年底事情太多了,静下心来学习实在太不容易。Transformer已经流行到不学不行了,半个月来陆陆续续抽空学习,现将自身的理解和思考记录一下。老规矩,先上原文图:
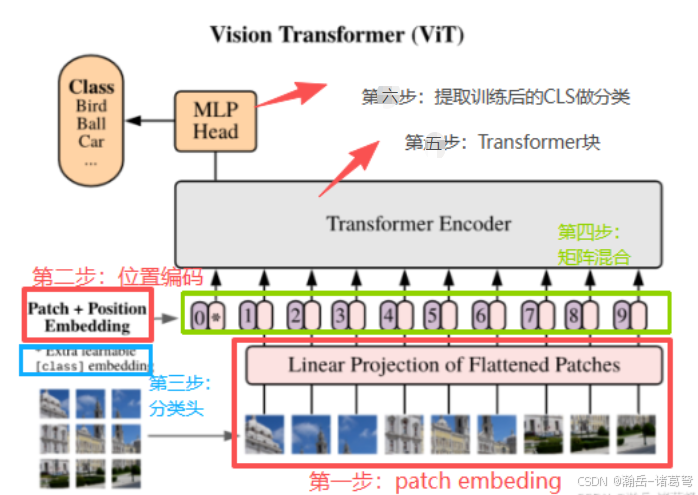
按照原文作者的说法,ViT可以理解为:通过对图像做预处理,符合原本用在NLP(自然语言处理)领域的Transformer,也可实现图像分类。
ViT可以拆分成大概6个步骤。网上很多视频、教程是写在一起的,在学习过程中,分别将这几个步骤单独进行封装,对理解和后期将其复用到视频分类中都有较大帮助。接下来,我按我的理解记录下学习的过程。依然,先上图:
画框框的就是拆分出来的各需要注意的模块。
第一步:patch embeding
将一副图片,分成尺度相同的不同小块,然后按照小块进行二维卷积的特征提取(就是将图片变成可以计算的数字)
思考1:尺度
网上所有的教程都是把img_size设置成一个int大小,这个完全可以修改,因为我们现实生活中的图像大小本来大多都是16:9的尺度,不会是正方形。如果强制进行缩放,不可避免地会造成原本图像特征的失真。所以,在我的代码中,允许图像尺度的定义,如:

这样本身就不会影响patches的计算。
思考2:特征提取

原文中的特征提取感觉太过简单,特别是stride设置为path_size的大小,这个应该会破坏卷积的平移不变性和旋转不变性,个人感觉完全可以利用经典的卷积神经网络将这块的功能给替换。这样做可能会导致embeding提取的速度降低,但感觉可以试一试,应该会有一些涨点。
思考3:patch embeding稍加修改就可以实现序列分类,如:视频
transformer天生就是为序列而生(NLP),如果将视频中的每一帧进行embeding,则可以直接套用模型。而视频帧的embeding则可以利用经典神经网络(如:ResNet101)完成。
第二步:位置编码
这里理解不深,不加位置编码,程序依然可以进行有效分类,而且我感觉在大力出奇迹的情况下,多训练几个epoch应该也没有问题。按照原文中的说法,位置信息可以完成patch之间的关联学习。但我感觉就是增加一个可学习的维度。
python
import torch
def PositionEncoding(max_length, hidden_size):#max_length表示句子里最多有多少token,hidden_size与embedding维度相等,也就是每个 token 向量的大小
pe = torch.zeros(max_length, hidden_size) # 初始化位置编码,全为0
# .unsqueeze(1)在张量的维度上增加了一个维度,使其从一维变为二维,第二维的大小为 1。这样做为了后面矩阵广播,方便和 div_term相乘
position = torch.arange(0, max_length).unsqueeze(1) # 位置信息,从0到max_length-1
# print(position)
div_term = torch.exp(torch.arange(0, hidden_size, 2)* -(torch.log(torch.Tensor([10000.0])) / hidden_size))# 计算位置编码的权重
#利用广播机制,得到一个 (max_length, hidden_size/2) 的矩阵,每个元素是 pos/ (10000^(2i/d))
# print(div_term.shape)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
print(pe.shape)
return pe不得不说,原文中的位置编码(position embeding)代码写的非常优雅。注:原文的位置编码是:固定位置编码,现在有可学习的位置编码等方式。个人觉得,用固定位置编码更好,特别是在做视频分类的时候,帧的顺序还是不能让网络去学习。效率也高。
这段代码不用去看(天才的代码思路),会用就行。
第三步:CLS(分类标记:Classfication ToKen)
CLS的实现就是一行代码,但我感觉是确是ViT对Transformer修改的神来之笔。实现非常简单,就一行代码:
python
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))CLS对我启发很大。我看到的时候在想,如果是我来做,我会怎么构建网络,我肯定只会把V全部作为输入,接上卷积和前馈神经网络最终做分类。
那CLS到底做什么用的,从数学角度上说,就是一组与path embeding相同尺度的向量。经过训练后,得到一组加权学习后的尺度不变的向量。讲人话就是:CLS是融合所有path embeding训练后的特征。
第四步:矩阵融合
没啥说的,比较简单,就是构建一个矩阵。CLS+Position Embeding+Patch Embeding
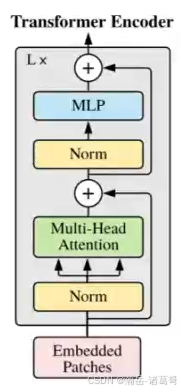
第五步:Transformer块
多头注意力block,按照原图搭就完了,网上很多教程全是手写,其实torch.nn.MultiHeadAttention提供了现成的封装,用起来也简单。
第六步:提取训练后的CLS,接MLP做分类
这步就简单了,就是一个前馈神经网络(多层感知机),代码如下:
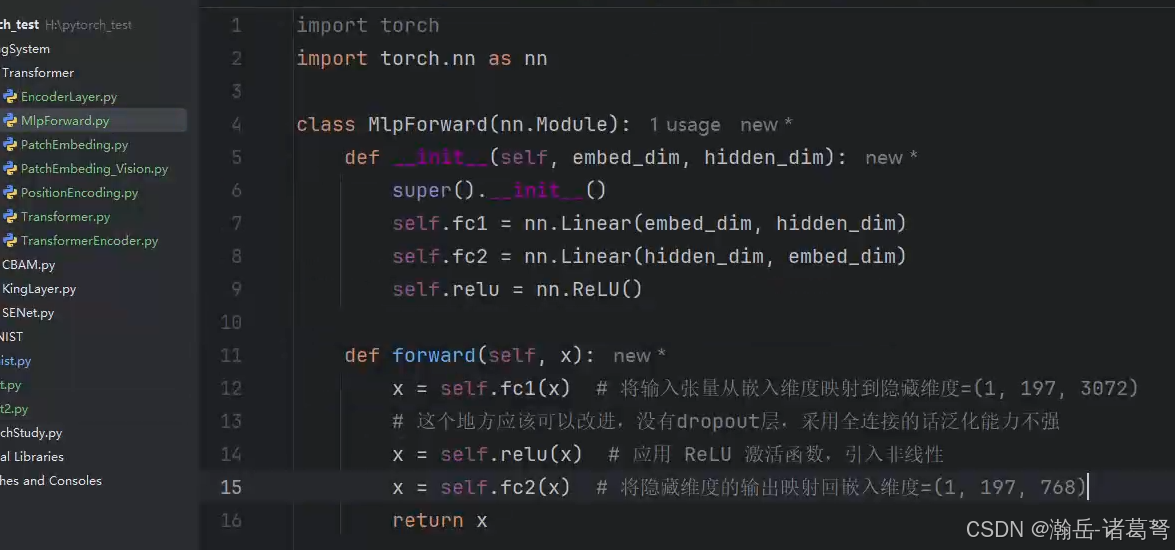
感觉transformer这块的实现也好简单,不知道为什么,连个dropout层也没有,有点想不通。按照道理来说transformer的设计人员有如此之多的神来之笔,这块为什么不加点优化呢?是没必要?如果按照768维来说的确没啥必要,但如果维度一高呢?感觉还是必须的。需要实验来论证。
拓展思路(运用于行为识别):
-
通过关键帧提取或者时间窗口,将不定长视频,采样为帧数固定的序列
-
提取骨架(或直接利用骨架图片),用之前的特征建模方法,或者直接将图片给embeding(由于图片的尺度较大,可以利用经典神经网络来提取深度特征)
-
CLS和Position embeding,transformer block保持原文的方法
-
MLP稍微修改一下,出结果