目录
[1.1 数据集与实验设置](#1.1 数据集与实验设置)
[1.2 离线性能评估](#1.2 离线性能评估)
[1.3 不同曝光量笔记的效果](#1.3 不同曝光量笔记的效果)
[1.4 消融实验](#1.4 消融实验)
[1.5 CSFT模块中数据多样性的影响](#1.5 CSFT模块中数据多样性的影响)
[1.6 CSFT模块强度的影响](#1.6 CSFT模块强度的影响)
[1.7 案例分析](#1.7 案例分析)
[1.8 在线实验](#1.8 在线实验)
[二、 结论](#二、 结论)
上一篇论文:推荐大模型系列-NoteLLM: A Retrievable Large Language Model for Note Recommendation(二)
一、实验
1.1 数据集与实验设置
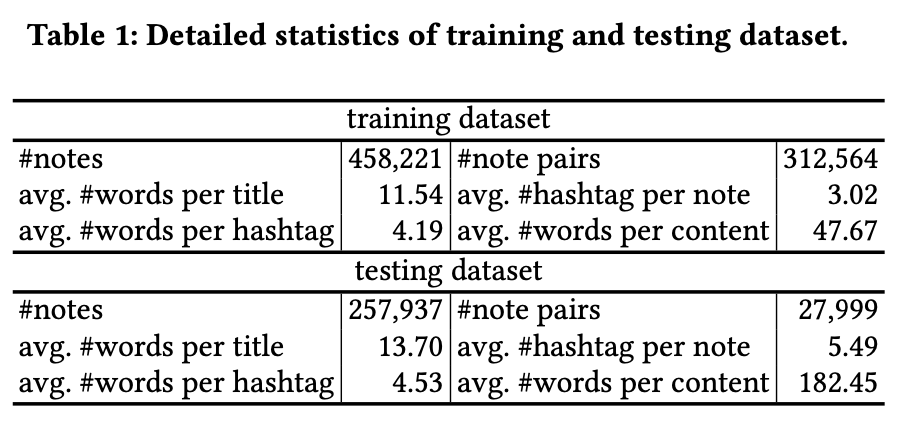
在小红书商品数据集上进行了离线实验。为平衡模型训练,基于一周的商品数据,从每个类别组合中提取固定数量的笔记对生成训练集。测试集的笔记池由接下来一个月的笔记随机抽取构成,并排除训练集中已存在的笔记。训练集和测试集的详细统计数据如表1所示。数据集中包含超过500个类别。
实验中采用Meta LLaMA 2 42作为基础大语言模型。在相关笔记对构建中,共现分数上界𝑢设为30,下界𝑙设为0.01,阈值𝑡设为10。笔记嵌入的维度𝑑设置为128,批量大小𝐵为641,每批包含128条笔记。受上下文长度限制,标题超过20个词元时截断,内容超过80个词元时截断。温度参数𝜏初始化为3,公式4中的𝛼设为0.01,话题标签生成任务的比率𝑟设定为40%。
为评估I2I推荐模型的离线性能,选择包含全部输入笔记信息的类别生成提示。从每对笔记中选取第一条作为目标笔记,另一条作为真实标注。随后根据目标笔记对测试池中所有笔记(排除目标笔记)进行排序,采用Recall@100、Recall@1k、Recall@10k和Recall@100k验证I2I笔记推荐效果。对于衣橱类别生成任务,使用准确率(Acc.)和虚构比例(Ill.)作为指标,后者表示模型生成的类别未出现在衣橱中的比例。自由形式话题标签生成任务则通过BLEU4、ROUGE1、ROUGE2和ROUGEL进行评估。
1.2 离线性能评估
本节验证NoteLLM在I2I笔记推荐中的有效性,并与以下基于文本的I2I推荐方法进行对比:
• zero-shot :直接使用LLMs生成嵌入向量并进行零样本检索,无任何提示词。
• PromptEOLzero-shot 10:一种零样本LLMs句子嵌入方法,采用显式单词语义限制提示。
• SentenceBERT 36:基于BERT通过对比学习建模笔记相似性,作为在线基线模型。
• PromptEOL+CSE 10:结合显式单词语义限制提示与对比学习微调LLMs。
• RepLLaMA26:基于LLMs的双编码器稠密检索器,未使用任何提示词。
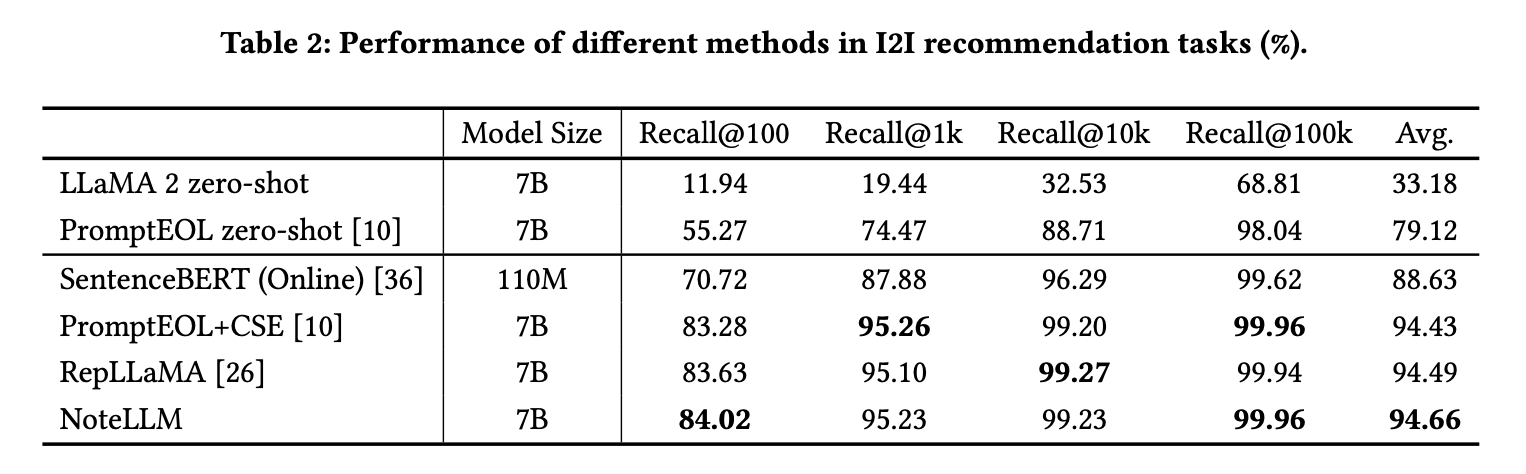
表2的结果揭示了关键发现:零样本方法虽具潜力,但性能仍不及微调方法,说明后者在笔记推荐领域的领域知识更具优势。对比LLaMA 2与SentenceBERT的方法显示,前者显著优于后者,表明LLMs在理解笔记内容上能力更强。PromptEOL+CSE(含特定提示)与RepLLaMA(无提示)性能相当,说明提示词能提升零样本检索,但微调后其效果减弱。最终,NoteLLM超越其他基于LLM的方法,主要归功于CSFT将摘要生成能力有效迁移至笔记嵌入压缩过程,通过提炼关键信息优化嵌入表示。
1.3 不同曝光量笔记的效果
本小节展示NoteLLM在处理不同曝光量笔记时的有效性。为进行全面分析,将真实笔记按曝光量划分为两类:第一类为低曝光笔记(曝光量<1,500),占测试笔记总量的30%,但其累计曝光量仅占0.5%;第二类为高曝光笔记(曝光量>75,000),仅占测试笔记总量的10%,但其累计曝光量高达75%。通过分别计算这两类笔记的召回率,进一步分析NoteLLM在不同曝光量下的表现。
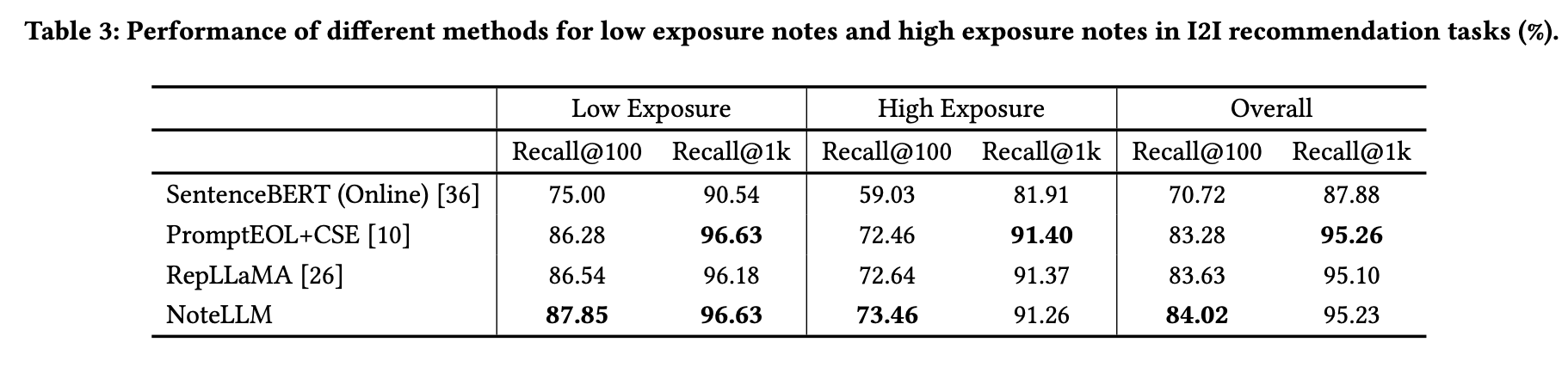
实验结果如表3所示。NoteLLM在大多数情况下对低曝光和高曝光笔记的召回率均优于其他方法,表明CSFT模块的加入能为所有笔记提供一致的性能提升,不受曝光量影响。需注意的是,其他方法虽在低曝光笔记上表现良好,但在处理高曝光笔记时性能下降,这归因于忽略了流行度偏差17。该特性增强了模型基于笔记内容召回的能力,尤其适合冷启动笔记的检索,从而激励用户发布更多新笔记,为社区创造更丰富的内容。
1.4 消融实验
本小节通过消融实验验证核心创新点的有效性,并在后续实验中展示模型在类别与标签生成任务上的表现。对比实验包含以下变体:
• w/o CSFT :仅使用GCL模块的基线方法。
• w/o GCL (𝑟 = 40%) :仅采用CSFT模块指导大语言模型生成标签与类别摘要。
• w/o GCL (𝑟 = 0%) :仅保留类别摘要任务。
• w/o GCL (𝑟 = 100%):仅指导大语言模型生成标签摘要。
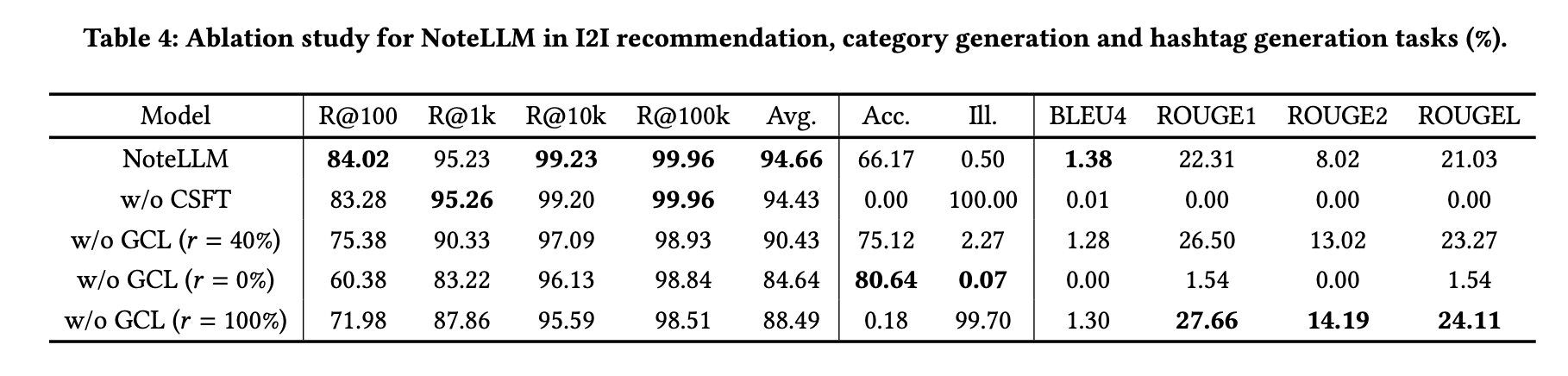
实验结果如表4所示,可得出以下结论:
CSFT模块的关键作用
未使用CSFT的变体在I2I推荐任务中性能显著低于NoteLLM,且完全丧失生成标签与类别的能力。这表明CSFT模块对增强笔记嵌入表示至关重要,同时验证单一模型可兼顾推荐与生成任务。
生成任务对推荐的增益
未使用GCL模块的变体在I2I推荐任务中表现优于PromptEOL零样本方法,说明标签/类别生成任务能提升推荐效果。
任务多样性的重要性
未使用GCL (𝑟 = 40%)的变体在I2I推荐任务中表现优于𝑟=0%与𝑟=100%的版本,表明任务多样性对CSFT优化具有积极影响。
标签与类别生成的权衡现象
未使用GCL (𝑟 = 0%)的变体能正确生成80.64%笔记的类别,但标签生成效果较差;而𝑟=100%的版本生成高质量标签,类别准确率却大幅下降。这一跷跷板效应说明两者存在任务冲突。
1.5 CSFT模块中数据多样性的影响
本小节探讨CSFT模块中数据多样性的影响。表5展示了不同任务在数据类型比例变化下的模型性能表现。
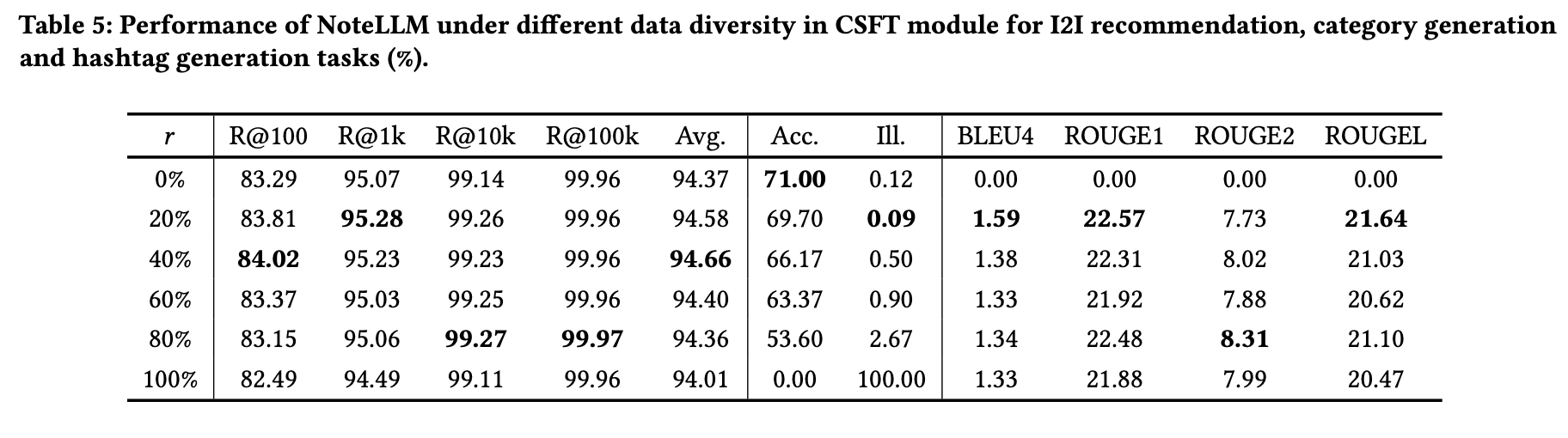
对于图像到图像(I2I)推荐任务,性能随比例𝑟的增加而提升。这是由于更高的𝑟值增强了指令调优的数据多样性,能更有效地指导大语言模型(LLMs)总结和压缩多样化的信息类型。
然而,当𝑟持续增加且指令调优数据更偏向标签生成任务时,性能开始下降。在类别生成任务中,随着数据更偏向标签生成任务,其性能表现逐渐恶化。但当𝑟从20%继续增加时,标签生成任务的性能并无显著变化。这可能是因为类别生成任务属于封闭式任务,需严格匹配结果;而标签生成任务是开放式生成任务,允许更高的灵活性。
1.6 CSFT模块强度的影响
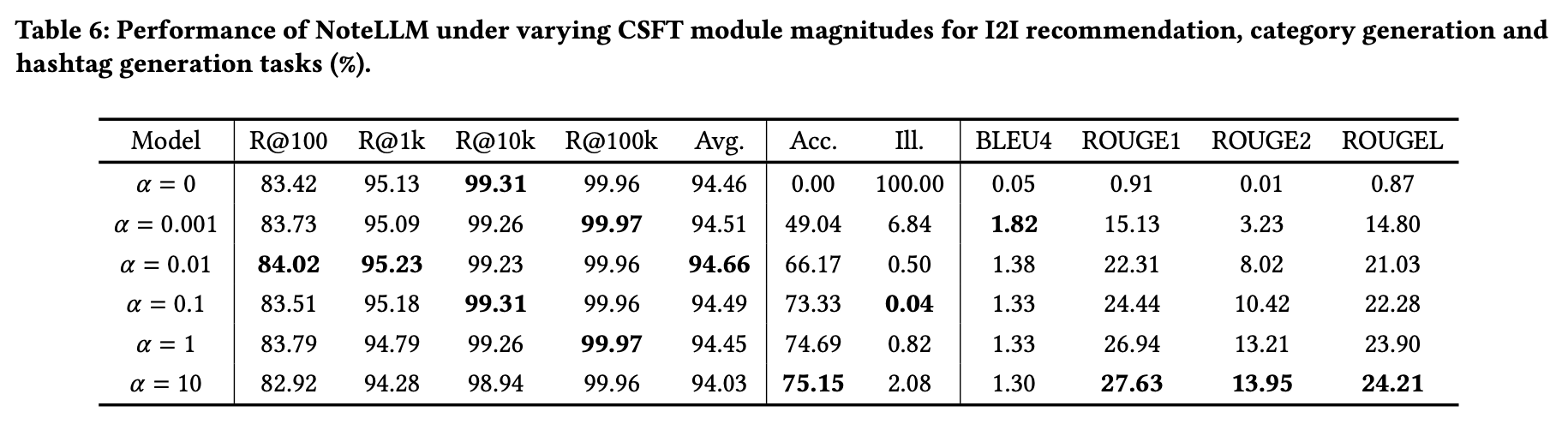
本小节探讨CSFT模块的强度(α值)对任务性能的影响。实验结果如表6所示。研究表明,略微增大α值能同时提升推荐任务和生成任务的性能。然而,随着α值持续增加,推荐任务的性能开始下降,而生成任务的性能则持续提升。这一现象揭示了生成任务与(I2I)推荐任务之间的权衡关系,表明需要采取平衡策略。
1.7 案例分析

最后展示笔记推荐与生成任务的部分案例如图3所示。图3(a)中,查询笔记建议避免购买哪些夏季衣物,而所有基线模型均推荐夏季穿搭。NoteLLM能准确推荐与极简生活相关的笔记。

图3(b)中,基线模型将笔记中的"兔子"误认为活体兔子,而非来自《远离陌生人》的玩具兔子。

图3(c)和图3(d)展示了话题标签生成任务的案例,体现了NoteLLM的优势。RedHashtag是小红书基于固定标签集分类的在线标签生成方法。
图3(c)中,NoteLLM未受"工厂"语义信息干扰,正确识别笔记内容聚焦于拍照技巧。图3(d)中,NoteLLM能生成更具体、长尾的标签,而非通用标签。但该方法仍存在幻觉问题57。
1.8 在线实验
在小红书平台上进行了为期一周的在线图像到图像(I2I)推荐实验。与之前采用SentenceBERT的在线方法相比,NoteLLM将点击率提升了16.20%。此外,召回性能的增强使评论数量增加了1.10%,每周发布者平均数量(WAP)提升了0.41%。这些结果表明,将大语言模型(LLMs)引入I2I笔记推荐任务中,能够提升推荐效果和用户体验。
实验还观察到,新笔记的单日评论数量显著增长了3.58%,说明大语言模型的泛化能力对冷启动笔记有益。目前,NoteLLM已部署至小红书的I2I笔记推荐任务中。
二、 结论
本研究提出了可检索的大语言模型NoteLLM,用于笔记推荐,其核心包含三个组件:笔记压缩提示(Note Compression Prompt)、生成式对比学习(GCL)和协同监督微调(CSFT)。为同时处理I2I推荐和标签/类别生成任务,采用笔记压缩提示生成压缩词嵌入,并同步输出标签/类别。
通过GCL基于压缩词的隐藏状态进行对比学习,获取协作信号。CSFT则在保留NoteLLM生成能力的同时,利用笔记的语义与协作信息生成标签和类别,从而增强推荐嵌入效果。全面的实验验证了NoteLLM的有效性。
本篇关于notellm的论文讲解就到这里,下一篇会继续介绍notellm2
传送门: