目录
[1.1 NoteLLM框架](#1.1 NoteLLM框架)
[1.2 笔记压缩提示](#1.2 笔记压缩提示)
[1.3 生成-对比学习](#1.3 生成-对比学习)
[1.4 协同监督微调(Collaborative Supervised Fine-Tuning)](#1.4 协同监督微调(Collaborative Supervised Fine-Tuning))
上一篇论文:推荐大模型系列-NoteLLM: A Retrievable Large Language Model for Note Recommendation(一)
一、方法论
1.1 NoteLLM框架
本节介绍NoteLLM的框架,包含三个核心组件:笔记压缩提示词构建(Note Compression Prompt Construction)、生成式对比学习(GCL)和协同监督微调(CSFT),如图2所示。
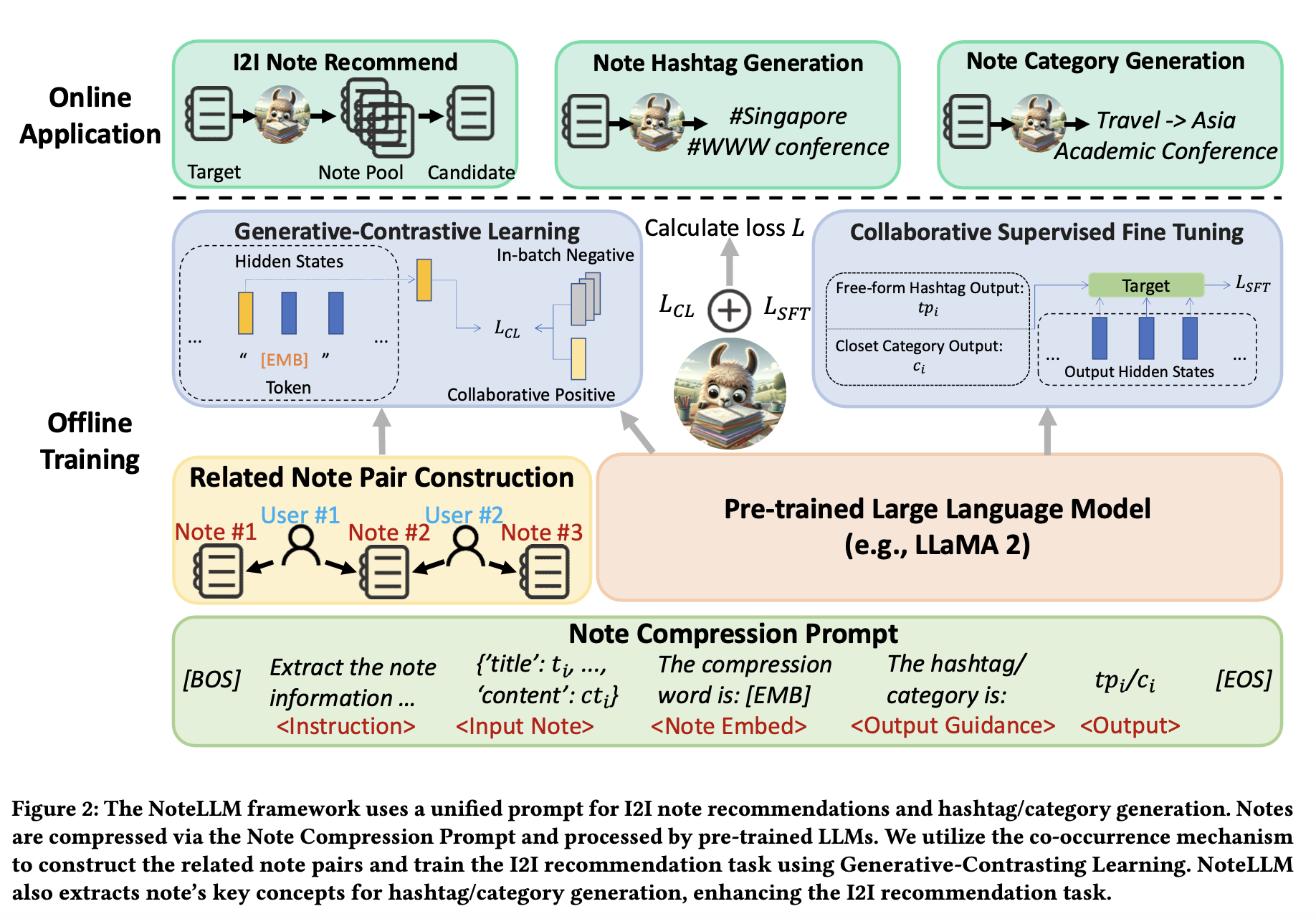
通过笔记压缩提示灵活管理图像到图像(I2I)推荐任务及标签/分类生成任务。这些提示经分词后输入大语言模型(LLMs)。NoteLLM将协同信号与语义信息共同嵌入隐藏状态中。
生成式对比学习(GCL)利用生成压缩词的隐藏状态进行对比学习,从而捕获协同信号。
协同监督微调(CSFT)结合笔记的语义与协同信息,生成标签及分类内容。
1.2 笔记压缩提示
采用统一的笔记压缩提示(Note Compression Prompt)来同时支持图像到图像(I2I)推荐和生成任务。为了利用自回归大语言模型(LLMs)在I2I推荐任务中的生成能力,目标是将笔记内容压缩为单个特殊标记。这一压缩后的特殊标记通过生成式对比学习(GCL)获取协同知识,随后通过协同监督微调(CSFT)利用该知识生成标签/分类。
具体提出以下通用模板,用于笔记压缩及标签/分类生成:

特殊令牌与占位符说明
BOS、EMB、EOS 是特殊令牌(special tokens),用于标记文本的开始、嵌入和结束。
<Instruction>、<Input Note>、<Output Guidance>、<Output> 是占位符,在实际使用时会被替换为具体内容。
分类生成的具体内容定义
该模板中,占位符的具体含义如下:
- <Instruction>:任务指令,描述用户需要完成的操作。
- <Input Note>:输入说明,提供输入数据的格式或要求。
- <Output Guidance>:输出引导,指导如何生成正确的输出。
- <Output>:实际输出内容,由模型根据指令生成。

以下为话题标签生成的模板:

针对用户生成的话题标签数量不可预测的情况,采用随机抽取原始标签子集作为生成目标,以减少对大语言模型的潜在误导。随机选择的话题标签数量记为<j>,该数值同时嵌入<指令>和<输出引导>两部分。
完成提示词构建后,将其进行令牌化处理并输入大语言模型。模型通过蒸馏协作信号与关键语义信息,将其压缩为核心词汇,最终基于笔记的核心思想生成话题标签/分类。
1.3 生成-对比学习
预训练大语言模型(LLMs)通常通过指令微调或人类反馈强化学习(RLHF)学习新知识。这些方法主要利用语义信息提升模型的有效性和安全性。然而,在推荐任务中,仅依赖语义信息并不充分。协同信号对识别用户感兴趣的内容至关重要,但LLMs中缺乏此类信号。因此,提出生成-对比学习(GCL)以增强LLMs捕获协同信号的能力。GCL采用对比学习,从整体视角学习笔记间的关系邻近性,而非依赖特定答案或奖励模型。
协同信号整合
为将协同信号融入LLMs,采用共现机制基于用户行为构建相关笔记对。其假设是:被频繁共同阅读的笔记可能相关。具体实现中,收集一周内的用户行为数据统计共现次数,记录用户先浏览笔记𝑛𝐴后点击笔记𝑛𝐵的行为。同时,为区分不同用户对共现的贡献差异,为不同点击分配权重。共现得分计算公式如下:
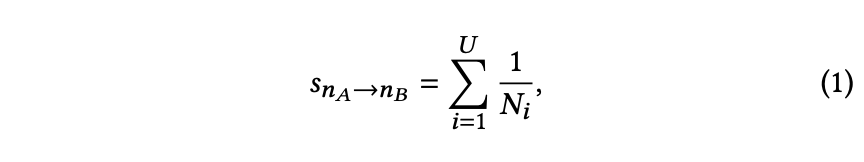
𝑠𝑛𝐴→𝑛𝐵 表示从笔记𝑛𝐴到笔记𝑛𝐵的共现分数,𝑈是用户行为数据中的用户数量,𝑁𝑖表示第𝑖个用户在用户行为数据中点击的笔记集合的数量。这一操作的目的是防止活跃用户的误导行为,他们可能会盲目点击推荐给他们的每一条笔记。
计算所有笔记对的共现分数后,构建从笔记𝑛𝑖到所有其他笔记的共现分数集合S𝑛𝑖,具体定义为{𝑠𝑛𝑖→𝑛𝑗 |1 ≤ 𝑗 ≤ 𝑚,𝑖 ≠ 𝑗}。接着,从S𝑛𝑖中过滤掉共现分数高于阈值𝑢或低于阈值𝑙的异常笔记。最后,从过滤后的集合中选择共现分数最高的𝑡条笔记作为笔记𝑛𝑖的相关笔记。
构建相关笔记对后,训练NoteLLM以基于文本语义和协同信号判断笔记的相关性。不同于简单地使用特殊池化词表示笔记,通过提示(prompt)压缩笔记信息生成一个虚拟词。该虚拟词的最后隐藏状态包含给定笔记的语义信息和协同信号,可用于表示笔记。
具体而言,由于大语言模型(LLM)的自回归特性,取EMB前一个token的最后隐藏状态,并通过线性层将其转换到维度为𝑑的笔记嵌入空间。第𝑖条笔记𝑛𝑖的嵌入表示为𝒏𝑖。假设每个小批量(minibatch)包含𝐵对相关笔记,则每个小批量共有2𝐵条笔记。将笔记𝑛𝑖的相关笔记记为𝑛𝑖+,其嵌入表示为𝒏𝑖+。参考相关研究,生成式-对比学习(GCL)的损失函数计算如下:
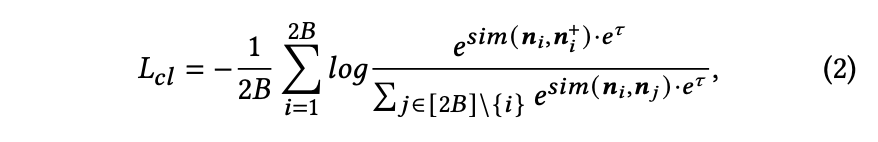
该公式中:
- (
) 表示生成式-对比学习(GCL)的损失函数。
- (
- (
1.4 协同监督微调(Collaborative Supervised Fine-Tuning)
大语言模型(LLMs)因其强大的语义理解和生成能力而备受关注。现有研究尝试将LLMs的卓越能力应用于句子嵌入生成10, 26, 28, 30, 39,但这些方法忽视了LLMs的生成特性,仅将其视为嵌入生成器,未能充分挖掘其潜力。此外,这些方法未充分利用代表笔记核心概念的标签/分类信息。
生成标签/分类与生成笔记嵌入具有相似性,两者均旨在总结笔记内容。标签/分类生成任务从文本生成角度提取关键信息,而笔记嵌入任务则从协同过滤视角将笔记压缩为虚拟词,用于I2I推荐。为此,NoteLLM联合建模生成式-对比学习(GCL)与协同监督微调(CSFT)任务,以提升嵌入质量。通过将两项任务整合至单一提示模板,为两者提供额外信息并简化训练流程。
具体实现中,CSFT利用笔记的语义内容及压缩令牌中的协同信号生成标签/分类。为提升训练效率并缓解遗忘问题40,每个批次中随机选择𝑟条笔记执行标签生成任务,其余笔记用于分类生成任务。CSFT损失函数计算如下:
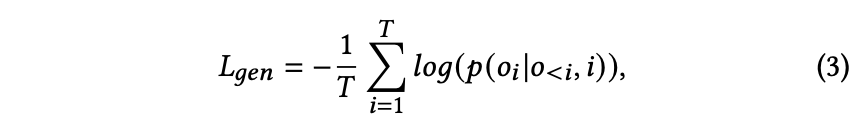
𝐿𝑔𝑒𝑛 表示 CSFT(协同监督微调)损失,𝑇 是输出序列的长度,𝑜𝑖 代表输出序列 𝑜 中的第 𝑖 个 token,而 𝑖 是输入序列。最终,NoteLLM 的损失函数结合了 GCL(全局对比学习)和 CSFT,定义如下:
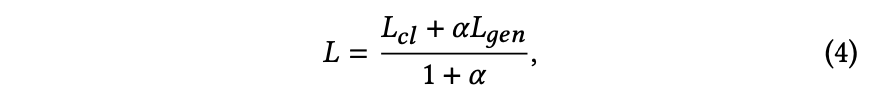
其中,𝐿 表示 NoteLLM 的总损失函数,𝛼 为超参数。通过模型更新,NoteLLM 能够同步执行笔记推荐场景中的图文推荐(I2I)任务以及话题标签/类别生成任务。
本篇内容关于方法论的部分已经完成描述,下一篇会具体讲解实验部分。
下一篇论文:推荐大模型系列-NoteLLM: A Retrievable Large Language Model for Note Recommendation(三)