一、什么是ICL
ICL:In-context Learning(上下文学习),其核心是大语言模型(LLM)的一种"特殊能"------无需更新模型参数(不用Fine-tune),仅通过"任务描述+少量示例"的上下文提示,就能完成任务。
从一个游戏例子入手:
- 任务规则:输入仅含 a/b 的序列 → a 对应欧洲国家,b 对应亚洲国家;
- 示例:输入 "abab" → 输出 "England(欧)、China(亚)、Germany(欧)、Japan(亚)";
- 模型表现:输入 "bbaa" → 模型输出 "India(亚)、Turkey(亚)、France(欧)、Italy(欧)",且能解释 "土耳其 95% 领土在亚洲"(利用自身知识补全逻辑)。
关键结论(ICL 的核心定义):
ICL 是大语言模型的无参数更新学习能力------ 不用像传统模型那样通过梯度下降更新权重(W 和 b),仅靠 "上下文里的任务描述 + 示例",就能理解任务并生成结果。
对比熟悉的"传统学习":
python
# 传统学习的核心流程(你肯定懂)
def model(x): return W*X + b # 初始化权重
for epoch in range(n):
for batch_x, batch_y in dataset:
y_pred = model(batch_x)
loss = 损失函数(y_pred, batch_y)
grad = 反向传播(loss)
W = W - lr*grad # 关键:更新权重(学习的核心)而 ICL没有 "更新权重" 这一步------ 模型的 "学习" 完全在推理时完成,靠上下文提示激活自身预训练的知识,相当于 "看例子就会做新题"。
二、ICL 的分类:Zero-shot / One-shot / Few-shot
ICL 的三种形式,核心区别是 "是否给示例、给多少示例",且均无参数更新:
| 类型 | 定义 | 例子(翻译任务) |
|---|---|---|
| Zero-shot | 只给任务描述,不给任何示例 | 提示:"Translate English to French: cheese=>" → 模型直接输出法语翻译 |
| One-shot | 任务描述 + 1 个示例 | 提示:"Translate English to French: sea otter=>loutre de mer; cheese=>" |
| Few-shot | 任务描述 + 多个示例(通常 3-5 个) | 提示:"Translate English to French: sea otter=>loutre de mer; peppermint=>menthe poivree; cheese=>" |
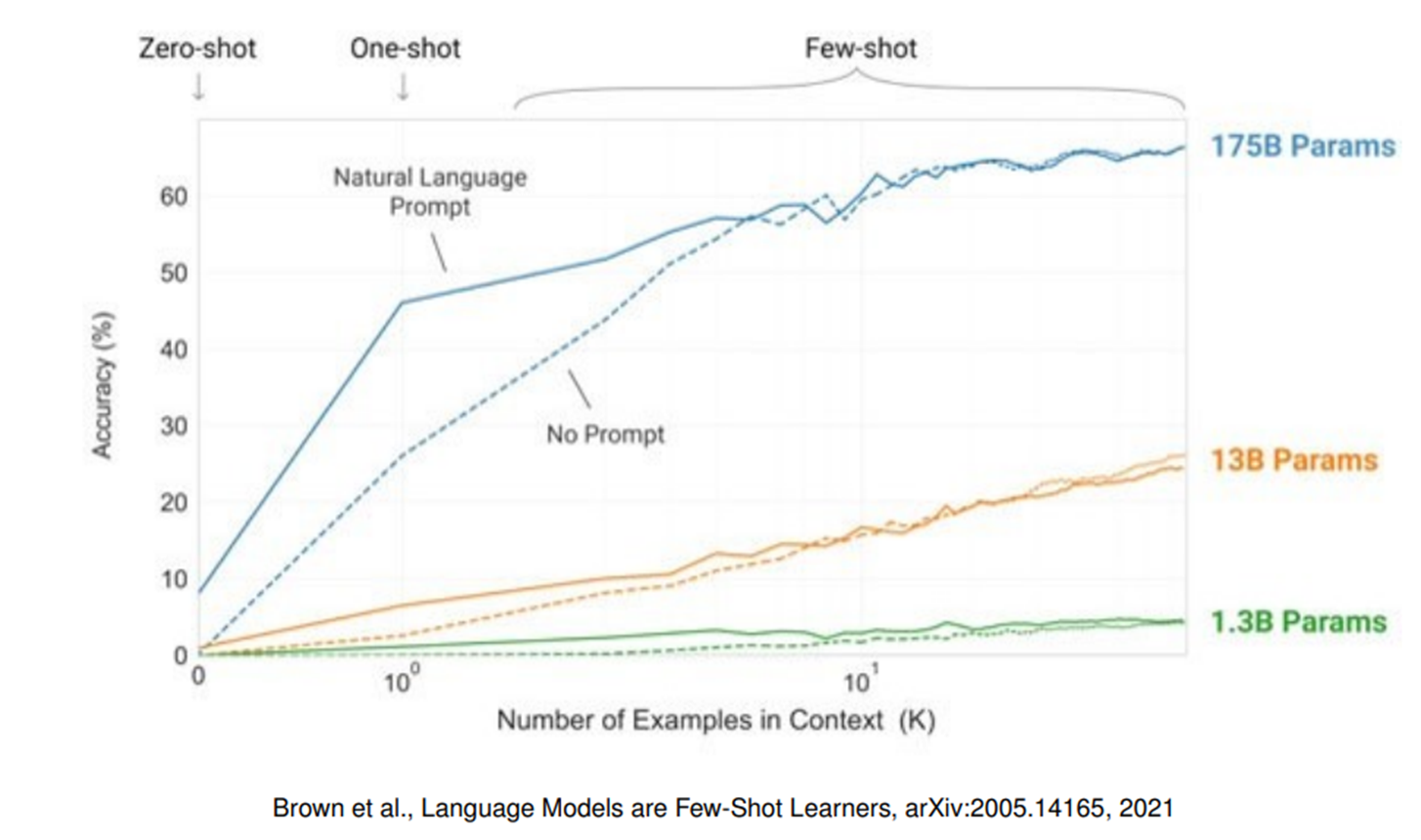
关键图表解读:
- 模型规模越大(如 175B 参数),ICL 效果越好;
- 多数情况下:Few-shot > One-shot > Zero-shot(给示例能大幅提升准确率);
- 例外:后面会讲 "精巧的 Prompt 设计,可能让 Zero-shot 超过 Few-shot"。
三、ICL 的核心优势:为什么它能挑战 Fine-tune?
1.流程对比
| 传统做法(Fine-tune 为核心) | ICL 做法 |
|---|---|
| 1. 定义任务 → 2. 建立标注规范 → 3. 标注人员学习规范 → 4. 人工标注数据 → 5. 审核标注 → 6. 用标注数据训练模型 → 7. 验证效果 | 1. 定义任务 → 2. 写 Prompt(任务描述 + 少量示例) → 3. 模型直接预测 |
2.核心优势总结
-
零标注成本:不用人工标注数据(深度学习中最耗时的环节);
-
快速落地:改任务只需要改 Prompt,不用重新训练模型;
-
泛化性强:一个大模型靠不同 Prompt,能适配翻译、分类、数学推理等多种任务;
-
终极潜力:PPT 提到 "如果 ICL 完全成熟,可能终结 Fine-tune 范式"------ 因为 Fine-tune 的核心痛点(标注成本高、任务固定、迭代慢),ICL 都能解决。
四、ICL的关键研究:反直觉现象(重点掌握)
1.China-of-Thought(CoT,思维链):让ICL会"推理"
CoT是ICL的重要延伸------通过Prompt引导模型"一步步思考",而不是直接输出答案,专门解决数学题推理等复杂任务。
-
对比示例):
-
普通 Prompt(直接输出答案):输入问题 → 模型输出 "27"(错误);
-
CoT Prompt(引导分步推理):输入问题 + "Let's think step by step" → 模型输出 "23-20=3,3+6=9"(正确)。
-
-
关键:CoT 本质是 "Prompt 格式优化",属于 ICL 的一种使用技巧,不用改模型,仅靠文字引导就能提升推理准确率。
2. Fine-tune 会 "伤害" ICL 能力
这是重要结论,和熟悉的 Fine-tune 逻辑相反:
-
现象:模型经过 Fine-tune 后,在特定任务上表现更好,但会 "忘记" ICL 能力 ------ 面对未训练过的新任务,即使给示例,ICL 效果也会大幅下降(甚至几步 Fine-tune 就失效);
-
原因:Fine-tune 让模型 "专业化"(权重适配特定任务),但失去了预训练时的 "泛化灵活性",而 ICL 依赖的是预训练模型的全局知识和上下文理解能力。
3. 示例数量≠效果:精巧 Prompt 比多示例更重要
-
反直觉现象:有时 One-shot 效果比 Few-shot 差(PPT 提到 "简单冒号 Prompt 的 1-shot 不如 Zero-shot");
-
解决方案:优化 Prompt 格式,比如 "Master Translator" Prompt(用 "专业译者完美翻译" 这样的表述),比简单的 "French: XX → English: XX" 效果好得多;
-
魔法词(Magic Words):比如 Zero-shot-CoT 中的 "Let's think step by step",不用给示例,仅靠这一句话就能激活模型的推理能力。
4. 错误示例影响有限:ICL 有 "抗干扰性"
即使 Prompt 中混入 50% 的错误示例(比如 a 对应亚洲国家),ICL 的准确率也不会大幅下降 ------ 模型能自动过滤部分噪声,更倾向于学习示例中的 "规律" 而非单个错误。
5. ICL 能 "压倒" 模型的先验知识
模型的预训练知识(先验)可能被 ICL 的上下文覆盖:
-
例子:之前的游戏是 "a = 欧洲、b = 亚洲",如果后续 Prompt 要求 "a = 数字 1、b = 数字 2",模型会遵守新规则,忽略之前的国家映射知识;
-
意义:ICL 的灵活性极强,能让模型快速适配 "与自身知识相反" 的新任务。
五、ICL 的成因:目前没有标准答案(两种假说)
学术界对 ICL 为什么能工作没有统一解释,仅有的两种核心假说:
1. Meta Learning(元学习)
-
核心观点:大模型在预训练时,已经学会了 "学习的方法"(元学习能力);
-
通俗理解:预训练过程相当于让模型 "学会如何快速学新东西",ICL 时,模型会在内部 "训练一个小型临时网络",来适配上下文里的任务(不用更新外部权重)。
2. Bayesian Inference(贝叶斯推理)
-
核心观点:模型将上下文里的示例视为 "观测数据",通过隐式贝叶斯推理,推断出任务的概率分布(比如 "a 对应欧洲" 的概率);
-
通俗理解:模型把示例当作 "证据",结合自身预训练的先验知识,计算出最可能的任务规则,然后生成结果。
六、ICL 的使用要点(实际用的时候重点关注)
总结了影响 ICL 效果的三大关键因素:
- 模型规模:ICL 是大模型的专属能力 ------ 参数越大(如 175B),ICL 效果越好;小模型(如 1.3B)的 ICL 能力很弱(图表可验证);
- 示例的数量和顺序 :
- 数量:多数任务 3-5 个示例足够(过多示例可能引入噪声);
- 顺序:示例的排列会影响效果(比如先易后难、同类示例集中,效果更好,具体需根据任务调整);
- Prompt 格式 :这是最易优化的点 ------
- 明确任务描述(避免模糊);
- 示例格式统一(比如 "输入→输出" 的固定结构);
- 复杂任务用 CoT(加 "一步步思考" 引导)。
七、Fine-tune vs ICL:到底该怎么选?(对比总结)
| 维度 | Fine-tune(你熟悉的) | In-Context Learning |
|---|---|---|
| 核心依赖 | 标注数据、训练资源(GPU、时间) | 大模型、高质量 Prompt(任务描述 + 示例) |
| 优点 | 1. 小模型也能出效果;2. 任务适配性强(专业) | 1. 零标注成本;2. 快速迭代(改 Prompt 即改任务);3. 泛化性强(适配多任务) |
| 缺点 | 1. 标注成本高、迭代慢;2. 任务固定(难适配新任务) | 1. 必须用大模型;2. 受上下文长度限制(比如输入示例太多会超出 token 限制) |
| 共同点 | 1. 以预训练模型为基座;2. 生成结果不完全可控;3. 缺乏可解释性 | 同上 |
适用场景建议:
-
用 Fine-tune:有大量标注数据、任务固定(如专属领域的文本分类)、只有小模型;
-
用 ICL:任务多变(如今天翻译、明天写代码)、无标注数据、需要快速落地(如临时做数据可视化)、有大模型资源。