一、引言
在数据驱动决策的时代,数据分析与可视化已成为企业运营、业务优化的核心需求,但传统数据分析流程往往受限于 "编程门槛高、工具切换繁琐、可视化效率低" 等问题。华为 ModelEngine Nexent低代码平台推出的单智能体数据分析解决方案,以 "一体化数据处理 + 工具自动调用 + 可视化智能生成" 为核心,无需复杂编程,即可实现从数据接入到图表输出的全流程自动化。本文将从技术逻辑、实践操作、核心优势等维度,深度评测该数据分析智能体的实际表现。
官网地址:https://modelengine-ai.net/#/home
二、部署ModelEngine Nexent
2.1 部署ModelEngine Nexent
ModelEngine Nexent是开源项目,整个项目的源码都开源到了Github仓库里面,所以我们部署ModelEngine Nexent有两种方式,一种是将源码克隆下来,把所有前后端环境都在自己电脑上配置一下,然后把每个服务都启动,然后访问前端页面来进行ModelEngine Nexent的开发体验,不过这种部署方法比较适合那些想在ModelEngine Nexent平台的基础上继续开发新功能的深度用户。而身为体验用户,我特别推荐大家选择ModelEngine Nexent的Docker一键部署的方式,这种方式不需要大家进行繁琐的环境配置,只需要安装一个docker,然后傻瓜式一键部署即可,在这里作者也选择的是docker部署。
Github 仓库地址:https://github.com/ModelEngine-Group/nexent

在windows系统中,进入PowerShell以后,先输入wsl进入到ubuntu系统里面,前提是我们需要安装个ubuntu系统在windows下,可以上网参考公开教程进行安装,这里由于作者很早前就安装过docker和ubuntu,所以这里就不再详细讲述。
这里用docker的deploy.sh脚本进行部署ModelEngine Nexent的时候,由于Windows 系统的换行符是 CRLF(\r\n),而 WSL(Linux 环境)只识别 LF(\n) 换行符,不转换的话,文件里多余的 \r 字符会被 WSL 当成无效内容,导致脚本执行报错(如 $'\r': command not found)、配置文件解析异常,所以必须把这些文件的换行符从 CRLF 转为 LF,才能在 WSL 中正常使用。
所以启动deploy.sh脚本前,需要先进行下转换,具体操作步骤如下:
python
sudo apt update && sudo apt install -y dos2unix
git clone https://github.com/ModelEngine-Group/nexent.git
cd nexent/docker
cp .env.example .env # 复制环境变量配置文件
dos2unix *.sh .env .env.*
bash deploy.sh安装完成如下图所示:
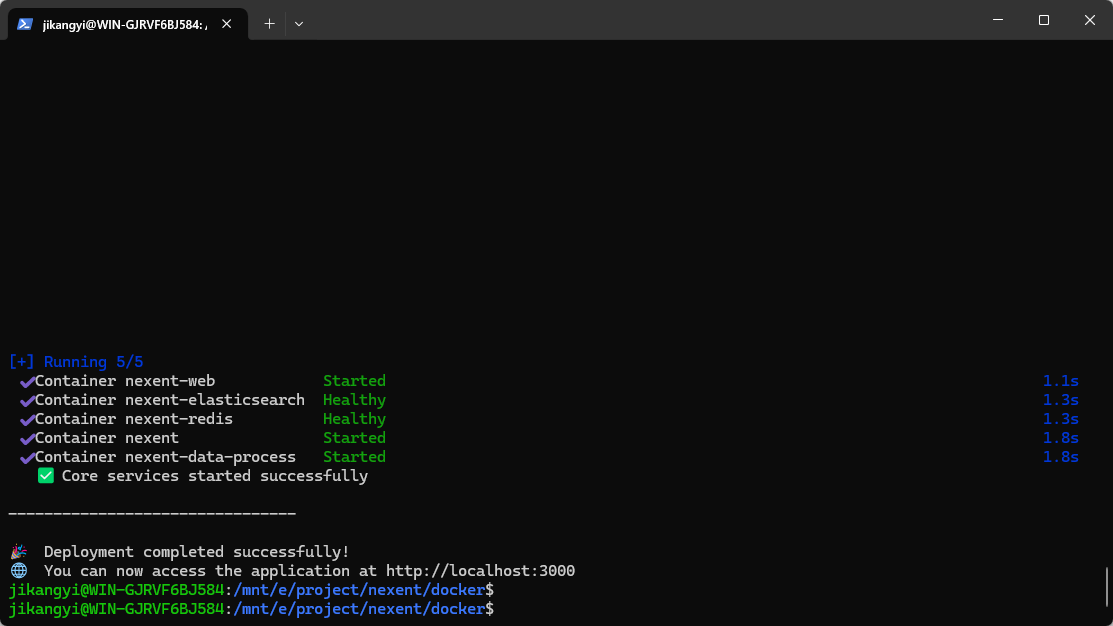
访问http://localhost:3000/zh即可看到如下界面:

2.2 配置模型
首先我们需要先配置下模型,这里我们需要配置的有大语言模型、向量模型和视觉语言模型,配置起来也非常简单,这里我推荐使用阿里的千问系列模型,可以访问阿里百炼大模型平台,直接创建API的秘钥,不过要注意的是,我们如果之前没有用过这款平台的话需要领取下免费额度,这样我们就可以拥有所有模型的免费调用额度。
具体配置如下图所示:
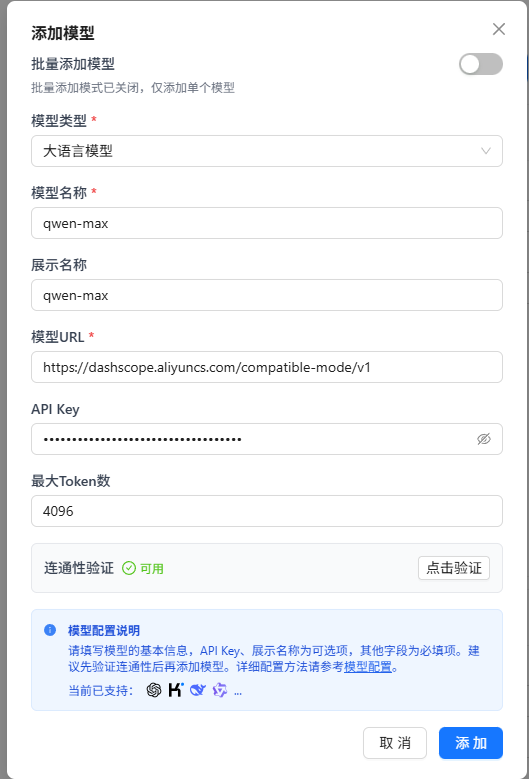
视觉语言模型也是同理,不过这里需要用qwen-vl-plus,这是qwen系列的多模态大模型,可以理解图片。
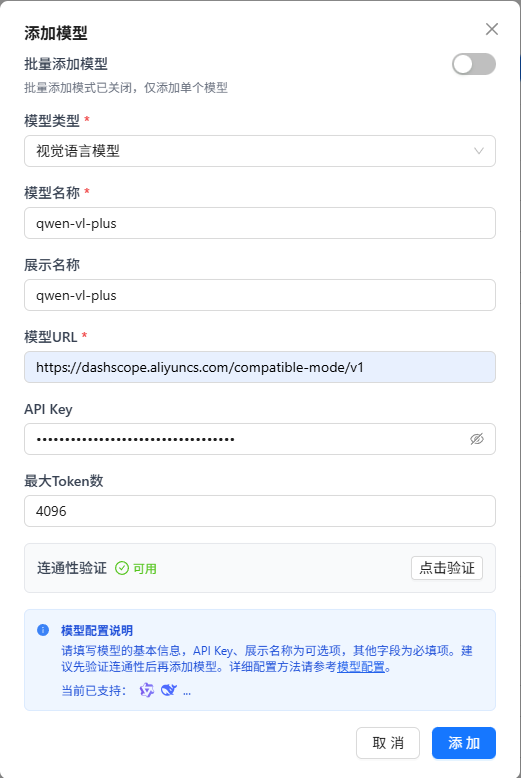
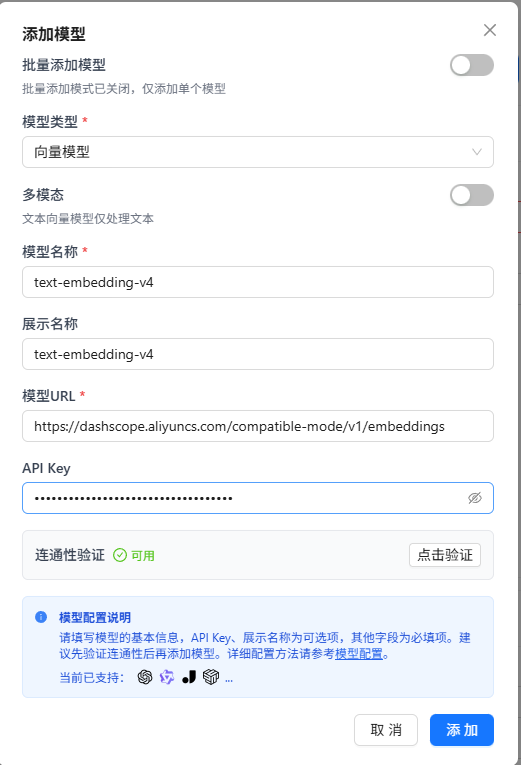
向量模型配置的模型URL需要在原先大语言模型和视觉语言模型的基础上添加/embeddings才能够联通,这是需要我们注意的一个点。
添加完成模型配置以后,我们需要在左侧对我们自己的智能体定义一下名称以及功能描述,这里我们想做的是一款数据分析智能体,所以我对其命名为"数智洞察官",听起来一个比较fashion的名字,然后功能描述定义为:
"数智洞察官" 是基于华为 ModelEngine Nexent低代码平台打造的零代码数据分析智能体,专注于为各行业用户提供 "数据接入 - 分析建模 - 可视化生成 - 结论输出" 的全流程自动化服务。它支持多源数据(本地文件、数据库、API 接口等)一键接入,通过自然语言指令即可完成复杂数据分析任务(如趋势分析、占比统计、关联挖掘等),并自动匹配最优可视化图表(折线图、柱状图、热力图等),输出可直接复用的结构化分析报告。无论你是缺乏编程基础的业务人员,还是需要快速获取数据洞察的管理者,"数智洞察官" 都能帮你打破技术门槛,以分钟级效率将原始数据转化为决策依据,真正实现 "人人都是数据分析师"。
具体配置如下图所示:
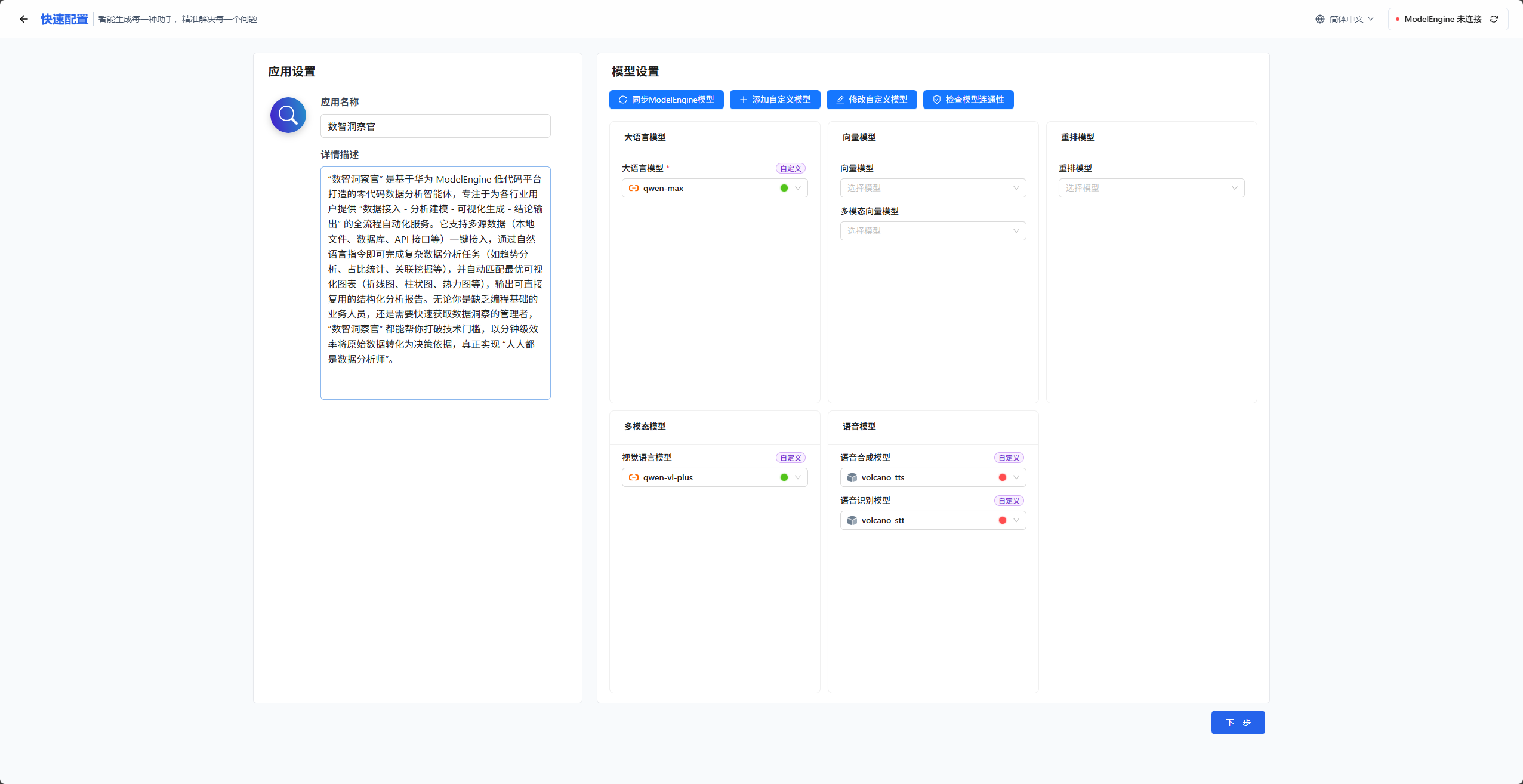
然后一切准备就绪以后,我们点击下一步,接着会跳转到知识库配置页面。
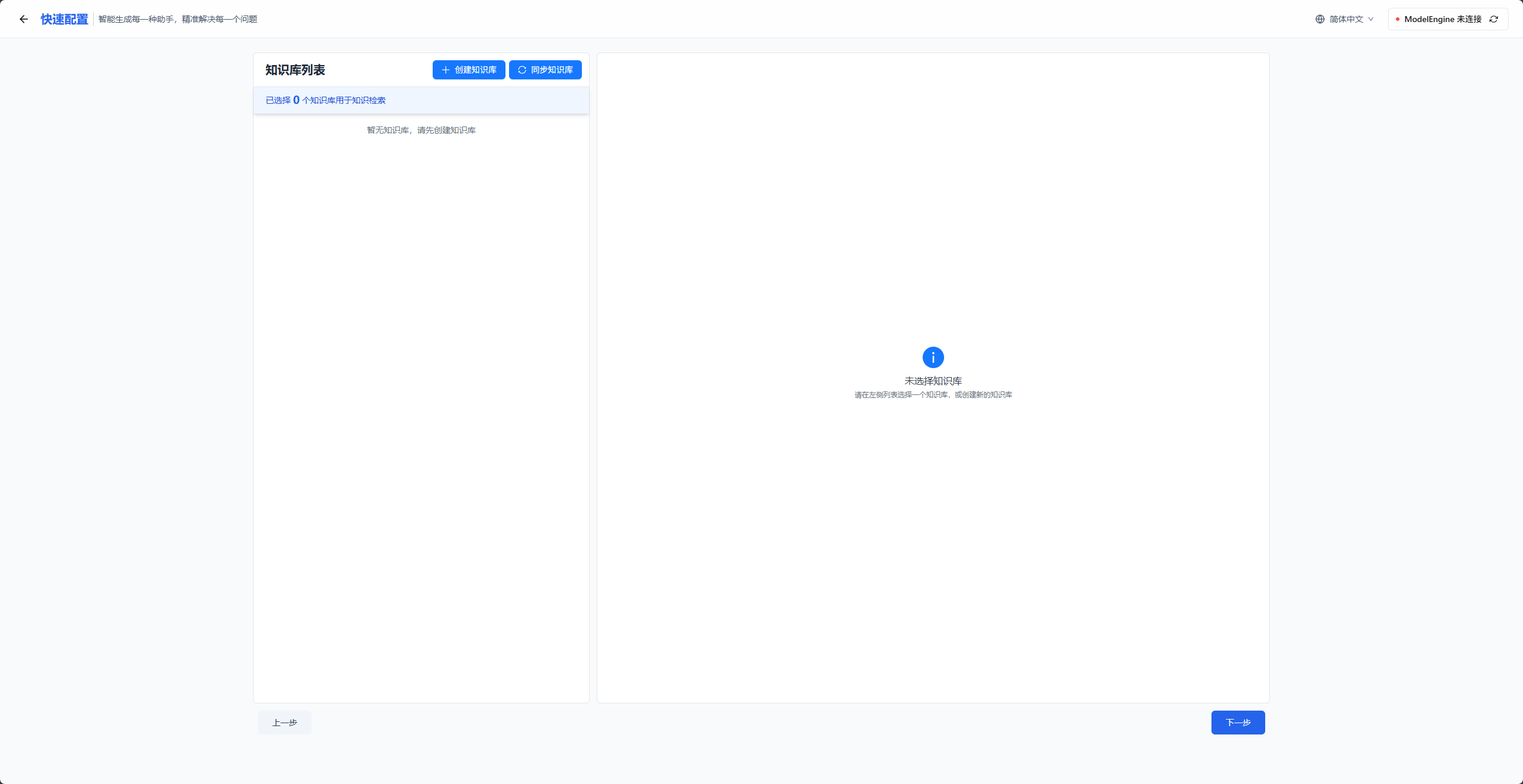
这里客观的讲,我们这一款智能体只需要配置数据分析工具和MCP服务即可实现我们的目的,不过也可以上传一些知识库,比如大家经常做数据分析的小伙伴,一定有自己的一套数据分析脚本代码,这一套代码已经非常成熟了,这时候我们就可以把我们保存的代码文档当做知识库提供给ModelEngine Nexent,那么当你需要分析以为经常分析的数据时,智能体就能够依据你知识库里面的代码文件进行数据分析,这往往会生成你想要的数据分析报告,符合你需求标准的数据分析可视化。
这里我们重点测试ModelEngine Nexent的可视化工具调用能力以及MCP服务调用能力,所以知识库我没有提前准备,就不为其添加知识库配置了,大家自己感兴趣了可以尝试。
2.3 配置工具和MCP
点击下一步,然后可以看到我们创建智能体的页面到了,这个页面是ModelEngine Nexent的主要配置页面,这里能够同步我们之前创建的智能体,以及创建新的智能体,还可以添加工具和MCP服务。
接下来,我们需要配置下工具和MCP,这里由于我们是一个数据分析智能体,而且我们的服务是部署在本地的,所以可以为智能体配置本地文件操作的工具,比如读取文件、读取文件列表,创建文件等功能。如下图所示,把本地工具的file里面的蓝色部分勾选上行即可。
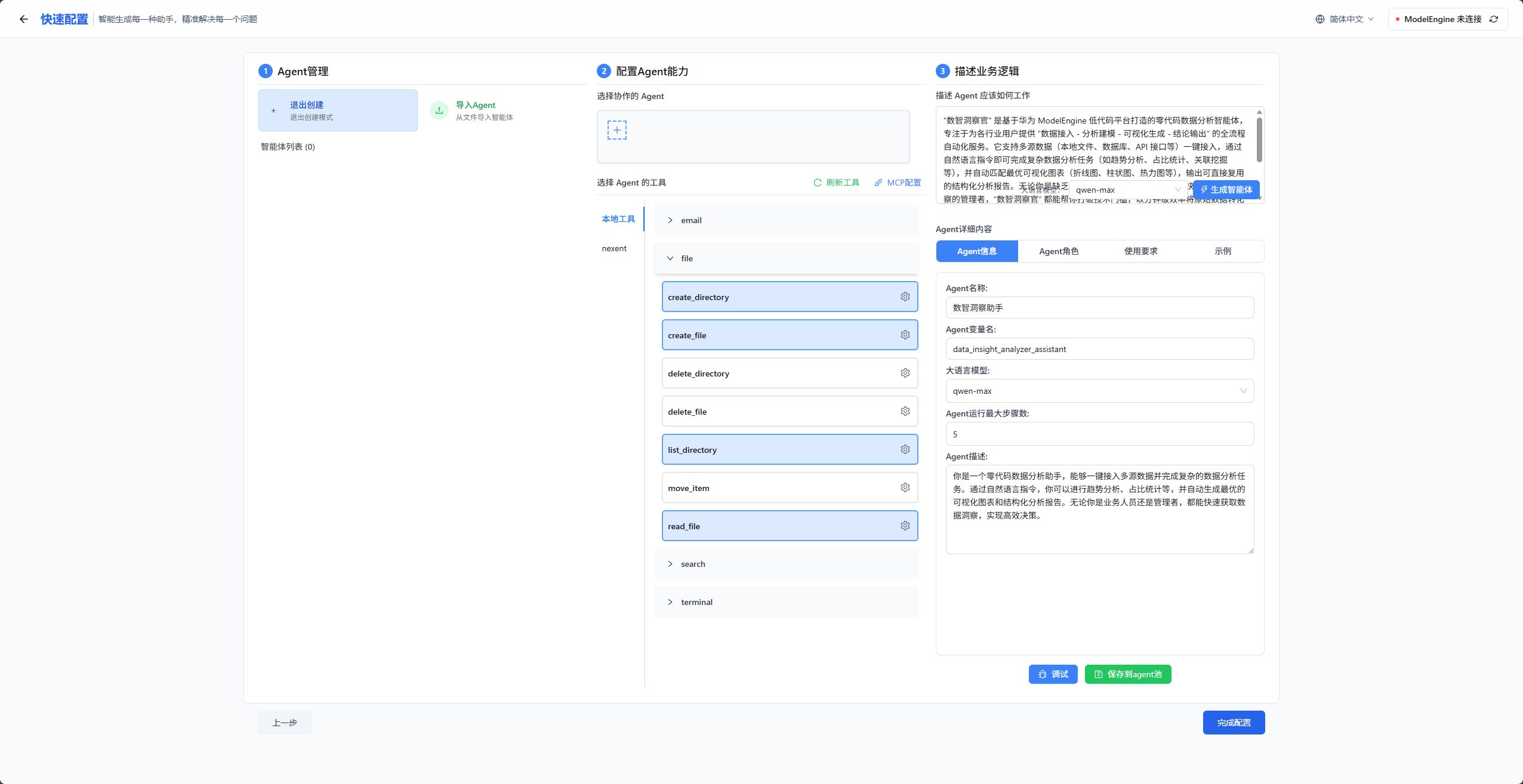
然后,我们也可能上网搜索数据信息,所以这里也可以访问:https://exa.ai/浏览器官网,用谷歌账号登录后拿到它的apikey:
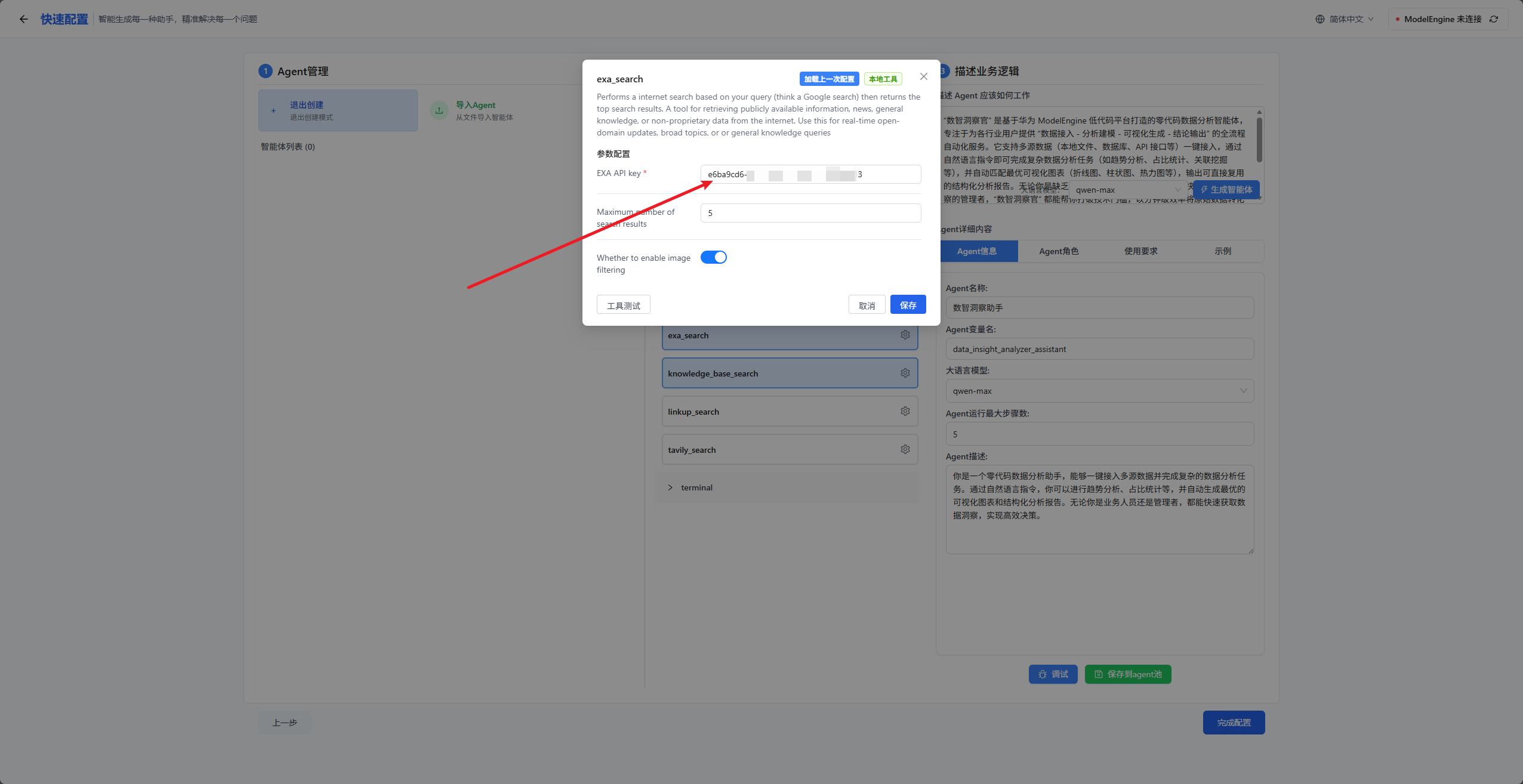
然后打开search里面的exa search,将apikey填入进去,然后保存。该工具可以帮我们通过关键字搜索网上的数据。该工具是一个强大的搜索引擎集成工具,其设计旨在通过高效的检索机制提升应用程序的功能,刚好符合我们的需求。具体操作如下图所示:
配置完以后,我们还可以前往魔搭社区的MCP广场,找一款好用的可视化MCP服务。
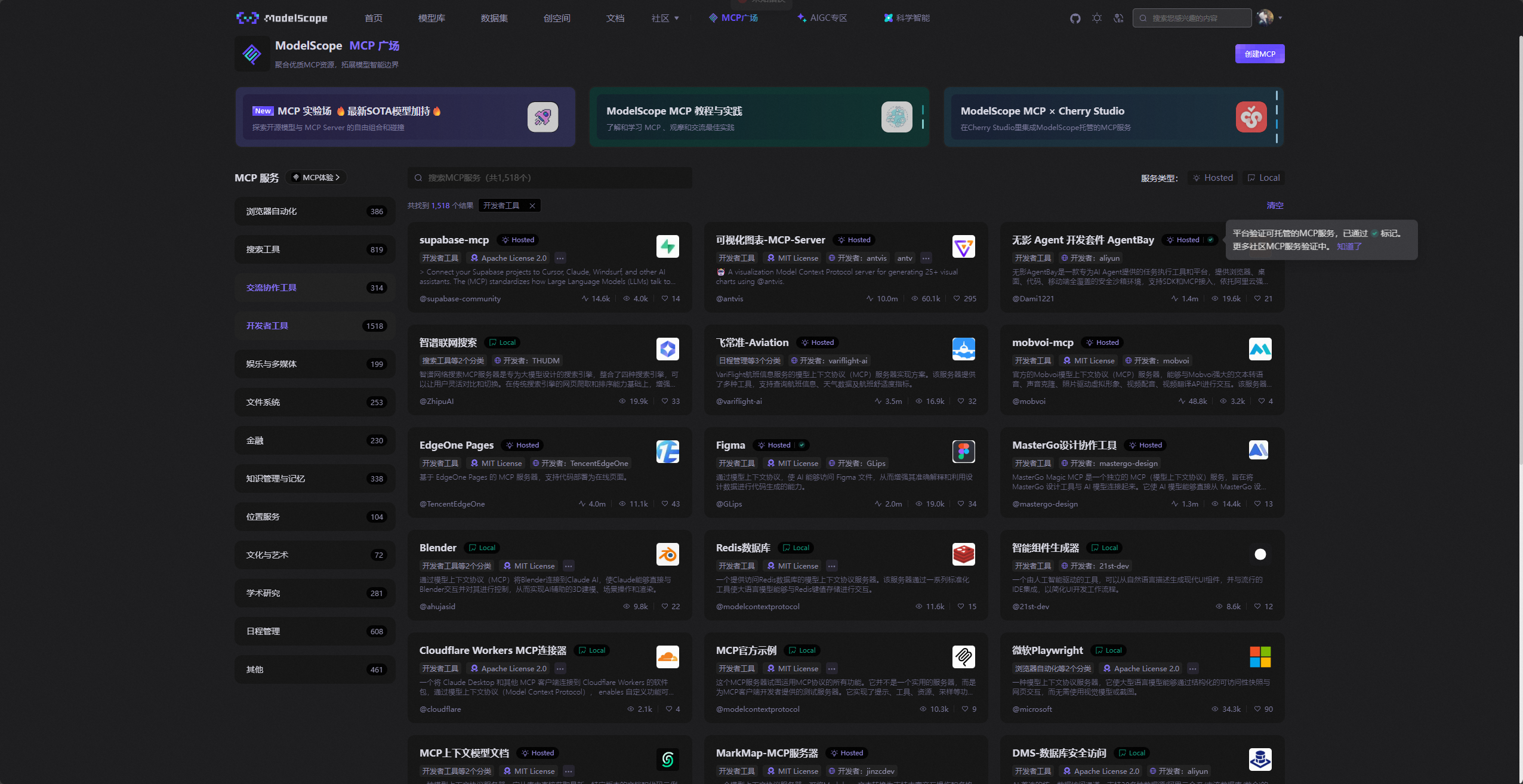
可以直接在上面搜索栏搜索可视化三个关键字,它就会自动检索我们需要的MCP服务。可以看到这里有6个可视化相关的MCP服务,这里我们可以先大概浏览一下,然后选择一款最适合我们的MCP服务。由于我们是要对图表进行数据分析并可视化,所以第一个MCP服务最合适。
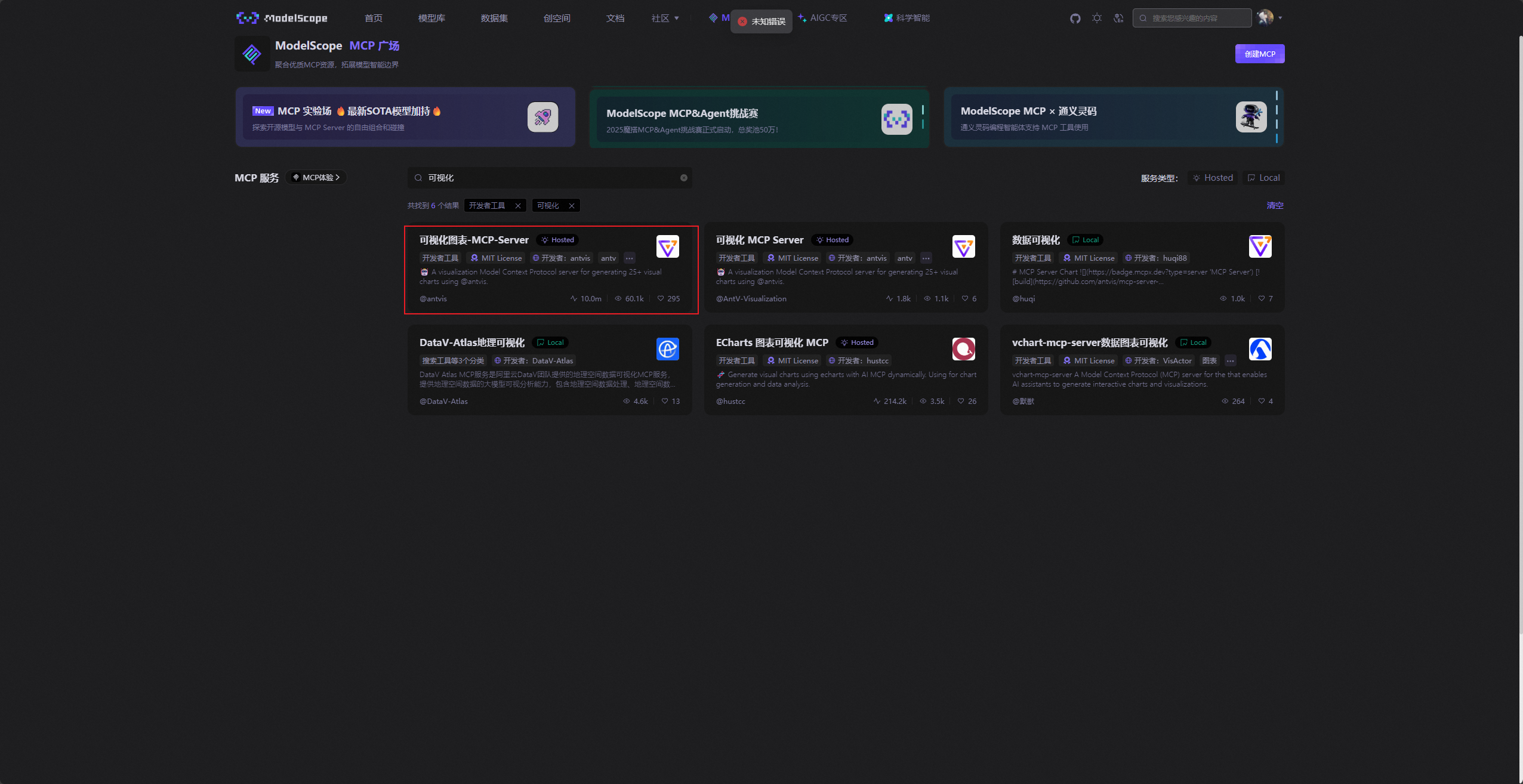
进入后,点击右臂的SSE配置生成按钮。
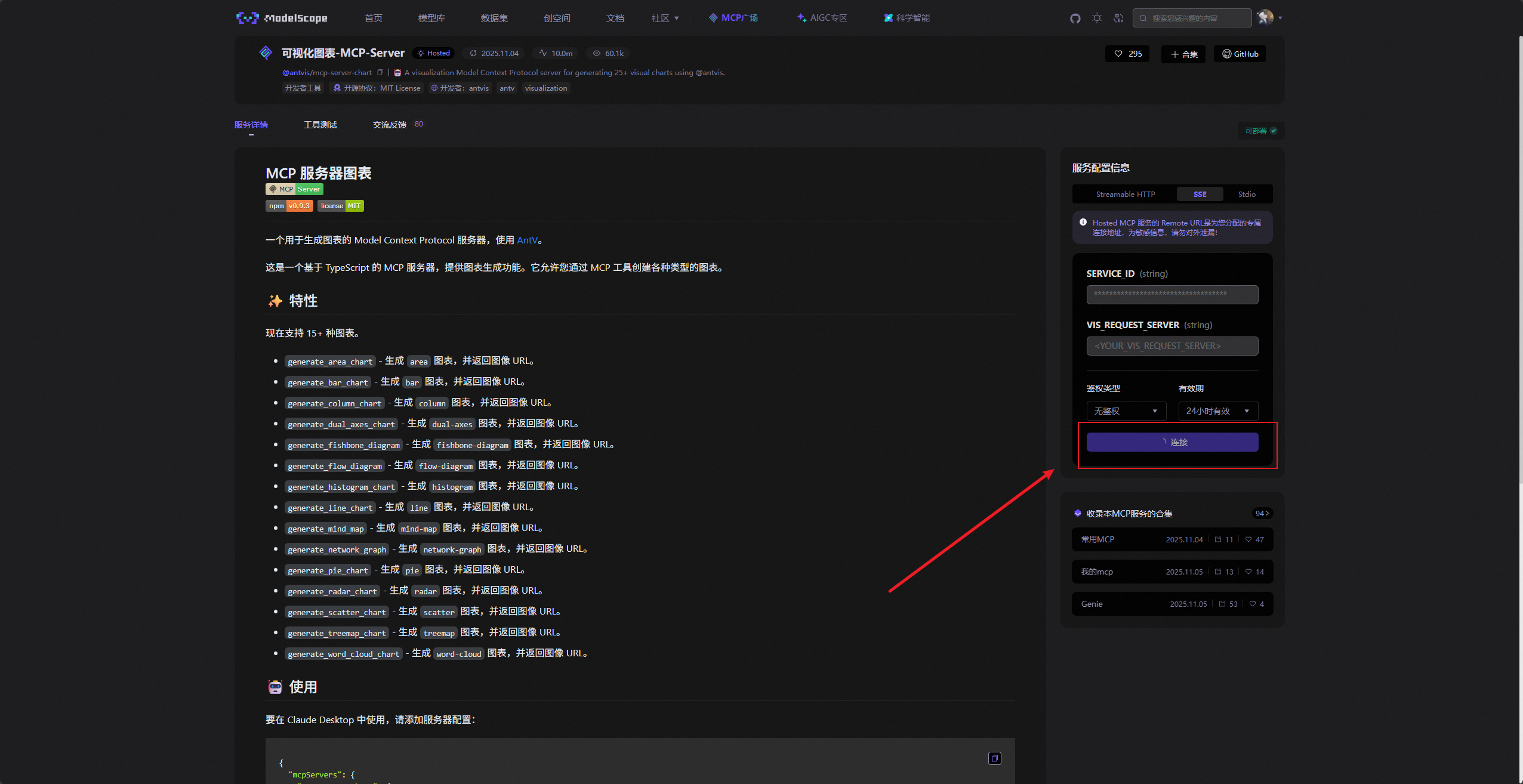
然后可以看到魔搭社区会给我们生成一个SSE配置,里面有SSE的URL地址,由于ModelEngine Nexent只支持SSE协议的MCP服务,所以我们把里面URL复制下就行。
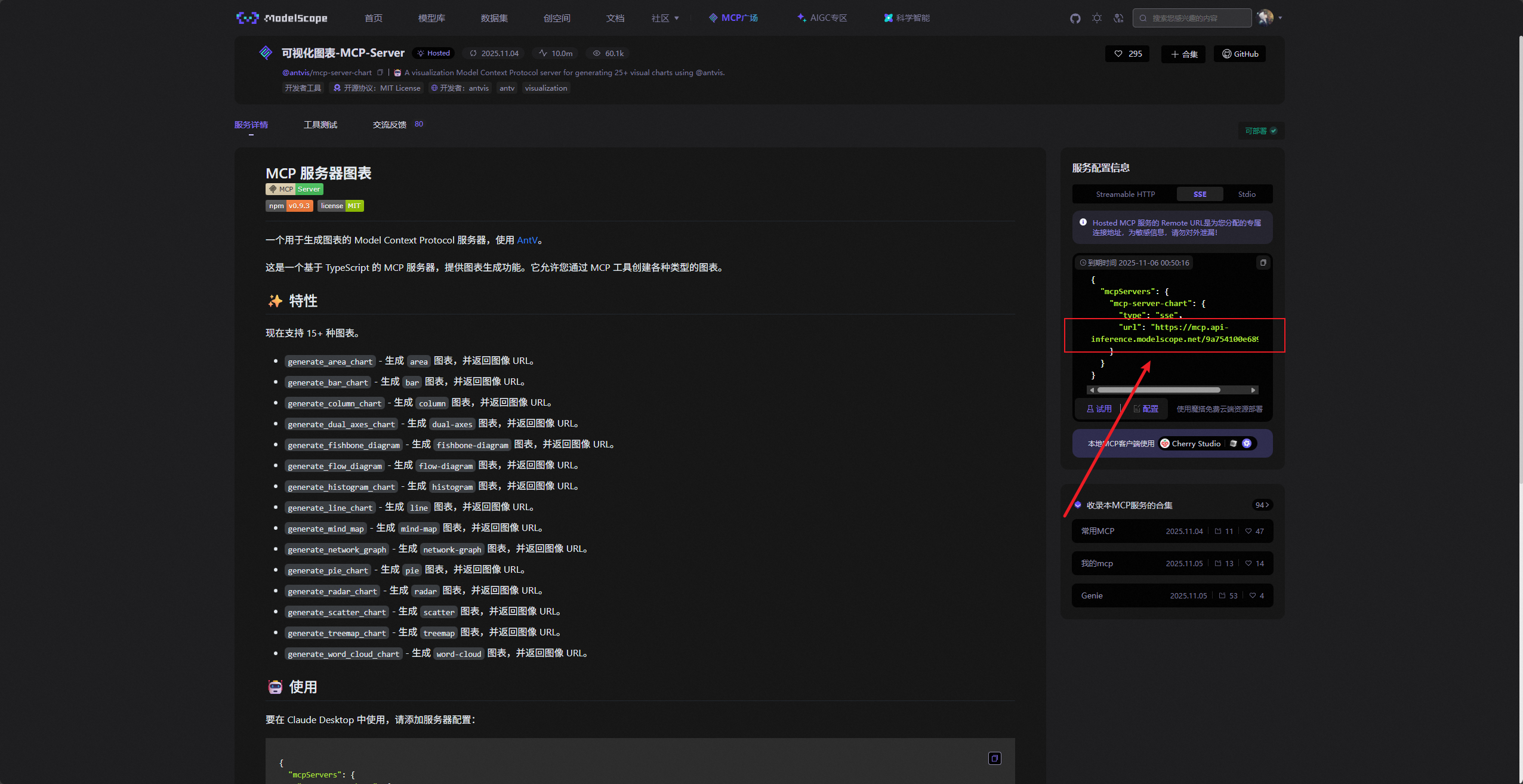
复制了MCP的SSE协议URL以后,我们回到ModelEngine Nexent,打开MCP配置,将URL粘贴进去,然后再给MCP服务起一个名字即可,如下图所示:
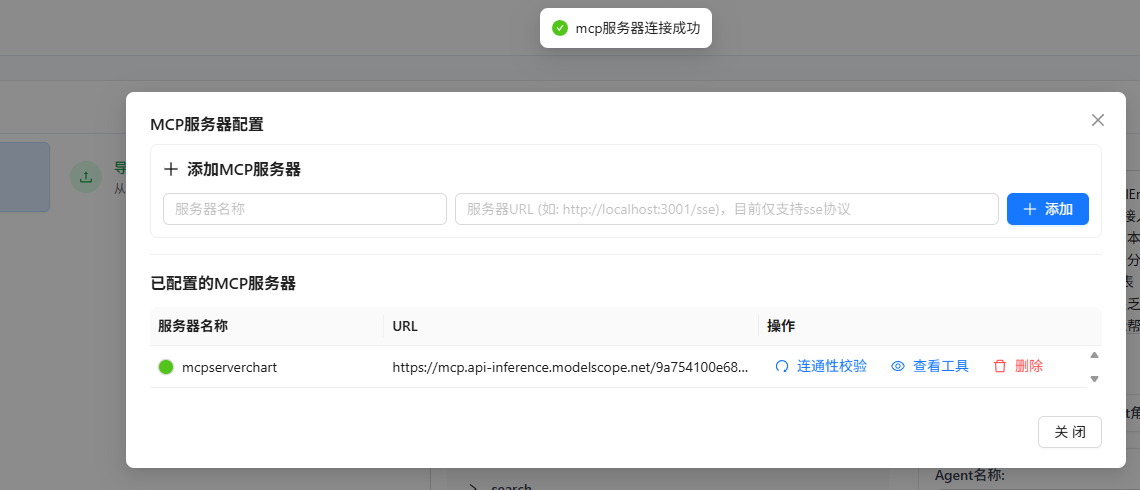
这时候还不算完,我们真正想要MCP服务生效,还得将它的所有功能勾选上,具体操作如下图:
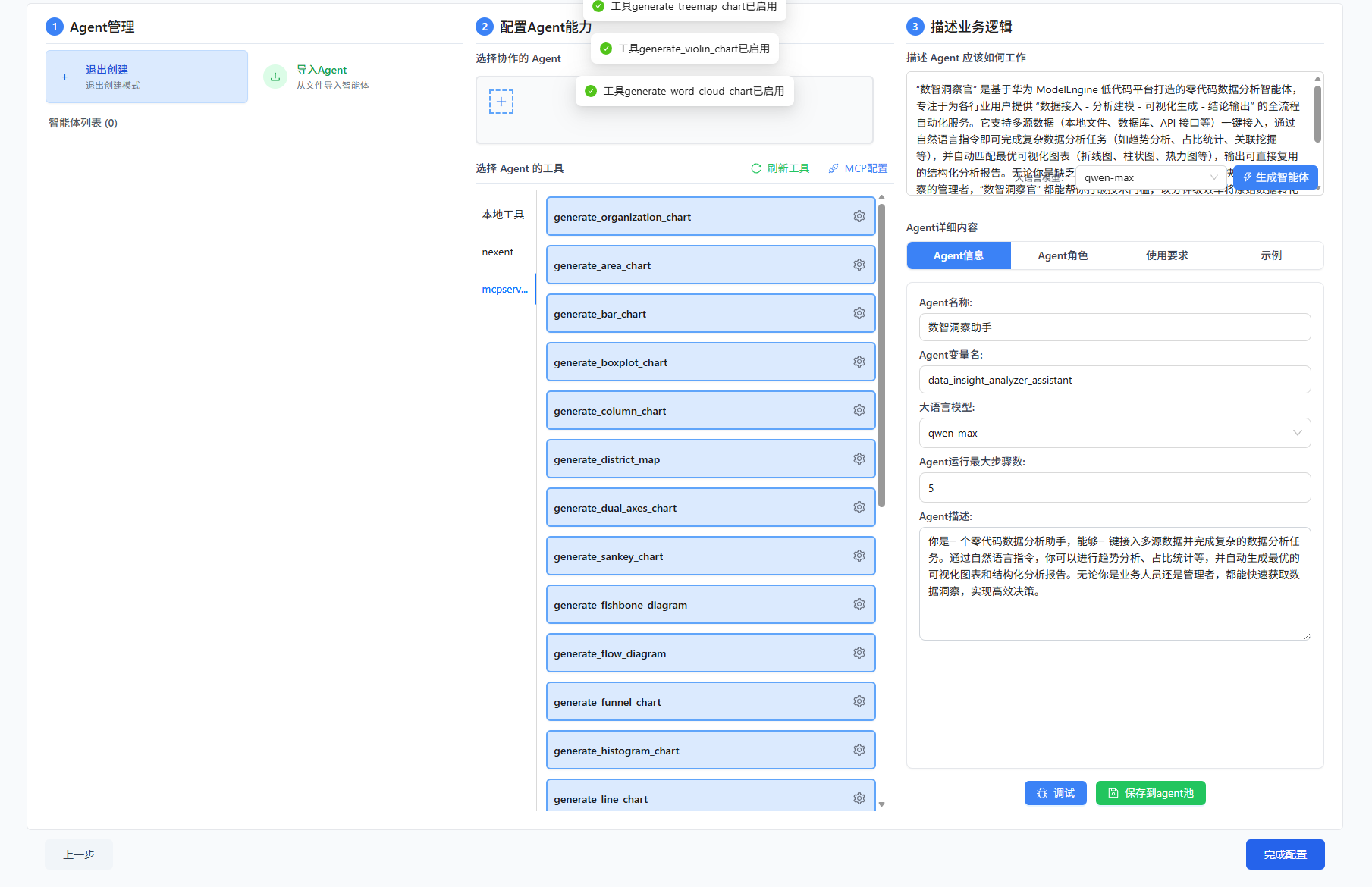
不过这里我是默认要使用所有功能的,如果大家只是需要该MCP帮你生成柱状图、饼状图等特定图谱,那么只需要开启对应的功能即可,这样会避免开启功能过多而影响agent响应准确率。
2.4 一键生成prompt
工具配置好了以后,我们就可以来为我们的智能体一键生成prompt,为其进行角色设定。
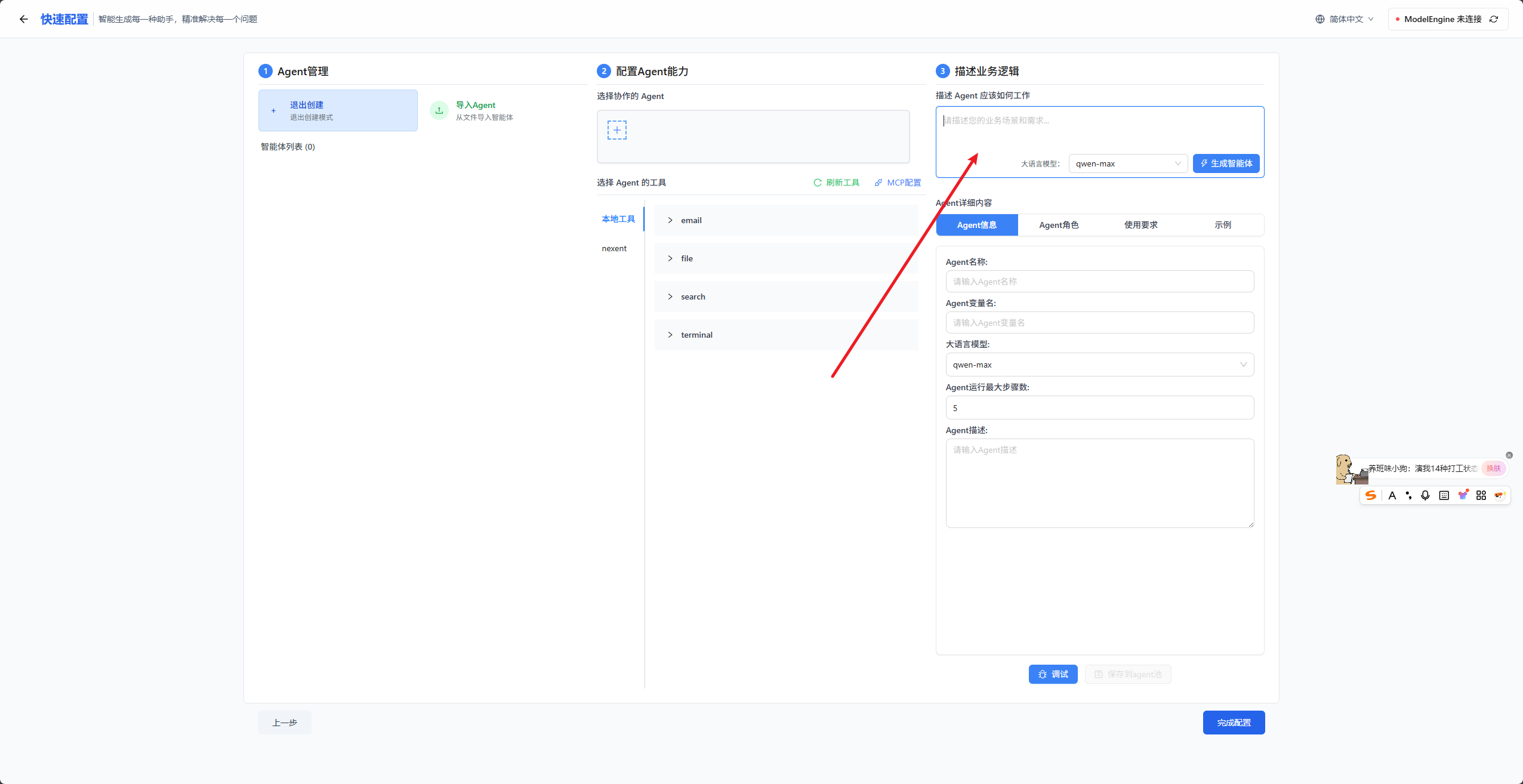
这里我们只需要把自己之前给智能体的描述输入进去,然后就可以一键生成prompt。这里不得不赞美这个功能,以往做智能体开发,最让我头痛的就是写prompt了,对于理科生来讲,就是应该把写prompt的任务交给最擅长该任务的大语言模型来。
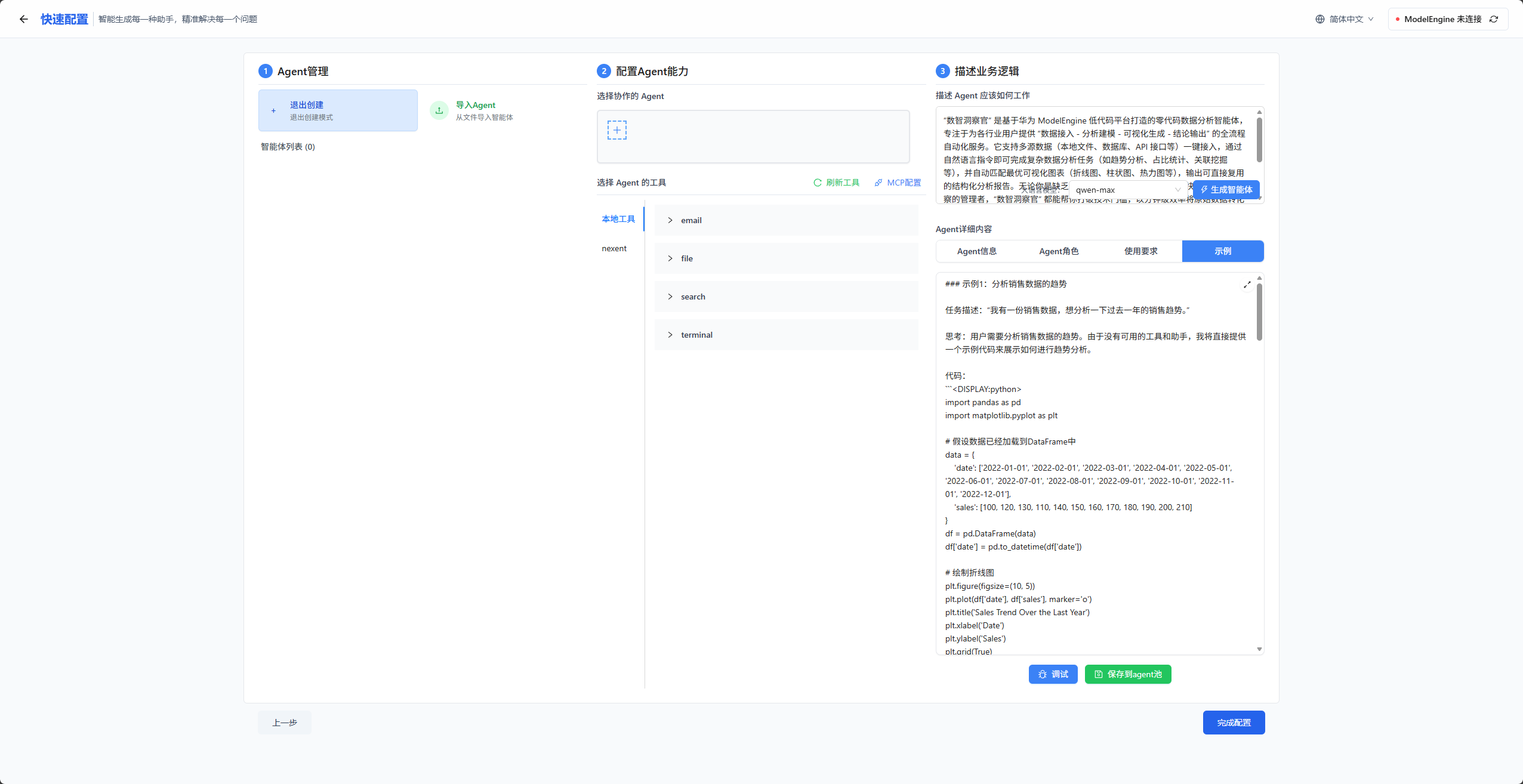
可以看到,它生成的prompt生成的质量也很高,而且还会有示例给大模型,我们能够看到它生成的示例也十分详细,里面还有代码。
2.5 调试智能体
我们配置好本地工具和MCP服务并通过连通性校验以后,就可以进行智能体的调试了,ModelEngine Nexent提供了智能体调试窗口,可以在保存智能体配置之前,通过调试我们的智能体来判断是否满足我们的需求和目标,如果不满意,我们也可以随时进行配置的更改,直到达到我们的预期以后,我们再保存智能体配置。
刚好我这里有一个北京市空气质量分析的数据表:
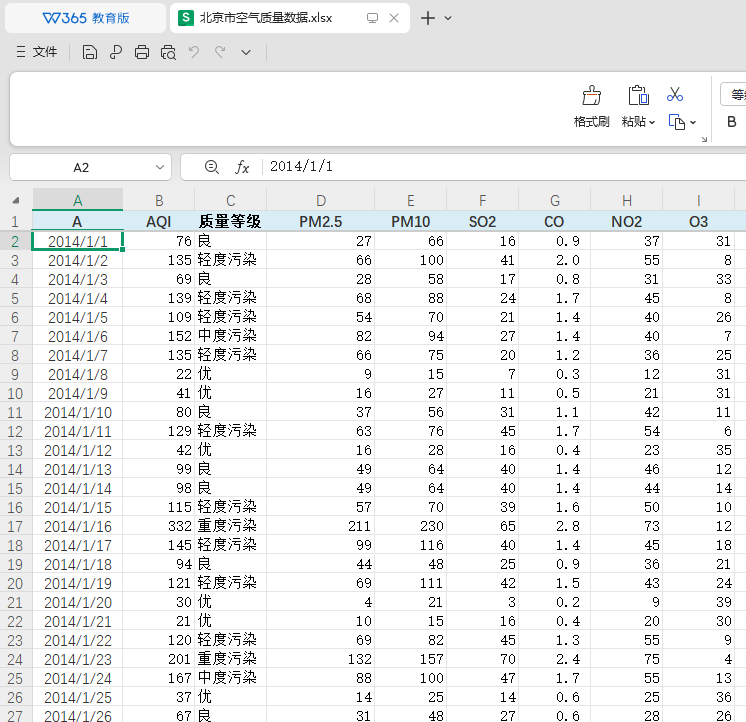
我们直接给他本机的文件地址,看它是否能调用文件操作工具读取该文件,并调用MCP服务进行可视化分析。
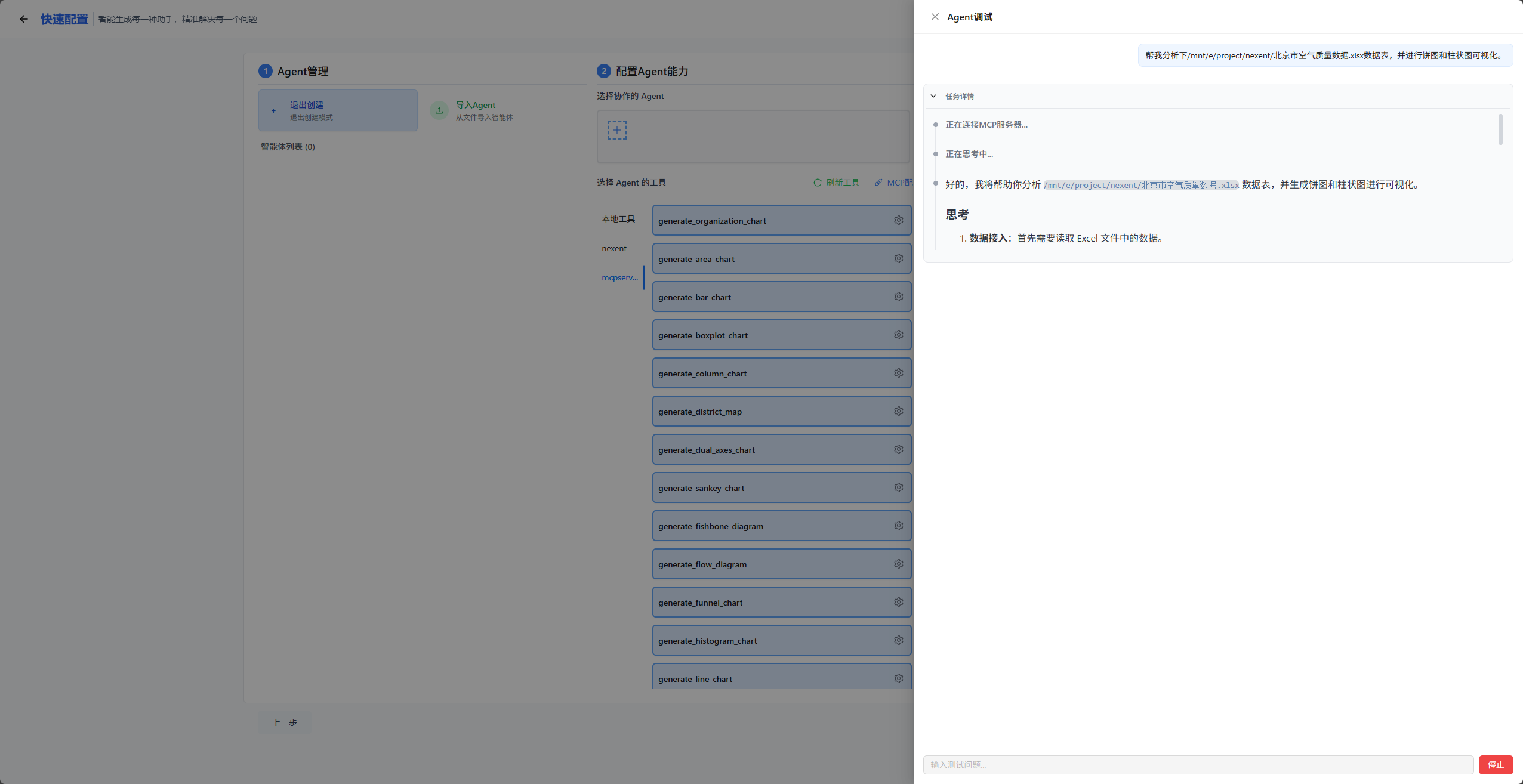
可以看到,我给它了本地文件的路径,然后又让他帮我进行饼图和柱状图的可视化,它会直接调用MCP服务,然后生成代码进行文件读取,以及可视化操作。
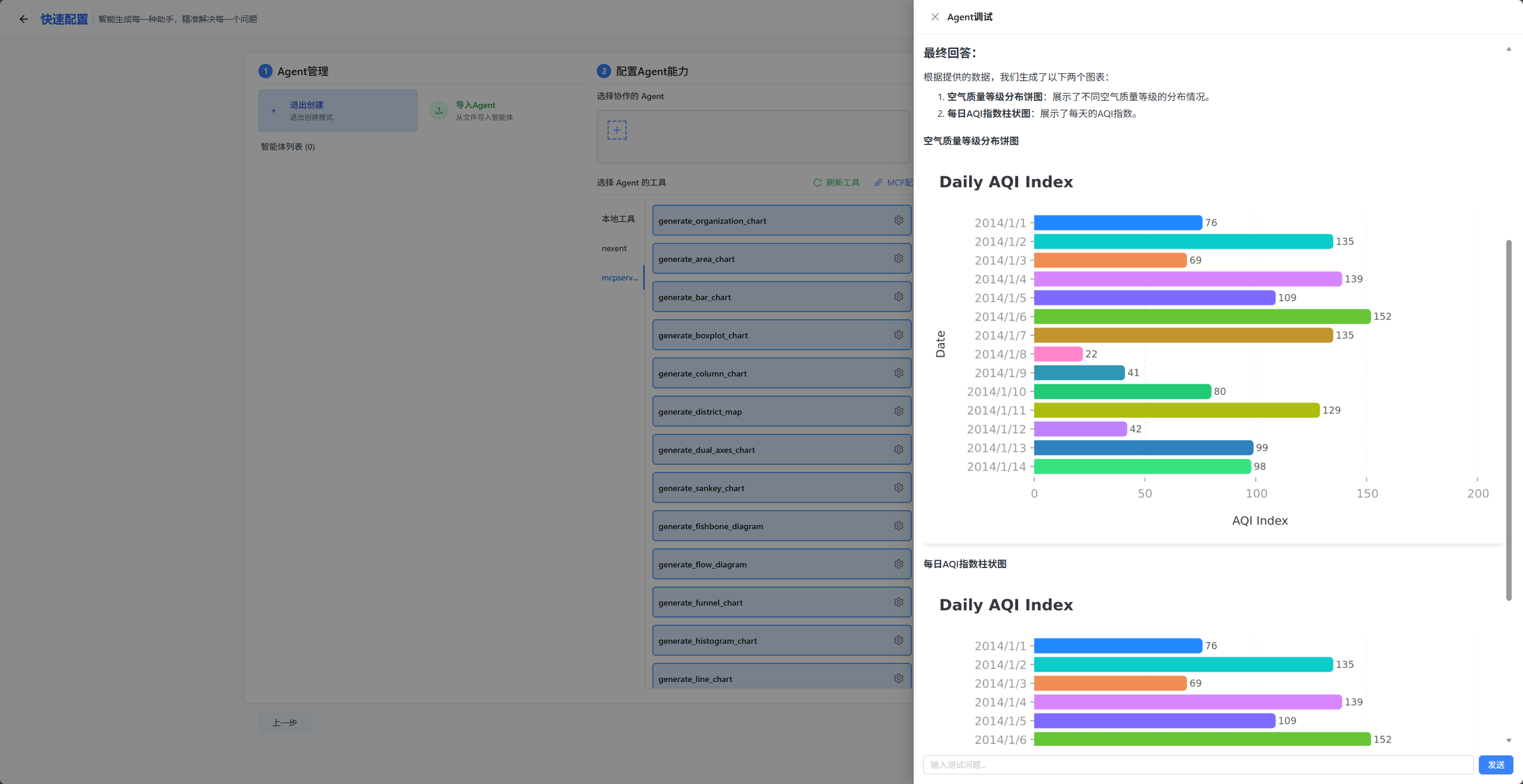
可以看到它真的给我们生成了图表,不过好像第一个饼图生成错了,全部给生成了柱状图,这时候我们让它继续输出饼状图。
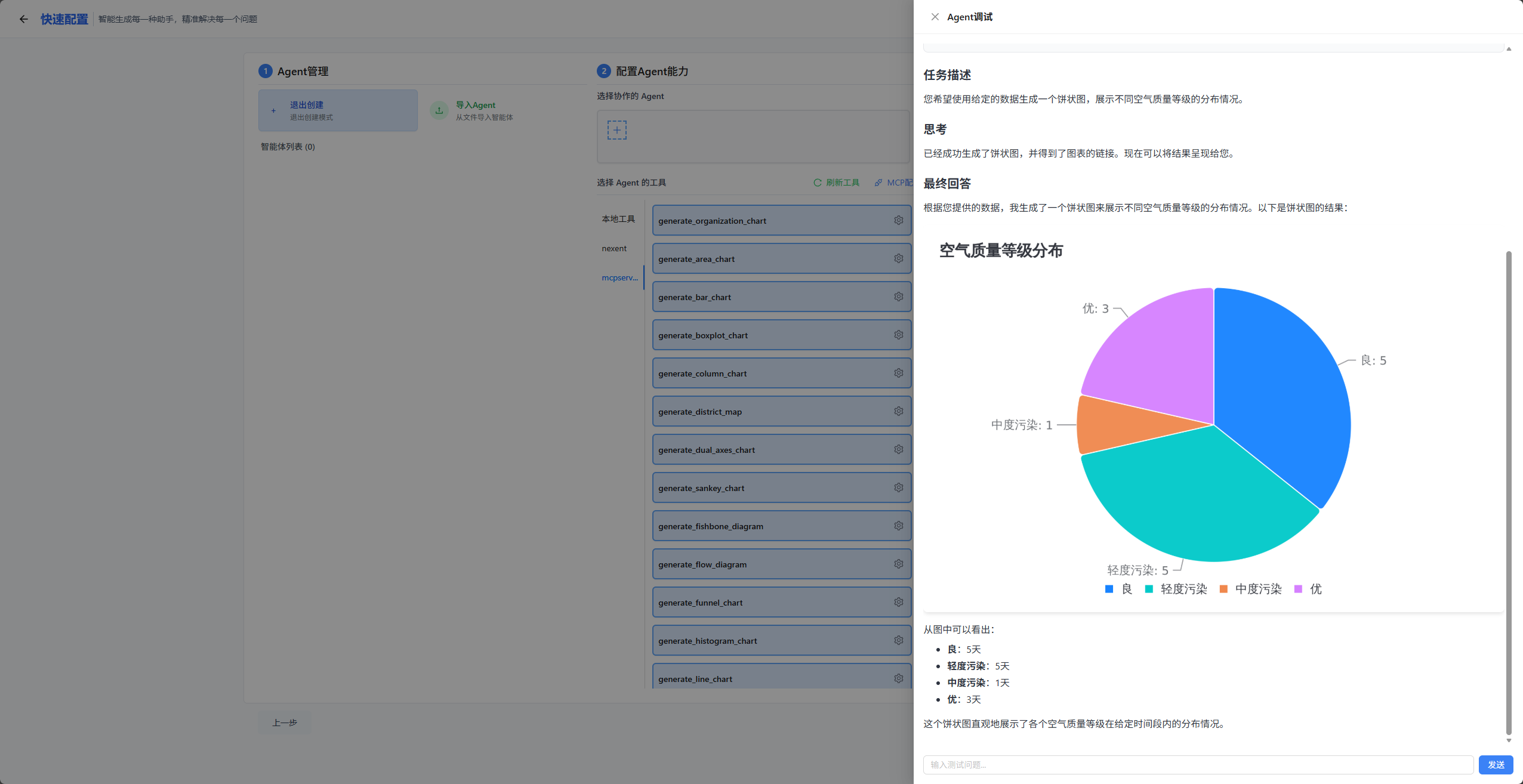
可以看到确实生成了饼状图,这时候我们就可以把智能体配置进行保存了。
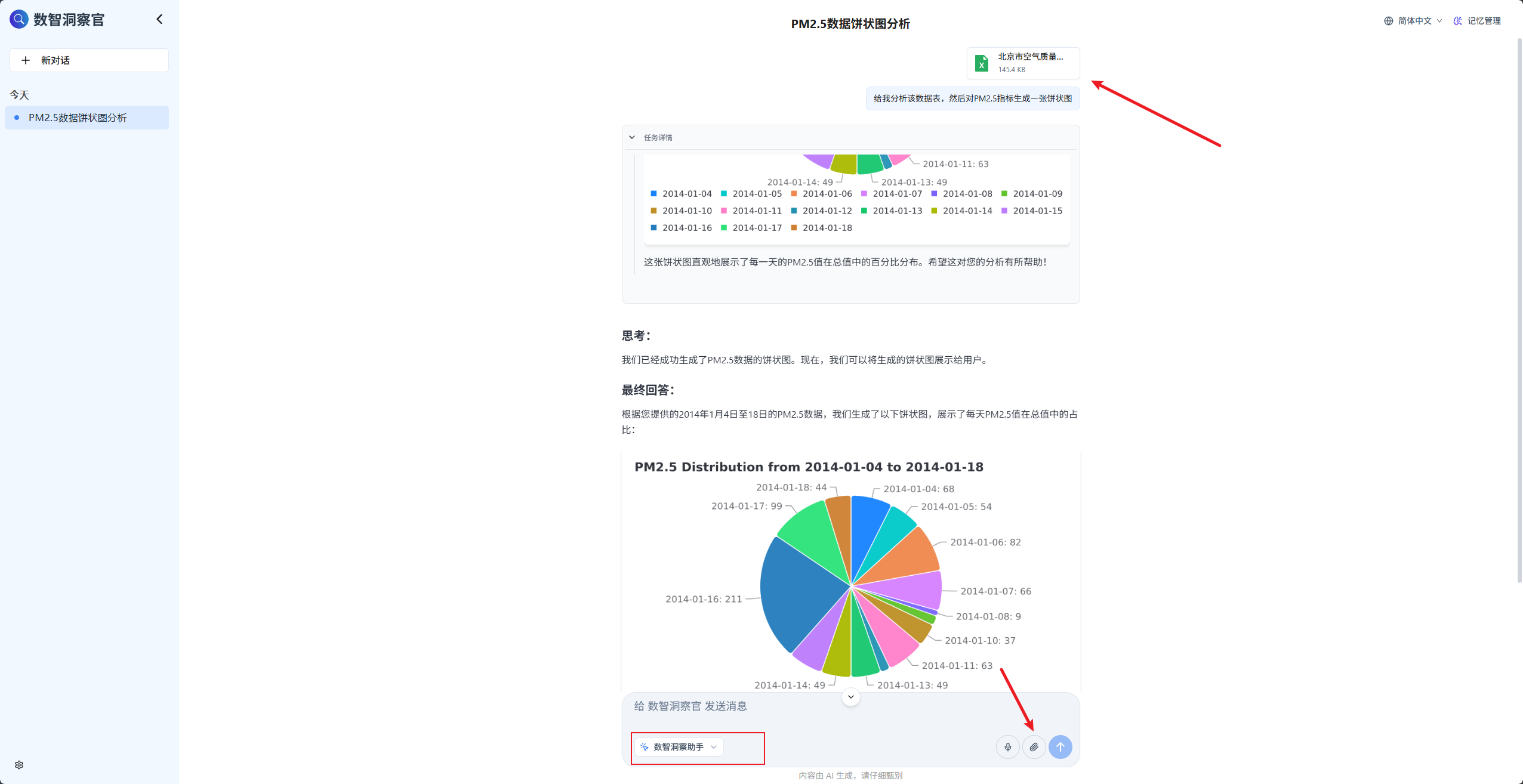
我们保存完智能体配置后,进入到正式使用界面,就会发现其跟我们平时用的GPT官网很像,但是我们可以聊天框的左下角选择我们配置的智能体,然后也可以提交本地文件,让其进行可视化,效果还是蛮不错的,而且比调试的时候更好用。
三、 核心优势:对比传统数据分析,效率与门槛的双重革新
相较于 "Excel 手动计算 + Python 编程分析 + PowerBI 画图" 的传统模式,ModelEngine Nexent数据分析智能体的优势尤为突出:
| 对比维度 | 传统数据分析流程 | ModelEngine Nexent数据分析智能体 |
|---|---|---|
| 技术门槛 | 需掌握 Excel 函数、SQL/Python 编程、BI 工具操作 | 零代码,自然语言输入需求即可,非技术人员也能上手 |
| 操作效率 | 数据清洗→分析→画图需多工具切换,耗时 1-2 小时 | 全流程自动化,单任务平均耗时≤3 分钟,效率提升 20 倍 + |
| 可视化适配性 | 需手动选择图表类型、调整样式,易出现 "图表与数据不匹配" | 智能匹配最优图表,自动优化样式,无需人工调整 |
| 数据兼容性 | 多源数据需手动整合,格式转换繁琐 | 自动兼容多格式数据,数据库 / 文件 / API 数据一键接入 |
| 结果复用性 | 分析逻辑需重新编写,图表难以二次修改 | 支持保存分析模板,后续同类数据可直接复用,图表支持实时更新 |
四、 行业场景落地:让数据分析走进业务一线
该数据分析智能体凭借 "低门槛、高效率、强适配" 的特性,可在多行业实现深度落地:
- 零售行业:门店运营人员无需编程,上传每日销售数据后,输入 "分析 Top5 热销商品、各门店销售排名",1 分钟内获取可视化图表,快速调整补货策略;
- 互联网行业:运营人员通过接入用户行为数据,输入 "分析近 7 日用户活跃趋势、核心功能使用频次",智能体自动生成趋势图与漏斗图,辅助活动效果评估;
- 金融行业:风控人员接入信贷数据,输入 "分析不同客群逾期率、贷款金额分布",智能体生成热力图与直方图,助力风险模型优化;
- 政务领域:基层工作人员上传民生数据(如社保参保人数、公共服务使用率),输入 "分析年度数据同比变化、区域分布差异",快速生成政务报告所需图表。
五、 总结:单智能体重构数据分析生产力
华为 ModelEngine Nexent低代码平台的数据分析智能体,以 "单智能体一体化闭环" 打破了传统数据分析的技术壁垒。其核心价值在于:将 "数据处理 - 分析建模 - 可视化生成" 的复杂流程封装为 "自然语言输入→结果输出" 的极简操作,让非技术人员也能快速掌握数据分析能力,真正实现 "人人都是数据分析师"。
相较于多智能体的复杂协作,该单智能体更聚焦 "轻量化、高频次" 的数据分析需求,以 "低门槛、高效率、强实用" 为核心优势,完美适配企业一线业务场景。在数据驱动决策成为刚需的今天,ModelEngine Nexent的数据分析智能体不仅降低了数据分析的应用门槛,更让数据洞察能够快速转化为业务行动,成为企业提升运营效率的核心工具。