这是笔者的学校的高性能计算的题型分布,大家可以对比参照一下自己学校的。

第一章,第二章知识点回顾

1、高性能计算(High performance computing)
性能衡量单位:FLOPS(浮点运算 / 秒),常用量级:GFLOPS(10⁹次 / 秒)、TFLOPS(10¹² 次 / 秒)
性能衡量方式:LINPACK 测试(超算排名的常用标准)、实际应用程序的运行耗时
2、全局求和实例
并行计算的典型案例:多个计算单元先算 "局部和",再通过通信(比如 MPI 的 "归约操作")合并成 "全局和",是数据并行的实际应用场景。
3、任务并行和数据并行
任务并行 :把不同任务分给不同计算单元(比如一个单元算排序、一个算过滤)
数据并行 :把同一任务的不同数据分给不同单元(比如把大数组拆成小块,各自算求和)
4、并行硬件分类
Flynn 经典分类(按 "指令流 + 数据流" 分):
SISD:单指令流单数据流(冯诺依曼计算机,传统单核)
SIMD:单指令多数据(比如向量处理器)
MIMD:多指令多数据(多核、集群,实际常用)
内存结构分类:
分布式内存系统:各节点有独立内存,靠通信交互(集群、超级计算机)
共享内存系统:多处理器共享同一块内存(个人电脑);其中 UMA(统一内存访问,速度一致)、NUMA(非统一,访问不同内存区域速度不同)
5. 计算机系统发展 & 编程模型
单核时代:串行编程
多核时代(共享内存编程模型):Pthreads(POSIX 多线程)、OpenMP(编译制导式并行编程)
分布式时代(分布式内存编程模型):MPI(消息传递接口,跨节点通信)、MapReduce(大数据分布式计算)
异构时代(异构系统编程模型):CUDA(英伟达 GPU 专用编程)、OpenCL(跨平台异构编程)
第三章
1. MPI 基础信息
全称:Message Passing Interface(消息传递接口,分布式内存并行编程的标准)
头文件:#include <mpi.h>
编译运行:
编译:用mpicc 文件名.c -o 可执行文件
运行:mpirun -np 进程数 ./可执行文件(-np 指定启动的进程数量)
2. 通信方式核心概念
通信子:是 "进程组 + 通信规则" 的集合(比如默认的MPI_COMM_WORLD是包含所有进程的通信子)
通配符:点对点通信中用MPI_ANY_SOURCE(接收任意进程的消息)、MPI_ANY_TAG(接收任意标签的消息)
两类通信:
点对点:两个进程一对一发 / 收(核心函数MPI_Send发送、MPI_Recv接收)
集合通信:多个进程参与的批量通信(下面是核心函数)
3. 集合通信函数(必记作用)
MPI_Reduce():把所有进程的同一数据,按 "计算规则(比如求和、取最大)" 汇总到根进程
MPI_Scatter():根进程把一个大数组,拆分后分散给所有进程
MPI_Bcast():根进程把一个数据广播给所有进程(所有进程都拿到相同数据)
MPI_Gather():所有进程把自己的数据,收集到根进程(和 Scatter 相反)
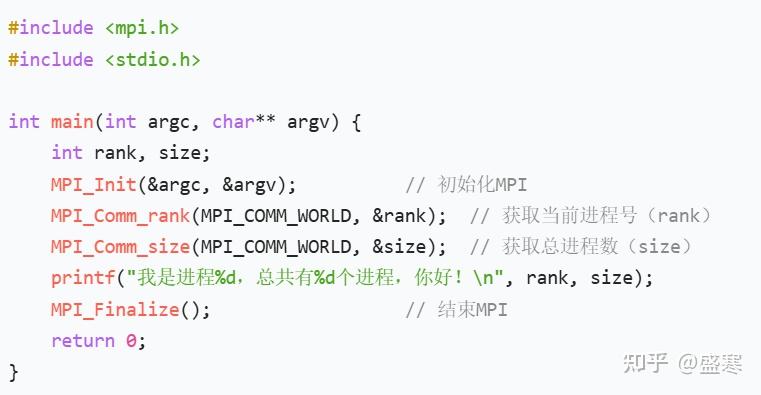
4、问候MPI程序
5、计时功能

第四、五章
1. 编译运行(先记命令,考试大概率考)
Pthreads:编译时加 -lpthread(比如 gcc test.c -o test -lpthread),运行就是普通执行程序
OpenMP:编译加 -fopenmp(GCC 环境),运行时可以用环境变量控制线程数
2. 核心技能
- for 循环并行:普通无依赖的 for,用
#pragma omp parallel for包裹;有循环依赖的,得拆成 "无依赖的计算步骤"(比如把递推式改成能并行算的形式) - schedule 子句:控制循环任务分配,记两个常用的:
static(静态分块)、dynamic(动态分块);环境变量记OMP_NUM_THREADS(设线程数)
3. 临界区保护(必考区分)
critical:默认互斥,所有线程抢同一个 "锁"- 命名
critical:不同名字的临界区可以同时进(比如#pragma omp critical(area1)) atomic:只保护简单运算(加减乘),比critical高效- 简单锁:Pthreads 里的
pthread_mutex_t(lock/unlock 函数)
4. 实例
不用抠细节,记 "梯形积分 / 算 Pi" 的并行思路:线程分块算部分结果,最后汇总时用临界区 /atomic 保护结果变量
指令复习
parallel 指令
功能:标记一段代码为 "并行区域",进入该区域时会创建多个线程,所有线程都会执行这段代码。
注意:单独使用时,代码会被线程重复执行(如 4 个线程会执行 4 次),通常需配合for等指令拆分任务。
for 指令
功能:需嵌套在parallel区域内,将后续 for 循环的任务拆分给多个线程并行执行(每个线程执行循环的一部分)。
用法:需与parallel组合(分两行写:#pragma omp parallel + #pragma omp for)。
parallel for 指令
功能:是parallel与for的简写组合,直接实现 "创建并行区域 + 拆分 for 循环任务",等价于parallel + for。 场景:最常用的循环并行方式,直接写#pragma omp parallel for即可。
atomic 指令
功能:对 单一变量的简单操作(如加减乘)实现互斥保护,是最轻量的临界区方式。
优势:比critical高效;局限:仅支持简单表达式(如sum += x),无法保护代码块。
critical 指令
功能:保护一段代码块的互斥执行,同一时间仅一个线程能进入该代码块。
对比:比atomic灵活(可保护多句代码),但开销更大;支持 "命名"(如critical(area1)),不同名称的critical区域可同时执行。
barrier 指令
功能:线程同步的 "路障",所有线程必须都到达该位置后,才能继续执行后续代码。
场景:确保某阶段任务全部完成后,再进入下一阶段(如所有线程算完局部结果后,同步再汇总)。 这些指令是 OpenMP 并行编程的基础,核心是通过parallel/parallel for拆分任务、atomic/critical保护共享资源、barrier实现线程同步,从而实现高效并行。
子句复习
1. num_threads
- 作用:指定并行区域的线程数量
- 用法 :配合
parallel/parallel for使用,例如#pragma omp parallel num_threads(4)表示用 4 个线程执行后续代码 - 场景:明确控制并行的线程规模,避免依赖环境变量的默认值
2. reduction
- 作用:自动合并多个线程的局部计算结果(无需手动加临界区)
- 用法 :指定 "操作符 + 变量",例如
reduction(+:sum)表示每个线程拥有独立的sum副本,最终自动将所有副本的值相加得到全局sum - 常用操作符 :
+、-、*、&等;优势:替代手动临界区,避免竞争且更高效
3. default
- 作用:控制并行区域中变量的默认共享属性
- 常用选项 :
default(shared):未显式声明的变量默认是共享(OpenMP 默认行为);default(none):要求显式声明所有变量的属性(private/shared),强制避免默认属性导致的错误
- 场景 :用
default(none)提升代码安全性,防止变量作用域混淆
4. private
- 作用:声明变量为 "线程私有"------ 每个线程拥有该变量的独立副本,互不干扰
- 注意:私有变量的初始值不会继承外部变量,需在并行区域内重新初始化
- 场景 :循环变量(如
for中的i)、线程内临时变量
5. shared
- 作用:声明变量为 "线程共享"------ 所有线程共用同一个变量实例
- 注意 :共享变量需通过
atomic/critical等方式保护,避免并发修改错误 - 场景:需要多个线程共同读写的全局结果变量
6. schedule
- 作用 :控制
for循环的任务划分方式(分配给线程的迭代块规则) - 常用策略 :
static:静态分块(如schedule(static, 5)表示每个线程分 5 个迭代),适合任务耗时均匀的场景;dynamic:动态分块(线程完成当前任务后再申请新任务),适合任务耗时不均的场景
- 场景:优化循环并行的负载均衡
函数复习
OpenMP 并行编程中常用的辅助函数,可分为线程管理、计时、锁操作三类,核心作用是实现线程控制、性能统计与精细化同步,以下是各函数的解读:
一、线程管理类函数
omp_get_num_threads()
作用:获取当前并行区域内的活动线程数量。
注意:仅在并行区域内调用有效(串行区域调用会返回 1,因为串行时只有 1 个主线程);常用于调试或动态适配线程逻辑。
omp_get_thread_num()
作用:获取当前线程的唯一编号(线程号从 0 开始,如 4 个线程的编号为 0~3)。
场景:区分不同线程执行差异化逻辑(如线程 0 负责初始化、其他线程负责计算),或标记线程的局部结果。
omp_set_num_threads()
作用:设置后续并行区域的线程数量。
注意:优先级低于num_threads子句(若同时使用#pragma omp parallel num_threads(4),该函数的设置会被覆盖);常用于全局统一控制线程规模。
二、计时函数
omp_get_wtime()
作用:获取系统的 "墙上时间"(当前时间戳),用于统计程序运行耗时。
使用方式:在代码段的开始和结束处分别调用,计算两次返回值的差值(单位为秒)
double start = omp_get_wtime(); // 并行代码 double end = omp_get_wtime(); printf("耗时:%f秒\n", end - start);
场景:测试并行程序的性能(对比串行 / 并行的耗时差异)。
三、锁操作类函数(精细化临界区控制)
这组函数用于手动管理锁(比critical指令更灵活),流程为 "初始化→获取→释放→销毁":
omp_init_lock(omp_lock_t lock)
作用:初始化锁,将锁设置为 "未锁定" 状态;必须在使用锁前调用。
omp_destroy_lock(omp_lock_t lock)
作用:销毁锁,释放锁占用的资源;用于锁不再使用时,避免内存泄漏。
omp_set_lock(omp_lock_t lock)
作用:尝试获取锁;若锁已被其他线程占用,当前线程会阻塞,直到锁被释放。
omp_unset_lock(omp_lock_t lock)
作用:释放锁,让其他阻塞的线程可以获取该锁。
场景:当需要跨多个代码块共享同一把锁(而非critical的局部代码块)时,用这组函数实现更灵活的同步。