目录
一.过拟合
过拟合是机器学习模型在训练过程中过分迎合训练数据中的细节、噪声甚至随机波动,导致其在训练集上表现非常好,但在新的、未见过的数据,如测试集上泛化能力差、预测效果显著下降的现象。
可能产生的原因:
模型过于复杂:相对于有限的训练数据,模型的容量或"表达能力"过强,例如深度过大的神经网络、决策树分支过多,使其有能力"记住"而非"学习"数据中的一般规律。
训练数据不足或质量差:数据量太小,不足以代表真实的数据分布;或者数据中含有大量噪声、异常值,模型错误地将这些偶然特征当作了规律来学习。
训练时间过长(尤其对于迭代模型):在训练神经网络等模型时,如果迭代轮次过多,模型会从最初学习通用模式逐渐转向精确拟合训练数据中的每一个样本,包括其中的噪声,从而导致过拟合。
二.正则化
1.Lasso回归(套索回归)
普通线性回归的目标是找到一组系数(权重),使得预测值y和真实值之间的均方误差最小。
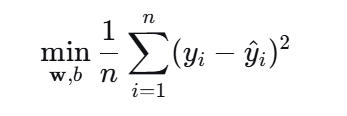
由于不影响优化结果,也可以简化为最小化误差平方和。
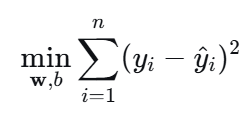
Lasso回归在普通线性回归的目标函数上增加了一个L1 正则化惩罚项:
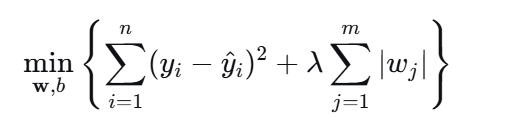

Lasso回归会对模型所有权重系数的绝对值之和进行惩罚,从而约束模型的复杂度。这个惩罚项会促使模型自动将不重要的特征对应的系数压缩为零(稀疏化)。
2.Ridge回归(岭回归)
岭回归是一种在普通线性回归基础上加入了L2正则化惩罚项 的机器学习算法。其核心思想是在最小化预测误差的同时,对模型所有权重系数的平方和进行惩罚,从而约束模型的复杂度,防止过拟合。
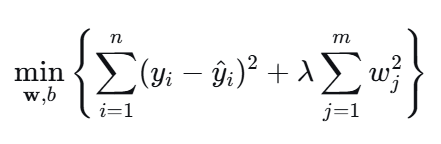


岭回归通过对模型所有权重系数的平方和 进行惩罚,从而约束模型的复杂度。这个惩罚项会使所有系数同时缩小,但不会将任何系数压缩至零。
关于岭回归为什么不产生零系数?
从几何角度看,L2惩罚项对应的约束区域是一个平滑的圆形/球形。在优化过程中,损失函数的等高线与这个光滑区域相切的点几乎不可能落在坐标轴上,因此所有系数都只会被缩小,而不会精确为零。可以看看这个视频协助理解。
什么是 L1 L2 正规化 正则化 Regularization (深度学习 deep learning)_哔哩哔哩_bilibili
上面视频也有讲到,当特征之间高度相关时,普通线性回归或Lasso回归的系数可能会变得不稳定,岭回归通过惩罚项可以稳定系数估计,也就是岭回归能够处理多重共线性问题。
3.Dropout
Dropout 是一种在神经网络训练过程中使用的正则化技术,其核心思想是在每次前向传播时,随机"丢弃"网络中一定比例的神经元(通常包括其输入和输出连接)。这种随机屏蔽迫使网络不能过度依赖任何一个或一组特定的神经元,因为它们在每次训练迭代中可能被禁用,从而鼓励网络学习到更鲁棒、更分散的特征表示。
以下是神经网络Dropout的步骤:

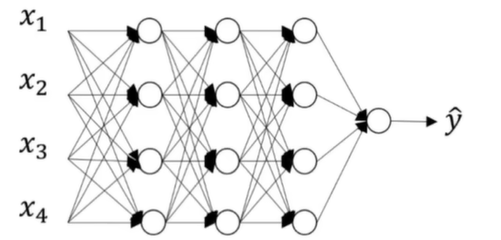
下图是没有使用Dropout正则化的神经网络:
下图是使用Dropout正则化的神经网络,且丢弃率p=0.5:
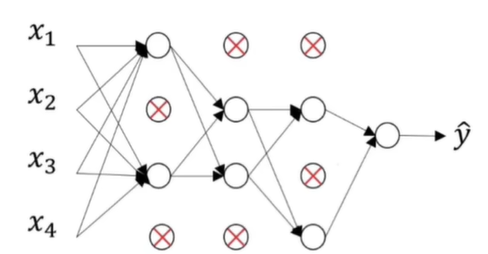
上面两张图片是来自下面视频的案例: