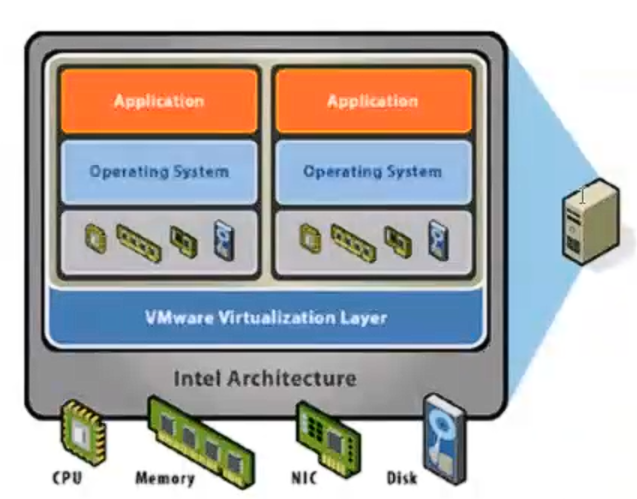
。容器化部署:与虚拟化类似,但是共享了操作系统。优点:
1.可以保证每个容器拥有自己的文件系统、CPU、内存、进程空间等
2.运行应用程序所需要的资源都被容器包装,并和底层基础架构解耦
3.容器化的应用程序可以跨云服务商、跨Linux操作系统发行版进行部署
4.部署快速。
二、Docker环境的准备
2.1配置yum的docker源
略
2.2 安装docker
略
检查docker服务是否启动且开机自启动
systemctl start docker
systemctl enable docker
systemctl status docker查看docker版本能运行出,版本号说明安装成功
docker -v主要docker命令
#查看docker中的已安装镜像列表
docker images
# 查看运行中的容器
docker ps
# 显示所有容器(运行中、已停止、已退出)
docker ps -a2.3安装docker-compose组件
Docker Compose是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。
快速编排:
1.有些复杂的程序部署组件有前后步骤/依赖关系
2.能实现程序的快速扩容+缩容
Compose 是 Docker 公司推出的一个工具软件,可以管理多个 Docker 容器组成一个应用。你需要定义一个 YAML 格式的配置文件docker-compose.yml,写好多个容器之间的调用关系。然后,只要一个命令,就能同时启动/关闭这些容器
优势
。避免了多次使用 Dockerfile、Build、Image 命令或者 DockerHub 拉取 Image(当前案例中,prometheus、grafana、node_exporter、alertmanager等需要分别拉取镜像images启动程序,使用了docker-compose则可以在一个yaml文件中一步启动)
。需要创建多个Container,多次编写启动命令:
。Container互相依赖的如何进行管理和编排(prometheus和其他组件有启动的依赖关系、先后顺序。用docker-compose的yaml文件可以比较方便的管理这类依赖)
安装
#从github中拉取下载docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-Linux-x86_64" -o /usr/local/bin/docker-compose
#设置文件具备执行权限
sudo chmod +x /usr/local/bin/docker-compose
#查看已安装的版本,如果能正常输出版本号说明安装compose完毕
docker-compose -v主要的compose命令
#启动一个compose
docker-compose up
#关闭一个compose
docker-compose down三、Docker-compose安装Prometheus
3.1 主要文件及树形结构
root@localhost data# tree
.
└── docker-prometheus
├── alertmanager
│ └── config.yml
├── docker-compose.yaml
├── grafana
│ ├── config.monitoring
│ └── provisioning
└── prometheus
├── alert.yml
└── prometheus.yml
3.2 创建基本目录结构
#切换到root用户
mkdir /data/docker-prometheus -p
mkdir /data/docker-prometheus/{grafana,prometheus,alertmanager} -p
cd /data/docker-prometheus/3.3 创建alertmanager的配置文件
vi alertmanager/config.yml
global:
# 163邮箱SMTP服务器
smtp_smarthost: 'smtp.163.com:465'
# 发件邮箱
smtp_from: '17711712380@163.com'
# 发件邮箱用户名
smtp_auth_username: '17711712380@163.com'
# 发件邮箱密码(授权码)
smtp_auth_password: 'GStn5dw5K4JntCiY'
# 是否启用TLS
smtp_require_tls: false
route:
# 按告警名称分组
group_by: ['alertname']
# 等待时间,看是否有更多告警一起发送
group_wait: 10s
# 同一分组内发送新告警的等待时间
group_interval: 10s
# 重复发送告警的时间间隔
repeat_interval: 10m
# 默认接收器
receiver: 'email'
receivers:
# 接收器名称
- name: 'email'
# 邮件配置
email_configs:
# 收件邮箱
- to: '1814603398@qq.com'
inhibit_rules:
# 抑制规则:当有严重告警时,抑制对应的警告级别告警
- source_match: # 源告警(触发抑制的告警)
severity: 'critical'
target_match: # 目标告警(被抑制的告警)
severity: 'warning'
# 需要匹配的标签
equal: ['alertname', 'dev', 'instance']3.4 创建grafana的配置文件
vi grafana/config.monitoring
# 设置管理员密码为 "123456"
GF_SECURITY_ADMIN_PASSWORD=123456
# 禁止用户在 Grafana 网站自行注册账户。
GF_USERS_ALLOW_SIGN_UP=false3.5 创建prometheus的配置文件
vi prometheus/prometheus.yml
# 全局配置
global:
scrape_interval: 60s # 将抓取间隔设置为每60秒一次。默认是每1分钟一次
evaluation_interval: 60s # 每60秒评估一次规则。默认是每1分钟一次
# Alertmanager 配置,告诉 Prometheus 把触发的告警发送到哪里
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# 告警规则文件配置
rule_files:
- "alert.yml"
# 抓取配置(一共创建四个Prometheus监控项)
scrape_configs:
# 1. Prometheus 自身监控,确保监控系统本身正常工作
- job_name: 'prometheus'
scrape_interval: 60s # 覆盖全局默认值,每60秒从该作业中抓取一次目标
static_configs:
- targets: ['localhost:9090']
# 2. Alertmanager 监控,alertmanager 是Docker容器名,需要在同一Docker网络
- job_name: 'alertmanager'
scrape_interval: 60s
static_configs:
- targets: ['alertmanager:9093']
# 3. cAdvisor 容器监控,Google开发的容器监控工具
- job_name: 'cadvisor'
scrape_interval: 60s
static_configs:
- targets: ['cadvisor:8080']
labels:
instance: 'Prometheus服务器'
# 4. Node Exporter 主机监控,监控Linux主机指标的工具
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node-exporter:9100']
labels:
instance: 'Prometheus服务器'3.6 创建prometheus的告警文件
vi prometheus/alert.yml
groups:
- name: Prometheus_alert
rules:
# 对任何实例超过30秒无法联系的情况发出警报
- alert: 服务告警
expr: up == 0 #触发条件 (expr),up = 0:监控目标不可达,抓取失败
for: 30s
labels:
severity: critical
annotations:
summary: "服务异常,实例: {{ $labels.instance }}"
description: "{{ $labels.job }} 服务已关闭超过30秒"3.7创建docker-compose.yaml文件(我是rockylinux9.6)
yaml中指定的镜像版本与前述二进制安装中的各组件版本保持一致。cadvisor表示普罗米修斯对docker平台的监控组件,此处采用v0.47.2
| 镜像名 | 版本号 |
|---|---|
| prometheus | v2.45.5 |
| alertmanager | v0.27.0 |
| node-exporter | v1.8.0 |
| grafana | 9.3.16 |
| cadvisor | v0.47.2 |
vi docker-compose.yaml #root@localhost docker-prometheus# vi docker-compose.yaml
version: '3.3'
# 存储卷
volumes:
prometheus_data: {} # 持久化Prometheus数据
grafana_data: {} # 持久化Grafana配置
networks:
monitoring: #为监控栈创建的自定义网络的名称。所有加入此网络的服务(通过 networks: - monitoring),就如同连接到了同一个内部局域网。
driver: bridge
services:
prometheus:
image: prom/prometheus:v2.45.5
container_name: prometheus
restart: always # 容器退出时会自动重启
#宿主机"指的就是运行Docker引擎的那台物理服务器或云虚拟机。
volumes: #下面三个都是 "将外部存储挂载到容器内部",其中两个外部存储直接指向宿主机路径,另一个指向Docker管理的抽象卷。
- /etc/localtime:/etc/localtime:ro # 同步宿主机时间。将宿主机的时间文件只读挂载到容器内,使容器时间与宿主机一致。
- ./prometheus/:/etc/prometheus/ # 提供配置文件。将宿主机当前目录下的 prometheus/ 文件夹,挂载为容器内的配置目录。这是你管理配置的主要方式。
- prometheus_data:/prometheus # 持久化存储数据。将Docker管理的名为 prometheus_data 的存储卷,挂载到容器内,用于保存监控数据库。确保数据不丢失。
command:
- '--config.file=/etc/prometheus/prometheus.yml' #核心配置文件路径。指定 Prometheus 从容器内的 /etc/prometheus/prometheus.yml 文件读取其主配置。这个路径与你之前的卷挂载 ./prometheus/:/etc/prometheus/ 直接对应,使你可以在宿主机上管理配置。
- '--storage.tsdb.path=/prometheus' #数据存储路径。指定 Prometheus 将其时序数据库(TSDB)文件写入容器内的 /prometheus 目录。这个路径与你挂载的 prometheus_data 命名卷对应,确保了监控历史数据的持久化。
- '--web.console.libraries=/usr/share/prometheus/console_libraries' #控制台模板库路径。指定 Web 控制台使用的 JavaScript 库的目录。通常使用镜像内的默认值,无需更改。
- '--web.console.templates=/usr/share/prometheus/consoles' #控制台模板路径。指定 Web 控制台使用的 HTML 模板文件的目录。通常也使用默认值。
- '--web.enable-lifecycle' #开启后,你可以通过向 Prometheus 发送一个 HTTP POST 请求,来热重载配置文件,而无需重启整个服务,避免了监控中断。
- '--storage.tsdb.retention.time=30d'
networks:
- monitoring #指定该服务应该加入到名为 monitoring 的自定义Docker网络中。
links: #不必须,现代版本的 Docker 中,只要服务位于同一自定义网络(如这里的 monitoring),它们就可以互相解析对方的服务名
- alertmanager
- cadvisor
- node-exporter
expose: #告知 Docker 该容器监听的内部端口号(这里是9090)
- '9090'
ports: #将容器的内部端口(左边的9090)映射到宿主机上的端口(右边的9090),意味着你可以在宿主机上通过访问 localhost:9090 来直接访问 Prometheus 的Web界面。
- '9090:9090'
depends_on: #确保在启动 prometheus 容器之前,先启动 cadvisor 容器。
- cadvisor
alertmanager:
image: prom/alertmanager:v0.27.0
container_name: alertmanager #为容器命名,便于管理。
restart: always #宕机自动重启,保证告警服务高可用。
volumes:
- /etc/localtime:/etc/localtime:ro # 同步宿主机时间,确保告警时间戳准确。
- ./alertmanager/:/etc/alertmanager/ #核心挂载。将宿主机当前目录下的 ./alertmanager/ 文件夹,挂载到容器内的配置目录 /etc/alertmanager/。你必须在此目录下创建 config.yml 配置文件。
command:
- '--config.file=/etc/alertmanager/config.yml' #指定配置文件路径,指向上面挂载的目录中的文件。
- '--storage.path=/alertmanager' #重要参数。指定Alertmanager内部数据(如静默状态、通知历史)的存储路径。
networks: #加入监控专用网络,使Prometheus能通过 alertmanager:9093 域名向其发送告警。
- monitoring
expose: #将9093端口暴露给同一Docker网络(如 monitoring)内的其他容器。这是为了让Prometheus容器能够访问它。
- '9093'
ports: #端口映射。将容器内的9093端口映射到宿主机的9093端口,使你能够通过浏览器访问 http://<宿主机IP>:9093 来打开Alertmanager的Web管理界面。
- '9093:9093'
cadvisor: #它是整个监控栈的"容器资源探针",专门负责自动收集宿主机上所有运行容器的实时性能数据。
image: m.daocloud.io/gcr.io/cadvisor/cadvisor:v0.47.2
container_name: cadvisor #指定容器名称,便于管理。
restart: always #确保服务中断后自动重启。
volumes:
- /etc/localtime:/etc/localtime:ro #同步宿主机时间
- /:/rootfs:ro #挂载宿主机根目录(只读)。cAdvisor从这里读取主机整体的文件系统使用情况、容器镜像层等信息。
- /var/run:/var/run:rw #挂载Docker运行时目录(读写)。这是唯一需要读写权限的挂载。cAdvisor通过该目录下的Unix套接字(如 /var/run/docker.sock)与Docker守护进程通信,动态发现和查询所有容器的详细信息(如状态、配置)。
- /sys/fs/cgroup:/sys/fs/cgroup:ro #挂载系统信息目录(只读)。/sys 是Linux内核暴露硬件和设备信息的虚拟文件系统,cAdvisor从这里获取CPU、内存、网络设备等全局硬件指标。
- /var/lib/docker/:/var/lib/docker:ro #挂载Docker数据目录(只读)。这里存储了容器的镜像、可写层等实际数据,cAdvisor通过分析它来计算各容器的精确磁盘使用量。
networks: #加入监控专用网络,使Prometheus能通过 cadvisor:8080 访问其指标接口。
- monitoring
expose: #仅暴露端口给内部网络。但不映射到宿主机。
- '8080'
node-exporter: #它是监控栈的 "主机资源探针" ,专门负责收集宿主机本身(即运行Docker的虚拟机或物理服务器)的硬件和操作系统级指标,与 cAdvisor 形成互补。
image: prom/node-exporter:v1.8.0
container_name: node-exporter #指定容器名称。
restart: always # 确保服务中断后自动重启。
volumes:
- /etc/localtime:/etc/localtime:ro #同步宿主机时间。
- /proc:/host/proc:ro #挂载进程信息目录(只读)。Linux的 /proc 虚拟文件系统包含所有进程和内核状态信息(如CPU、内存、任务列表)。这是获取CPU使用率、内存详情、进程统计的关键。
- /sys:/host/sys:ro #挂载系统设备目录(只读)。Linux的 /sys 虚拟文件系统暴露硬件设备、驱动和内核参数信息。用于获取磁盘I/O、网络统计、温度(如有)等指标。
- /:/rootfs:ro #挂载根文件系统(只读)。主要用于计算整个主机和各挂载点的磁盘使用情况。
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host)'
networks: #加入监控专用网络,使Prometheus能通过 node-exporter:9100 访问其指标接口。
- monitoring
ports: #端口映射。将容器内的9100指标端口映射到宿主机的9100端口。
- '9100:9100'
grafana:
image: grafana/grafana:9.3.16
container_name: grafana
restart: always
user: "472:472" #关键修改:指定以Grafana官方用户运行,避免权限问题
volumes:
- /etc/localtime:/etc/localtime:ro
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
env_file:
- ./grafana/config.monitoring
networks:
- monitoring
links:
- prometheus
ports:
- '3000:3000'
depends_on:
- prometheus3.8 运行docker-compose
执行docker-compose.yaml文件之前先执行:此命令只需在首次启动前执行一次。它会将数据卷的所有权赋予Grafana容器用户,
Grafana 官方镜像出于安全考虑,默认强制使用一个非 root 的专用用户来运行,这个用户在镜像内的用户ID(UID)就是 472。
[root@localhost docker-prometheus]# cd /data/docker-prometheus
[root@localhost docker-prometheus]# docker run --rm -v grafana_data:/var/lib/grafana alpine chown -R 472:472 /var/lib/grafana
[root@localhost docker-prometheus]# docker-compose up -d
......
Creating cadvisor ... done
Creating alertmanager ... done
Creating node-exporter ... done
Creating prometheus ... done
Creating grafana ... done运行时间较慢。需要拉取若干docker镜像文件,运行完毕不报错说明成功
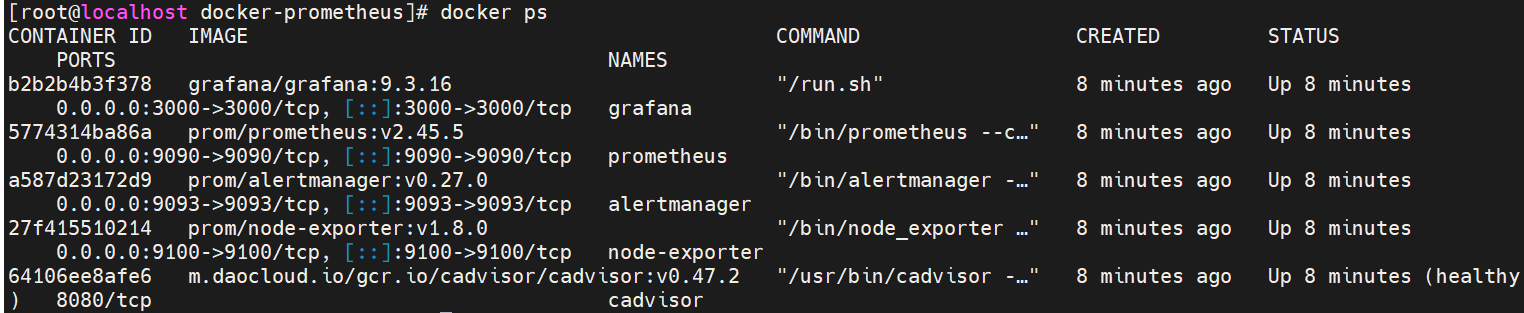
3.9 检查compose的运行状态
检查镜像,发现5个镜像都已正常拉取
docker images检查容器,发现五个容器都处于up运行状态
检查端口
ss -lntp|egrep "3000|9090|9100|9093"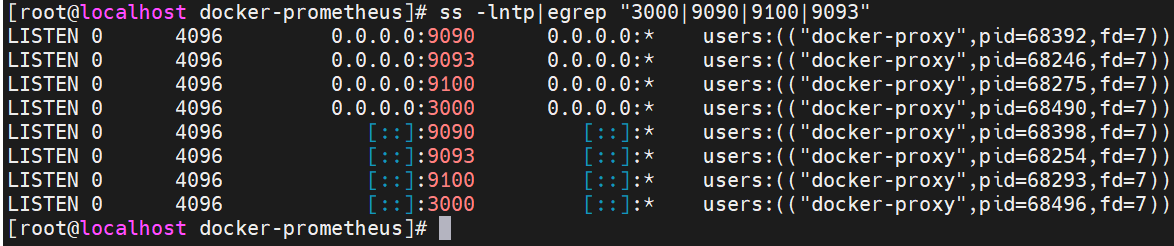
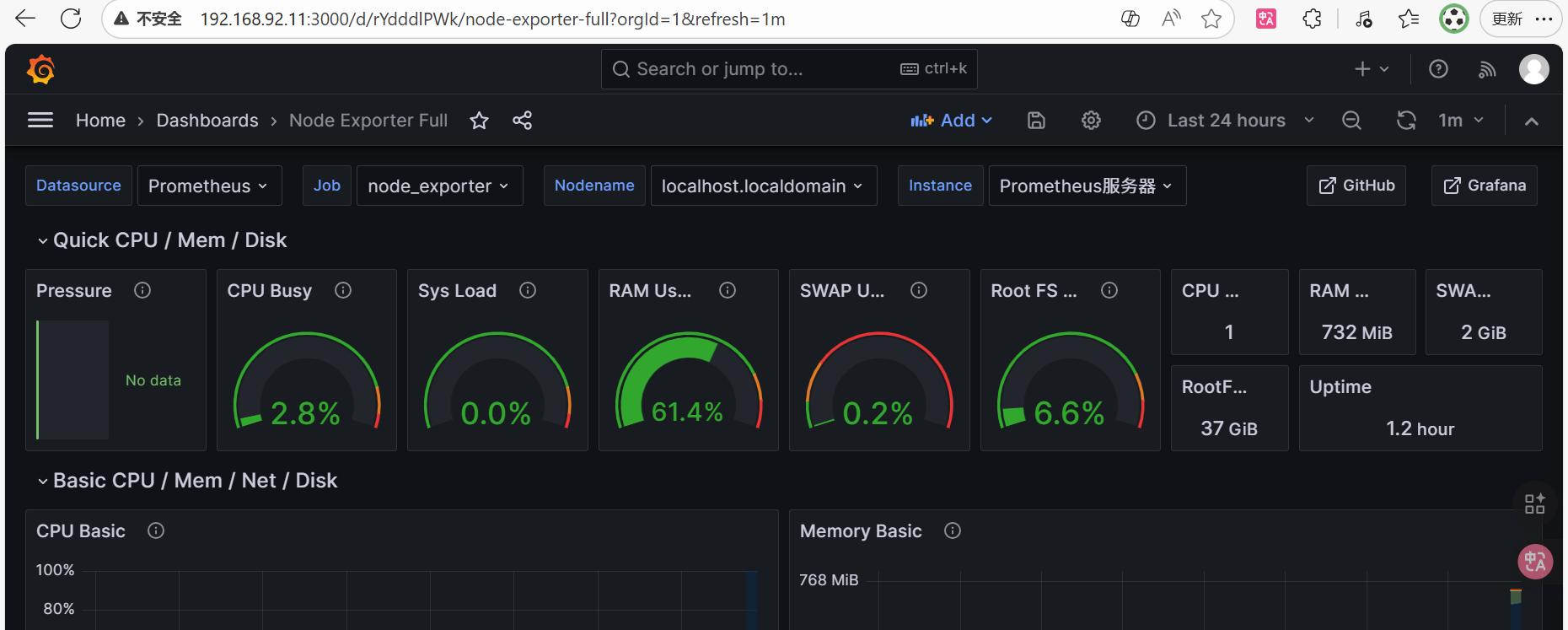
web访问地址
| 应用 | 访问地址 | 账号密码 |
|---|---|---|
| prometheus | http://192.168.92.11:9090/ | 无 |
| grafana | http://192.168.92.11:3000/ | admin/123456 |
| alertmanager | http://192.168.92.11:9093/ | 无 |
| node_exporter | http://192.168.92.11:9100/metrics | 无 |
配置grafana的数据源
。访问grafana
。选择配置->Data sources
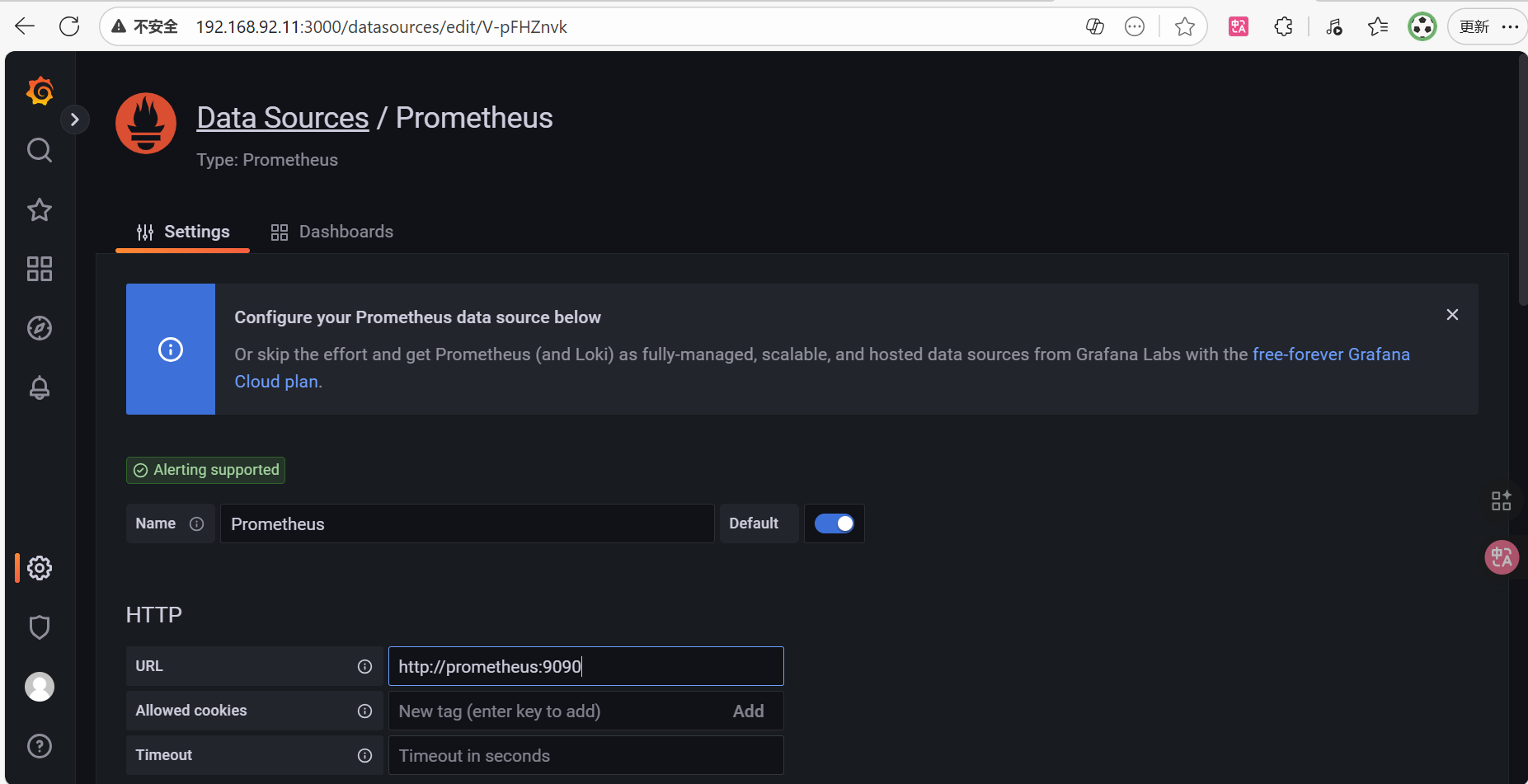
只要配置url,然后点save&test就可以
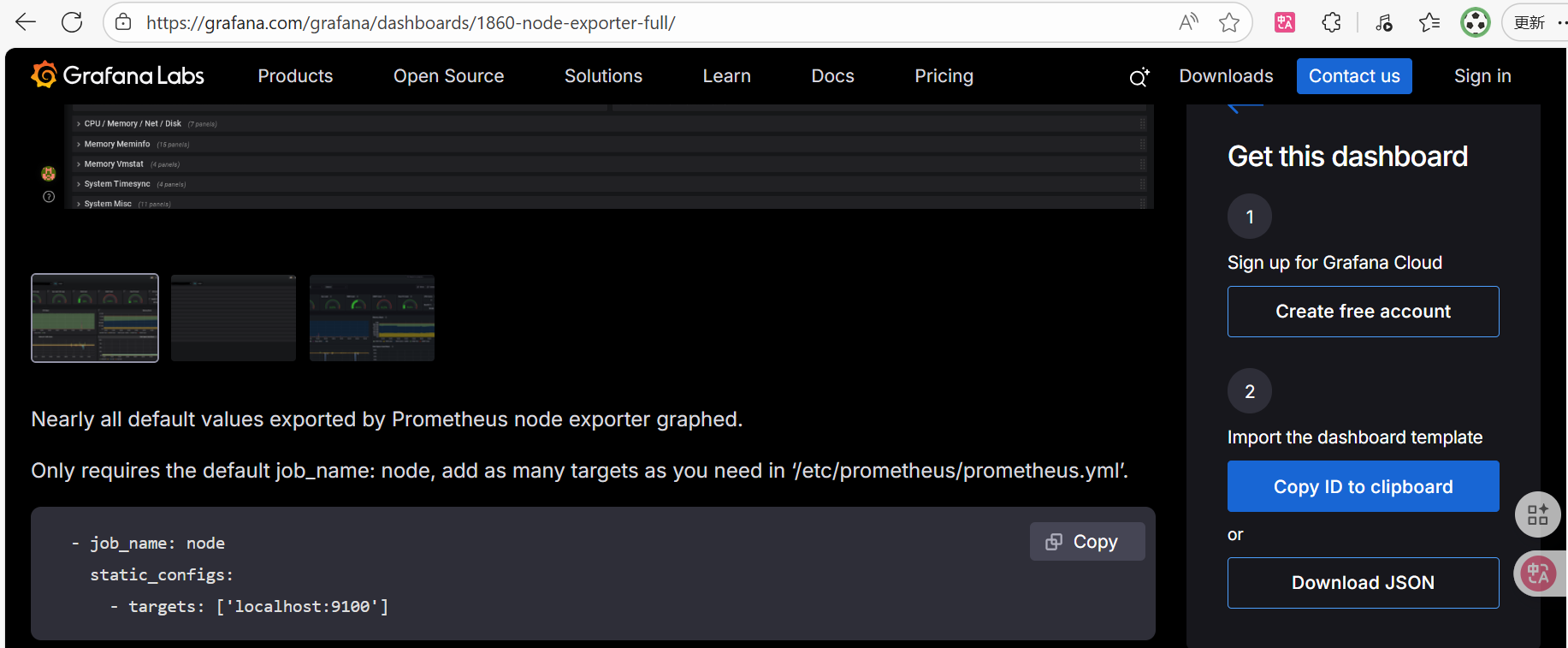
添加node_exporter
。访问grafana官网
https://grafana.com/grafana/dashboards/
找到node exporter full的插件
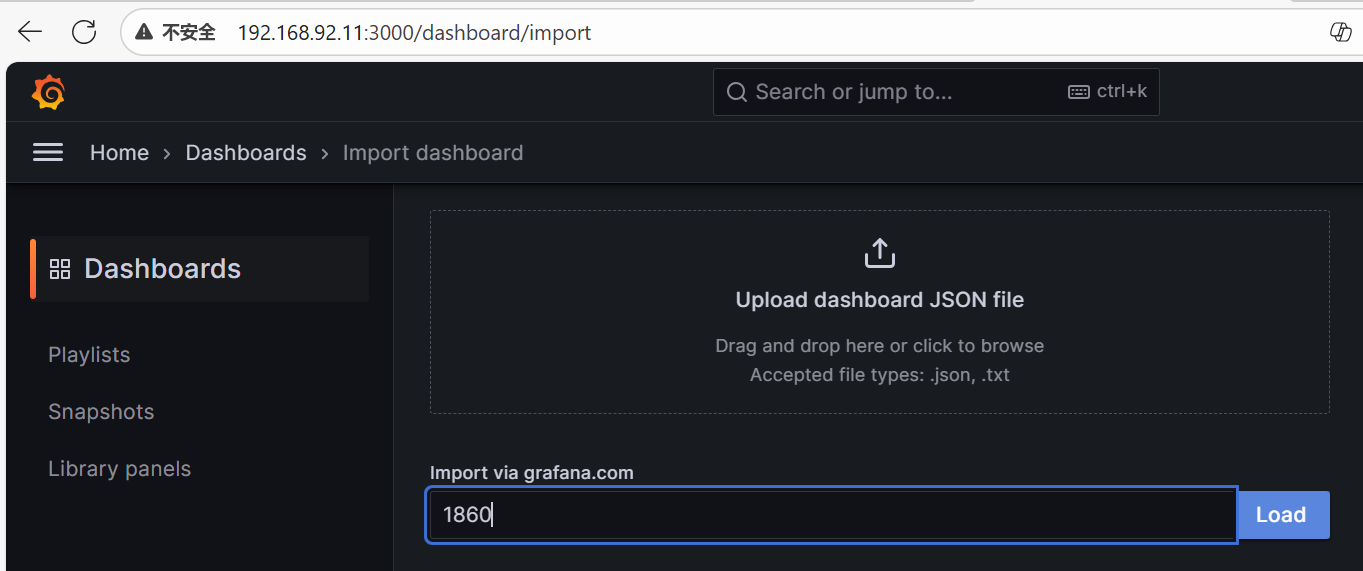

。即可在grafana中查看监控数据