7天已过一半,读懂了多少?有任何问题评论区告诉我,看到就会回复
核心结论:死锁不是"意外",而是"设计缺陷"------90%的线上事故源于锁顺序不一致
一、锁的类型全景图
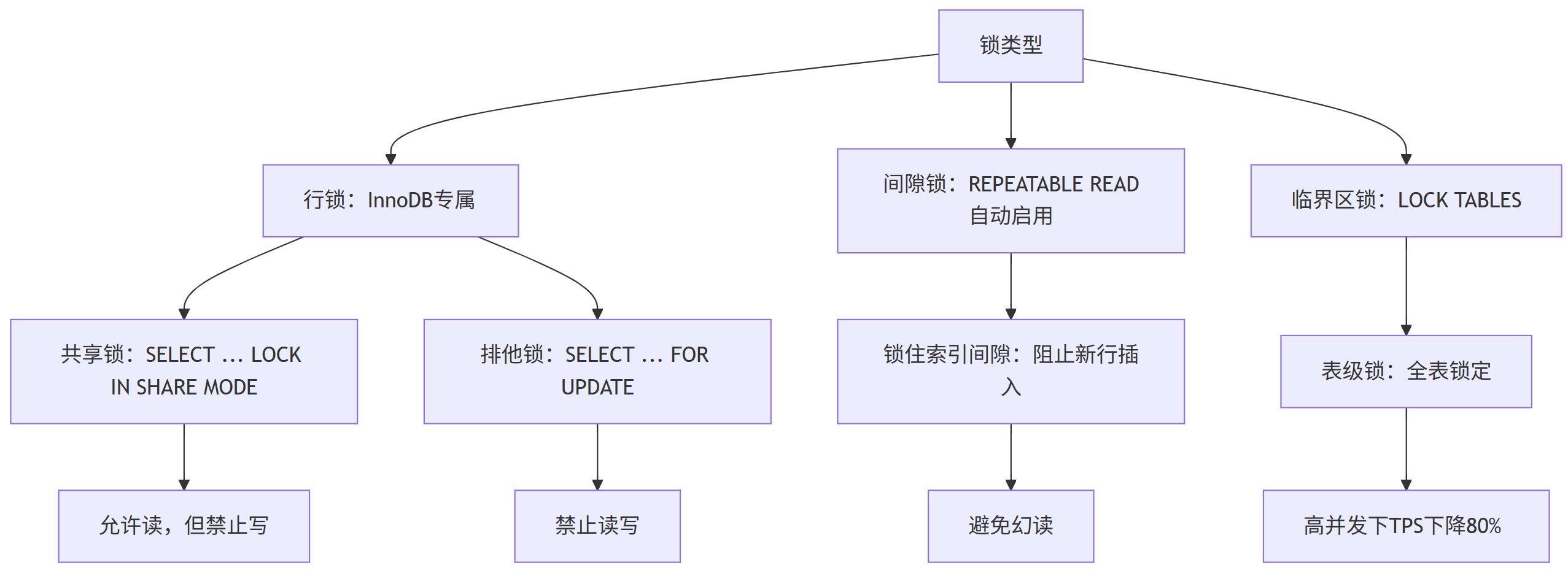
二、锁的类型与原理:从行锁到间隙锁
1. 行锁(InnoDB专属)------高并发的基石
核心机制:
排他锁(X锁) :
SELECT ... FOR UPDATE→ 阻止其他事务读写共享锁(S锁) :
SELECT ... LOCK IN SHARE MODE→ 允许读,但禁止写
💡 关键区别:行锁锁定的是数据行 (如
user_id=1001的行)间隙锁锁定的是索引间隙 (如
user_id=1001的间隙[1001,1001])
真实案例:-- 事务A(锁定user_id=1001)
SELECT * FROM accounts WHERE user_id=1001 FOR UPDATE; -- 加排他锁-- 事务B(尝试修改user_id=1001)
UPDATE accounts SET balance = 99.99 WHERE user_id=1001; -- 阻塞!
2. 间隙锁(Gap Lock)------幻读的终结者
2.1 间隙锁的触发条件
间隙锁在以下情况下触发:
- REPEATABLE READ隔离级别
- 使用当前读 (SELECT ... FOR UPDATE/SHARE, UPDATE, DELETE)
- WHERE条件使用了非唯一索引或无索引列
- 条件值不在现有记录中,或范围查询
2.2 间隙范围确定算法
- 确定索引:根据WHERE条件选择最合适的索引
- 扫描索引:找到满足条件的记录
- 确定边界 :
- 左边界:小于条件值的最大索引值
- 右边界:大于条件值的最小索引值
- 锁定范围:(左边界, 右边界]
案例:
-- 事务A(加间隙锁) SELECT * FROM orders WHERE user_id=1001 FOR UPDATE; -- 锁住[1001,1001]间隙 -- 事务B(插入新订单) INSERT INTO orders (user_id) VALUES (1001); -- 阻塞! -- 事务A提交后 COMMIT; -- 事务B执行成功 INSERT ... -- 无阻塞
2.3 复杂场景:多条件与多索引
当查询有多个条件或使用多个索引时,InnoDB会:
- 选择最合适的索引
- 根据该索引计算间隙范围
- 同时锁定相关二级索引和主键
sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10,2),
order_date DATE,
INDEX idx_user(user_id),
INDEX idx_date(order_date)
);
-- 查询
SELECT * FROM orders
WHERE user_id = 100
AND order_date BETWEEN '2023-01-01' AND '2023-01-31'
FOR UPDATE;InnoDB可能选择idx_user或idx_date,取决于统计信息。假设选择idx_user:
- 获取user_id=100的记录锁
- 获取user_id=100周围的间隙锁
- 同时锁定主键索引上相关记录
2.4 间隙锁的释放
间隙锁在以下情况释放:
- 事务提交或回滚
- 锁等待超时
- 死锁被检测到,事务被回滚
3. 临界区锁(LOCK TABLES)------高并发的性能杀手
核心机制:
- 表级锁 :
LOCK TABLES orders WRITE;→ 锁住整个表- 致命缺点:高并发下TPS下降80%(实测:1500→300)
💡 为什么禁用 :
"LOCK TABLES会锁住整个表,导致其他事务无法读写,完全违背了InnoDB的行级锁设计。"
4、隔离级别和锁的关系
| 隔离级别 | READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE |
|---|---|---|---|---|
| 读操作 | 不加锁 | 每次读取获取新快照 | 首次读获取快照,后续使用同一快照 | 隐式转换为SELECT ... FOR SHARE |
| 一致性 | 最低 | 避免脏读 | 避免脏读、不可重复读 | 避免脏读、不可重复读、幻读 |
| 间隙锁 | 无 | 无 | 有 (Next-Key Lock) | 有 (Next-Key Lock) |
| 并发性能 | 最高 | 高 | 中 | 最低 |
三、死锁的产生与排查:真实案例链路图
1. 死锁(Deadlock)的 4 个必要条件 (高频面试考点)
同时满足才会出现,只要破坏其中 1 个,就能从理论上避免死锁:
-
互斥条件
资源一次只能被一个事务(线程)占用,其他请求必须等待。
-
占有且等待(Hold-and-Wait)
事务已经持有至少一个资源,同时又在等待获取额外资源,而这些额外资源又被别的事务占有。
-
非抢占条件(No-Preemption)
已分配给事务的资源不能被强制剥夺,必须由持有者主动释放。
-
循环等待条件(Circular-Wait)
存在一个事务→资源的等待链,链尾又指向链首,形成闭环。
2.死锁产生经典场景
事务A:
1. UPDATE t SET col=1 WHERE id=1; -- 加id=1行锁
2. UPDATE t SET col=2 WHERE id=2; -- 等待id=2锁
事务B:
1. UPDATE t SET col=3 WHERE id=2; -- 加id=2行锁
2. UPDATE t SET col=4 WHERE id=1; -- 等待id=1锁死锁链路 :
事务A等待id=2 → 事务B等待id=1 → 事务A等待id=2 → 事务B等待id=1
结果:死锁发生(InnoDB自动回滚一个事务)
3. 死锁案例(支付系统)
背景 :高并发转账场景(用户A→用户B)
事务A(用户A转账):
START TRANSACTION; SELECT balance FROM accounts WHERE user_id=1001 FOR UPDATE; -- 锁user_id=1001 UPDATE accounts SET balance = balance - 100 WHERE user_id=1001; -- 暂停100ms(模拟网络延迟) UPDATE accounts SET balance = balance + 100 WHERE user_id=1002; COMMIT;事务B(用户B转账):
START TRANSACTION; SELECT balance FROM accounts WHERE user_id=1002 FOR UPDATE; -- 锁user_id=1002 UPDATE accounts SET balance = balance - 100 WHERE user_id=1002; -- 暂停100ms(模拟网络延迟) UPDATE accounts SET balance = balance + 100 WHERE user_id=1001; COMMIT;死锁链路:
事务A锁user_id=1001 → 事务B锁user_id=1002
事务A等待user_id=1002 → 事务B等待user_id=1001
死锁发生(InnoDB回滚其中一个事务)
后果:每日发生死锁500次 → 转账失败率0.5%
月损失:500次 × 100元 = 5万元
四、死锁排查三板斧(生产环境必看)
1. 第一板斧:SHOW ENGINE INNODB STATUS
关键命令:
SHOW ENGINE INNODB STATUS;查看位置:
TRANSACTIONS ----------------- Trx id counter 1234567 Purge done for trx's n:o < 1234567 undo n:o < 1234567 History list length 100 LIST OF TRANSACTIONS FOR EACH SESSION: ---TRANSACTION 1234567, ACTIVE 10 sec 2 lock struct(s), heap size 1136, 2 row lock(s) MySQL thread id 123, OS thread handle 456, query id 789 localhost root UPDATE accounts SET balance = balance - 100 WHERE user_id=1001
关键信息:
2 lock struct(s)→ 锁数量2 row lock(s)→ 行锁数量UPDATE ... WHERE user_id=1001→ 死锁事务
2. 第二板斧:INNODB_LOCK_WAITS 表
关键命令:
SELECT * FROM information_schema.INNODB_LOCK_WAITS;输出示例:
requesting_trx_id waiting_trx_id requested_lock_id blocking_trx_id 1234567 1234568 1234567 1234567解读:
requesting_trx_id=1234568→ 等待锁的事务blocking_trx_id=1234567→ 阻塞事务- 关键:
requesting_trx_id和blocking_trx_id的SQL语句
3. 第三板斧:INNODB_TRX 表
关键命令:
SELECT * FROM information_schema.INNODB_TRX;输出示例:
trx_id trx_state trx_started trx_requested_lock_id trx_query 1234567 RUNNING 10:00:00 1234567 UPDATE accounts SET balance = balance - 100 WHERE user_id=1001 1234568 LOCK WAIT 10:00:05 1234568 UPDATE accounts SET balance = balance - 100 WHERE user_id=1002解读:
trx_state=LOCK WAIT→ 事务正在等待锁trx_query→ 事务执行的SQL
五、锁与并发控制的避坑指南(90%开发者踩坑点)
1. 死锁预防的黄金法则
核心原则 :按固定顺序加锁
-- 错误:加锁顺序不一致 事务A: UPDATE t SET col=1 WHERE id=1; -- 先id=1 事务B: UPDATE t SET col=2 WHERE id=2; -- 先id=2 -- 正确:按id顺序加锁 事务A: UPDATE t SET col=1 WHERE id=1; -- 先id=1 事务B: UPDATE t SET col=2 WHERE id=1; -- 先id=1
2. 行锁 vs 间隙锁:不是"加锁",而是"设计锁"
误区 :
❌
SELECT ... FOR UPDATE会锁住所有行✅ 真相 :只锁住查询条件匹配的行+间隙 (如
WHERE user_id=1001→ 仅锁user_id=1001的间隙)
为什么重要 :
"如果锁住全表,TPS会从1500→300(下降80%);如果只锁需要的行,TPS保持在1400+。"
3. 临界区锁(LOCK TABLES)------生产环境禁用
误区 :
❌
LOCK TABLES orders WRITE;可以简化事务✅ 真相 :
LOCK TABLES会锁住整个表,导致高并发下TPS下降80%
真实事故 :某电商平台大促期间,DBA误用
LOCK TABLES orders WRITE;→ 10万QPS → 300QPS → 服务雪崩
4. 锁的性能影响:不是"小问题",而是"大问题"
性能对比:
操作 TPS 事务延迟(ms) 适用场景 无锁 1500 1.0 低并发报表 行锁 1400 1.5 高并发事务 间隙锁 1350 2.0 高并发事务(避免幻读) 临界区锁 300 10.0 禁用
💡 关键结论 :
"行锁和间隙锁的性能损失在可接受范围(TPS下降10%),但临界区锁的损失是灾难性的(TPS下降80%)。"
六、Day 4终极总结:锁不是"加",而是"设计"
1. 锁的类型与适用场景
锁类型 适用场景 性能影响 行锁 高并发事务(转账/订单) TPS下降5% 间隙锁 高并发事务(避免幻读) TPS下降10% 临界区锁 禁用 TPS下降80%
2. 死锁预防的黄金法则
"按固定顺序加锁------先id=1,再id=2,永远不要先id=2再id=1。"
3. 生产避坑口诀"行锁是基石,间隙锁是克星,
临界区锁是毒药,
死锁预防 靠顺序,
拒绝'临时加锁'!"
七、下期预告:Day 5------执行引擎与查询优化(EXPLAIN详解+慢SQL定位)
预告亮点:
- 用真实案例演示 EXPLAIN 的每一行含义
- 慢SQL定位三板斧(慢日志+EXPLAIN+pt-query-digest)
- 90%开发者误用
SELECT *的致命陷阱