1、引言:大模型时代的效率挑战
随着大语言模型(LLM)参数规模从数十亿扩展到万亿级别,这些模型在展现惊人能力的同时,也带来了前所未有的计算挑战。单个GPT-4规模的模型可能需要数百GB的GPU内存,推理延迟显著,部署成本高昂。量化技术正是在这种背景下成为解决大模型效率瓶颈的关键手段,它通过降低数值精度来减少模型大小、加速推理,同时尽可能保持模型性能。
2、核心概念解析
2.1、量化主要目标与解决的问题
量化技术主要实现三大目标:
-
内存占用优化:将FP32(32位浮点)参数转换为INT8(8位整数)可减少75%的存储空间
-
推理速度提升:整数运算在多数硬件上比浮点运算更快,且功耗更低
-
部署门槛降低:使大模型能在消费级硬件(如笔记本电脑、手机)上运行
以Llama 3 70B模型为例,原始FP32版本需要约280GB内存,而INT8量化后仅需70GB,使单张消费级显卡部署成为可能。
2.2、量化类型全景图
量化主要分为两大范式,各有适用场景:
| 类型 | 训练后量化(PTQ) | 量化感知训练(QAT) |
|---|---|---|
| 流程 | 在训练完成后应用 | 训练过程中模拟量化 |
| 精度损失 | 相对较大 | 相对较小 |
| 计算成本 | 低(仅需校准) | 高(需重新训练或微调) |
| 典型应用 | 快速部署、大规模服务 | 高精度要求的边缘设备 |
实际选择建议:对于大多数LLM应用,PTQ是首选,因其简单高效;只有在精度损失不可接受时才考虑QAT。
**2.3、**技术原理深入
2.3.1、 FP32到INT8的转换机制
量化的核心是建立浮点数到整数的映射关系:
python
量化:Q = round(r/scale) + zero_point
反量化:r' = (Q - zero_point) * scale其中scale(缩放因子)和zero_point(零点偏移)是量化的关键参数。
2.3.2、信息保留策略:
-
对称量化:适用于权重,零点固定为0
-
非对称量化:适用于激活值,能更好地处理数据分布偏移
2.3.3、校准的核心作用与方法
校准是确定最优scale和zero_point的过程,直接影响量化质量:
| 校准方法 | 原理 | 适用场景 |
|---|---|---|
| 最小-最大法 | 使用数据范围直接计算 | 简单快速,分布均匀时效果好 |
| 熵最小化 | 最小化量化前后信息损失 | 激活值量化,精度要求高 |
| 百分位法 | 排除异常值影响(如99.9%分位数) | 处理长尾分布,鲁棒性强 |
实践中,常用少量代表性数据(100-1000个样本)进行校准,无需完整训练集。
3、实现细节
3.1、数值映射方法对比
3.1.1、均匀量化:
-
优势:硬件友好、实现简单、几乎所有AI加速器都支持
-
劣势:对非均匀分布数据效率低
-
典型应用:权重矩阵、线性层计算
3.1.2、非均匀量化:
-
优势:对数据分布适应性强,精度损失小
-
劣势:硬件支持有限,计算复杂
-
代表技术:对数量化(logarithmic quantization)
3.1.3、最新趋势
混合均匀量化,对不同层使用不同位宽(如注意力层用8位,输出层用4位)。
3.1.4、精度恢复技术
量化导致精度损失不可避免,但可通过多种技术缓解:
-
混合精度量化:
-
敏感层保持高精度(FP16),其他层量化
-
自动敏感度分析确定各层最优位宽
python# 伪代码示例:混合精度策略 sensitive_layers = analyze_sensitivity(model, calibration_data) for layer in model.layers: bits = 16 if layer in sensitive_layers else 8 quantize_layer(layer, bits)
-
-
量化感知微调:
-
在量化模型上使用LoRA等技术进行轻量微调
-
恢复3-10%的精度损失
-
-
自适应量化策略:
-
根据输入动态调整量化参数
-
特别适用于处理多样化输入的大模型
-
**3.2、**工具生态与实践指南
3.2.1、主流量化工具对比
| 工具 | 核心优势 | 典型场景 | 易用性 | 相关网站 |
|---|---|---|---|---|
| TensorRT | NVIDIA硬件优化极致 | 生产环境部署 | 中等 | https://github.com/NVIDIA/TensorRT |
| GGML/llama.cpp | CPU优化、多平台支持 | 边缘设备、本地运行 | 高 | https://github.com/ggml-org/llama.cpp |
| Hugging Face | 与transformers无缝集成 | 快速实验、研究 | 极高 | https://github.com/huggingface |
| ONNX Runtime | 跨框架、跨硬件 | 企业级跨平台部署 | 中等 | https://github.com/microsoft/onnxruntime |
3.2.2、Llama 3量化实战示例
python
# 使用Hugging Face进行GPTQ量化(4位权重量化)
from transformers import AutoModelForCausalLM, AutoTokenizer
from optimum.gptq import GPTQQuantizer
# 加载原始模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B")
# 配置GPTQ量化器
quantizer = GPTQQuantizer(
bits=4, # 4位量化
dataset="c4", # 校准数据集
block_size=128, # 量化块大小
)
# 应用量化
quantized_model = quantizer.quantize_model(model)
# 保存量化模型
quantized_model.save_pretrained("./llama-3-8b-gptq-4bit")3.2.1、量化效果评估:
python
# 量化前后对比测试
def evaluate_model(model, test_dataset):
# 测量内存占用
memory_mb = model.get_memory_footprint() / 1024**2
# 测量推理速度
import time
start = time.time()
outputs = model.generate(**test_sample)
latency = time.time() - start
# 评估精度
accuracy = compute_accuracy(outputs, references)
return {"memory_mb": memory_mb, "latency": latency, "accuracy": accuracy}**3.3、**llama3的量化信息
在https://ollama.com/搜做llama3,可以查找到llama3的最新版本,可以查看模型的具体信息:
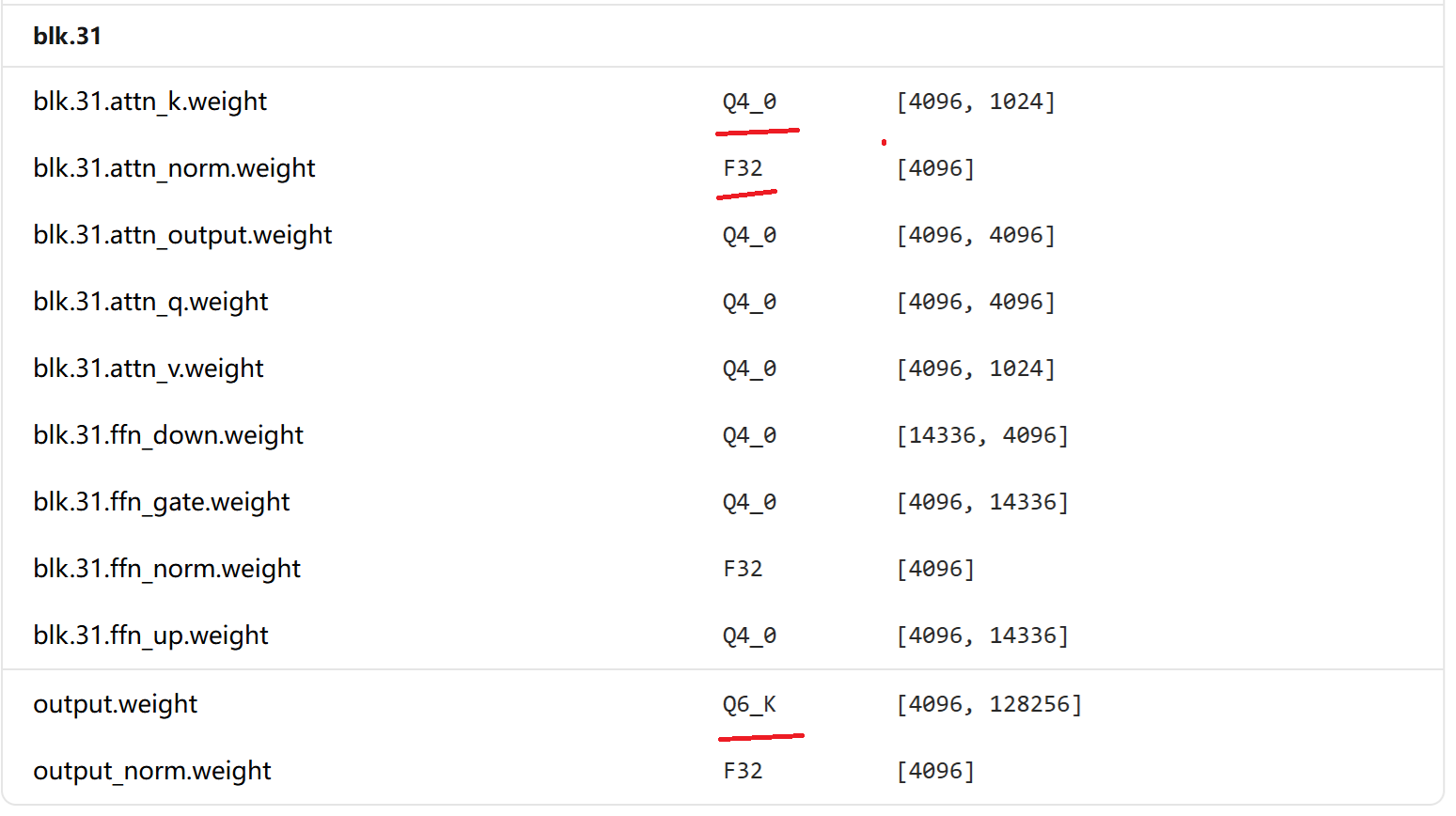
这里的Q4_0、FP32和Q6_K是GGUF(GPT-Generated Unified Format)文件中的量化类型标识,这反映了llama.cpp采用的分层混合量化策略。
具体信息可以参考: https://blog.csdn.net/jimmyleeee/article/details/156397722
4、最新研究进展
4.1、超低精度量化(FP4/INT4)
-
现状:LLAMA、Falcon等模型已实现4位量化部署
-
关键技术:
-
双量化(Double Quantization):对量化参数再次量化
-
分组量化(Group-wise Quantization):以小分组为单位量化,减少误差
-
-
性能表现:4位量化相比16位,内存减少75%,推理速度提升2-3倍
4.2、稀疏量化结合
-
核心思想:识别并保留重要参数的高精度,其余量化和稀疏化
python# 稀疏量化概念示意 def sparse_quantize(weight_matrix, sparsity_ratio=0.5): # 1. 识别重要参数(基于幅度或梯度) importance = calculate_importance(weight_matrix) # 2. 保留重要参数为高精度 mask = importance > threshold sparse_high_precision = weight_matrix * mask # 3. 其余参数进行低精度量化 dense_low_precision = quantize_to_4bit(weight_matrix * (1 - mask)) return sparse_high_precision + dense_low_precision
4.3、LLM量化的特殊性
与传统CNN量化相比,LLM量化面临独特挑战:
-
动态范围极大:激活值分布随输入变化显著
-
异常值问题:某些层的少量参数值特别大,影响整体量化
-
注意力机制敏感:Q/K/V矩阵的量化需要特殊处理
-
位置编码保持:需要确保位置信息的精确性
4.4、解决方案:
-
每通道量化(Per-channel Quantization):为每个通道计算独立缩放因子
-
平滑量化(SmoothQuant):将激活值的难度转移到权重
-
注意力特定优化:对注意力分数使用更高的精度
4.5、实际应用权衡
4.5.1、硬件适配策略
| 硬件平台 | 推荐量化策略 | 注意事项 |
|---|---|---|
| NVIDIA GPU | TensorRT INT8量化 | 利用Tensor Core加速 |
| Apple Silicon | GGML Q4_K_M | 针对神经引擎优化 |
| 移动设备 | 混合精度(权重INT8,激活INT16) | 平衡精度与功耗 |
| 浏览器部署 | WebGPU + 8位量化 | 考虑JavaScript数值精度限制 |
4.5.2、量化对模型能力的影响评估
量化可能影响模型的特定能力,需要系统评估:
-
推理能力测试:
python# 构建多维度评估集 evaluation_tasks = { "logical_reasoning": logical_reasoning_dataset, "mathematical_reasoning": math_problems, "code_generation": code_benchmarks, "few_shot_learning": few_shot_tasks, } # 量化前后对比测试 results = {} for task_name, dataset in evaluation_tasks.items(): original_score = evaluate(original_model, dataset) quantized_score = evaluate(quantized_model, dataset) degradation = (original_score - quantized_score) / original_score results[task_name] = degradation -
常见发现:
-
知识密集型任务对量化更敏感
-
推理能力比记忆能力更容易受影响
-
4位量化下,少样本学习性能下降约5-15%
-
5、动手实践
5.1、量化实施步骤
-
准备阶段:
-
选择目标硬件和部署场景
-
确定可接受的精度损失阈值(通常<1%)
-
准备校准数据集(500-1000个代表性样本)
-
-
实施流程:
pythondef quantize_model_step_by_step(model, config): # 步骤1:分析模型结构 layer_sensitivity = analyze_model_sensitivity(model) # 步骤2:选择量化策略 if config.hardware == "edge": strategy = EdgeOptimizedStrategy() else: strategy = ServerOptimizedStrategy() # 步骤3:校准 calibration_data = load_calibration_data() quant_params = calibrate_model(model, calibration_data) # 步骤4:应用量化 quantized_model = apply_quantization(model, quant_params, strategy) # 步骤5:验证与调优 if evaluate_model(quantized_model) < config.threshold: quantized_model = fine_tune_quantized_model(quantized_model) return quantized_model -
常见陷阱与规避:
-
校准数据不具代表性:使用领域相关数据校准
-
忽视异常值影响:使用百分位校准法
-
硬件兼容性问题:提前测试目标推理引擎
-
5.2、完整代码示例
python
# 完整的Llama模型量化工作流
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from torch.quantization import quantize_dynamic
# 1. 加载模型
model_name = "meta-llama/Llama-3-8B"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 2. 准备校准数据
calibration_texts = [
"The capital of France is",
"Machine learning is",
# ... 更多代表性样本
]
calibration_inputs = tokenizer(calibration_texts, return_tensors="pt", padding=True)
# 3. 动态量化(PyTorch内置)
quantized_model = quantize_dynamic(
model,
{torch.nn.Linear}, # 量化线性层
dtype=torch.qint8
)
# 4. 评估量化效果
print(f"原始模型大小: {model.get_memory_footprint() / 1e9:.2f} GB")
print(f"量化后大小: {quantized_model.get_memory_footprint() / 1e9:.2f} GB")
# 5. 保存量化模型
torch.save(quantized_model.state_dict(), "llama-3-8b-quantized.pt")6、批判性思考与展望
6.1、量化的理论极限
-
信息论约束:根据香农信息论,低位表示必然丢失信息
-
硬件物理限制:数字表示的动态范围与精度权衡
-
模型组件限制:某些组件难以量化:
-
位置编码(需要高精度位置信息)
-
LayerNorm的gamma/beta参数
-
嵌入层(尤其对稀有词汇)
-
6.2、超越量化的轻量化技术
量化并非唯一的模型压缩路径,其他有前景的技术包括:
-
知识蒸馏:用小模型学习大模型的行为
-
结构化剪枝:移除不重要的神经元或层
-
低秩分解:将大矩阵分解为小矩阵乘积
-
条件计算:根据输入动态激活模型部分
6.3、未来趋势:
混合技术将成为主流,如"剪枝+量化"、"蒸馏+量化",在多个维度同时优化。
7、结论:量化技术的平衡艺术
大模型量化本质上是在效率与性能间寻求最优平衡的艺术。随着硬件进化(如支持FP4的NPU)和算法创新(如学习型量化),量化的边界正不断扩展。对于实践者而言,成功的关键在于:
-
理解应用场景的真实约束:不只是追求最低精度,而是找到满足需求的最优解
-
建立系统化评估框架:从多维度评估量化影响,避免片面优化
-
保持技术开放性:量化是工具而非目的,与其他优化技术结合使用
量化技术使大模型民主化成为可能,让更多开发者和组织能够利用这些强大的AI能力。随着研究的深入,我们正朝着"无损量化"的理想不断接近,同时也在重新思考:在有限的计算资源下,智能的边界究竟在哪里?