一、DINOv2
1、数据集: LVD-142M数据集,由公开数据集和网络数据集组成,数据集经过PCA哈希去重,NSFW过滤和人脸模糊,整合汇总之后生成1.2亿的数据集;
2、DINOv2的去重方式叫copy detection pipeline(SSCD)
①自去重:去除数据内部冗余
第一步:特征提取,提取图片的特征向量
第二步:计算余弦相似度,计算每张图片最相近的k=64张图片
第三步:只保留相似度大于0.6的近邻对
第四步:并查集算法将相似数据连接在一起,形成一个连通分量,每个连通分量只保留一张图片
②相对去重:防止评估集数据泄露
第一步:计算训练图像与测试图像的余弦相似度
第二步:设定阈值0.45,将超过阈值的训练图像删掉
这是为了防止模型"作弊"式地获得虚假的高性能指标,确保模型在测试时不会因数据泄露导致评估结果失真
③自监督图像检索:
注意:自监督图像检索不是单独的步骤,是自去重和相对去重中间的一步,就是将图像编码,然后聚类的那一步
第一步:使用在 ImageNet-22k 上进行预训练过的 ViT-H/16 的自监督神经网络,对数据进行编码,计算每个图像的嵌入向量
第二步:聚类分组
第三步:给一个查询向量(来自数据集内部),检索与查询向量最相似的4或32(N可调节)个图像;(如果聚类所在的组太小,则会从聚类中抽取10000(M可调节)张图像)
第四步:将这些相似的图像和查询图像一起训练
3、损失函数
DINOv2的损失函数包含四部分:DINOv1的交叉熵损失、iBOT的损失函数、以及一个正则项KoLeo regularizer损失
①image-level objective :DINOv1的损失函数(详见前一篇文章)
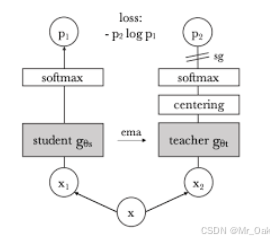
②patch-level objective :iBOT 的损失函数
iBOT用了BERT的MIM思想,即将vit切分的patches,进行mask
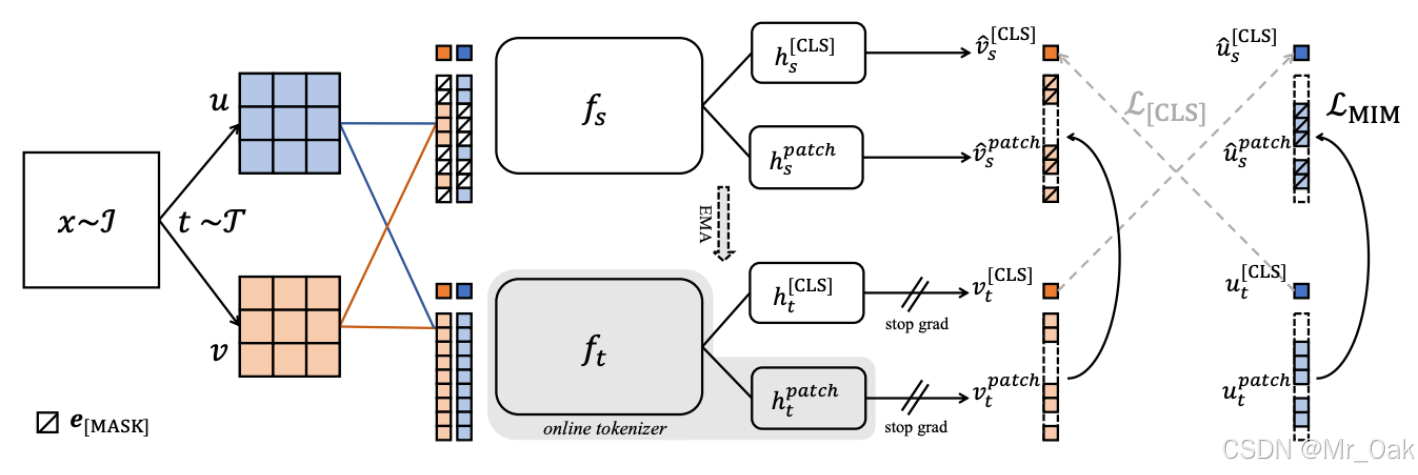 第一步:图像x,经过两种不同的图像增强,得到u和v
第一步:图像x,经过两种不同的图像增强,得到u和v
第二步:u和v分别被分成固定大小(比如16*16)的小块
第三步:随机遮盖30%-80% 的图像块(DINOV2中没有用到MIM,因为DINOv2的student网络输入就是crop过的图片,相当于已经mask了 )
第四步:student接收mask之后的图像块,学习局部与全局的关联性,teacher接受完整的图像块,这里teacher用的是online tokenizer(这个是实时的,不同与BERT的预训练,这部分是实时训练的,用的是vit架构)
第五步:student和teacher都得到了u和v的cls和tokens
第六步:cls_loss:student的clsu和teacher的clsv计算交叉熵loss,student的clsv和teacher的clsu计算交叉熵loss(因为u和v是来自同一张图片,所以两者的cls token应该是一致的,两者交叉验证),然后两者求均值;其中teacher的loss在计算的时候要经过center和sharpen,具体详见DINOv1 (在DINOv2中没有用到cls_token Loss,只用到了patch_token Loss)
第七步:patch_loss:student的mask的u和teacher的u计算交叉熵loss,student的mask的v和teacher的v计算交叉熵loss,然后两者求均值;
第八步:student的梯度更新正常更新,teacher的梯度更新通过动量更新(center的更新也是通过动量更新)
③KoLeo损失 :特征正则化
KoLeo损失基于Kozachenko-Leonenko熵估计器,其核心思想是通过 特征空间中样本点的最近邻距离来最大化特征的熵 ,从而避免特征坍塌(Collapse)问题。
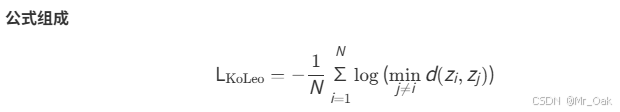

注意:
KoLeo Loss只在student中计算
输入是经过Vit结构的特征向量,在softmax之前(和dino loss用的是同一套head)
三个loss综合回传更新student网络参数
4、要点
①Untying head weights between both objectives :iBOT中cls_token Loss和patch_token Loss是共享一套权重的,但是DINOV2发现在数据量比较大的情况下,模型在Patch级别会欠拟合,在图像级别会过拟合;因此DINOV2将student网络的cls_token和patch_token用不同的检测头来计算Loss;
可以理解为cls_token和patch_token分别经过两个不同的MLP,用来计算不同的loss
而teacher网络也是两个head,只不是参数不是反传的,而是动量更新的

②Sinkhorn-Knopp centering :教师模型中的原有的softmax-centering 存在不稳定性,因此teacher网络用了Sinkhorn-Knopp centering来避免坍塌、增强与student的一致性,同时提高计算效率;
具体操作:通过3次行归一化和列归一化,然后最终用softmax
③Adapting the resolution :自适应性分辨率机制,预训练阶段用224224大小的图像,在预训练的最后一段时间内,用518 518大小的图像,便于提高检测效果,平衡资源占用;
④关于输入 :student网络的输入和teacher网络的输入和DINOV1差不多,一张图经过两种增强,得到两个全局图像,然后crop成8个局部图像,局部图像和全局图像对齐(即缩放到和全局图像一个尺寸),student网络接受全局+局部图像,并且做mask,teacher网络只接受全局图像;
5、一些问答:
① DINOv2 的训练框架属于什么范式?和 DINO 有什么区别?
答:DINOv2 属于 self-distillation without labels 的自监督方法,采用:teacher-student 架构、多视图对齐(global / local crops)、projection head、EMA 更新 teacher
与 DINO 不同的是:融合了 iBOT(patch-level masked prediction)、引入 KoLeo Regularizer(feature 分布均匀化)、使用 frozen teacher(no centering / no sharpening)、使用更强的数据增强策略、backbone 更加标准化(ViT with registers)
② 为什么 teacher 不反向传播,而是用 EMA 更新?
答:保持 teacher 作为"平滑的目标网络",能:稳定训练、提供低噪声 target、保证对齐一致性
③ DINOv2 的输入是什么样的?
多尺度 multi-crop(两张 global crop + 多张 local crop)
部分 crop 用于 iBOT masked patch prediction
teacher 只接收 global crops
④ 什么是"head untying"?为什么需要它?
答:DINOv2 使用两个 projection head:
| head | 用途 | 输入 |
|---|---|---|
| DINO head | image-level loss(CLS) | CLS token |
| iBOT head | patch-level loss(mask pred) | patch tokens |
Untying 表示这两个 head 不共享参数,因为:
CLS 和 patch 的任务不同,统计分布不同
使用同一个 head 会冲突、降低性能
teacher 也有两个对应的 head,参数来自 student 的 EMA 版本。
⑤ student 和 teacher 的输入有什么不同?
答:
| 组件 | Student | Teacher |
|---|---|---|
| 输入 crop 数量 | global + local | only global |
| 是否 masking | 是(用于 iBOT) | 否 |
| 是否接收 small crops | 是 | 否 |
⑥ iBOT 损失在 DINOv2 中如何运作?mask 如何实现?
答:mask 方式:在 student 的输入 patch 中:按概率随机 mask(15%--40%),用一个 MASK token embedding 替换原 patch embedding,这个 mask 只发生在 student 上。
iBOT loss:
student 的 masked patch 输出 → student iBOT head → q(patch)
teacher 的 unmasked patch 输出 → teacher iBOT head → p(patch)
计算 cross-entropy 或 soft target loss(和 masked autoencoder 不同,它是预测 teacher 的分类分布)
⑦ KoLeo Regularizer 是什么?在哪一步计算?输入是什么?
答:KoLeo 是 特征均匀化正则化,目标是让 embedding 在单位球面上排列得更均匀。
输入:student DINO head 输出的 CLS embedding(z_dino)
在哪计算:只用 student,不用 teacher
⑧ 为什么 KoLeo 只作用在 DINO head 输出而不是 iBOT head?
答:KoLeo 是 global feature regularizer;iBOT 是 patch-level feature,不代表整图;对 local patch 做均匀性约束会破坏语义结构;官方代码中明确只对 image-level embedding 做 KoLeo(CLS token)
⑨ DINOv2 为什么 teacher 不再使用 centering 和 sharpening?
答:因为加入 iBOT 与多尺度数据增强后,teacher 的输出统计更加稳定,DINOv1 中用于稳定分布的 centering / sharpening 不再需要。此外,去掉该机制简化了实现,提高训练效率。
⑩ DINOv2 如何让 CLS token 和 patch token 能同时学到语义?
答:image-level CLS 对齐(LDINO)提供全局语义信号,patch-level masked prediction(LiBOT)提供局部结构信号,两个损失共同作用,CLS 学语义,patch 学物体分解结构,KoLeo 保持 global 语义空间分布良好,最终让 backbone 产生强特征,可直接用于分类/检索/分割。
⑩① 为什么要禁止 teacher 接受 local crop?
答:teacher 只提供全局语义 supervision,如果 teacher 也处理 local,会导致:student 与 teacher 语义尺度不一致,supervision 变弱,多视图不再是"global → local 对齐"
⑩② DINOv2 的训练目标各自作用在哪些 token?
答:
| Loss | token | 是否 mask | head |
|---|---|---|---|
| LDINO | CLS(student vs teacher) | 无 | DINO head |
| LiBOT | Patch(masked student vs unmasked teacher) | ✔ | iBOT head |
| LKoLeo | CLS(student) | 无 | DINO head |
⑩③ 为什么 student 需要多 crop,但 teacher 只需要 global crops?
答:student 需要见到:多视角(global + local)、多尺度、部分 masked;
teacher 负责提供一个稳定、全局一致的目标,所以用统一视角(global)。
⑩④ 为什么说 DINOv2 是"纯自监督"?它和监督训练一样强?
答:因为它没有使用任何标签。
但通过:自蒸馏、teacher 的 EMA、多层次多尺度的 dense prediction(iBOT)、KoLeo 的均匀化、高质量的增强 pipeline、学习到了比 supervised 更具泛化性的图像表征。
⑩⑤ DINOv2 的 teacher parameters 更新时 momentum 是如何 schedule 的?为什么固定不是最优?
答:使用 cosine schedule,让 momentum 从 0.996 → 1.0
随训练推进更接近 1,使 teacher 更稳定
早期 teacher 要跟得上 student,晚期 teacher 要稳定提供 target
⑩⑥ 为什么 iBOT 的 patch-level loss 没有采用 masked autoencoder 的 pixel reconstruction?
答:因为 MAE reconstruction 偏向低级纹理;iBOT 对齐 teacher 的语义表征,更适合学习语义 patch embedding。
⑩⑦ 解释 register tokens 在 DINOv2 中的作用。
答:Register tokens(固定数量)作为特殊 token:缓冲 self-attention 信息、稳定特征结构、在大批量训练时提高表示一致性、类似于"可学习的 memory slot"
它们不参与 loss。