为了尽量提高本地部署的小参量打折精度LLM获取数据时的幻觉问题,最近研究了下MCP。stdio和streamable-http方式都尝试了一下,在我的测试场景下都可行。鉴于streamable-http方式部署更为灵活,因此也尝试了一下用树莓派5充当streamable-http类型的MCP服务器。其实方法是通用的,跨平台完全可用。
我的测试场景是数据库内存放一套员工信息,模拟我知道某人姓名或前几个字,希望查询到他的工号。
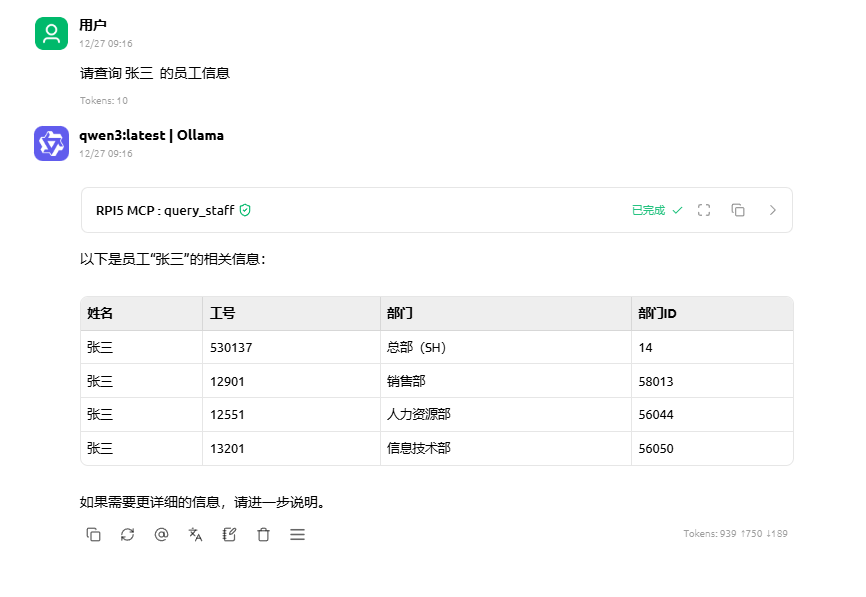
跑通后在Cherry Studio中实际效果如下:
代码编写也很简单。首先还是环境准备,先创建一个名为mcp的环境:
bash
source ~/anaconda3/bin/activate
conda create -n mcp python=3.11
conda activate mcp然后安装fastmcp主框架。顺带着把数据库连接库也一起装了(我的计划里mssql和mysql都会用到):
python
pip install fastmcp pymssql pymysql然后写python(这里只用到了mysql。调用mssql的代码整体类似,个别细节上略有不同),保存为server.py:
python
from fastmcp import FastMCP
import pymysql
import json
from decimal import Decimal
from datetime import datetime, date
from pymysql.cursors import DictCursor
# ---------- 通用序列化补丁 ----------
def json_default(obj):
if isinstance(obj, (datetime, date)):
return obj.strftime('%Y-%m-%d %H:%M:%S')[:19]
if isinstance(obj, Decimal):
return float(obj)
raise TypeError(f'Unsupported type: {type(obj)}')
mcp = FastMCP("Demo") # 1. 实例化
@mcp.tool() # 2. 注册工具
def query_staff(emp_name: str) -> str:
"""
根据提供的姓名查询员工基本信息。以二维表格方式呈现。
Query basic employee infomation by employee name.
:param emp_name: 姓名。
"""
rows = []
# 这里去数据库查
conn = pymysql.connect(
host="你的mysql服务器",
user="你的用户名",
password="你的密码",
database="你的数据库",
charset="utf8mb4",
cursorclass=DictCursor
)
sql = """
select * from Sheet1 where staff_name like %s
"""
try:
with conn.cursor() as cur:
cur.execute(sql, (emp_name + "%",))
rows = cur.fetchall() # 一次性拿列表
except pymysql.DatabaseError as e: # 数据库层错误
print('数据库报错:', e)
except Exception as e: # 其他所有异常
print('其他异常:', e)
finally:
conn.close()
return json.dumps(rows, ensure_ascii=False, default=json_default)
if __name__ == "__main__":
# 3. 以 streamable-http 方式监听 8000 端口
mcp.run(transport="streamable-http", host="0.0.0.0", port=8000, path="/mcp")需要注意的是:
1、@mcp.tool() 是第一个关键。我的这个小示例里仅提供了一个工具(query_staff),但实际上可以继续添加其他工具 ,只要在函数前也加上@mcp.tool()。
2、注意函数体内的这段注释,
"""
根据提供的姓名查询员工基本信息。以二维表格方式呈现。
Query basic employee infomation by employee name.
:param emp_name: 姓名。
"""
看着是"注释",但实际上有它极为重要的用途,回答了一个很现实的问题:LLM怎么知道什么时候去触发调用MCP工具,又怎么知道那个词其实是参数?
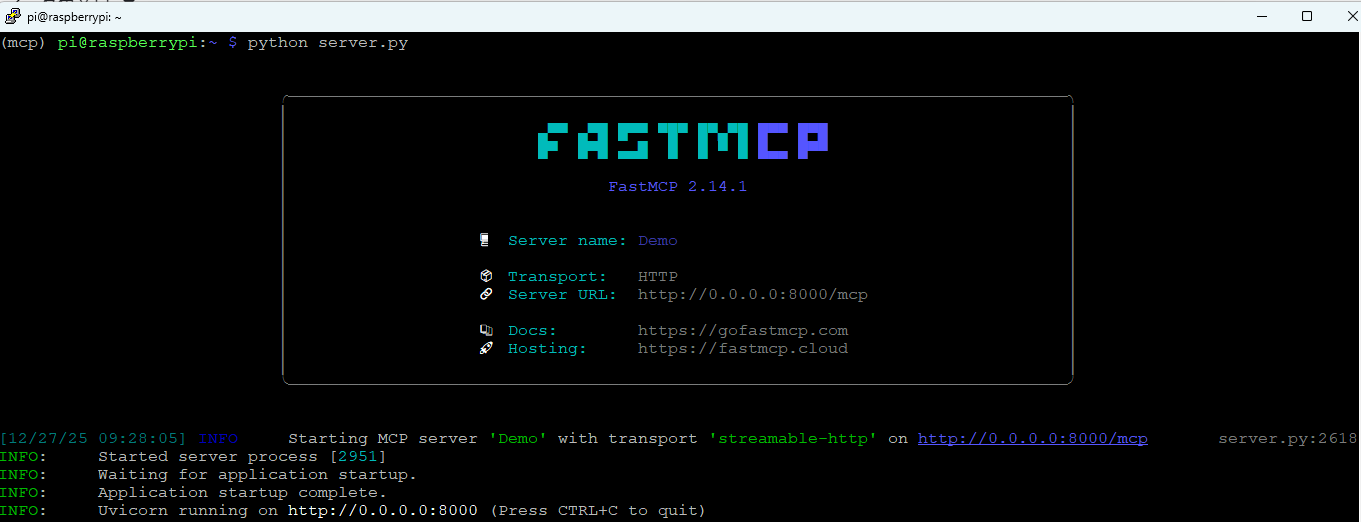
运行就一句话,python server.py。一切正常的话看起来应该这样:
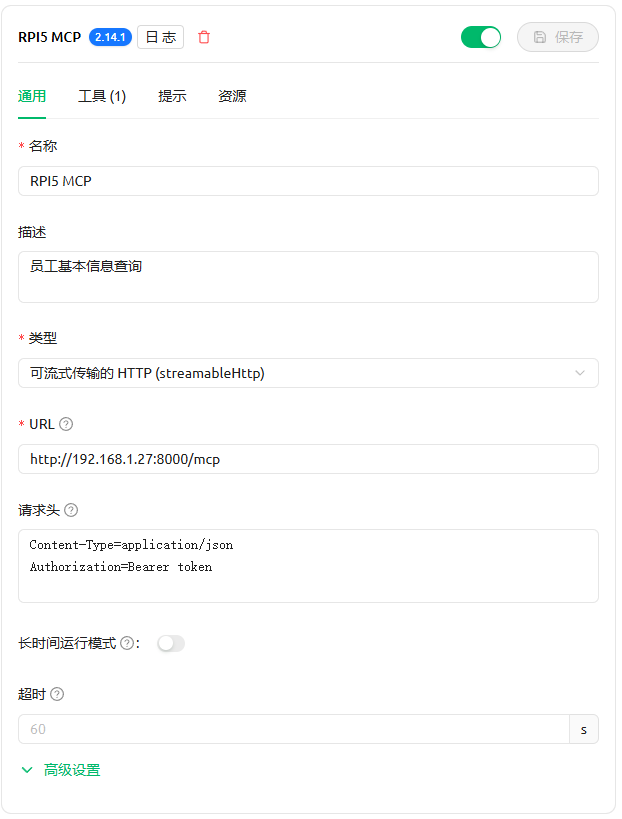
Cherry Studio中需要配置该MCP,参考信息如下。IP地址改成你实际的。以目前的测试情况看请求头并不能省略:
最后想说的是,给LLM会话工具配置mcp也不是万能的。小参量LLM的幻觉表现之一就是它会不调用工具直接编个结果扔给你。因此如果在意数据准确性的话,建议每次都要看下答复上方是否出现了成功调用工具的记录。