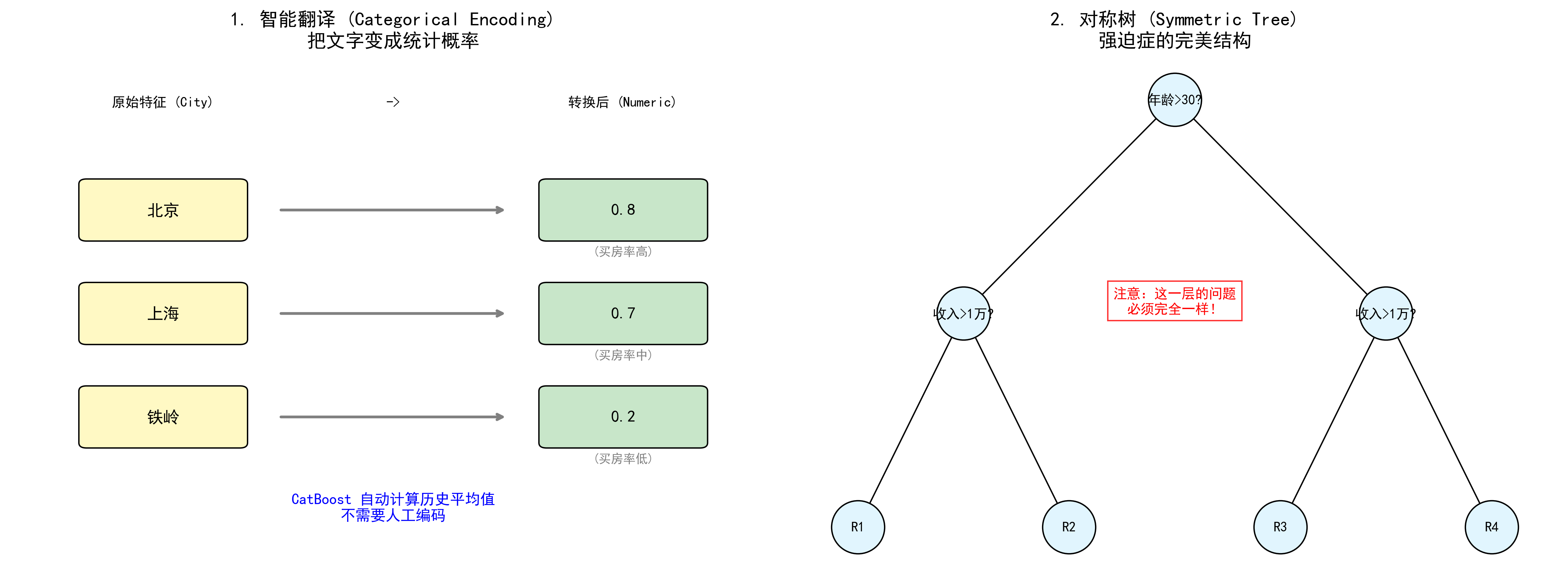
图解说明:
- 左图 (智能翻译):CatBoost 能自动把"北京"、"上海"这样的文字,转换成"买房概率"这样的数字,机器直接能读懂。
- 右图 (对称树):CatBoost 的树结构非常整齐,同一层的问题必须一样(比如都问"收入>1万?"),这让它预测速度飞快。
GBDT 家族的第三位巨头------CatBoost。
它的名字听起来像"猫 (Cat)",但其实它是 Category (类别) + Boosting (提升) 的缩写。
如果说 XGBoost 是力量型 选手,LightGBM 是速度型 选手,那么 CatBoost 就是一位技巧型 选手,它最擅长的绝活是:处理那些非数字的"类别"数据。
它是俄罗斯搜索巨头 Yandex 开源的神器。如果你完全不懂算法,没关系。我们来看看它到底解决了什么痛点。
1. 它的必杀技:搞定"类别特征"
在机器学习里,电脑只认识数字(1, 2, 3...),不认识文字。
但是,现实世界里有很多数据是**"类别"**,比如:
- 颜色:红、黄、蓝
- 城市:北京、上海、广州
- 品牌:苹果、华为、小米
传统方法的尴尬
以前,为了让电脑看懂这些词,我们通常用两种笨办法:
- 编号法 (Label Encoding) :
- 北京=1,上海=2,广州=3。
- 问题:电脑会误以为"广州(3)"比"北京(1)"大,但这只是个代号,没有大小之分啊!这会误导模型。
- 独热编码 (One-Hot Encoding) :
- 变成 3 列:是北京吗?是上海吗?是广州吗?
- 问题:如果城市有 1000 个,表格瞬间变宽 1000 倍,电脑内存直接爆炸。
CatBoost 的智慧:智能翻译
CatBoost 自带一个超级聪明的"翻译官"。它不需要你手动处理这些数据,扔进去就行。
它用了一种叫 Ordered Target Statistics (排序目标统计) 的方法。
简单说,就是用"历史平均值"来代替类别。
举个栗子 🌰 :
我们要预测一个人会不会买房。特征是"城市"。
- CatBoost 会看:在过去的数据里,"北京"的人买房的概率是多少?比如是 80%。
- 那它就把"北京"翻译成 0.8。
- "上海"的人买房概率是 70%,那就翻译成 0.7。
这样,既保留了城市的特征,又变成了电脑能看懂的数字,而且没有增加表格的宽度!
2. 另一个绝活:对称树 (Symmetric Trees)
XGBoost 和 LightGBM 长出来的树,往往是歪七扭八的(哪里有需要往哪里长)。
但 CatBoost 有强迫症,它长出来的树是完全对称的。
什么是对称树?
- 普通树:第一层判断"年龄>30?",左边分支第二层判断"收入>1万?",右边分支第二层判断"有孩子吗?"(左右问的问题不一样)。
- 对称树 :第一层判断"年龄>30?",不管你走左边还是右边 ,第二层必须都问"收入>1万?"。
为什么要这么做?
虽然看起来有点死板,但这对计算机非常友好!
- 预测速度极快:因为结构固定,电脑可以并行处理,预测的时候就像走高速公路,不用频繁变道。
- 不容易过拟合:结构简单,泛化能力强。
3. 为什么叫 "Ordered" (有序)?
CatBoost 在训练的时候,非常讲究**"先来后到"**。
在计算"北京买房概率"的时候,它不会偷看未来的数据。
- 比如处理第 100 条数据时,它只统计前 99 条数据里"北京"的情况。
- 这有效防止了**"数据泄露"**(Prediction Shift),就像考试时坚决不让你偷看标准答案,这样练出来的模型才经得起实战考验。
4. CatBoost 的优缺点
✅ 优点 (为什么它是神器?)
- 傻瓜式操作:不用费劲做特征工程(把文字转数字),直接把含中文、字符串的表格扔进去,它自己会处理得很好。
- 参数少:默认参数的效果就非常好,不需要像 XGBoost 那样调参调半天。
- 预测快:得益于对称树结构,模型上线后跑得飞快。
❌ 缺点 (也要注意)
- 训练慢:虽然预测快,但训练过程(尤其是处理类别特征时)比较耗时,比 LightGBM 慢不少。
- 吃显存:如果用 GPU 训练,对显存要求比较高。
5. 总结
CatBoost 就是一位自带翻译官的强迫症专家:
- Category :最擅长处理红黄蓝、北上广这种类别数据,自动把它们翻译成靠谱的数字。
- Symmetric :种的树必须对称,为了预测起来跑得快。
- Ordered:严格遵守时间顺序,不偷看答案。
如果你手头的数据里有很多非数字的列 (比如电商数据、用户画像),又不想花时间洗数据,CatBoost 绝对是你的首选!🐱