在大模型推理领域,vLLM 凭借其创新的 PagedAttention 机制,成为了高吞吐量推理的事实标准。而 vLLM-Ascend 则是 vLLM 社区官方支持的昇腾(Ascend)硬件后端插件。它让华为昇腾 NPU 能够无缝运行 vLLM,享受极致的推理性能。
本文将带你快速入门 vLLM-Ascend,从源码结构解析到环境部署,再到跑通第一个推理 Demo。
一、 深入 vLLM-Ascend 开源仓结构
在开始部署之前,理解源码结构对于后续的调试和开发至关重要。vllm-ascend 是一个独立于 vLLM 主仓的硬件插件项目,它遵循了 vLLM 的硬件插件化架构。
让我们进入 vllm-ascend 文件夹,看看它的核心构成:
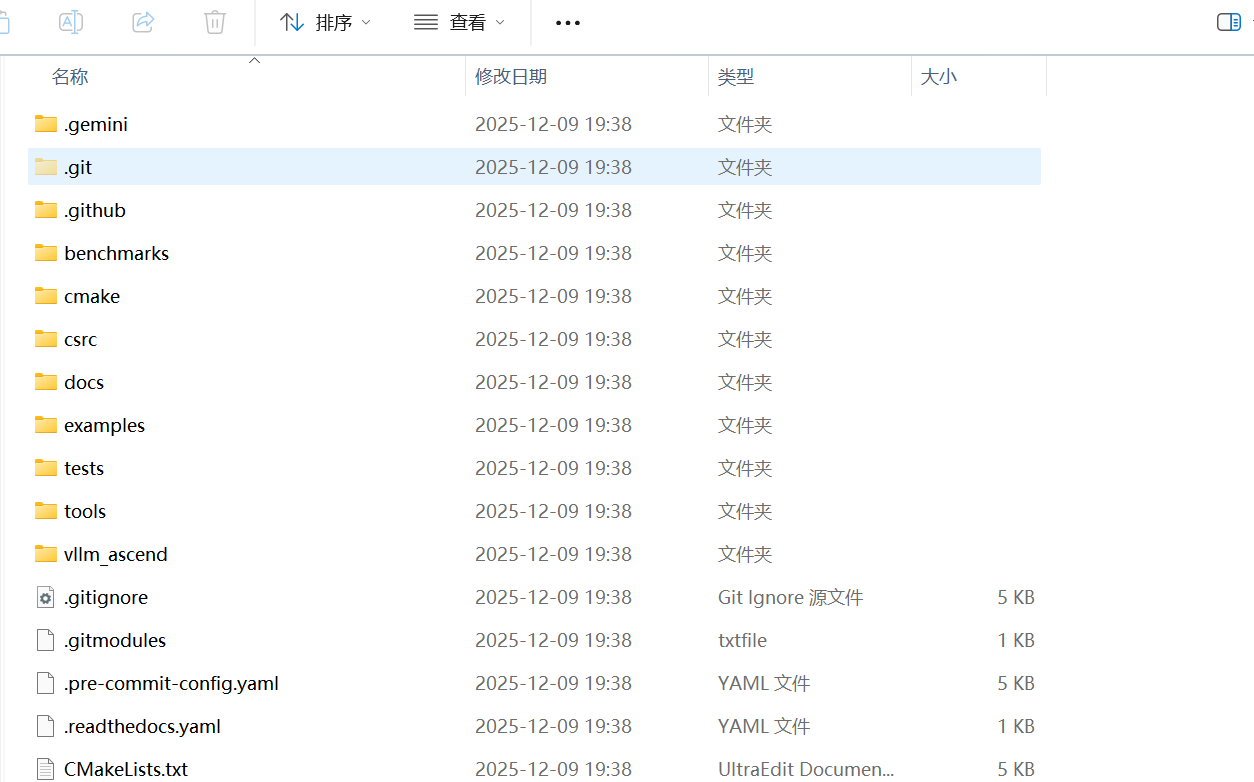
如上图所示,关键目录解析如下:
- vllm_ascend/: 这是 Python 包的核心源码目录,包含了设备注册、模型加载器适配等逻辑。
- csrc/: 存放 C++ 编写的自定义算子(Custom Ops)。由于 NPU 的架构特殊性,部分算子(如 FlashAttention、PagedAttention 的特定实现)需要通过 C++ 调用 ACLNN 接口来实现,以获得最佳性能。
- docs/: 包含了详细的文档,从安装指南到开发者手册。
- Dockerfile: 提供了构建容器镜像的标准描述文件,方便在 Docker 环境中快速部署。
- benchmarks/: 包含了一系列基准测试脚本,用于验证 NPU 上的推理吞吐量和延迟。
二、 环境准备与依赖安装
要在昇腾 NPU 上运行 vLLM,我们需要准备好底层的驱动和软件栈。
1. 硬件与基础软件要求
- 硬件: Atlas 800I A2 (910B) 等支持 BF16/FP16 的昇腾设备。
- 操作系统: Linux (Ubuntu 20.04/22.04 或 openEuler)。
- NPU 驱动与固件: 请确保已安装最新版本的 NPU 驱动。
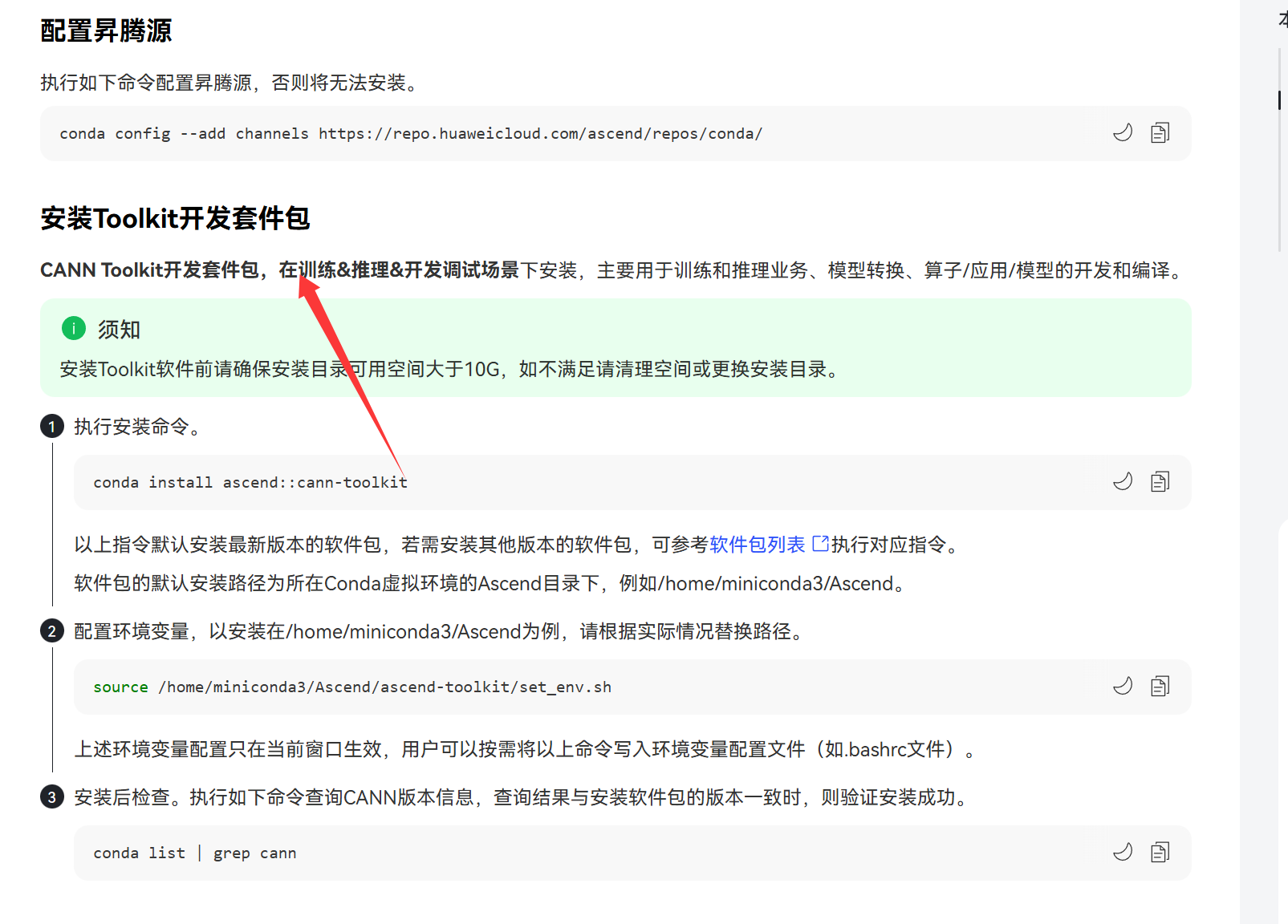
- CANN Toolkit: 这是昇腾的核心软件栈。你需要安装 CANN 8.0 或更高版本。
-
- 下载与安装请参考 CANN 官方网站。
2. 源码安装 vLLM-Ascend
虽然可以通过 pip 安装预编译包,但为了获得最新的特性适配,我推荐使用源码安装。
# 1. 克隆仓库
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
# 2. 安装依赖并编译
pip install -e .
安装过程会自动编译 csrc 目录下的 C++ 算子,生成适配当前 CANN 版本的 .so 动态库。看到 "Successfully installed" 即表示安装成功。
三、 基础配置与环境变量
在运行之前,正确配置环境变量是避坑的关键。
我们需要重点关注以下配置:
-
加载 CANN 环境变量:
-
这是必须的,否则系统找不到 NPU 设备。
source /usr/local/Ascend/ascend-toolkit/set_env.sh
-
指定 NPU 设备:
-
如果你的机器有多张卡,可以通过
ASCEND_RT_VISIBLE_DEVICES来控制 vLLM 可见的设备。export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3
-
调试选项 (可选):
-
如果在运行过程中遇到不明报错,开启同步执行模式有助于定位问题(虽然会降低性能)。
export ASCEND_LAUNCH_BLOCKING=1
四、 快速上手:离线推理 (Offline Inference)
一切准备就绪,让我们来跑一个简单的 Python 脚本,验证环境是否正常。
我们将使用 vLLM 的 LLM 类来加载一个模型(例如 Llama-2 或 Qwen),并生成一段文本。
这部分的内容我们也可以参照官方给我们的实操指南来进行操作:
python代码示例:
from vllm import LLM, SamplingParams
# 1. 初始化 LLM 引擎
# vLLM 会自动识别 NPU 环境
llm = LLM(
model="/data/models/Llama-2-7b-hf", # 替换为你的模型路径
trust_remote_code=True,
tensor_parallel_size=1
)
# 2. 定义提示词
prompts = [
"Hello, my name is",
"The capital of France is",
]
# 3. 设置采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 4. 生成输出
outputs = llm.generate(prompts, sampling_params)
# 5. 打印结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")代码核心点解析:
- LLM(model=...): 初始化引擎。vLLM 会自动检测环境,当安装了
vllm-ascend插件后,它会自动识别并使用 NPU 后端。 - SamplingParams: 定义采样参数,如
temperature(温度)和top_p。
运行脚本后,你就能看到如下输出:

注意日志中的 Initializing an LLM engine ... on ascend device,这证明 vLLM 已经成功挂载到了昇腾 NPU 上,并且使用了 NPU 优化的 PallasAttention 算子。
五、 进阶:多卡张量并行推理 (Tensor Parallelism)
对于 Llama-2-70B 或 Qwen-72B 这样的大模型,单张显卡的显存往往捉襟见肘。这时候,我们就需要利用 vLLM 的 张量并行 (Tensor Parallelism, TP) 功能,将模型切分到多张 NPU 卡上运行。
昇腾 NPU 之间通过 HCCS (High Speed Cache Coherency System) 高速互联,非常适合进行这种细粒度的并行计算。
1. 准备工作
首先,确保你通过 ASCEND_RT_VISIBLE_DEVICES 暴露了足够数量的 NPU 卡。例如,使用 4 张卡:
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,32. 修改推理脚本
启用多卡并行非常简单,只需要在初始化 LLM 时设置 tensor_parallel_size 参数即可。
# 初始化 LLM 引擎,启用 4 卡并行
llm = LLM(
model="/data/models/Llama-2-70b-hf",
tensor_parallel_size=4, # 关键参数:设置为卡数
trust_remote_code=True
)3. 运行与观察
当你运行脚本时,vLLM 会自动启动分布式后端(Ray 或 multiprocessing),并在每张卡上加载部分模型权重。
你会在日志中看到类似 Rank 0, Rank 1 ... 的初始化信息。如果一切顺利,推理速度将会有显著提升,同时显存占用会均匀分布在 4 张卡上。
六、 总结
通过本文,我们从零搭建了 vLLM-Ascend,探索了其源码结构,理解了 Python 插件与 C++ 算子的组织方式,完成了 CANN 环境配置和源码安装,并成功运行离线推理,掌握了多卡张量并行(TP)的配置方法。vLLM-Ascend 极大降低了在昇腾硬件上部署高性能大模型的门槛,随着社区持续发展,越来越多的模型架构(如 MoE 和 Multi-Modal)也将得到支持。