目录
[(三)解决策略三:cache高可用 + 后端数据库限流](#(三)解决策略三:cache高可用 + 后端数据库限流)
干货分享,感谢您的阅读!
在高并发场景下,缓存作为前置查询机制,显著减轻了数据库的压力,提高了系统性能。然而,这也带来了缓存失效、增加回溯率等风险。常见的问题包括缓存穿透、缓存雪崩、热Key和大Key等。这些问题如果不加以处理,会影响系统的稳定性和性能。因此,采用有效的缓存策略,如缓存空结果、布隆过滤器、缓存过期时间随机化、多级缓存等,对于保障系统在高并发情况下的可靠性至关重要。本次我们将详细探讨缓存雪崩及其应对策略。
一、问题描述
缓存层挡在db层前面,抗住了非常多的流量,在分布式系统中,"everything will fails",缓存作为一种资源,当cache crash后,流量集中涌入下层数据库,称之为缓存雪崩。
造成这种问题通常有2种原因:
- 业务层面:大量的缓存key同时失效,失效请求全部回源到数据库,造成数据库压力过大崩溃。
- 系统层面:缓存服务宕机。
二、解决策略分析
(一)解决策略一:分散过期时间
业务层面的原因,主要是缓存key过期时间一致,造成同一时间,大量缓存key同时失效。针对这种问题的解决方案,主要是防止缓存在同一时间一起过期,如在设置的过期时间的基础上增加1-5分钟的随机值,使缓存失效时间比较均匀。通过这种方式,可以避免缓存key在同一时间失效,进而防止大量请求同时回溯到数据库。
java
import java.util.Random;
public class CacheManager {
private static final Random RANDOM = new Random();
// 设置缓存值并增加随机过期时间
public void setCache(String key, Object value, int baseExpirationTimeInSeconds) {
int randomOffset = RANDOM.nextInt(300); // 1-5分钟的随机值,单位是秒
int finalExpirationTime = baseExpirationTimeInSeconds + randomOffset;
// 这里假设使用的是某个缓存框架的set方法
cache.set(key, value, finalExpirationTime);
}
}(二)解决策略二:提前演练压测
系统在实际运行中可能会遇到各种性能瓶颈,提前演练和压测可以帮助发现这些瓶颈并进行优化。
在系统上线前,进行充分的压力测试和演练,找出系统的性能瓶颈,预估合适的系统存储和计算容量。根据压测结果,调整系统架构和配置,确保在高并发情况下系统能够稳定运行。
(三)解决策略三:cache高可用 + 后端数据库限流
- 采用双缓存热备份方案来进可能提升缓存资源的可用性
- 后端数据库限流(Hystrix),缓存层宕机,流量集中打到数据库,会再次让db崩溃。为保护这种情况下的db,在db层加入限流(Hystrix)
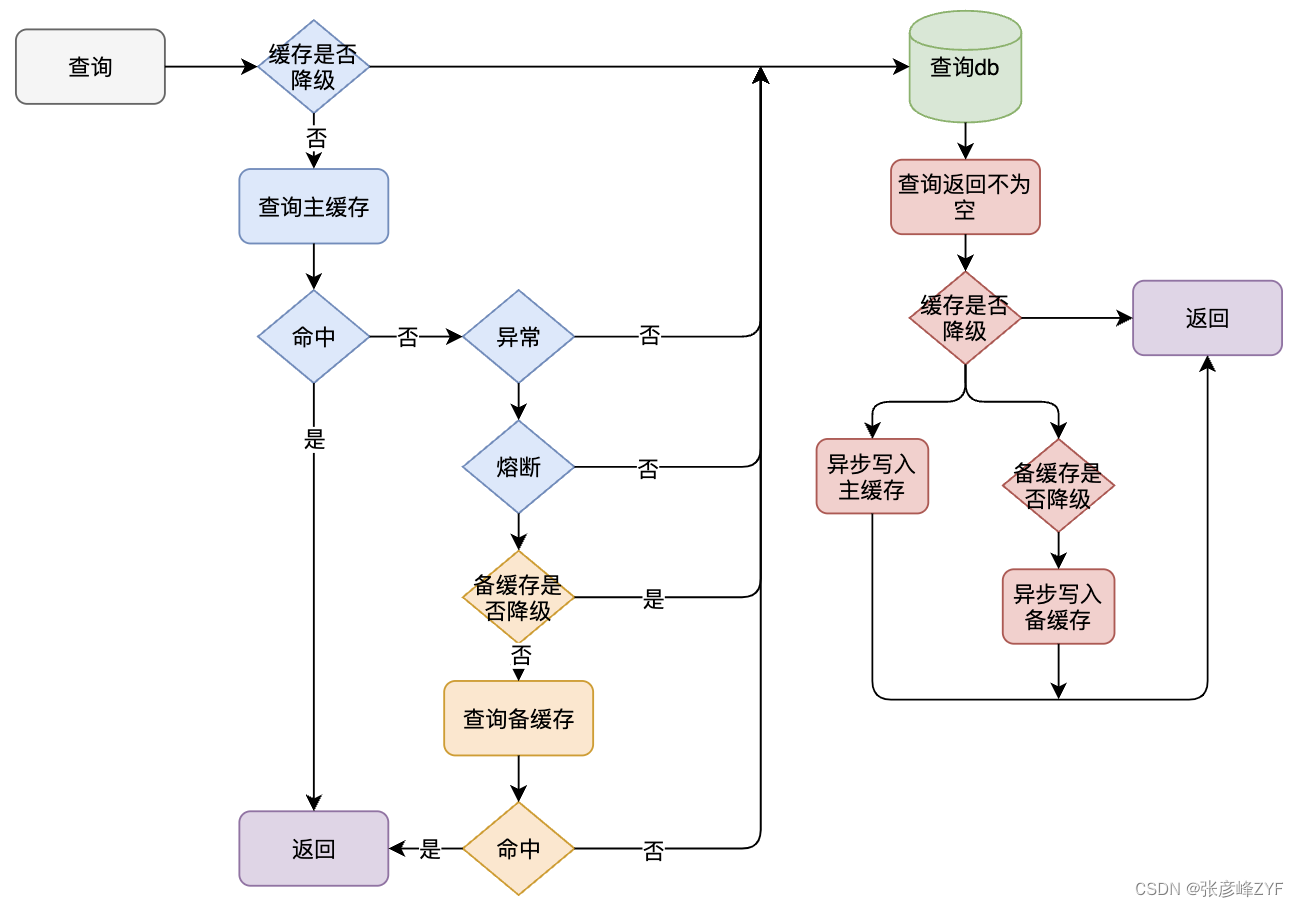
具体实现如下:
java
public class CacheSupplier {
@Qualifier(value = "tairCache")
@Autowired
private HACache tair;
@Qualifier(value = "squirrelCache")
@Autowired
private HACache squirrel;
@Autowired
private CacheConfig cacheConfig;
// 当前主备缓存引用,默认 master(squirrel) slave(celler)
private CachePair cachePair;
public CachePair getCachePair() {
if (!cacheConfig.isCacheOn()) {
return null;
}
if (cachePair != null && !cacheConfig.changed()) {
return cachePair;
}
return updateCachePair();
}
private synchronized CachePair updateCachePair() {
if (cachePair == null || cacheConfig.changed()) {
cacheConfig.getConfigLock().lock();
try {
cachePair = createCachePair();
cacheConfig.unchanged();
} finally {
cacheConfig.getConfigLock().unlock();
}
}
return cachePair;
}
private CachePair createCachePair() {
CachePair cp = new CachePair();
cp.setMaster(selectCache(cacheConfig.getMasterCache(), tair, squirrel));
if (cacheConfig.isSlaveOn()) {
cp.setSlave(selectCache(cacheConfig.getSlaveCache(), squirrel, tair));
}
return cp;
}
private HACache selectCache(String cacheName, HACache defaultCache1, HACache defaultCache2) {
if (CacheConfig.TAIR.equals(cacheName)) {
return tair;
} else if (CacheConfig.SQUIRREL.equals(cacheName)) {
return squirrel;
} else {
return defaultCache1 != null ? defaultCache1 : defaultCache2;
}
}
}三、总结
缓存雪崩作为高并发场景下的一个典型问题,严重威胁着系统的稳定性和性能。当缓存层失效或服务宕机时,大量请求会直接涌入数据库,造成数据库负载过重甚至崩溃。因此,采取有效的应对策略至关重要。
本文首先明确了缓存雪崩的定义及其两种主要成因,即业务层面的大量缓存key同时失效和系统层面的缓存服务宕机。针对这些成因,提出了三种解决策略:
- 分散过期时间:通过在设置的过期时间基础上增加随机值,使缓存失效时间均匀分布,避免大量请求同时回溯到数据库。
- 提前演练压测:通过充分的压力测试和演练,找出系统的性能瓶颈,并在系统上线前进行优化,确保系统在高并发情况下的稳定运行。
- cache高可用和后端数据库限流:采用双缓存热备份方案提升缓存资源的可用性,并在数据库层加入限流机制,防止缓存层宕机时流量集中打到数据库,进而保护数据库的稳定性。
这些策略各有优劣,结合具体业务场景和系统特点,灵活运用这些策略可以有效防止缓存雪崩。