在机器学习领域,聚类算法是无监督学习的核心应用,而文本特征提取则是自然语言处理的基础步骤。本文将结合实战代码,详细拆解KMeans、DBSCAN两种经典聚类算法及TF-IDF文本特征提取方法,帮你快速掌握核心原理与落地技巧。
一、KMeans聚类:基于距离的经典聚类算法
1.1 核心原理
KMeans是一种基于距离的聚类算法,核心思想是通过预设聚类数量K,将数据划分为K个簇,使得每个簇内样本的相似度最高(距离最近),簇间样本的相似度最低(距离最远)。算法流程可概括为: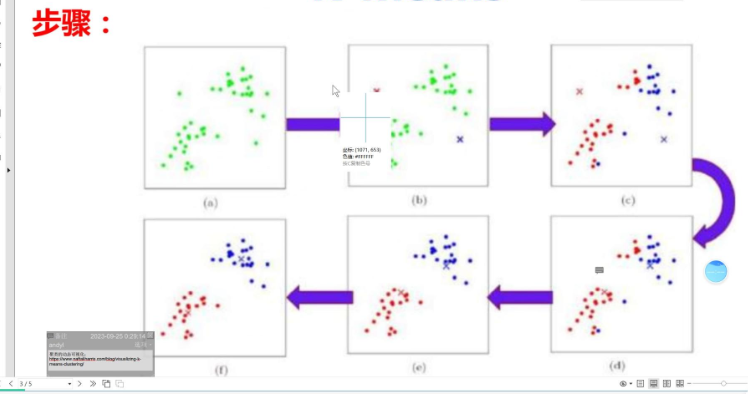
-
随机初始化K个聚类中心;
-
计算每个样本到各聚类中心的距离,将样本归入最近的簇;
-
重新计算每个簇的均值作为新的聚类中心;
-
重复步骤2-3,直到聚类中心稳定或达到最大迭代次数。
聚类效果评价方式:

1.2 实战代码:聚类效果评估与可视化
下面以实际数据集为例,实现KMeans聚类,并通过轮廓系数评估聚类效果,绘制聚类数与轮廓系数的关系折线图,辅助选择最优K值。以之前寝室分配的数据集为例:
python
data = np.loadtxt("datingTestSet2.txt")
x = data[:, :-1]
score = []
# 定义要测试的聚类数量列表
n_clusters_list = [2,3,4,5,6,7,8,9,10]
# 2. 遍历不同聚类数,计算轮廓系数(添加random_state保证结果可复现)
for i in n_clusters_list:
# 固定random_state,避免每次运行结果不一致
labels = KMeans(n_clusters=i, random_state=42).fit(x).labels_
# 计算轮廓系数并添加到列表
silhouette_score = metrics.silhouette_score(x, labels)
score.append(silhouette_score)
# 3. 打印轮廓系数结果(方便查看数值)
print("各聚类数对应的轮廓系数:")
#zip([a,b,c], [1,2,3]) 会变成 (a,1)、(b,2)、(c,3),方便同时遍历多个列表
for cluster_num, s_score in zip(n_clusters_list, score):
print(f"聚类数 {cluster_num}: {s_score:.4f}")
# 4. 绘制折线图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 创建画布
plt.figure(figsize=(10, 6))
# 绘制折线图,添加标记点更易查看
plt.plot(n_clusters_list, score, marker='o', linestyle='-', color='b', linewidth=2, markersize=8)
# 添加图表标题和坐标轴标签
plt.title('K-Means聚类数与轮廓系数关系', fontsize=14)
plt.xlabel('聚类数(K值)', fontsize=12)
plt.ylabel('轮廓系数', fontsize=12)
# 添加网格线,方便读取数值
plt.grid(True, alpha=0.3)
# 标注最大值点(可选,直观看到最优K值)
max_score_idx = np.argmax(score)
max_k = n_clusters_list[max_score_idx]
max_s = score[max_score_idx]
plt.annotate(f'最优K值:{max_k}\n系数:{max_s:.4f}',
xy=(max_k, max_s),
xytext=(max_k+0.5, max_s-0.05),
arrowprops=dict(arrowstyle='->', color='red'))
# 显示图表
plt.show()运行结果:1.3 核心要点解读
-
labels_属性:KMeans模型训练后生成的核心属性,存储每个样本的聚类标签(整数),标签从0开始,对应不同的簇。
-
zip函数:用于将"聚类数列表"与"轮廓系数列表"配对遍历,实现聚类数与对应分数的一一对应输出,简化代码逻辑。
-
最优K值选择:通过轮廓系数折线图及标注功能,可快速定位最优聚类数,避免盲目设置K值。
-
random_state参数:固定随机种子,确保每次运行模型的聚类结果一致,便于调试和复现。
二、DBSCAN聚类:基于密度的智能聚类算法
KMeans需预设聚类数,且对非球形簇效果较差,而DBSCAN(基于密度的带噪声应用空间聚类)可解决这些问题,无需预设簇数,能识别任意形状的簇和噪声点。
2.1 核心原理与关键概念
DBSCAN基于"密度"划分簇,核心思想是:将密度足够高的区域划分为簇,稀疏区域的点视为噪声。关键概念如下: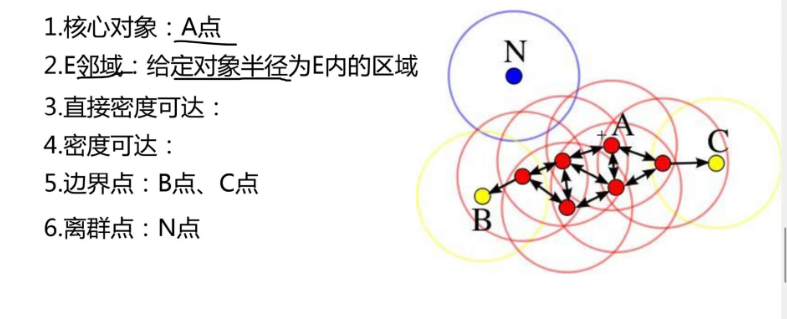
-
E邻域:以某个点为中心,半径为E的区域。
-
核心对象:若一个点的E邻域内包含的样本数≥MinPts(最小点数阈值),则该点为核心对象。
-
密度可达:通过一系列核心对象的E邻域传递,可到达的点称为密度可达。
-
噪声点:无法被任何核心对象密度可达的点,标注为-1。
算法流程:遍历所有未处理的点,若为核心对象则扩展其密度可达的所有点形成簇,否则标记为噪声,直到所有点处理完毕。
可以理解为病毒扩散,只要接触的范围近就会被感染,一个群体被感染完之后开始下一轮,区别于kmeans在于聚类出特殊的形状,而不是仅仅通过距离的远近你你你来实现聚类,如实现笑脸表情的聚类两种算法的区别: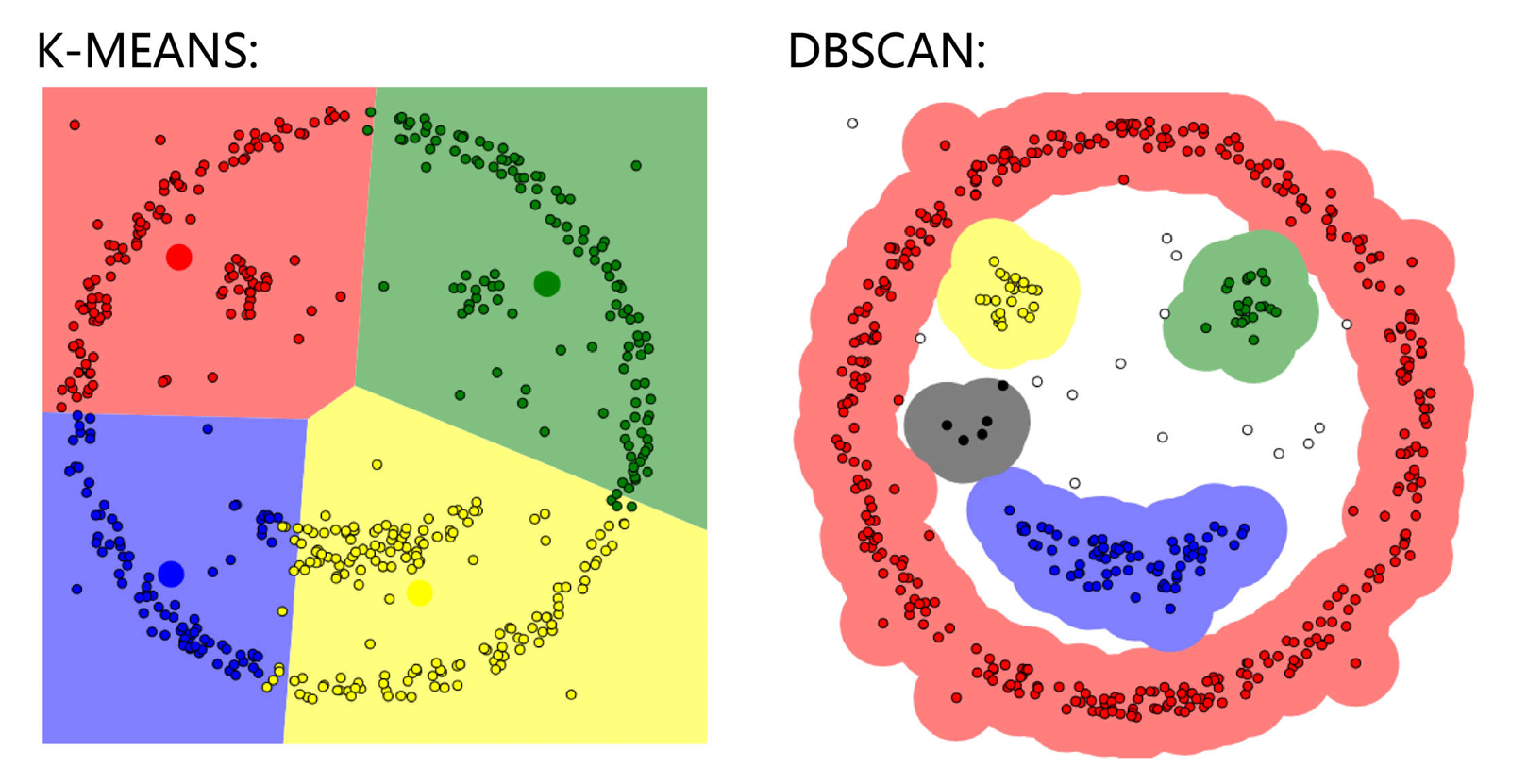
API:
三、TF-IDF:自然语言处理的核心文本特征提取方法
在自然语言处理中,需将文本转换为数值特征才能用于机器学习模型。TF-IDF(词频-逆文档频率)是常用的特征加权方法,用于评估一个词对某篇文档的重要程度,即寻找关键词的方法。
3.1 核心原理
TF-IDF由两部分组成,核心逻辑是:一个词在本文档中出现越频繁(TF高),且在所有文档中出现越稀少(IDF高),则该词对本文档的重要性越高(TF-IDF值越大)。
-
词频(TF):某词在当前文档中的出现次数/当前文档总词数,衡量词在本文档的活跃度。
-
逆文档频率(IDF):log(总文档数/(包含该词的文档数+1)),"+1"是为了避免分母为0,衡量词的稀缺性。
-
TF-IDF值:TF × IDF,最终的词权重,值越大越重要。
3.2 实战代码:按行提取文本关键词
将文本文件的每一行视为一个独立文档,通过TF-IDF计算并排序每个文档的关键词,过滤无意义的英文停用词(如the、is)。
python
from sklearn.feature_extraction.text import TfidfVectorizer
# 步骤1:读取txt文件,每一行作为一个文本
with open("task2_1.txt", "r", encoding="utf-8") as f:
# 读取所有行,去掉空行和换行符
documents = [line.strip() for line in f if line.strip()]
# 步骤2:初始化TF-IDF转换器(自动过滤英文停用词)
tfidf = TfidfVectorizer(stop_words="english") # stop_words="english"过滤常见无意义词
# 步骤3:计算所有文本的TF-IDF矩阵
tfidf_matrix = tfidf.fit_transform(documents)
# 获取所有词汇(特征名)
all_words = tfidf.get_feature_names_out()
# 步骤4:遍历每个文本,按TF-IDF权重降序排序关键词
print("=== 每个文本的关键词排序(按TF-IDF权重从高到低)===")
for idx, doc in enumerate(documents, start=1):
# 获取当前文本的TF-IDF值(转换为数组格式)
tfidf_values = tfidf_matrix[idx - 1].toarray()[0]
# 将"词汇"和"对应的TF-IDF值"配对,过滤掉权重为0的词
word_tfidf = [(word, value) for word, value in zip(all_words, tfidf_values) if value > 0]
# 按TF-IDF值降序排序
word_tfidf_sorted = sorted(word_tfidf, key=lambda x: x[1], reverse=True)
# 输出结果
print(f"\n文本{idx}:{doc}")
print("关键词排序:", [word for word, _ in word_tfidf_sorted])运行结果:
3.3 核心要点解读
-
中文处理注意事项 :上述代码适用于已分词的文本(词之间用空格分隔)。若处理原始中文文本,需先使用jieba等分词库分词,示例:
import jieba; seg_doc = " ".join(jieba.lcut("机器学习入门教程"))。 -
停用词过滤 :通过
stop_words="english"过滤英文停用词,中文停用词可自行构建列表传入该参数。 -
应用场景:搜索引擎排序、文本分类/聚类的特征输入、文档关键词提取等。
四、总结:核心知识点与应用场景对比
| 技术点 | 核心优势 | 局限性 | 典型应用场景 |
|---|---|---|---|
| KMeans | 原理简单、计算高效,适合大规模数据 | 需预设簇数,对非球形簇、噪声敏感 | 用户价值分群、图像分割、数据初步聚类 |
| DBSCAN | 无需预设簇数,识别任意形状簇和噪声 | 对参数敏感,高维数据表现较差 | 地理热点分析、网络攻击检测、异常数据过滤 |
| TF-IDF | 简单高效,能有效提取文本核心特征 | 依赖分词质量,无法捕捉语义关系 | 关键词提取、文本分类/聚类特征输入、搜索引擎 |
综上,KMeans和DBSCAN是两种互补的聚类算法,需根据数据分布和业务需求选择;TF-IDF是文本处理的基础,常与聚类、分类算法结合使用。掌握这些基础技术,能覆盖大部分无监督学习和文本处理的入门场景。