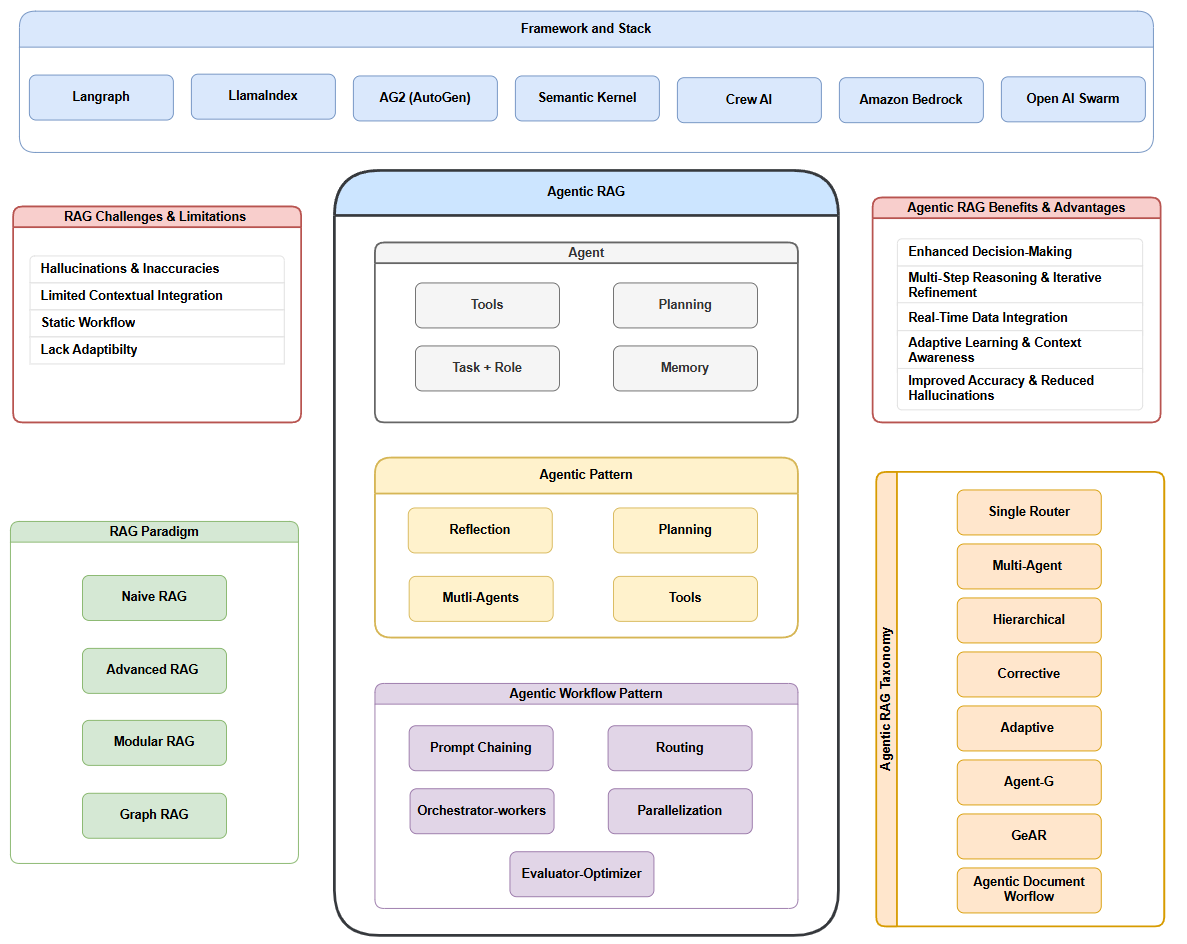
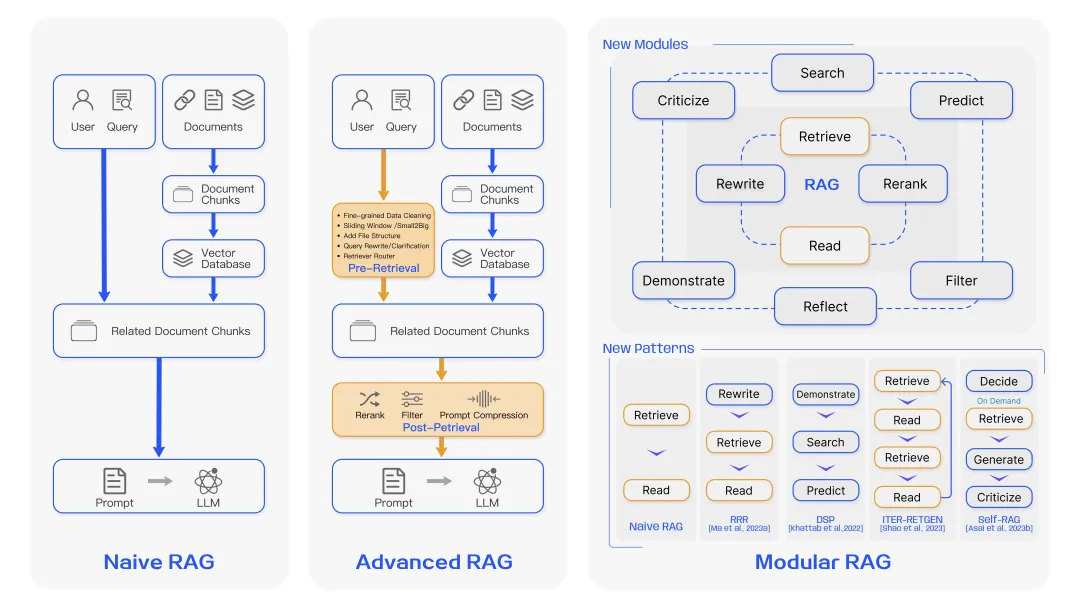
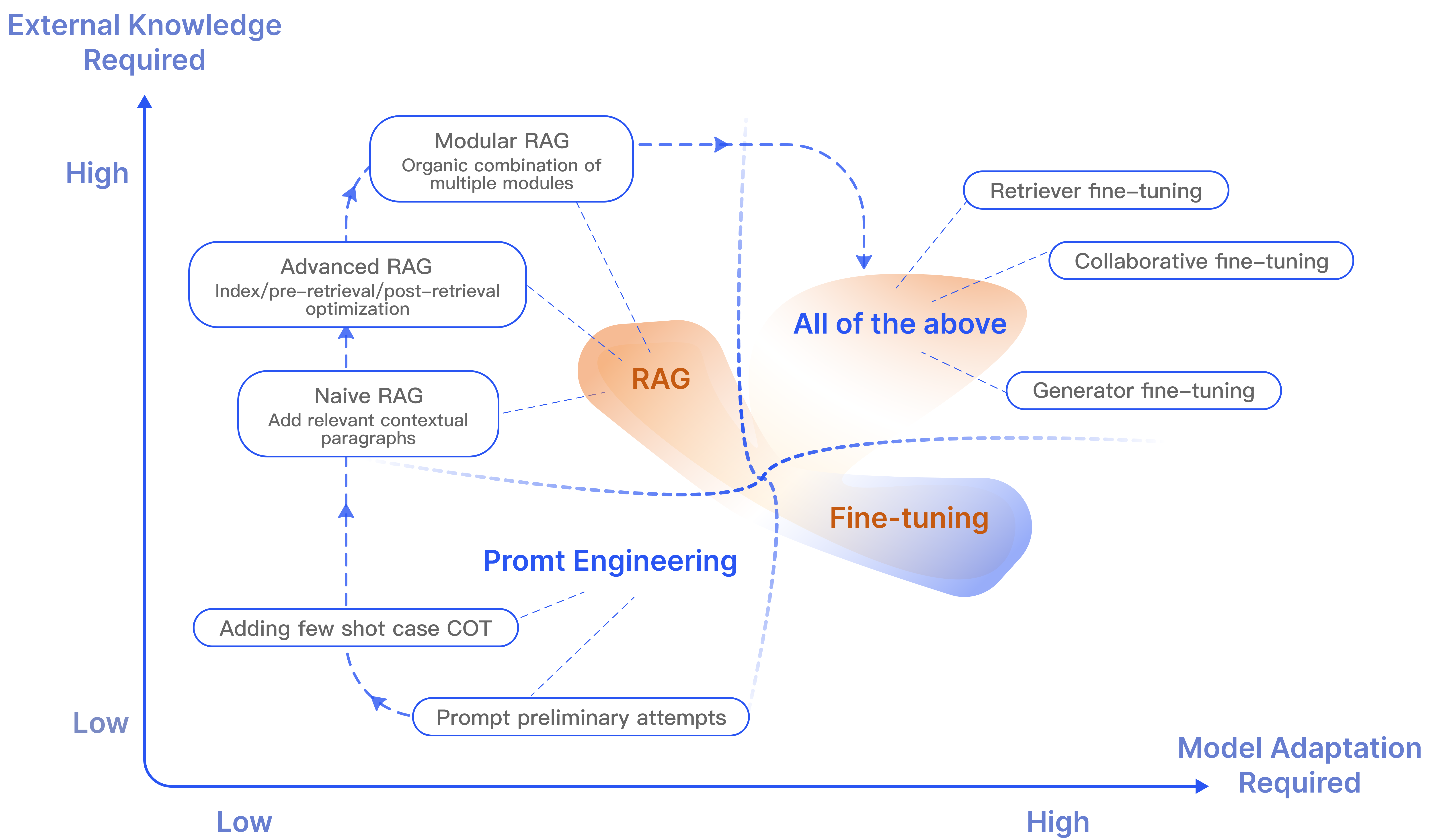
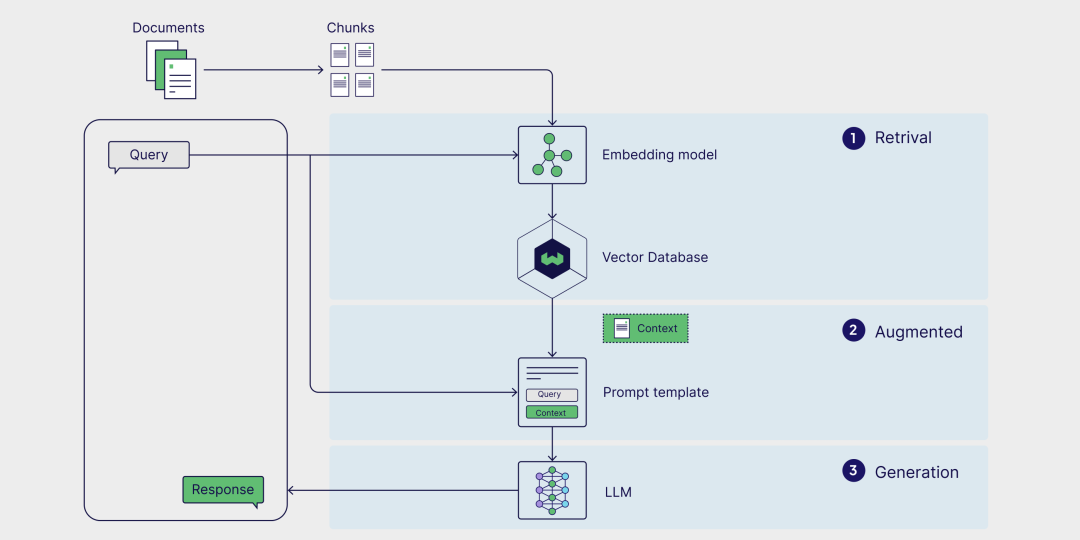
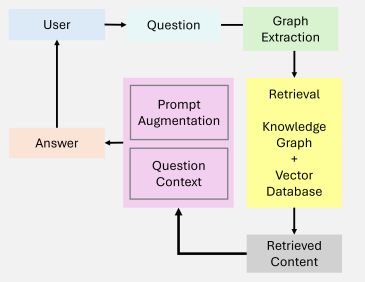
**稠密检索(Dense Retriever):****将query与文档都编码为向量,在向量空间中计算相似度(如内积或余弦距离);能够基于语义理解检索相关内容;需要训练编码器,存储开销大,检索效率低。**编码模型: **BERT、RoBERTa、MiniLM、MPNet、E5、bge。****评估基准:**MTEB(Massive Text Embedding Benchmark)或计算前 K 个结果中相关文档的召回率。
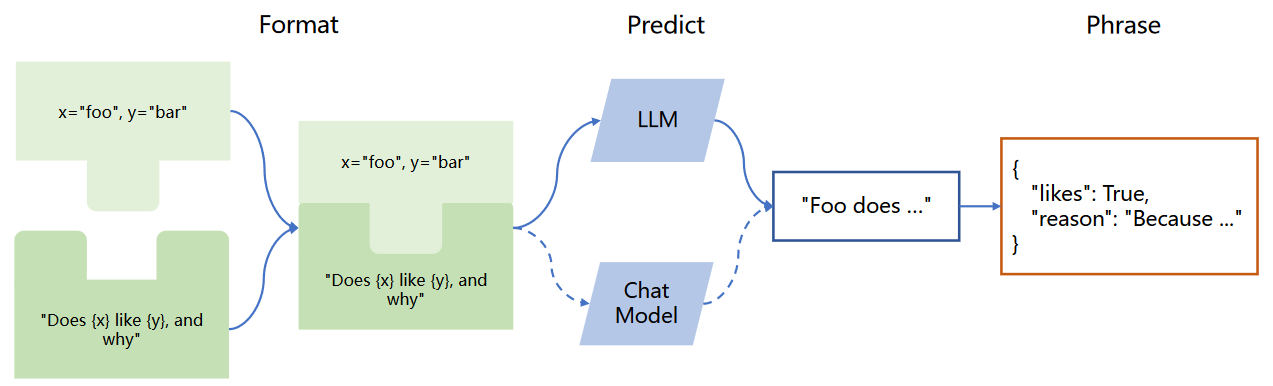
from langchain import PromptTemplate
template = """ You are a naming consultant for new companies. What is a good name for a company that makes {product}? """
prompt = PromptTemplate.from_template(template)
prompt.format(product="colorful socks")
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
os.environ["TOGETHER_API_KEY"] = "sk-***"
model = ChatOpenAI(
base_url="https://api.deepseek.com",
api_key=os.environ["TOGETHER_API_KEY"],
model="deepseek-chat",)
# 多轮对话
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Hi AI, how are you today?"),
AIMessage(content="I'm great thank you. How can I help you?"),
HumanMessage(content="I'd like to understand string theory.")
]
# 返回 AIMessage 对象
response = model(messages)
print(response.content)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
model = ChatOpenAI(
base_url="https://api.deepseek.com",
api_key="sk-****",
model="deepseek-chat")
parser = StrOutputParser()
# 将 prompt 模板、模型 和 输出解析器 串联成一个 chain
# chain 会依次执行:生成提示 → 调用模型 → 解析输出
chain = prompt_template | model | parser
print(chain.invoke({"language": "Chinese", "text": "hi"}))
**【指定输出类型】**LangChain 输出结构化的数据,解析为类的实例。
复制代码
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# 定义输出类
class TranslationResult(BaseModel):
"""翻译结果的结构化输出类"""
translated_text: str = Field(description="翻译后的文本")
source_language: str = Field(description="源语言")
target_language: str = Field(description="目标语言")
# 创建解析器,指定输出为 TranslationResult 类
parser = PydanticOutputParser(pydantic_object=TranslationResult)
system_template = """Translate the following into {language}.
{format_instructions}"""
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
model = ChatOpenAI(
base_url="https://api.deepseek.com",
api_key="sk-***",
model="deepseek-chat"
)
chain = prompt_template | model | parser
result = chain.invoke({
"language": "Chinese",
"text": "Stay curious, and the world will always feel new.",
"format_instructions": parser.get_format_instructions()
})
print(f"翻译结果: {result.translated_text}")
print(f"源语言: {result.source_language}")
print(f"目标语言: {result.target_language}")
【修改提示词】
复制代码
from langchain.prompts import ChatPromptTemplate
# 创建一个空的ChatPromptTemplate实例
template = ChatPromptTemplate()
# 添加聊天消息提示
template.add_message("system", "You are a helpful AI bot.")
template.add_message("human", "Hello, how are you doing?")
template.add_message("ai", "I'm doing well, thanks!")
template.add_message("human", "What is your name?")
# 修改提示模板
template.set_message_content(0, "You are a helpful AI assistant.")
template.set_message_content(3, "What is your name? Please tell me.")
# 格式化聊天消息
messages = template.format_messages()
print(messages)
【流式传输】在LLM生成回复时,不必等待完整结果返回,而是边生成边输出,让用户实时看到生成进度。
复制代码
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
class TranslationResult(BaseModel):
translated_text: str = Field(description="翻译后的文本")
source_language: str = Field(description="源语言")
target_language: str = Field(description="目标语言")
# 创建模型实例
model = ChatOpenAI(
base_url="https://api.deepseek.com",
api_key="sk-***",
model="deepseek-chat",
streaming=True
)
simple_template = "Translate the following into {language}:"
simple_prompt = ChatPromptTemplate.from_messages(
[("system", simple_template), ("user", "{text}")]
)
stream_chain = simple_prompt | model | StrOutputParser()
print("翻译中: ", end="", flush=True)
for chunk in stream_chain.stream({
"language": "Chinese",
"text": "Stay curious, and the world will always feel new."
}):
print(chunk, end="", flush=True)
print("\n")