⭐ 深度学习入门体系(第 6 篇): MLP 和 CNN 有什么本质区别?
------什么时候该用 MLP?什么时候该用 CNN?一篇文章讲清楚
这一篇我们来讲一个很多初学者都会搞混的问题:
为什么做图像分类时不用 MLP,而用 CNN?
两者到底区别在哪里?
MLP 也能处理图片吧?为什么精度差这么多?
那什么时候应该用 MLP,什么时候应该用 CNN?
你可能在课程或网上看到过许多解释,但大部分都太抽象、太数学。
这篇文章我们讲人话,让你真正理解两者的差别,并且能在自己的项目中做正确选择。
文章目录
- [⭐ 深度学习入门体系(第 6 篇): MLP 和 CNN 有什么本质区别?](#⭐ 深度学习入门体系(第 6 篇): MLP 和 CNN 有什么本质区别?)
-
- [------什么时候该用 MLP?什么时候该用 CNN?一篇文章讲清楚](#——什么时候该用 MLP?什么时候该用 CNN?一篇文章讲清楚)
- [🎯 一、MLP 和 CNN 的一句话解释](#🎯 一、MLP 和 CNN 的一句话解释)
- [🧱 二、MLP:它的本质是"把所有像素当作一串数字处理"](#🧱 二、MLP:它的本质是“把所有像素当作一串数字处理”)
-
- [🌪 为什么 MLP 对图像很难?](#🌪 为什么 MLP 对图像很难?)
- [🧩 三、CNN:它的核心能力在于"局部感知 + 空间结构感知"](#🧩 三、CNN:它的核心能力在于“局部感知 + 空间结构感知”)
- [🧠 四、一个生活类比:](#🧠 四、一个生活类比:)
-
- [MLP 和 CNN 的不同观察"方式"](#MLP 和 CNN 的不同观察“方式”)
- [🔍 MLP:像"盲盒"评委](#🔍 MLP:像“盲盒”评委)
- [📷 CNN:像"图片扫描仪"](#📷 CNN:像“图片扫描仪”)
- [🧬 五、结构上的本质区别](#🧬 五、结构上的本质区别)
-
- [① 参数量完全不同](#① 参数量完全不同)
- [② 是否保留空间结构?](#② 是否保留空间结构?)
- [③ 权重是否共享?](#③ 权重是否共享?)
- [🎨 六、什么时候用 MLP?什么时候用 CNN?](#🎨 六、什么时候用 MLP?什么时候用 CNN?)
- [✅ (一)适用 CNN 的场景(绝大多数图像任务)](#✅ (一)适用 CNN 的场景(绝大多数图像任务))
- [⚪(二)适用 MLP 的场景(图像任务极少见)](#⚪(二)适用 MLP 的场景(图像任务极少见))
- [🎯(三)特殊情况:视觉 MLP(Vision MLP)](#🎯(三)特殊情况:视觉 MLP(Vision MLP))
- [📌 七、本质总结(很重要)](#📌 七、本质总结(很重要))
- [🧭 八、快速问答:常见困惑一次解决](#🧭 八、快速问答:常见困惑一次解决)
-
-
- [Q1:MLP 能不能也做图像分类?](#Q1:MLP 能不能也做图像分类?)
- [Q2:CNN 为什么这么高效?](#Q2:CNN 为什么这么高效?)
- [Q3:MLP 有没有可能超过 CNN?](#Q3:MLP 有没有可能超过 CNN?)
- [Q4:卷积是不是被 Transformer 取代了?](#Q4:卷积是不是被 Transformer 取代了?)
-
- [🧱 九、用一句极简的话总结本篇](#🧱 九、用一句极简的话总结本篇)
- [🔜 下一篇](#🔜 下一篇)
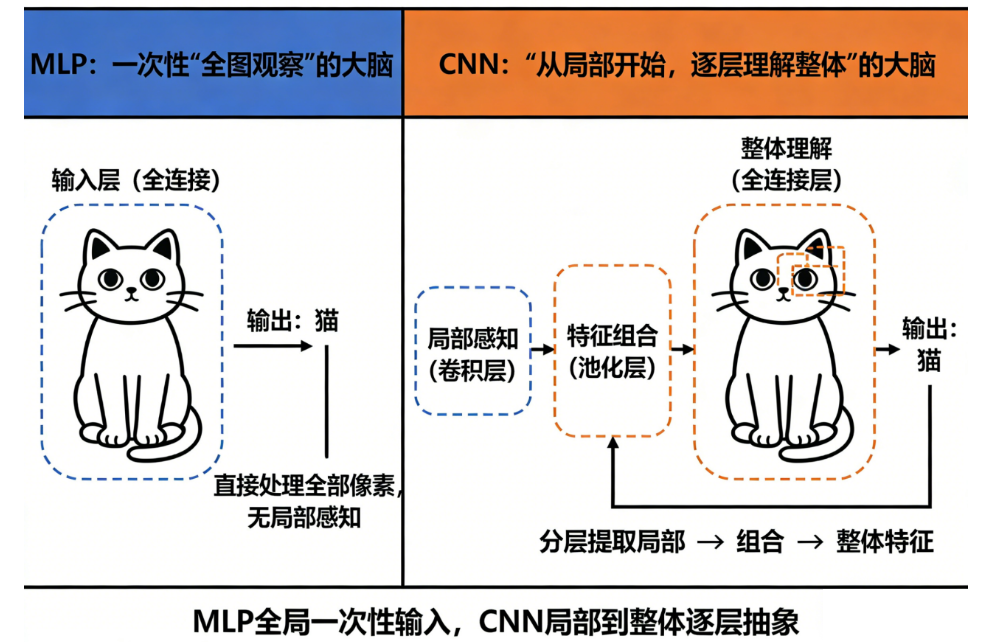
🎯 一、MLP 和 CNN 的一句话解释
如果只能用一句话区分 MLP 和 CNN,那就是:
MLP 是一次性"全图观察"的大脑
CNN 是"从局部开始,逐层理解整体"的大脑
两者的"观察方式"完全不同,所以处理图片的表现也完全不同。
🧱 二、MLP:它的本质是"把所有像素当作一串数字处理"
你给一张 224×224 的图片(3 通道),MLP 会这样处理:
- 把图片展平成一个超级长的向量
- 每个像素都变成一个独立的输入神经元
- 网络对这些像素之间的空间关系"毫无概念"
类比:
给你一个 50 万字的小说,把所有文字随机排成一行,然后让你理解剧情。
可以想象效果会很糟糕。
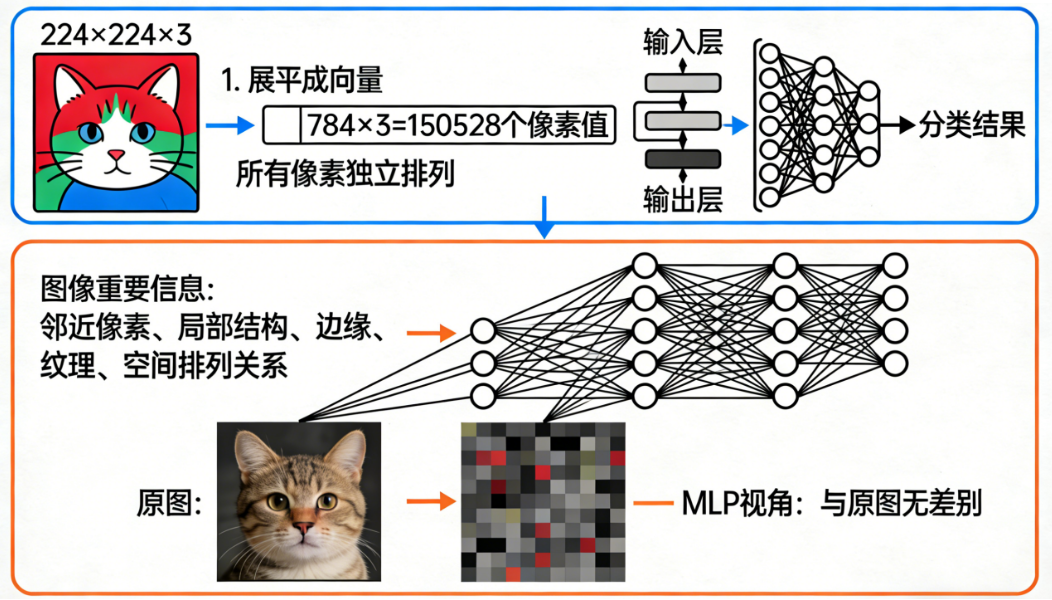
🌪 为什么 MLP 对图像很难?
因为图片的重要信息在于:
- 邻近像素
- 局部结构
- 边缘
- 纹理
- 空间排列关系
而 MLP 一展平,就把所有这些结构信息打碎了。
换句话说:
图片的"空间结构"是 MLP 先天就看不懂的。
除非你强行给它超级超级大的训练集和算力(也就是现代 Vision Transformer 那种玩法)。
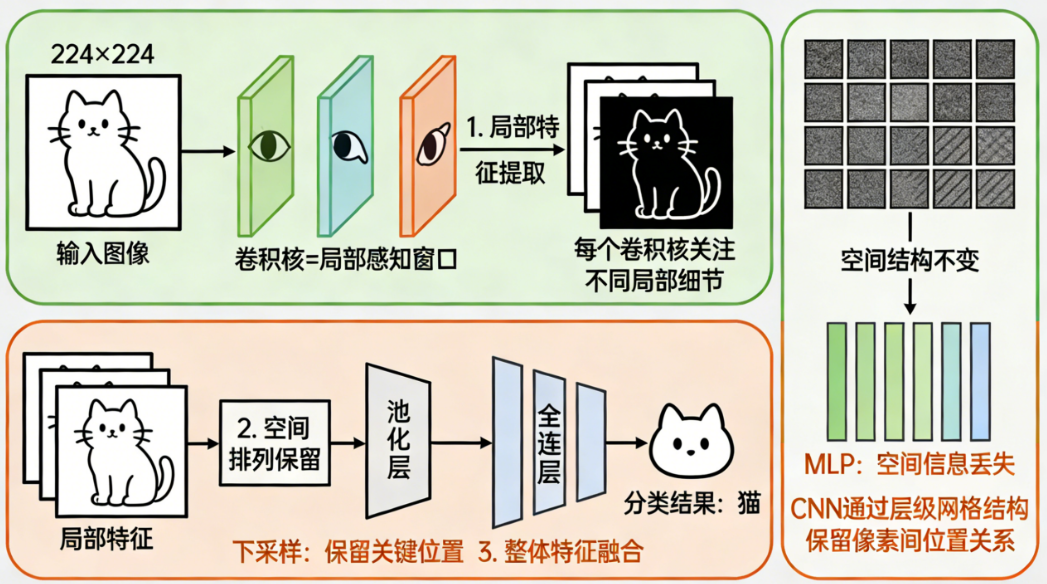
🧩 三、CNN:它的核心能力在于"局部感知 + 空间结构感知"
CNN 不会把图片展平,而是:
- 用小卷积核看局部像素
- 局部特征逐步组合成更复杂的结构
- 保留空间关系
- 对位置、边缘、纹理都有自然的敏感性
所以 CNN 能够做到:
- 看到"这是耳朵"
- 再看到"这是猫脸"
- 最终知道"这是一只猫"
这套逻辑结构是 MLP 天然不具备的。
🧠 四、一个生活类比:
MLP 和 CNN 的不同观察"方式"
我们用一个生活化类比描述两者差异。
🔍 MLP:像"盲盒"评委
给你一副拼图,把所有拼图块打乱成一堆,你必须直接猜图是什么。
MLP 就是这样:
- 它只能看到你给它的所有数字
- 但不知道这些数字在空间上怎么摆
- 这非常难
📷 CNN:像"图片扫描仪"
CNN 是从左到右、从上到下"扫视"图像的:
- 先看到小区域
- 再组合成大区域
- 最终理解整体图形
就像人观察物体一样。
MLP 更像是接收到一堆无序信息,而 CNN 是从有序结构中学习。
🧬 五、结构上的本质区别
我们直接对比它们的结构,这样最清晰。
① 参数量完全不同
假设输入是 224×224×3 的图片:
-
MLP 的第一层如果有 1024 个神经元,需要的参数:
224×224×3×1024 ≈ 150 百万参数
(仅第一层)
-
CNN 的卷积核通常是 3×3×3×32:
3×3×3×32 ≈ 864 个参数
差了几十万倍。
CNN 便宜、轻快;MLP 巨大、难训练。

② 是否保留空间结构?
| 模型 | 是否保留空间结构? | 结果 |
|---|---|---|
| MLP | 不保留 | 看不出局部关系 |
| CNN | 完全保留 | 能看出边缘、纹理、物体 |
这就是 CNN 擅长图像的根本原因。
③ 权重是否共享?
CNN 卷积核在全图共享参数。
MLP 每个像素都需要一个独立权重,不共享。
这又让 CNN 更快、更稳、更容易泛化。
🎨 六、什么时候用 MLP?什么时候用 CNN?
这是最实用的问题,具体如下。
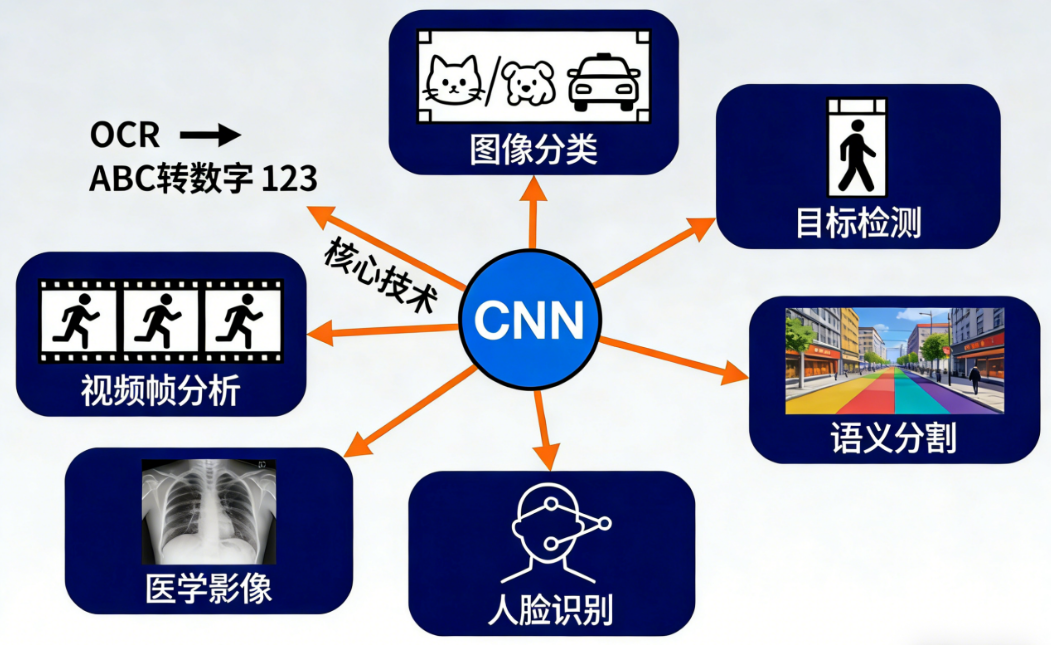
✅ (一)适用 CNN 的场景(绝大多数图像任务)
CNN 是图像领域的"黄金标准":
- 图像分类
- 目标检测
- 语义分割
- 人脸识别
- 医学影像
- OCR
- 视频帧分析
一句话:
只要你的任务是和"图像结构"相关,就选 CNN。
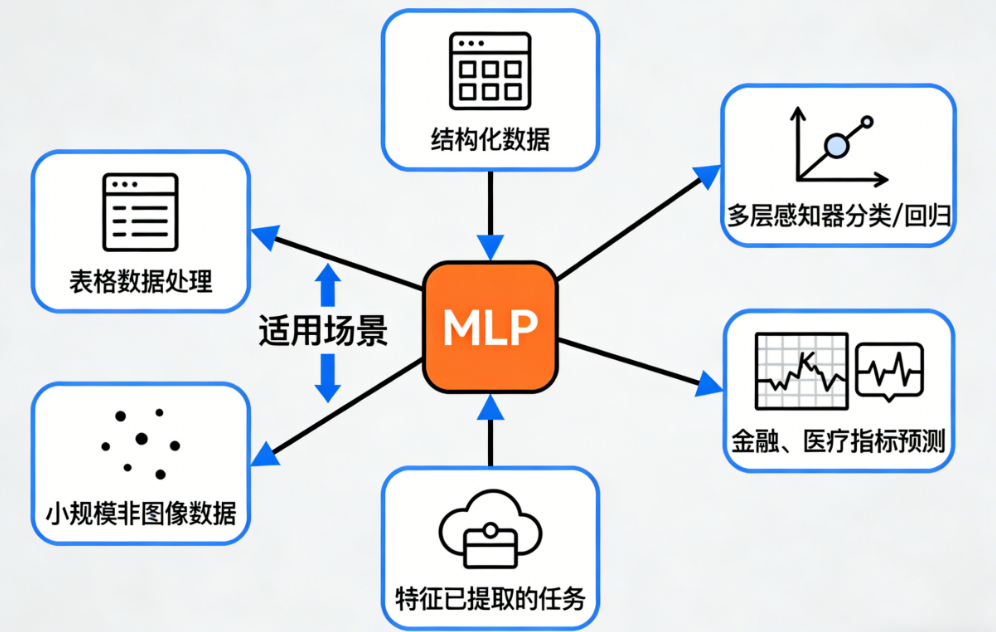
⚪(二)适用 MLP 的场景(图像任务极少见)
MLP 适合:
- 结构化数据(表格数据)
- 多层感知器分类/回归任务
- 金融、医疗指标预测
- 特征已经提取好的情况(如 embedding 输入)
- 小规模非图像数据
简单说:
"行列数据"对 MLP 最友好,而"空间结构数据"对 CNN 最友好。
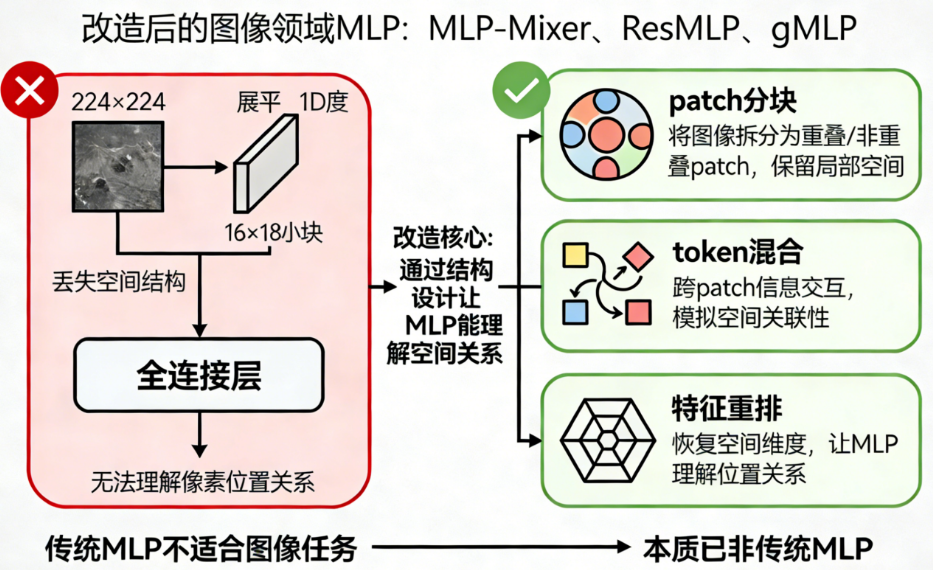
🎯(三)特殊情况:视觉 MLP(Vision MLP)
你可能听过:
- MLP-Mixer
- ResMLP
- gMLP
它们是专门改造过的"图像领域 MLP",通过添加:
- patch 分块
- token 混合
- 特征重排
让 MLP 能理解空间关系。
但它们本质上已经不是传统 MLP 了。
📌 七、本质总结(很重要)
如果你要把本篇最核心的理解记住一句话:
MLP 不懂图像的空间结构,CNN 天然懂。
再扩展一句:
CNN 更像人类视觉:从小块开始理解整个世界;
MLP 更像"全部输入混成一锅"的传统模型。
因此:
- 处理图像 → CNN(优选)
- 处理 structure data → MLP(优选)
这是大多数任务中的实践结论。
🧭 八、快速问答:常见困惑一次解决
Q1:MLP 能不能也做图像分类?
可以,但表现很差,参数多、对空间不敏感。
Q2:CNN 为什么这么高效?
因为它共享权重,并且从局部结构学习。
Q3:MLP 有没有可能超过 CNN?
有,但必须配上 Transformer 的 token 技巧
(例如 MLP-Mixer 系列)。
但这基本属于"改造过的 MLP",不再是传统结构。
Q4:卷积是不是被 Transformer 取代了?
没有。
在数据量不足时,卷积仍然是更稳、更快、更好训练的模型。
🧱 九、用一句极简的话总结本篇
CNN 适合图像,因为它能理解空间结构;
MLP 适合结构化数据,因为它把输入当作一维向量处理。
这就是它们的本质差别。
🔜 下一篇
《深度学习入门体系(第 7 篇):什么是损失函数?交叉熵为什么总是"分类任务的首选"?》