摘要
https://arxiv.org/pdf/2512.16913
在本工作中,我们提出了一个泛化于不同场景距离的全景度量深度基础模型。我们从数据构建和框架设计的角度探索了数据闭环范式。我们通过结合公开数据集、来自我们UE5模拟器的高质量合成数据、文本到图像模型以及来自网络的真实全景图像,收集了一个大规模数据集。为了减少室内/室外和合成/真实数据之间的域差距,我们引入了一个三阶段伪标签生成流水线,为未标注图像生成可靠的真实标签。对于模型,我们采用DINOv3-Large作为主干网络,因其强大的预训练泛化能力,并引入了即插即用的范围掩码头、以锐度为中心的优化和以几何为中心的优化,以提高对不同距离的鲁棒性,并强制多视图间的几何一致性。在多个基准测试(例如Stanford2D3D、Matterport3D和Deep360)上的实验证明了强大的性能和零样本泛化能力,在多样化的真实场景中具有特别鲁棒和稳定的度量预测。项目页面位于:https://insta360-researchteam.github.io/DAP_website/
1. 引言
全景深度估计因其对周围环境的全方位360∘×180∘360^{\circ}\times180^{\circ}360∘×180∘覆盖为空间智能带来的好处而受到越来越多的关注。它有利于各种机器人应用,例如导航任务中的全向避障。
尽管其重要性,全景深度估计仍然落后。无论是特定于全景的相对/尺度不变方法(例如,Panda9、Depth Anywhere44、DA225)还是统一的度量深度(DAC 15、Unik3D 32)框架,都难以泛化到多样化的真实世界场景,特别是室外场景。一个可能的原因是现有数据的规模和多样性有限,这源于数据收集和标注的高昂成本。
受此启发,我们探索了全景深度估计的数据闭环范式,这提出了数据扩展的两个关键挑战:构建具有可靠、高质量真实标签的大规模数据集,以及设计能够有效适应这种数据扩展的模型。解决这两个挑战对于构建几何一致且可泛化的全景基础模型至关重要。
在数据层面,我们整合了室内数据集Structured3D52,使用基于UE5的AirSim360模拟器14合成了90K个高质量的室外样本,从互联网收集了约170万个未标注的全景图像,并通过DiT36013生成了20万个室内全景图。为了减少室内/室外和合成/真实数据之间的域差距导致的性能下降,我们提出了一个两阶段伪标签生成流水线。在第一阶段,我们在Structured3D和AirSim360的平衡混合数据上训练一个场景不变标注器,然后为190万个未标注图像生成伪标签。在第二阶段,我们使用一个判别器在室内和室外场景中选择前60k个置信度最高的伪标注样本,并在这个扩展的数据集上训练真实感不变标注器,以细化伪标签。最后,在第三阶段,我们的基础模型DAP在所有标注数据和由真实感不变标注器生成的细化伪标签数据上联合训练。
对于基础模型设计,我们采用度量深度估计,因其可扩展到任意距离的全景图。我们使用DINOv3-Large作为编码器,以利用其强大的预训练视觉先验,并使用传统的深度头模块进行密集估计49。我们进一步引入了一组损失函数,以增强对距离的鲁棒性和跨视角的几何一致性。具体来说,我们提出了一个轻量级的深度范围掩码头,通过使用距离阈值(例如,10/20/50/100米)以即插即用的方式过滤区域,从而减轻深度分布不均的问题。此外,我们通过失真感知地图设计了Silog、DF-Gram、梯度、法线和点云损失,以补偿等距柱状投影中非均匀的像素几何特性。
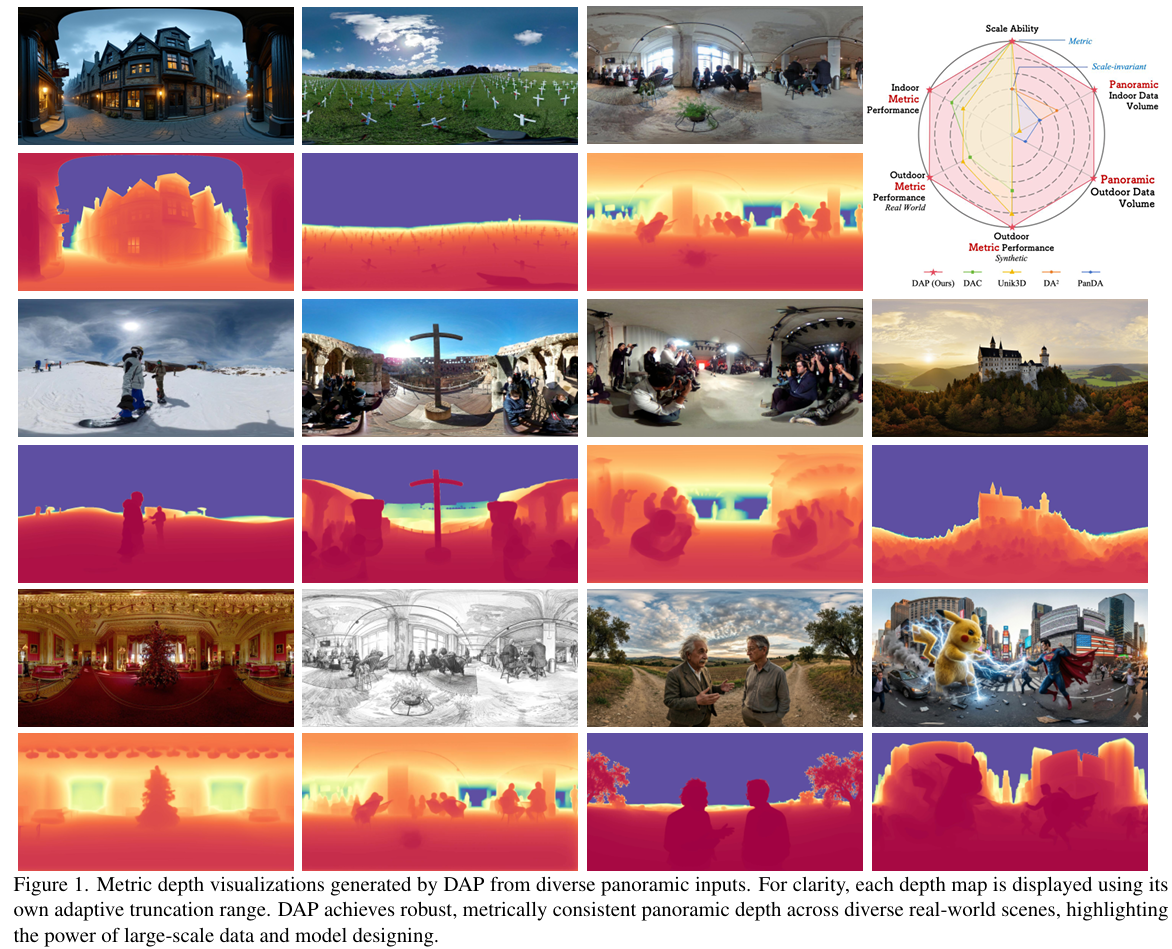
在室内和室外测试集(例如Stanford2D3D、Matterport3D和Deep360)上进行的大量实验证明了我们的基础模型在不同基准测试上的强大泛化能力和有效性。除了定量的优越性,如图1所示,我们的模型表现出出色的视觉一致性和尺度感知能力,在具有复杂几何结构、远距离区域和天空区域的挑战性真实场景中生成逼真的深度预测。这些结果突出了模型对合成和真实环境的鲁棒性和强适应性。总之,主要贡献可总结如下:
-
我们构建了一个大规模全景数据集,包含超过200万个合成域和真实域的样本。它包括来自Structured3D的高质量室内数据、使用基于UE5的AirSim360模拟器渲染的90K张逼真室外全景图,以及从互联网和DiT360收集和生成的190万张过滤后的全景图,实现了多样化且可扩展的深度监督。
-
我们设计了一个三阶段流水线,通过逐步细化伪标签,并弥合合成-真实和室内-室外的域差距。这是通过多种数据筛选技术和大规模半监督学习实现的,以增强跨域泛化能力。
-
我们结合了一个即插即用的范围掩码以及以几何和锐度为中心的优化,其中相关的损失项(LSILog,LDF,Lgrad,Lnormal,Lpts)(\mathcal{L}{S I L o g},\mathcal{L}{D F},\mathcal{L}{g r a d},\mathcal{L}{n o r m a l}, \mathcal{L}_{p t s})(LSILog,LDF,Lgrad,Lnormal,Lpts),确保了不同全景图的度量一致性和结构保真度。
综合评估表明,我们的模型能很好地泛化到开放的真实世界场景,生成尺度一致且感知连贯的深度图。它在合成基准测试的定量评估和多样化真实世界全景图的定性评估中都达到了最先进的性能。
2. 相关工作
透视深度估计。随着深度学习和大规模透视深度数据集的快速发展,透视深度估计取得了快速进展,最近的度量和尺度不变模型(如UniDepth31, 33、Metric3D18, 50、DepthPro8和MoGe46, 47)表现出强大的性能。一些相对深度估计方法极大地受益于数据扩展,例如DepthAnything48, 49模型展示了令人印象深刻的零样本泛化能力。最近,一些方法在有限但高质量的数据集上对具有强大先验能力的大型预训练生成模型(如Stable Diffusion17, 35和FLUX7)进行微调,取得了有竞争力的结果16, 21, 24, 42。然而,透视范式固有地限制了感知到有限的视野(FoV),无法捕捉场景的完整360°空间几何结构。
全景深度估计。域内方法。早期方法专注于域内设置,即模型在同一数据集上进行训练和评估。为了解决等距柱状投影(ERP)的严重失真问题,主要有两个方向:失真感知设计23, 29, 36, 39, 51, 53和投影驱动策略1-3, 5, 6, 11, 20, 27, 30, 34, 37, 40。然而,过度依赖域内训练通常会导致过拟合和有限的泛化能力,这促使了最近在零样本和跨域全景深度估计方面的努力。
零样本方法。与域内训练相比,零样本全景深度估计由于更强的泛化能力,对于跨域应用更为实用。现有方法可分为三类:第一类利用预训练的透视深度模型为全景图生成伪标签,如Depth Anywhere43和PanDA9,它们通过立方体投影或在大规模未标注全景图上的半监督学习来蒸馏知识。最近,DA225通过透视到ERP转换和基于扩散的外绘来扩展训练数据,并结合失真感知Transformer,提高了零样本性能。第三类工作旨在实现通用的、具备度量能力的相机建模:Depth_Any_Camera15通过几何驱动的增强,在ERP表示下统一了多样化的成像几何结构,而UniK3D32使用谐波射线表示在球坐标中重新表述深度,以增强宽视野的泛化能力。
3. 方法
我们引入了一个可扩展的全景深度基础模型,该模型统一了跨不同域和场景类型的度量估计。我们的方法包括三个主要部分:一个用于跨合成和真实全景图进行数据扩展的大规模数据引擎(第3.1节),一个用于有效利用大规模未标注数据的三阶段流水线(第3.2节),以及一个具有多损失优化的几何一致性网络设计,用于高质量的度量深度估计(第3.3节)。
3.1. 数据引擎
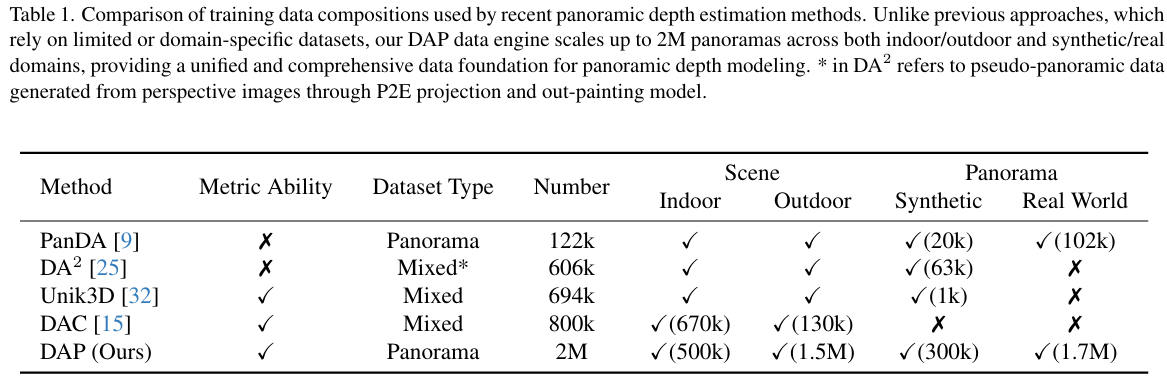
概述。为了实现全景深度估计的扩展,我们构建了一个全面的数据引擎,统一了合成域和真实域的多种数据源,如表1所示。与之前全景深度方法(如PanDA9、UniK3D32和DAC15)使用的数据集相比,我们的数据引擎实现了最大的全景规模,约200万个样本,以及最广泛的域覆盖范围,涵盖室内/室外和合成/真实世界全景图。它通过支持大规模监督和半监督学习,成为构建我们基础模型的基石。
模拟室外场景数据。为了解决室外全景监督数据稀缺的问题,我们使用高保真仿真平台Airsim36014构建了一个名为DAP-2M-Labeled的合成室外数据集。我们模拟无人机在中低空轨迹上飞越多样化环境,以在真实的照明和环境条件下捕获全景图像和相应的深度图。总共从五个具有代表性的室外场景(包括纽约市、旧金山市、Downtown West、城市公园和罗马)收集了超过90K个具有像素对齐深度标注的全景帧,涵盖了超过26,600个完整的全景序列。
未标注数据。我们从互联网收集了250K个全景视频并将其处理为图像帧。经过仔细的筛选程序并过滤掉具有不合理地平线的样本后,我们获得了总共170万张高质量的全景图像。然后,我们使用大型多模态模型Qwen2-VL45自动将这些全景图分类为室内和室外场景,产生了大约25万张室内样本和145万张室外样本。由于室内全景图在真实世界数据中相对稀缺,我们进一步使用最先进的全景生成模型DiT36013生成了额外的20万张室内样本。这些集合共同构成了我们的DAP-2M-Unlabeled,为预训练和半监督学习提供了丰富的多样化环境覆盖。
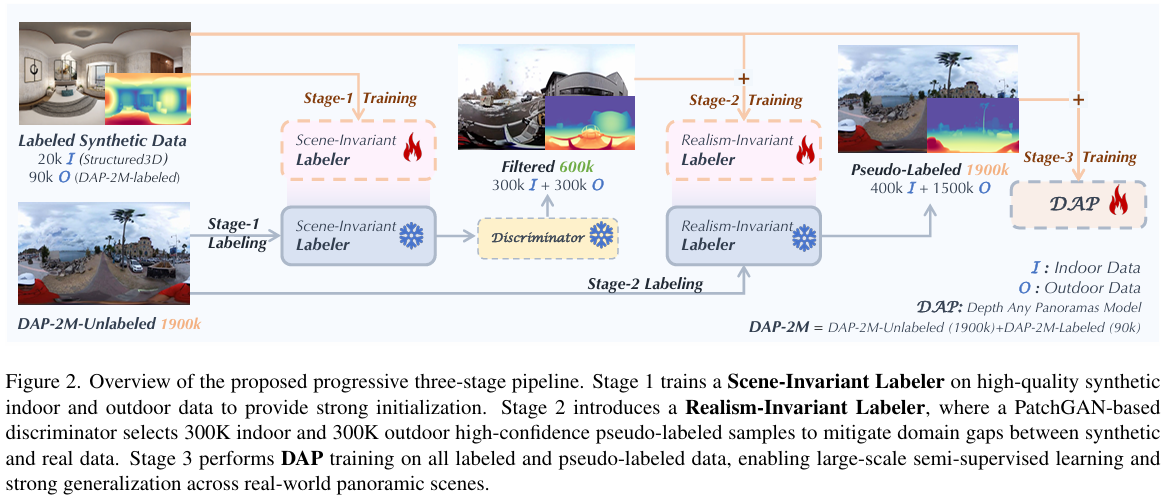
3.2. 三阶段流水线
如图2所示,我们采用一个三阶段流水线来有效利用真实世界中的大规模未标注数据,同时通过几何和密集细节监督范式来增强网络的学习能力。我们的流水线包括三个阶段:
阶段1:场景不变标注器训练。我们首先在具有精确度量深度标注的2万张合成室内和9万张合成室外数据集上训练一个场景不变标注器。此阶段的目标是学习一个能泛化于室内和室外环境的标注模型,而不是过度拟合特定的场景布局或光照条件。在几何和光度多样化的合成场景上进行训练,使标注器能够学习一致的、基于物理的深度线索,从而跨域泛化,为在真实世界全景数据上生成可靠的伪深度标签提供了鲁棒的初始化。
阶段2:真实感不变标注器训练。我们首先预训练一个深度质量判别器来评估深度预测的可靠性,其中合成的真实深度图被视为正样本,而场景不变标注器的输出被视为负样本,这一步使判别器能够学习一个与场景无关的质量先验,用于后续的过滤。更多细节,请参阅补充材料。接下来,我们将场景不变标注器应用于所有未标注的真实图像,并使用训练好的判别器评估深度质量。排名前30万的室内和30万室外样本被选为高置信度伪标注数据,这些数据与阶段1的合成数据集结合,用于训练真实感不变标注器。通过学习跨不同真实域的可靠伪标签,该标注器对外观变化和真实感特定差异变得鲁棒,使其能够泛化到合成纹理和光照条件之外。
阶段3:DAP训练。如表2所示,我们的Depth Any Panorama(DAP)模型在真实感不变标注器生成的所有190万伪标注数据以及之前的标注数据上进行训练。这使得DAP模型能够有效地受益于密集特征和大规模伪监督,从而在真实世界全景深度估计上获得更好的泛化能力。
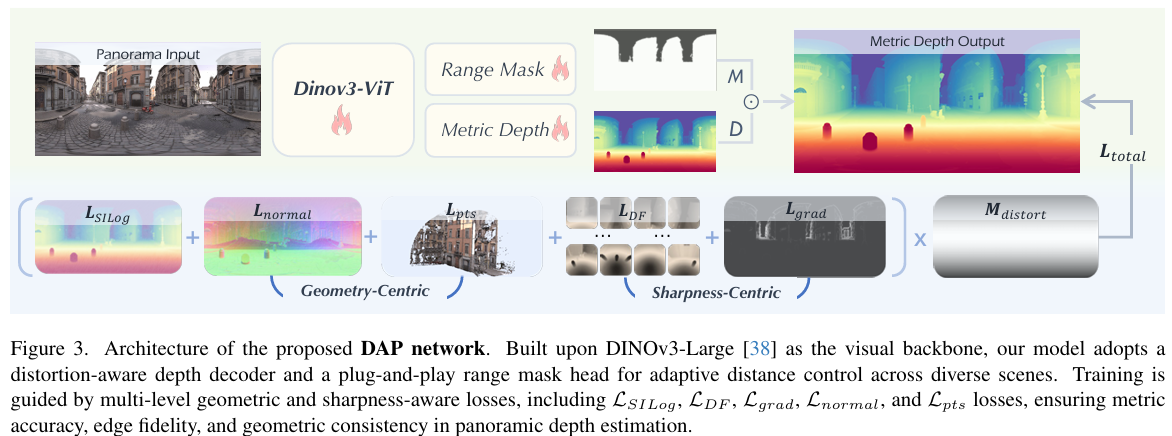
3.3. 模型设计
如图3所示,我们的DAP网络以全景图像作为输入,并使用DINOv3-Large38作为视觉主干进行强大的特征提取。我们引入了两个特定任务的头:一个范围掩码头和一个度量深度头。范围掩码头输出一个二元掩码MMM,用于定义不同距离阈值下的有效空间区域,而深度头预测一个密集的度量深度图DDD。为了适应从封闭的室内空间到大规模的室外场景的多样化环境,我们提供了四个即插即用的范围掩码头,距离阈值分别为10米、20米、50米和100米,允许灵活适应不同的空间尺度。每个范围掩码头都使用加权BCE和Dice损失的组合进行独立优化:
Lmask=∥M−Mgt∥2+0.5LDice(M,Mgt),\mathcal{L}{m a s k}=\left\|M-M{g t}\right\|^{2}+0.5\mathcal{L}{D i c e}(M,M{g t}),Lmask=∥M−Mgt∥2+0.5LDice(M,Mgt),
其中MMM和MgtM_{g t}Mgt分别表示预测的和真实的范围掩码。最终的度量深度输出通过MMM和DDD的逐元素相乘获得,确保预测在不同深度范围内保持物理有效和尺度一致。这种双头设计使得DAP能够鲁棒地适应不同的场景几何结构,并在广泛的空间条件范围内保持高质量的度量深度估计。对于优化,除了采用之前工作9中的SILog损失LSILog\mathcal{L}_{S I L o g}LSILog,我们还引入了一组互补的损失函数来增强几何一致性和边缘保真度。
以锐度为中心的优化 受38, 46启发,我们引入了一个密集保真度约束,称为LDF\mathcal{L}{D F}LDF,以增强局部锐度和结构一致性。为了缓解ERP中的几何失真,我们首先使用位于二十面体顶点处的虚拟相机将每个深度图分解为12个透视块。这些透视图保留了细粒度的细节并避免了极点附近的拉伸伪影,从而提供了更高保真度的监督。对于每个视图,我们应用一个有效掩码,归一化深度值,并计算预测深度图和真实深度图之间的基于Gram矩阵的相似度。最终的LDF\mathcal{L}{D F}LDF定义为所有N=12N=12N=12个视图的平均损失:
LDF=1N∑k=1N∥Dpred(k)⊙Dpred(k)⊤−Dgt(k)⊙Dgt(k)⊤∥F2,\mathcal{L}{D F}=\frac{1}{N}\sum{k=1}^{N}\biggl\|D_{p r e d}^{(k)}\odot{D_{p r e d}^{(k)}}^{\top}-D_{g t}^{(k)}\odot{D_{g t}^{(k)}}^{\top}\biggr\|_{F}^{2},LDF=N1k=1∑N Dpred(k)⊙Dpred(k)⊤−Dgt(k)⊙Dgt(k)⊤ F2,
其中N=12N=12N=12表示视图的数量。
面向锐度的梯度细化。为了进一步增强物体边界的锐度,我们引入了一个基于梯度的损失Lgrad\mathcal{L}{g r a d}Lgrad,该损失显式地关注ERP域中的高频边缘区域。虽然LDF\mathcal{L}{D F}LDF在无失真的透视块上增强了密集保真度,但Lgrad\mathcal{L}{g r a d}Lgrad通过直接在ERP表示中保持局部不连续性来补充它。具体来说,我们使用Sobel算子沿x和y方向计算梯度幅度图,并通过阈值化真实Sobel梯度幅度来导出一个边缘掩码MEM{E}ME。然后仅在这些掩码区域内应用梯度损失,使用SILog损失12:
Lgrad=LSILog(ME⊙Dpred,ME⊙Dgt).\mathcal{L}{g r a d}=\mathcal{L}{S I L o g}(M_{E}\odot D_{p r e d},M_{E}\odot D_{g t}).Lgrad=LSILog(ME⊙Dpred,ME⊙Dgt).
这种设计提高了深度边界的一致性和锐度,有效地补充了密集保真度约束,以恢复精细的几何细节。
以几何为中心的优化 为了提高几何一致性,我们引入了法线损失Lnormal23,25\mathcal{L}{n o r m a l}\left23,25\\rightLnormal23,25。预测和真实的深度图都被转换为表面法线场npred,ngt∈RH×W×3\mathbf{n}{p r e d},\mathbf{n}{g t}\in\mathbb{R}^{H\times W\times3}npred,ngt∈RH×W×3。Lnormal\mathcal{L}{n o r m a l}Lnormal然后定义为预测法线和真实法线之间的L1距离:
Lnormal=∥npred(i,j)−ngt(i,j)∥1.\mathcal{L}{n o r m a l}=\|\mathbf{n}{p r e d}(i,j)-\mathbf{n}{g t}(i,j)\|{1}.Lnormal=∥npred(i,j)−ngt(i,j)∥1.
我们进一步使用点云损失Lpts\mathcal{L}{p t s}Lpts。深度图被投影到球坐标系以获得3D点云Ppred,Pgt∈RH×W×3\mathbf{P}{p r e d},\mathbf{P}_{g t}\in\mathbb{R}^{H\times W\times3}Ppred,Pgt∈RH×W×3,损失定义为:
Lpts=∥Ppred(i,j)−Pgt(i,j)∥1.\mathcal{L}{p t s}=\|\mathbf{P}{p r e d}(i,j)-\mathbf{P}{g t}(i,j)\|{1}.Lpts=∥Ppred(i,j)−Pgt(i,j)∥1.
总体目标 总体训练目标是上述所有损失的加权组合,并使用了失真地图来处理等距柱状投影中的非均匀像素分布28。失真地图补偿了极点附近像素的过度表示,确保了整个球域上的梯度贡献平衡:
Ltotal=Mdistort⊙(λ1LSILog+λ2LDF+λ3Lgrad+λ4Lnormal+λ5Lpts+λ6Lmask),\begin{aligned}\mathcal{L}{total}&=M{distort}\odot\big(\lambda_{1}\mathcal{L}{SILog}+\lambda{2}\mathcal{L}{DF}+\lambda{3}\mathcal{L}{grad}\\&+\lambda{4}\mathcal{L}{normal}+\lambda{5}\mathcal{L}{pts}+\lambda{6}\mathcal{L}_{mask}\big),\end{aligned}Ltotal=Mdistort⊙(λ1LSILog+λ2LDF+λ3Lgrad+λ4Lnormal+λ5Lpts+λ6Lmask),
其中λi\lambda_{i}λi,i∈{1,2,3,4,5,6}i\in\{1,2,3,4,5,6\}i∈{1,2,3,4,5,6}表示权重参数。
4. 实验
训练数据集。如第3.1节所述,用于训练的数据集总结在表2中。我们利用了来自多样化室内和室外环境的标注和未标注数据,以增强我们模型的泛化能力。Structured3D52提供了具有真实深度监督的高质量合成室内场景。DAP-2M-Labeled包含9万张具有深度标注的真实世界样本,而DAP-2M-Unlabeled包含190万张没有深度标签的真实图像,这些数据在我们的流水线中被用于伪标签学习。对于我们的DAP模型,训练分辨率是512×1024512\times1024512×1024。
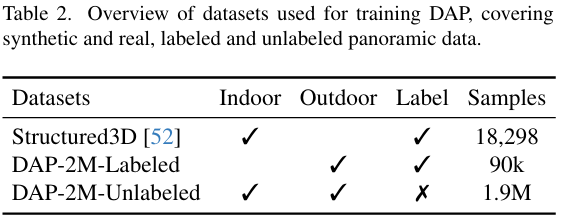
评估数据集与指标。对于评估,遵循先前工作9,我们在两个广泛使用的室内数据集Matterport3D10和Stanford2D3D4上评估我们的方法,以评估其零样本性能。对于室外场景,我们使用Deep36026作为测试集,同样在零样本设置下。由于现有的室外数据有限,我们进一步引入了一个新的基准测试DAP-Test,它包含1343张具有精确深度标注的高质量室外图像。遵循19,我们使用包括绝对相对误差(AbsRel)、均方根误差(RMSE)和百分比度量δ1\delta_{1}δ1(其中阈值i=1.25i=1.25i=1.25)在内的指标评估深度估计性能。
实现细节。所有实验均在H20 GPU上进行。对于模型训练,ViT主干的学习率设置为5e-6,解码器的学习率设置为5e-5,使用Adam优化器22。损失权重λ1\lambda_{1}λ1, λ2\lambda_{2}λ2, λ3\lambda_{3}λ3, λ4\lambda_{4}λ4, λ5\lambda_{5}λ5和λ6\lambda_{6}λ6分别设置为1.0, 0.4, 5.0, 2.0, 2.0和2.0。数据增强包括颜色抖动、水平平移和翻转,遵循9。更多细节请参阅补充材料。
4.1. 定性与定量评估
零样本性能。表3报告了在Stanford2D3D、Matterport3D和Deep360上的零样本度量深度结果。我们将我们的方法与最近的度量深度方法进行了比较,并仅作为参考列出了一些尺度不变方法。请注意,尺度不变模型在评估时需要真实深度来获取尺度,而我们的方法直接从输入全景图预测绝对度量尺度,无需任何后处理对齐。尽管如此,我们的结果仍然相当好。
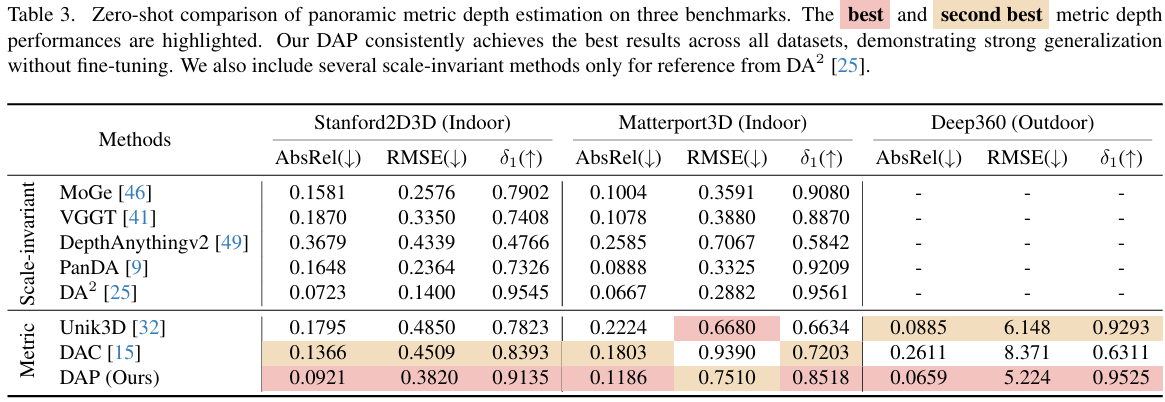
在所有三个基准测试中,DAP始终提供最佳性能。在Stanford2D3D和Matterport3D上,它显著降低了AbsRel,同时实现了明显更高的δ1\delta_{1}δ1,展示了对未见室内场景的强大泛化能力。在Deep360上,DAP获得了最低的AbsRel和RMSE以及最高的δ1\delta_{1}δ1。这些结果表明,DAP在一个单一的基础模型内统一了室内和室外全景深度估计,并且在没有任何微调的情况下达到了最先进的性能,展示了我们数据引擎的可扩展性和三阶段流水线的鲁棒性。
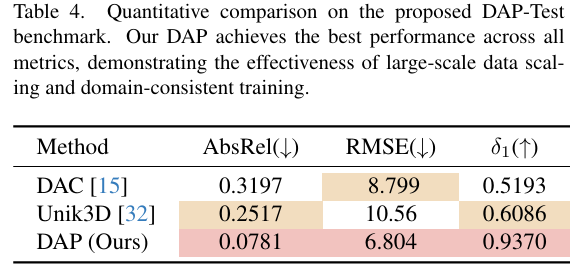
DAP-Test性能。表4展示了在我们提出的DAP-Test基准测试上的定量结果。尽管这个数据集对我们的模型来说被认为是域内数据,但它作为评估大规模数据扩展和训练策略有效性的重要手段。与之前最先进的方法相比,DAP在所有指标上都优于DAC和Unik3D。具体来说,DAP将AbsRel从0.2517降低到0.0781,将RMSE从10.563降低到6.804,同时将δ1\delta_{1}δ1从0.6086提高到0.9307。这些实质性改进证明了我们的数据引擎和统一框架在实现准确、度量一致且鲁棒的全景室外场景深度估计方面的优势。
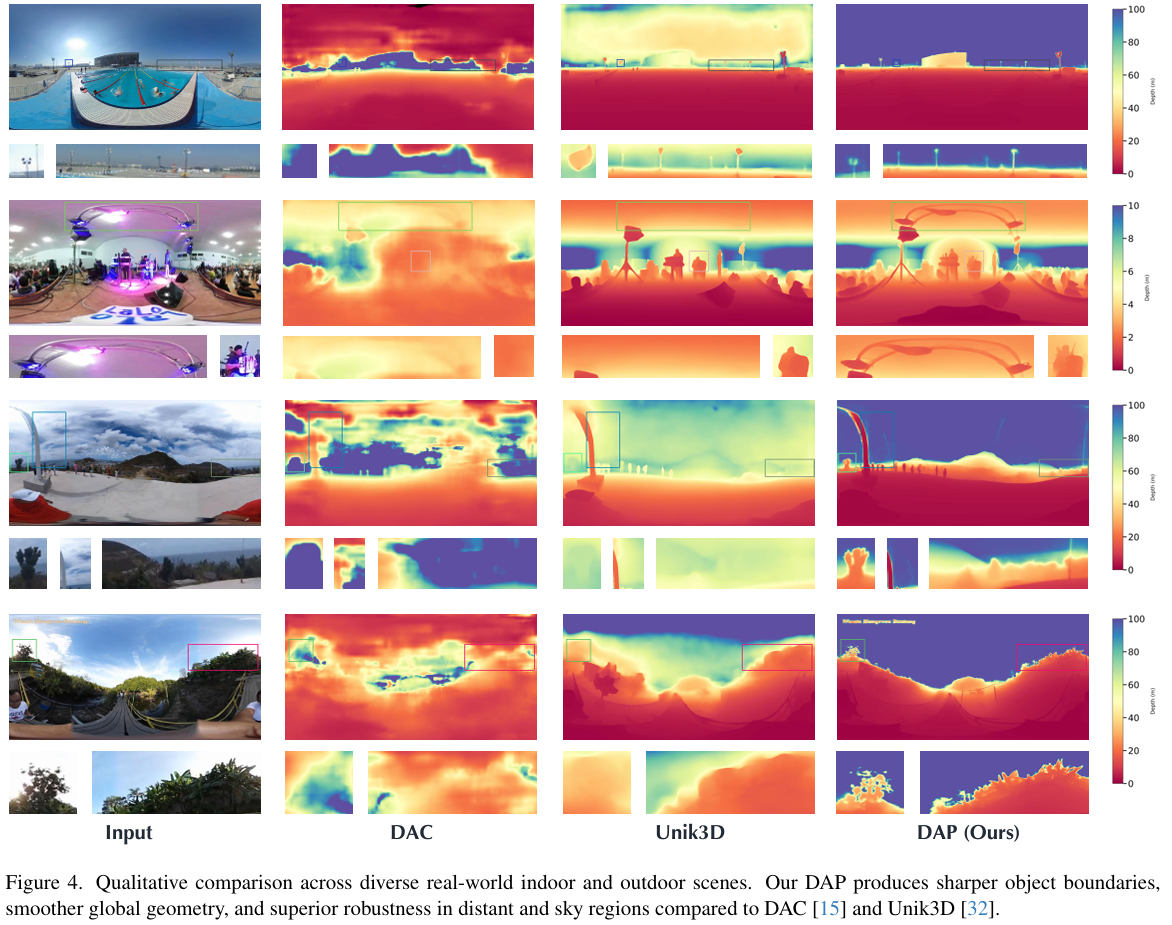
定性比较。图4展示了DAC15、Unik3D32和我们的DAP在多样室内和室外真实场景中的定性比较。与现有方法相比,DAP生成了更清晰的物体边界和更连贯的全局几何结构,特别是在具有大深度不连续性或复杂场景布局的区域。对于室内环境,我们的模型准确地保留了精细的结构细节,如家具边缘和墙壁边界,而Unik3D和DAC常常表现出过度平滑或扭曲的深度过渡。值得注意的是,尽管Unik3D在Deep360上表现良好,但其对多样化真实世界室外场景的泛化能力有限。特别是,现有方法无法在远距离区域和天空区域保持稳定的深度结构,导致扭曲或坍塌的预测。相比之下,DAP即使在如此具有挑战性的条件下也保持了强大的鲁棒性和度量一致性,实现了对近处和远处空间结构的平滑和真实表示。这些视觉结果进一步证实了我们的大规模数据训练和范围感知设计有效地提高了全景深度估计中的度量保真度和视觉真实感。

图5展示了在Stanford2D3D数据集上的定性比较。与现有方法相比,我们的方法更准确地重建了远处结构,并保持了其他模型倾向于模糊或过度平滑的精细几何细节。结果还表明我们的方法表现出更强的尺度感知能力,产生的深度和光照分布在视觉上更接近真实情况。特别是,我们预测中的远处墙壁和天花板区域保留了一致的颜色梯度和结构完整性,证明了我们基于退化感知的设计在保持全局尺度一致性的同时恢复高频细节的有效性。
4.2. 消融研究
为了公平评估我们框架中每个组件的贡献,同时最小化外部先验的影响,我们采用DINOv3-Large作为编码器,并对所有变体进行完全微调。我们进行了全面的消融研究以分析DAP中关键模块的有效性。补充材料中提供了额外的视觉比较。
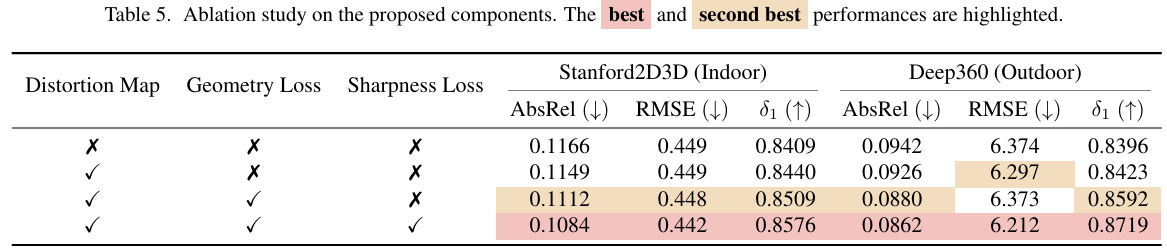
模型设计。表5总结了消融结果。从一个仅使用标准LSILog\mathcal{L}{S I L o g}LSILog损失训练的基线开始,我们逐步添加失真地图、几何一致性损失和锐度相关损失。失真地图提高了在ERP失真下的优化稳定性,而以几何为中心的损失(Lnormal和Lpts)(\mathcal{L}{n o r m a l}和\mathcal{L}{p t s})(Lnormal和Lpts)进一步增强了结构一致性。添加以锐度为中心的损失(LDF和Lgrad)(\mathcal{L}{D F}和\mathcal{L}{g r a d})(LDF和Lgrad)获得了最佳性能,在Stanford2D3D和Deep360上实现了最低的AbsRel(0.1084/0.0862)和最高的δ1\delta{1}δ1(0.8576/0.8719)。
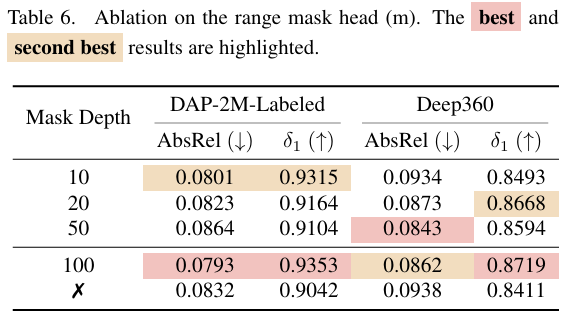
范围掩码头。我们使用10米、20米、50米和100米的阈值评估了即插即用的范围掩码头(表6),为了公平比较,将真实深度相应地进行了截断。较小的阈值(10米和20米)强调近处几何结构,在DAP-2M-Labeled上实现了δ1\delta_{1}δ1高于0.91。100米设置提供了最佳的整体平衡,在DAP-2M-Labeled和Deep360上实现了AbsRel 0.0793/0.0862和δ1\delta_{1}δ1 0.9353/0.8719。移除掩码显著降低了性能,证实了其在过滤不可靠的远距离深度预测和稳定训练方面的有效性。总体而言,范围掩码头提供了一种灵活可靠的机制,用于在不同场景尺度间保持度量一致性。
5. 结论
在本文中,我们提出了一个全景度量深度基础模型DAP,它是通过大规模数据扩展和一个统一的三阶段训练流水线构建的。通过结合可靠的伪标注、几何感知设计和一个即插即用的范围掩码头,DAP在室内-室外基准测试中实现了强大的零样本泛化和最先进的性能,在多样化的真实世界室外环境中具有特别鲁棒和稳定的度量预测。