
AI(即人工智能 Artificial Intelligence)是计算机科学的一个分支,旨在让计算机模仿人类的决策能力、像人类一样思考,学习和解决问题的技术。而大模型是实现AI的一种强大技术和路径。
大模型,通常指大规模预训练模型,是深度学习的一个分支。它的大体现在三个方面:
- 参数量巨大:千亿、万亿级别的神经元连接,能够存储海量知识。
- 训练数据巨大:使用整个互联网规模的文本、图像、代码等进行训练。
- 算力消耗巨大:需要强大的GPU集群进行数周甚至数月的训练。
像ChatGPT、Claude 、文心一言、通义千问都属于大模型的一种。
ollama
Ollama 是一个开源工具,可以让你能在自己的电脑上轻松地运行、管理和部署大型语言模型。 像deepseek、通义千问、gemini等模型都可以通过ollama进行部署运行。官网地址为: ollama.com/ 。 下载并安装成功后,我们可以进入Models选择自己需要的模型进行部署,机器性能有限,所以选取了qwen3:0.6b作为本次部署的模型。
这些大模型中都带有个"b",这个b表示十亿的意思。0.6b则表示6亿个参数,参数越多表示功能越强大。  选择对应的模型后,进入详情可以查看ollama的安装命令。将该命令复制后进行安装。
选择对应的模型后,进入详情可以查看ollama的安装命令。将该命令复制后进行安装。 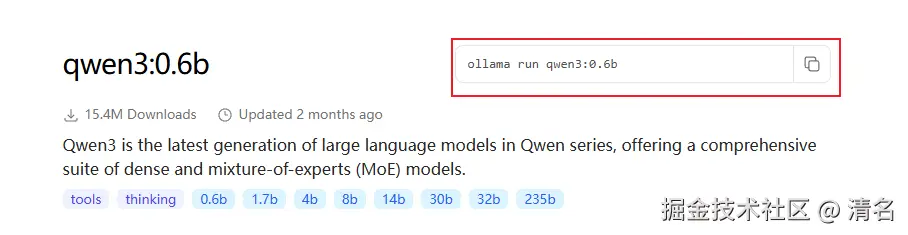

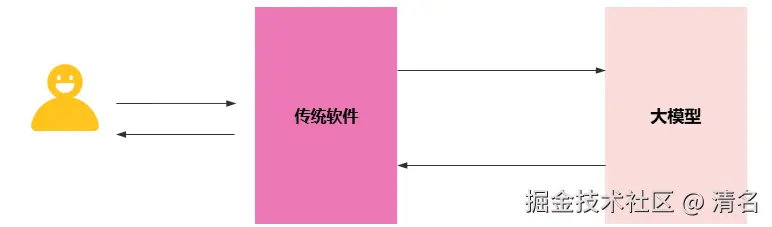
虽然成功的部署了大模型,但是当前状态下用户无法直接使用该模型。所以需要建立一个桥梁,来连接用户和大模型。对于传统软件来讲,想要进行智能化改造,目前有两种选择:LangChain4j 和Spring Ai。本次将以LangChain4j来作为桥梁,LangChain4j 是一个专为Java设计的大语言模型集成框架,其核心目标是简化将各类大语言模型集成到Java应用程序中的过程。
LangChain4j
OpenAiChatModel
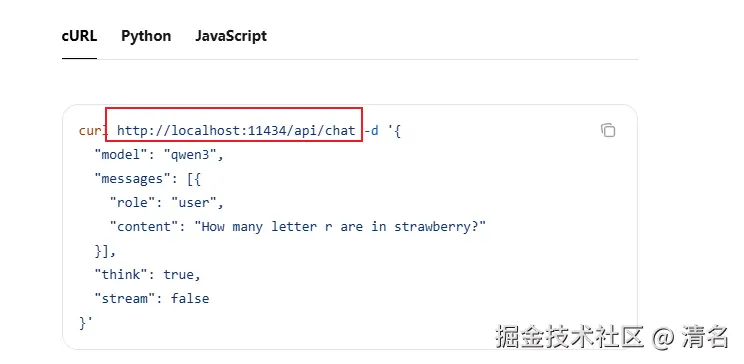
本地部署大模型后,会提供出各种api,ollama默认提供的服务端口是11434,langchain4j底层已经默认集成了这些接口,而这些接口被封装在OpenAiChatModel中,所以OpenAiChatModel是OpenAi的关键入口,我们在使用时只需要调用对应的方法即可,减少了很多的接口对接的时间。现在需要将langchain4j整合到项目中,下面是demo中相关框架的版本,需要注意的是,langchain4j强制使用17及以上的jdk版本。。
springboot版本为3.5.0
jdk版本为17
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>3.5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.5.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.29.0</version> <!-- 最新稳定版本 -->
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>0.29.0</version> <!-- 如果使用 Spring Boot Starter -->
</dependency>如果你使用的是云版的大模型,那么这部可以忽略,你只需要在yml文件中配置相应的模型信息即可。这段配置主要是用于本地部署版本,本地部署一般不需要apiKey,但是这里不填的话会报错,所以随便填上一点内容就行。baseUrl填写模型的地址就行,需要注意的是,ollama的官网中提供的api接口地址并没有v1部分,但是这里不配置的话请求时会404。
java
@Configuration
public class ChatModelConfig {
@Bean
public OpenAiChatModel openAiChatModel(){
return OpenAiChatModel.builder()
.baseUrl("http://127.0.0.1:11434/v1") // ollama地址
.modelName("qwen3:0.6b") // 模型名称
.apiKey("123") // apikey 随便填写
.build();
}
}给用户提供一个模拟对话的接口,用户将通过该接口将对话内容请求到模型中,模型再将思考结果通过该接口返回给用户。
java
@RequestMapping("/api")
@RestController
public class ChatApiController {
OpenAiChatModel openAiChatModel;
ChatApiController( OpenAiChatModel openAiChatModel){
this.openAiChatModel = openAiChatModel;
}
@PostMapping("/chat")
public String chat(@RequestBody ChatDTO chatDTO){
String response = openAiChatModel.generate(chatDTO.getData());
return response;
}
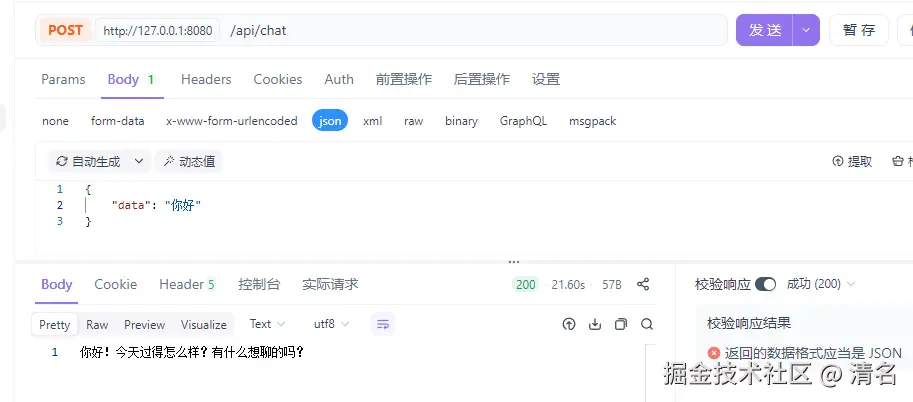
}通过该接口发送对话内容并查看模型思考的结果。
@AiService
上面使用了OpenAiChatModel进行了对话demo的编写,但是LangChain4j提供了更简洁的编码方式,即使用@AiService注解来进行声明式编写。在使用该注解时,需要自定义一个对话接口,并在接口上添加该注解。该注解内有几个参数wiringMode(模型是自动配置还是手动配置),chatModel(指定的模型配置)等。现在对上面的代码进行改造。首先定义一个AiChatService接口,并添加注解。
java
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, // 表示手动配置,默认自动配置
chatModel = "openAiChatModel" // 对话模型
)
public interface AiChatService {
// 实现ai对话
public String chat(String content);
}在原来的controller中,将OpenAiChatModel替换为AiChatService,重启成功后,并进行对话,模型同样返回了结果。
java
AiChatService aiChatService;
ChatApiController(AiChatService aiChatService){
this.aiChatService = aiChatService;
}
@PostMapping("/chat")
public String chat(@RequestBody ChatDTO chatDTO){
String response = aiChatService.chat(chatDTO.getData());
return response;
}
流式调用
流式调用主要用于让大模型生成回复时,实时的、逐步的输出内容,而不是等全部内容生成完才一次性返回,文字能像"打字"一样出现,缩短用户等待时间,像常用的deepseek,豆包等都是采用流式调用的方式,大大提高了用户体验。LangChain4j中,提供了OpenAiStreamingChatModel对象,使用该对象结合Spring提供的Flux<T>即可实现流式调用。首先引入langchain4j-reactor的依赖。
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>Model配置和上述配置几乎相同,只是将OpenAiChatModel替换成了OpenAiStreamingChatModel。logRequests和logResponses的作用是输出与模型交互的请求和响应报文日志。
java
@Bean
public OpenAiStreamingChatModel openAiStreamingChatModel(){
OpenAiStreamingChatModel build = OpenAiStreamingChatModel.builder()
.baseUrl("http://127.0.0.1:11434/v1")
.modelName("qwen3:0.6b")
.apiKey("123")
.logRequests(true)
.logResponses(true)
.build();
return build;
}配置完成后,需要在定义的接口中新增一个流式调用的方法,并且方法的返回值类型需要是Flux<T>,同时在@AiService注解内需要配置流式模型的配置(streamingChatModel)。
java
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel"
)
public interface AiChatService {
/**
* 非流式对话
* @param content
* @return
*/
String chat(String content);
/**
* 流式对话
* @param content
* @return
*/
Flux<String> chatFlux(String content);
}在以上全部实现后,在额外提供一个给用户调用的接口,这个接口的返回类型同样需要使用Flux。这里需要注意的是在@GetMapping中,需要将produces的值设置为text/html;charset=utf-8,否则返回的内容将会是一串乱码。直接调用该接口,会直接展示流式调用效果。
java
@GetMapping(value = "/chat-flux",produces = "text/html;charset=utf-8")
public Flux<String> chatFlux(@RequestParam(name = "content") String content){
Flux<String> chatFlux = aiChatService.chatFlux(content);
return chatFlux;
} 上面响应的内容不太美观,那我们自己可以实现一个简单的前端页面来模拟ai智能问答(网上找一个模板或者ai生成一个就行,没必要在这个上面浪费时间)。虽然回复有些卡顿,但作为古董级的笔记本部署0.6b的模型效果也算不错了😔😔😔。
上面响应的内容不太美观,那我们自己可以实现一个简单的前端页面来模拟ai智能问答(网上找一个模板或者ai生成一个就行,没必要在这个上面浪费时间)。虽然回复有些卡顿,但作为古董级的笔记本部署0.6b的模型效果也算不错了😔😔😔。
会话记忆
通常来说,正常的对话具有连续性,我们可能通过连续的对话能够更加准确的理解对方的意图或想法。但是对于机器而言,每一句对话都是独立的,并没有连续的效果。比如下面对话,机器并没有通过上下文,来理解我提问的问题。
 为了让机器能够理解对话的内容,就需要将对话的上下文一并推给机器,让机器在连续对话中记住之前交互内容的能力。它使得对话能够保持连贯性,而不是每次只处理独立的单轮对话,这就是会话记忆。目前会话记忆主要有两种,一种是短期记忆,一种是长期记忆。
为了让机器能够理解对话的内容,就需要将对话的上下文一并推给机器,让机器在连续对话中记住之前交互内容的能力。它使得对话能够保持连贯性,而不是每次只处理独立的单轮对话,这就是会话记忆。目前会话记忆主要有两种,一种是短期记忆,一种是长期记忆。
- 短期记忆(上下文窗口)
固定上下文长度,将整个对话历史作为输入传递给模型。这是目前最常见的方式。 - 长期记忆(外部存储)
通过向量数据库、缓存或用户档案存储重要信息,在需要时检索并注入到当前对话中。
如果想要实现短期记忆,langchain4j提供了MessageWindowChatMemory,并且可以通过调用maxMessages方法来确定上下文的消息数量,并在@AiService注解中来指定会话记忆配置对象chatMemory。
java
@Bean
public ChatMemory chatMemory(){
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(30) // 上下文长度为30条
.build();
return chatMemory;
}
java
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemory = "chatMemory" // 配置会话记忆
)当重新运行后在进行同样的提问,可以看出来模型已经根据会话记忆的上下文进行理解并准确的回答问题了。 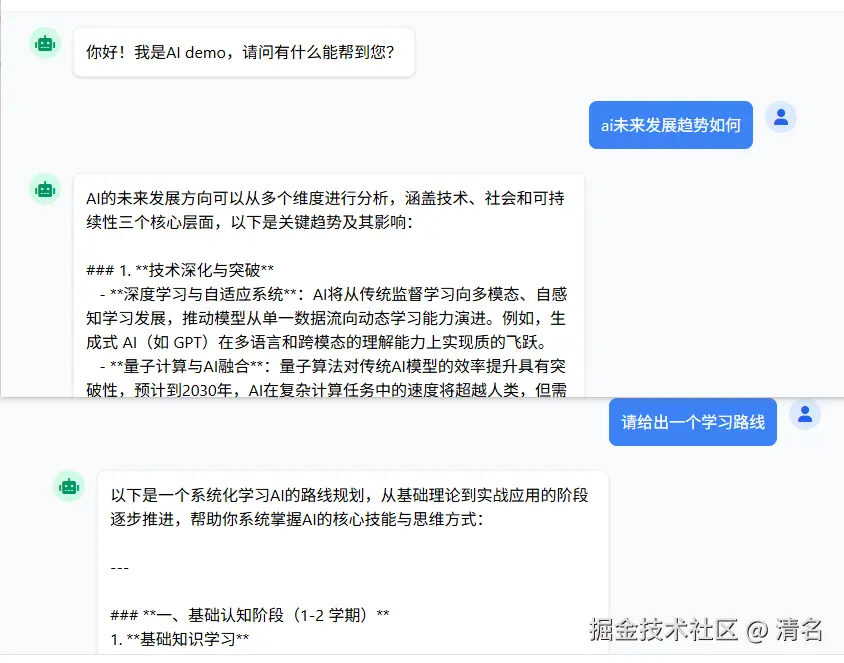
短期记忆存在一个弊端,因为对话记忆内容是存储在内存中的,当服务器重启时,那这些记忆的内容就会丢失。如果想要实现长期记忆,则需要自主开发实现,比如将对话内容存储到redis中。在Langchain4j中有提供 ChatMemoryStore接口,长期存储时需要实现这个接口。以redis为例,定义一个ChatMemoryStore的实现类RedisChatStoreService,将对话消息进行存储。需要注意的是,实现长期记忆的同时,也要实现会话隔离。
java
@Component
public class RedisChatStoreService implements ChatMemoryStore {
@Autowired
StringRedisTemplate redisTemplate;
// 以会话id作为缓存的key
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String message = redisTemplate.opsForValue().get(memoryId.toString());
return ChatMessageDeserializer.messagesFromJson(message);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
redisTemplate.opsForValue().set(memoryId.toString(), ChatMessageSerializer.messagesToJson(list));
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(memoryId.toString());
}
}长期记忆实现后,需要将该内容配置到记忆对象中,与短期记忆不同,这里需要实现一个对话记忆提供对象ChatMemoryProvider,并且在对象中配置对话存储实现类以及记忆id。
java
@Autowired
RedisChatStoreService redisChatStoreService;
@Bean
public ChatMemoryProvider chatMemoryProvider(){
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.chatMemoryStore(redisChatStoreService)
.maxMessages(30)
.build();
}
};
}在service红需要在@AiService注解中,需要指定上述定义的会话记忆提供者chatMemoryProvider。并且在流式调用的方法中指定记忆id。@MemoryId表示该字段为记忆id,@UserMessage表示为该字段为用户对话的内容。
less
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
// chatMemory = "chatMemory" // 配置会话记忆
chatMemoryProvider = "chatMemoryProvider"
)
......
Flux<String> chatFlux(@MemoryId String memoryId, @UserMessage String content);配置完成后,当再次发起对话时,对话的内容已经被存储到redis当中了,这样即使重启,也不会导致记忆内容丢失。 

总结
LangChain4j 是专为 Java 开发者设计的 AI 应用开发框架,相当于 Python中的LangChain。它简化了大模型在Java应用中的集成。核心优势在于提供简洁的 API 支持对话管理、RAG(后面会涉及到)、工具调用等高级功能。同时支持多种 AI 服务提供商,并可与 Spring Boot 等主流 Java 框架无缝集成,让企业级应用快速获得 AI 能力而无需重构技术栈。