2025.12.26论文阅读记录
论文题目:
《Location is Key: Leveraging LLM for Functional Bug Localization in Verilog Design》
《定位是关键:利用大型语言模型实现Verilog设计中的功能缺陷定位》
论文方法概述
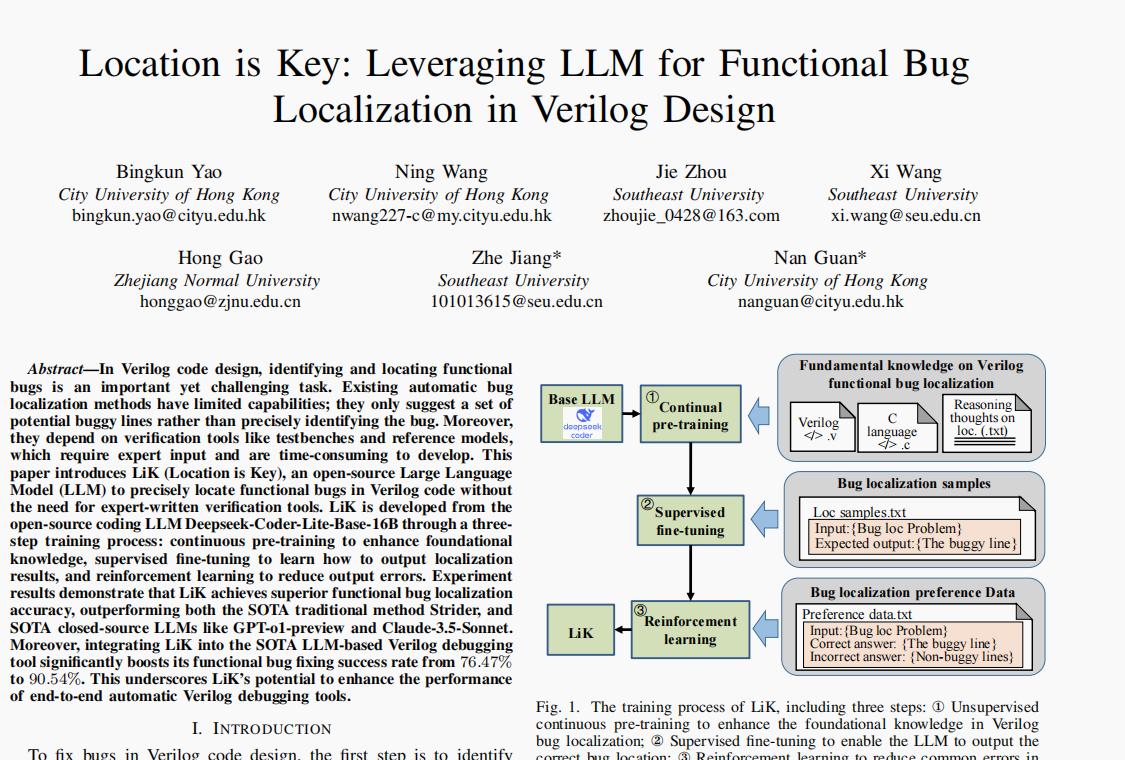
论文提出了一个名为LiK (Location is Key)的开源大语言模型(LLM),用于自动定位Verilog代码中的功能性bug。与传统方法不同,LiK不依赖于专家编写的测试工具或验证模型,直接通过分析代码来定位bug****。
定位bug 注释:分析定位,没有说修改
LiK的训练过程分为三步:
- 持续预训练 (Continual Pre-training):提高模型对Verilog的基础知识。
- 有监督微调 (Supervised Fine-tuning):让模型学会输出准确的bug定位结果。
- 强化学习 (Reinforcement Learning):通过减少常见的定位错误,进一步提高模型的性能。
方法细节
1. 持续预训练(Continual Pre-training)
- 目的 :让基础模型获得更多关于Verilog的知识,特别是如何识别和定位bug。
- 数据来源 :
- VGen 数据集c16472 (包含来自GitHub的开源Verilog代码)。
- OpenCores 数据集(一个重要的开源硬件设计平台)。
- 内部数据集(从与硬件设计公司合作获取)。
- 预训练流程 :通过两轮无监督的预训练,首先增强模型对Verilog语言的基础理解,再通过第二轮专注于功能性bug定位。
2. 有监督微调(Supervised Fine-tuning)
- 在这一步,使用已标注的bug定位样本对模型进行训练,模型输入 包括Verilog设计描述和带bug的代码,输出 是特定的bug定位(即准确的bug行)。
- 数据量 :由于训练数据有限(36.72MB),作者采用了LoRA算法(低秩适配)来避免过拟合。
3. 强化学习(Reinforcement Learning)
- 目的:让模型在训练过程中通过反馈学习避免错误。
- 如何运作 :强化学习(使用SimPO算法 )通过对正确和错误的输出进行奖励差异化处理,鼓励模型选择正确的bug定位行。
- 训练样本 :每个训练样本包含一个bug定位问题 ,以及正确答案 (bug所在的行)和错误答案(非bug行)。
数据来源和训练过程
- 数据来源 :训练数据来自以下几个方面:
- VGen 数据集:包括GitHub上的开源Verilog代码。
- OpenCores 平台:提供了更多的硬件设计代码。
- 内部数据集:来自与硬件设计公司合作的专有数据。
- 数据大小 :由于硬件设计领域的封闭性,Verilog的公开数据非常有限,总数据大小为253MB。
- 数据生成 :通过Claude-3.5-Sonnet生成了关于bug定位的推理思维(reasoning thoughts),这些思维帮助模型更好地理解bug的定位方式。
性能评估
实验结果表明,LiK 模型的bug定位准确率 超过了现有的传统方法(Strider)和其他LLM模型(如GPT-4、Claude-3.5)。具体表现如下:
- LiK 的性能(pass@1) :93.33%,大大超过了所有其他模型。
- 与其他LLM模型的对比 :包括GPT-3.5 (40.25%)、Claude-3.5(90.8%)等,LiK的准确率明显更高。
此外,LiK在不同类型的bug定位上表现出色,特别是在数值错误、关键字错误和边缘条件错误的定位上,优于其他所有基线方法。
影响强化学习的作用
强化学习帮助LiK减少了错误的定位,改进了bug定位的稳定性。通过奖励机制,模型能更好地处理输出不稳定的问题,并在不同的温度设置下提高定位准确度。
未来方向
- 增加数据集的规模:由于硬件设计数据稀缺,未来将尝试增加更多的训练数据以进一步提升模型的性能。
- 扩展到更多硬件语言 :LiK目前主要用于Verilog,未来还计划扩展到VHDL 、SystemVerilog等其他硬件描述语言。
总结
这篇论文介绍了LiK ,一个用于自动定位Verilog功能性bug 的开源LLM模型。LiK通过三步训练:预训练、微调和强化学习,显著提升了bug定位的准确性。通过与现有方法的对比,LiK表现出色,特别是在不依赖专家工具的情况下,它能直接定位bug所在的行。
LiK不仅为硬件开发人员 提供了一个有效的自动化调试工具,还为未来的自动化硬件调试系统提供了重要的改进方向。
如果你有更多问题,或者需要进一步的解释,随时告诉我!
更加详细的介绍一下:如下
1. 论文的目标与任务
这篇论文的目标是开发一个用于定位Verilog代码中功能性++bug++的工具 。功能性bug不同于语法错误,它们可以通过语法检查,但却导致电路行为异常,检测起来非常困难。因此,自动定位这些bug是非常具有挑战性的,尤其是当开发人员无法依赖传统的手动验证工具(如testbenches和参考模型)时。
论文提出了一个新的方法,名为LiK (Location is Key),这是一个基于**大型语言模型(LLM)**的工具,能够在没有专家提供验证工具的情况下,精确地定位Verilog代码中的功能性bug。
帮我通俗的解释一下这里功能性bug是啥?通俗的例子解释一下
功能性 bug 的定义
功能性bug 是指在程序或硬件设计中,代码看起来没有语法错误,能够顺利通过语法检查,但在实际运行时 却会导致程序或硬件设备表现不正常,出现了意外的行为。这种类型的bug通常是由于逻辑错误或者设计不当引起的。
与语法错误的区别:
- 语法错误:像是拼写错误或格式不正确的代码,编译器或解释器会立刻报错,告诉你哪里出了问题。
- 功能性bug:代码在语法上是正确的,但执行时却不能按照预期工作,可能是因为逻辑上出错或者条件判断错误。
例子1:时钟分频器中的功能性bug
假设你在设计一个时钟分频器,它的任务是将一个频率较高的时钟信号分频成一个频率较低的信号。代码看起来没有问题,语法检查也通过了,但是它在实际运行时却没有按预期工作。
- 代码中的错误 :你可能在计算分频系数时,输入了错误的数值,例如将分频系数设置成了8 ,而实际应该是16。这个错误在语法上没有问题,编译器不会报错,程序也能正常运行,但是输出的频率会不对,导致电路行为异常。
- 具体影响:假设这个分频器用于产生时序信号,作为其他电路的时钟源。如果时钟频率错误,其他依赖这个信号的电路也会发生错误,可能导致整个系统无法正常工作。
例子2:加法器中的功能性bug
假设你设计了一个加法器,用于计算两个数的和。你的代码逻辑上看起来没有问题,但加法器总是返回错误的结果。
- 代码中的错误:你可能在加法的实现中,不小心将某些位的输入顺序搞错了(比如第一个数的高位和低位位置交换了)。这个错误看起来并不会触发语法错误,编译器不会报错,因为你的代码没有违反语法规则,但是加法的结果就会错。
- 具体影响 :在实际应用中,可能会出现计算结果与预期不符的问题。例如,原本期望加法器输出5 + 3 = 8,但是加法器却输出了一个错误的结果5 + 3 = 6,这个错误看起来是正常的代码运行,但显然不符合预期。
功能性bug 的挑战:
- 为什么难以检测 :功能性bug不像语法错误那样容易被编译器或者解释器发现。编译器只检查代码的语法是否正确,并不会检查代码是否实现了预期的功能。功能性bug更多的是由于逻辑设计上的缺陷,这些问题不会被语法检查工具发现。
- 如何定位功能性bug :要检测功能性bug,我们需要通过运行时的行为 来观察电路或程序是否按预期工作,通常依赖于测试用例 或模拟来验证设计的正确性。而这正是LiK(Location is Key)模型的目标所在,它帮助自动定位这些功能性bug。
总结:
功能性bug 就是程序或电路运行时,虽然代码语法正确,但它的行为不符合预期,导致系统或设计出现错误。功能性bug很难通过简单的语法检查发现,通常需要深入分析代码的逻辑或者通过测试来定位。
2. 使用的核心方法
LiK的训练和工作流程有三个主要阶段:
第一步:持续预训练(Continual Pre-training)
- 目标 :增强基础模型对Verilog代码和功能性bug定位的理解。
- 如何做的 :
- 首先,基于开源的Deepseek-Coder-Lite-Base-16B 模型,LiK进行了无监督的预训练 ,使其具备了对Verilog代码的基本理解。c16473
- 预训练使用了大量的Verilog数据 和少量的C语言数据。其中C语言用于帮助模型理解Verilog和C语言的相似之处(因为它们在语法结构上有很多相似性),这样有助于模型更好地理解Verilog的特性。
预训练使用的数据来源包括:
-
- VGen 数据集:来自GitHub的开源Verilog文件。
- OpenCores 平台:这是一个主要的开源硬件设计平台。
- 内部数据集:从与硬件设计公司合作获取的Verilog代码。
第二步:有监督微调(Supervised Fine-tuning)
- 目标 :让模型学会输出正确的bug定位。
- 如何做的 :
- 通过有监督微调 ,LiK学习如何从给定的设计描述和带bug的Verilog代码中输出正确的bug行。微调的输入是一个带有bug的Verilog代码和其设计描述,输出是该代码中具体的bug行。
- 由于训练数据较少,微调阶段使用了LoRA算法(低秩适配)来防止过拟合,确保训练过程更加高效。
第三步:强化学习(Reinforcement Learning)
- 目标 :进一步优化模型,减少定位错误,提升bug定位的准确性。
- 如何做的 :
- 强化学习 通过奖励机制使模型在生成结果时,优先生成正确的bug行 ,同时避免生成错误的bug行 。强化学习(使用SimPO算法)让模型从正确和错误的答案中学习,进一步减少常见的bug定位错误。
- 在训练过程中,模型通过模拟生成多个答案,并将正确答案 (实际bug行)和错误答案(非bug行)进行比较,优化参数,提升准确度。c16474
3. 使用的数据集
LiK使用了多个来源的数据集来训练和优化模型:
1. VGen 数据集
- 该数据集包含来自GitHub的开源Verilog代码 ,包括了大量的Verilog模块。VGen数据集为LiK提供了多样的Verilog代码样本,有助于提高模型对Verilog语法和结构的理解。
2. OpenCores 数据集
- OpenCores 是一个开源硬件设计平台,包含了大量的Verilog设计文件。通过这个平台,LiK可以接触到更多种类的硬件设计代码。
3. 内部数据集
- 为了弥补公开数据集的不足,LiK还使用了来自合作硬件设计公司的数据集 。这些数据集是专有数据,因此提供了更多行业特定的设计样本。
- 由于数据的稀缺性 ,特别是在硬件设计领域的封闭性 ,LiK使用了合成数据生成 方法。首先从现有的Verilog代码中插入bug,然后使用Claude-3.5-Sonnet 生成推理思维(reasoning thoughts),帮助模型更好地理解bug的定位方式。
Bug 插入类型:
- 运算符错误 :例如"+"与"-"的错误使用。
- 数值错误 :例如时钟分频比设置为8而不是16,或者声明一个4位信号时应该是6位。
- 关键字错误 :例如使用错误的关键字,如"wire"与"reg"。
- 变量名错误 :例如错误引用变量,如"counter1"与"counter2"。
- 边缘错误:例如将上升沿"posedge"与下降沿"negedge"混淆。
数据生成过程:
- 在每个Verilog模块中,随机插入这些类型的错误,并生成包含错误代码及其对应bug行的数据样本。
4. 实验和结果
LiK的性能经过一系列实验验证,特别是在bug定位准确性方面表现优异:
性能评估指标:
- pass@1 :表示模型生成的第一答案 是否正确,直接衡量模型的准确性。
- pass@5 :表示模型生成的前五个答案 中是否包含正确的答案,衡量模型的多样性和鲁棒性。
实验结果:
- 在bug定位任务中,LiK的pass@1 为93.33%,显著高于所有其他模型(如GPT-4 的78.08%和Claude-3.5的90.8%)。
- 通过将LiK与传统方法 (如Strider)进行对比,LiK不仅能够更准确地定位bug,还能减少错误输出,避免生成不相关的多行输出。
不同bug类型的表现:
- LiK在定位数值错误、关键字错误和边缘错误等类型的bug时,表现尤其突出,准确性超过了所有基准模型。
LiK 的集成效果:
- 将LiK集成到现有的自动Verilog调试系统(如MEIC)后,bug修复成功率从76.47%提升到90.54%,显示出LiK对自动调试系统的显著改进效果。
5. 结论
LiK是一个通过基于LLM的训练和强化学习方法,高效定位Verilog功能性bug的工具。其创新之处在于:
- 无须专家编写的验证工具 ,能够直接从Verilog代码中精确定位bug。
- 通过强化学习优化bug定位过程,提高准确性。
- 集成到现有的自动调试系统中,显著提升功能性bug修复的成功率。
论文展示了LiK在定位Verilog功能性bug中的强大能力,并指出了LLM在硬件调试中的广泛潜力。
c16471分析定位,没有说修改
c16472数据集添加进去自己的表格(这几篇文献的都总结一下)
c16473先无监督学习基本的Verilog代码理解, 然后有监督微调确定bug定位
c16474形成一个正向激励或者抵制
c16475他也用了这个东西(说数据太少了)
c16476分析完这几个文章的:
用的什么方法
什么数据集
做了什么任务
达到什么样的效果
分析完成以后就是跟潘博交流一下,这个文章也是使用了自己加入bug,按道理说最后结果也不具有说服力,得不到认可;看看潘博可以不可以给讲一下,他现在正在做的任务,也就是王老师认可的做法(我现在只知道你使用的是那个Hack@DAC 2021)那个数据集