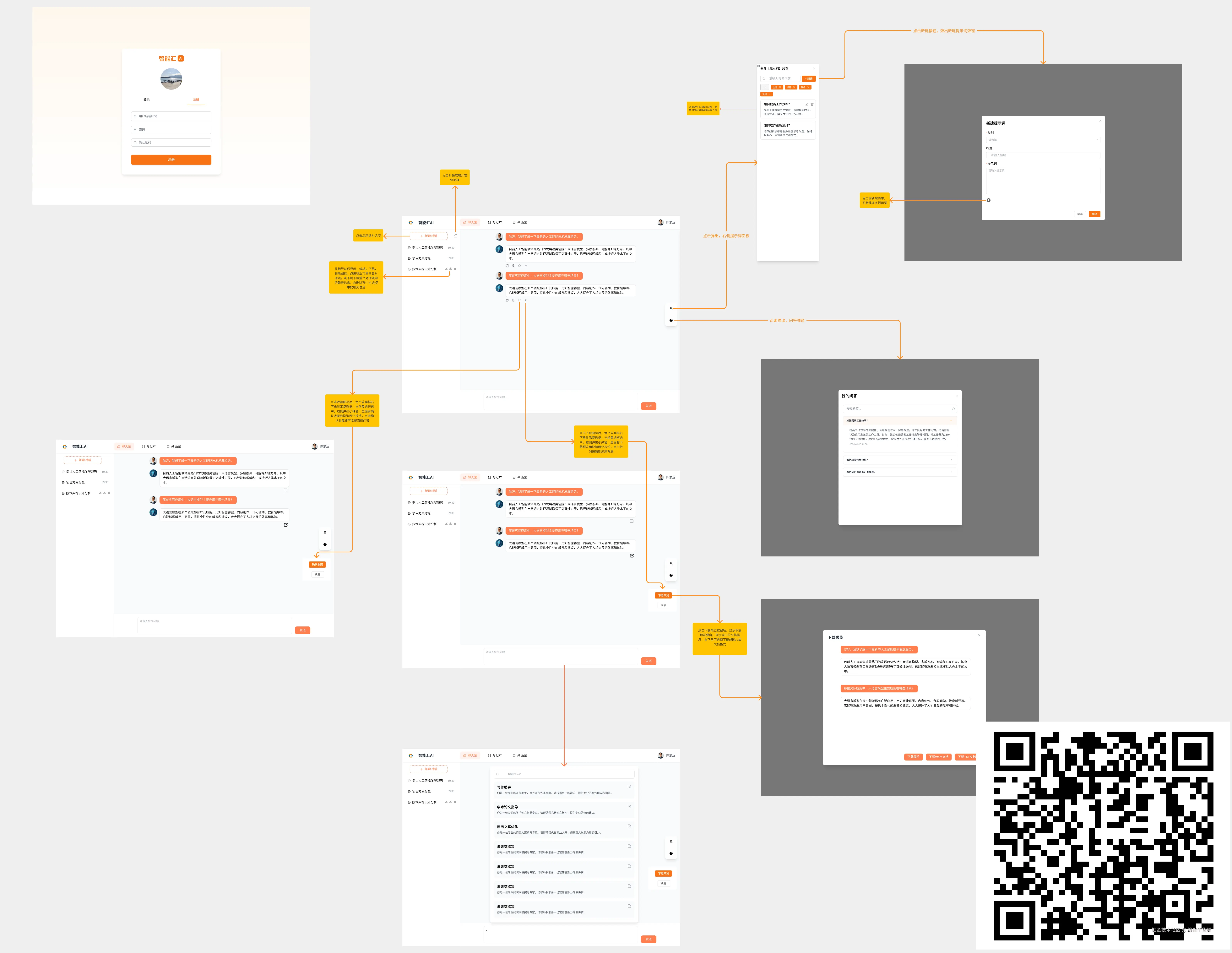
🚀
最近搞了一个挺有意思的项目:用 Vue3.5 + Node.js 从 0 到 1 打造一个生产级的 AI 多模态应用。
你可以在里面:
- 跟 AI 实时对话(支持流式打字动画)💬
- 输入文字,直接合成语音,秒变播音员🎙️
- 打开麦克风,"边说边写",语音实时转文字🗣️→⌨️
- 甚至还能用一句话生成图片🎨!
👇先上个图镇楼:
🧠 项目背景 & 技术选型
传统 AI 应用一般只做到聊天或语音单点功能,我们的目标是------多模态整合,用户能在同一平台体验完整的 AI 能力。
技术栈选得都是最新稳定版,并且围绕"可维护性 + 性能 + 用户体验"下了不少功夫:
🧩 技术栈(核心)
- 前端: Vue 3.5 + Vite + Element Plus + Pinia + markdown-it
- 后端: Node.js + Express + Prisma + MySQL
- AI 模型: 接入字节的 豆包 多个模型:
-
- 对话模型(支持快速&深度思考模式)
- 图像生成(Seedream 4.0)
- 语音合成(TTS)
- 语音识别(ASR)
💡核心亮点拆解(开发者视角)
✅ 1. 登录 & 权限:安全做到了极致
我们不是简单写个登录接口就完事儿,而是:
- JWT + HttpOnly Cookie 存储,前后端自动鉴权
- 支持角色权限(用户 / 管理员)
- 防 CSRF / XSS,登出清除所有状态
- 密码加密用的是 bcrypt 单向哈希
体验上:用户完全无感,开发上也很省事。
🧠 2. AI 对话系统:双模型 + 流式输出
快速模式回答快,深度模式适合复杂逻辑问题。
难点是两个模型参数格式不一样,还要做流式输出(逐字显示)。
解决方案:
- 后端统一封装接口,自动判断模型类型
- 前端自定义 POST SSE 客户端,支持流式渲染
- 用户只管点按钮,打字效果很丝滑~
🔁 3. 聊天长列表不卡顿?我们用了虚拟滚动!
聊天记录多了,页面卡顿是常态?
我们用虚拟滚动 + 分页方案:
- 初始加载 20 条消息,支持滚动加载更多
- 可视区域 + buffer 区渲染,其他用 padding 占位
- 自动保持滚动位置,体验完全不打断
性能提升效果惊人:
| 项目 | 优化前 | 优化后 |
|---|---|---|
| 首屏加载 | 1.8 秒 | 0.3 秒 |
| DOM 节点 | 2000+ | 40 |
| 滚动帧率 | 30~40fps | 55~60fps |
🔊 4. TTS 实时语音合成:0.5 秒内开口说话!
传统 TTS 有 3~5 秒延迟,这太慢了。
我们做了:
- 后端用 WebSocket 中继豆包 TTS 服务
- 前端用 Audio 标签边接收边播放
- 文本预处理(去 markdown、限制长度)
最终效果:基本做到了"输入即说话",延迟控制在 0.5~1 秒之间!
📝 5. 富文本编辑器 + AI 写作助手
基于 WangEditor 二次封装:
- 支持选中文本生成续写内容
- 也可点击工具栏触发 AI
- 生成内容逐字输出,写完自动插入到光标处
优势: 非常适合写简历、方案、内容草稿之类的场景。
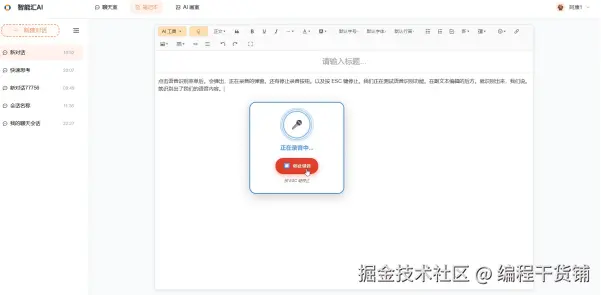
🎤 6. 语音转写(ASR):真正做到"边说边写"
通过麦克风录音 → PCM 流传输 → 实时返回识别结果 → 实时填进文本框。
- 支持格式转换(Float32 → Int16 PCM)
- WebSocket 通信、错误重连机制
- 最小延迟识别结果,边说边填不掉帧
结果:打字效率 ×2,不用再手动输入长段内容。
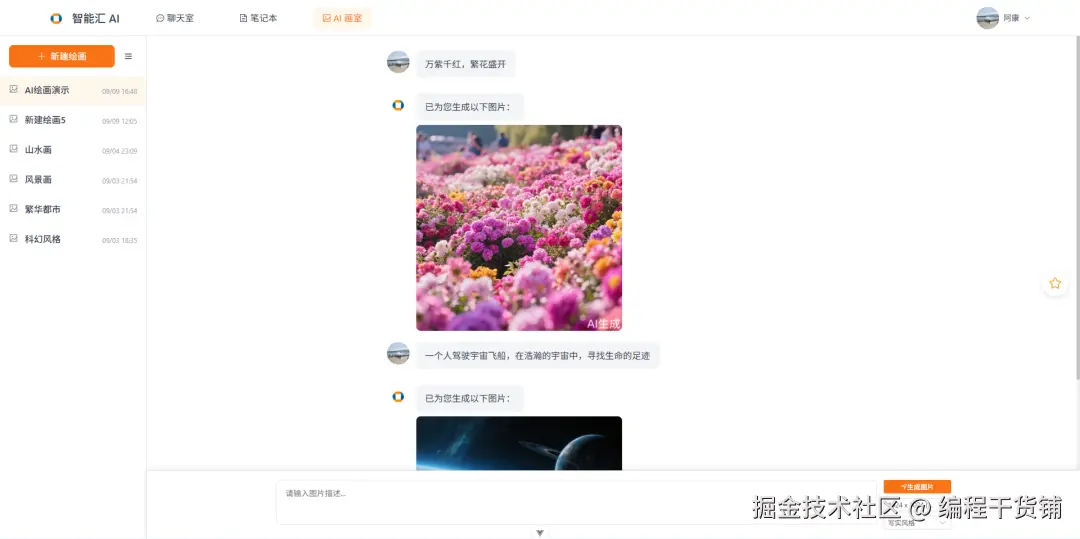
🎨 7. 图片生成:不仅能画,还能保存得住
豆包图像生成是在线图片 URL,但 URL 1 小时就失效?
我们的处理方式:
- 后端自动将图片下载存到本地
- 支持智能识别格式,最多并发下载 4 张
- 本地路径写入数据库,图片长期可用
✅ 工程化细节补充
- 统一异常处理 & 日志记录(使用 Morgan)
- 接口响应格式统一(code/msg/data)
- 模块解耦清晰,方便后期功能扩展
- Prisma 类型推导 + 自动生成 SQL
- WebSocket 与 REST 协同管理连接状态
🧾 总结一下
你可以把这个项目理解成一个"轻量 AI 多模态平台"。
✔ 安全性:JWT + Cookie + 加密✔ 用户体验:流式、实时、不卡顿✔ 工程质量:架构清晰,代码规范,日志可观测✔ AI 能力:对话 + 语音 + 图像,多模态整合✔ 可维护性:模块化开发,方便继续扩展新模型、新功能
从0到1打造一款具备Ai聊天,AI写作,文生图,语音合成,语音识别功能的多模态全栈项目;
扫码了解:
🚀
最近搞了一个挺有意思的项目:用 Vue3.5 + Node.js 从 0 到 1 打造一个生产级的 AI 多模态应用。
你可以在里面:
- 跟 AI 实时对话(支持流式打字动画)💬
- 输入文字,直接合成语音,秒变播音员🎙️
- 打开麦克风,"边说边写",语音实时转文字🗣️→⌨️
- 甚至还能用一句话生成图片🎨!
👇先上个图镇楼:
🧠 项目背景 & 技术选型
传统 AI 应用一般只做到聊天或语音单点功能,我们的目标是------多模态整合,用户能在同一平台体验完整的 AI 能力。
技术栈选得都是最新稳定版,并且围绕"可维护性 + 性能 + 用户体验"下了不少功夫:
🧩 技术栈(核心)
- 前端: Vue 3.5 + Vite + Element Plus + Pinia + markdown-it
- 后端: Node.js + Express + Prisma + MySQL
- AI 模型: 接入字节的 豆包 多个模型:
-
- 对话模型(支持快速&深度思考模式)
- 图像生成(Seedream 4.0)
- 语音合成(TTS)
- 语音识别(ASR)
💡核心亮点拆解(开发者视角)
✅ 1. 登录 & 权限:安全做到了极致
我们不是简单写个登录接口就完事儿,而是:
- JWT + HttpOnly Cookie 存储,前后端自动鉴权
- 支持角色权限(用户 / 管理员)
- 防 CSRF / XSS,登出清除所有状态
- 密码加密用的是 bcrypt 单向哈希
体验上:用户完全无感,开发上也很省事。
🧠 2. AI 对话系统:双模型 + 流式输出
快速模式回答快,深度模式适合复杂逻辑问题。
难点是两个模型参数格式不一样,还要做流式输出(逐字显示)。
解决方案:
- 后端统一封装接口,自动判断模型类型
- 前端自定义 POST SSE 客户端,支持流式渲染
- 用户只管点按钮,打字效果很丝滑~
🔁 3. 聊天长列表不卡顿?我们用了虚拟滚动!
聊天记录多了,页面卡顿是常态?
我们用虚拟滚动 + 分页方案:
- 初始加载 20 条消息,支持滚动加载更多
- 可视区域 + buffer 区渲染,其他用 padding 占位
- 自动保持滚动位置,体验完全不打断
性能提升效果惊人:
| 项目 | 优化前 | 优化后 |
|---|---|---|
| 首屏加载 | 1.8 秒 | 0.3 秒 |
| DOM 节点 | 2000+ | 40 |
| 滚动帧率 | 30~40fps | 55~60fps |
🔊 4. TTS 实时语音合成:0.5 秒内开口说话!
传统 TTS 有 3~5 秒延迟,这太慢了。
我们做了:
- 后端用 WebSocket 中继豆包 TTS 服务
- 前端用 Audio 标签边接收边播放
- 文本预处理(去 markdown、限制长度)
最终效果:基本做到了"输入即说话",延迟控制在 0.5~1 秒之间!
📝 5. 富文本编辑器 + AI 写作助手
基于 WangEditor 二次封装:
- 支持选中文本生成续写内容
- 也可点击工具栏触发 AI
- 生成内容逐字输出,写完自动插入到光标处
优势: 非常适合写简历、方案、内容草稿之类的场景。
🎤 6. 语音转写(ASR):真正做到"边说边写"
通过麦克风录音 → PCM 流传输 → 实时返回识别结果 → 实时填进文本框。
- 支持格式转换(Float32 → Int16 PCM)
- WebSocket 通信、错误重连机制
- 最小延迟识别结果,边说边填不掉帧
结果:打字效率 ×2,不用再手动输入长段内容。
🎨 7. 图片生成:不仅能画,还能保存得住
豆包图像生成是在线图片 URL,但 URL 1 小时就失效?
我们的处理方式:
- 后端自动将图片下载存到本地
- 支持智能识别格式,最多并发下载 4 张
- 本地路径写入数据库,图片长期可用
✅ 工程化细节补充
- 统一异常处理 & 日志记录(使用 Morgan)
- 接口响应格式统一(code/msg/data)
- 模块解耦清晰,方便后期功能扩展
- Prisma 类型推导 + 自动生成 SQL
- WebSocket 与 REST 协同管理连接状态
🧾 总结一下
你可以把这个项目理解成一个"轻量 AI 多模态平台"。
✔ 安全性:JWT + Cookie + 加密✔ 用户体验:流式、实时、不卡顿✔ 工程质量:架构清晰,代码规范,日志可观测✔ AI 能力:对话 + 语音 + 图像,多模态整合✔ 可维护性:模块化开发,方便继续扩展新模型、新功能
从0到1打造一款具备Ai聊天,AI写作,文生图,语音合成,语音识别功能的多模态全栈项目;
右下角扫码了解: