https://arxiv.org/pdf/2501.02822
摘要
道路损伤检测与评估是基础设施维护的关键组成部分。然而,当前的方法通常在单张图像中检测多种类型、不同尺度的道路损伤方面存在困难。这是由于缺乏包含多种尺度损伤类型的道路数据集。为了克服这一缺陷,首先,我们提出了一个名为多样道路损伤数据集 的新数据集,用于道路损伤检测,该数据集捕获了单张图像中多样的道路损伤类型,弥补了现有数据集的一个关键空白。然后,我们提供了我们的模型------RDD4D ,该模型利用了Attention4D模块 ,能够在多个尺度上实现更好的特征精炼。Attention4D模块通过结合位置编码和"Talking Head"组件的注意力机制处理特征图,以捕获局部和全局上下文信息。在我们进行的、比较各种最先进模型在我们提出的数据集上的综合实验分析中,我们增强的模型在检测大型道路裂缝方面表现出卓越的性能,平均精度为0.458,并在整体AP为0.445的情况下保持了有竞争力的性能。此外,我们还在CrackTinyNet数据集上提供了结果;我们的模型性能提升了约0.21。代码、模型权重、数据集及我们的结果可在 https://github.com/msaqib17/Road_Damage_Detection 获取。
索引词---损伤检测,道路检测,损伤分类与识别,类型定位,表面检测,损伤分类,数据集构建,智能手机数据集收集,无人机数据集构建
I. 引言
基础设施和公共设施,例如道路,在一个国家的经济中扮演着至关重要的角色,特别是在现代城市中。在任何国家的经济快速增长时期,重点都集中在修建道路、桥梁和公路上。然而,许多此类基础设施,如道路,由于多种因素(例如雨水、天气、车辆和使用年限)已经老化,导致了各种道路损伤1。
道路损伤严重影响驾驶员的安全、车辆的价值和运行效率。此外,未来几十年需要检测的道路数量将急剧增加;因此,每个国家都需要大量的预算用于维修、恢复、修复和维护2。根据美国联邦公路管理局的数据,2020年美国的道路网络为417万英里,高于1990年的387万英里3。此外,为了修建新道路和维护现有道路,美国政府每年花费超过300亿美元4。在欧洲,每年有5000万人在交通事故中受伤5。与此同时,美国汽车协会记录显示,实际的道路损伤在五年内给美国司机造成了约150亿美元的损失,平均每年30亿美元4。这些统计数据的主要原因是道路状况不佳。
专业工程师依靠他们的知识、经验和背景来识别受影响的基础设施。由于基础设施检测需求的增加,全球许多城市和市政当局利用各种传感器,如激光扫描仪、路面轮廓仪、多个摄像头和3D传感器来检测道路。这些传感器捕获道路资产、路面以及纵向和横向视图的图像。鉴于上述基础设施道路维护和管理的不利趋势,迫切需要高效、可靠和先进的技术进行监控。一种直接的方法是人工视觉评估;然而,这种方法费力、昂贵、耗时且容易出错。
为了解决人工检测的问题,许多研究人员选择了自动道路检测技术来研究道路状况,这些技术大致可分为三类:1) 激光扫描6方法,它能提供关于道路状况的准确信息,但价格昂贵且需要封闭道路;2) 基于振动7的方法仅限于接触到的道路元素;3) 基于视觉8-10的技术成本低廉但精度不足。尽管基于图像的方法存在缺点,但近期基于视觉方法的进展正在取得卓越的成果,从而将其益处扩展到各种应用,如道路标志检测11、交通分析12、人群计数13、目标检测14等。
还应注意的是,配备了不同传感器的专用车辆,包括激光扫描仪、路面轮廓仪、多个摄像头和3D传感器,用于通过捕获道路资产图像、路面图像以及纵向和横向轮廓图像来检测道路15。尽管这些车辆比传统的人工视觉调查方法更便宜且更高效,但根据安装在车辆上的系统所需的传感器,其成本仍可能达到数百万美元每辆16。与此同时,像智能手机这样的手持设备已经普及,配备了高分辨率摄像头、强大的传感器和处理器。因此,基于视觉的技术正在迅速发展并变得更加普及。我们还预计智能手机将在控制道路检测成本方面发挥关键作用。
最近,研究人员尝试利用基于视觉的技术,通过利用卷积神经网络和深度学习方法检测道路表面损伤。为此,研究方向要么是检测道路表面的损伤(不论其类型),要么是将道路损伤类型分类为特定类别8。开创性工作侧重于检测方向性裂缝,即水平和垂直裂缝10,随后发展到检测三种道路损伤类别,即水平、垂直和鳄鱼纹裂缝17。同样,文献9提供了对道路损伤类型的全面分类,因为区分损伤类型对于准确的路况规划至关重要。
迄今为止,基于视觉的检测方法缺乏共同的基础,并存在各种缺陷,例如:1)结果在非标准数据集上进行比较,每种算法都使用自己的道路损伤数据集。我们的目标是创建一个标准数据集,其灵感来源于其他研究领域已建立的标准基准数据集,例如用于去噪的DnD、用于目标分类的ImageNet和用于点云的PartNet。2)数据集通常只有一个视角用于评估方法。3)算法在设计用于道路损伤检测的网络方面投入不足,或者简单地采用来自其他视觉研究领域的最先进的现成模型。需要一个专门针对道路损伤检测需求的网络模型。4)最后,道路损伤可以分为多种类型(例如日本的八种损伤类型);然而,当前的研究只考虑了其中的少数几种;因此,它们在实际场景中的直接应用具有挑战性。
我们的贡献:本研究的贡献如下:
- 我们提出了一个新的、具有挑战性的道路损伤检测数据集,该数据集捕获了单张图像中不同条件下的多种损伤类型,弥补了现有数据集的一个重要空白。该数据集能够更稳健地训练和评估检测模型。
- 我们引入了一种用于道路损伤检测的4D注意力机制。这种增强使网络能够同时处理局部细节和全局上下文,从而更准确地检测不同尺度的道路损伤。
- 通过与最先进模型的广泛实验评估比较,我们提供了全面的基准测试结果,展示了当前道路损伤检测方法的优势和局限性,为未来的研究方向提供了有价值的见解。
II. 相关工作
道路基础设施的维护对于确保安全高效的交通至关重要。道路维护中最重大的挑战之一是检测和监控道路表面的裂缝。道路表面的裂缝可能导致事故,如果不及时检测和处理,可能导致昂贵的维修费用。机器学习技术,特别是CNN,被广泛应用于自动道路裂缝检测。这些技术在提高道路裂缝检测、分类准确性和效率方面显示出前景。然而,这些方法在真实世界数据和大型数据集上的评估有限,而这对于实际应用至关重要。在本节中,我们分析了最近使用机器学习技术进行道路裂缝检测的研究,重点介绍了它们的目标、贡献和局限性。本综述旨在概述使用机器学习进行裂缝检测的最新技术,并确定提高这些方法准确性和鲁棒性的前瞻性研究方向。
A. 传统方法
使用传统图像处理算法研究道路损伤检测,这些算法主要依赖于背景减除、阈值分割、分割和特征提取。例如,使用带有OTSU阈值的灰度直方图18、灰度共生矩阵19、改进的中值滤波和形态学滤波20、支持向量机算法21、机器学习模型库22和边缘检测器23来检测路面裂缝和不同类型的道路损伤。然而,这些算法存在局限性和缺点,例如对照明和背景变化的敏感性、对人工设计特征的依赖、对噪声的敏感性、复杂背景以及无法推广到各种道路及其类型,从而降低了道路损伤检测的准确性。
B. 深度学习方法
最近的研究24,25利用深度卷积神经网络进行自动道路评估和损伤识别。Zhang等人26训练了有监督的深度CNN来分类智能手机路面图像以进行道路损伤检测,旨在发现是否存在损伤。类似地,基于VGG的网络27检测混凝土表面的裂缝。此外,Crack-pot28采用基于摄像头的GPU板来识别道路裂缝和坑洞,这为自动驾驶车辆和机器人提供了平稳的行驶体验。同样,Fan等人29训练了一个简单的CNN来识别路面状况,展示了其有效管理各种路面特征的能力。此外,文献30表明,深度神经网络在识别路面裂缝方面优于边缘检测方法。
最近,Karaaslan等人31在一个半监督的基于深度学习的注意力引导方法中分析了裂缝和剥落,其中检测到的边界框经过人工验证,然后应用像素级分割,从而显著降低了分割的计算成本。Guan等人32将立体视觉与深度学习相结合,通过创建由2D、3D和增强3D图像组成的数据集,对裂缝和坑洞进行了基于分割的分析。此外,为了更快地进行分割,作者使用了基于深度可分离卷积的改进U-net,并执行了3D图像分割以自动测量坑洞的体积。类似地,Asfault方法33收集车辆加速度计传感器的数据来记录车辆振动,并使用机器学习评估道路状况。
C. 基于智能手机的方法
由于具有各种传感器、高分辨率多摄像头、大存储内存和有效的处理器,像智能手机这样的手持设备最近已成为道路检测的标准工具。此外,手持设备对于检测大型道路网络来说是高效且具有成本效益的。例如,SmartPatrolling34利用智能手机内置传感器收集数据,并利用动态时间规整来评估路面状况,其性能优于传统算法。类似地,Mertz等人35使用安装在日常作业车辆(例如普通乘用车、公共汽车和垃圾车)上的车载智能手机检测道路损伤,并连接到笔记本电脑进行处理。Casas-Avellaneda和Lopez-Parra36使用智能手机在地图上可视化坑洞。Maeda等人37设计了一个用于收集和检测道路缺陷的智能手机实时应用。
D. 道路损伤检测数据集
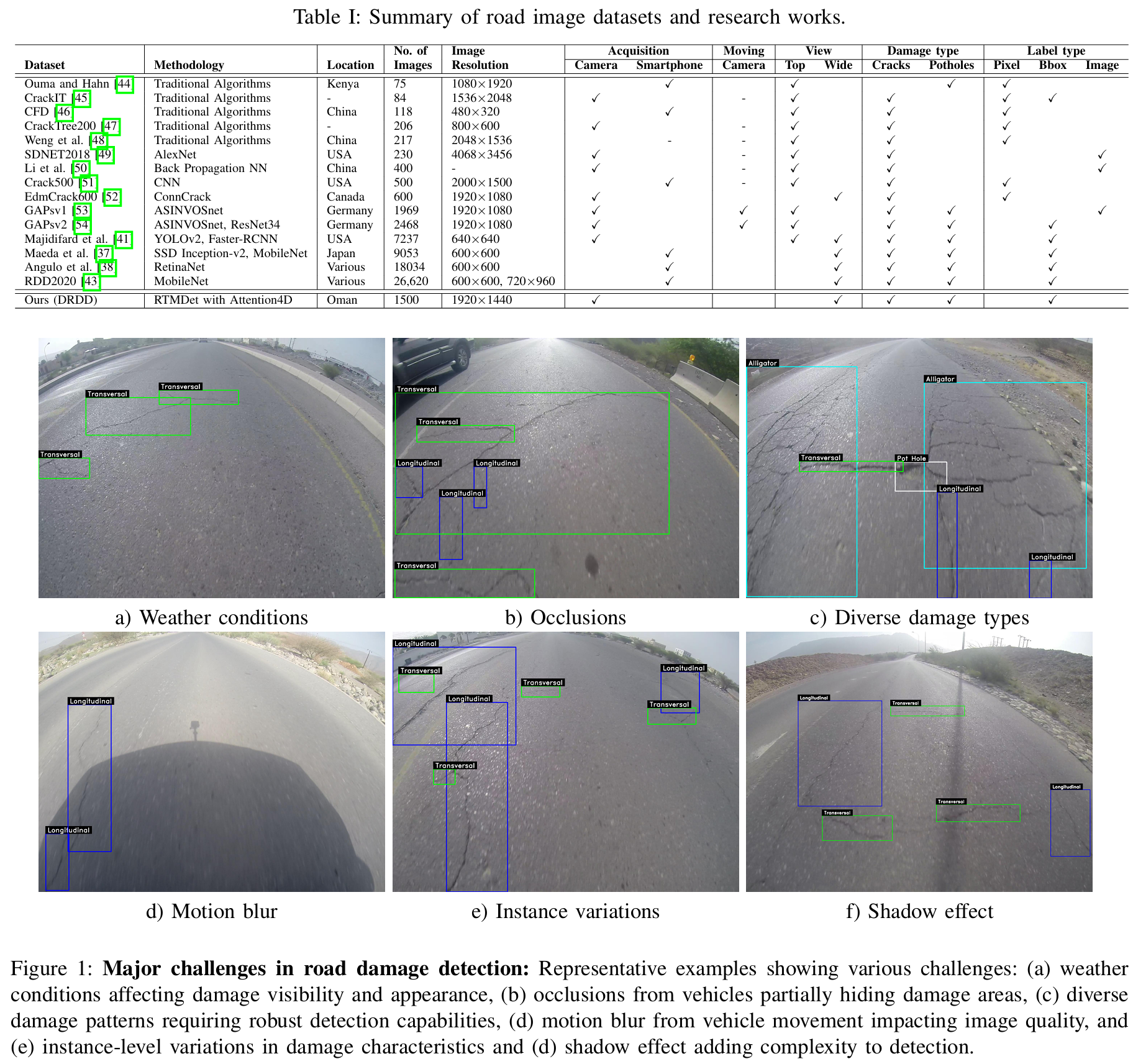
Maeda等人37编制了公开可用的RDD-2018数据集,该数据集通过智能手机应用收集。全球多个市政当局正在使用该应用来更快地监控道路状况。因此,世界各地的研究人员对这些数据、方法和模型表现出了兴趣。继37之后,研究人员要么向数据集中添加更多图像,要么使用该软件收集新的数据集。例如,38的作者通过包含来自意大利和墨西哥的图像扩展了数据集,将数量增加到超过18k张。类似地,39利用37的软件,结合了来自意大利的7k张道路损伤图像。模型在新的数据集上进行训练,并考虑了已识别的道路损伤严重性。40的作者使用工业高分辨率相机收集了来自上海的超过45k张道路图像数据集,并使用YOLO模型检测和分类路面损伤。另一方面,41使用了谷歌街景图片,这些图片易于获取且免费,包含表征和计算密度的顶部和广角视图。研究表明Faster R-CNN落后于YOLO-v2模型。此外,42使用了有限的谷歌API图像进行基于CNN的坑洞检测。尽管谷歌街景照片具有可访问性和免费性,但标注它们仍然费力、耗时且劳动密集。最近,提出了RDD43用于检测和分类道路损伤,该数据集包含大量图像。然而,大多数照片只包含单一损伤,并且损伤本身并不特别复杂。另一方面,我们收集的数据集中的损伤更加复杂,并且通常在一张图像中出现多个实例。表I显示了有关数据集的更多信息。
总而言之,所综述的研究表明,机器学习技术,特别是深度CNN,能够准确检测道路裂缝。然而,这些评估仅限于小数据集,并且对真实世界数据的评估有限,而这对于实际应用至关重要。此外,一些研究缺乏对所提出的CNN的详细解释,使得结果难以复现。
III. 数据集
我们生成并收集了最具挑战性的道路损伤数据集。我们的数据集称为多样道路损伤数据集 ,包含1500张图像,涉及5种损伤类型,使用GoPro相机在不同天气条件和白天时间拍摄。我们第一个数据集中图像的分辨率为1920×14401920\times14401920×1440像素。我们已经与研究人员和市政规划人员核实,额外的视角将方便作为初始阶段。该数据集包含5个不同的类别,具有现实世界中的长尾类别不平衡和独特的类别分布,如图5所示。此外,数据标注项目涉及12名具有专业技能和不同背景的人员,耗费了大量的人工小时。我们还对每批数据进行了几轮质量评估。
A. 数据集特征
多样化条件。DRDD针对不同场景和天气条件收集。图像包含丰富的背景,如树木、建筑物、构筑物和其他车辆。与现有数据集不同,我们数据集中的图像在场景中具有更多样化的物体分布。由于拍摄时间不同,光照条件也不同,影响了图像中像素的颜色。类似地,图像在晴天和阴天条件下拍摄,以捕捉变化。天气条件会影响损伤类型和背景,这使得许多算法难以区分天气引起的结构特征和实际损伤类型。
损伤密度。我们的数据集包含各种密度场景,分为三个级别:少于两个、两到三个以及多于三个损伤类型。高密度是我们数据集最关键的特征之一。表I比较了广泛用于大规模户外场景损伤检测类型的相关数据集。我们的数据集有三个显著的评估参数:i) 每张图像的损伤类型数量,我们的数据集平均有3个损伤,多于现有数据集;ii) 场景中损伤类型的分布显示了道路损伤的比率,统计数据显示我们的数据集在密度上超过其他数据集;iii) 损伤程度,通过计算每个损伤类型周围以米为单位的平均损伤数量来衡量。
遮挡。DRDD在常规交通时段收集,以确保它们反映实际场景。然而,一个缺点是数据集中的图像存在遮挡。图1(b)展示了这种情况的一个例子,其中损伤类型部分被遮挡,由于可见特征有限,使得检测具有挑战性。根据遮挡情况,数据集可以测试技术在具有挑战性案例中的性能。
实例级多样性。我们在图1(e)中展示了不同的实例级密度。损伤类型之间的类间差异显著。由于形状和尺度细节的变化,远距离实例难以学习,因为损伤类型在大小、结构和外观上各不相同,这使得我们的数据集对大多数现有算法具有挑战性。
多样化损伤类型。道路损伤不遵循特定的模式;因此,单个场景可能包含不止一种类型的损伤。这也反映在我们的数据集中,其中存在不止一种损伤类型。此类图像如图1©所示。
B. 数据集挑战
我们在规模上取得了比以往任何数据集都大得多的成果;规模对于泛化(任何数据集的最终目标)至关重要。然而,跨城市和国家使用数据也带来了几个挑战,例如噪声源和模糊性。我们在数据集中管理了几个已知的噪声源和模糊性,如图1所示。
标注噪声。标签的准确性在很大程度上取决于标注者,他们是专家和领域专家;因此,与志愿者或正在学习该过程的人相比,标注很可能更准确。此外,对于损伤类型没有公认的定义。
图像质量。通过各种相机和手持设备获取的图像的质量和分辨率差异很大。有时车辆会遮挡道路损伤,我们通过手动删除图像来避免,但部分遮挡的可能性始终存在。此外,我们还在数据集中捕获了多个视角以缓解遮挡问题。
未标注的伪影。有些伪影并未对道路造成损伤,但有一些临时或表面的标记,例如刹车时轮胎的拖痕、道路上的油漆剥落或树枝、垃圾等不需要的物品的一部分。这些可能看起来类似于道路损伤类型;然而,我们关注的损伤通常是最突出的,其他伪影的存在可能会在检测和定位中造成混淆,从而误导算法。
修补噪声。道路损伤通常使用人工技术修复,但由于使用临时材料,这些修补很快会脱落。这种修补通常会掩盖实际损伤的结构,给标注者带来困惑,导致准确性差异。
不需要的阴影。太阳的方向会影响图像。如果太阳在拍摄图片的车辆后方,车辆阴影可能会遮挡图像的一部分,甚至可能遮挡损伤类型的某些部分,如图1(d)所示。因此,这对算法来说变得具有挑战性,因为损伤类型的某些区域被阴影掩盖,而其他区域则处于直射阳光下,导致像素颜色差异。
C. 评估协议
我们建立了一个评估协议,明确地将我们的数据集划分为训练/测试集,具体表达如下。
按数据集划分。根据传统协议,我们关注算法在训练和测试集属于同一数据集时的泛化能力。训练集和测试集是互斥的;这里,训练在指定数量的图像上进行,测试在同一数据集的另一组图像上进行,以避免在特定类别上过拟合。
D. 标注
我们手动为两个数据集的图像标注了高质量的真实标签。我们使用2D边界框(x,y,w,h)标注了道路损伤类型,其中x,y表示中心坐标,w,h分别是沿x轴和y轴的宽度和高度。为每种损伤类型提供了一个文件,其ID与图像相同。
E. 道路裂缝类型
最后,我们想介绍一下道路损伤的类型。损伤类型可以分为鳄鱼纹裂缝、块状裂缝、纵向裂缝、坑洞裂缝和横向裂缝。这些是最主要的类型,通常在全球大多数道路上都可以找到。图1显示了这些提到的裂缝。
- 坑洞:坑洞是由于水渗入道路并侵蚀下方地面而在道路表面形成的孔洞。此外,重型交通和磨损的表面层会加剧损伤,导致沥青破碎形成坑洞。最初很小,由于持续的车辆交通进一步侵蚀沥青,以及雨水或洪水冲走更多材料,这些坑洞会迅速扩大。
- 纵向裂缝:这些裂缝沿着道路的长度延伸,可能是由地面膨胀和收缩、排水不良或路基沉降引起的。它们通常由地面的自然运动引起,可以在路肩和道路中心线上找到。纵向裂缝也可能是由于暴露在阳光和高温下导致沥青表面收缩引起的。
- 横向裂缝:这些裂缝横穿道路,通常由温度变化和重型交通引起。当道路随着温度变化而膨胀和收缩,导致沥青表面开裂时,就会发生这类裂缝。这些类型的裂缝通常出现在车轮轨迹中,主要是由下层反射裂缝引起的。
- 鳄鱼纹或疲劳裂缝:这是一系列相互连接的裂缝,类似于鳄鱼的皮肤。它们是由于沥青表面失效和重型交通荷载引起的。当沥青表面无法再支撑交通重量并开始疲劳和变形时,就会发生这些裂缝。这些裂缝也被称为"疲劳开裂",可以在路肩和车轮轨迹上找到。
- 块状裂缝 :这些是将表面分成大块或矩形块的裂缝。当沥青表面过厚且顶层收缩率与底层不同,导致表面开裂时形成。

IV. 方法论
由于其在COCO数据集上的卓越性能以及与边缘计算设备的兼容性 ,我们选择实时模型检测 轻量级目标检测模型作为我们的基线。该模型是单阶段实时目标检测家族的最新成员,在目标检测和实例分割任务中取得了出色的性能。如图3(a)所示,RTMDet架构包括三个主要模块:骨干网络、颈部和头部。最近的研究通常在RTMDet中采用CSPDarkNet55作为骨干架构;然而,我们采用了CSPNeXt作为我们的骨干网络56,该架构在基础模块中利用了大核深度可分离卷积。我们的选择基于以下观察:通过使网络更深更宽,该模型能快速学习全局上下文。
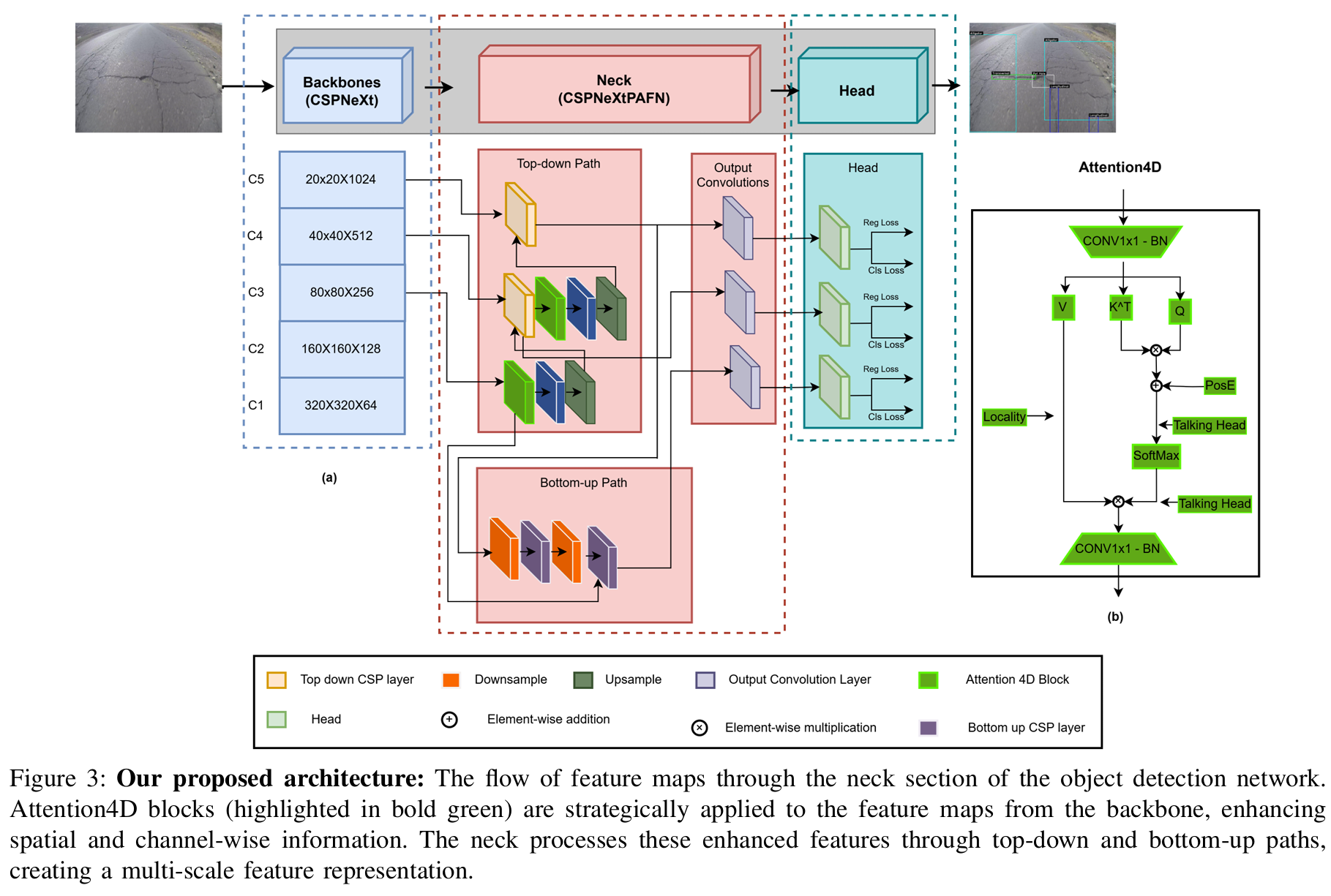
骨干模型有两种选择。第一种是较小的架构,表示为P5\mathrm{P_{5}}P5,而第二个版本P6\mathrm{P_{6}}P6是较大的变体。我们选择了前一个版本,它在下采样2k2^{k}2k倍后产生五个特征图尺度,其中k∈{1,2,⋯ ,5}k\in\{1,2,\cdots,5\}k∈{1,2,⋯,5},表示为C1, C2, C3, C4\mathrm{C_{1},\:C_{2},\:C_{3},\:C_{4}}C1,C2,C3,C4和C5\mathbf{C}{5}C5。颈部模块使用骨干网络最后三个特征图尺度C3 (i.e.,8,256,80,80)\mathrm{C{3}}\;(\mathrm{i.e.},8,256,80,80)C3(i.e.,8,256,80,80)、C4\mathbf{C}{4}C4(即8, 512, 40, 40)和C5\mathbf{C}{5}C5(即8,1024, 20, 20)执行特征融合。此外,颈部模块进一步结合了多尺度特征金字塔网络,该网络使用来自骨干网络的三个特征图,并通过自上而下和自下而上的特征传播57,58来增强特征,然后将其传递到头部进行检测和分类。
需要注意的是,CSPNeXtPAFPN架构的自上而下和自下而上路径虽然有效,但可能无法充分利用不同尺度特征之间的可能关系,可能导致细粒度细节的丢失。RTMDet的颈部部分负责融合和精炼来自骨干网络的多尺度特征。因此,我们提出并集成了Attention4D模块。通过利用这一点,所述模型可以更有效地捕获和利用跨不同尺度的局部和全局上下文信息。最终,每个尺度的特征图被检测头用来预测目标边界框及其类别。这种架构适用于一般目标和旋转目标。它还可以通过添加核和掩码特征生成头来扩展到分割任务59。
Attention4D模块 :我们模型的核心创新是Attention4D模块 ,如图3(b)所示。该模块通过一系列操作处理输入特征图。首先是一个1×1卷积,然后是批归一化以调整通道维度。输出被分成三个分支:值、转置键KT⃗\vec{K^{T}}KT 和查询。键分支和查询分支进行逐元素乘法。结果结合了位置编码和"Talking Head"输入。Softmax操作对注意力权重进行归一化。Softmax输出与值分支和另一个"Talking Head"输入进行逐元素相乘。最后,结果通过另一个1×1卷积和批归一化。这个Attention4D模块使网络能够捕获局部和全局上下文信息,潜在地提高了模型对复杂场景的理解能力。Attention4D模块被战略性地集成在颈部架构自上而下路径的关键点。
在自上而下路径中,一个Attention4D块在处理来自最高层特征图的输入之后进行进一步精炼。我们在第一个自上而下的CSPLayer之后应用第二个Attention4D块。自下而上路径将来自自上而下路径的Attention4D块的输出馈送到下采样操作中,然后到达自下而上的CSPLayers。这种集成使得网络能够在多个尺度上使用我们的注意力机制精炼特征,潜在地捕获细粒度细节和高级语义信息。
损失函数 :训练单阶段目标检测器的关键一步是将不同尺度的密集预测与真实边界框进行匹配。这个过程被称为标签分配 ,随着时间的推移已经发展出多种策略60-62。虽然最近的方法集中在标签分配的动态方法学上63-65,但我们采用了动态软标签分配策略66,该策略使用与训练损失一致的成本函数作为匹配标准,以更准确地将标签分配给预测的边界框。这种动态软标签分配策略基于最先进的框架65。成本函数定义如下:
ℓ=λ1⋅δ+λ2⋅θ+λ3⋅ρ,\ell=\lambda_{1}\cdot\delta+\lambda_{2}\cdot\theta+\lambda_{3}\cdot\rho,ℓ=λ1⋅δ+λ2⋅θ+λ3⋅ρ,
其中λ1=1,λ2=3,\lambda_{1}=1,\lambda_{2}=3,λ1=1,λ2=3,和λ3=1\lambda_{3}=1λ3=1是默认的加权因子。此外,δ\deltaδ、θ\thetaθ、ρ\rhoρ和lll分别代表分类、定位、中心邻近度和总成本。在传统方法中,δ\deltaδ通常依赖于二进制标签。这可能导致分类得分高但边界框不准确的预测获得较低的分类成本,反之亦然。为了解决这个问题,提出了软标签yyy分配策略来代替二进制标签。我们计算修改后的分类成本如下:
δ=CE(y^,y)⋅(y−y^)2,\delta=\mathrm{C E}(\hat{y},y)\cdot(y-\hat{y})^{2},δ=CE(y^,y)⋅(y−y^)2,
其中CE代表交叉熵,y^\hat{y}y^是预测值。这种方法的动态方面意味着标签分配在训练期间可以改变,允许模型专注于信息量最大的样本。受GFL71启发,SoftLabel使用交并比作为软标签,提供更详细的预测准确性评估。对于θ\thetaθ,现有方法使用广义IoU72通常缺乏对高质量和低质量匹配的足够区分。软标签方法使用对数IoU尺度θ=−log(IoU)\theta=-\log(\mathrm{I o U})θ=−log(IoU),放大了好匹配和差匹配之间的差异,特别是对于较低的IoU值。这有助于模型在训练期间区分高质量和低质量的预测。
最后,中心邻近度成本用以下公式取代了僵化的基于中心的准则64,65,73:
ρ=η∣yc^−yc∣−ϵ,\rho=\frac{\eta}{|\hat{y_{c}}-y_{c}|-\epsilon},ρ=∣yc^−yc∣−ϵη,
其中η\etaη和eee是可调参数,而yc^\hat{y_{c}}yc^是预测中心,ycy_{c}yc是实际中心。在公式1所示的总体成本函数中,中心成本不仅鼓励在分类和边界框回归方面准确的预测,而且还鼓励预测位于目标中心。例如,如果两个预测在分类置信度和边界框重叠方面相似,那么在训练期间会更倾向于更接近真实目标中心的预测。
V. 实验
A. 设置
训练细节 。在训练期间,我们在实验中使用批大小为4。我们将权重衰减设置为0.9,表明有相当大的正则化效果来对抗过拟合,尽管这个数字比通常的要大。与通常在0.8到0.99之间的常规值相比,我们将动量设置为5e-4。我们将模型训练了300个周期,以确保完全的性能优化。
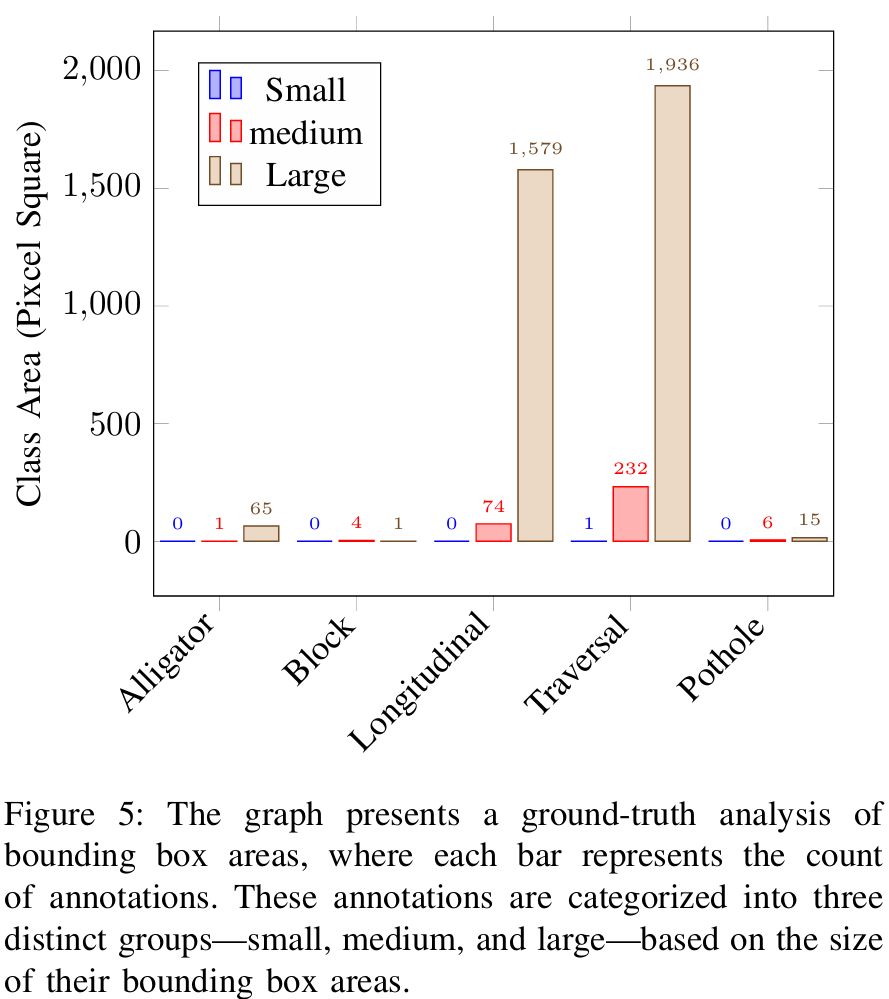
数据集 。道路裂缝数据集的视频是使用安装在汽车前部、对准道路表面的GoPro相机录制的。当车辆穿越各种道路时,它记录了在不同光照条件下的多种类型的裂缝,全面代表了不同的道路状况。土木工程师仔细审查并验证了每种道路状况,以准确识别和确认各种裂缝类型的存在。我们以MP4格式录制了30个视频片段,每个片段的分辨率为1920×1440像素,帧率为30fps。大多数视频片段持续20到30分钟。然后将这些视频转换为帧,并丢弃由于车速导致的模糊图像以保持质量。我们使用计算机视觉标注工具以Pascal-VOC和COCO格式标注图像。从视频片段中,我们共标注了1,500张图像。图5展示了数据集的分布。一些视频帧包含多达45个标注,显示了单帧内各种道路裂缝的复杂和杂乱性质。COCO指标根据边界框的面积将数据集中的对象分为三种大小。小对象占据少于32×3232\times3232×32像素的区域,中等对象在32×3232\times3232×32像素到96×9696\times9696×96像素之间,大对象超过96×9696\times9696×96像素。根据我们对真实标签的分析,如图5所示,大多数标注对象根据COCO指标被归类为大或中等。
评估指标。为了评估我们目标检测器的性能,我们使用了COCO评估指标,这是评估目标检测和分割模型的标准指标。COCO评估框架提供了跨不同IoU阈值和基于不同对象大小(小、中、大)对模型性能的详细分析。
VI. 比较
A. 在我们提出的DRDD数据集上的比较
精确率和召回率是用于评估模型性能的重要指标。精确率衡量检测的准确性,即预测为阳性的识别中实际正确的比例。高精确率表明模型在其识别中很少犯错,当它预测对象存在时是可靠的。另一方面,召回率评估模型捕获数据集中所有实际阳性检测的能力。它反映了模型做出的真正阳性检测相对于数据集中实际存在的阳性总数的比例。高召回率表明模型漏掉的真实阳性很少,最大限度地提高了如果对象存在则模型将识别它的机会。在这两个指标上平衡的性能对于可靠的道路损伤检测系统至关重要。我们评估了各种深度学习模型,即YOLOv8 74、YOLOv7 68、YOLOV6 75、PPYOLOE 69、YOLOX 65和RTMDet 66,在使用平均精度和平均召回率指标检测小、中、大型道路裂缝方面的性能,如表IV所示。
所有模型在小型损伤上的AP和AR分数为-1.000(APS\mathrm{A P_{S}}APS和ARS\mathrm{A R}_{S}ARS),这表明数据集中不存在小型损伤,而不是检测性能差。这一观察证实了我们数据集中的大多数道路损伤属于大型类别。对于中型损伤,YOLOv7获得了最高的AP 0.127,其次是RTMDET的0.123。在大型损伤类别中,我们数据集中的实例大多集中于此,我们的RDD4D方法以0.458的AP显著优于其他方法,而RTMDET以0.280的AP位居第二。
在召回率性能方面,YOLOV6在检测中型损伤方面表现出强大的能力,AR最高为0.460,其次是PPYOLOE的0.388。对于构成我们数据集主体的大型损伤,我们的方法获得了最佳的AR 0.690,RTMDET紧随其后为0.623。总体而言,我们提出的方法表现出优越的性能,在所有模型中获得了最高的AP、AP50和AP75分数,分别达到0.446、0.687和0.451,相较于表现次佳的RTMDET(AP=0.268,AP50=0.527,AP75=0.229\mathrm{A P}=0.268,\mathrm{A P}50=0.527,\mathrm{A P}75=0.229AP=0.268,AP50=0.527,AP75=0.229)有显著改进。这些结果验证了我们方法的有效性,特别是在检测占主导地位的大型道路损伤方面。
关于召回率,所有模型在处理小对象时都遇到困难,AR得分为-1.000。这是由于数据集中没有小型裂缝。PPYOLOE对中型物体记录了最高的AR 0.388,表明其在识别中型裂缝存在方面更有效,尽管其精确率较低。我们的模型在大型道路裂缝上表现出最高的召回率,AR为0.690,确认了其在精确率和可靠识别数据集中更高比例的大型道路裂缝方面的鲁棒性。
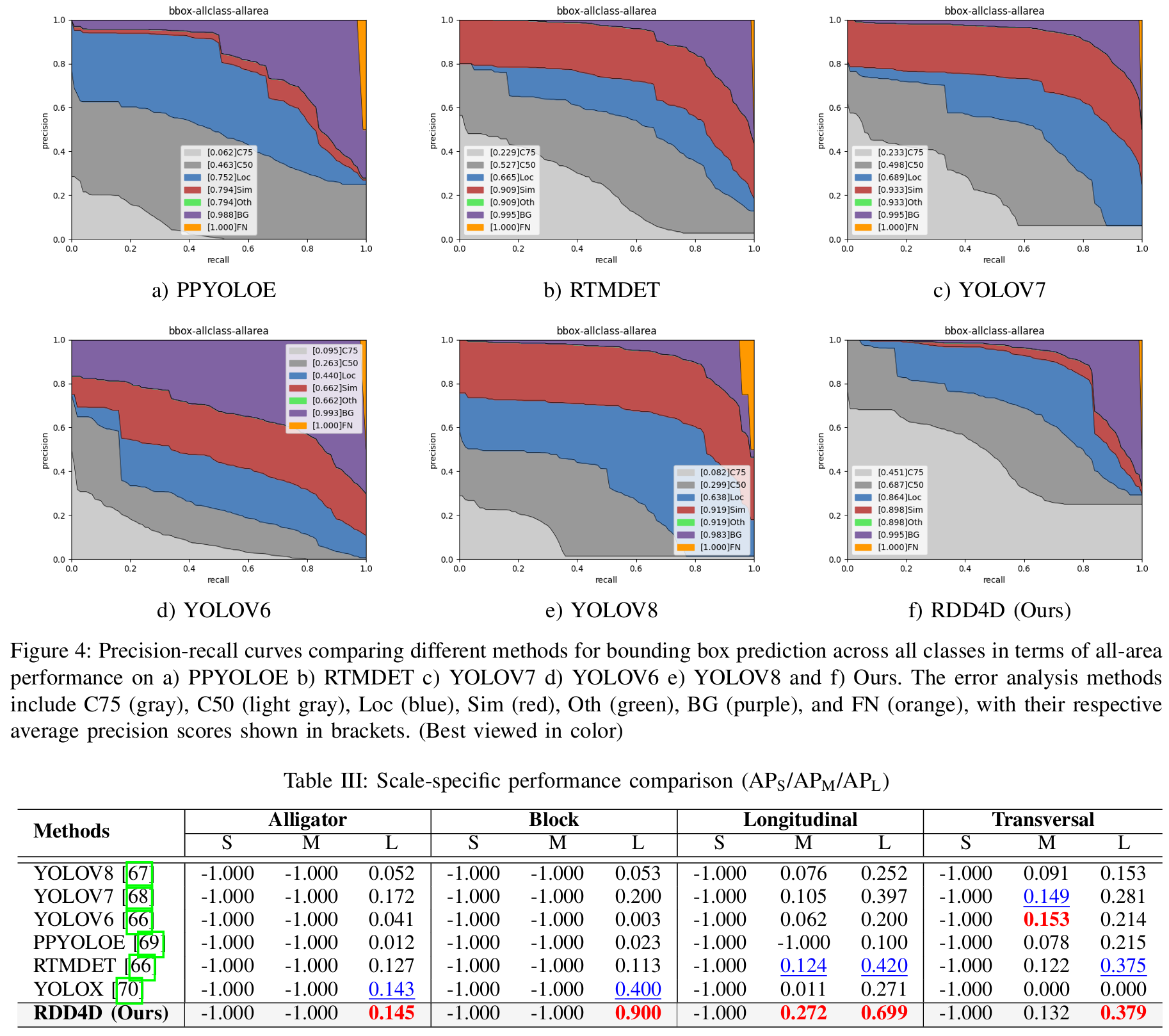
图4显示了我们模型与其他模型之间各种误差分布的全面分析。道路损伤评估中的检测误差可以分为几种类型:当边界框放置不精确时的定位误差 ;视觉相似损伤类型之间的基于相似性的混淆 ;损伤被错误分类的类别混淆 ;正常路面被错误识别为损伤的背景误报 ;以及实际损伤未被检测到的漏报 。我们的模型获得了更高的置信度分数(C75=0.451C75=0.451C75=0.451,C50=0.687C50=0.687C50=0.687),相比于YOLOV6(C75=0.095,C50=0.263C75=0.095,C50=0.263C75=0.095,C50=0.263)、YOLOV7(C75=0.233C75=0.233C75=0.233,C50=0.498C50=0.498C50=0.498)和YOLOV8(C75=0.082, C50=0.299C75=0.082,\;C50=0.299C75=0.082,C50=0.299)。定位精度(Loc=0.864\mathrm{L o c}=0.864Loc=0.864)优于所有其他模型,表明边界框预测更精确。我们的模型在较高的召回率值上保持了更好的精确率,具有更平衡的基于相似性和类别混淆误差的分布(Sim和Oth=0.898\mathrm{Oth}=0.898Oth=0.898)。虽然背景检测误差(BG=0.995\mathrm{BG}=0.995BG=0.995)和漏报(FN=1.000\mathrm{F N}=1.000FN=1.000)存在,但它们在图中所占比例相对较小,特别是在高召回率值下。更平滑的曲线和随着召回率增加精确率逐渐下降的趋势表明检测性能更稳健和稳定。这种跨所有误差类别的全面改进表明,我们的模型不仅实现了更好的绝对性能,而且比现有方法更有效地处理各种检测挑战。
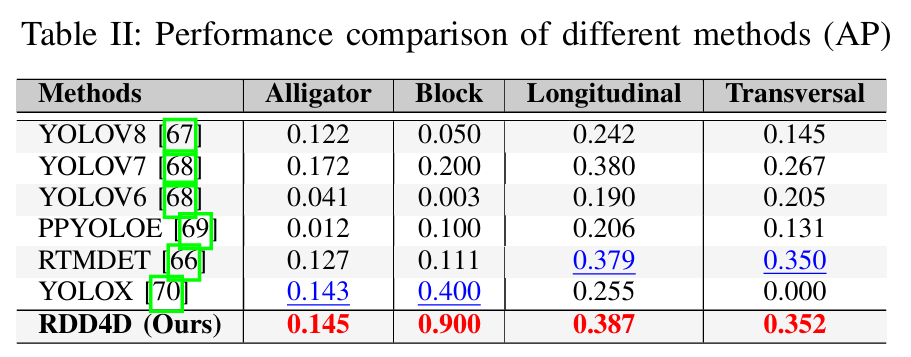
表II提供了每个类别的AP,表III展示了跨不同损伤类型的详细尺度特定分析。Alligator和Block裂缝以及Transversal裂缝中、小尺度的值为-1.000,表明我们的数据集中不存在这些尺度的变化。我们的方法在检测所有类别的大型尺度损伤方面表现出卓越的性能,在Alligator、Block、Longitudinal和Transversal裂缝上获得了最高的AP分数,分别为0.145、0.900、0.699和0.379。

这一全面分析证实了我们的模型在不同损伤类型和尺度上的稳健性能,特别是在检测大型道路损伤方面表现出色,而这些损伤构成了现实世界中的大多数情况。
B. 在CrackTinyNet数据集上的比较
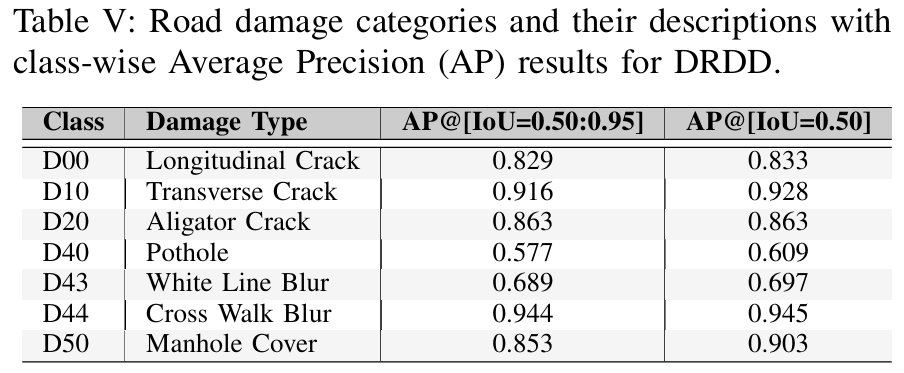
如表VI所示,我们提出的方法在CrackTinyNet76数据集上相比于现有方法有显著改进。该数据集将道路表面缺陷分为七个不同的类别:三种裂缝类型(纵向-D00、横向-D10和鳄鱼纹-D20)、表面变形(坑洞-D40)、两种标记劣化类型(白线模糊-D43和人行横道模糊-D44)以及基础设施元素(井盖-D50)。我们的模型以0.825的mAP@.5分数显著优于先前的最佳表现者CrTNet76(0.601),在这项数据集上检测准确率提升了37%。与广泛使用的目标检测框架如YOLOv874(0.445)和EfficientDet77(0.552)相比,这一改进尤为显著。我们的模型产生的误报检测更少,这对于实际应用至关重要,因为误报可能导致不必要的维护检查。像YOLOv5s 78和SSD 79这样的传统模型显示出相当低的精确率(分别为0.27和0.31)。也许最令人印象深刻的是,我们的模型达到了0.98的召回率,展示了其检测数据集中几乎所有道路损伤实例的能力。这相较于CrTNet的0.61召回率有显著提升,并且远远超过了其他基准模型,如Fast R-CNN 80(0.55)和YOLOv8(0.53)。
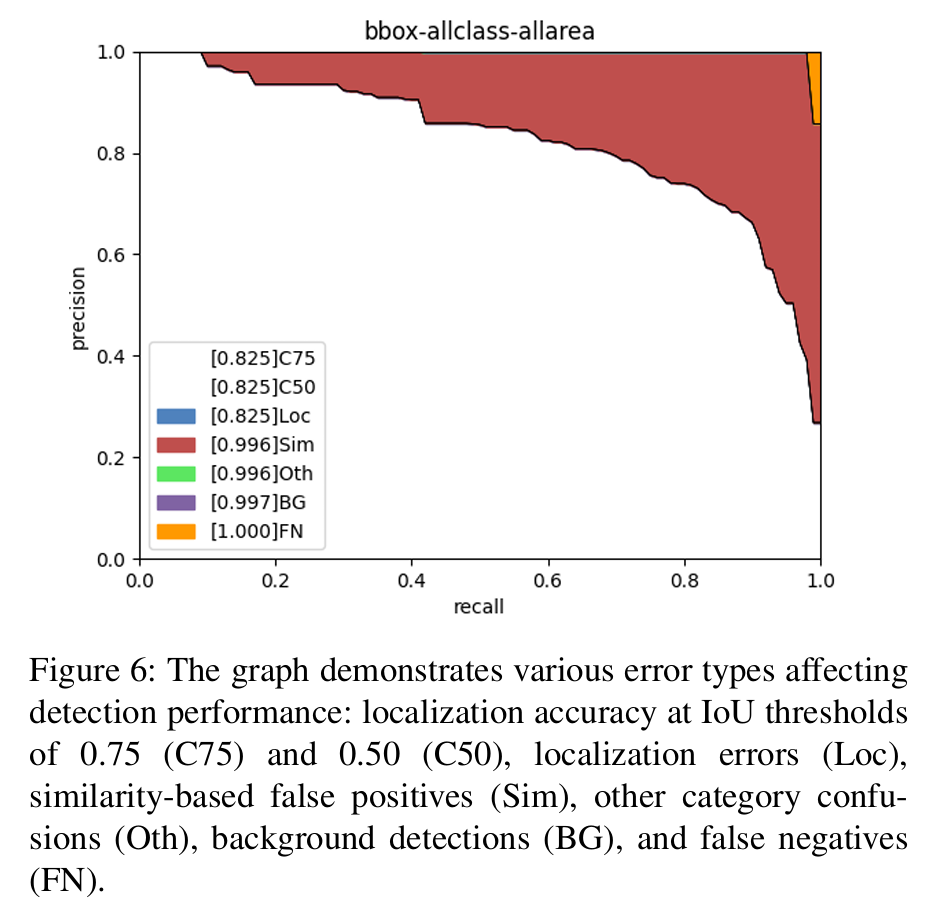
图6中的精确率-召回率图显示了模型在不同IoU阈值下具有一致的置信度分数(C75和C50均为0.825)的优秀性能。代表相似性误差(Sim=0.996)的红色主导区域表明,大多数检测错误源于相似损伤类型之间的混淆,而不是定位问题(Loc=0.825\mathrm{L o c}=0.825Loc=0.825)或背景误识别(BG=0.997)。该模型在大多数召回率值上保持高精确率,性能仅在非常高的召回率水平下才下降。表V中的类别性能分析显示,我们的模型在检测人行横道模糊(D44)和横向裂缝(D10)方面表现出色,在两个IoU阈值上都获得了超过0.90的AP分数。对鳄鱼纹裂缝(D20)、井盖(D50)和纵向裂缝(D00)的检测也表现出强大的性能,AP分数超过0.82。然而,该模型在检测白线模糊(D43)和坑洞(D40)方面显示出相对较低的准确性,其中坑洞是最具挑战性的类别,AP分数为0.577和0.609,这可能是由于其不规则的形状和多变的外观。
C. 消融研究
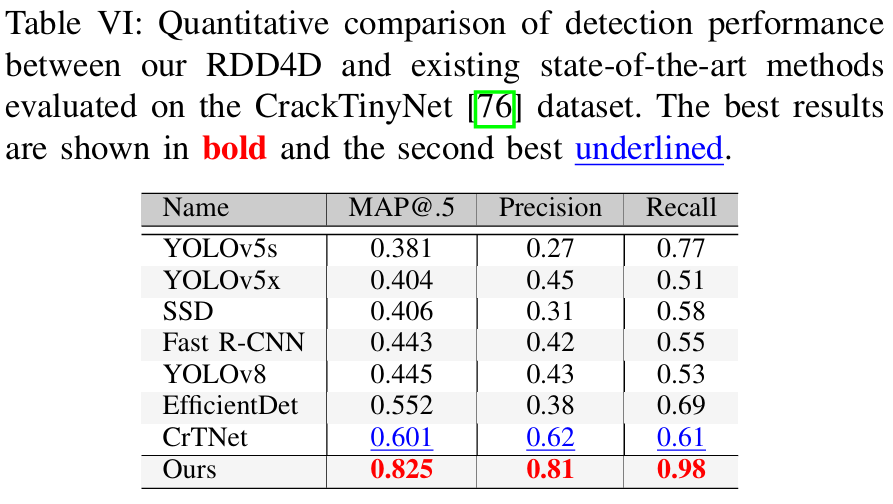
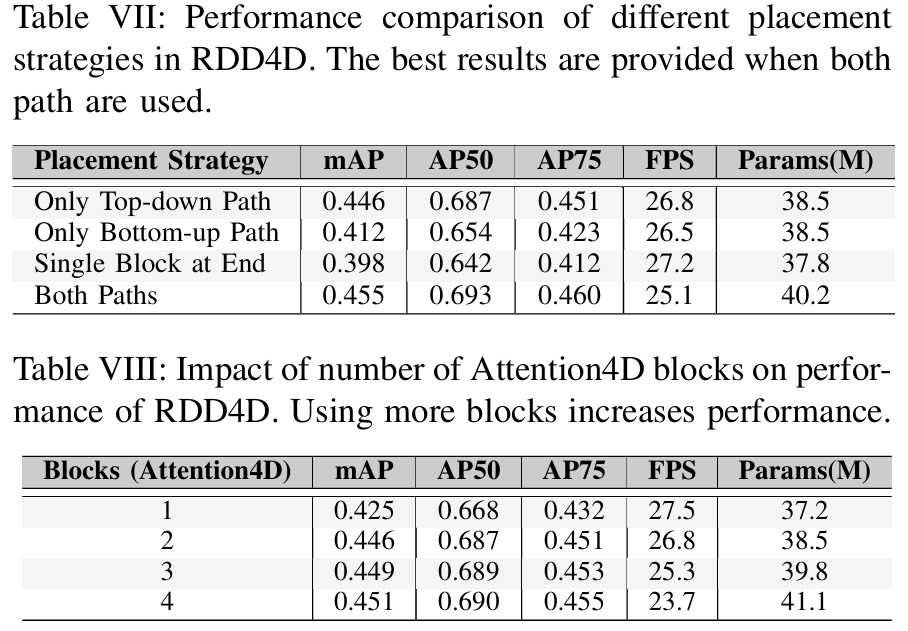
表VII所示的关于Attention4D块放置策略的消融研究表明,在自上而下路径中使用块能产生更优的性能(mAP=0.446\mathrm{mAP}=0.446mAP=0.446,AP50=0.687,AP75=0.451\mathrm{A P}50=0.687,\quad\mathrm{A P}75=0.451AP50=0.687,AP75=0.451),相比于自下而上路径(mAP=0.412\mathrm{mAP}=0.412mAP=0.412)或单个块放置(mAP=0.398\mathrm{mAP}=0.398mAP=0.398)。虽然在两个路径中都实施块能略微提高性能(mAP=0.455\mathrm{mAP}=0.455mAP=0.455),但这是以降低推理速度(25.1 FPS 对比 26.8 FPS)和增加参数数量(40.2M 对比 38.5M)为代价的。这表明,在自上而下路径中放置块在检测精度和计算效率之间提供了最佳平衡。表VIII对Attention4D块数量的进一步分析显示了一个清晰的性能趋势。虽然单个块显示出适度的结果(mAP=0.425\mathrm{mAP}=0.425mAP=0.425),但实施两个块能显著提高性能(mAP=0.446\mathrm{mAP}=0.446mAP=0.446),同时参数增加1.3M,这是合理的。尽管添加三个或四个块能略微提高准确率(分别为mAP=0.449\mathrm{mAP}=0.449mAP=0.449和0.451),但计算开销变得相当大,将FPS分别降低到25.3和23.7,同时将参数数量增加到39.8M和41.1M。这些结果验证了我们选择在自上而下路径中使用两个Attention4D块作为最优配置,提供了检测精度和计算效率之间的最佳折衷。
VII. 结论
在本文中,我们通过引入具有集成Attention4D机制的增强架构,解决了检测多种类型道路损伤这一具有挑战性的任务。我们收集了一个新的数据集,该数据集捕获了多样化的道路损伤类型,其中大多数图像包含不同的损伤类型,为这一领域的未来研究提供了宝贵的资源。我们已经证明,我们的方法在我们提出的数据集和CrackTinyNet数据集上都优于其他方法。我们的模型表现良好,因为4D注意力模块有效地处理了局部和全局上下文信息。这项工作为未来自动化道路损伤检测系统的发展奠定了坚实的基础,这对于高效的基础设施维护至关重要。
致谢
该研究项目由阿曼高等教育部、科学研究和创新部根据合同编号(BFP/RGP/ICT/21/406)资助。
核心代码:
python
import torch
import torch.nn as nn
import math
import itertools
from thop import profile # 用于FLOPs计算,可选
from torchsummary import summary # 用于模型结构摘要,可选
class Attention4D(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8, attn_ratio=4, resolution=7, act_layer=nn.ReLU, stride=None):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
if stride is not None:
self.resolution = math.ceil(resolution / stride)
self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim), )
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2
self.N2 = self.N
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d),
)
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d), )
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.proj = nn.Sequential(act_layer(),
nn.Conv2d(self.dh, dim, 1),
nn.BatchNorm2d(dim), )
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def count_parameters(self):
"""计算模块的总参数量"""
total_params = 0
trainable_params = 0
# 遍历所有参数
for name, param in self.named_parameters():
num_params = param.numel()
total_params += num_params
if param.requires_grad:
trainable_params += num_params
# 打印每个参数的详细信息
print(f" {name}: shape={list(param.shape)}, params={num_params:,}")
# 计算缓冲区(buffer)的参数量(通常不计入可训练参数)
buffer_params = 0
for name, buffer in self.named_buffers():
num_params = buffer.numel()
buffer_params += num_params
print(f" Buffer {name}: shape={list(buffer.shape)}, params={num_params:,}")
print(f"\n总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
print(f"缓冲区参数量: {buffer_params:,}")
print(f"总参数量(含缓冲区): {total_params + buffer_params:,}")
return total_params, trainable_params, buffer_params
def get_parameter_details(self):
"""获取详细的参数信息"""
param_details = {}
# 卷积层参数
conv_layers = ['q', 'k', 'v', 'v_local', 'talking_head1', 'talking_head2', 'proj']
for layer_name in conv_layers:
if hasattr(self, layer_name):
layer = getattr(self, layer_name)
if isinstance(layer, nn.Sequential):
for i, sub_layer in enumerate(layer):
if isinstance(sub_layer, (nn.Conv2d, nn.BatchNorm2d)):
param_details[f"{layer_name}.{i}"] = {
'type': type(sub_layer).__name__,
'params': sum(p.numel() for p in sub_layer.parameters())
}
elif isinstance(layer, (nn.Conv2d, nn.BatchNorm2d)):
param_details[layer_name] = {
'type': type(layer).__name__,
'params': sum(p.numel() for p in layer.parameters())
}
# 注意力偏置参数
param_details['attention_biases'] = {
'type': 'Parameter',
'params': self.attention_biases.numel()
}
return param_details
def forward(self, x): # x (B,N,C)
B, C, H, W = x.shape
if self.stride_conv is not None:
x = self.stride_conv(x)
q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
attn = (
(q @ k) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = self.talking_head1(attn)
attn = attn.softmax(dim=-1)
attn = self.talking_head2(attn)
x = (attn @ v)
out = x.transpose(2, 3).reshape(B, self.dh, self.resolution, self.resolution) + v_local
if self.upsample is not None:
out = self.upsample(out)
out = self.proj(out)
return out
# ==================== 调用示例 ====================
if __name__ == "__main__":
# 设置随机种子确保结果可重现
torch.manual_seed(42)
print("=" * 80)
print("Attention4D 模块调用示例")
print("=" * 80)
# ==================== 示例1: 基本使用 ====================
print("\n" + "-" * 60)
print("示例1: 基本使用 (标准配置)")
print("-" * 60)
# 创建模型实例
model_basic = Attention4D(
dim=384,
key_dim=32,
num_heads=8,
attn_ratio=4,
resolution=20,
act_layer=nn.ReLU,
stride=None
)
# 创建输入张量 [batch_size, channels, height, width]
input_tensor = torch.randn(2, 384, 20, 20)
print(f"输入张量形状: {input_tensor.shape}")
# 前向传播
output = model_basic(input_tensor)
print(f"输出张量形状: {output.shape}")
# 计算参数量
print("\n参数量统计 (基本配置):")
total_params, trainable_params, buffer_params = model_basic.count_parameters()
# ==================== 示例2: 带stride的使用 ====================
print("\n" + "-" * 60)
print("示例2: 带stride的使用 (下采样)")
print("-" * 60)
# 创建带stride的模型实例
model_stride = Attention4D(
dim=384,
key_dim=32,
num_heads=8,
attn_ratio=4,
resolution=14, # 原始分辨率
act_layer=nn.ReLU,
stride=2 # stride=2,会下采样
)
# 创建输入张量 [batch_size, channels, height, width]
input_tensor_stride = torch.randn(2, 384, 14, 14)
print(f"输入张量形状: {input_tensor_stride.shape}")
# 前向传播
output_stride = model_stride(input_tensor_stride)
print(f"输出张量形状: {output_stride.shape}")
# 计算参数量
print("\n参数量统计 (带stride配置):")
total_params_stride, _, _ = model_stride.count_parameters()
# ==================== 示例3: 不同配置的使用 ====================
print("\n" + "-" * 60)
print("示例3: 不同配置的使用 (轻量级版本)")
print("-" * 60)
# 创建轻量级配置的模型
model_light = Attention4D(
dim=192, # 更小的通道数
key_dim=16, # 更小的key维度
num_heads=4, # 更少的头数
attn_ratio=2, # 更小的attn_ratio
resolution=7,
act_layer=nn.GELU, # 使用GELU激活函数
stride=None
)
input_tensor_light = torch.randn(4, 192, 7, 7)
print(f"输入张量形状: {input_tensor_light.shape}")
output_light = model_light(input_tensor_light)
print(f"输出张量形状: {output_light.shape}")
print("\n参数量统计 (轻量级配置):")
total_params_light, _, _ = model_light.count_parameters()
# ==================== 示例4: 详细参数分析 ====================
print("\n" + "-" * 60)
print("示例4: 详细参数分析")
print("-" * 60)
param_details = model_basic.get_parameter_details()
print("各组件参数量详情:")
for name, details in param_details.items():
print(f" {name}: {details['type']}, 参数量: {details['params']:,}")
# 计算总FLOPs(可选,需要安装thop)
try:
from thop import profile
# 计算FLOPs
flops, params = profile(model_basic, inputs=(input_tensor,))
print(f"\n计算复杂度分析:")
print(f" FLOPs: {flops / 1e9:.2f} G")
print(f" 参数量: {params / 1e6:.2f} M")
except ImportError:
print("\n提示: 安装thop库可以进行FLOPs计算: pip install thop")
# ==================== 示例5: 梯度检查 ====================
print("\n" + "-" * 60)
print("示例5: 梯度检查")
print("-" * 60)
# 确保模型在训练模式
model_basic.train()
# 前向传播
output = model_basic(input_tensor)
# 创建目标(随机)
target = torch.randn_like(output)
# 计算损失
loss = torch.nn.MSELoss()(output, target)
print(f"损失值: {loss.item():.4f}")
# 反向传播
loss.backward()
# 检查梯度
print("梯度检查 (部分参数):")
grad_stats = {}
for name, param in model_basic.named_parameters():
if param.grad is not None:
grad_norm = param.grad.norm().item()
grad_stats[name] = grad_norm
if len(grad_stats) < 5: # 只显示前5个
print(f" {name} 梯度范数: {grad_norm:.6f}")
# ==================== 性能测试 ====================
print("\n" + "-" * 60)
print("性能测试 (推理速度)")
print("-" * 60)
import time
# 切换到评估模式
model_basic.eval()
# 预热
with torch.no_grad():
for _ in range(10):
_ = model_basic(input_tensor)
# 测试推理时间
num_iterations = 100
start_time = time.time()
with torch.no_grad():
for _ in range(num_iterations):
_ = model_basic(input_tensor)
end_time = time.time()
avg_time = (end_time - start_time) / num_iterations
print(f"平均推理时间: {avg_time * 1000:.2f} ms")
print(f"吞吐量: {1 / avg_time:.2f} 样本/秒 (batch_size=2)")
print("\n" + "=" * 80)
print("Attention4D 模块演示完成!")
print("=" * 80)