1、VLLM的学习
2. 整体架构的介绍:
csrc的学习:
主要包含CUDA内核的优化
数据流向、测试实例:
Tests主要包含一些模块实例的演示:

所支持的模型:
我们先看Pytorch库中模型的算子:
可以发现Linear层用的都是Pytorch内置的权重torch.nn.Linear;
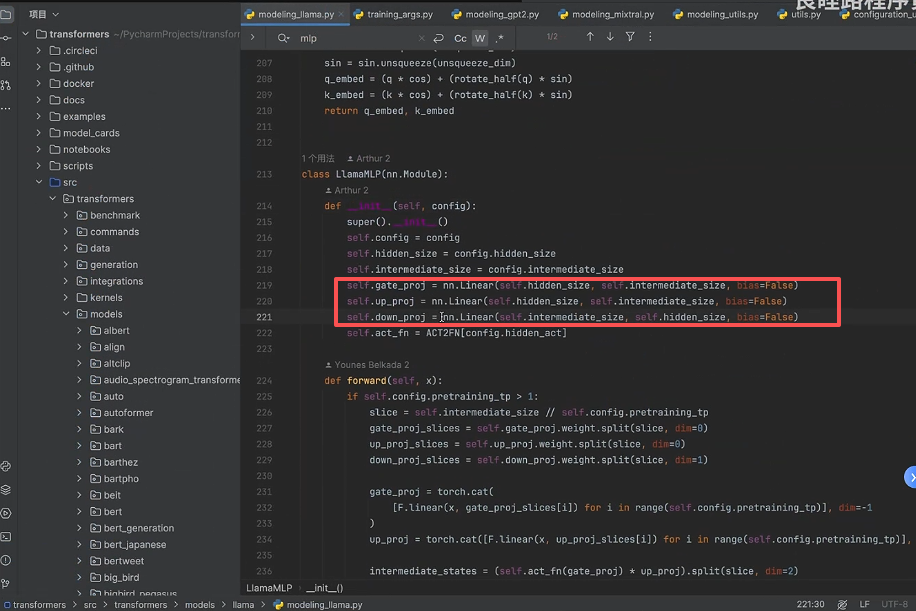
然后VLLM会将这些权重转换为VLLM内置自己定义的权重
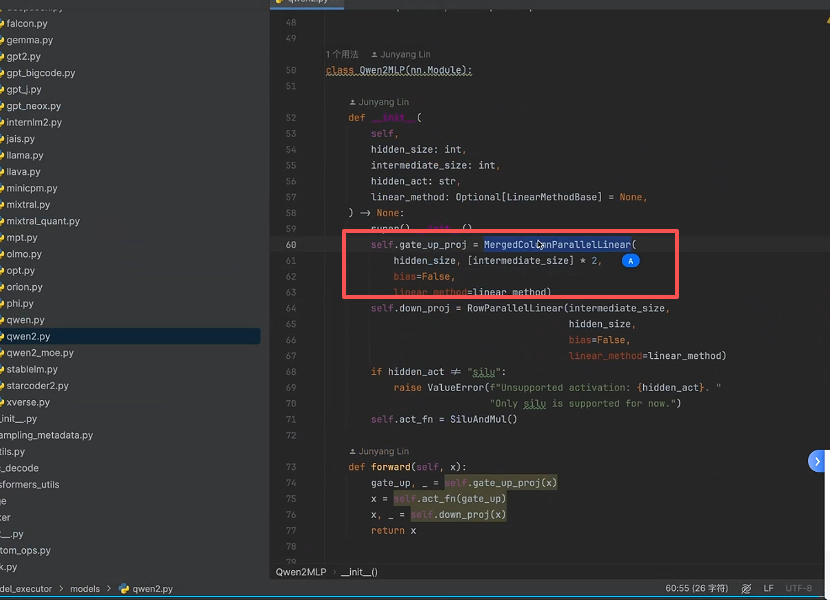
3. 源码解读---vllm 实例:
1. 首先我们看下VLLM的实例代码
VLLMs目前支持同步离线推理和异步离线推理:
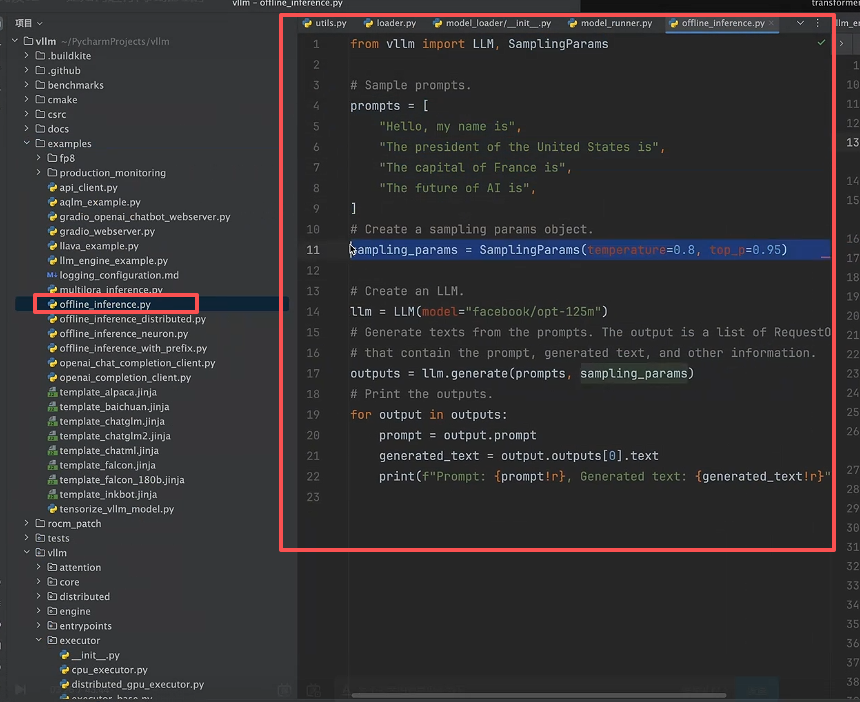
2. 从代码层面明确 vllm 的区别:
与HuggingFace上的实例类似,参考连接如下:
https://blog.csdn.net/weixin_57128596/article/details/154795289?spm=1001.2014.3001.5501
以下是 Huggingface 官方的方式:加载模型->编码输入->推理->解码输出
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 模型名称(Hugging Face 上的 Qwen2-7B 模型)
model_name = "Qwen/Qwen2-7B"
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True, # Qwen 模型需要信任远程代码
padding_side="right" # 右填充(符合中文习惯)
)
# 设置 pad_token(Qwen 模型默认没有 pad_token,需要手动设置)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 方式2:4-bit 量化加载(仅需 ≥8GB 显存,推荐显存不足时使用)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_4bit=True, # 启用 4-bit 量化
bnb_4bit_quant_type="nf4", # 量化
bnb_4bit_compute_dtype=torch.float16
)
# 3. 推理函数(封装成可复用的函数)
def qwen2_inference(prompt, max_new_tokens=512, temperature=0.7):
"""
Qwen2-7B 推理函数
:param prompt: 输入提示词
:param max_new_tokens: 生成的最大新token数
:param temperature: 生成温度(越高越随机)
:return: 生成的文本
"""
# 编码输入
inputs = tokenizer(
prompt,
return_tensors="pt",
padding=True,
truncation=True,
max_length=2048
).to(model.device) # 将输入移到模型所在设备
# 生成回复
with torch.no_grad(): # 禁用梯度计算,节省显存
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=True, # 采样生成(非贪心)
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 解码输出(只保留生成的部分,去掉输入)
response = tokenizer.decode(
outputs[0][len(inputs["input_ids"][0]):],
skip_special_tokens=True
)
return response
# 4. 测试推理
if __name__ == "__main__":
# 测试提示词
test_prompt = "请解释一下什么是大语言模型,并用简单的例子说明"
# 执行推理
print("输入提示:", test_prompt)
print("="*50)
response = qwen2_inference(test_prompt)
print("模型回复:", response)可以看到 VLLM 直接通过内置的 vllm 库加载模型权重,而分词器本身还是用的 Transformers 的库 AutoTokenizer 加载,目的是对输入分词然后设置Template。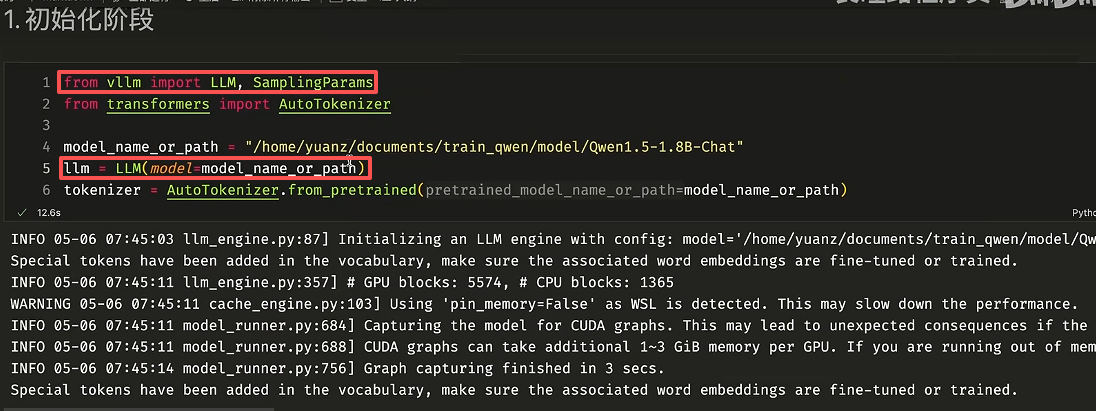
然后直接调用内置的 generate 函数即可。
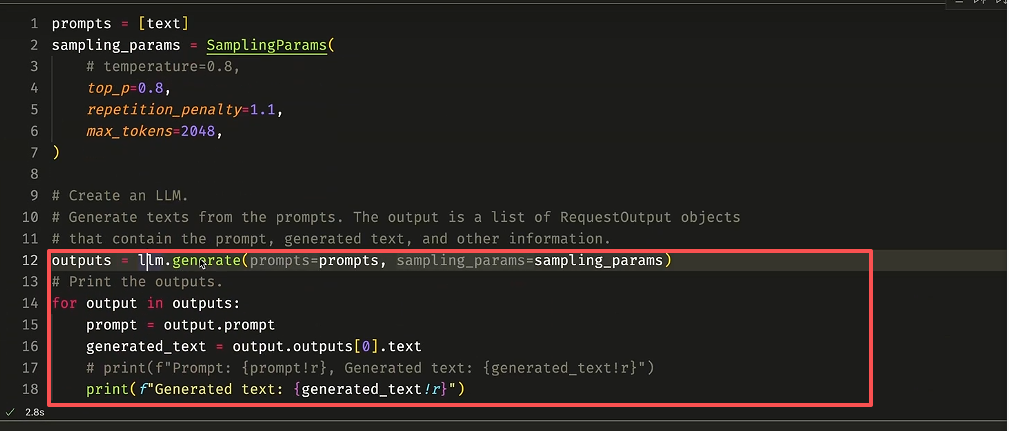
结论: vllm 主要在 llm 初始化阶段以及推理阶段做了更改。
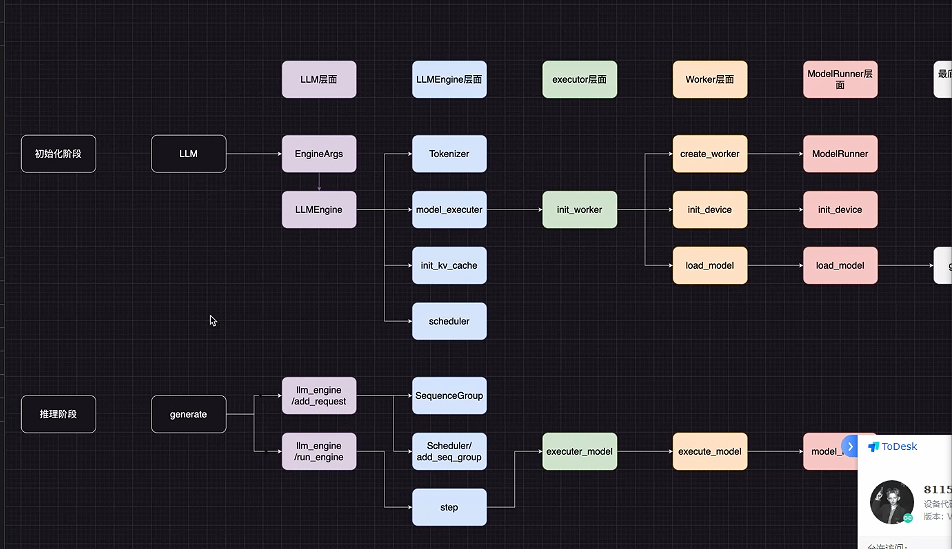
4. 源码解读-llm的初始化:
输入:
- 提示词和随机采样参数(必须)
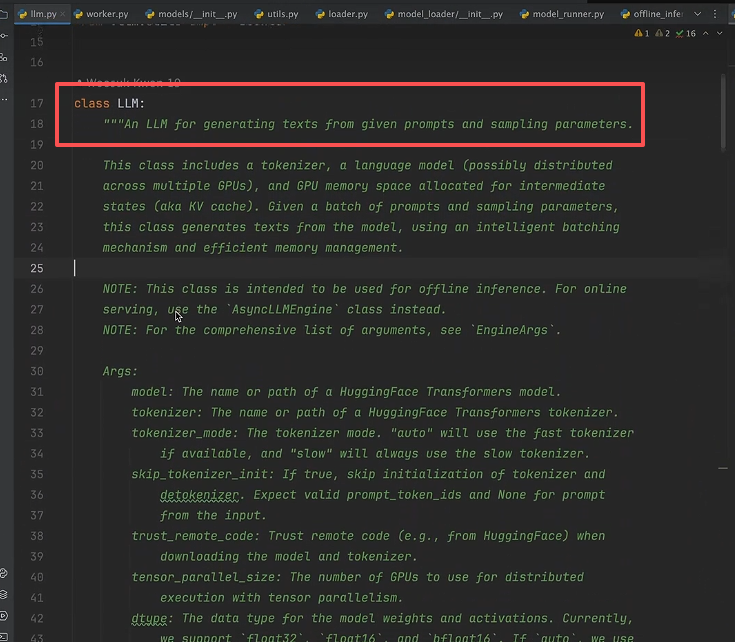
- 其余参数;

参数转换类---EngineArgs:
将传入的参数通过 EngineArgs 进行构造,得到实例化参数 engine_args 。
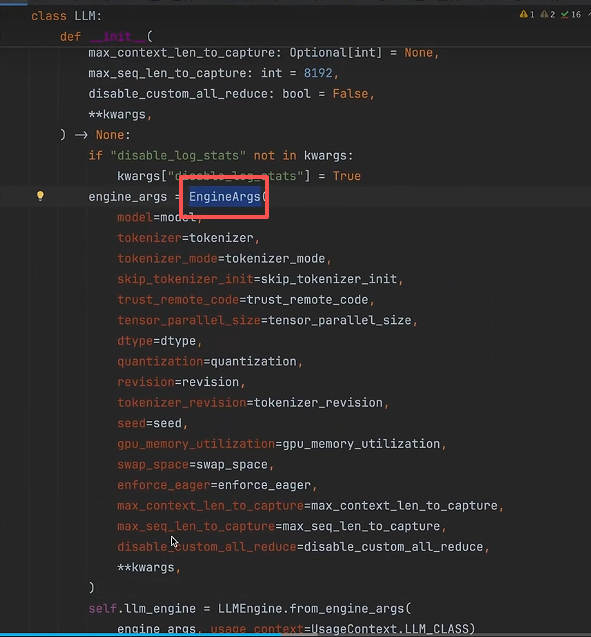
原因是:模型权重初始化的类 LLMEngine 所需的参数包含模型配置、缓存配置、时间调度机制、Lora、Token采样配置、是否是视觉模型等等(这些参数在后续执行器的初始化中需要用到),如下图所示。
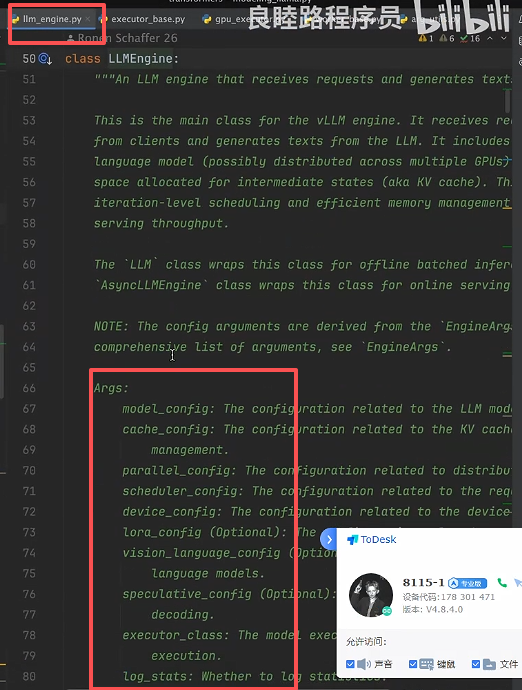
初始化的几个包如下所示:
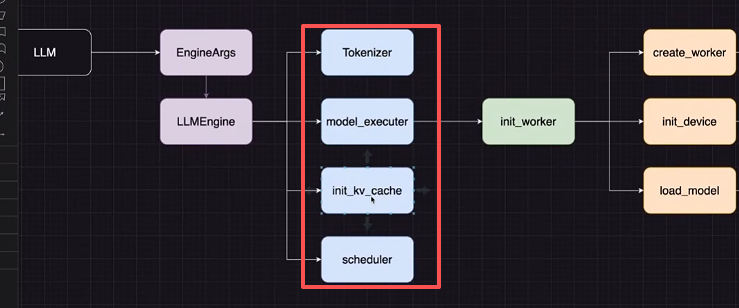
- Tokenizer: 分词器,将文本转换为数字 ID,添加 Template。
- Executor: 基类、单卡GPU、CPU、xxGPU的执行器,如下图所示。
- init_kv_cache: 缓存优化,涉及 PageAttention。
- Scheduler: 时间调度器,用于批量处理。
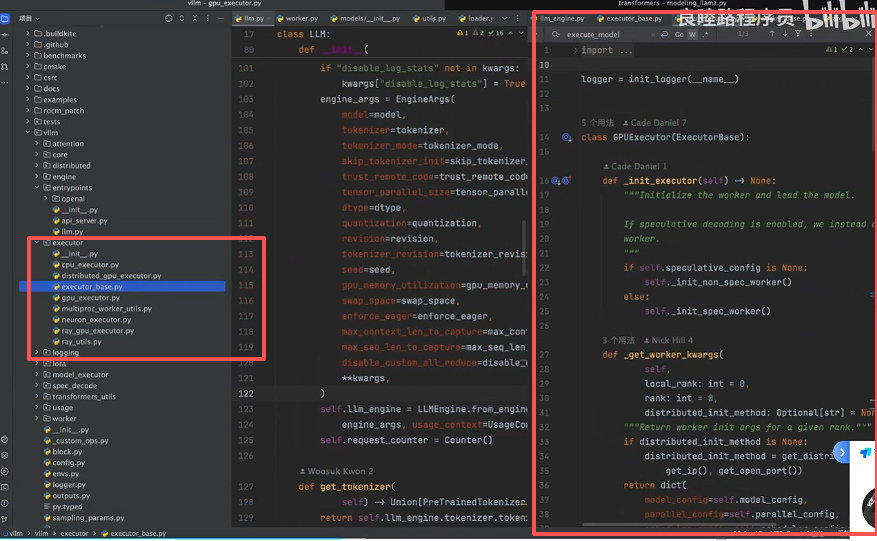
5. 初始化以 GPUExcutor 为例
第一步: 可以看到 llm 初始化的时候需要通过 executor_class() 导入执行器,所需参数包含模型配置、缓存配置、时间调度机制、Lora、Token采样配置等等。
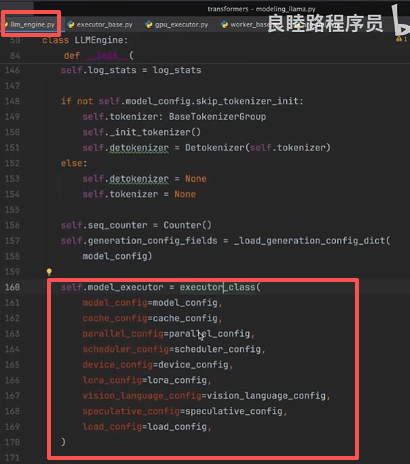
第二步: Executor 主要包含三种 worker 的初始化形式:
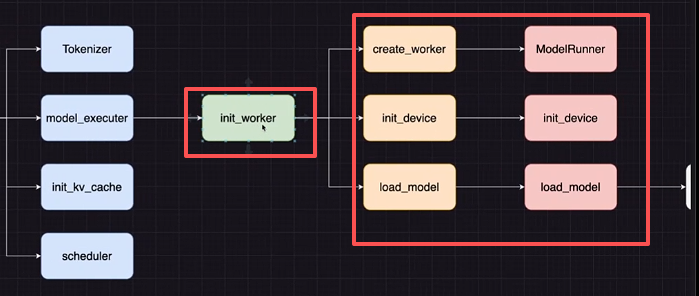
以 GPUExecutor 代码为例:
- 创建worker;
- 设备worker;
- 模型加载worker;
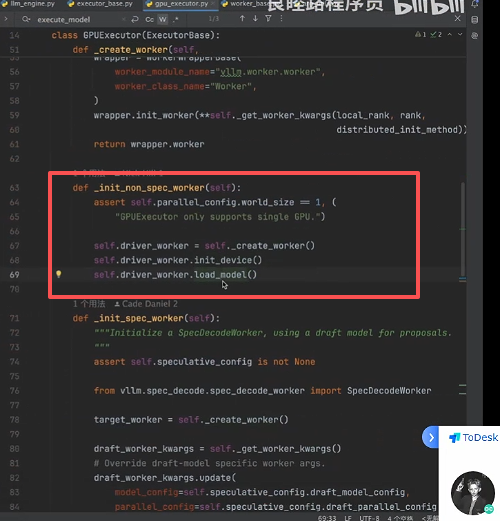
首先是创建worker,create_worker:
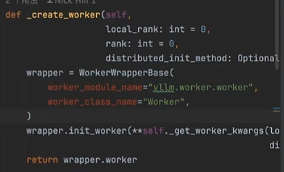
可以发现 Worker 的创建是通过文件路径初始化的:
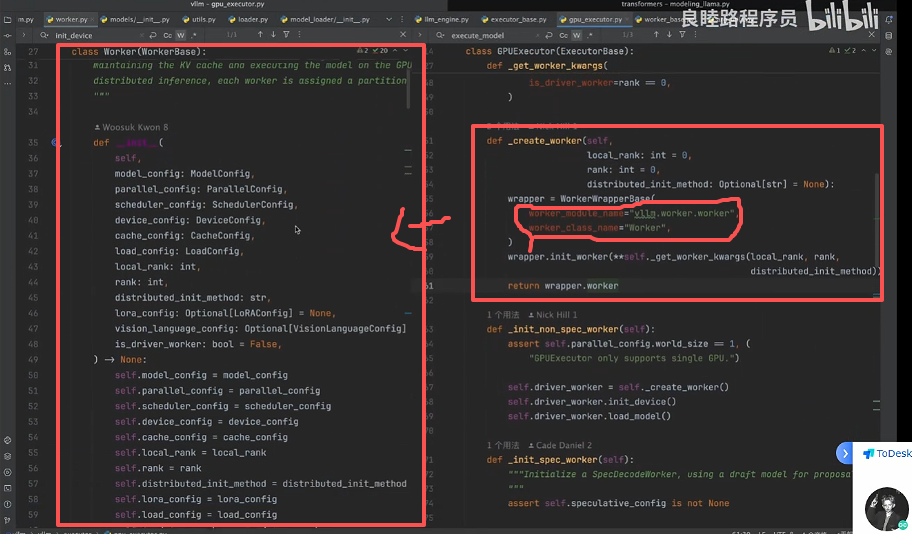
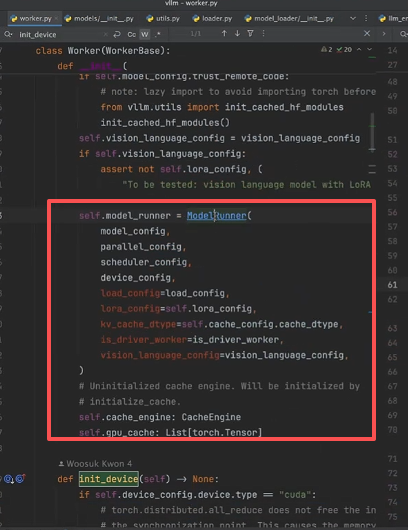
可以发现 Worker.py 中又加载了 ModelRunner ,主要用了加载配置、Lora配置、Kv-Cache的配置
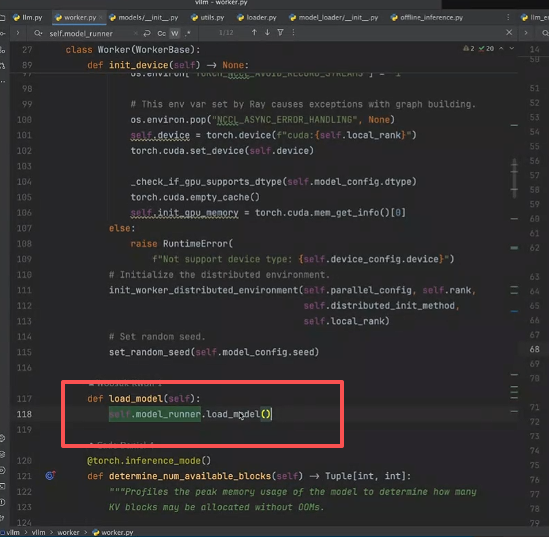
然后 load_model中也用了 modelRunner 类,主要用ModelRunner完成模型的加载和初始化:
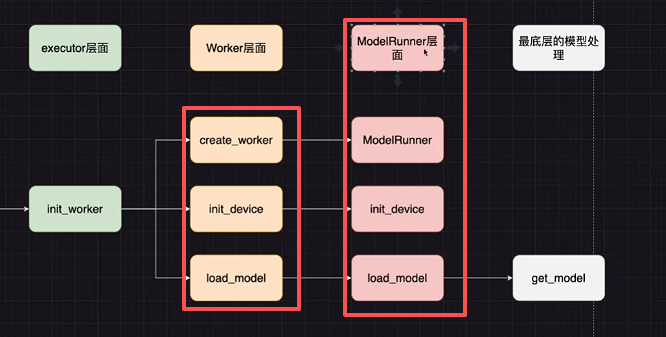
ModelRunner层面:
可以发现 ModelRunner 是整个执行流程最底层的层面。
可以发现ModelRunner中的 load_model() 函数,主要包括模型权重加载和转换:
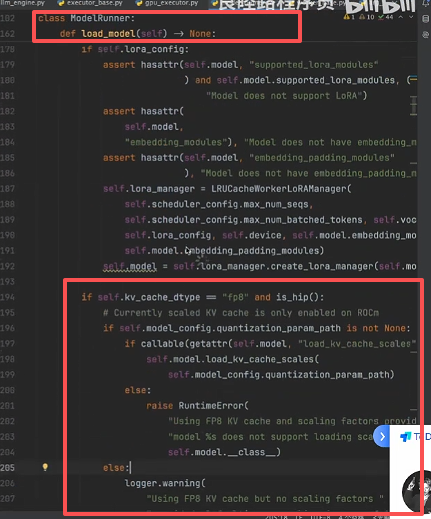
其中模型权重的加载主要在 get_model() 函数中,如下图所示:
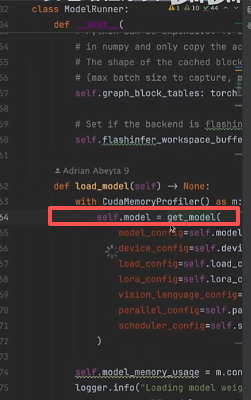
点进 get_model()函数中可以发现,主要先通过 get_model_loader()得到加载器:
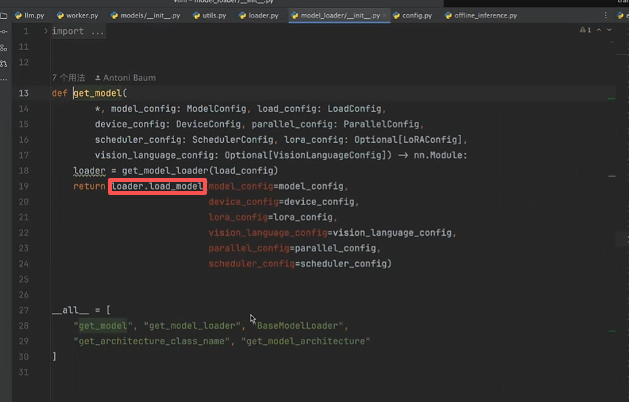
可以发现 loader有几种初始化的方法,如下图所示:
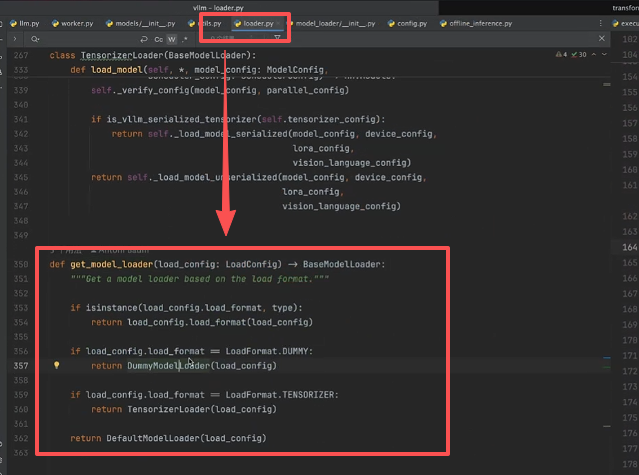
我们以 DummyModelLoader 为例,发现模型权重加载主要依赖 initialize_model 函数,如下图所示:
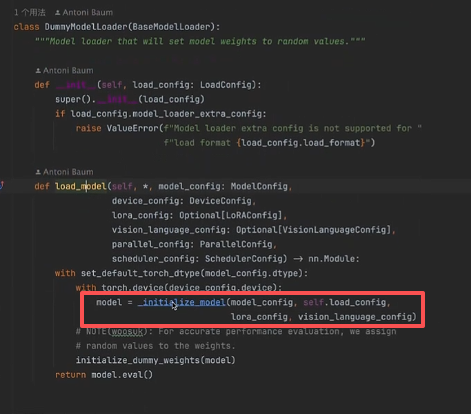
点入 initialize_model()函数可以发现,可以获取模型的架构和模型的注册器,因此能够找到加载的模型:
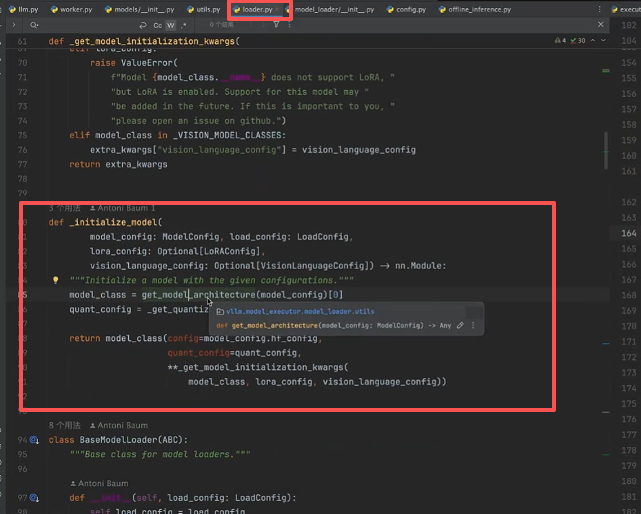
点入 get_model_architecture() 函数可以发现,主要用了模型注册器,自动检查模型的映射:
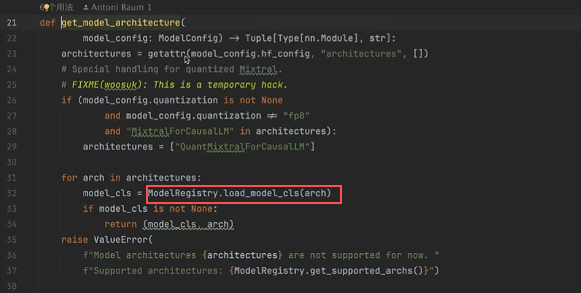
其中模型注册器 ModelRegistery 会自动检查模型的映射,如下两张图所示:
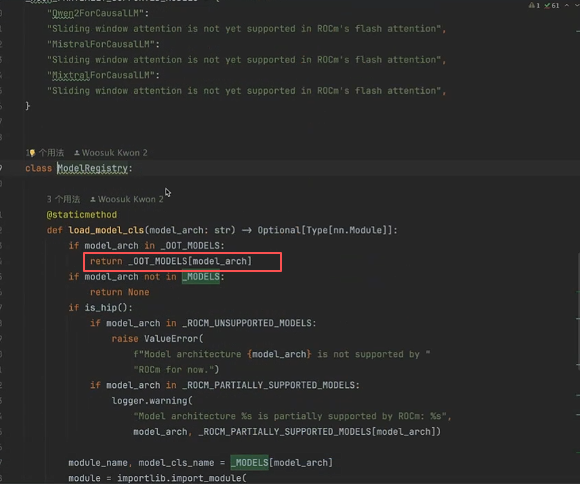
找到映射后会自动跳转对应的模型类:
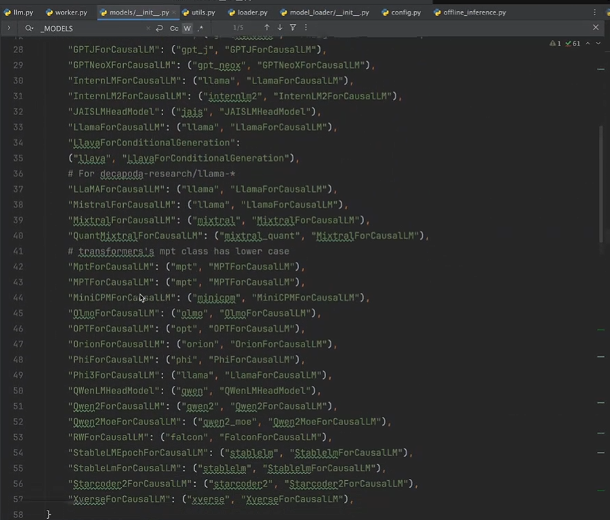
跳转到以下模型类: