一、MySQL大表的标准和定义

- 数据量维度:单表行数超过1000万行,或单表占用空间超过100GB(不同业务场景下阈值差异较大,如高并发业务中500万行可能就成为大表);
- 并发场景性能维度:查询耗时稳定超过500ms,更新/删除操作出现锁等待,索引维护(创建、删除、重建)耗时过长(超过1小时);
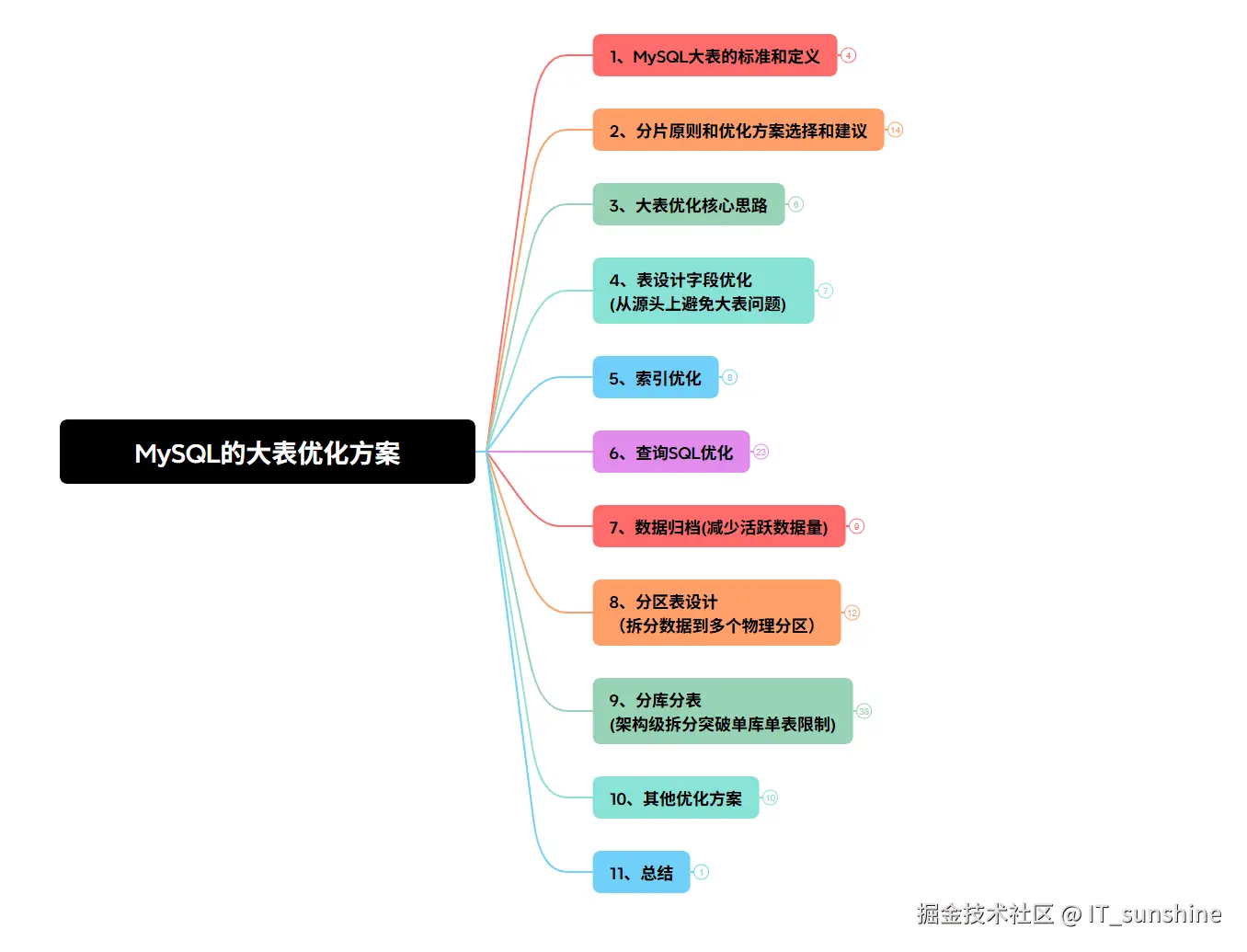
二、分片原则和优化方案选择和建议
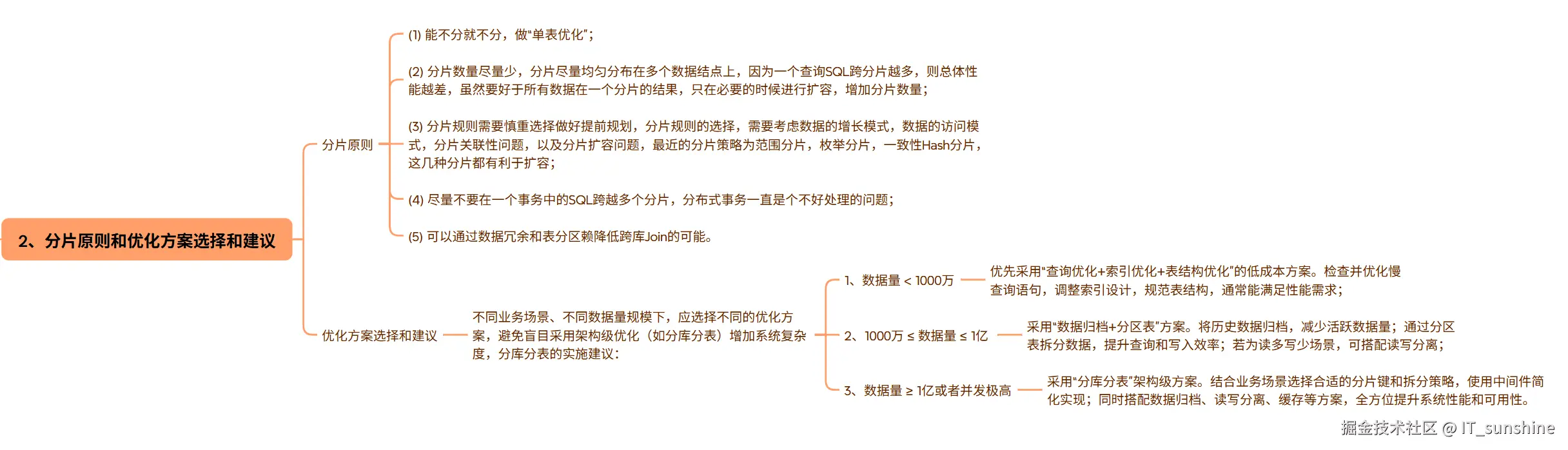
分片原则
(1) 能不分就不分,做"单表优化";
(2) 分片数量尽量少,分片尽量均匀分布在多个数据结点上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量;
(3) 分片规则需要慎重选择做好提前规划,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性Hash分片,这几种分片都有利于扩容;
(4) 尽量不要在一个事务中的SQL跨越多个分片,分布式事务一直是个不好处理的问题;
(5) 可以通过数据冗余和表分区赖降低跨库Join的可能。
优化方案选择和建议
不同业务场景、不同数据量规模下,应选择不同的优化方案,避免盲目采用架构级优化(如分库分表)增加系统复杂度,分库分表的实施建议:
- 数据量 < 1000万:优先采用"查询优化+索引优化+表结构优化"的低成本方案。检查并优化慢查询语句,调整索引设计,规范表结构,通常能满足性能需求;
- 1000万 ≤ 数据量 ≤ 1亿:采用"数据归档+分区表"方案。将历史数据归档,减少活跃数据量;通过分区表拆分数据,提升查询和写入效率;若为读多写少场景,可搭配读写分离;
- 数据量 ≥ 1亿或者并发极高:采用"分库分表"架构级方案。结合业务场景选择合适的分片键和拆分策略,使用中间件简化实现;同时搭配数据归档、读写分离、缓存等方案,全方位提升系统性能和可用性。
三、大表优化核心思路

- 表设计层:从源头减少数据冗余,合理设计表结构和索引,避免数据过度堆积;
- 查询与索引层:提升查询效率,减少无效数据扫描,降低索引维护成本;
- 架构和运维层:通过分库分表、读写分离、数据归档等方式,分散单表压力,提升系统并发能力。
四、表设计字段优化 (从源头上避免大表问题)

- 优先使用占用空间小的字段类型。例如,存储用户ID时,若范围允许,使用INT(4字节)而非BIGINT(8字节);
- 存储状态、性别时,使用TINYINT(1字节)而非VARCHAR;
- 使用整数或枚举代替字符串类型;
- 尽量使用多时区 / 全球化的TIMESTAMP(4字节)而非DATETIME(8字节),同时TIMESTAMP具有自动赋值以及⾃自动更新的特性;
- 单表不要有太多字段,建议在30个以内;
- 避免使用NULL字段,对于非必填字段,设置合理的默认值,避免大量NULL值存储。MySQL对NULL值的存储和查询效率较低,且NULL值无法参与索引;
- 避免使用大字段,尽量避免在核心业务表中使用TEXT、BLOB等大字段。若必须存储(如用户头像、富文本内容),可将大字段拆分到单独的附属表中,核心表仅存储关联ID,减少核心表的数据行大小,提升查询时的磁盘I/O效率;
五、索引优化

- 遵循最左匹配原则,创建联合索引时,将查询频率高、区分度高的字段放在前面。例如,业务中频繁查询"用户ID+订单状态",则联合索引应为(user_id, order_status),而非(order_status, user_id);
- 控制索引数量,单表索引数量建议不超过5个,过多的索引会导致INSERT、UPDATE、DELETE操作时需要同步维护多个索引,严重降低写入性能。对于大表,每增加一个索引,写入耗时可能会显著增加;
- 使用覆盖索引,针对频繁的查询场景,创建覆盖索引,避免回表查询。例如,查询"用户ID、订单金额、订单时间"时,创建联合索引(user_id, order_amount, order_time),查询时可直接从索引中获取所需数据,无需访问主键索引;
- 避免无效索引,删除未使用或重复的索引。可通过MySQL的慢查询日志、sys.schema_unused_indexes视图(MySQL 8.0+)统计索引使用情况,清理无效索引;避免创建与主键索引重复的索引(如主键为id,再创建索引(id));
- 考虑分区索引,对于分区表,索引会按分区创建,每个分区的索引体积更小,查询时只需扫描对应分区的索引,提升查询效率。
- 避免没必要索引,值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段;
- 合理创建联合索引(避免冗余),如(a,b,c) 相当于 (a) 、(a,b) 、(a,b,c);
- 根据查询有针对性创建索引,考虑在WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描;
六、查询SQL优化

①避免全表扫描
- 确保查询走索引:避免在查询条件中对索引字段进行函数操作(如SUBSTR、DATE_FORMAT)、隐式类型转换(如将VARCHAR类型的字段与INT值比较),这些操作会导致索引失效,触发全表扫描。例如,避免"WHERE SUBSTR(user_phone, 1, 3) = '138'",可改为"WHERE user_phone LIKE '138%'"(前提是user_phone字段有索引);
- **避免使用模糊查询前缀%:模糊查询"LIKE '%xxx'"或"LIKE '%xxx%'"会导致索引失效,触发全表扫描。若业务需模糊查询,可考虑使用Elasticsearch等搜索引擎替代,或通过业务调整改为"LIKE 'xxx%'";
- **避免使用OR条件(无索引时):当OR条件中的字段无索引时,会触发全表扫描。可将OR改为UNION ALL(若结果无重复),且确保每个查询分支都走索引。例如,"WHERE user_id = 1 OR order_id = 100"可改为"(SELECT * FROM order WHERE user_id = 1) UNION ALL (SELECT * FROM order WHERE order_id = 100)"。
②优化查询语句结构
- 只查询所需字段:避免使用SELECT *,只查询业务需要的字段。一方面减少数据传输量,另一方面若查询字段可通过覆盖索引获取,可避免回
- 控制JOIN表数量:JOIN表数量越多,查询复杂度越高,性能越差。大表查询中,JOIN表数量建议不超过3个。对于复杂查询,可通过分步骤查询、中间表存储结果等方式简化;
- 避免使用子查询(尤其是相关子查询):相关子查询会导致MySQL重复执行子查询语句,效率极低。可将子查询改为JOIN查询,或通过临时表存储子查询结果;
- 合理使用LIMIT:对于分页查询,使用LIMIT控制返回结果数量。但需注意,当分页页码较大时(如LIMIT 100000, 20),MySQL会扫描前100020条数据再丢弃前100000条,效率较低。可通过"索引+主键"优化,例如"WHERE id > 100000 LIMIT 20"(前提是id为自增主键,且查询条件可基于id过滤)。
③优化事务和锁
- 控制事务粒度:避免长事务,长事务会占用锁资源,导致其他操作出现锁等待。大表操作中,尽量将事务拆分为短事务,只包含必要的SQL语句;
- 使用合理的隔离级别:根据业务需求选择最低的隔离级别。例如,若业务允许脏读,可使用READ UNCOMMITTED;大多数业务可使用READ COMMITTED,避免REPEATABLE READ带来的间隙锁问题,减少锁等待;
- 避免行锁升级为表锁:MySQL中,若查询条件未走索引,会触发全表扫描,此时行锁会升级为表锁,导致其他操作无法并发执行。需确保更新、删除操作的查询条件走索引,避免表锁。
④其他
- 不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边;
- SQL语句尽可能简单:一条SQL只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大SQL可以堵死整个库;
- OR改写成IN:OR的效率是n级别,IN的效率是log(n)级别,in的个数建议控制在200以内;
- 不用函数和触发器,在应用程序实现;
- 模糊查询避免左模糊%xxx式查询;
- 使用同类型进行比较,比如用'123'和'123'比,123和123比;
- 尽量避免在WHERE子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描;
- 对于连续数值,使用BETWEEN不用IN:SELECT id FROM t WHERE num BETWEEN 1 AND 5;
- 列表数据不要拿全表,要使用LIMIT来分页,每页数量也不要太大。
七、数据归档(减少活跃数据量)
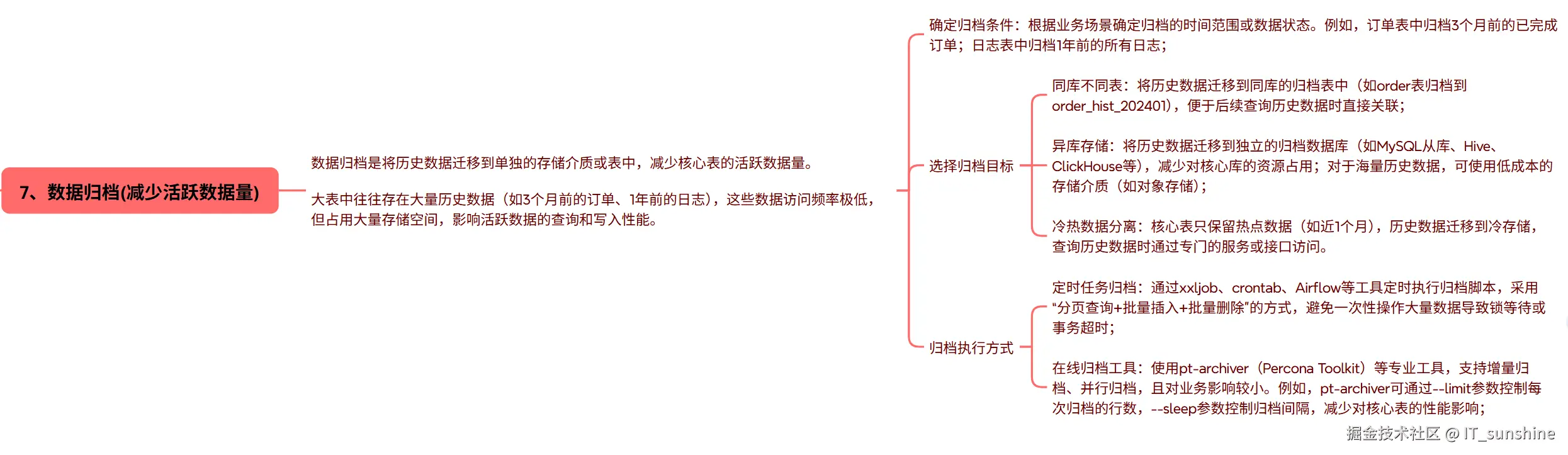
数据归档是将历史数据迁移到单独的存储介质或表中,减少核心表的活跃数据量。 大表中往往存在大量历史数据(如3个月前的订单、1年前的日志),这些数据访问频率极低,但占用大量存储空间,影响活跃数据的查询和写入性能。
-
确定归档条件:根据业务场景确定归档的时间范围或数据状态。例如,订单表中归档3个月前的已完成订单;日志表中归档1年前的所有日志;
-
选择归档目标
- 同库不同表:将历史数据迁移到同库的归档表中(如order表归档到order_hist_202401),便于后续查询历史数据时直接关联;
- 异库存储:将历史数据迁移到独立的归档数据库(如MySQL从库、Hive、ClickHouse等),减少对核心库的资源占用;对于海量历史数据,可使用低成本的存储介质(如对象存储);
- 冷热数据分离:核心表只保留热点数据(如近1个月),历史数据迁移到冷存储,查询历史数据时通过专门的服务或接口访问。
-
归档执行方式
- 定时任务归档:通过xxljob、crontab、Airflow等工具定时执行归档脚本,采用"分页查询+批量插入+批量删除"的方式,避免一次性操作大量数据导致锁等待或事务超时;
- 在线归档工具:使用pt-archiver(Percona Toolkit)等专业工具,支持增量归档、并行归档,且对业务影响较小。例如,pt-archiver可通过--limit参数控制每次归档的行数,--sleep参数控制归档间隔,减少对核心表的性能影响;
八、分区表设计 (拆分数据到多个物理分区)

分区表是MySQL提供的一种表级优化方案,将一个大表在逻辑上拆分为多个小表,物理上存储为多个独立的文件。查询时,MySQL只需扫描对应的分区,无需扫描全表,从而提升查询效率;同时,分区表便于数据归档(直接删除整个分区)、备份恢复(单独备份某个分区)。
-
分区类型选择
- MySQL支持多种分区类型,需根据业务场景选择:
- 范围分区(RANGE Partition):按连续的范围划分分区,适用于按时间、ID等有序字段拆分的场景(如订单表、日志表)。例如,订单表按创建时间分区,每个分区存储1个月的数据;用户表按用户ID分区,每个分区存储100万用户的数据。范围分区是最常用的分区类型,便于数据归档(直接删除旧分区);
- 列表分区(List Partition):按离散的值列表划分分区,适用于数据状态固定的场景(如订单状态、用户所属地区)。例如,订单表按订单状态分区,分为"待支付""已完成""已取消"三个分区, 核销表可以按核销状态分区,分为"未核销"、"已核销"、"已退款";
- 哈希分区(Hash Partition):按字段的哈希值划分分区,适用于数据均匀分布、无明显范围或列表特征的场景。例如,将用户表按用户ID哈希分区,确保每个分区的数据量相对均衡;但哈希分区不便于数据归档;
- 复合分布(Composite Partition):结合两种分区类型(如RANGE-HASH、RANGE-LIST),适用于复杂场景。例如,订单表先按创建时间范围分区,每个范围分区内再按订单状态列表分区。
- MySQL支持多种分区类型,需根据业务场景选择:
-
分区表使用注意事项
- 分区键选择:分区键需与查询条件高度相关,确保查询时能精准定位到少数几个分区(即"分区裁剪")。例如,若订单表的查询多基于创建时间,则分区键选择创建时间;若查询多基于用户ID,则分区键选择用户ID;
- 控制分区数量:分区数量并非越多越好,过多的分区会增加MySQL的元数据管理成本,导致查询时分区裁剪效率下降。一般建议单表分区数量不超过100个;
- 避免跨分区查询:跨分区查询(如查询多个分区的数据)会导致MySQL扫描多个分区,性能可能与非分区表相当甚至更差。需通过业务优化避免跨分区查询,或通过索引优化提升跨分区查询效率;
- 分区表限制:MySQL 5.7及以下版本中,分区表不支持外键;某些存储引擎(如MyISAM)对分区表的支持有限,建议使用InnoDB引擎;分区表的索引是按分区创建的,需确保每个分区的索引设计合理。
九、分库分表 (架构级拆分突破单库单表限制)

-
核心概念
- 水平拆分:将同一个表的数据按行拆分到多个表中,每个表的结构相同。例如,将订单表按用户ID哈希拆分到10个表中,每个表存储10%的用户订单数据。水平拆分是分库分表的主流方式,能有效突破单表数据量限制;
- 垂直拆分:将同一个表的数据按列拆分到多个表中,每个表存储部分字段。例如,将用户表拆分为用户基本信息表(存储ID、姓名、手机号等核心字段)和用户详情表(存储地址、简介等大字段),核心表数据量小,查询效率高;
- 分库:将拆分后的表分布到多个数据库中,避免单库的CPU、内存、磁盘I/O资源瓶颈。例如,将10个订单分表分布到2个数据库中,每个数据库存储5个分表;
- 分片键:用于拆分数据的字段(如用户ID、订单ID、创建时间),分片键的选择直接影响分库分表的效果,需确保数据均匀分布、查询能精准定位分片。
-
分库分表策略
-
水平拆分
- 范围拆分:按分片键的范围拆分数据,如按订单创建时间拆分,每个分片存储1个月的数据;按用户ID拆分,每个分片存储100万用户的数据。范围拆分便于数据归档(直接删除旧分片),但可能出现数据热点(如最新月份的订单分片访问频率极高);
- 哈希拆分:按分片键的哈希值取模拆分数据,如按用户ID % 10拆分到10个分片。哈希拆分能确保数据均匀分布,避免热点分片,但不便于数据归档,查询历史数据时可能需要访问多个分片;
- 一致性哈希拆分:在哈希拆分的基础上,通过一致性哈希算法减少分片扩容时的数据迁移量。适用于业务数据量持续增长、需要频繁扩容的场景。
-
垂直拆分
- 按字段访问频率拆分:将高频访问的核心字段(如用户ID、姓名、订单金额)放在主表,低频访问的字段(如用户简介、订单备注)放在从表;
- 按字段类型拆分:将大字段(TEXT、BLOB)拆分到单独的表中,主表仅存储关联ID,减少主表的数据行大小,提升查询效率。
-
分库分表实现方式
-
客户端分片
- 在应用程序中直接实现分库分表逻辑,通过代码控制数据的写入和查询分片。优点是灵活性高,缺点是开发成本高,需维护大量分片逻辑代码,后续扩容、迁移困难;
-
中间件分片
- 使用专业的分库分表中间件(如Sharding-JDBC、MyCat、TDSQL),中间件封装了分片逻辑,应用程序通过中间件访问数据库,无需关注分片细节。优点是开发成本低、易于维护和扩容,是目前主流的实现方式。
-
-
如何保证分布式数据库架构中全局唯一ID的生成?
-
分布式ID生成的要求和核心难点
- (1) 全局唯一性:保持生成的ID全局唯一,在任何情况下也不会出现重复的值(如防止时间回拔,时钟周期问题);
- (2) 趋势递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM聊天中的增量消息、排序等特殊需求;
- (3) 高性能:ID的需求场景多,中心化生成组件后,需要高并发处理,以接近 0ms的响应大规模并发执行;
- (4) 高可用: 作为ID的生产源头,需要100%可用,当接入的业务系统多的时候,很难调整出各方都可接受的停机发布窗口,只能接受无损发布;
- (5) 易接入:作为逻辑上简单的分布式ID要推广使用,必须强调开箱即用,容易上手;
-
大厂自研分布式ID框架实现
- 美团分布式ID生成系统Leaf(对Snowflake算法进行了改进)
- Leaf-segment方案:可生成全局唯一、全局有序的ID
- Leaf-snowflake方案:可生成全局唯一、局部有序的ID
- 百度分布式ID生成器UidGenerator(对Snowflake算法进行了改进)
- 滴滴的高性能ID生成器(Tinyid)
- vivo的自研分布式ID服务
- 美团分布式ID生成系统Leaf(对Snowflake算法进行了改进)
-
-
各大框架对比

- 分片键选择至关重要:分片键需满足"数据均匀分布"和"查询精准定位"两个核心要求。例如,订单表若按订单ID哈希拆分,查询"某用户的所有订单"时会需要访问所有分片,效率极低;此时应选择用户ID作为分片键,查询时可直接定位到用户所属的分片;
- 避免分布式事务:分库分表后,跨分片的操作会产生分布式事务,分布式事务实现复杂、性能差。需通过业务优化避免跨分片操作,或采用最终一致性方案(如本地消息表、事务消息)替代分布式事务;
- 考虑扩容方案:拆分时需预留扩容空间,避免后续扩容时大量数据迁移。例如,采用一致性哈希拆分,或按"2的幂次"拆分(如初始拆分为8个分片,后续可扩容为16个);
- 运维复杂度提升:分库分表后,数据库集群的运维难度显著增加,需关注分片的健康状态、数据一致性、备份恢复等问题。可借助中间件的监控功能,或使用专业的运维工具(如Prometheus、Grafana)进行监控。
十、其他优化方案
-
读写分离
- 对于读多写少的大表场景(如商品表、用户表),可采用读写分离架构:主库负责写入操作(INSERT、UPDATE、DELETE),从库负责读取操作(SELECT),通过主从复制同步数据。读写分离能分散单库的读写压力,提升查询性能,需注意主从复制的延迟问题,对于实时性要求高的查询,需路由到主库。
-
数据库参数优化(通过优化MySQ的配置参数,提升数据库性能)
- 调整缓冲池大小(innodb_buffer_pool_size):建议设置为服务器物理内存的50%-70%,提升数据和索引的缓存命中率;
- 调整日志相关参数(innodb_log_file_size、innodb_log_buffer_size):增大日志文件大小,减少日志刷盘次数;增大日志缓冲区,减少磁盘I/O;
- 调整连接数参数(max_connections、wait_timeout):根据业务需求设置合理的最大连接数,避免连接耗尽;设置合理的连接超时时间,释放空闲连接;
-
硬件与存储优化,硬件和存储是数据库性能的基础,大表场景下需选择高性能的硬件
- 使用SSD硬盘:SSD的读写速度远高于机械硬盘,能显著提升大表的磁盘I/O效率;
- 提升CPU和内存配置:大表查询和索引维护需要大量CPU和内存资源,选择多核CPU、大容量内存的服务器;
- 使用RAID阵列:通过RAID 0、RAID 10等阵列方式,提升磁盘的读写性能和可靠性。
十一、总结
MySQL大表优化是一个系统性工程,需从表设计、查询、索引、数据归档、分区表、分库分表等多个维度综合考量,核心是"减少数据量、降低访问成本、分散压力"。优化过程中应遵循"先易后难、先软后硬"的原则,优先采用低成本、低风险的方案,再根据业务需求逐步升级到架构级优化。大厂的实战案例表明,优化方案需紧密结合业务场景:电商订单表适合分库分表+数据归档,日志表适合分区表+冷热分离,商品表适合垂直拆分+读写分离+缓存。同时,优化后的监控与运维至关重要,能确保系统长期稳定运行。好了,今天的分享就到此结束了,如果文章对你有所帮助,欢迎:点赞👍+评论💬+收藏❤ ,我是:IT_sunshine ,我们下期见!