Fun-Audio-Chat-8B 介绍
Fun-Audio-Chat-8B 是由 TONGYI Fun 团队开发的大型音频语言模型(Large Audio Language Model),专为自然、低延迟的语音交互设计,在语音问答、音频理解、语音函数调用等多个场景中表现优异,支持中英双语交互,采用 Apache 2.0 开源许可协议。(开源地址:https://huggingface.co/FunAudioLLM/Fun-Audio-Chat-8B)
核心特性
1. 双分辨率语音表征(Dual-Resolution Speech Representations)
创新采用 "5Hz 共享骨干网络 + 25Hz 精细化头部" 架构,相比其他模型常用的 12.5Hz 或 25Hz 帧速率,在保持高语音质量的前提下,将 GPU 计算量减少近 50%,兼顾效率与性能。
2. 同尺寸模型顶尖性能
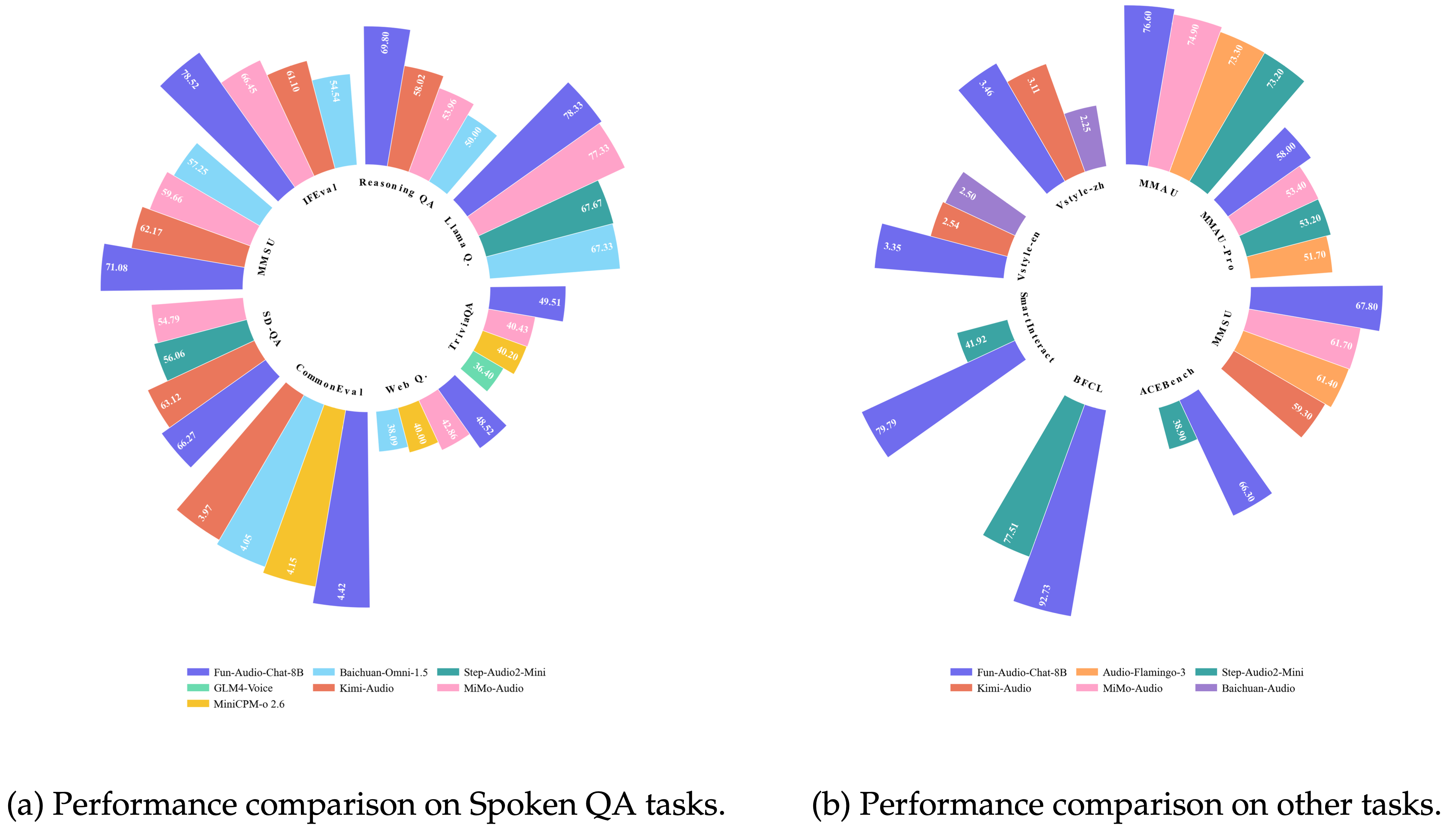
在 8B 参数级别模型中,于多个权威基准测试中排名前列,覆盖语音问答、音频理解、语音交互等核心场景,涉及的基准测试包括:
- 语音问答(Spoken QA):OpenAudioBench、VoiceBench
- 语音转语音(Speech-to-Speech):UltraEval-Audio
- 音频理解(Audio Understanding):MMAU、MMAU-Pro、MMSU
- 语音函数调用(Speech Function Calling):Speech-ACEBench、Speech-BFCL、Speech-SmartInteract
- 语音指令遵循(Speech Instruction-Following):VStyle
3. 全面的语音交互能力
支持多样化语音相关任务,满足复杂场景需求:
- spoken QA:语音问答,直接通过语音输入提问并获取语音 / 文本答案
- 音频理解:解析音频内容、情感、场景等信息
- 语音函数调用:通过语音指令触发特定功能调用
- 语音指令遵循:精准响应语音形式的指令要求
- 语音共情(Voice Empathy):模拟共情式语音反馈,提升交互自然度
模型详情
| 属性 | 具体信息 |
|---|---|
| 模型尺寸 | 约 8B 参数 |
| 架构设计 | 双分辨率语音表征(Dual-Resolution Speech Representations) |
| 支持语言 | 英语(English)、中文(Chinese) |
| 许可协议 | Apache 2.0(可商用、可修改,需保留原版权声明) |
| 张量类型 | BF16 |
| 关联模型 | 配套依赖 Fun-CosyVoice3-0.5B-2512 模型 |
环境要求
基础依赖
- Python 版本:3.12
- PyTorch 版本:2.8.0
- 必要工具:ffmpeg(音频处理依赖)
- 其他依赖:torchaudio==2.8.0 及 requirements.txt 中指定的包
硬件要求
- 推理(Inference):GPU 显存 ≥ 24GB
- 训练(Training):4 块 80GB 显存 GPU(如 A100 80GB)
安装与部署
1. 环境配置步骤
bash
运行
bash
# 克隆代码仓库(含子模块)
git clone --recurse-submodules https://github.com/FunAudioLLM/Fun-Audio-Chat
cd Fun-Audio-Chat
# 安装 ffmpeg
apt install ffmpeg
# 创建并激活 Conda 环境
conda create -n FunAudioChat python=3.12 -y
conda activate FunAudioChat
# 安装 PyTorch 及 torchaudio(适配 CUDA 12.8)
pip install torch==2.8.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
# 安装其他依赖
pip install -r requirements.txt2. 模型下载
支持通过 Hugging Face Hub 或 ModelScope 两种方式下载预训练模型,需同时下载主模型和配套依赖模型:
方式一:通过 Hugging Face Hub 下载
bash
运行
bash
# 安装 huggingface-hub 工具
pip install huggingface-hub
# 下载主模型 Fun-Audio-Chat-8B
hf download FunAudioLLM/Fun-Audio-Chat-8B --local-dir ./pretrained_models/Fun-Audio-Chat-8B
# 下载配套模型 Fun-CosyVoice3-0.5B-2512
hf download FunAudioLLM/Fun-CosyVoice3-0.5B-2512 --local-dir ./pretrained_models/Fun-CosyVoice3-0.5B-2512方式二:通过 ModelScope 下载
bash
运行
bash
# 下载主模型 Fun-Audio-Chat-8B
modelscope download --model FunAudioLLM/Fun-Audio-Chat-8B --local_dir pretrained_models/Fun-Audio-Chat-8B
# 下载配套模型 Fun-CosyVoice3-0.5B-2512
modelscope download --model FunAudioLLM/Fun-CosyVoice3-0.5B-2512 --local_dir pretrained_models/Fun-CosyVoice3-0.5B-25123. 快速推理
配置完成后,可通过以下命令快速运行核心功能:
bash
运行
bash
# 设置 Python 路径
export PYTHONPATH=`pwd`
# 语音转文本(Speech-to-Text)
python examples/infer_s2t.py
# 语音转语音(Speech-to-Speech)
python examples/infer_s2s.py引用规范
若使用该模型进行学术研究或商业开发,建议引用相关论文:
bibtex
bibtex
@article{funaudiochat2025,
title={Fun-Audio-Chat Technical Report},
author={Qian Chen and Luyao Cheng and Chong Deng and Xiangang Li and Jiaqing Liu and Chao-Hong Tan and Wen Wang and Junhao Xu and Jieping Ye and Qinglin Zhang and Qiquan Zhang and Jingren Zhou},
year={2025},
eprint={2512.20156},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2512.20156},
}
@misc{tan2025drvoiceparallelspeechtextvoice,
title={DrVoice: Parallel Speech-Text Voice Conversation Model via Dual-Resolution Speech Representations},
author={Chao-Hong Tan and Qian Chen and Wen Wang and Chong Deng and Qinglin Zhang and Luyao Cheng and Hai Yu and Xin Zhang and Xiang Lv and Tianyu Zhao and Chong Zhang and Yukun Ma and Yafeng Chen and Hui Wang and Jiaqing Liu and Xiangang Li and Jieping Ye},
year={2025},
eprint={2506.09349},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.09349},
}相关资源
- 论文链接:Fun-Audio-Chat Technical Report、DrVoice
- GitHub 代码库:https://github.com/FunAudioLLM/Fun-Audio-Chat
- Demo 页面:参考官方仓库或 Hugging Face 模型页指引
- 依赖项目:Transformers、LlamaFactory、Moshi、CosyVoice、Safetensors
- https://ai-bot.cn/fun-audio-chat/
- https://huggingface.co/FunAudioLLM/Fun-Audio-Chat-8B