1. String类的重要性
C 语言依赖字符数组/指针和标准库函数来处理字符串,但这种数据和操作分离的方式难以满足面向对象编程的需求。鉴于字符串的广泛应用,Java 专门引入了 String 类,它将字符串数据及其操作方法封装成一个整体,提供了面向对象且更易用的字符串解决方案。
2. String常用操作
2.1 字符串的构造
字符串的构造一般使用下面三种方式进行构造:
java
String s1 = "hello";
String s2 = new String("hello");
char[] array = {'h','e','l','l','o'};
String s3 = new String(array);其在内存中的分布图可以大致认为是如下图的情况:
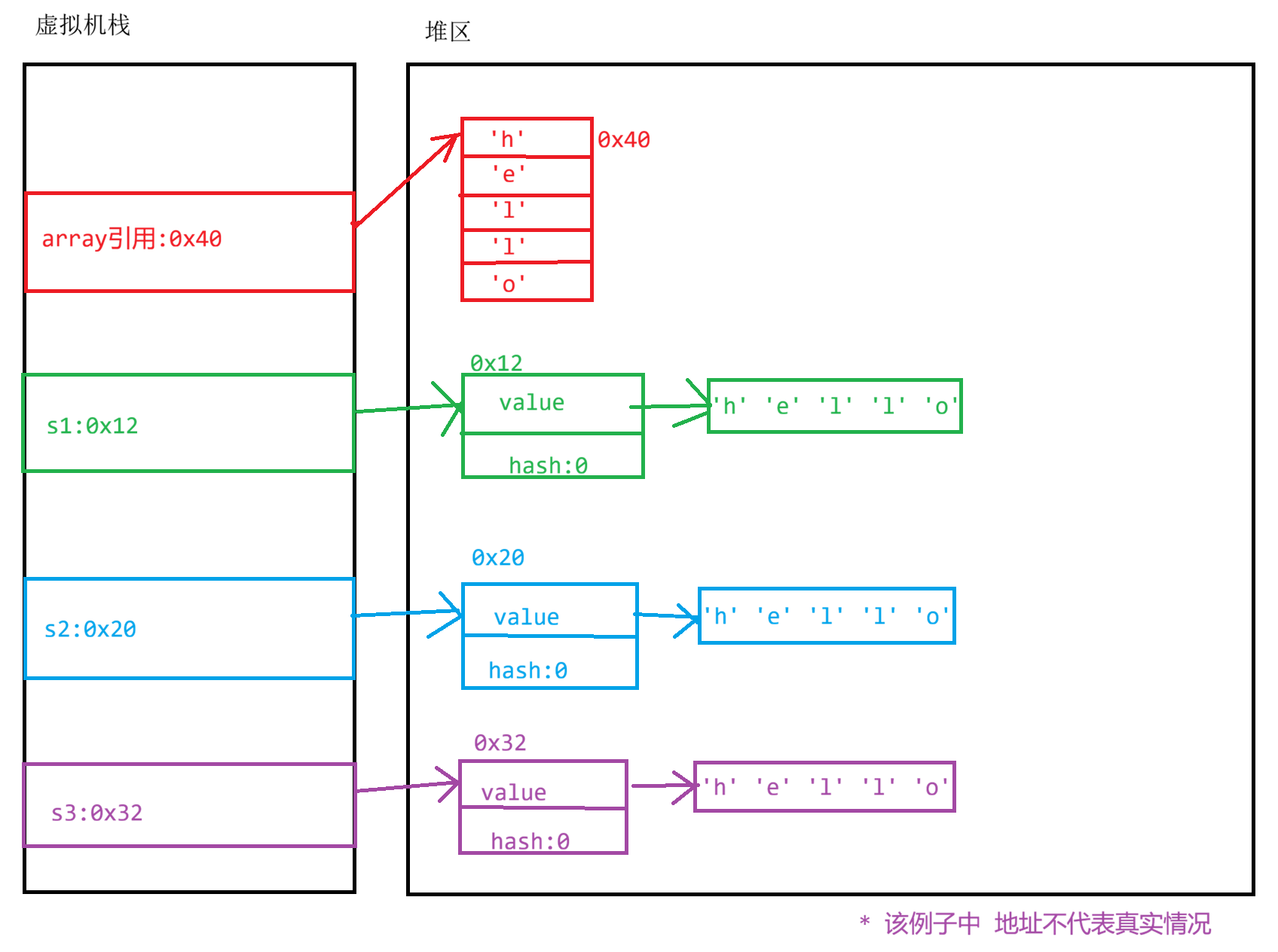
按照这个逻辑,你可能会产生一个疑问:s3 是通过传入 array 数组来构造的,但为什么 s3 和 array 却不是同一个对象呢?
要解开这个疑惑,我们需要深入 String 的构造过程:
当执行 new String(array) 时,JVM 的处理过程其实是一个深拷贝 。它会在堆内存中创建一个新的 String 对象,并将原始 array 数组的内容 完整地复制一份,用这份新的副本来初始化 String 对象内部私有的 value 字符数组。因此,s3 和 array虽然数据相同,但内存地址完全不同,是两个独立的对象。
2.2 String 对象的比较
2.2.1 使用 == 比较
在Java的String中,使用 == 进行比对两个实例化的String对象,对比的是两个对象的引用是否一致,
比对的值是对象的地址,而不是对象中具体的值
java
public static void main(String[] args) {
String s1 = new String("hello");
String s2 = new String("hello");
if ( s1 == s2 ) {
System.out.println("s1 = s2");
} else {
System.out.println("s1 != s2");
}
String s3 = s2;
if (s2 == s3) {
System.out.println("s2 == s3");
} else {
System.out.println("s2 != s3");
}
System.out.println("s1" + " @" + identityHashCode(s1));
System.out.println("s2" + " @" + identityHashCode(s2));
System.out.println("s3" + " @" + identityHashCode(s3));
/*identityHashCode(s1) 返回的值 是根据对象的内存地址 (虚拟地址)进行计算后的结果
能够做到比对对象是否是同一对象、每一个不同对象的结果都是唯一的 如图对象的身份ID */
}运行输出:
bash
s1 != s2
s2 == s3
s1 @1283928880
s2 @999966131
s3 @999966131通过结果可以发现,s1 与 s2 并不是同一个对象 ,而s2 s3 是同一对象,这与代码中一致。
2.2.2 equals 方法
在编程语言中、我们通常使用 == 来判断两个对象的值是否相等、但是 == 并不是万能的、在String的字符串对比中、就不能做到、它只能用于对比两个对象的地址是否一致、而无法直接通过 == 来判断内部的值是否相等、那么,如果我们想要比对两个对象中的值是否一致、可以通过使用 equals 来进行判断
方法定义:
javapublic boolean equals(Object anObject)作用:用于比较两个字符串对象的内容是否相等
使用方法:
java字符串对象.equals(待比较对象)返回值:布尔类型
结果:
如果内容一致: 返回ture
如果内容不一致:返回 flase
经典案例:
java
public static void main(String[] args) {
String s1 = new String("hello");
String s2 = new String("hello");
if (s1 == s2) {
System.out.println("s1 = s2");
} else {
System.out.println("s1 != s2");
}
if (s1.equals(s2)) {
System.out.println("s1 = s2");
} else {
System.out.println("s1 != s2");
}
}输出结果:
java
s1 != s2
s1 = s2通过图片来了解:
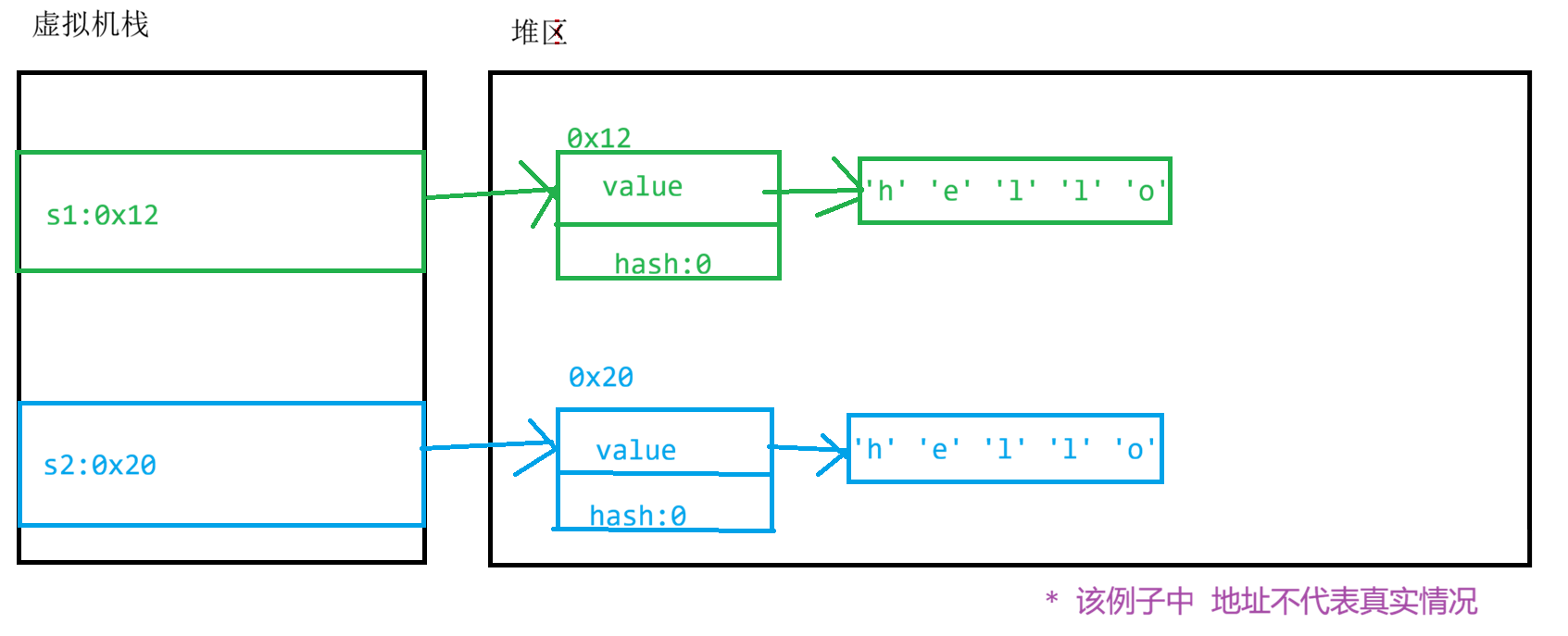
如图所示,很明显,s1与s2的存储地址是不同的、而如果直接使用 == 来比对两个对象、对比的是对象的地址是否相同,而不是其值
而通过 equals 比对s1 与 s2 的值 ,由于 s1 与 s2 的内容完全相同、所以输出 等于。
但是有一个特殊场景如下:
java
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
if (s1 == s2) {
System.out.println("s1 = s2");
} else {
System.out.println("s1 != s2");
}
if (s1.equals(s2)) {
System.out.println("s1 = s2");
} else {
System.out.println("s1 != s2");
}
}当运行这段代码时,你会发现一个有趣的现象:s1 == s2 竟然输出了 true。
我们之前才说过,== 比较的是对象的内存地址。那这里难道不是比较地址吗?
其实,它比较的确实是地址------而且 s1 和 s2 的地址完全一样。这是怎么回事呢?
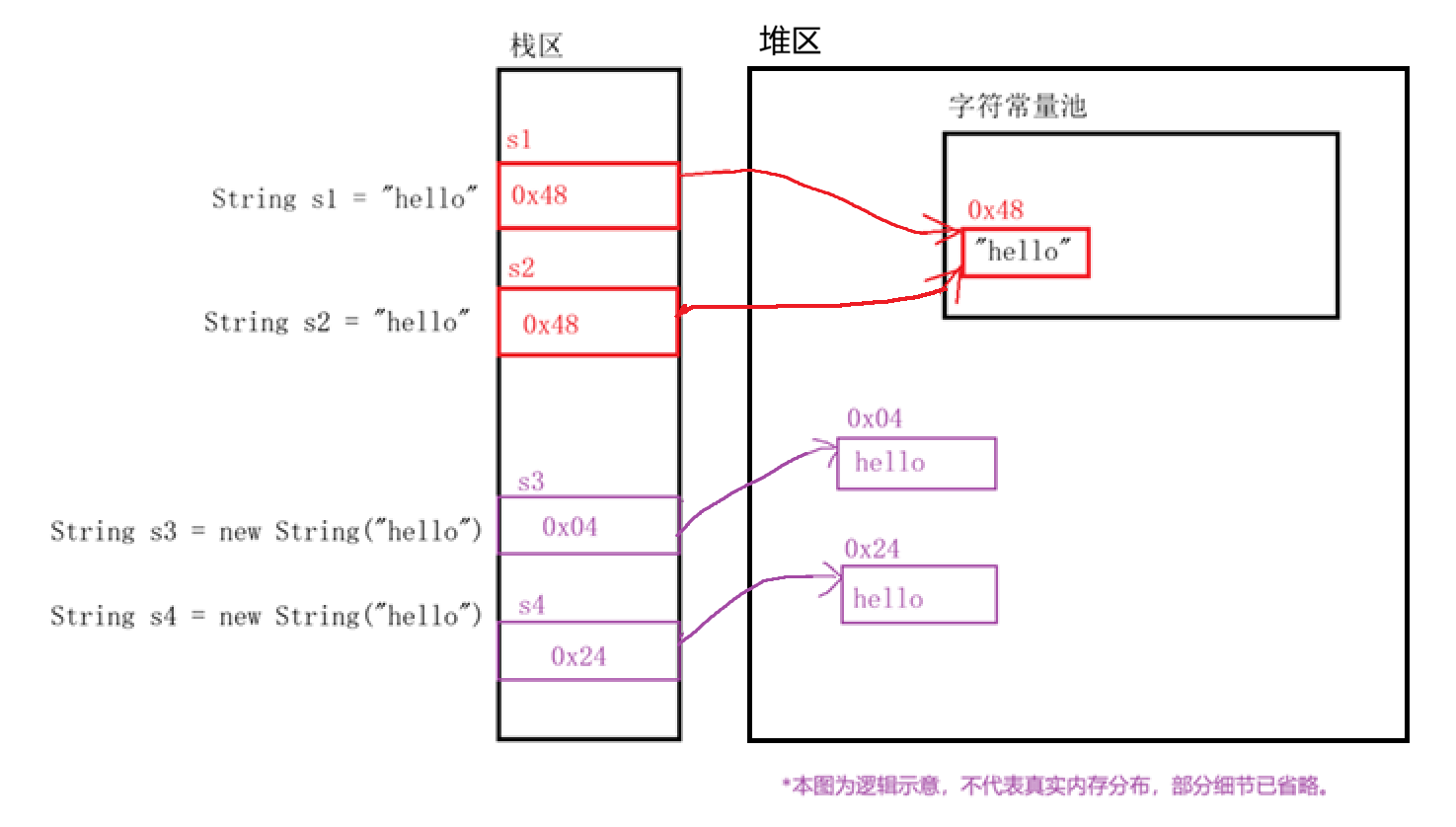
这就要说到 JVM 的一个巧妙设计:字符串常量池。
你可以把它想象成 JVM 内存中的一个"字符串缓存区"。当 JVM 遇到字符串字面量时,它不会急着创建新对象,而是先去这个池子里查一查:
-
String s1 = "hello"; JVM 在常量池里搜寻,没找到 "hello",于是创建一个新对象并放入池中。
-
String s2 = "hello"; JVM 再次搜寻,发现池中已有 "hello",于是直接复用,把引用赋给 s2。
所以 s1 和 s2 指向的是同一个对象,地址自然相同。
但问题又来了:为什么用 new String("hello") 创建的字符串,地址就不一样了呢?
这是因为 new 关键字会绕过常量池 。每次执行 new,JVM 都会在堆内存中创建一个全新的对象,无论常量池里是否已经存在相同的字符串。
换句话说:
- 字面量方式 → 复用常量池 → 地址相同
new方式 → 强制新建对象 → 地址不同
如果还是难以理解,可以对照下图进行辅助理解:
2.2.3 CompareTo 方法
与equals不同的是,equals返回的是boolean类型,而compareTo返回的是int类型。具体比较方式如下:
在Java中,String类的compareTo方法(定义为public int compareTo(String anotherString))用于实现字符串的自然顺序比较 ,返回int值表示两个字符串的相对大小差值,常用于排序、集合比较等场景。与equals不同,equals仅检查内容相等(返回boolean),而compareTo计算大小关系(返回整数)。
方法定义:
javapublic int compareTo(String anotherString)作用:用于比较两个字符串对象的大小差值(主要用于排序或比较对象顺序)
使用方法:
java字符串对象.compareTo(待比较对象)返回值:int
比较规则:
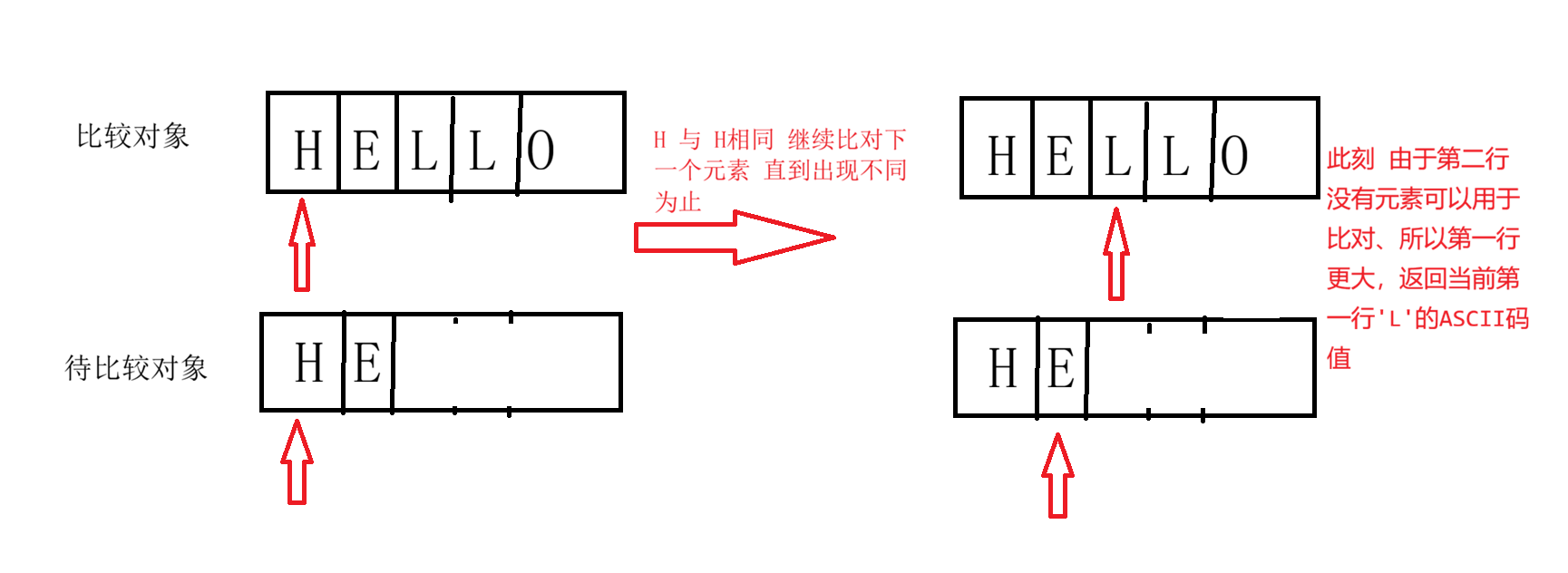
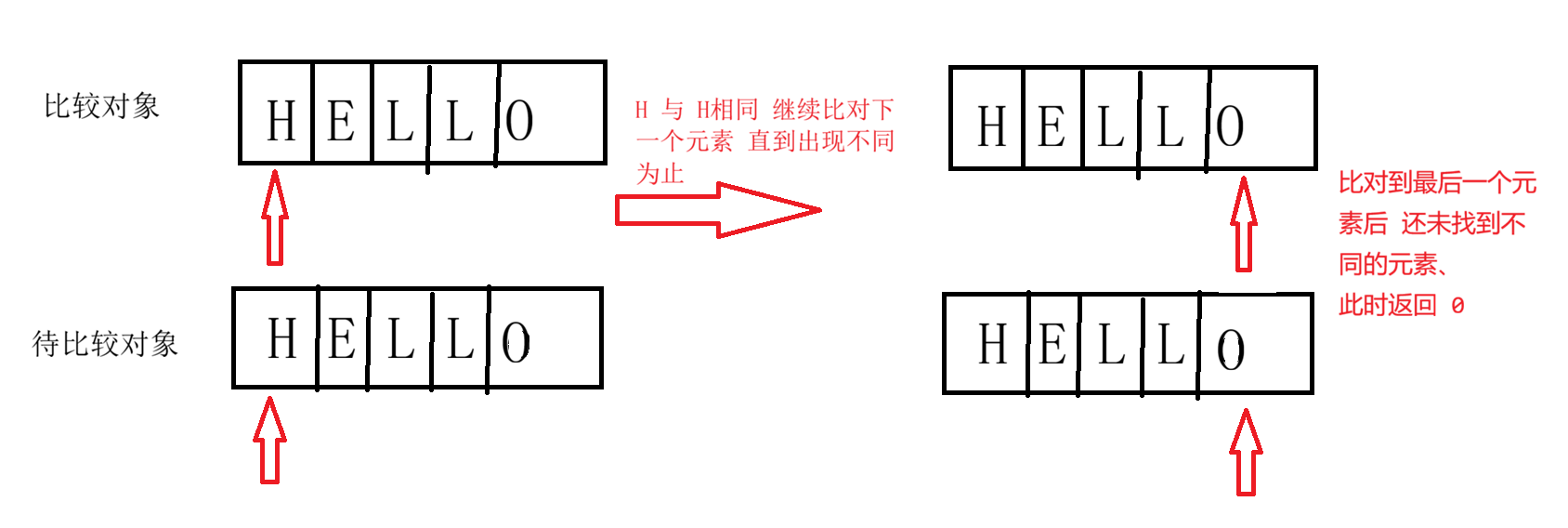
- 逐字符比较Unicode值,直到发现不同字符或结束。
- 如果一个字符串是另一个的前缀(如
"java"vs"javascript"),较短的视为"小",返回长度差值("java".compareTo("javascript")→ 返回-4)。- 区分大小写(大写ASCII值小于小写):
"A".compareTo("a")→ 返回-32。结果:
- 负整数(如-1):当前对象"小于"指定对象。
- 零(0):当前对象"等于"指定对象。
- 正整数(如1):当前对象"大于"指定对象。
比较规则 可视化图例:
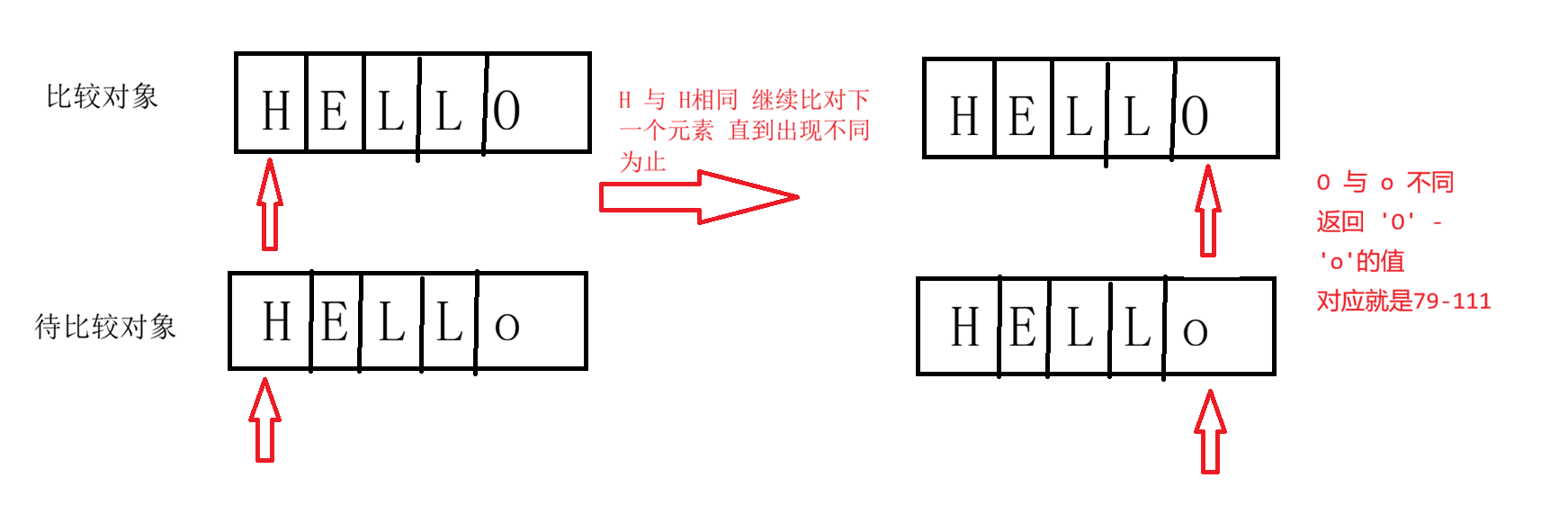
如果长度不同:
如果元素相同:
2.3 字符串查找
在Java中,String类提供了丰富的查找方法,用于在字符串中定位字符或子字符串。这些方法基于索引(index)进行操作,索引从0开始计数。
- 如果查找失败,通常返回-1;
- 如果索引无效(如负数或超出字符串长度),会抛出
IndexOutOfBoundsException异常。
查找方式分为从前向后查找 (indexOf系列)和从后向前查找 (lastIndexOf系列),支持指定起始位置(fromIndex)以优化搜索。
以下表格整理出了一些常用的查找方法:
1. 字符查找方法(查找单个字符)
这些方法针对Unicode字符(int类型),常用于定位特定字符位置。
| 方法签名 | 功能描述 | 参数说明 | 返回值 | 注意事项 |
|---|---|---|---|---|
int indexOf(int ch) |
从字符串开头查找指定字符ch第一次出现的位置。 |
ch:要查找的Unicode字符(如'A'或65)。 |
字符首次出现的索引(0-based);如果未找到,返回-1。 | 字符区分大小写;ch可以是ASCII或Unicode值。 |
int indexOf(int ch, int fromIndex) |
从指定位置fromIndex开始,向后查找字符ch第一次出现的位置。 |
ch:要查找的字符;fromIndex:起始索引(包含)。 |
从fromIndex开始的首次出现索引;如果未找到或fromIndex >= 字符串长度,返回-1。 |
fromIndex < 0时视为0;如果fromIndex太大,可能跳过整个字符串。 |
int lastIndexOf(int ch) |
从字符串末尾向前查找指定字符ch第一次出现的位置(即最后一个出现位置)。 |
ch:要查找的字符。 |
字符最后一次出现的索引;如果未找到,返回-1。 | 适用于查找后缀或逆向定位;同样区分大小写。 |
int lastIndexOf(int ch, int fromIndex) |
从指定位置fromIndex开始,向前(向左)查找字符ch第一次出现的位置。 |
ch:要查找的字符;fromIndex:起始索引(包含)。 |
从fromIndex向前的首次出现索引;如果未找到或fromIndex < 0,返回-1。 |
fromIndex >= 字符串长度时视为字符串末尾;用于精确控制搜索范围。 |
2. 子字符串查找方法(查找字符串片段)
这些方法一般用于查找整个子字符串。
| 方法签名 | 功能描述 | 参数说明 | 返回值 | 注意事项 |
|---|---|---|---|---|
int indexOf(String str) |
从字符串开头查找指定子字符串str第一次出现的位置。 |
str:要查找的子字符串(不能为空)。 |
子字符串首次出现的起始索引;如果未找到,返回-1;如果str为空字符串,返回0。 |
子字符串必须连续匹配;区分大小写;如果str长度为0,返回0(空串视为匹配开头)。 |
int indexOf(String str, int fromIndex) |
从指定位置fromIndex开始,向后查找子字符串str第一次出现的位置。 |
str:要查找的子字符串;fromIndex:起始索引(包含)。 |
从fromIndex开始的首次出现起始索引;如果未找到或fromIndex >= 字符串长度,返回-1。 |
fromIndex < 0时视为0;优化长字符串搜索,避免全扫描。 |
int lastIndexOf(String str) |
从字符串末尾向前查找指定子字符串str第一次出现的位置(即最后一个出现位置)。 |
str:要查找的子字符串。 |
子字符串最后一次出现的起始索引;如果未找到,返回-1;如果str为空,返回字符串长度。 |
适用于查找后缀或逆向匹配;空子字符串返回字符串长度。 |
int lastIndexOf(String str, int fromIndex) |
从指定位置fromIndex开始,向前(向左)查找子字符串str第一次出现的位置。 |
str:要查找的子字符串;fromIndex:起始索引(包含)。 |
从fromIndex向前的首次出现起始索引;如果未找到或fromIndex < 0,返回-1。 |
fromIndex >= 字符串长度时视为字符串末尾;用于精确逆向搜索。 |
3. 位置访问方法(辅助查找结果)
这些方法常与查找方法结合使用,用于获取查找结果的具体字符或验证位置。
| 方法签名 | 功能描述 | 参数说明 | 返回值 | 注意事项 |
|---|---|---|---|---|
char charAt(int index) |
返回指定索引位置的字符。 | index:要获取的字符索引(0-based)。 |
指定位置的字符。 | 如果index < 0 或 index >= 字符串长度,抛出IndexOutOfBoundsException;常用于验证查找结果。 |
由于方法太多,这里不作演示。
2.4 字符串的转化
2.4.1 大小写字符的转化
使用**toUpperCase( )**方法 可以将指定对象中的元素 全部转换成大写;
使用**toLowerCase( )**方法 可以将指定对象中的元素 全部转换成小写
java
public static void main(String[] args) {
String s1 = "hello";
String s2 = s1.toUpperCase();// 将s1中的元素转换成大写
String s3 = s2.toLowerCase();// 将s2中的元素转换成小写
System.out.println(s1);
System.out.println(s2);
System.out.println(s3);
}2.4.2 数值和字符串的类型转化
使用String.valueOf( ) 方法 可以将指定对象中的元素 转换成字符串形式
*String.valueOf() 可以直接传入基本数据类型(如int、double)或对象(如自定义类实例),返回对应的字符串表示。
java
public static void main(String[] args) {
int i1 = 123; // 整型数值
double d1 = 3.14; // 浮点数值 String sI1 = String.valueOf(i1); // 转换为 "123"
String sD1 = String.valueOf(d1); // 转换为 "3.14"
// 对于自定义对象 String dog = String.valueOf(new Dog("xiaoHuang", 6)); // 默认调用对象的toString()
System.out.println(sI1); // 输出: 123
System.out.println(sD1); // 输出: 3.14
System.out.println(dog); // 输出: Dog@<hashcode> (未重写toString时)
}
class Dog {
String name;
int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
}输出:
123
3.14
Dog@776ec8df
那么为什么可以通过该方法将基本数据类型转换成字符串类型呢?
通过查看JDK源码(java.lang.String类),可以发现String.valueOf(Object obj) 的实现非常简洁:
java
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}当调用这个方法后,传入的对象给 obj,返回值便是 obj.toString()。所以究其本质,是调用了 toString 方法来进行转换。
基于该方法,我们可以通过重写 toString 来做到指定自定义内容的转换。
java
public static void main(String[] args) {
int i1 = 123;
double d1 = 3.14;
String sI1 = String.valueOf(i1);
String sD1 = String.valueOf(d1);
String dog = String.valueOf(new Dog("xiaoHuang", 6));
System.out.println(sI1); // 输出: 123
System.out.println(sD1); // 输出: 3.14
System.out.println(dog); // 输出: Dog{name='xiaoHuang', age=6} (重写 toString 后)
}
class Dog {
String name;
int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}输出:
123
3.14
Dog{name='xiaoHuang', age=6}
2.5 字符串替换
使用 String.replace() 方法可以将字符串中的指定字符或子字符串替换成新的内容。
String.replace() 支持字符替换(char)或字符串替换(String),返回替换后的新字符串(原字符串不变)。常用变体包括 replaceAll()(支持正则)和 replaceFirst()(只替换第一个)。
java
public static void main(String[] args) {
String s1 = "hello word";
// 将所有 word 替换成java
String s2 = s1.replace("word","java");
System.out.println("s2:" + s2);
// 将所有 l 替换成 a
String s3 = s1.replace("l","a");
System.out.println("s3:" + s3);
// 变体:replaceFirst() *只替换第一个
String s4 = s1.replaceFirst("l","o");
System.out.println("s4:" + s4);
}输出:
s2:hello java
s3:heaao word
s4:heolo word
2.6 字符串拆分
使用 String.split() 方法可以将字符串按照指定分隔符拆分成字符串数组。
String.split() 返回 String\[\] 数组,支持正则表达式作为分隔符。如果分隔符为空,将拆分成单个字符;如果字符串为空,返回空数组。
java
public static void main(String[] args) {
String ip = "192.168.0.1";
String mail = "123456@gamil.com";
//根据 '.' 分割ip地址
String[] ips = ip.split("\\.");
System.out.println("ip切割后:");
for (String s:ips) {
System.out.println(s);
}
//根据 '@' 和 '.' 分割邮箱地址
String[] mails = mail.split("[@,.]");
System.out.println("mail 切割后");
for (String s:mails) {
System.out.println(s);
}
}2.7 字符串截取
使用 String.substring() 方法可以从字符串中截取指定范围的子字符串。
String.substring(int beginIndex, int endIndex) 截取从 beginIndex(包含)到 endIndex(不包含)的部分;如果只传 beginIndex,则截取到末尾。返回新字符串,原字符串不变。
java
public static void main(String[] args) {
String str = "Hello World";
// 截取从索引 0 到 5(不包含 5)
String sub1 = str.substring(0, 5);
System.out.println(sub1); // 输出: Hello
// 截取从索引 6 到末尾
String sub2 = str.substring(6);
System.out.println(sub2); // 输出: World
}3.String的不可变性 - 详解
在Java中,String对象具有不可变性(Immutability) ,这意味着一旦一个String对象被创建,它包含的字符序列就无法被修改。
尝试修改的示例:
java
public static void main(String[] args) {
String s1 = "hello";
s1[0] = 'e'; // 编译错误!
// 错误信息: java: 需要数组, 但找到java.lang.String
}这段代码无法编译,因为Java语法规定不能通过下标操作符([])直接修改String对象的字符。那么,为什么我们不能直接修改String内部的值呢?
要理解这一点,需要先回顾String对象在JVM中的存储方式(简化模型),如下图:
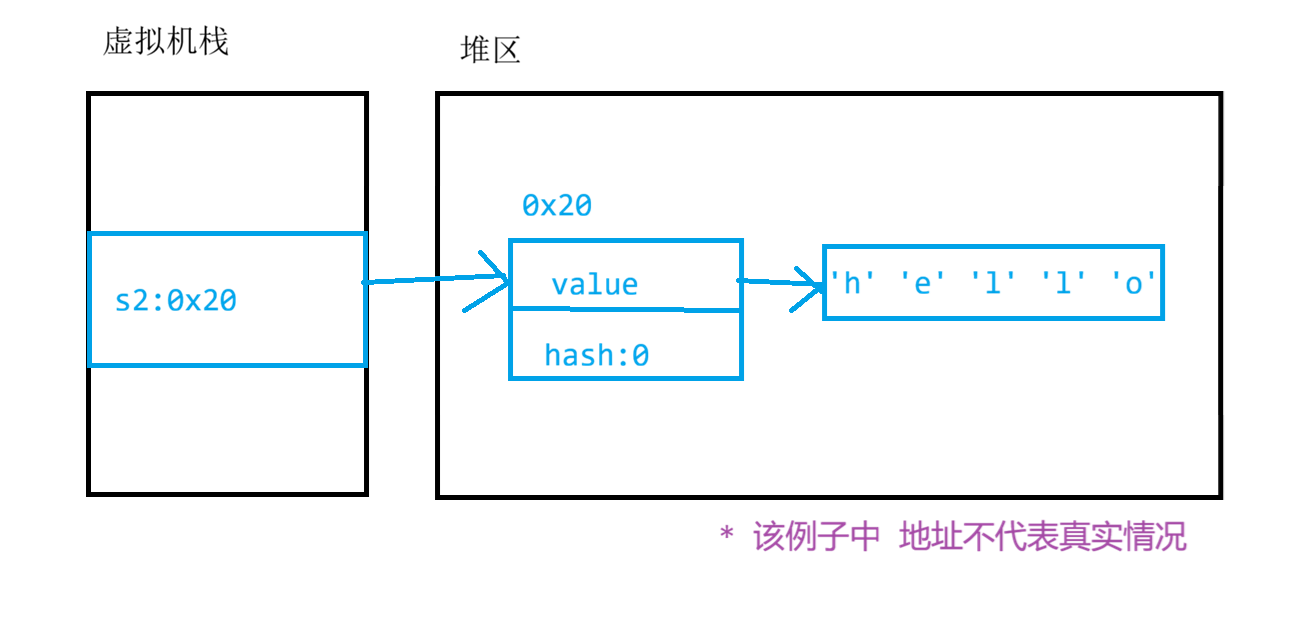
- 栈(Stack) :变量
s2存储在栈中,其值指向堆中某个String对象的引用。- 堆(Heap) :
String对象内部包含一个char[](或Java 9+的byte[])类型的value字段,用于实际存储字符数据。
s2的值本质上是这个value数组的地址引用。
因此,理论上 ,如果我们能直接拿到这个value数组的引用,并通过下标修改其元素,就能改变String的内容。
在上面知识的补充后,此刻我们再通过查看JDK源码来查找一下原因: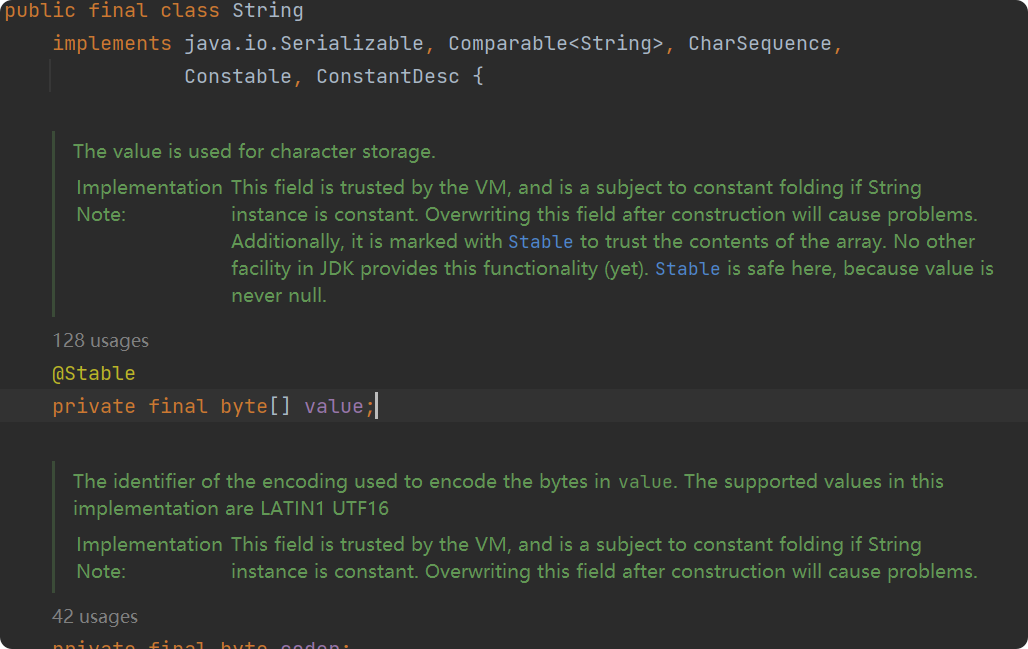
查看java.lang.String类的源码(以Java 8为例),关键部分如下:
java
public final class String ... {
private final char value[]; // Java 9+ 变为 private final byte[] value;
...
}我们看到:
value字段被private修饰:外部类无法直接访问。value字段被final修饰:引用一旦初始化(在构造函数中赋值)后,不能再指向新的数组对象。String类本身被final修饰:不能被继承,避免子类破坏不可变性。
那么原因是被final所修饰的原因吗?我们可以自己仿照写一下,看看是不是这个原因:
我们来自定义一个MyString类模拟String的核心结构,只使用final修饰数组引用:
java
import java.util.Arrays;
class MyString {
public final byte[] value;
public MyString(byte[] value) {
this.value = value;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (byte c:value) {
sb.append((char)c);
}
return sb.toString();
}
}
public static void main(String[] args) {
byte[] chars1 = {'a','b','c','d'};
MyString myString = new MyString(chars1);
System.out.println("修改前" + myString);
byte[] chars2 = {'b','c'};
myString.value = chars2;// 报错
}发现代码运行编译不通过,那么真的就是这个原因吗?其实并不是,让我们看下列代码:
java
import java.util.Arrays;
class MyString {
public final byte[] value;
public MyString(byte[] value) {
this.value = value;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (byte c:value) {
sb.append((char)c);
}
return sb.toString();
}
}
public static void main(String[] args) {
String s1 = "hello";
byte[] chars = {'a','b','c','d'};
MyString myString = new MyString(chars);
System.out.println("修改前" + myString);
myString.value[0] = 'n';
System.out.println("修改后" + myString);
}运行结果:
修改前abcd
修改后nbcd
运行后,发现可以修改?那么就说明不是被final修饰的缘故咯?那么我们再回看一下源码,是不是被 private 所修饰的缘故呢?
我们如果需要修改对应的内容,那么就需要拿到value的值 然后通过下标引用来修改,然后此刻value被private所修饰了,那么我们貌似就拿不到value的值了,那就无法修改了。是不是这样的呢?还是老样子,我们自定义实现一下,看看是不是这个原因:
java
import java.util.Arrays;
class MyString {
private byte[] value;
public MyString(byte[] value) {
this.value = value;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (byte c:value) {
sb.append((char)c);
}
return sb.toString();
}
}
public static void main(String[] args) {
String s1 = "hello";
byte[] chars = {'a','b','c','d'};
MyString myString = new MyString(chars);
System.out.println("修改前" + myString);
myString.value[0] = 'n';//value 在 MyString 中是 private 访问控制
System.out.println("修改后" + myString);
}发现编译报错,那么肯定就是这个缘故了吧?其实也不对,让我们看下面的反例代码:
java
import java.util.Arrays;
class MyString {
private byte[] value;
public MyString(byte[] value) {
this.value = value;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (byte c:value) {
sb.append((char)c);
}
return sb.toString();
}
}
public static void main(String[] args) throws Exception {
byte[] chars = {'a','b','c','d'};
MyString myString = new MyString(chars);
System.out.println("修改前:" + myString);
// 通过反射访问 private 字段
java.lang.reflect.Field valueField =
MyString.class.getDeclaredField("value");
valueField.setAccessible(true);
byte[] value = (byte[]) valueField.get(myString);
value[0] = 'n';
System.out.println("修改后:" + myString);
}运行结果:
修改前:abcd
修改后:nbcd
所以 private 修饰符也不是直接导致 String 有不可变性的缘故.
实际上,private 修饰符在 String 不可变性中起到了重要作用,但其实它并非唯一原因,String 的不可变性是多种设计共同保证的结果。
String 的不可变性并非由某一个关键字单独保证,而是由 多种设计共同作用的结果,主要包括:
-
String 内部字符数组
value被private修饰,外部无法直接访问; -
value被final修饰,引用在构造后不可再指向新的数组; -
String 类本身被
final修饰,无法被继承并通过重写方法破坏不可变性; -
不对外提供任何可以修改内部字符数组的方法;
-
字符串常量池的存在,使得不可变性成为必要前提。
正是以上多重机制的共同约束,才保证了 String 在正常使用场景下的不可变性。
4.StringBuilder & StringBuffer 的区别
| 特性 | String | StringBuilder | StringBuffer |
|---|---|---|---|
| 可变性 | 不可变 任何修改都创建新对象 | 可变 原地修改,不创建新对象 | 可变 原地修改 |
| 性能 | 低 拼接时产生大量对象 | 最高 单线程下无锁开销 | 中 有同步锁开销 |
| 适用环境 | 单线程 | 单线程 | 多线程 |
那么,对于 StringBuilder 和 StringBuffer,该如何选择呢?
这要看具体的应用场景:
如果整个场景基本是顺步执行(单线程)、不存在异步或多线程操作,那么更推荐使用 StringBuilder。因为如果无脑选用 StringBuffer,会由于反复上锁解锁,造成性能上的浪费。
下面我为了更好的了解到这三种类型的性能对比,通过下面的代码可以很直观的感受到性能的差异对比:
java
public static void main(String[] args) {
long startTime,endTime;
String s = new String("");
StringBuilder sb = new StringBuilder("");
StringBuffer sbf = new StringBuffer("");
startTime = System.currentTimeMillis();
// 测试String
for (int i = 0;i < 100000; i++) {
s += i;
}
endTime = System.currentTimeMillis();
System.out.println("String 类 运行总时长:" + (endTime - startTime) + " ms");
startTime = System.currentTimeMillis();
// 测试StringBuilder
for (int i = 0;i < 100000; i++) {
sb.append(i);
}
endTime = System.currentTimeMillis();
System.out.println("StringBuilder 类 运行总时长:" + (endTime - startTime) + " ms");
startTime = System.currentTimeMillis();
// 测试StringBuffer
for (int i = 0;i < 100000; i++) {
sbf.append(i);
}
endTime = System.currentTimeMillis();
System.out.println("StringBuffer 类 运行总时长:" + (endTime - startTime) + " ms");
}运行结果:
String 类 运行总时长:1705 ms
StringBuilder 类 运行总时长:2 ms
StringBuffer 类 运行总时长:2 ms
造成如此巨大性能差距的根本原因在于:String的不可变性导致每次修改都必须创建全新对象 ,而StringBuilder/StringBuffer通过可变数组实现原地修改。
String的过程: 以s += i为例,JVM实际执行:
- 创建新对象:分配新内存空间(原长度 + 新内容长度)
- 复制旧数据:将原字符串内容完整复制到新对象
- 追加新内容:写入新字符
- 销毁旧对象:原对象变成垃圾,等待GC回收
- 引用更新:将新对象引用赋值给变量
而StringBuilder & StringBuffer 是如下步骤:
- 检查容量:查看内部char数组剩余空间是否足够
- 直接追加 (如果空间足够):在数组末尾直接写入字符,零对象创建
- 自动扩容 (如果空间不足):
- 创建新数组(通常2倍于原容量)
- 复制原内容到新数组(仅一次)
- 追加新内容
- 注意 :扩容是按比例增长,10万次操作仅扩容约15次,而非每次重建
*end