TL;DR
- 场景:KNN/距离类模型在量纲不统一数据上效果失真,且归一化顺序易引入数据泄露
- 结论:先划分数据集;只用训练集拟合归一化参数;测试集只做 transform;交叉验证用 Pipeline 才稳
- 产出:一套可复用的 MinMaxScaler + KNN(含 distance 权重)工程流程与排错清单


归一化
距离类模型归一化要求
我们把 X 放到数据框中看一眼,是否观察到,每个特征值的均值差异很大?有的特征数值很大,有的特征数据很小,这种现象在机器学习中称为"量纲不统一",KNN 是距离类模型,欧式距离的计算公式中存在着特征上的平方和: 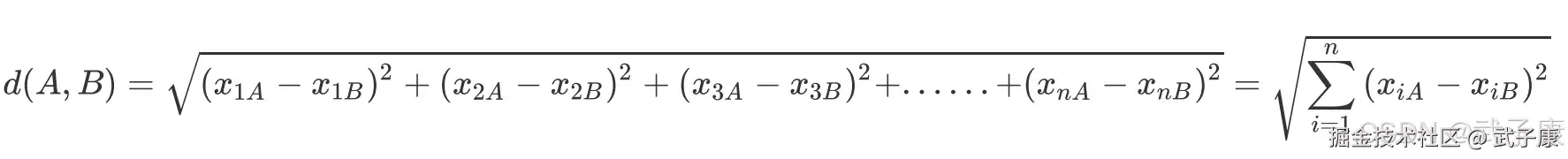 如果某个特征 Xi 的取值非常大,其他特征的取值和它比起来就不算什么,那么距离的大小很大程度上都回由这个 Xi 来决定,其他的特征之间的距离可能无法对 d(A,B)的大小产生什么影响,这种现象会让 KNN 这样的距离类模型的效果大打折扣。 然而实际分析情况中,绝大多数数据集都会存在各特征量纲不同的情况,此时若要使用KNN 分类器,则需要先对数据集进行归一化处理,即是将所有的数据压缩都同一个范围内。 当数据(X)按照最小值中心化后,再按极差(最大值-最小值)缩放,数据移动了最小值个单位,并且会被收敛到【0,1】之间,而这个过程,就称做数据归一化(Normalization,又称 Min-Max Scaling)。
如果某个特征 Xi 的取值非常大,其他特征的取值和它比起来就不算什么,那么距离的大小很大程度上都回由这个 Xi 来决定,其他的特征之间的距离可能无法对 d(A,B)的大小产生什么影响,这种现象会让 KNN 这样的距离类模型的效果大打折扣。 然而实际分析情况中,绝大多数数据集都会存在各特征量纲不同的情况,此时若要使用KNN 分类器,则需要先对数据集进行归一化处理,即是将所有的数据压缩都同一个范围内。 当数据(X)按照最小值中心化后,再按极差(最大值-最小值)缩放,数据移动了最小值个单位,并且会被收敛到【0,1】之间,而这个过程,就称做数据归一化(Normalization,又称 Min-Max Scaling)。
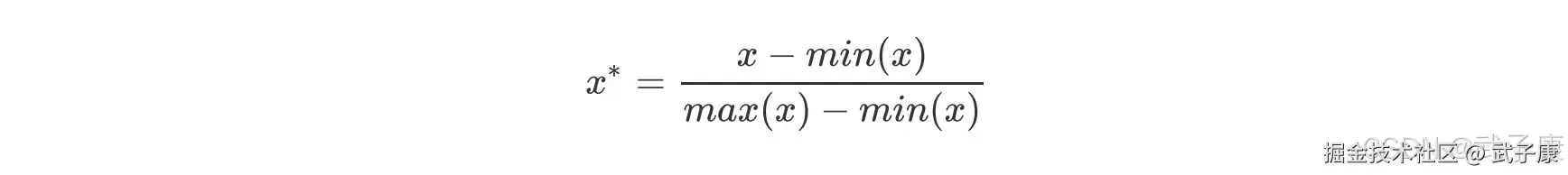
先分数据集 再做归一化
机器学习数据预处理中的归一化注意事项
错误做法分析
直接在全数据集X上进行归一化后再进行交叉验证绘制学习曲线的做法存在严重问题,这种操作会导致数据泄露(data leakage),具体表现在:
- 统计量计算错误:当使用全数据集计算归一化参数(如最小值和极差)时,这些参数实际上包含了未来测试集的信息
- 评估偏差:这种操作会使模型在交叉验证中表现异常好,但这种"好"是虚假的,因为测试集信息已经通过归一化过程泄露给了训练过程
正确做法详解
正确的数据预处理流程应该遵循以下步骤:
- 数据分割:首先将完整数据集分割为训练集和测试集(通常比例为7:3或8:2)
- 仅使用训练集计算归一化参数:在训练集上计算所需的归一化统计量(最小值、最大值、均值、标准差等)
- 应用归一化 :
- 使用训练集计算的参数对训练集本身进行归一化
- 使用相同的参数对测试集进行归一化(绝对不要在测试集上重新计算归一化参数)
- 模型训练与评估:在归一化后的数据上进行模型训练和交叉验证
现实业务场景的重要性
在实际业务中,这种规范尤为重要,因为:
- 模拟真实场景:我们永远只能基于历史数据(训练集)来构建模型,无法预先知道未来数据(测试集)的分布
- 避免过度乐观:使用错误的归一化方法会导致模型评估结果过于乐观,从而可能选择在实际应用中表现不佳的模型
- 流程一致性:生产环境中,新数据到来时也必须使用训练阶段确定的归一化参数进行处理
示例说明
假设我们有一个包含1000个样本的数据集:
- 首先分割为700个训练样本和300个测试样本
- 在700个训练样本上计算最小值为10,最大值为90(极差为80)
- 使用这些参数:
- 训练集归一化:(每个值-10)/80
- 测试集归一化:(每个值-10)/80(即使测试集中出现值5或95)
- 这样得到的评估结果才能真实反映模型在未知数据上的表现
python
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
data=pd.DataFrame(data)
(data-np.min(data,axis=0))/(np.max(data,axis=0)-np.min(data,axis=0))运行结果如下所示: 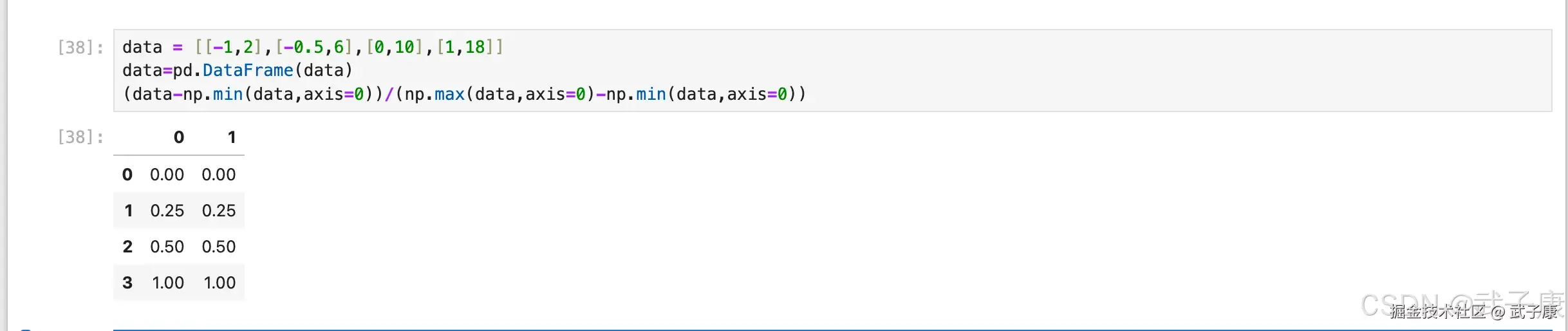
通过 sklearn 实现
python
from sklearn.preprocessing import MinMaxScaler as mms
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,y,test_size=0.2,random_state=420)
# 归一化
# 求训练集最大/小值
MMS_01=mms().fit(Xtrain)
# 求测试集最大/小值
MMS_02=mms().fit(Xtest)
# 转换
X_train=MMS_01.transform(Xtrain)
X_test =MMS_02.transform(Xtest)
score=[]
var=[]
for i in range(1,20):
clf=KNeighborsClassifier(n_neighbors=i)
# 交叉验证的每次得分
cvresult=CVS(clf,X_train,Ytrain,cv=5)
score.append(cvresult.mean())
var.append(cvresult.var())
plt.plot(krange,score,color="k")
plt.plot(krange,np.array(score)+np.array(var)*2,c="red",linestyle="--")
plt.plot(krange,np.array(score)-np.array(var)*2,c="red",linestyle="--")
plt.show()运行之后,我们查看结果如下所示: 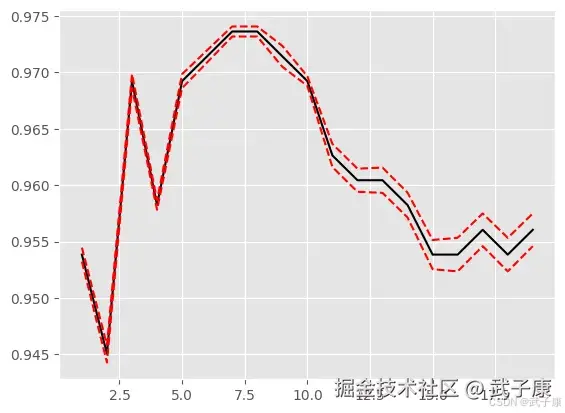
再次查看最大值,运行结果:
python
score.index(max(score))+1输出结果是: 
最终值是:7 无论 random_state取什么值,最优的 K 值都不会相差太多。
把经过交叉验证、归一化处理之后,我们得到最优 K 是 8,放在归一化后的训练集重新建模,然后在归一化后的测试集中查看结果分数:
python
clf=KNeighborsClassifier(n_neighbors=6,weights='distance').fit(X_train,Ytrain)
score=clf.score(X_test,Ytest)
score执行结果如下图所示: 
距离的惩罚
最近邻点距离远近修正在对未知样本分类过程中是一个重要的优化步骤。传统KNN模型采用"一点一票"的简单投票机制:在选取最近的K个邻居后,统计这些邻居的类别分布,每个邻居对分类结果的影响力相同。
然而这种简单投票机制存在明显缺陷。实际上,即使是K个最近邻点,它们与目标样本的距离也存在显著差异。根据KNN模型的基本假设------相似样本具有相似类别属性,距离更近的邻居往往与目标样本属于同一类别的概率更高。因此,距离较近的邻居理应比距离较远的邻居具有更大的投票权重。
举例来说,假设我们要对一个未知样本进行分类,K=5时找到的5个最近邻中:
- 3个A类样本,距离分别为0.1、0.5、1.2
- 2个B类样本,距离分别为0.2、0.3
在传统投票中A类以3:2胜出,但实际B类的两个样本距离明显更近。采用距离加权后,B类可能获得更高权重而胜出。常用的加权方式包括:
- 反比加权:权重=1/(距离+ε)
- 高斯加权:权重=exp(-距离²/σ²)
- 线性加权:权重=(最大距离-距离)/(最大距离-最小距离)
这种距离加权修正能更好地反映局部样本分布的实际情况,提高分类准确率,特别是在样本分布不均匀或存在噪声的情况下效果更为显著。
关于惩罚因子的选取有很多种方法,最常用的就是根据每个近邻 x=距离的不同对其做加权,加权方法设置 Wi 权重,该权重计算公式为:
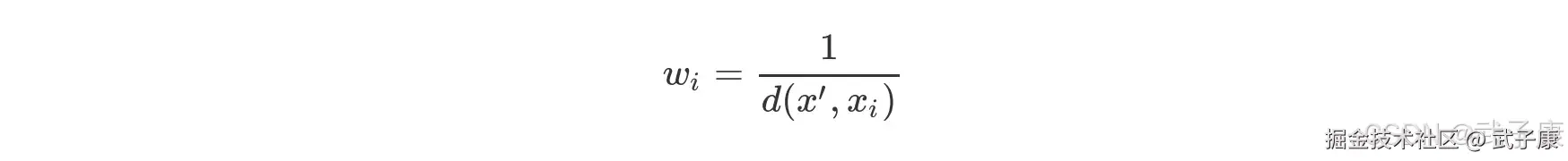 这里需要注意的是,关于模型的优化方法只是在理论上而言进行优化会提升模型判别效力,但实际应用过程中最终能否发挥作用,本质上缓释取决于优化方法和实际数据情况的契合程度,如果数据本身存在大量异常值点,则采用距离远近作为惩罚因子则会有较好的效果,反之则不然。 因此在实际我们进行模型优化的过程中,是否起到优化效果还是要以最终模型运行结果为准,在 sklearn 中,我们可以通过参数 weights 来控制是否适用距离作为惩罚因子。
这里需要注意的是,关于模型的优化方法只是在理论上而言进行优化会提升模型判别效力,但实际应用过程中最终能否发挥作用,本质上缓释取决于优化方法和实际数据情况的契合程度,如果数据本身存在大量异常值点,则采用距离远近作为惩罚因子则会有较好的效果,反之则不然。 因此在实际我们进行模型优化的过程中,是否起到优化效果还是要以最终模型运行结果为准,在 sklearn 中,我们可以通过参数 weights 来控制是否适用距离作为惩罚因子。
python
for i in range(1,20):
clf=KNeighborsClassifier(n_neighbors=i,weights='distance')
# 交叉验证的每次得分
cvresult=CVS(clf,X_train,Ytrain,cv=5)
score.append(cvresult.mean())
var.append(cvresult.var())
plt.plot(krange,score,color="k")
plt.plot(krange,np.array(score)+np.array(var)*2,c="red",linestyle="--")
plt.plot(krange,np.array(score)-np.array(var)*2,c="red",linestyle="--")
plt.show()执行结果如下所示: 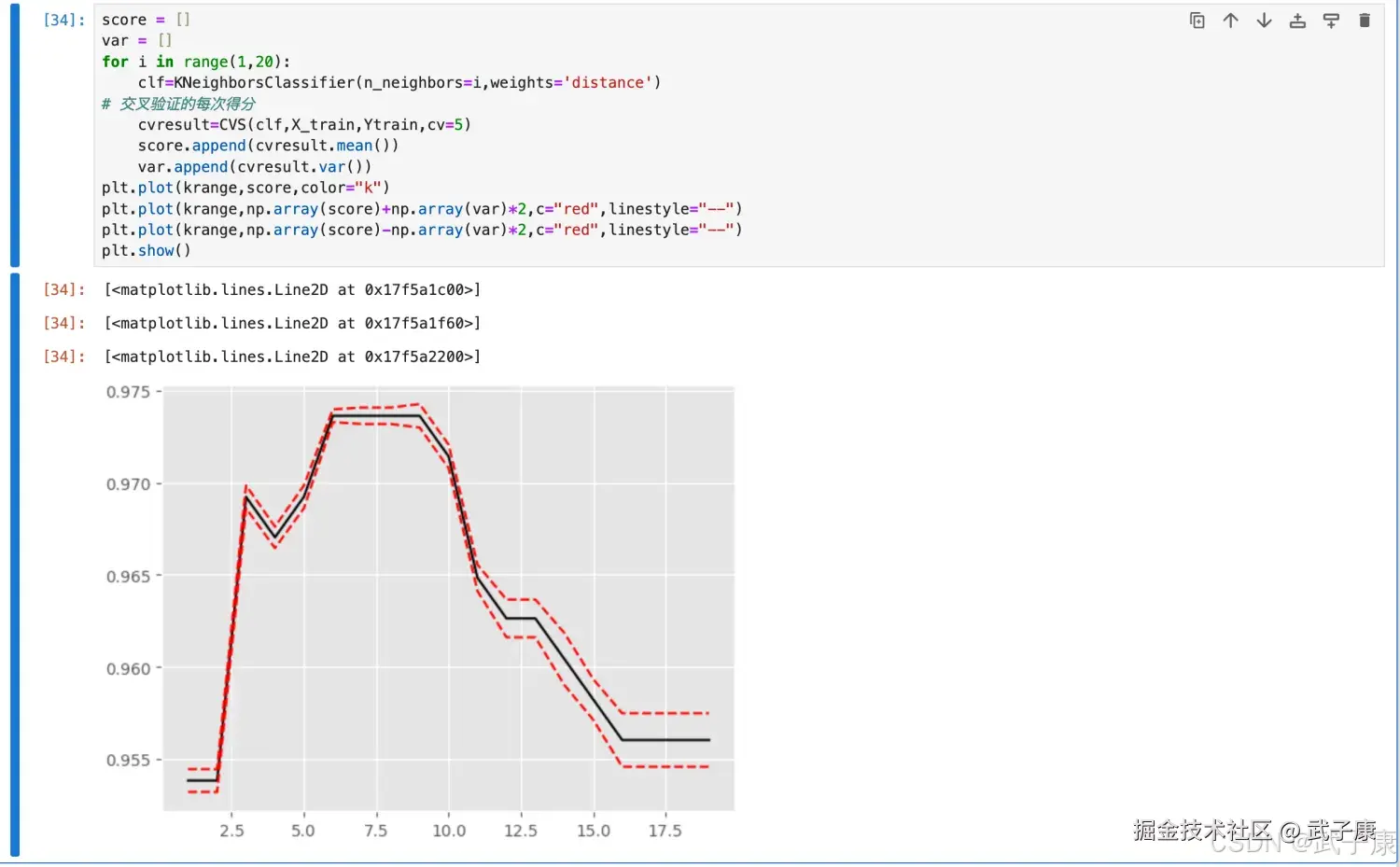 生成的图片如下所示:
生成的图片如下所示: 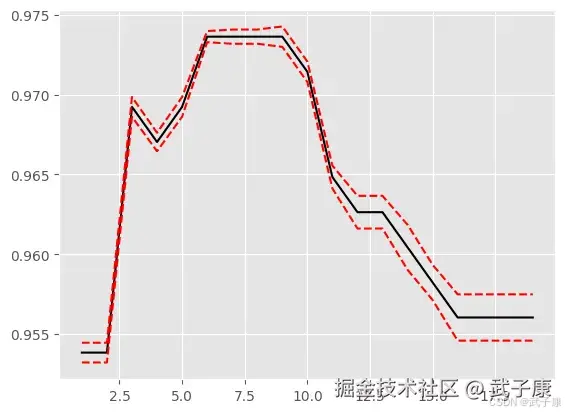 此时查看最大值:
此时查看最大值:
shell
score.index(max(score))+1输出结果如下: 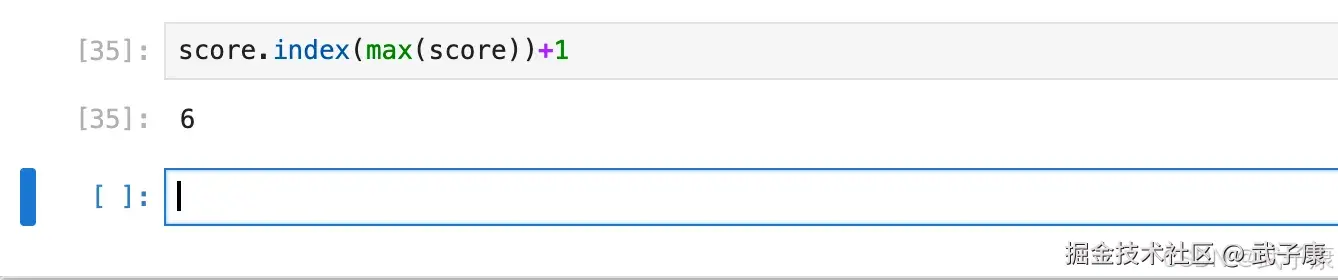
python
clf=KNeighborsClassifier(n_neighbors=6,weights='distance').fit(X_train,Ytrain)
score=clf.score(X_test,Ytest)
score执行结果如下所示: 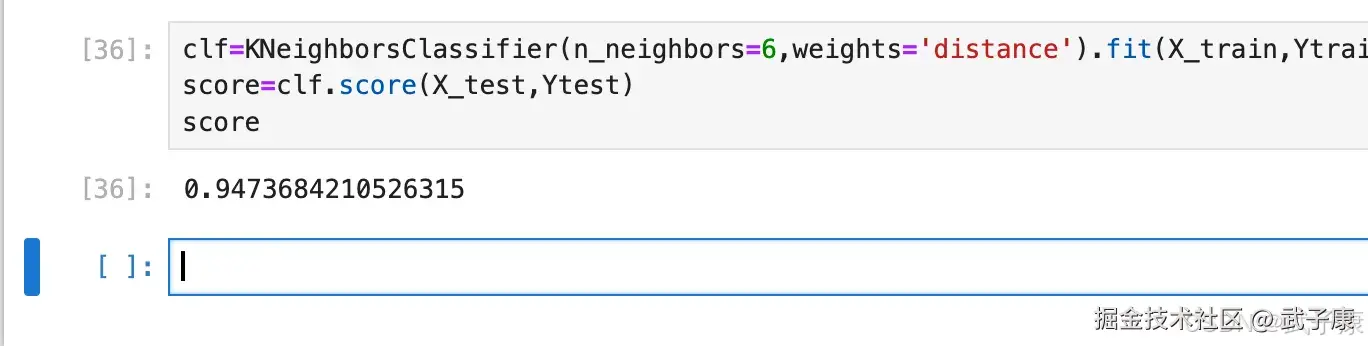
错误速查
| 症状 | 根因 | 定位方法 | 修复方案 |
|---|---|---|---|
| 交叉验证分数异常高、线上掉分明显 | 在全量 X 上 fit 归一化参数,产生 data leakage | 检查是否在 split/CV 之前 fit scaler | 先 split;仅在训练集 fit;CV 用 Pipeline(scaler+model) |
| 测试集表现不稳定、不同 random_state 波动大 | 测试集单独 fit 了 scaler(训练/测试缩放标准不一致) | 代码里出现 mms().fit(Xtest) |
测试集只用训练集 scaler 的 transform,不允许对 Xtest 再 fit |
| 训练/测试落在不同的 0,1 区间映射 | 分别拟合了两个 MinMaxScaler | 发现 MMS_01 和 MMS_02 同时存在且都 fit |
只保留一个 scaler:fit(Xtrain);两边都 transform |
| 最优 K 结论前后不一致(7/8/6 混用) | 文本与代码的 n_neighbors、index 计算未同步 | 文中"最终值是 7/最优K是8",但建模用 n_neighbors=6 |
统一口径:用同一套 score 列表与同一 n_neighbors 复现最终结论 |
| 绘图或循环报错(变量未定义/长度不匹配) | krange 未定义或与 score 长度不一致;score/var 未清空复用报 NameError 或 plot 维度错误 | 明确 krange=range(1,20);每次实验前 score=[]; var=[] |
|
| 加权 KNN 看似提升但不可复现 | 加权策略对异常点/噪声敏感,且评估流程不规范 | 对比不同 split、不同 CV 结果差异大 | 用固定评估协议:Pipeline + StratifiedKFold;同时报告均值与方差 |
| 线上新数据出现 <0 或 >1 的缩放结果被误判为错误 | 测试/线上数据超出训练集 min/max 属正常现象 | 发现 transform 后有负数或大于 1 | 保持训练期参数不变;必要时做异常值策略(截断/鲁棒缩放)并用验证集评估 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解