🧠 模块一:大数据科学导论(6%,3题)
- 大数据基本概念
定义:具有 Volume(大量)、Velocity(高速)、Variety(多样)、Veracity(真实性)、Value(价值密度低) 特征的数据集合。
与传统数据区别:规模更大、结构更复杂(文本、图像、日志等)、处理方式不同(分布式 vs 单机)。 - 大数据发展历程
起源:Google 三篇论文(GFS, MapReduce, BigTable)→ Apache Hadoop 开源实现
发展阶段:
批处理时代(Hadoop)
流处理兴起(Storm, Spark Streaming)
实时+批统一(Flink)
云原生与 AI 融合(当前趋势) - 应用场景
运营商:用户画像、网络优化、反欺诈
电商:推荐系统、库存预测
金融:风控、信用评分
政府:智慧城市、交通调度 - 数据挖掘概念
定义:从大量数据中发现隐藏模式、关联规则或趋势的过程。
常用任务:
分类(如垃圾邮件识别)
聚类(如客户分群)
关联规则(如购物篮分析)
回归(如房价预测)
CRISP-DM流程:业务理解 → 数据理解 → 数据准备 → 建模 → 评估 → 部署
💻 模块二:Python 编程基础(24%,12题)← 重中之重!
- 开发环境搭建
安装 Python(推荐 3.8+)
IDE:PyCharm / VS Code / Jupyter Notebook
包管理:pip install pandas numpy scikit-learn - 基础语法
变量与数据类型:int, float, str, bool, list, tuple, dict, set
运算符:+ - * / % // **, == != > <, and or not
控制结构:
python
if condition:
...
elif ...:
...
else:
...
for item in list:
...
while condition:
...- 函数
python
def func_name(param1, param2=默认值):
return result- 异常处理
python
try:
risky_code()
except ValueError as e:
print(e)
finally:
cleanup()- 文件操作
python
with open('file.txt', 'r') as f:
content = f.read()- 模块与包
导入:import math, from pandas import DataFrame
✅ 零基础重点练习:列表推导式、字典操作、函数定义、读写文件。
🛠️ 模块三:Python 数据处理工具(10%,5题)
- NumPy
核心:ndarray(多维数组)
常用操作:
python
import numpy as np
arr = np.array([1,2,3])
arr.shape, arr.dtype
np.mean(arr), np.std(arr)
arr.reshape(3,1)- Pandas(极其重要!)
核心数据结构:
Series:一维带标签数组
DataFrame:二维表格(类似 Excel)
常用操作:
python
df = pd.read_csv('data.csv')
df.head(), df.info(), df.describe()
df['new_col'] = df['col1'] + df['col2']
df.groupby('category').mean()
df.dropna(), df.fillna(0)
df.merge(other_df, on='id')- 爬虫基础
原理:HTTP 请求 → 解析 HTML → 提取数据
工具:
requests:发送请求
BeautifulSoup / lxml:解析 HTML
注意:遵守robots.txt,避免频繁请求 - 数据可视化
Matplotlib:
python
import matplotlib.pyplot as plt
plt.plot(x, y)
plt.bar(categories, values)
plt.show()Seaborn(更高级):
python
import seaborn as sns
sns.heatmap(df.corr())🤖 模块四:机器学习方法(16%,8题)
-
监督学习 vs 无监督学习

-
常用算法及适用场景
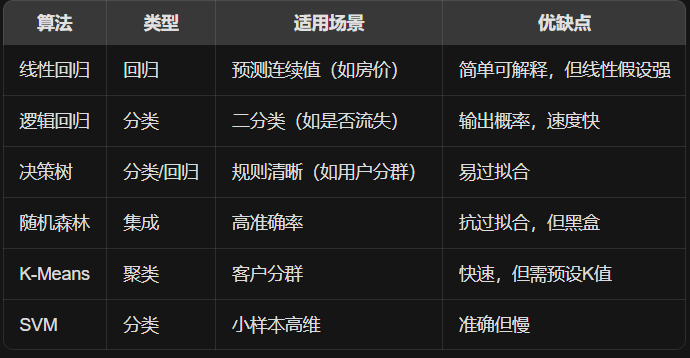
-
模型评估指标
分类:准确率、精确率、召回率、F1、AUC
回归:MAE、MSE、R²
-
Python 实现(sklearn)
python
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = RandomForestClassifier()
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(accuracy_score(y_test, pred))🧠 模块五:深度学习方法(14%,7题)
-
神经网络基础
结构:输入层 → 隐藏层 → 输出层
激活函数:ReLU(常用)、Sigmoid、Tanh
损失函数:交叉熵(分类)、MSE(回归)
优化器:SGD、Adam
-
常用模型

-
框架(了解即可)
TensorFlow / PyTorch
Keras(高层API)
-
优缺点
优点:自动特征提取、处理非线性关系强
缺点:需要大量数据、计算资源高、可解释性差
☁️ 模块六:大数据开发基础(8%,4题)
-
关系型 vs 分布式数据库

-
数据仓库
传统:Oracle, Teradata ------ 集中式,成本高
分布式:Hive ------ 基于 HDFS,用 SQL 查询大数据(HQL)
-
Hadoop 生态
HDFS:分布式文件系统(存储)
MapReduce:编程模型(计算)
Map:分发任务
Reduce:汇总结果
YARN:资源调度
-
Spark
内存计算,比 MapReduce 快 10-100 倍
支持批处理、流处理、ML(MLlib)、图计算(GraphX)
核心抽象:RDD / DataFrame
-
Flink
真正的流处理引擎(低延迟)
支持"流批一体"
适用于实时风控、实时推荐
📡 模块七:中国移动大数据发展历程(22%,11题)← 必背!
-
梧桐大数据平台
中国移动自研的大数据能力开放平台
目标:"连接+算力+能力" 融合
提供:数据治理、AI建模、可视化、API服务
-
技术栈
底层:Hadoop + Spark + Flink
中台:数据中台、AI中台
上层:行业应用(如智慧交通、数字政府)
-
发展趋势
从"数据汇聚"到"智能赋能"
构建"梧桐生态":联合合作伙伴,开放数据能力
推进 "东数西算" 国家战略
-
典型应用案例
位置大数据:人流热力图、疫情追踪
通信反诈:基于通话行为识别诈骗号码
智慧网点:根据用户画像推荐套餐
网络优化:预测基站负载,动态调整资源
✅ 考试重点:记住"梧桐"的定位、三大能力(连接+算力+能力)、典型场景(反诈、位置服务、智慧运营)