关键词:数据湖 / 流批一体 / MLOps / 自动驾驶数据闭环 / Occupancy / VLA / 世界模型 / 小模型本地推理 / 可靠性
2025 年我最强烈的感受,不是模型又变大了多少,而是交付形态变了:单一模型 Demo 不稀缺,稀缺的是可持续迭代的闭环系统------数据进来、模型更新、评估回归、收益再回推到数据生产端。
这一年我写作与实践的主线始终只有一句话:**把"算法能力"变成"系统能力",把"模型效果"变成"闭环产能"。**所以你会看到我的内容同时覆盖大数据、模型部署/可靠性、自动驾驶与具身智能:它们不是分散赛道,而是同一条链路的不同层。
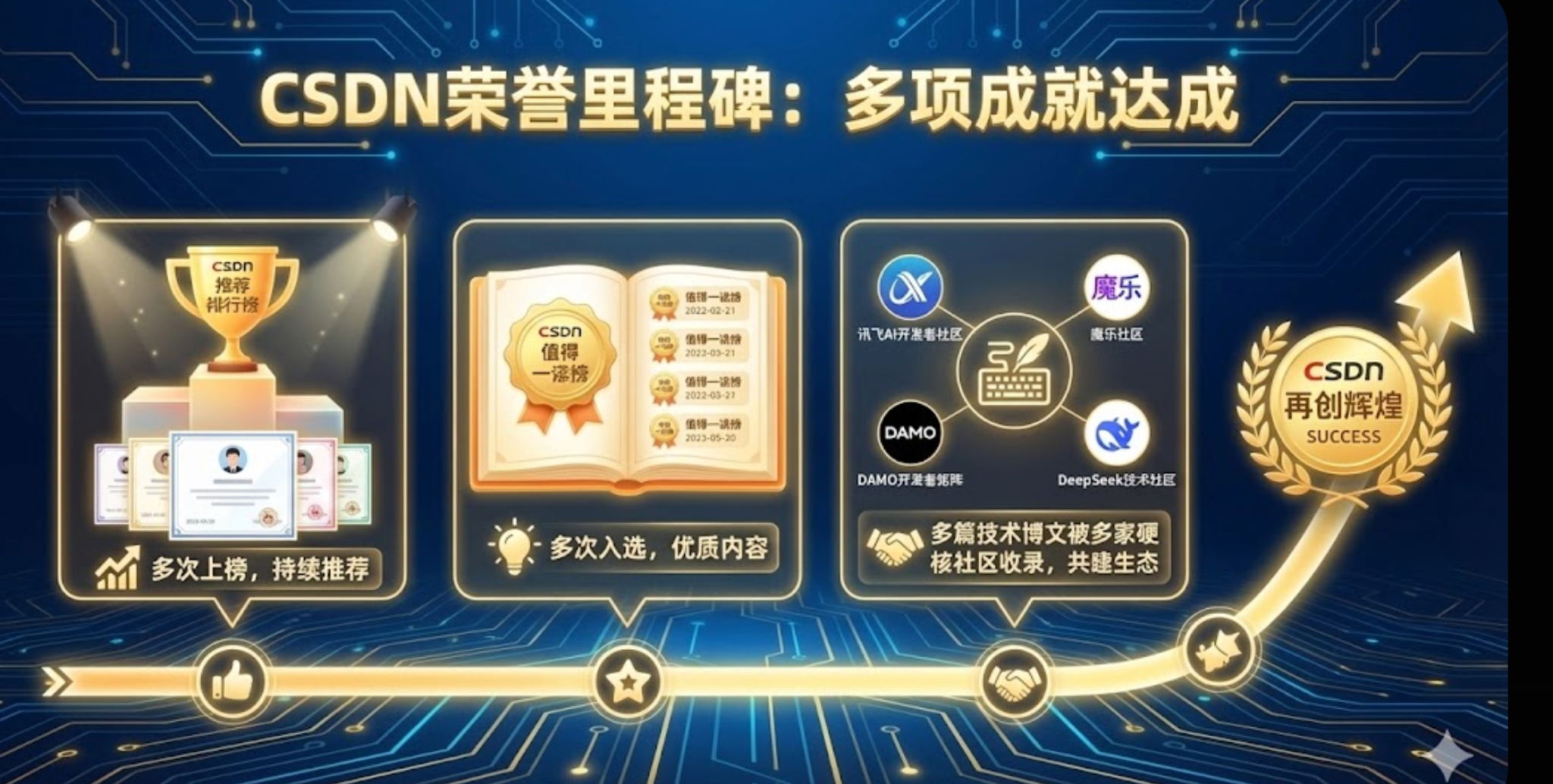
2025 年我的 CSDN 内容侧里程碑记录(多次上榜/优质内容入选/多社区收录等)。这些"结果"对我更像是一个校验:硬核内容是否真的被持续阅读、复用与验证。
你读完这篇文章能带走什么?
一个可复用的闭环视角(Data → Model → Action → Data)+ 我在 2025 围绕每一层写过/做过哪些"能落地"的关键事件。
1)统一视角:Data → Model → Action → Data
我把复杂系统压成四段链路,因为这能逼迫自己"只讲关键件",也让读者"能对号入座":
-
Data(数据):海量、多模态、分布式、质量强约束
-
Model(模型):范式变化快,但工程边界更重要(吞吐、延迟、成本、可靠性)
-
Action(行动):自动驾驶规划控制、机器人动作生成,本质都是"从预测到决策"
-
Back to Data(回流):评价体系、难例挖掘、自动标注、数据再生产
小结:闭环不是口号,是可拆解的链路;
如果这条链路里任何一处"不可复现 / 不可扩展 / 不可监控",系统就无法迭代。所以下一节我先从最底层说起:数据底座。
2)数据底座:不是"存下来",而是"能被持续迭代使用"
在大模型与具身智能里,数据底座的关键从来不是容量,而是三件事:
-
可追溯:数据/特征/标签版本能回滚
-
可增量:持续入湖、持续修正、持续重算(默认增量而非全量)
-
可观测:质量、血缘、延迟、成本可被量化
我在 2025 写数据湖/管道/引擎时,刻意把"工程闭环"写清楚:不是写"能用",而是写"在生产里能持续用"。比如:
-
性能可预期:像数据湖的布局策略(例如 Z-Order),本质是在降低查询的不确定性,避免下游只能靠堆算力。
-
更新语义可复现:像 Delta Lake 的 MERGE 原子更新,必须讲清并发语义,否则"能跑"不等于"能上线"。
-
元数据可演进:像 Iceberg/Catalog/存储计算解耦,决定了多引擎协作的上限。
为了把这些写成"能落地、能验收"的准则,我通常会收敛成四条:
-
用 ODS/DWD/DWS 分层约束数据含义
-
用 CDC/增量 作为默认计算模式
-
用 质量门禁(校验规则/异常回流)作为生产必选项
-
用 布局/索引/聚簇 做可预期性能
小结:数据工程的价值不在"处理一次",而在"可持续迭代"
数据底座解决的是"数据如何稳定供给"。下一节要解决的是:当模型跑在本地、跑在服务里时,真正的生产风险在哪里。
3)模型侧:小模型能本地推理,但"可靠性"要系统化解决
2025 年我写模型,不只写"效果",而是把"落地风险"当成第一等问题:幻觉、错误事实、不可控推理链、成本不可控、延迟不可控。
所以我围绕三件"能直接落地"的能力写得最多:
-
本地推理服务化:让推理模型从"文件"变成"服务"。我做过 QwQ-32B 的本地部署闭环(推理引擎、起 API、交互验证),重点不是跑通,而是沉淀成可复用模板。
-
成本压缩(量化/吞吐):量化不是技巧,是交付能力的一部分。我跟进过 INT8 量化路线,把吞吐/成本/精度的工程权衡讲清楚。
-
可靠性中间层:我拆过 CoVe(Chain-of-Verification),把它写成可插拔流水线:生成 → 规划验证 → 独立验证 → 修正输出,并讨论成本/并行/缓存。
小结:本地部署只是起点;可靠性中间层 + 成本边界控制,才是从 Demo 到生产的分水岭。
模型层解决的是"智能如何稳定输出"。但在自动驾驶/机器人里,模型只是消费数据;系统要赢,必须具备"生产训练信号"的能力------这就是下一节。
4)自动驾驶:闭环关键不是"训练",而是"数据再生产能力"
自动驾驶最现实的一句话是:模型不缺,缺的是稳定产出高质量训练信号的流水线。
所以我在 2025 的自动驾驶内容里,把重点放在"真值/标签/难例"的生产链上,而不是只谈模型结构:
-
真值生产(Occupancy):我做过离线自动标注 Occupancy,把真值生成拆成可执行方案,并写清 3D Ray Casting 的工程实现与优化点。
-
数据底座(ROS Bag 存储):我写过 ROS Bag 的存储与分析(压缩率、查询时延、复杂查询能力三者同时成立)。
-
仿真回流:我拆过 Rosbag → OpenSCENARIO → 仿真验证的数据闭环链路,强调从海量数据中提炼关键场景,形成可持续回归。
为了让这段更可迁移,我习惯压成"闭环三板斧":
-
真值生产:离线/自动标注 + 一致性校验
-
难例挖掘:异常检测、规则引擎、分桶策略
-
回归评估:指标体系与线上/离线一致性
小结:训练是消费数据,闭环必须生产数据;
自动驾驶把"Action"做成了工业级闭环。具身智能要走到同一层级,核心矛盾会更尖锐:既要泛化,又要可训练、可评估、可迭代。
5)具身智能与机器人:VLA 的核心矛盾是"泛化"和"可训练性"同时要
2025 年具身智能最显著的变化,是 VLA 不再停留在"拼模块",而是进入"训练范式创新"的阶段。
我对这件事的写法很明确:**Do it yourself,**在专栏中,我没有停留在解读 论文,而是手写了可运行实现。
-
我实现过 Physical Intelligence 的 π0.5 + KI(知识隔离):从架构到训练/推理/评估/调试,把路径写成"能复现"的工程指南。
-
我也持续拆解"世界模型"路线:当生成数据成为训练数据的重要组成,并能显著提升下游 VLA 的表现时,具身系统的闭环形态会发生质变。
关键工程点
-
架构设计:如何将 VLM 的语义特征与 50Hz 的高频电机控制信号对齐?
-
知识隔离:如何确保机器人在学习"倒咖啡"时,不会遗忘"拿杯子"的基础能力?
-
Sim2Real:在 Isaac Gym / Genesis 中训练的策略,如何零样本迁移到真机?
小结:具身智能的难点不是概念,而是可训练/可评估/可迭代;写作要把"论文机制"变成"工程骨架"。
讲完链路四层,最后我用"系统层级"把 2025 的代表性输出整理一次------这比按时间线堆链接更像一份可复用的工程目录。
在整理 2025 的代表性输出之前,我先放一张"数据快照"。对我来说,这些数字不是炫耀项,而是一个校验:硬核内容是否真的被持续阅读、沉淀与复用。
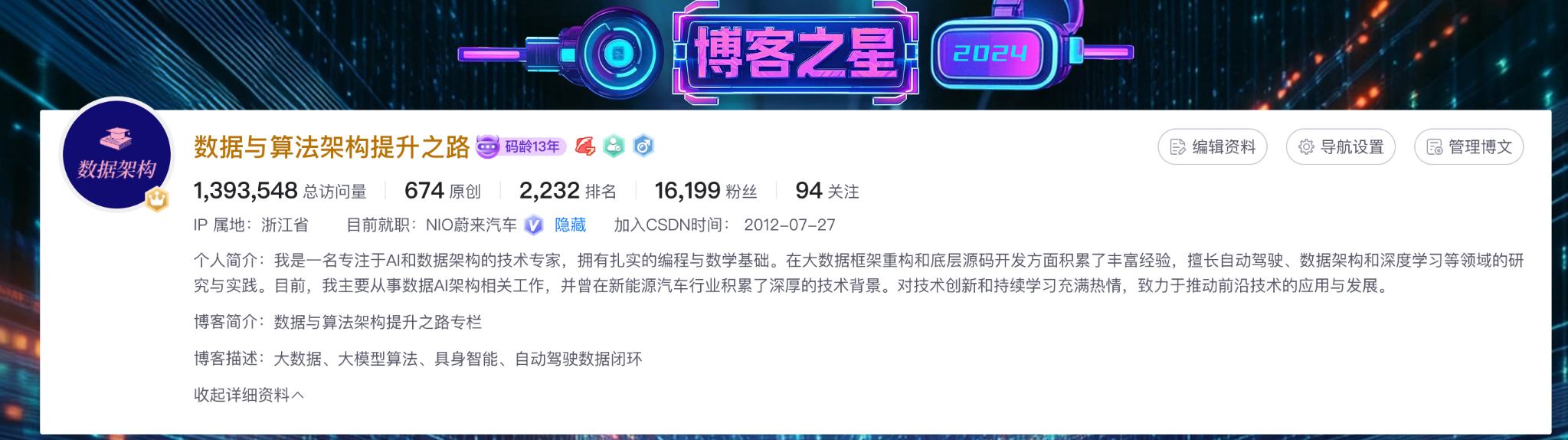
我的 CSDN 主页数据概览(总访问量/原创数/排名/粉丝等)
6)2025 代表性输出:按系统层级组织
下面按 Data / Model / Action&Feedback / Embodied Action/ Infr 分层列代表作。
A. Data Layer(数据底座/平台工程)
B. Model Layer(小模型本地推理 / 成本 / 可靠性)
C. Action & Feedback(自动驾驶闭环:真值/难例/回归)
D. Embodied Action(具身智能:VLA / 世界模型)
E. Infr Layer(模型推理训练:训推平台)
另外,我也在用"外部复用"来验证内容是否真的写到了可迁移层:一篇文章如果足够结构化、足够可复现,才会被不同社区以"可引用/可二次传播"的方式收录。
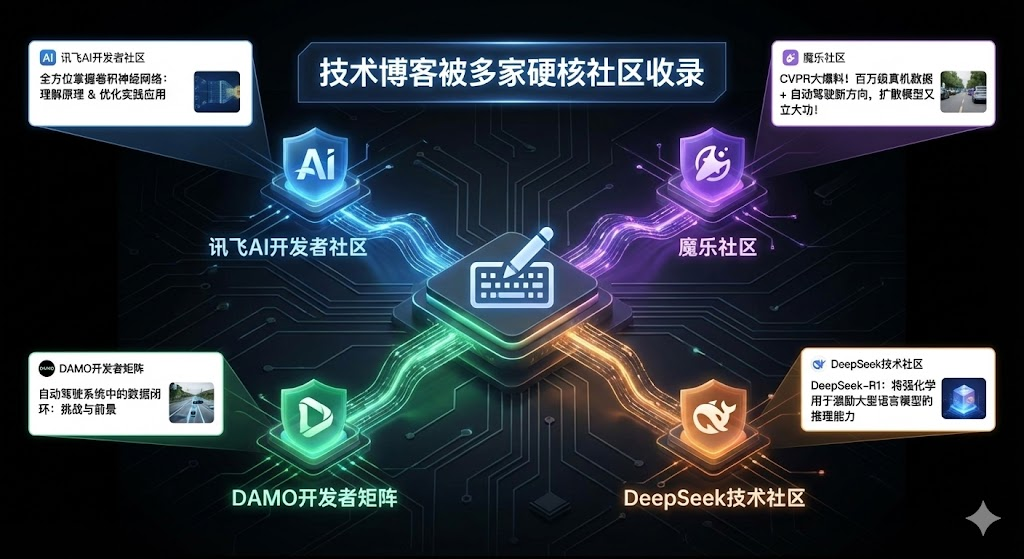
2025 年部分文章被讯飞 AI 开发者社区、魔乐社区、DAMO 开发者矩阵、DeepSeek 技术社区等收录。对我来说这不是展示项,而是一个工程指标:内容是否具备可复用性与传播性。
因此,下一步我希望把"外部收录的复用"进一步前移到"写作阶段的协作输入端"------也就是让评论区变成我的需求池/难例池/配置池。
7)评论区共创:把互动变成"闭环输入端"
我的硬核文章搜索量不低,但互动偏低的根因很简单:读者"拿走就用",但不知道怎么参与、参与后能得到什么。
所以我把评论区设计成闭环系统的输入端:需求池 / 难例池 / 配置池 。
如果你愿意参与协作,请按这个格式留言(我会把高共性问题整理成后续文章的可复用交付物):
评论区模板
1)你的场景:数据平台 / 自动驾驶 / 具身机器人 / 大模型应用
2)你的瓶颈:数据质量、成本、延迟、吞吐、标注、评估回归、可靠性
3)你的约束:数据规模(TB/PB)、模态(图像/点云/视频/轨迹)、是否需要本地部署
4)你最想要的交付物:SOP / 代码模板 / 指标体系 / 选型对比 / 排错清单
我会做什么
选取高频组合整理成《闭环方案清单》(架构图 + 最小闭环步骤 + 排错清单)
在后续文章中统一更新,并在文末列出"共创贡献者"(昵称署名)
结语
2025 年我更确信一件事:**真正有价值的"智能",是被闭环系统稳定生产出来的。**我会继续用"数据闭环"的方式写大模型、写自动驾驶、写具身智能------把复杂系统拆成可复用模块,把落地经验写成可验证路径。

欢迎把你的瓶颈丢进评论区,我拿它做下一篇"可落地方案