一、Redis初步介绍
1.1 Redis是什么??
Redis是⼀种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的是,Redis中的值可以是由string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、 Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此Redis可以满足很多的应用场景,
而且因为Redis会将所有数据都存放再内存中,所以它的读写性能非常惊人。不仅如此,Redis还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据不会"丢失"。
除了上述功能以外,Redis还提供了键过期、发布 订阅、事务、流水线、Lua脚本等附加功能。总之,如果在合适的场景使⽤好Redis,它就会像⼀把瑞士军刀⼀样所向披靡。
1.2 Redis的出身
2008年,Redis的作者Salvatore Sanfilippo在开发⼀个叫LLOOGG的⽹站时,需要实现⼀个高性能的队列功能,最开始是使⽤MySQL来实现的,但后来发现⽆论怎么优化SQL语句等都不能使⽹站的性能提⾼上去,再加上自己囊中羞涩,于是他决定⾃⼰做⼀个专属于LLOOGG的数据库,这个就是Redis的前⾝。后来,Salvatore Sanfilippo将Redis1.0的源码发布到Github上,可能连他⾃⼰都没想到,Redis后来如此受欢迎。
假如现在有⼈问Redis的作者都有谁在使⽤Redis,我想他可以开句玩笑的回答:还有谁不使⽤Redis,当然这只是开玩笑,但是从Redis的官⽅公司统计来看,有很多重量级的公司都在使用Redis,如国外的Twitter、Instagram、Stack Overflow、Github等,国内就更多了,如果单单从体量来统计,新浪微博可以说是全球最⼤的Redis使⽤者,除了新浪微博,还有像阿⾥巴巴、腾讯、搜狐、优酷、土豆、美团、小米、唯品会等公司都是Redis的使⽤者。除此之外,许多开源技术像ELK等 已经把Redis作为它们组件中的重要⼀环,⽽且Redis还提供了模块系统让第三⽅⼈员实现功能扩展,让Redis发挥出更⼤的威力。所以,可以这么说,熟练使⽤和运维Redis已经成为开发运维⼈员的⼀个必备技能。
1.3 Redis的作用(开源的)
1、消息代理(message broker):Redis最早被设计的初衷,就是用来做一个"消息中间件"即分布式系统下的生产者消费者模型。 message broker用于在不同应用程序中传递消息,它是一种解耦合的方式,使得应用程序可以独立运作而不需要知道其他应用程序的存在。但是当前很少会直接使用Redis作为中间件,因为业界有更多专业的消息中间件使用
2、高速缓存存储器(cache):Redis的特点之一就是在内存中存储数据,由于CPU的速度远高于内存,需要等待一定的时间周期,所以cache可以保存CPU刚用过或循环使用的一部分高频数据(提高命中率),当CPU需要再次使用的时候可以直接从cache中调用从而避免了重复从内存中存储数据,减少了CPU的等待时间从而提高系统性能。
3、流式处理引擎(streaming engine):Redis的具有高性能和低延迟的特性!流式处理引擎是一种专门用于处理流式数据的软件系统或者平台,streaming engine能够持续不断获取持续产生的流式数据并立即进行处理和分析,数据像水流一样源源不断流入,而不需要等所有数据都到达了再处理,比传统的批量处理更加高效。
4、数据库(database):mysql最大的问题就在于访问速度比较慢,由于很多互联网产品中对于性能的要求是很高的,所以redis作为数据库使用性能更快(定性角度可以知道redis快很多,但是很难定量衡量)!!
1.4 为什么要有Redis
问题1:mysql vs redis
---->redis虽然速度更快,但是和mysql相比最大的劣势就是存储空间是有限的!!具体使用哪个当数据库是要依据实际场景是否对性能的要求较高 !
MySQL主要是通过"表"的方式来存储组织数据的"关系型数据库",而Redis主要是通过"键值对"的方式来存储组织数据的"非关系型数据库"
问题2:有没有又大又快的方案呢??
----->可以把mysql和redis结合起来用,利用"二八原则"(20%的热点数据,能够满足80%的访问需求)。但是这样的话系统的复杂程度就大大提升了,如果数据发生了修改,还会涉及到redis和mysql之间的数据同步问题。
------>所以没有银弹 (在十九世纪哥特风潮影响下,银色子弹往往被描绘成具有驱魔功效的武器,是针对狼人、吸血鬼等超自然怪物的特效武器,在这里被比喻为具有极端有效性的解决方法,是杀手锏、最强杀招、王牌的代称)。就是说没有一种方案可以完美解决所有问题!
问题3:Redis只有在分布式系统中才能发挥出最大威力?
------->如果只是单机程序,那么直接通过变量存储数据显然是更优秀的存储方式,而在分布式系统中则是redis更优秀,因为定义变量是在当前服务器进程内部的内存空间,但是进程具有隔离性。分布式系统必然涉及到多个进程在不同的主机上。此时你想访问其他进程的内存里的变量是比较困难的。所以redis是针对上面的这个需求做的一个封装,意思就是既然无法突破进程的隔离性,那就基于网络(进程间通信)将自己内存中的变量给别的进程甚至是别的主机的进程进行使用。
二、Redis的特性
2.1 速度快
正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性能可以达到10万/秒,当 然这也取决于机器的性能,但这⾥先不讨论机器性能上的差异,只分析⼀下是什么造就了Redis如此之快,可以⼤概归纳为以下四点:
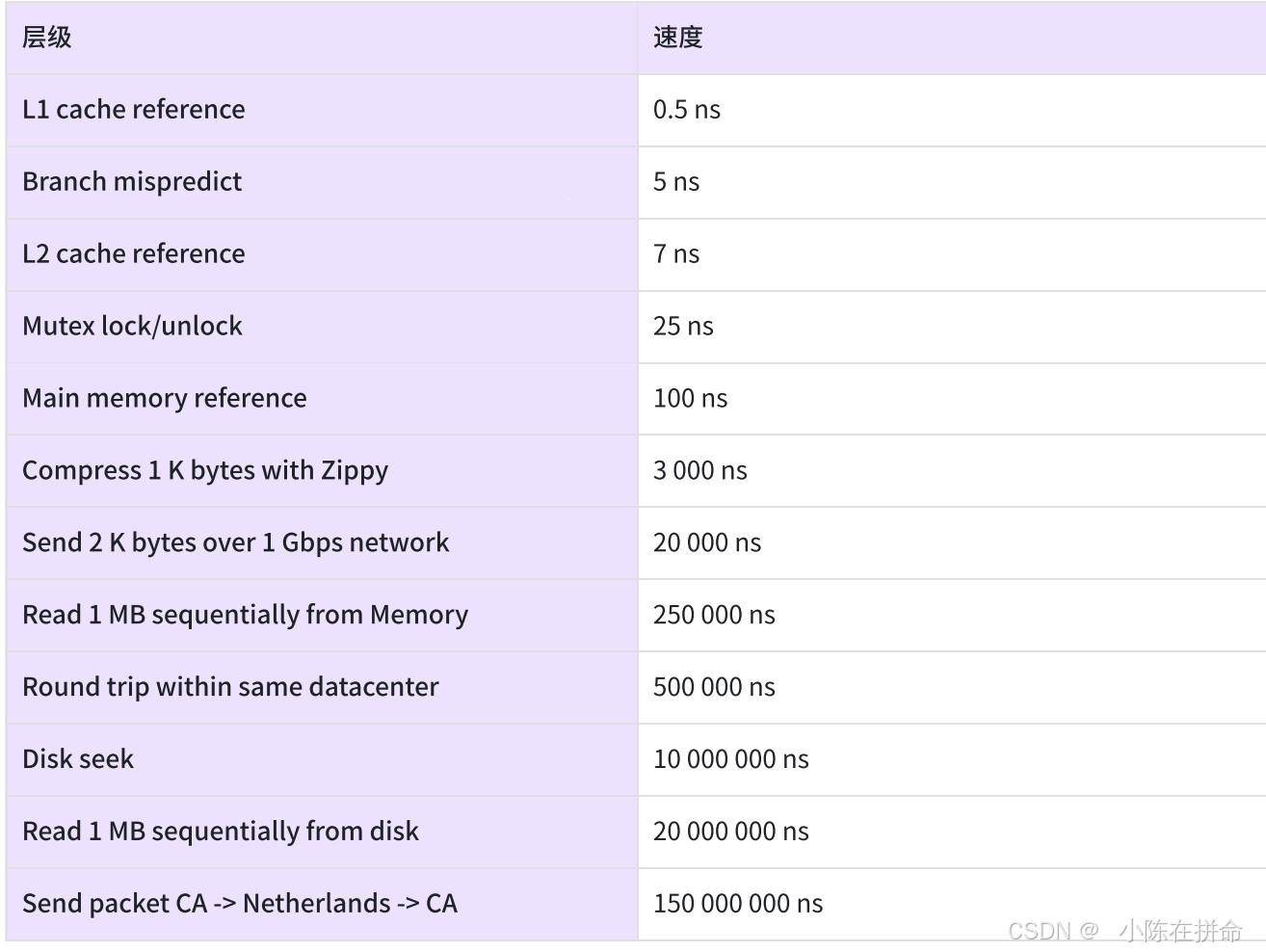
1、Redis的所有数据都是存放在内存中的,就要比访问硬盘的数据库快很多,下表是⾕歌公司2009年给出的各层级硬件执行速度,所 以把数据放在内存中是Redis速度快的最主要原因。
 2、Redis是用C语言实现的,⼀般来说C语言实现的程序"距离"操作系统更近,执⾏速度相对会更快。(这不是主要原因,因为Mysql也是用C语言开发的)
2、Redis是用C语言实现的,⼀般来说C语言实现的程序"距离"操作系统更近,执⾏速度相对会更快。(这不是主要原因,因为Mysql也是用C语言开发的)
3、Redis使用了单线程(虽然Redis在6.0版本引⼊了多线程机制,但主要也是在处理网络和IO,不涉及到数据命令,即命令的执行仍然采用了单线程模式。),这样的单线程模型减少了不必要的线程之间的竞争开销。
多线程提高效率的前提是CPU密集型的任务,使用多个线程可以充分利用cpu多核资源。但是Redis的核心任务主要是操作内存的数据结构。
4、作者对于Redis源代码可以说是精打细磨,曾经有⼈评价Redis是少有的集性能和优雅于一身的开源代码。Redis的核心功能都是比较简单的操作内存的数据结构
5、 从网络的角度上,Redis使用了IO多路复用的方式(epoll即使用一个线程管理很多个socket)
2.2 基于键值对的数据结构服务器
⼏乎所有的编程语⾔都提供了类似字典的功能,例如C++⾥的map、Java⾥的map、Python⾥ 的dict等,类似于这种组织数据的⽅式叫做基于键值对的⽅式,**与很多键值对数据库不同的是, Redis中的值不仅可以是字符串,而且还可以是具体的数据结构,这样不仅能便于在许多应用场景的开发,同时也能提高开发效率。**Redis的全程是REmote Dictionary Server,它主要提供了5种数据结构:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(ordered set/ zet),同时在字符串的基础之上演变出了位图(Bitmaps)和HyperLogLog两种神奇的"数据结构",并且随着LBS(Location Based Service,基于位置服务)的不断发展,Redis3.2.版本种加⼊ 有关GEO(地理信息定位)的功能,总之在这些数据结构的帮助下,开发者可以开发出各种"有意思"的应⽤。
2.3 丰富的功能
1、提供了键过期功能,可以用来实现缓存。
2、提供了发布订阅功能,可以⽤来实现消息系统。
3、针对Redis的操作,可以直接通过简单的交互式命令进行操作
4、⽀持Lua脚本功能,可以利⽤Lua创造出新的Redis命令。
5、提供了简单的事务功能,能在⼀定程度上保证事务特性。
6、提供了流水线(Pipeline)功能,这样客户端能将⼀批命令⼀次性传到Redis(可以带有一些逻辑),减少了网络的开销。
2.4 简单稳定
Redis的简单主要表现在三个⽅⾯。
1、Redis的源码很少,早期版本的代码只有2万⾏左右, 3.0版本以后由于添加了集群特性,代码增⾄5万⾏左右,相对于很多NoSQL数据库来说代码量相对 要少很多,也就意味着普通的开发和运维⼈员完全可以"吃透"它。
2、Redis使用单线程模型, 这样不仅使得Redis服务端处理模型变得简单,⽽且也使得客户端开发变得简单。
3、Redis不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库),Redis⾃⼰实现了事件处理的相关功能。 但与简单相对的是Redis具备相当的稳定性,在⼤量使⽤过程中,很少出现因为Redis⾃⾝BUG⽽导致宕掉的情况。
2.5 客户端语言多
Redis提供了简单的TCP通信协议,很多编程语⾔可以很⽅便地接⼊到Redis,并且由于Redis受到社区和各大公司的广泛认可,所以⽀持Redis的客户端语言也非常多,⼏乎涵盖了主流的编程语⾔,例如C、C++、Java、PHP、Python、NodeJS等。
2.6 持久化(Persistence)
通常看,将数据放在内存中是不安全的,⼀旦发生断电或者机器故障,重要的数据可能就会丢 失,因此Redis提供了两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据备份到硬盘中,当Redis重启的时候,就会再重启时加载到硬盘中的备份数据,使得Redis的内存恢复到重启前的状态,这样就保证了数据的可持久性。
 2.7 主从复制(Replication)
2.7 主从复制(Replication)
Redis提供了复制功能,实现了多个相同数据的Redis副本(Replica)(如图1-2所示),复制功能是分布式Redis的基础。从节点就相当于主节点的备份。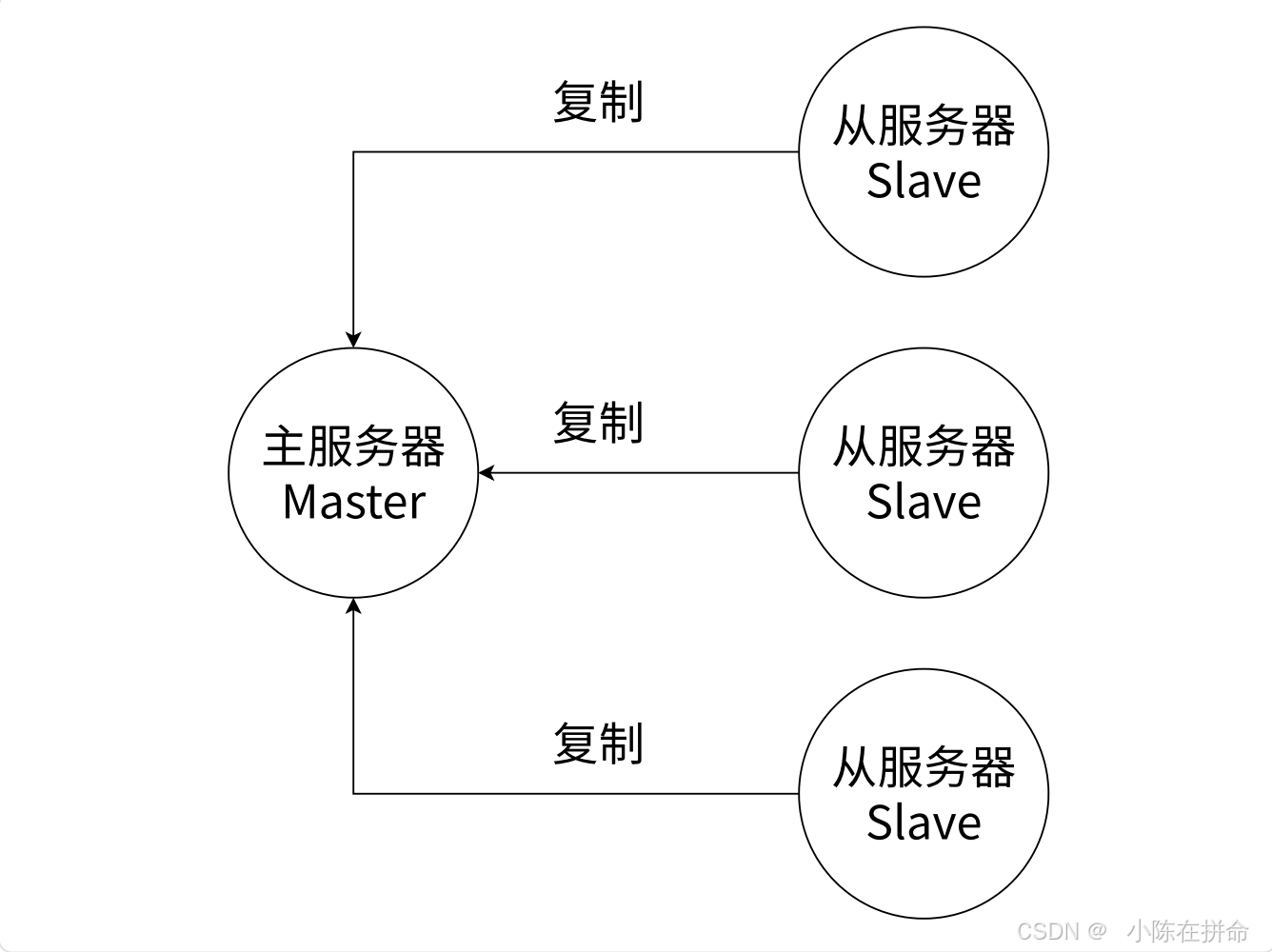
2.8 高可用(High Availability)和分布式(Distributed)
Redis提供了高可用实现的Redis哨兵(Redis Sentinel),能够保证Redis结点的故障发现和故 障自动转移。
也提供了Redis集群(Redis Cluster),是真正的分布式实现,提供了高可用、读写和容量的扩展性。(一个Redis能存储的数据是有限的,引入多个主机部署多个Redis节点,每个Redis存储数据的一部分)
2.9 可扩展性
Redis有提供一组API,可以在Redis原有的功能基础上通过C/C++/Rust语言编写Redis扩展(本质上就是一个动态链接库)

比如说Redis自身已经提供很多数据结构和命令了,我们可以通过扩展让Redis支持更多的数据结构和更多的命令!!
三、Redis的应用场景
3.1 需要低延迟高吞吐的实时应用数据库
虽然大多数情况下数据存储优先考虑的都是"大",但是仍然有一些场景考虑的是"快",比方说搜索引擎对于性能的要求非常高,所以搜索系统就没有用到MySQL这样的数据库,而是把所有需要检索的数据存储在类似于Redis这样的内存数据库来完成的。
当然使用这样的数据库存储大量数据是需要不少硬件资源的,并且存的是全量数据,是不可以随便丢弃的!!
3.2 缓存存储热点数据
缓存机制⼏乎在所有大型网站都有使⽤,合理地使用缓存不仅可以加速数据的访问速度,⽽且能够有效地降低后端数据源的压力。 Redis提供了键值过期时间设置,并且也提供了灵活控制最⼤内存和内存溢出后的淘汰策略。可以这么说,⼀个合理的缓存设计能够为⼀个网站的稳定保驾护航。且redis存的是部分数据,全量数据是以mysql为主的,那么redis的数据没了,还可以从mysql这边再加载回来!
3.3 会话存储

cookie是实现用户身份信息保存的,但其实只是在浏览器这边存储了一个用户的身份标识session id,而真正的用户数据是通过session存储在应用服务器上的。
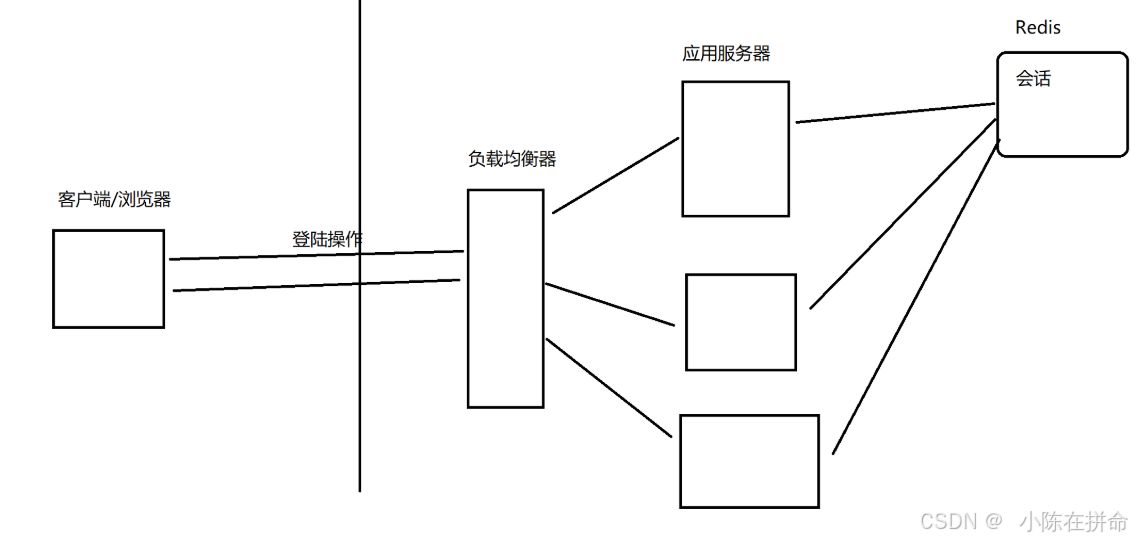
我们第一次登录的时候,会将用户信息通过session存在一个应用服务器上,但是如果我们第二次登录的时候,如果我们的负载均衡器没有将我们的请求发给之前的那个应用服务器,那就可能导致我们找不到之前的登录信息,所以又得重新登录一次...... 那么如何解决上述的问题呢??
------>(1)想办法让负载均衡器,把同一个用户的请求始终打到同一个机器上(不能轮询,而是通use id之类的方式来分配机器)
(2)把会话数据单独拎出来,放到一组独立的机器上存储(通过redis),并且这样的话即使应用服务器重启了,session也不会丢失(如上图),就算真的丢失了也可以通过mysql加载回来!!
3.4 消息队列系统
消息队列系统可以说是⼀个大型网站的必备基础组件(提供基于网络版本的生成消费者模型),对于分布式系统来说,服务器和服务器之间有时候也需要使用到生产者消费者模型的,因为其具有业务解耦、非实时业务削峰填谷等特性。
业内也有很多知名的消息队列 RabbitMQ、Kafka、RocketMQ......其中Redis提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强⼤,但是对于⼀般的消息队列功能基本可以满足。如果当前场景对于消息队列的功能依赖不是很多,且不想引入额外的依赖,那么redis就可以作为一个很好的选择。
3.5 排行榜系统
排⾏榜系统⼏乎存在于所有的⽹站,例如按照热度排名的排⾏榜,按照发布时间的排⾏榜,按照各种复杂维度计算出的排⾏榜,Redis提供了列表和有序集合的结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
3.6 计数器应用
计数器在⽹站中的作⽤⾄关重要,例如视频⽹站有播放数、电商⽹站有浏览数,为了保证数据的 实时性,每⼀次播放和浏览都要做加1的操作,如果并发量很⼤对于传统关系型数据的性能是⼀种挑战。Redis天然⽀持计数功能⽽且计数的性能也⾮常好,可以说是计数器系统的重要选择。
3.7 社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,⽽且传统的关系型数据不太合适保存这种类型的数据,Redis提供的数据结构可以相对⽐较容易地实现这些功能。
四、Redis不能做什么
实际上和任何⼀⻔技术⼀样,每个技术都有自己的应用场景和边界,也就是说Redis并不是万⾦油,有很多合适它解决的问题,但是也有很多不合适它解决的问题。我们可以站在数据规模和数据冷热的⻆度来进⾏分析。
站在数据规模的⻆度看,数据可以分为⼤规模数据和⼩规模数据,我们知道Redis的数据是存放 在内存中的,虽然现在内存已经⾜够便宜,但是如果数据量⾮常⼤,例如每天有⼏亿的⽤⼾⾏为数 据,使⽤Redis来存储的话,基本上是个⽆底洞,经济成本相当⾼。
站在数据冷热的⻆度,数据分为热数据和冷数据,热数据通常是指需要频繁操作的数据,反之为冷数据,例如对于视频⽹站来说,视频基本信息基本上在各个业务线都是经常要操作的数据,⽽⽤⼾的观看记录不⼀定是经常需要访问的数据,这⾥暂且不讨论两者数据规模的差异,单纯站在数据冷热的⻆度上看,视频信息属于热数据,用户观看记录属于冷数据。如果将这些冷数据放在Redis上,基本上是对于内存的⼀种浪费,但是对于⼀些热数据可以放在Redis中加速读写,也可以减轻后端存储的负载,可以说是事半功倍。
所以,Redis并不是万⾦油,最大的问题就是不能存储大规模的数据!!
不同的业务场景,分布式系统具体的实践方式差异是很大的!!所以我们一定要尽快进去大厂去接触更多的业务代码,才能更好地理解。
五、Redis ACL如果工作??
ACL(访问控制列表):用"标签"管理"命令权限"
Redis 有上百个命令。ACL 的核心逻辑是:不直接给用户分配"能执行哪些命令",而是给每个命令打上"标签",然后给用户分配"能使用哪些标签"。
Redis 内置了命令分类标签,例如:
read :只读命令,如 GET, HGET, LRANGE。
write :写命令,如 SET, HSET, LPUSH。
dangerous :危险命令,如 FLUSHALL, KEYS。
admin :管理命令,如 CLIENT, CONFIG, ACL自身。
pubsub:发布订阅相关命令。
假设场景:为三种角色创建ACL用户
(1)普通访问用户:只能读缓存,不能修改数据,不能看敏感信息
------>只允许read且只能访问特定的键,假设博客文章都以post::开头
# 创建用户 viewer,密码 123,允许读命令,且只能匹配 post:* 的键
ACL SETUSER viewer on >123 ~post:* +@read(2)编辑用户:可以读写文章但不能执行危险管理命令
------>只允许read和write,但禁止dangerous和 admin。键空间开放更多。
ACL SETUSER editor on >456 ~post:* ~comment:* +@write +@read -@dangerous -@admin(3)管理员:拥有全部权限
------>使用特殊标签 allcommands允许所有命令,allkeys允许访问所有键。通常还会限制来源 IP 以增加安全。
ACL SETUSER admin on >789 allkeys allcommands
六、Redis的安装和环境搭建
以Redis5 为主
平台:Linux(官方是不支持windows的,但是微软有维护一个windows版本的windows分支)
(开始学习的时候先在本机上安装,后面学到redis的集群相关的功能的时候再使用docker)
1、unbuntu安装
(1)先切换到root用户 su命令切换到root
(2)使用apt命令来搜索redis相关的软件包
apt search redis ---搜索和redis相关的软件包

(3)使用apt命令安装redis
安装命令:apt install redis
安装完后可以用 netstat -anp | grep redis 去查看

默认端口是6379,而绑定这个127.0.0.1的ip意味着只能由当前主机上的客户端访问,一旦跨主机就访问不了了!!
(4)需要手动修改配置文件,把ip改了
cd /etc/redis
这个redis.conf包含了redis的相关内容的配置功能
!!!什么叫配置文件------>一个大的软件,里面包含很多功能,有很多可以定制化的操作,就可以通过配置文件选择开启/关闭/设定某些功能(可以理解为将指令通过配置文件传达给程序)
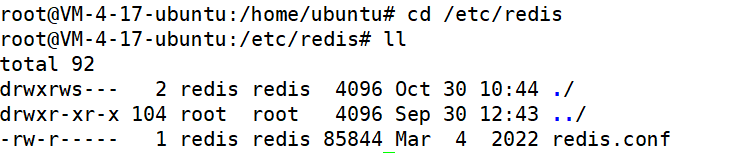
把127.0.0.1 改成0.0.0.0

保护模式也要改成no

当前阶段我们的数据不值钱,所以没有必要去配置密码(大多数情况下缓存的数据价值都不高)
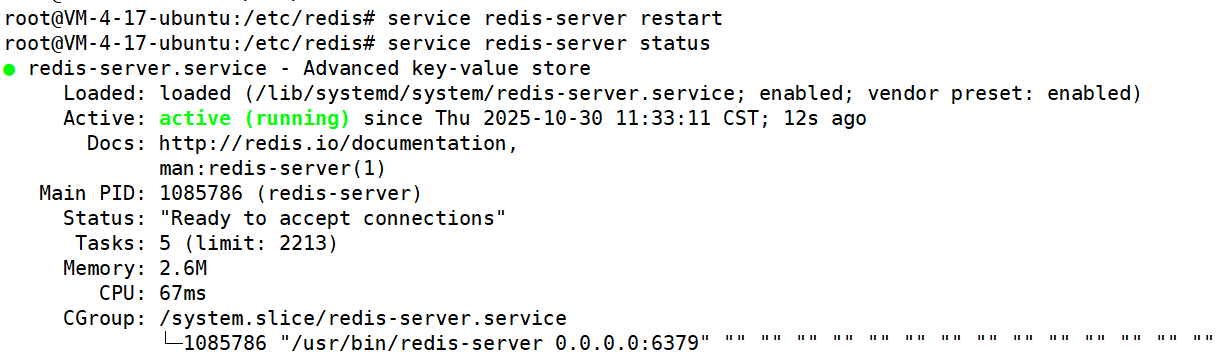
(5)重启服务器让配置生效 并 检查服务器状态
service redis-server restart
service redis-server status
(6)使用redis自带的客户端来连接服务器
redis-cli -h hostname -p port ##默认是127.0.0.1:6379
这个命令是redis自带的客户端连接工具,用来和redis服务器进行交互用的
可以用ping去测试是否连通,如果是PONG说明连通成功

(7) ctrl+d退出
2、centos安装
yum list | grep redis -》查看redis版本

如果是centos8,yum仓库中默认的redis版本就是5,直接yum install即可
yum install redis
如果是centos7,默认的是3系列比较老(此次我们需要按照额外的软件源 比如scl源)
yum install centos-release-scl-rh
yun install rh-redis5-redis
七、redis客户端介绍
7.1 redis也是一个服务端-客户端程序
1. 通过网络建立联系**------>所以redis的客户端和服务器可以在一个主机上,也可以在不同主机上**
2. 一个redis服务器可能服务多个redis客户端**------>所以redis服务端是数据存储和管理的主体**
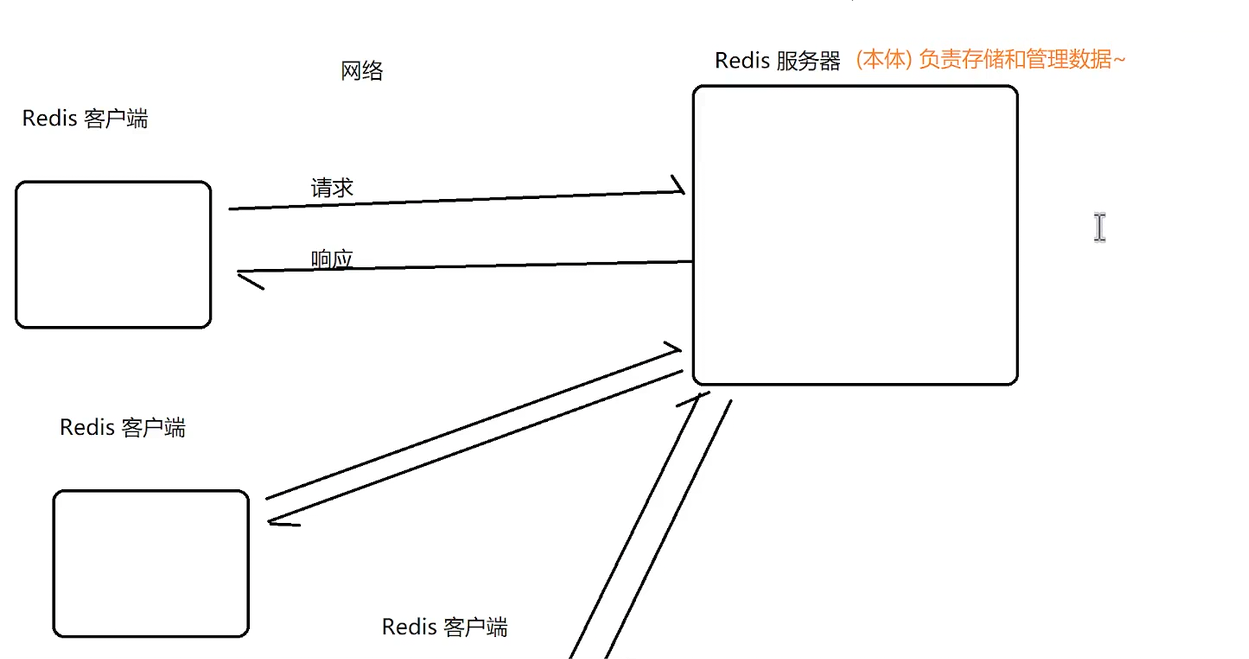
7.2 redis客户端的几种形态
1.自带命令行的客户端

-h和-p可以指定要链接的主机和端口,不带的话默认是本地redis服务器127.0.0.1:6739
一般退出可以用quit命令,或者ctrl+d(不要按ctrl+s,否则页面会卡住,此时ctrl+q可以解冻)
2.图形化界面客户端(桌面程序、web程序)
图形化工具虽然本地用着方便,但实际工作中常因公司网络安全限制而无法连接服务器数据库,因此掌握命令行操作才是更可靠的技能。

3.基于redis的api自行开发客户端工作中最主要的形态
非常类似于MySQL的C语言API和JDBC
7.3 redis的特点
相比较于MySQL这样的关系型数据块更快,但是如果直接和内存中的操作变量相比就没有优势了
未来要扩展成分布式系统,使用redis也是更佳的。
所以你到底用不用redis,需要考虑你更关注性能、数据独立部署。扩展性??需要对症下药

7.4 Redis 与 MySQL 的 "database" 核心差异

关键结论 :Redis 的"数据库"是预定义的、编号的、隔离的键空间 ,更像"命名空间"而非传统数据库。生产实践中几乎只用 0 号库。
7.5 数据库管理命令
|--------------------------------|----------------------------------|-----------|-------------------------------------------------------------------------------------------------------------------------------------------------------|
| 语法 | 作用 | 返回值 | 注意事项 |
| selectdbIndex | 切换到指定的数据库(0-15) | 成功返回 OK | 1. 切换后,所有后续命令 都在该库执行。 2. 客户端连接可随时切换,不影响其他连接。 3. 生产环境建议固定使用 0 号库,避免混乱。 |
| dbsize | 返回当前选中数据库中键(key)的数量。 | 键的数量(整数) | 1. 时间复杂度 O(1) ,性能极佳。 2. 只统计当前库,不包含其他库。 3. 用于监控和调试。 |
| flushdb ASYNC \| SYNC | 清空当前选中数据库中的所有键。 | 成功返回 OK | 1. 高危命令! 生产环境慎用。 2. 选项说明(图3): - ASYNC (异步,Redis 4.0+):后台线程慢慢删,不阻塞 主线程。 - SYNC (同步,默认):主线程立即删,会阻塞 服务。 3. 无备份,数据不可恢复。 |
| flushall ASYNC \| SYNC | 清空 Redis 实例中所有数据库(0-15)的所有键。 | 成功返回 OK | 1. 核弹级高危命令! 相当于 rm -rf /*。 2. 同样支持 ASYNC/SYNC选项。 3. 生产环境应严格禁用 (可通过配置或ACL)。 4. 测试环境也需谨慎。 |
八、Redis的单线程模型
8.1 redis线程模型的一体两面
**Redis 的核心命令处理是"单线程"的,但整个 Redis 进程是"多线程"**的。
|---------|---------------------------------------------------------------|
| 单线程(核心) | 串行执行所有客户端命令(经过网络IO后会在队列中排队) |
| 多线程(辅助) | 1、多个线程处理网络IO(读写数据) 2、后台线程处理持久化 (比如快照)、异步删除大货等重型任务 |
核心一句话:主线程只管"算",不管"搬"(IO)和"存"(持久化/删大货)
8.2 面试题:redis为什么选择单线程模型?为什么效率这么高?速度这么快?
1、redis的核心操作是对内存数据的简单键值存储,功能纯粹,属于"短平快"操作,不太吃CPU资源 ,即使使用多线程性能提升也不明显,相比之下MySQL是对硬盘进行事务、约束、复杂事务查询,开销大
2、单线程天然串行化所有命令,避免了多线程环境下的竞态条件。
3、处理网络IO的时候,可以使用epoll这样的IO多路复用机制,这也是为了应对单线程最大的弊端------阻塞风险。
8.3 epoll解决单线程阻塞的原理
epoll核心思想:用一个线程监视所有网络连接,只关注活跃事件是实现高并发的关键。
问题1:为什么可以用epoll呢?
1、大部分客户端并不时刻传输数据,连接时间多数是"静默"的。
想象你到饭店吃饭花了30分钟,但你和服务员的交流可能只有2分钟。
2、epoll事件通知机制可以让主线程只关注那些活跃连接,此时主线程就像"时事件驱动的调度员"
问题2:不适合epoll的场景
客户端需要频繁和服务端交互时,最好老老实实多搞几个线程。否则忙不过来。
想象一下你打游戏的时候,你妈喊你吃饭,这个时候你只能挂机或者叫你朋友帮你玩。