很多学习Java反射的人第一次接触反射时,都会直接去看Class.forName()、getDeclaredMethod()这些 API,用着用着就懵了:为什么这么慢?为什么能访问private成员?为什么框架里到处都是反射?其实问题就出在缺了一些前置知识。
本文我们先不讲反射API,先从一些基础知识点入手,慢慢的拆解Java反射。
先来看看类的加载机制。
一、源码到字节码
其实反射并不是什么高深的技术,不要被吓到。他的本质就是在操作JVM加载类时生成的类元数据。
如果我们不理解类是怎么被加载到JVM内存里的,就没办法真正明白反射在干什么。
打个比方,反射就是拿着类的完整档案在操作,而这个档案就是在类加载过程中自动生成的。
如果看过这个专栏前面的文章,我们应该知道java代码的生命周期是从编写.java源码开始的。
经过javac编译器编译之后,会生成.class字节码文件。
这个.class文件不是本地机器码,只是JVM能够理解的平台无关的中间代码。
一个关键的点就是.class文件不单单是方法体的指令序列,他还包括了很多的元数据。
回想一下我们随手写的一个类都包含了哪些东西。
java
package com.lazy.snail.day66;
/**
* @ClassName Student
* @Description TODO
* @Author lazysnail
* @Date 2025/12/16 10:53
* @Version 1.0
*/
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public void sayHi() {
System.out.println("Hello");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}类的全限定名、父类和实现的接口、字段的名称、类型、修饰符
方法的名称、参数类型、返回值类、修饰符
常量池、注解信息等等。
这些东西我们就称之为类的元数据。
白话一点,反射其实依赖的就是这些东西,可以看成是反射的原料。
二、类加载的三个阶段
当我们的程序运行起来的时候,JVM不会一股脑的把所有的.class文件都加载进去。
比如上面我们写的Student类,我们没有在任何地方以任何形式加载他,那么他就不会被加载到内存里。
我们另外写一个Main类,这个类只包含一个main方法,在运行前修改一下配置。
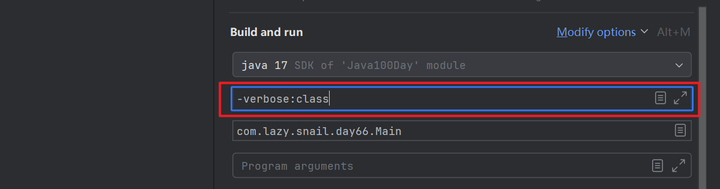
运行后,控制台会输出所有被加载的类信息,直接搜索Student,我们就会发现,Student根本没被加载。
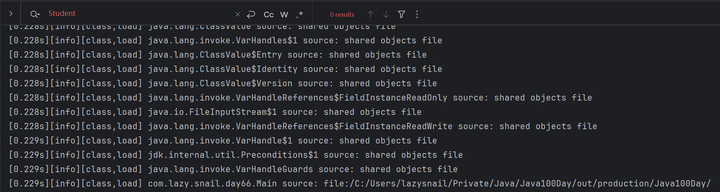
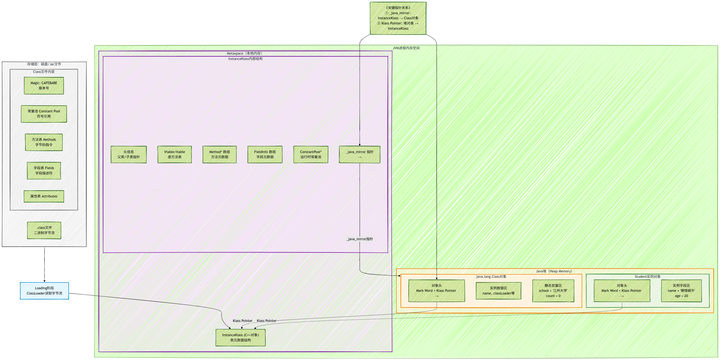
我们通常说的类加载,包含了三个主要阶段。这三个阶段并不是线性流水执行,阶段之间可能会交叉执行,只是各自开始的时间是线性的。比如在Loading开始后,Linking的验证也会开始工作。边读字节码文件,边校验。
三、加载(Loading)
这个阶段做的事情就是通过类加载器从磁盘、网络或者jar包里读取.class文件的二进制字节流,把他们load到JVM的方法区里。这个时候,JVM会解析字节码,生成类的内部数据结构。
方法区是JVM规范里的逻辑区域,HotSpot JVM在Java 8+中对方法区的具体实现是Metaspace,使用的是本地内存,不是堆内存。
我根据openJdk17的源码画了加载过程的流程图:
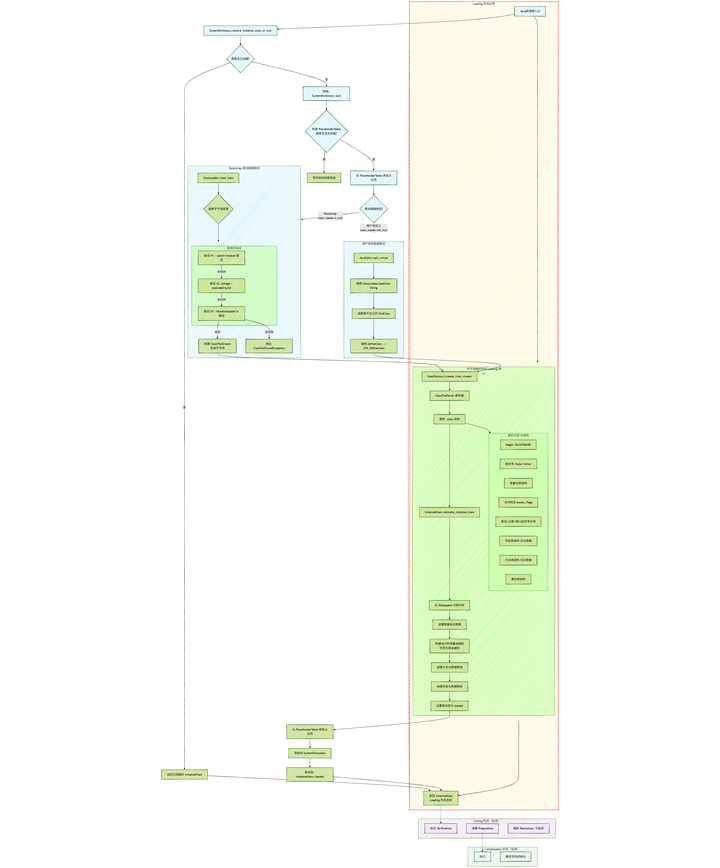
关于加载这个阶段的源码主要在src/hotspot/share/classfile/systemDictionary.cpp
这里我要说一下我们经常说的Java层面的加载器:启动类加载器、扩展类加载器、应用加载器、自定义加载器。
为什么我要强调Java层面呢?
因为在JVM看来,除了启动类加载器,其他的都是用户类加载器。
这个启动类加载器在Java中是没有一个类与之对应的,是一个虚拟的东西,他的加载逻辑是纯粹的C++实现的。
java
package com.lazy.snail.day66;
import javax.sql.DataSource;
/**
* @ClassName Day66Demo
* @Description TODO
* @Author lazysnail
* @Date 2025/12/18 13:44
* @Version 1.0
*/
public class Day66Demo {
public static void main(String[] args) {
System.out.println(String.class.getClassLoader());
System.out.println(DataSource.class.getClassLoader());
System.out.println(Student.class.getClassLoader());
}
}
String类是启动类加载器加载的,我们在代码中通过getClassLoader是获取不到加载器对象的。
PlatformClassLoader(Java9+扩展类加载器被重命名成了平台类加载器)和AppClassLoader已经我们自定义的类加载器在Java中都有具体类,都继承自ClassLoader。
你可能会想为什么String这样的类不在Java层面加载,而要交给JVM?
为什么Java不自己实现启动类加载器?
这个其实也很好理解,在Java里,任何一个类(.class)想要运行,都必须先被类加载器加载到内存里。
假设我们把启动类加载器(Bootstrap ClassLoader)设计成一个普通的Java类。
当JVM启动的时候,想要运行这个启动类加载器,发现这是一个Java类。为了运行这个Java类,JVM需要一个加载器来加载他,然后我们需要一个加载器的加载器,加载器的加载器的加载器......
发现问题了吧,这样设计就陷入无限循环了。
所以Java需要一个不是Java类的加载器,直接由C++编写嵌在JVM里面,这样我们运行Java的时候,操作系统才能直接运行C++,由C++代码直接去读取核心类库,塞到内存里面。
而String、Object、Integer这些类是整个Java世界的地基。
如果你让Java代码去加载String,比如让AppClassLoader去加载,AppClassLoader自身也是个Java对象,父类是ClassLoader,内部本来就有很多String,在加载String之前,你说你要用到String,是不是很诡异。
所以说为了让Java跑起来,就必须有非Java的代码(C++)先行一步,把最基础的类搬进内存。
String这样的基础类,必须在任何Java逻辑(包括Java编写的加载器)启动前就存在。
再一个点就是用C++直接加载核心类库,可以确保核心类不被篡改(你不能自定义一个java.lang.String去替换系统的),而且启动速度最快。
接下来我们看一下双亲委派,这个机制的核心逻辑都在ClassLoader的loadClass里面。
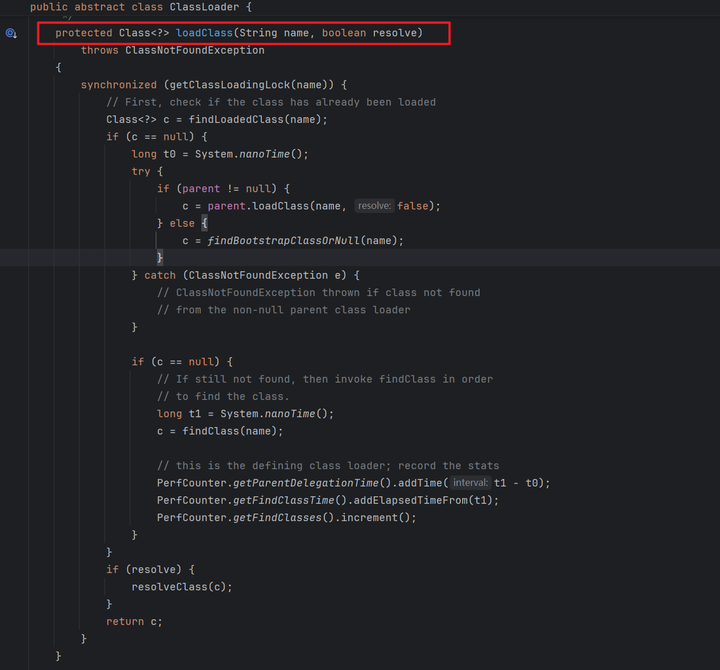
总结下来就三步,第一步,检查是不是已经加载了。第二步,parent是不是空的,不是就委托给父加载器,是空的就交给Bootstrap加载器。第三步,父加载器找不到的时候,就自己加载。
比如AppClassLoader要加载一个我们自己写的一个类Student,他不会马上就自己去找和加载。
他会先把这个加载请求委派给他的父类加载器,比如ExtClassLoader,父类加载器同样会执行这个逻辑,继续委派,直到启动类加载器Bootstrap ClassLoader。
启动类加载器就开始尝试加载,他在自己的搜索范围内肯定是找不到这个类的,他只能告诉扩展类加载器,我找不到,你自己找一下。扩展类加载器又开始在自己的搜索范围内找,还是找不到,又告诉应用程序类加载器,我没找到,你要自己搞定。然后应用程序类加载器就在classpath里面找,找到了就加载,没找到就抛出 ClassNotFoundException。
为什么要搞双亲委派?
核心就两点:
第一,有了双亲委派,能防止核心API被篡改。假如我们自己写了个java.lang.String类打包到classpath。如果没有委派机制,我们程序需要用到String类时,应用程序类加载器会直接在classpath里找到我们写的String类。相当于破坏了核心API。有了委派机制,当AppClassLoader接到加载 java.lang.String的请求时,会立刻一层层的委派给顶层的BootstrapClassLoader。就会发现之前已经加载了String(核心库的),这样AppClassLoader就根本没机会去找自己的classpath加载我们自己写的java.lang.String类了。
如果你写了个java.lang.Hacker,想混到java.lang包里,双亲委派是拦不住的,会被AppClassLoader加载,但是java不会让你这么干,Java不允许用户加载器加载java.开头的包。JVM会抛出SecurityException。
第二,在JVM里,一个类由他的全限定名和加载他的类加载器共同决定(即 (Class, ClassLoader)是一个唯一标识)。同一个类被两个不同的类加载器加载,在JVM看来就是两个完全不同的类。有了委派机制,对于同一个类,加载请求会沿着委派链向上传递,直到有加载器成功加载他。然后这个结果会被缓存并返回给所有下层的加载器。这就确保了不管哪个加载器需要这个类,最终都是由同一个加载器(通常是第一个在委派链上找到他的加载器)来加载,从而保证了类的全局唯一性。
简单的讲,Loading阶段就是IO流读取字节码 -> 存入方法区(Metaspace) -> 生成堆中Class对象的过程。
通过类的全限定名,利用类加载器找到这个类的二进制字节流(不管是在磁盘的 .class文件、Jar包里,还是网络传输来的)。
把这个字节流代表的静态存储结构(文件格式),转化成方法区(Metaspace)中的运行时数据结构(即C++里的InstanceKlass)。
在Java堆内存里生成一个代表这个类的java.lang.Class对象。 这个对象是方法区数据的访问入口。后续代码中 new Student()或者反射Student.class,其实都是通过堆里的这个Class对象去访问方法区里的具体类型信息。
四、链接(Linking)
链接这个阶段又分成了验证、准备、解析三个阶段。
4.1 验证
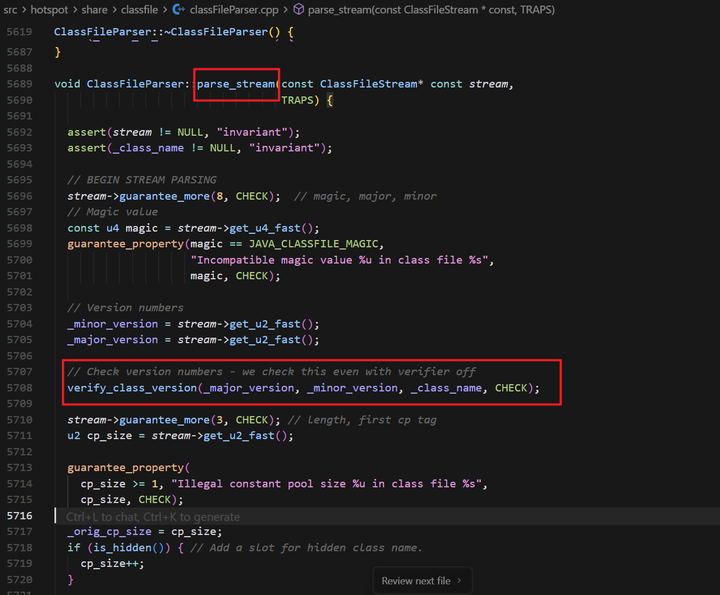
验证阶段其实在上一阶段Loading开始后就开始工作了。
最直观的就是HotSpot实现中的classFileParser在解析字节码流的时候,已经在做魔数、版本号等格式合法性检查。其实文件头、常量池、字段/方法表等的校验也穿插在了Loading阶段,只是逻辑上属于Linking的验证阶段。
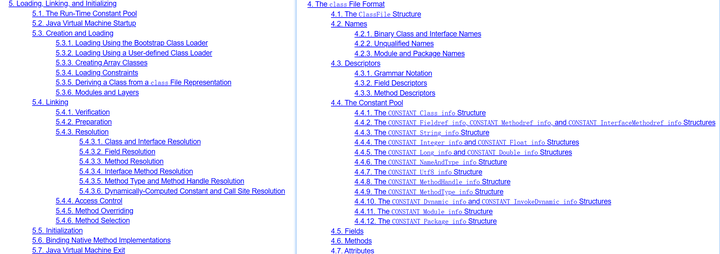
既然要进行验证,那肯定就有验证规则,Java虚拟机规范就是这些规则的来源。
主要集中在第四章和第五章:
首先验证的就是字节码文件的文件格式:比如魔数是不是0xCAFEBABE,版本号,比如我们用JDK 17编译的,要把这个class放到JDK 8的JVM上跑,版本号检查就会失败。常量池里的索引有没有越界?常量类型对不对?
第二部分就得验证下我们的Java代码逻辑通不通,这一步主要是对字节码描述的信息进行语义分析,保证符合Java语言规范。这里就不单是依靠JVMS了,还得依靠JLS。比如某个类是不是继承了被final修饰的类。关于抽象方法,如果某个类不是抽象类,他是不是实现了父类或接口中所有的抽象方法?非法重写父类的方法等等。
这部分的验证是不是有点熟悉,我们在IDE里面写个类继承final修饰的类,直接就报错了,在源码阶段就被拦住了,为啥在运行时阶段还要做这些验证?说白了JVM拿到的是字节码。至于这个字节码从哪儿来,怎么来的他控制不了,毕竟编译不是他干的活,为了安全,为了JVM不崩溃,所有的验证都要按照规则执行一遍他才放心。
第三部分就是检查方法体里面的代码。看看操作数栈上的数据类型是不是匹配等。JDK6以后JVMS引入了StackMapTable属性,javac(编译器)在编译的时候就把类型检查的证据写在class文件里,JVM验证器只需要检查证据是不是正确,而不需要自己重新推导一遍数据流。这就是为了加快类加载速度。
第四部分就是符号引用的验证,检查我们引用的外部类/方法到底存不存在,能不能访问。这一部分一般是穿插在解析阶段。
4.2 准备
上面的验证阶段过了,JVM就会认为我们的类是安全,没啥毛病了。就开始准备给他分配资源了。
准备阶段核心的任务有两个,分配内存和设置零值。这个阶段JVM会在内存中给类的静态变量分配空间,然后初始化成零值。
比如我们的类里面有这样一行代码:
java
public static int count = 666;这个阶段不会执行任何的Java代码,也不会把666赋值给count。
只是count先占个坑,把内存清"零",这里的零可能是0、0.0、\u0000、false、null。把666赋值给count是初始化阶段做的。
但是如果把代码修改成:
java
public static final int count = 666;多了一个final修饰符,在准备阶段结束的时候,count就已经是666了。
因为编译器在编译的时候,发现是final的,就会在字节码文件里生成一个ConstantValue属性,在准备阶段,JVM看到了这个属性,就直接进行赋值了,不会等到初始化。
4.3 解析
下面我们看看解析阶段又干了些什么?一句话就是把符号引用替换成直接引用。
我们的class文件里如果调用了System.out.println,常量池里面只存了"java/lang/System", "out", "println" 这些字符串,JVM只知道要找谁,比如System类,但是他不知道System在内存的哪个位置。
等到运行到System.out.println("懒惰蜗牛")的时候,JVM一看,这是个方法调用,要用到println的直接地址。
解析就开始了,去内存找java.lang.System加载了没,没加载还得先触发加载。然后在System类里面找静态字段 out,找到之后检查下out的类型是不是PrintStream,又去PrintStream类里面找签名匹配的println(String)方法,最终JVM拿到了println方法在内存里的入口地址。这个地址就是直接引用。这个地址会被缓存下来,下次运行的时候就不用再找一遍,直接用就行。
Java虚拟机规范没有强制规定解析阶段一定要在初始化之前完成。
由于我们是基于HotSpot进行的讨论,HotSpot选择的是惰性解析。也就是在链接阶段,先不解析那些具体的方法调用。等到代码真正运行到那一行时,发现还是符号引用,暂停一下,去解析成直接引用,然后缓存起来。
所以说解析这个阶段虽然逻辑上属于Linking,但从时间轴上看,一般都是穿插在初始化之后、甚至代码运行期间发生的。(当然也不是所有的解析动作都能拖,像继承关系、接口实现就得先解析好)
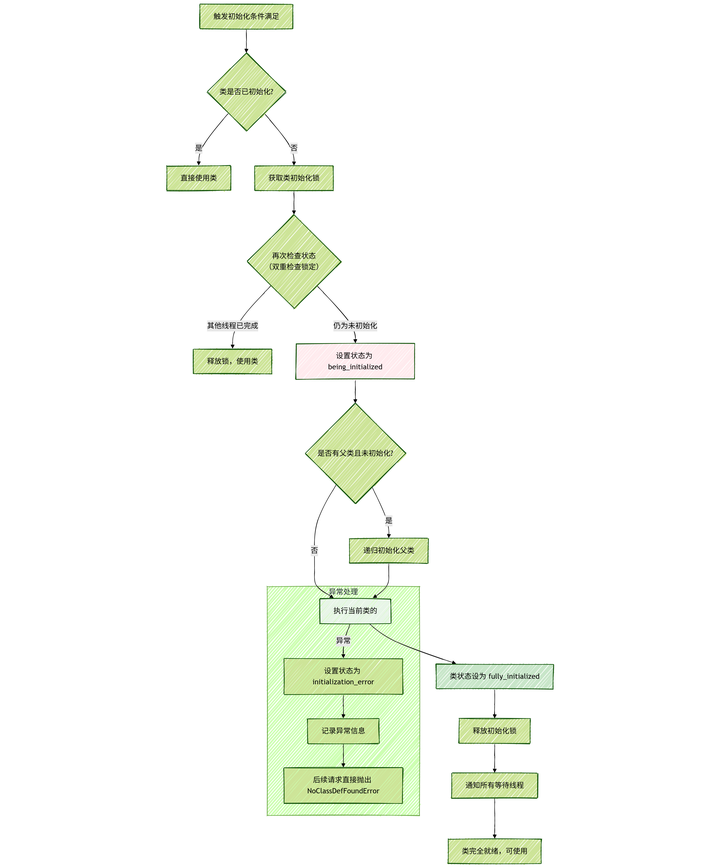
五、初始化(Initialization)
这个阶段就开始真正执行代码了,编译器在编译的时候会自动生成一个<clinit>方法(如果有类静态变量或者静态块),这个方法里搜集了类里面所有类变量的赋值操作和静态块里面的语句。然后按照他们在源码里出现的顺序,拼接在这个方法里。
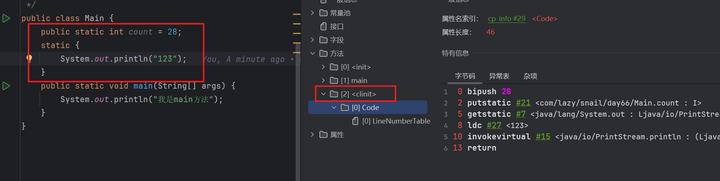
之前在准备阶段被赋"零"的变量,会在这个阶段被赋值为我们给定的值。
在JVM规范里,有且仅有6种情况会触发初始化。

第一种就是最常见的通过new进行实例化。
java
MyClass s = new MyClass();第二种访问或者设置静态字段。
java
System.out.println(MyClass.staticField); // 触发
MyClass.staticField = 123; // 触发
// 例外:编译期常量不触发
final static int CONST = 100; // 不触发
final static String HELLO = "Hello"; // 不触发
final static Object OBJ = new Object(); // 触发(不是基本类型或字符串)第三种是调用静态方法。
java
MyClass.staticMethod(); // 触发初始化第四种是反射调用。
java
Class.forName("com.lazy.snail.day66.MyClass"); // 触发
Class.forName("com.lazy.snail.day66", true, loader); // 明确指定初始化
// 注意:false 时不触发初始化
Class.forName("com.example.MyClass", false, loader); // 不触发反射这块我们后续再聊。
第五种是子类初始化的时候,父类需要先初始化。
java
class Parent { static { System.out.println("父类初始化"); } }
class Child extends Parent { static { System.out.println("子类初始化"); } }
// 初始化子类时,父类先初始化
new Child(); 第六种就是作为主类,也就是包含了main方法的类。
java
// 执行MyApp时,MyApp类被初始化
public class MyApp {
public static void main(String[] args) {
System.out.println("LazySnail");
}
}在被触发初始化时,JVM必须保证这个类已经完成了加载、验证、准备,至于解析,初始化过程需要用到的符号引用也需要解析,其他没用到的可以延迟到首次使用的时候进行解析。如果初始化触发了,类还没加载,就会去触发类的加载过程,顺序的执行下来,保证类的初始化。
初始化的一个大致流程:
初始化还有一些注意点。
java
// Son extends Father, Father有一个静态变量val
System.out.println(Son.val);这种情况只会触发父类的初始化,不会触发子类的初始化。对于静态字段,只有直接定义这个字段的类才会被初始化。
java
// ConstClass 有一个 public static final int MAX = 100;
System.out.println(ConstClass.MAX);这种不会触发初始化,之前我们已经讲过了。
java
Student[] students = new Student[10];还有类似这样的对象数组的定义,也不会触发Student的初始化。
他只是在堆里开辟了一个数组空间,里面全是null,还没有真正碰到Student。
结语
上述过程,我们把一个类从磁盘变成内存里的可用状态基本梳理了一遍。
Loading (加载): 找文件,读字节流,造Class对象。
Verification (验证): 按规则做校验,保安全。
Preparation (准备): 分配静态内存,赋零值。
Resolution (解析): 符号引用 -> 直接引用(可能推迟)。
Initialization (初始化): 执行 <clinit>,运行静态代码块,赋真值。
下一篇预告
待定
如果你觉得这系列文章对你有帮助,欢迎关注专栏,我们一起坚持下去!