根据您提供的详细信息和原始模板,我将为您完整整理一份结构清晰、内容详实的系统描述文档,适用于 F060 基于BERT + Vue + Flask 的电影评论情感分析系统。
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,私信获取! 麦麦大数据
编号: F060
视频
F060 基于BERTvue+flask电影评论情感分析系统
1 系统简介
系统简介:本系统是一个基于 Vue + Flask + MySQL 构建的电影评论情感分析与推荐系统 。其核心功能围绕电影信息管理、评论情感分析、个性化推荐与多维度数据分析 展开。主要功能模块包括:登录注册、用户权限控制、电影库查询、推荐系统、情感分析、可视化统计(词云、柱状图、箱线图等)、用户管理、电影管理。
系统整合了爬虫技术、自然语言处理(NLP)、协同过滤推荐与大数据可视化,为用户提供从电影浏览、情感洞察到行业趋势分析于一体的综合平台。尤其通过引入 BERT 三分类模型,实现对评论情感的更细粒度分析(积极、中立、消极),显著提升情感判断的准确性。
2 功能设计
该系统采用前后端分离的B/S架构模式,基于Vue.js + Flask + MySQL技术栈实现。前端通过Vue.js框架搭建响应式界面,结合Element UI 组件库提供友好的用户交互体验,使用Vue-Router 进行页面路由管理,Axios 实现与后端的异步数据交互。Flask后端负责构建RESTful API服务,通过Flask-SQLAlchemy ORM层操作MySQL数据库存储用户信息、电影数据、评论、用户行为日志等结构化数据,PyMySQL作为MySQL驱动支持。
在情感分析 功能方面,系统采用BERT预训练模型 进行细粒度三分类(积极、中立、消极),相较于传统LSTM二分类模型,显著提升了对复杂语义的理解能力。在权限控制方面,系统引入角色分离机制(用户、管理员),确保系统安全性与操作权限的隔离性。
2.1 系统架构图
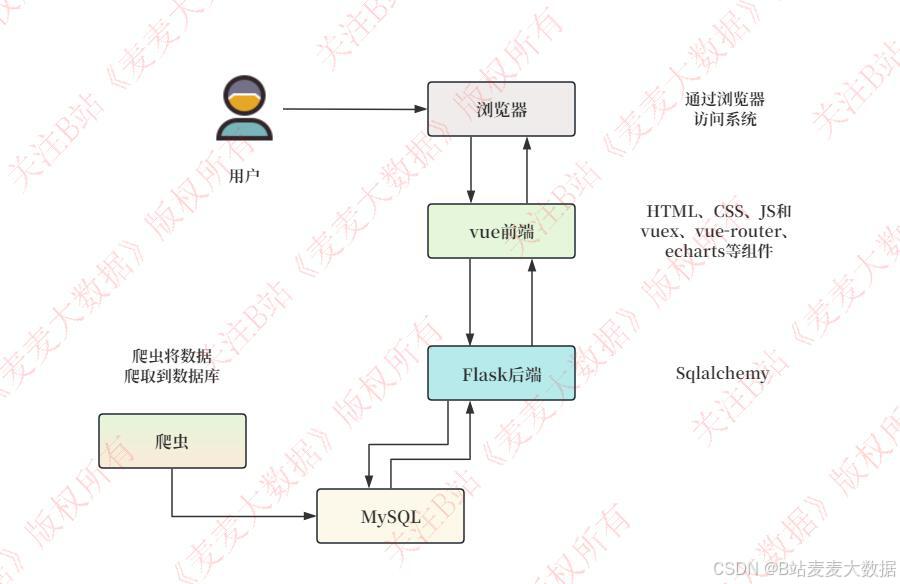
2.2 功能模块图
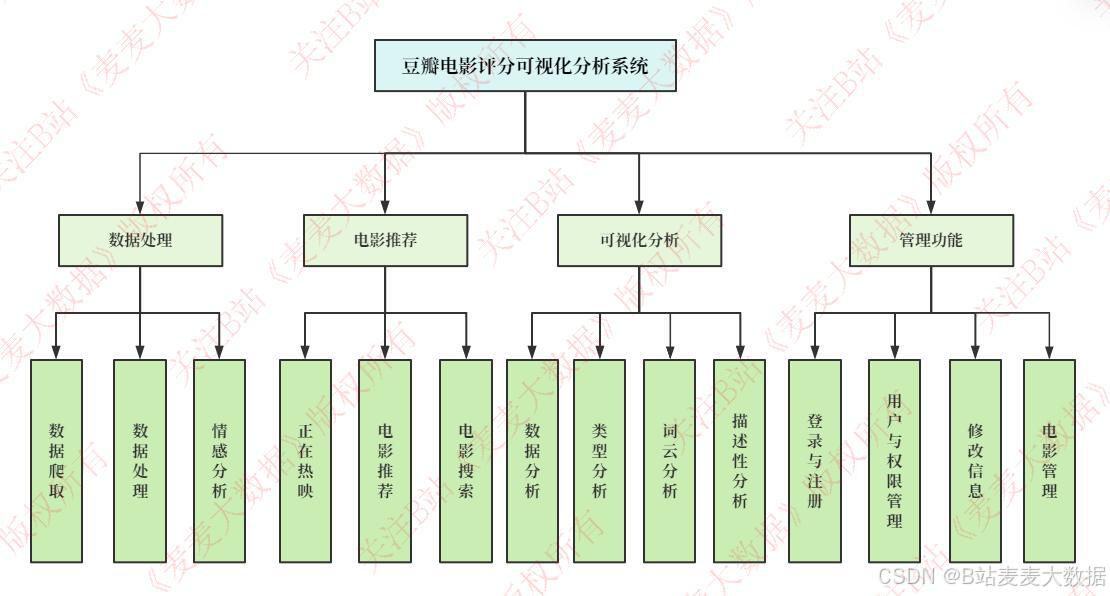
主要功能模块有:
- 用户登录与注册模块:支持账号注册、登录、身份验证与信息修改。
- 电影库模块:支持关键词模糊搜索(电影名/别名)、分页浏览、电影信息展示。
- 推荐模块:提供"正在上映"、"评分最高"、"基于用户协同过滤(UserCF)"与"基于物品协同过滤(ItemCF)"四种推荐策略。
- 情感分析模块:基于BERT模型分析影评情感倾向,支持情感类别与置信度展示。
- 数据分析模块 :
- 数据统计与可视化
- 类型词云分析
- 时空趋势分析
- 评分分布分析(箱线图)
- 权限与管理模块 :
- 管理员角色拥有用户管理(增删改查、权限分配)和电影管理(增删改查、状态设置)权限。
- 个人设置模块:支持头像上传、个人信息修改与密码重置。
2.3 流程图
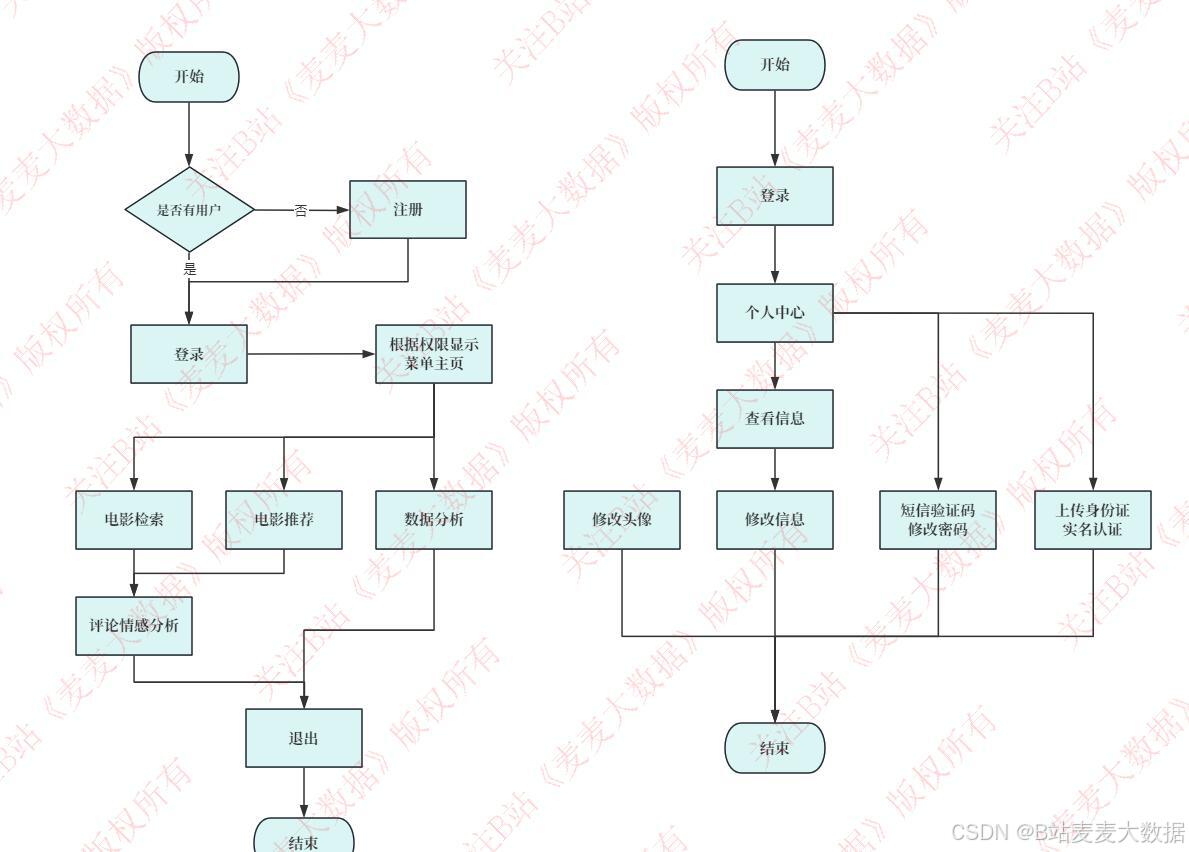
该系统流程图完整地展现了用户与管理员在系统中的主要操作流程,体现了系统的权限分离设计。
用户流程:
系统启动后,首先进入"是否已有用户"的判断。如果用户已有账号,则直接进入"登录"环节;否则,需要先"注册"。
登录成功后,用户可进入"个人中心"。
从个人中心,用户可进行多种核心操作,包括"电影推荐"、"数据统计"、"电影检索"和"评论情感分析"。
在"评论情感分析"中,用户可以查看评论的深度解析,并可选择"退出"流程结束会话。
在"数据统计"模块,用户可以进行"修改信息"和"上传头像"。
管理员流程:
管理员在登录后同样进入"个人中心"。
从个人中心,管理员可以进行"修改信息"和"上传头像"。
核心功能是"修改头像"和"实名认证"这两个流程,这表明管理员需要对用户信息进行强制管理与验证。
该流程图通过分支结构明确了不同角色的权限范围,用户侧操作丰富,而管理员侧操作则聚焦于核心管理功能,整体流程清晰、易于理解。
2.4 E-R图
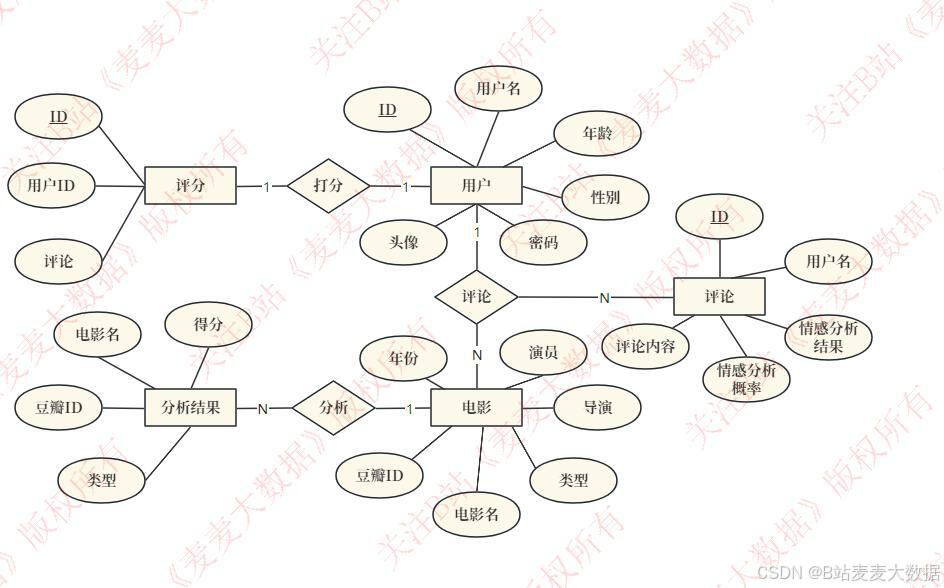
该实体关系图清晰地定义了电影评论情感分析系统的核心数据模型。系统主要围绕三个核心实体构建:用户、电影和评论。
用户实体包含了用户的基本信息,如唯一标识ID、用户名、年龄、性别、头像和密码。同时,用户与"评论"实体通过"1对N"的关系相连,表示一个用户可以发表多条评论。
评论实体是系统的核心数据之一,记录了用户对电影的评价信息,包含ID、评论内容、情感分析结果以及与电影和用户的关联标识。一个"评论"对应一条"电影"。
电影实体包含了电影的详细信息,是整个系统的业务核心。其属性包括ID、电影名、豆瓣评分、类型、导演、演员、年份和评论ID(用于关联所有针对该电影的评论)。
图中还定义了分析实体,它与"用户"和"电影"实体通过"分析"关系相连。该实体记录了用户的评分和对电影的分析结果,这可能是系统进行推荐或统计分析的依据,反映了用户对电影的深度理解和评价。
整个数据模型结构逻辑清晰、层次分明,为系统存储、管理和分析用户、电影及评论数据提供了坚实的数据基础。
2.5 用例图
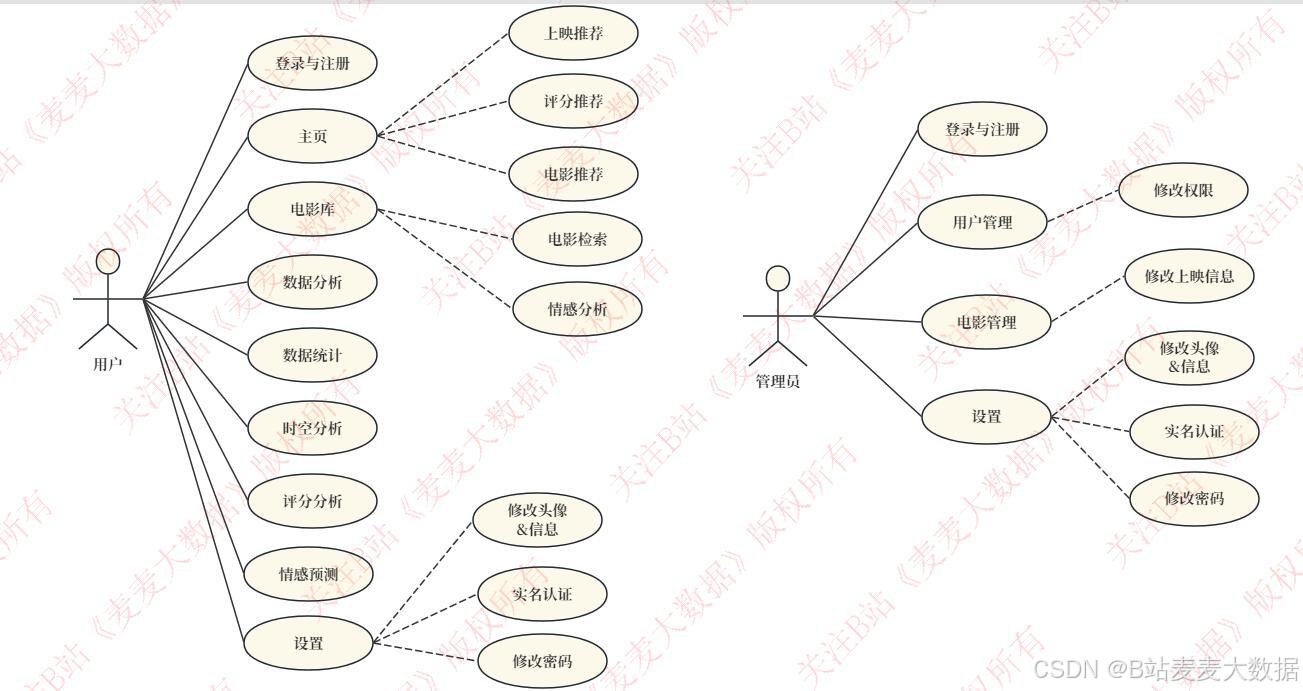
该用例图从用户视角清晰地展示了系统提供的功能及不同用户角色的权限划分。
用户用例:
登录与注册:新用户可以注册账号,老用户可以登录。
主页:登录后首先进入主页,主页提供"电影推荐"和"评分推荐"等功能。
电影库:用户可以查询和浏览电影信息。
数据统计:提供"情感分析"、"时空分析"以及"数据统计"功能,满足用户对电影数据的深入分析需求。
修改信息:用户可以"修改头像"、"修改密码"以及"实名认证"来管理自己的账户信息。
评论:用户可以进行"评论"操作。
管理员用例:
管理:管理员拥有比普通用户更高的权限,其用例是"管理"。
管理员的权限包括:
"用户管理":对系统用户进行增删改查和权限管理。
"电影管理":对电影信息进行增删改查以及修改电影状态。
"修改信息"和"上传头像":与普通用户类似,可管理自身账户。
"修改密码"和"实名认证":进行账户安全设置。
该用例图明确区分了用户和管理员两个角色,通过实线连接表示了功能与角色的关系,通过虚线连接表示了扩展功能(如"评论"、"修改密码"是"管理"用例的扩展)。这直观地体现了系统的权限控制机制,确保了系统的安全性和可维护性。
3 系统详细设计
3.1 登录 & 注册
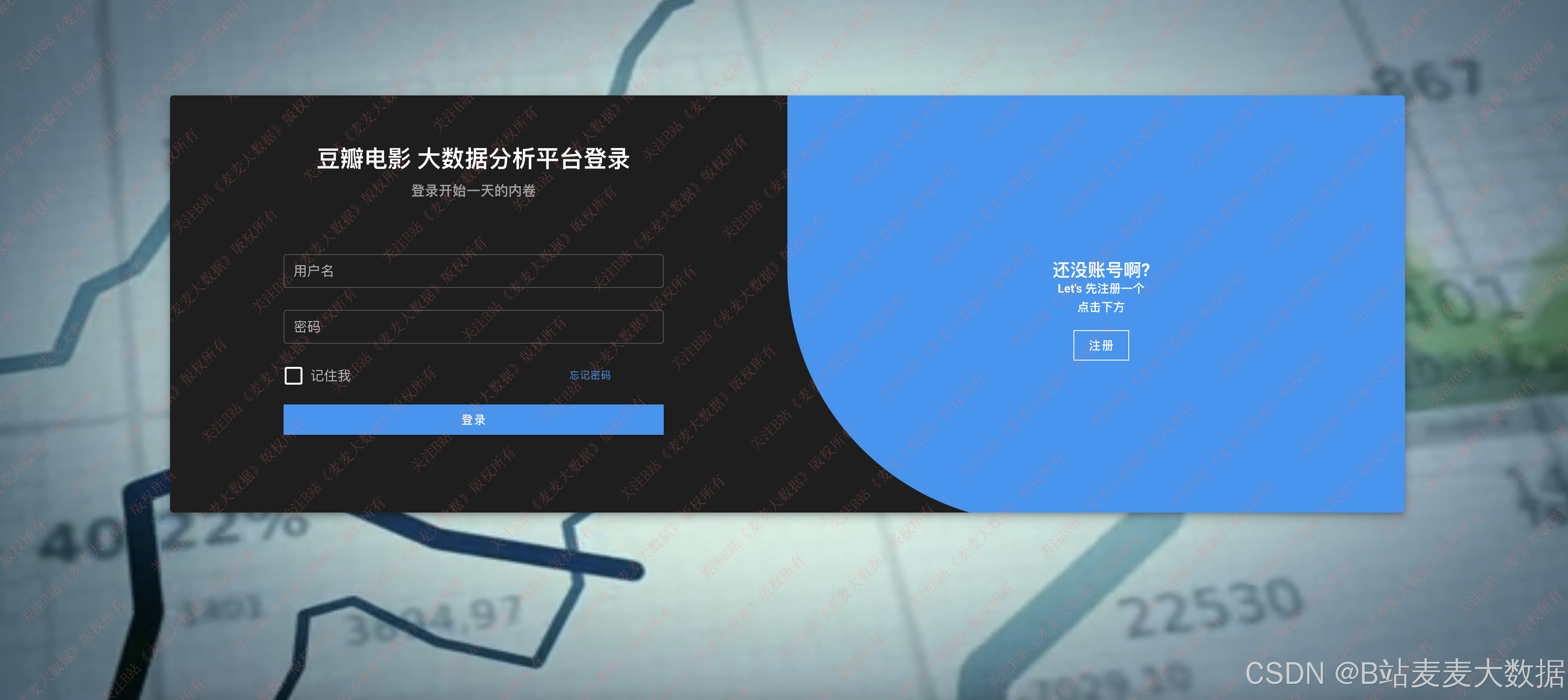
登录注册模块实现的是一个可切换的登录注册界面,用户可点击"去登录"或"去注册"进行页面切换。登录功能需验证用户名与密码的合法性,验证通过后自动跳转至主页;注册功能支持用户填写用户名、密码和邮箱,注册成功后自动跳转至登录页。系统对密码进行加密存储,保障用户信息安全。
3.2 电影库
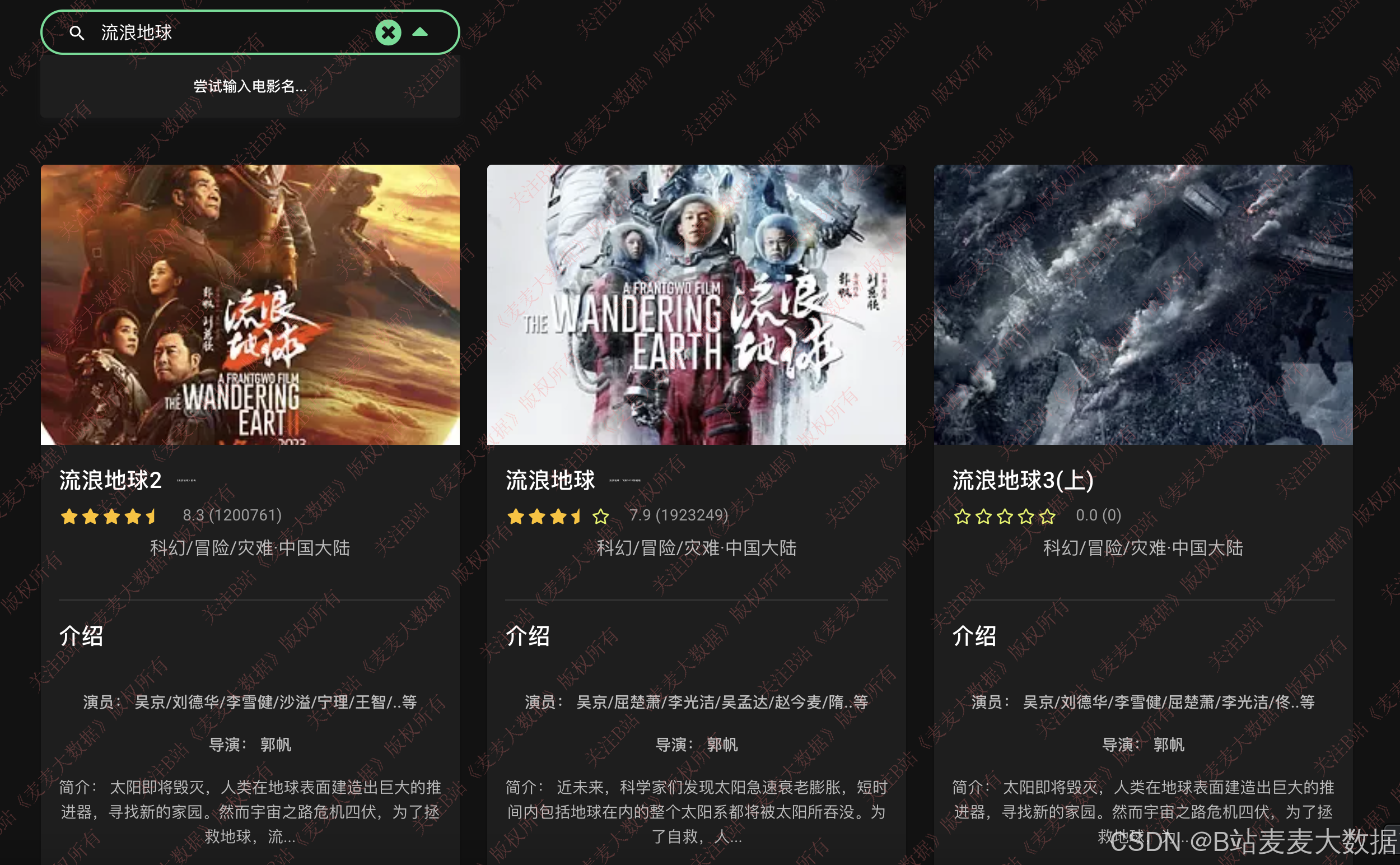
电影库模块支持用户通过输入关键词进行模糊搜索 ,可在电影名称或别名字段中进行查询。为提升用户体验,系统采用前端响应式设计 和搜索防抖机制,防止高频请求,仅在用户输入停止后触发搜索请求。搜索结果以卡片形式展示,包括电影封面、名称、评分(豆瓣评分)及简介等关键信息。
3.3 推荐系统
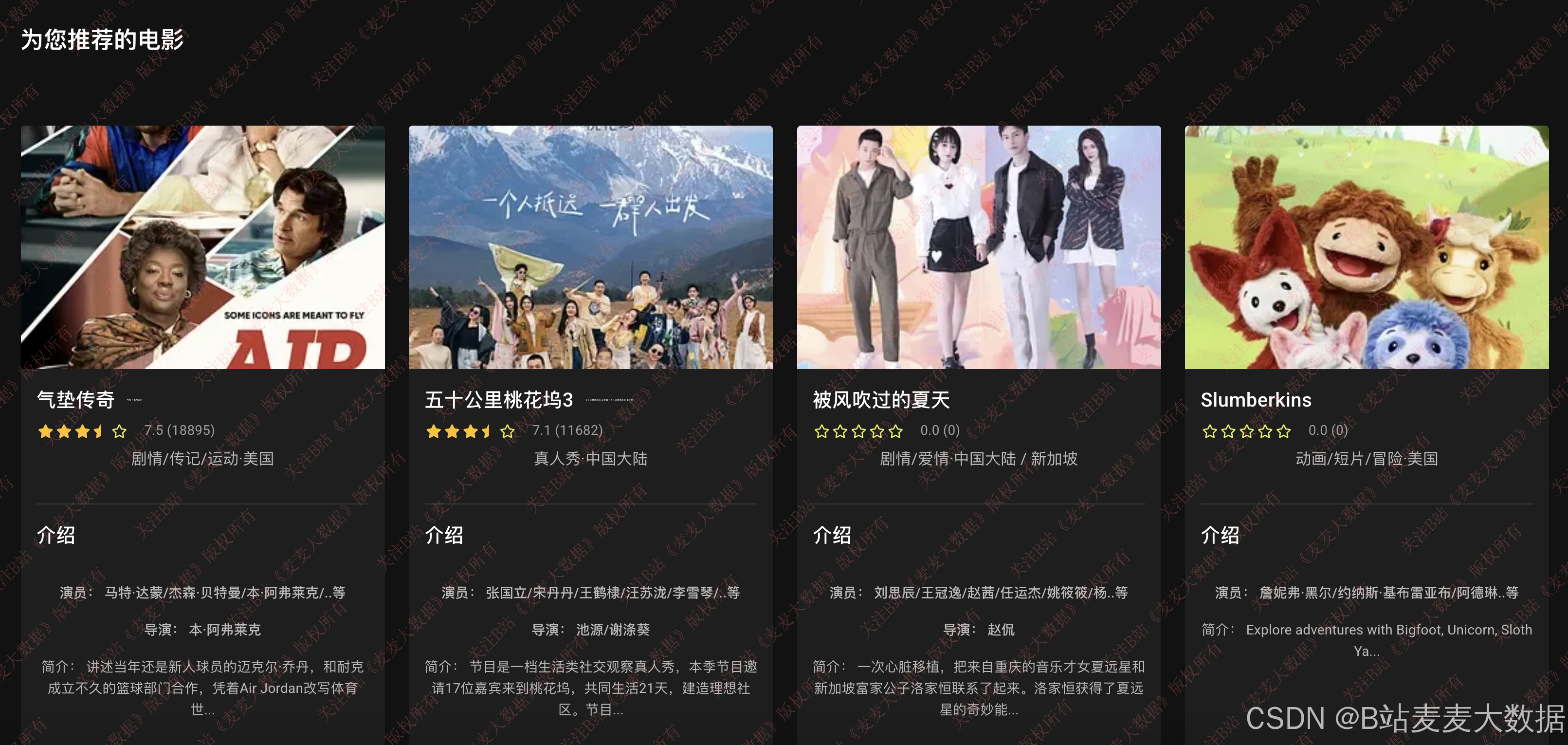
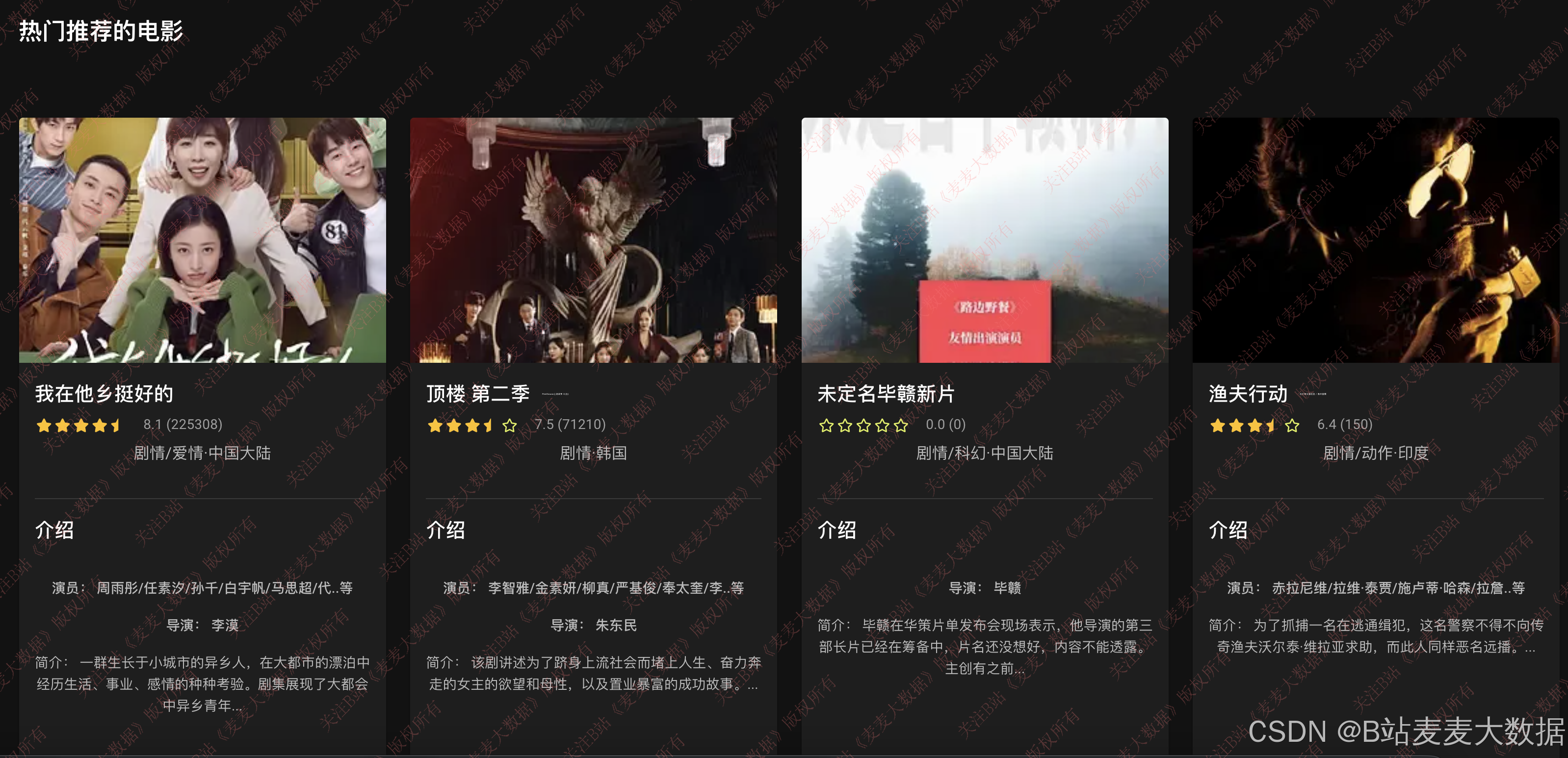
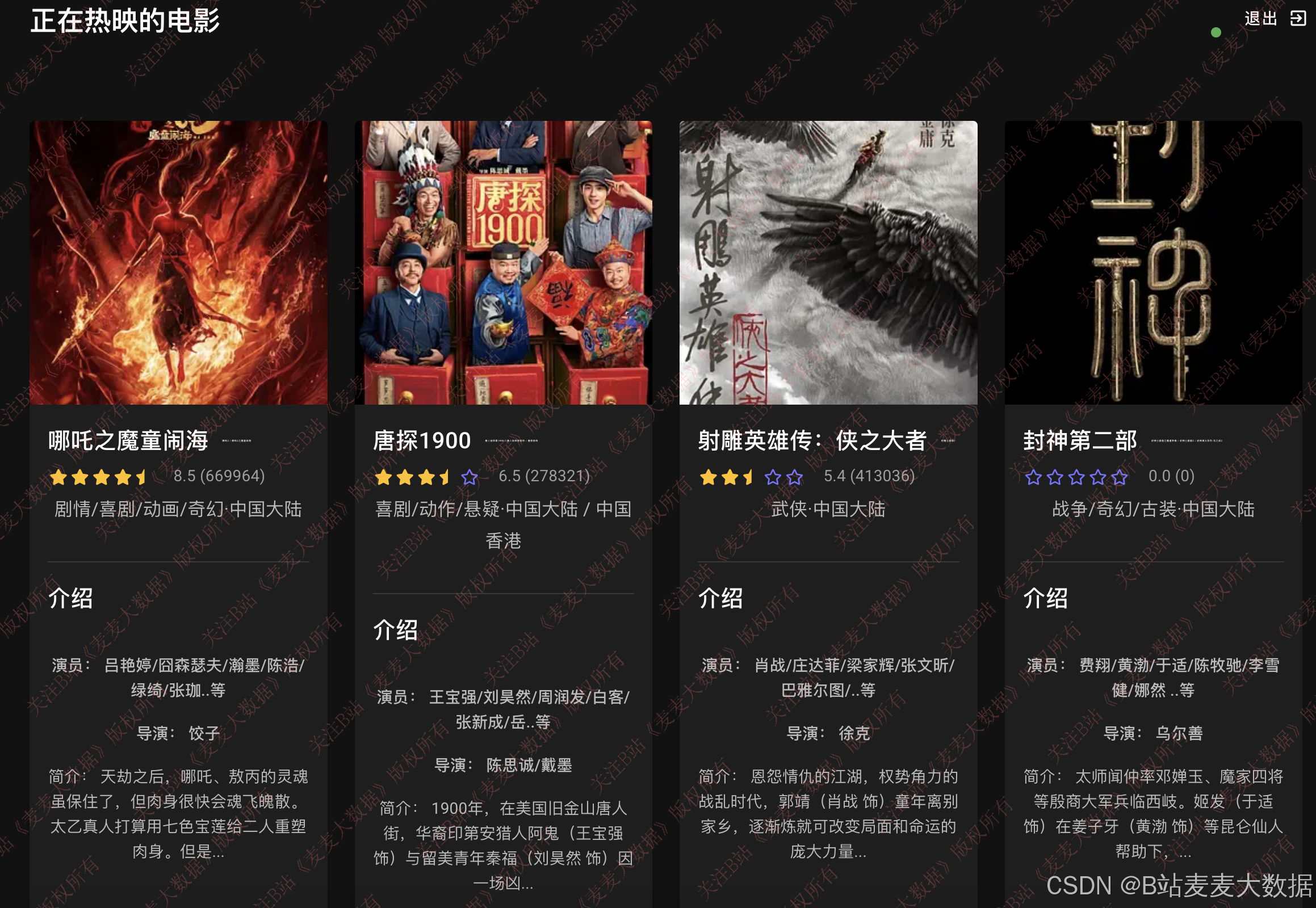
推荐模块包含四个子功能:
- 正在上映电影:标记上映中的影片,优先展示;
- 评分最高电影:按豆瓣评分降序排列,展示口碑最佳的电影;
- UserCF推荐:基于用户相似度,为当前用户推荐与其口味相近的电影;
- ItemCF推荐:基于电影相似性,为用户推荐与已感兴趣影片类似的电影。
推荐结果将根据用户浏览历史动态调整排序,实现个性化推荐。
3.4 情感分析
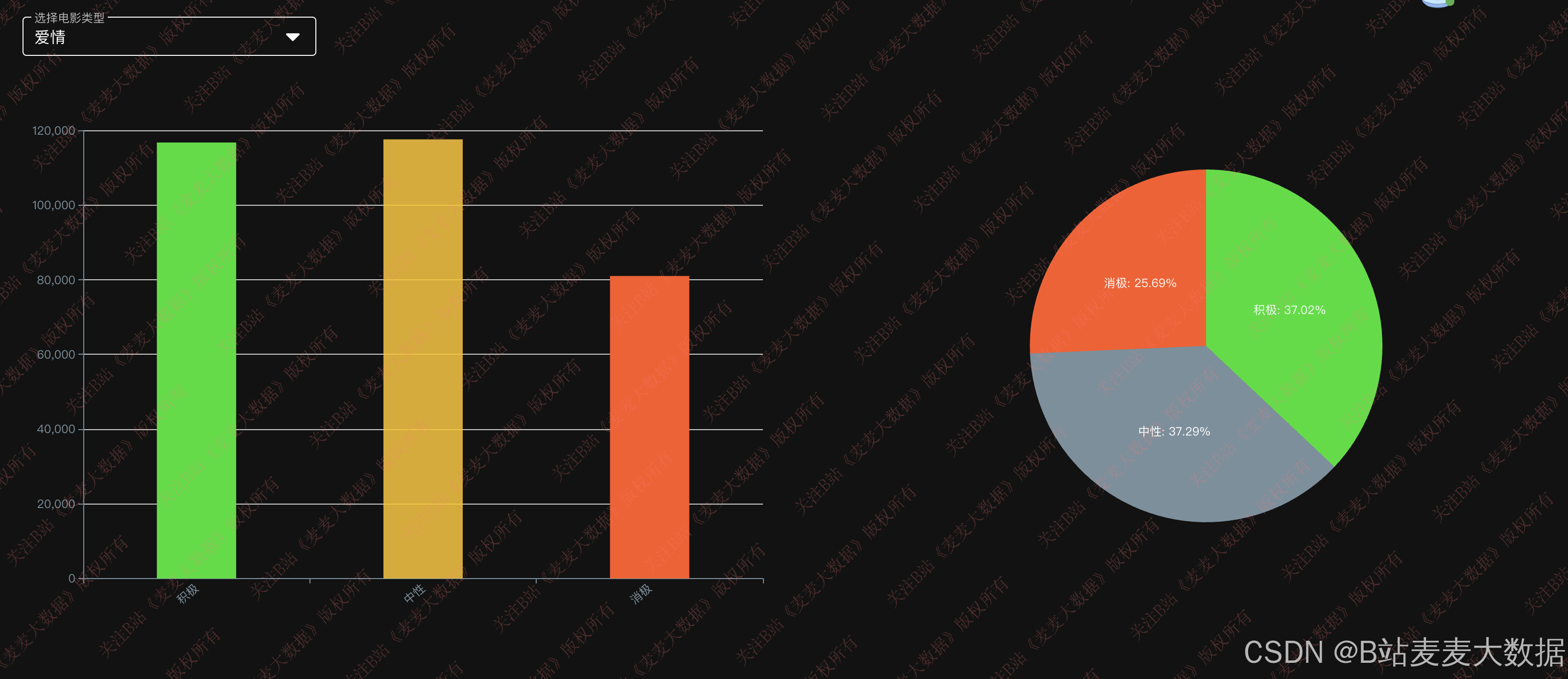

情感分析模块使用预训练的 BERT 模型 对用户评论进行三分类:积极、中立、消极。系统支持:
- 每部电影的评论情感分布统计;
- 显示典型积极/消极评论样本;
- 提供情感概率图与类别比例饼图。
该模块提升了传统评分数据的深度解读能力,为用户选片与电影行业分析提供参考。
3.5 数据可视化
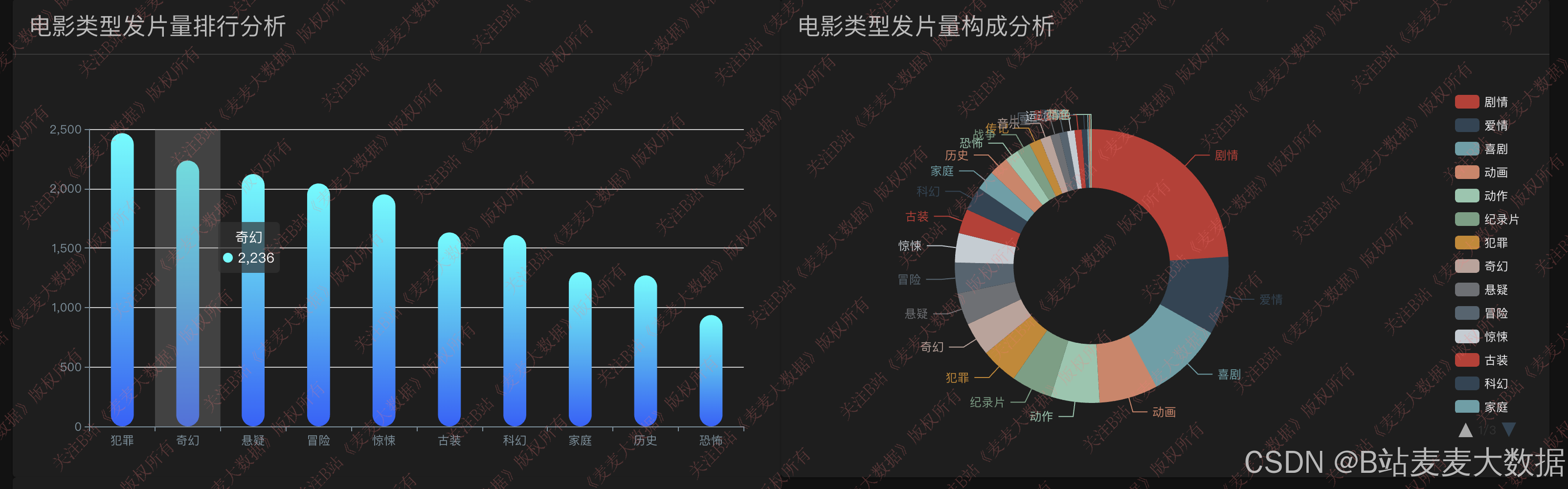
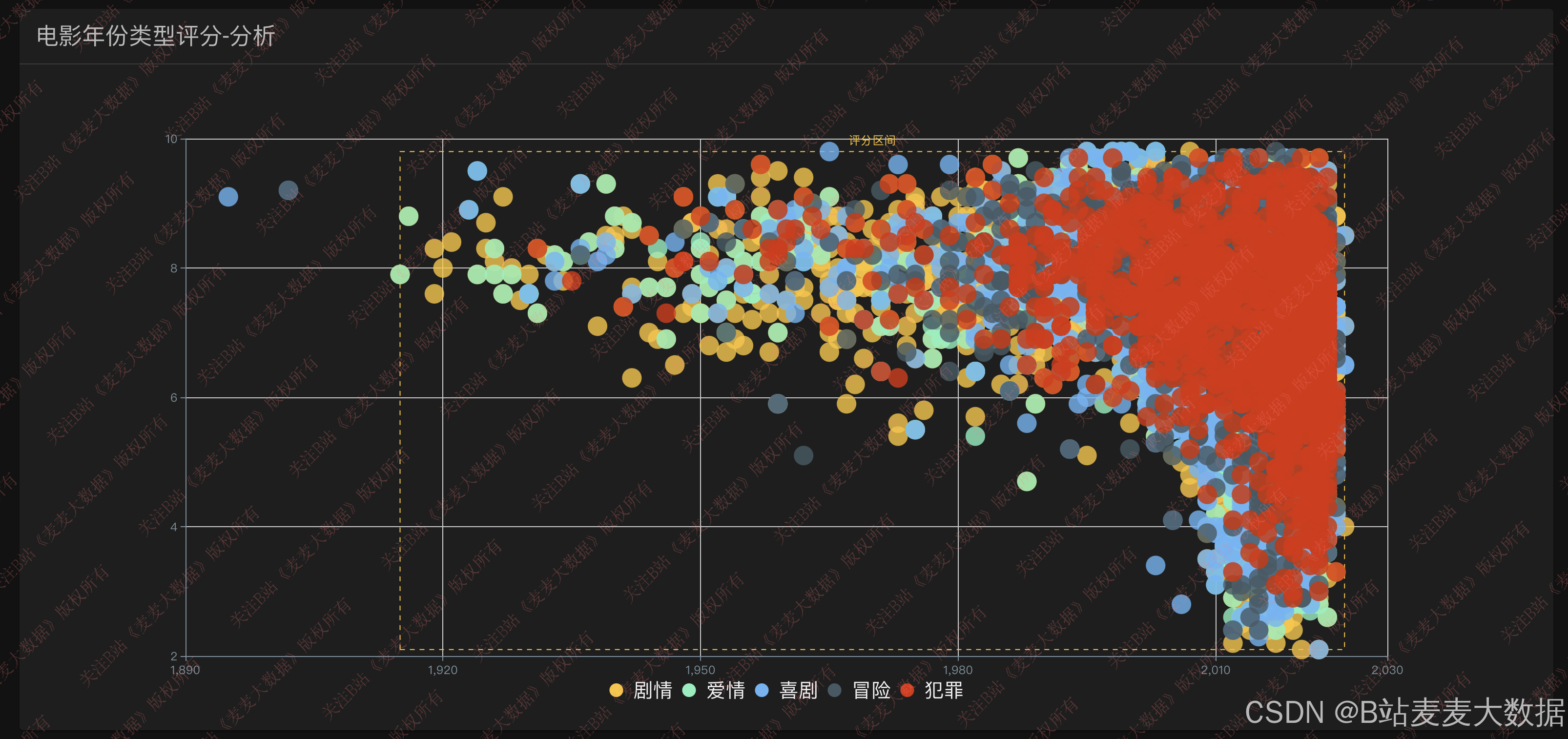
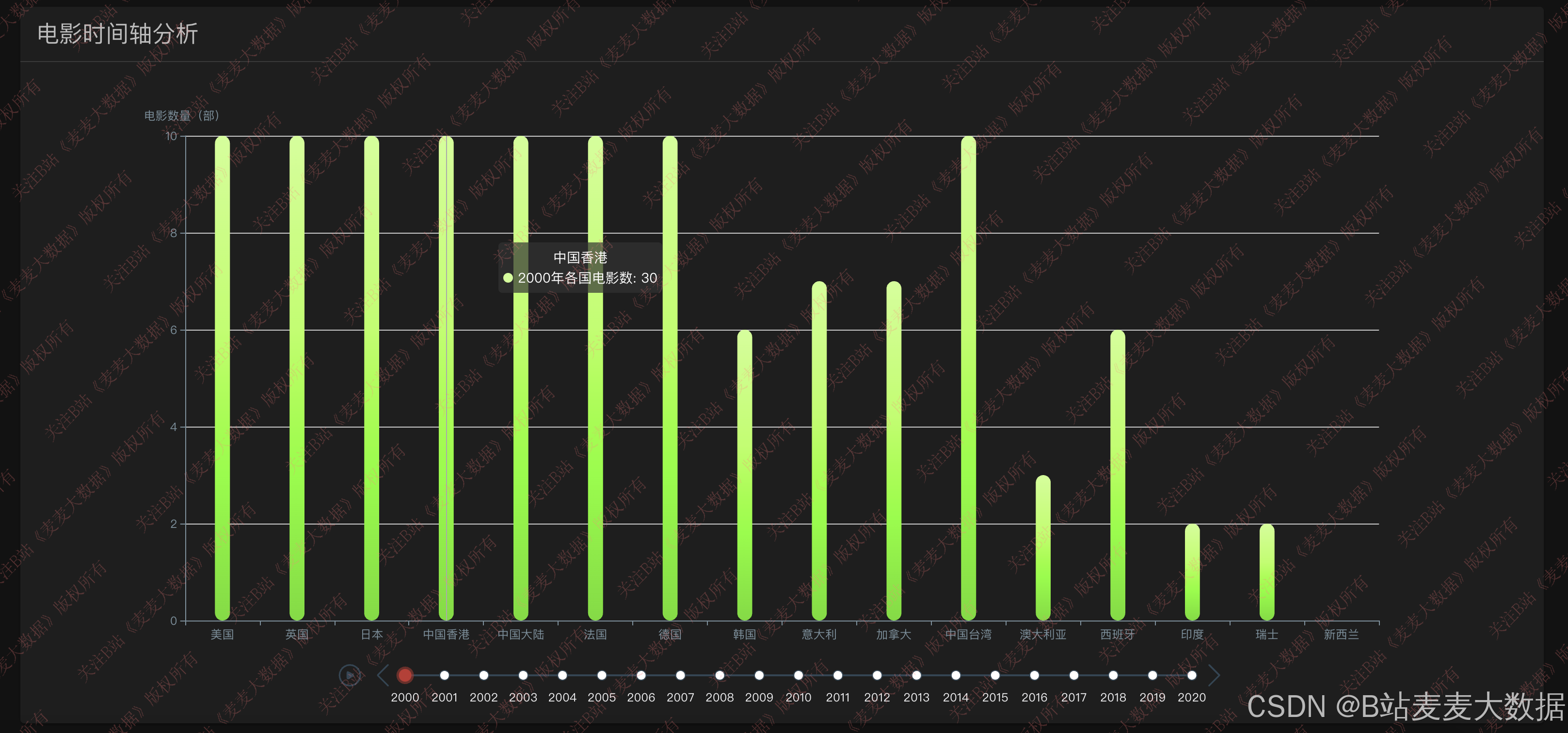

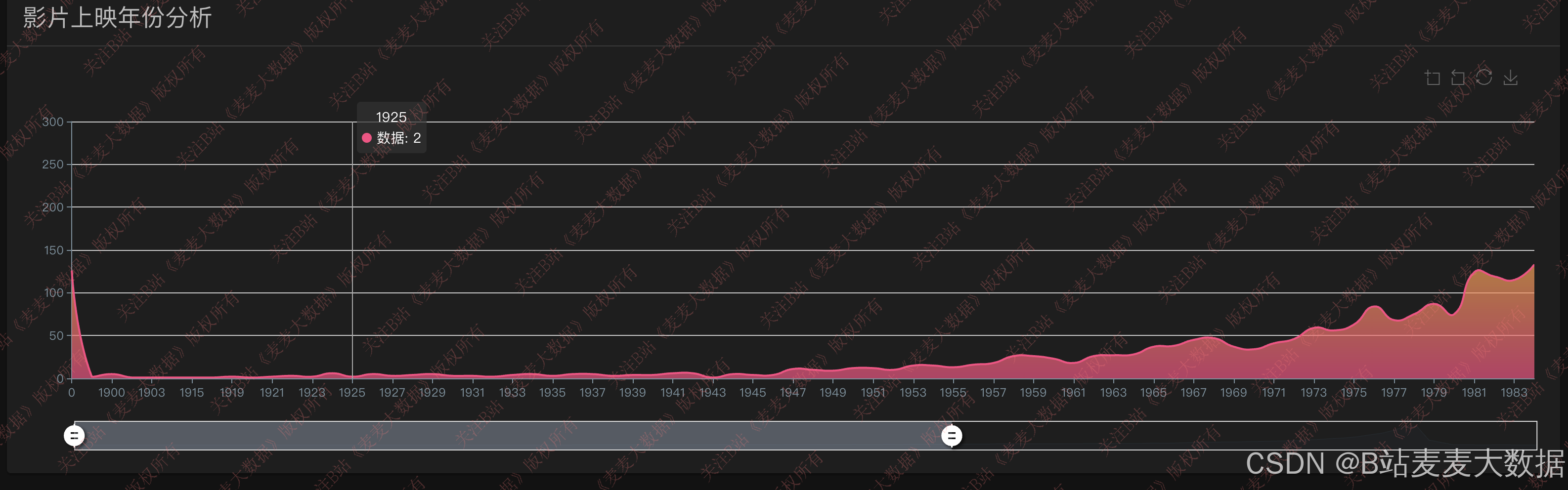
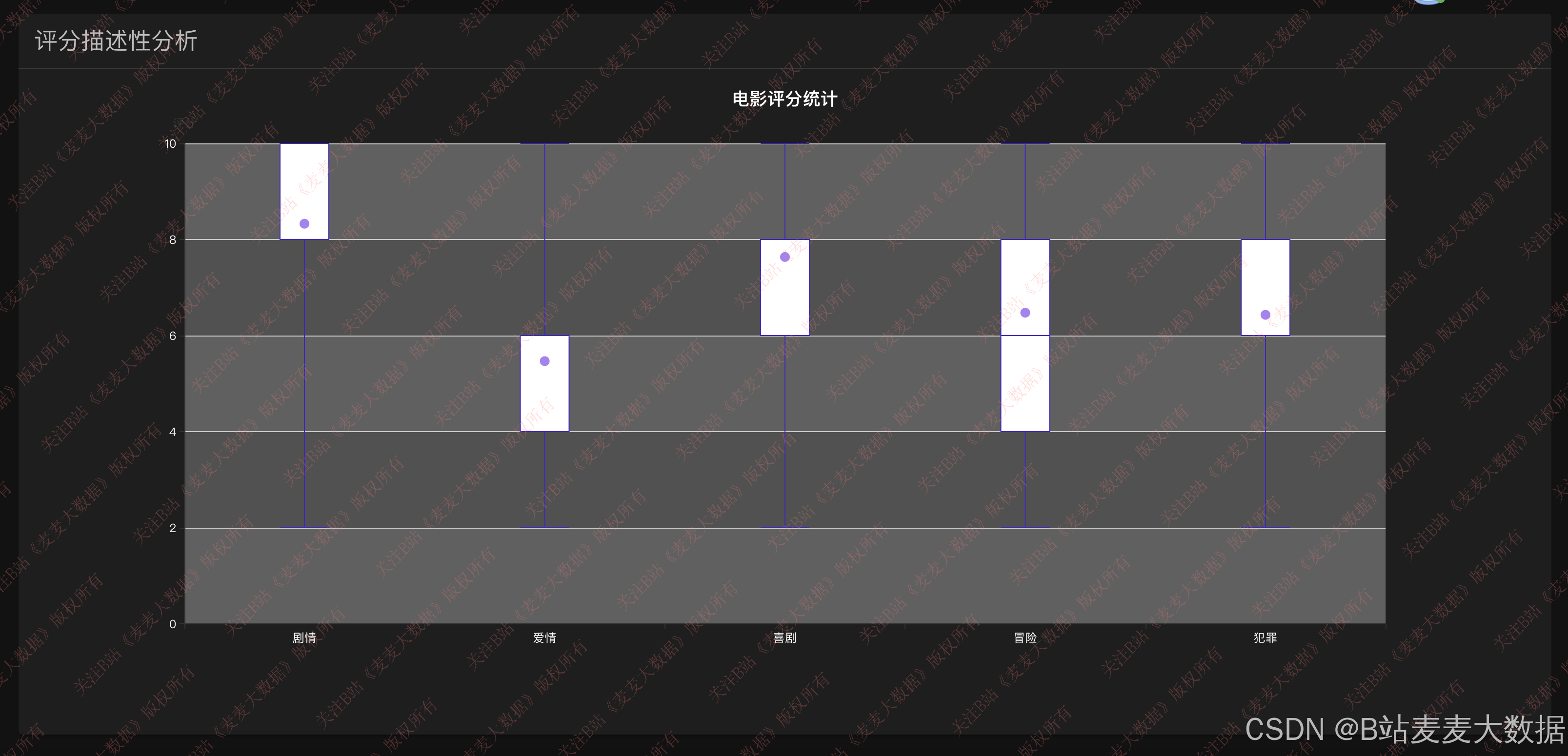


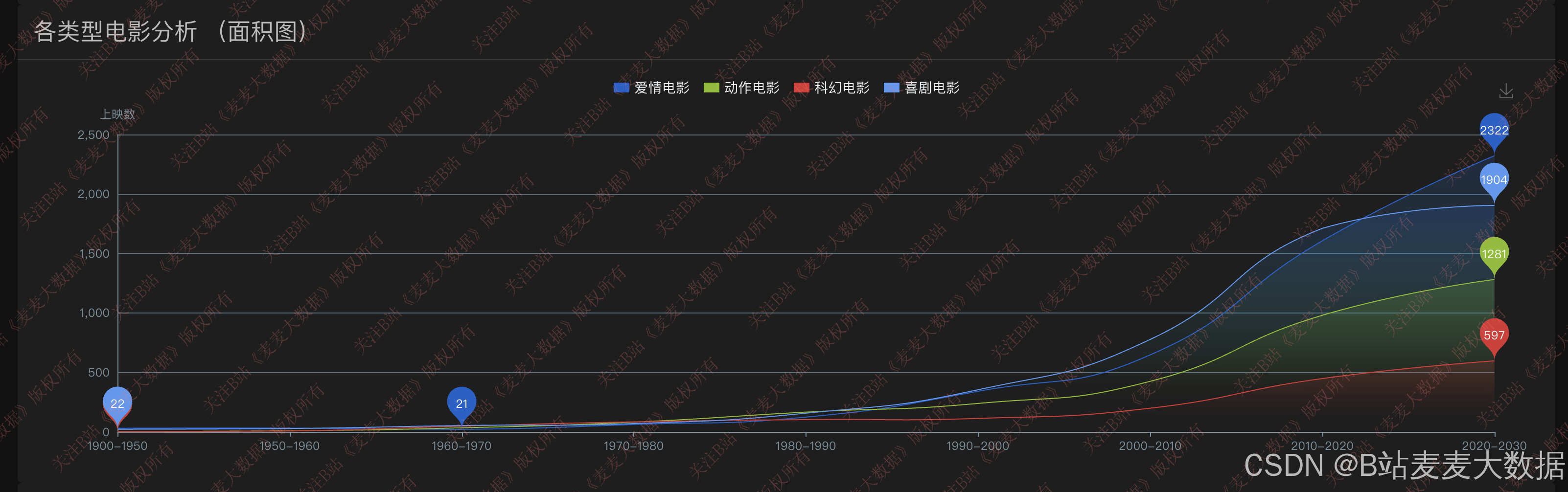
数据可视化模块基于 ECharts 库实现,提供多维度、交互式的数据分析视图:
- 电影上映统计:按年份区间展示电影上映数量柱状图,反映行业热度趋势;
- 类型电影上映分析:展示不同电影类型在各年份的发行量,使用面积图揭示类型变迁;
- 数据大屏:动态数据看板,支持多指标联动;
- 词云分析:对电影简介进行分词后生成词云,直观展示高频主题词;
- 箱线图分析:展示不同电影类型的评分分布(均值、中位数、四分位、离群值),揭示评分特征。
该模块不仅服务于普通用户,也为电影研究者和从业者提供决策支持。
3.6 用户管理(管理员功能)
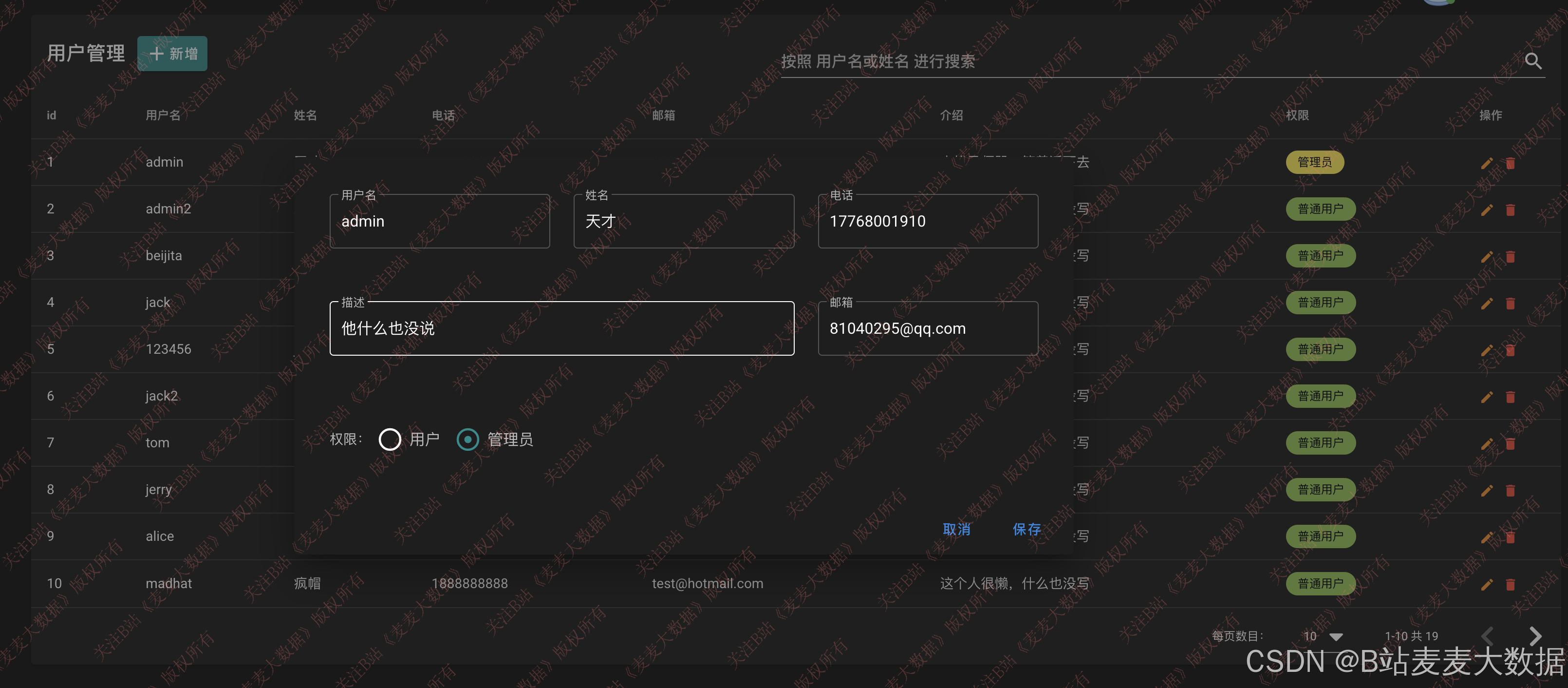
管理员登录后可进入用户管理页面,实现:
- 用户信息的增删改查;
- 用户角色(普通用户/管理员)权限分配;
- 查看用户行为日志(可选);
- 强制修改密码或注销账号。
3.7 电影管理(管理员功能)

管理员可对电影信息进行管理:
- 添加新电影(含名称、类型、导演、演员、简介等);
- 修改或删除已有电影信息;
- 设置电影状态(如"已上映"、"下映"、"未上映");
- 支持批量导入或导出数据(支持CSV)。
3.8 个人设置
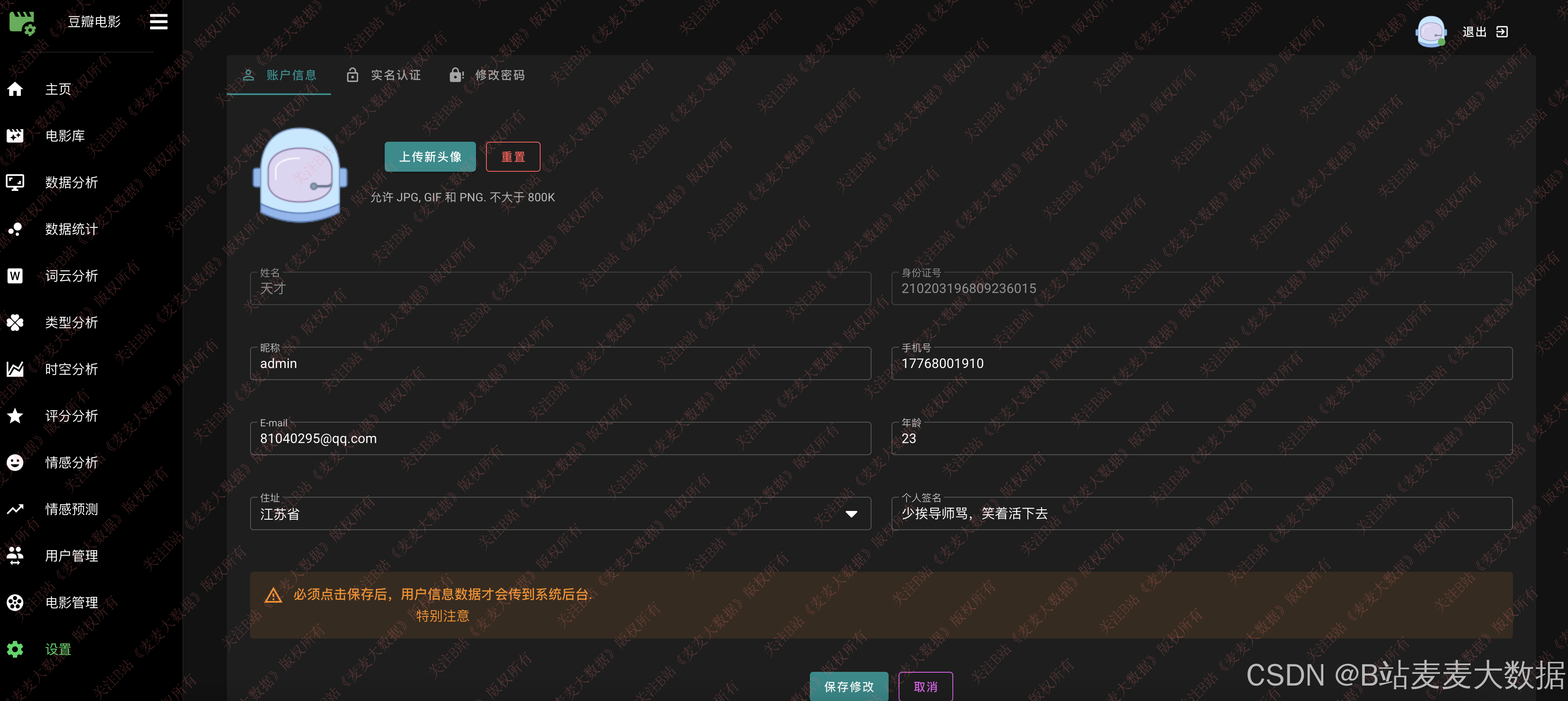
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
4 程序核心算法代码
4.1 代码说明
代码实现主要包括三个部分:
- BERT情感分析模型:使用微调后的BERT模型对评论文本进行三分类。
- 数据爬取与清洗:通过Scrapy爬虫获取豆瓣评论数据并清洗存储至MySQL。
- 词云生成与数据分析 :基于Python的
jieba分词库和wordcloud库生成词云图。
4.2 流程图
(此处插入流程图说明)
- 数据采集:Scrapy爬虫 → 获取电影详情与评论数据 → 清洗 → 存入MySQL。
- 情感分析:加载BERT模型 → 输入清洗后的评论文本 → 预测情感类别与概率 → 存储分析结果。
- 推荐计算:基于用户行为构建用户-电影矩阵 → 计算UserCF/ItemCF相似度 → 生成推荐列表。
- 可视化分析:从MySQL读取数据 → 调用ECharts绘制多图表 → 前端渲染。
4.3 代码实例
4.3.1 BERT情感分析模型(Python)
python
# config.py
class Config:
model_name = 'bert-base-chinese'
num_classes = 3 # 三分类:消极、中性、积极
model_save_path = './models/bert_sentiment_model.pth'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
batch_size = 16
max_pad_length = 128
learning_rate = 2e-5
# model.py
import torch
import torch.nn as nn
from transformers import BertModel, BertConfig
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.model_name)
self.dropout = nn.Dropout(0.5)
self.classifier = nn.Linear(self.bert.config.hidden_size, config.num_classes)
def forward(self, x):
_, pooled_output = self.bert(x[0], x[1], return_dict=False)
pooled_output = self.dropout(pooled_output)
output = self.classifier(pooled_output)
return torch.softmax(output, dim=1)
python
# predict.py
import torch
from model import Model
from datasets import DatasetIterater
import numpy as np
def clean(text):
# 去除网址、合并空格等
import re
text = re.sub(r'http://\S+|https://\S+', '', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
def load_dataset(texts, labels=None):
# 将文本转化为模型输入格式
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(config.model_name)
encoded = [tokenizer(text, max_length=128, truncation=True, padding='max_length') for text in texts]
input_ids = torch.tensor([item['input_ids'] for item in encoded])
attention_mask = torch.tensor([item['attention_mask'] for item in encoded])
return DatasetIterater(input_ids, attention_mask)
def final_predict(text):
config = Config()
model = Model(config)
model.load_state_dict(torch.load(config.model_save_path))
model.eval()
text = clean(text)
dataset = load_dataset([text])
with torch.no_grad():
outputs = model(dataset)
prediction = torch.argmax(outputs, dim=1).item()
prob = torch.softmax(outputs, dim=1).tolist()[0]
return prediction, prob4.3.2 数据库查询(SQL)
sql
-- 查询电影名称与对应的情感评分
SELECT m.name, AVG(s.sentiment_score) AS avg_sentiment
FROM movies m
JOIN sentiments s ON m.douban_id = s.douban_id
WHERE m.status = '上映'
GROUP BY m.name
ORDER BY avg_sentiment DESC;
sql
-- 词云分析:提取电影简介的关键词
SELECT content FROM movie_briefs WHERE content IS NOT NULL;4.3.3 Scrapy爬虫(Python)
python
# spiders/douban_spider.py
import scrapy
from scrapy.loader import ItemLoader
from movie.items import MovieItem, CommentItem
import time
import random
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
for sel in response.css('div.item'):
item = ItemLoader(item=MovieItem(), selector=sel)
item.add_css('title', 'a::text')
item.add_css('rating', 'spanrating::text')
item.add_css('genre', 'p:nth-child(2)::text')
yield item.load_item()
next_page = response.css('a.next::attr(href)').get()
if next_page:
time.sleep(random.uniform(2, 5))
yield response.follow(next_page, self.parse)文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,私信获取! 麦麦大数据
编号: F060