对比学习
论文链接在:https://github.com/mli/paper-reading/
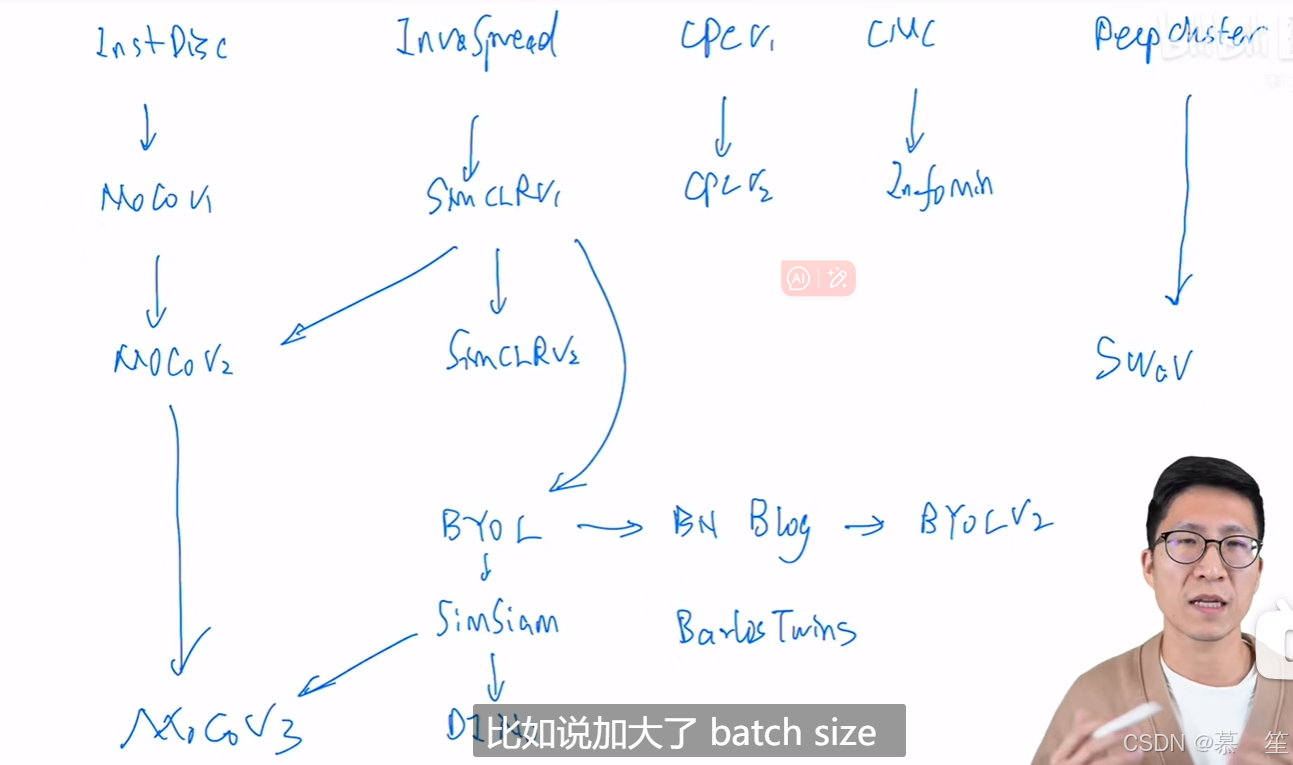
1 百花齐放
InstDisc(Instance Discrimination)
论文:Unsupervised Feature Learning via Non-Parametric Instance Discrimination
提出了个体判别任务,并将其与NCE loss 进行对比学习,从而取得了无监督表征学习的结果
用别的数据结构存储负样本以及如何对特征进行动量的更新
一个编码器和memory bank
InvaSpread(Invariant and Spreading)
论文:Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
也是用个体判别这个代理任务去对比学习
没有使用额外的数据结构存储大量的负样本,其正负样本来自同一个minibatch
只使用一个编码器进行端到端的学习
效果不够好的原因:负样本不够多,只有500多个(可以理解成SimCLR的前身)
CPC(Contrastive Predictive Coding)
论文:Representation Learning with Contrastive Predictive Coding
可以处理音频、图片、文字、强化学习
用预测的代理任务去做对比学习
一个编码器和一个自回归模型
CMC(Contrastive Multiview Coding)
论文:Contrastive Multiview Coding
定义正样本的方式:一个物体的多个视角都可以作为正样本(多视角多模态)
数据集:NYU RGBD
两个甚至多个编码器
2 cv双雄
MoCov1(Momentum Contrastive)
论文:Momentum Contrast for Unsupervised Visual Representation Learning
队列(取代了memory bank)
动量编码器(取代了loss里的约束项)
这篇论文比较level,自顶向下的写作方式
SimCLRv1(A Simple Franework for Contrastive Learning of Visual Representations)
论文:A Simple Franework for Contrastive Learning of Visual Representations
链接:A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org)
重大创新点:g()函数------简单来说是一个mlp层,只有一个全连接层+一个relu激活函数(训练的时候使用)
衡量是否有一致性:采用normalized temperature-scaled的交叉熵函数
创新点:更多的数据增强,g()函数(MLP head),大batch训练很久
MoCov2(Momentum Contrastive)
论文:Improved Baselines with Momentum Contrastive Learning
MoCov1 + improments from SimCLRv1
SimCLRv2(Big Self-Supervised Models are strong semi-supervised learners)
论文:Big Self-Supervised Models are Strong Semi-Supervised Learners
主要讲述半监督学习
创新点:更大的模型(152层的残差网络,SKNet),g()函数变成两层MLP,添加动量编码器
SwAV(swapped assignment views)
论文:Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
创新点:聚类对比学习、multi-crop
3 不用负样本
BYOL(Bootstrap Your Own Latent0)
论文:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
BYOL workd even without batch statistics
自己跟自己学
使用了动量编码器
batch norm生成的平均图片
SimSiam
论文:Exploring Simple Siamese Representation Learning
孪生网络
不需要负样本,不需要大的batchsize,不需要动量编码器
成功训练没有坍塌的原因:存在stop gradient
4 Transformer
Mocov3
论文:An Empirical Study of Training Self-Supervised Vision Transformers
如何更稳定的自监督训练ViT
MoCov3 = MoCov2 + SimSiam
DINO(self-distillation with no labels)
论文:Emerging Properties in Self-Supervised Vision Transformers
transformer + 自监督
论文:Emerging Properties in Self-Supervised Vision Transformers
transformer + 自监督