大家都知道AI计算,特别是模型训练与推理环节,核心依赖于并行计算架构。
在AI的底层算法中,诸如矩阵乘法、卷积运算、循环结构以及梯度反传等关键操作,均需调动成千上万块GPU,通过高度并行的任务调度来高效推进,从而显著压缩整体耗时。
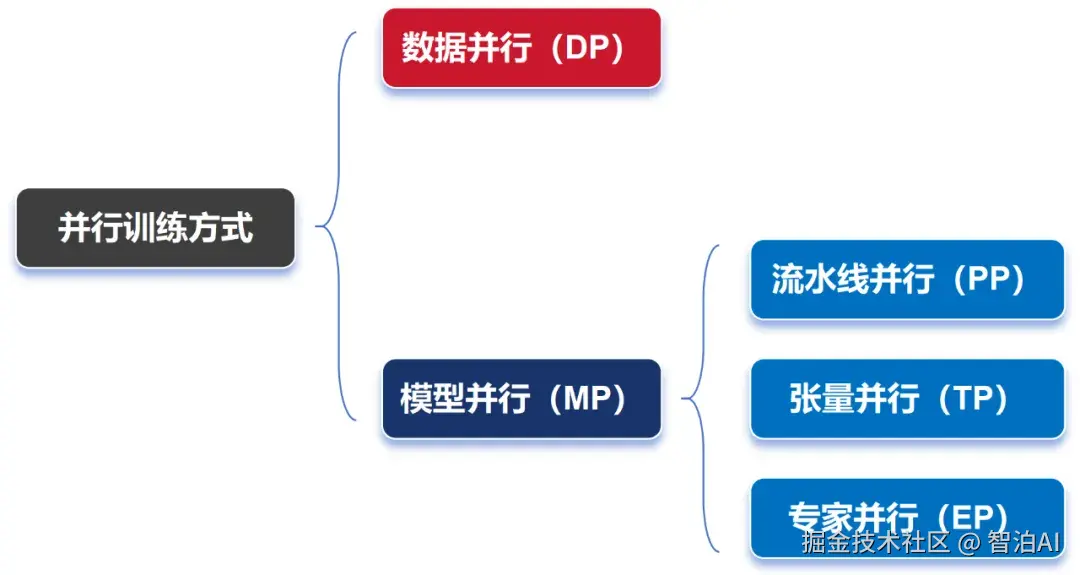
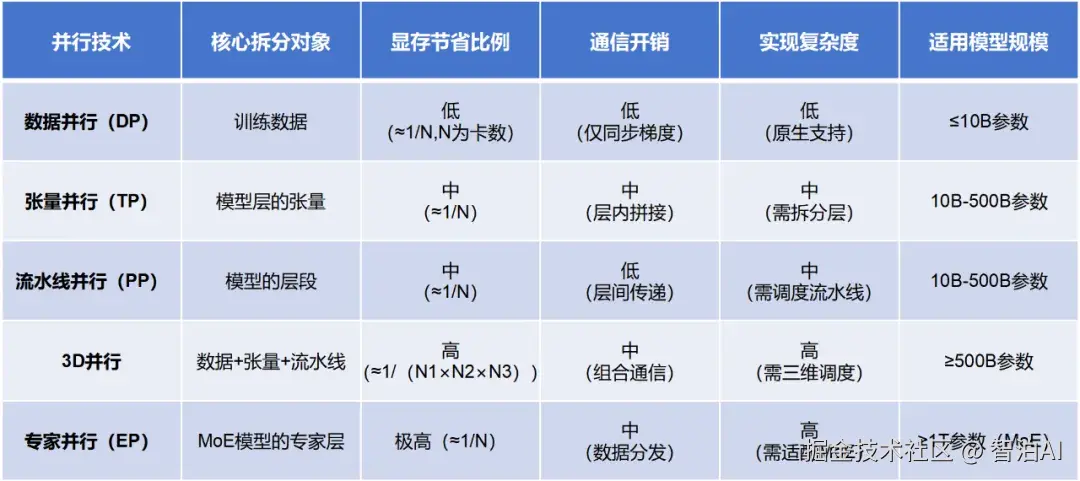
构建高性能并行计算框架时,业界普遍采用以下四种主流策略:
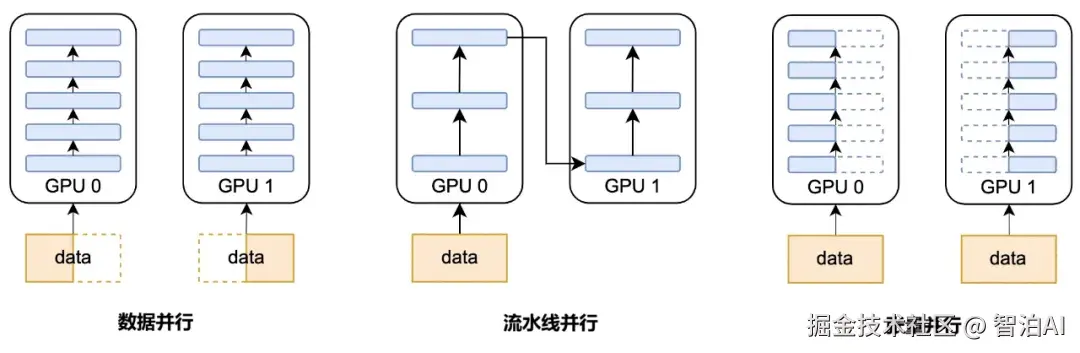
Data Parallelism,数据并行
Pipeline Parallelism,流水线并行
Tensor Parallelism,张量并行
Expert Parallelism,专家并行
接下来,我们将逐一对这些并行机制的运行逻辑展开解析。
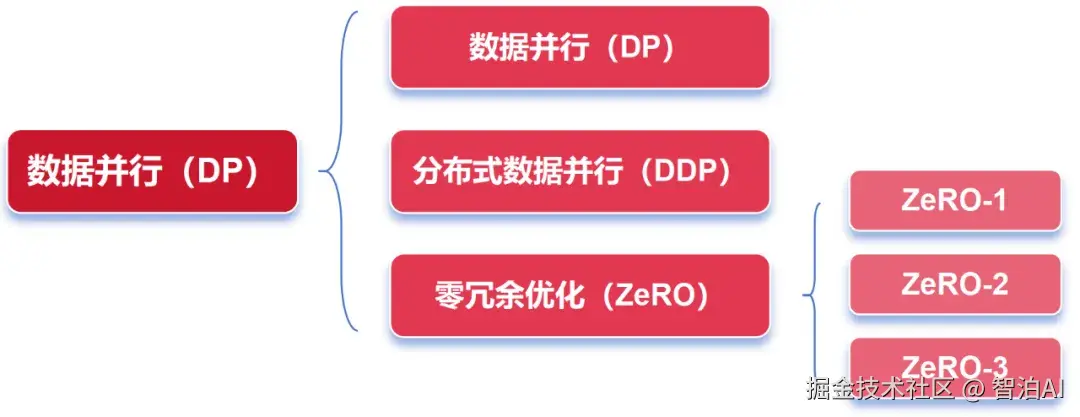
一、DP(数据并行)
首先来看DP,即数据并行(Data Parallelism)。
在AI训练中,并行策略总体上可划分为两大类:数据并行与模型并行。
此前提到的PP(流水线并行)、TP(张量并行)和EP(专家并行),均归属于模型并行的范畴,后续将另行展开说明。
这里,我们先对神经网络的训练流程做一个概览。通俗来讲,其核心环节主要包含以下几个关键阶段:
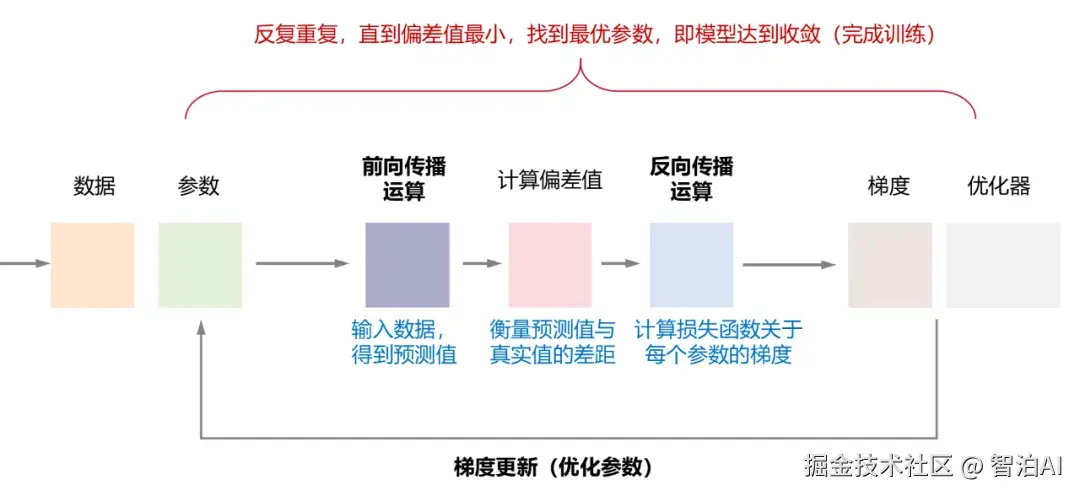
前向传播:将一批训练样本输入模型,输出对应的预测值。
损失计算:利用损失函数量化预测输出与真实标签之间的偏差。
反向传播:从损失值出发,沿网络反向计算各参数的梯度。
参数更新:优化器依据梯度信息,调整所有权重与偏置(即参数)。
上述步骤持续迭代,直至模型性能满足预期目标,训练即告完成。
再来看数据并行。
数据并行是大模型训练中最普遍采用的并行策略(同样适用于推理阶段)。
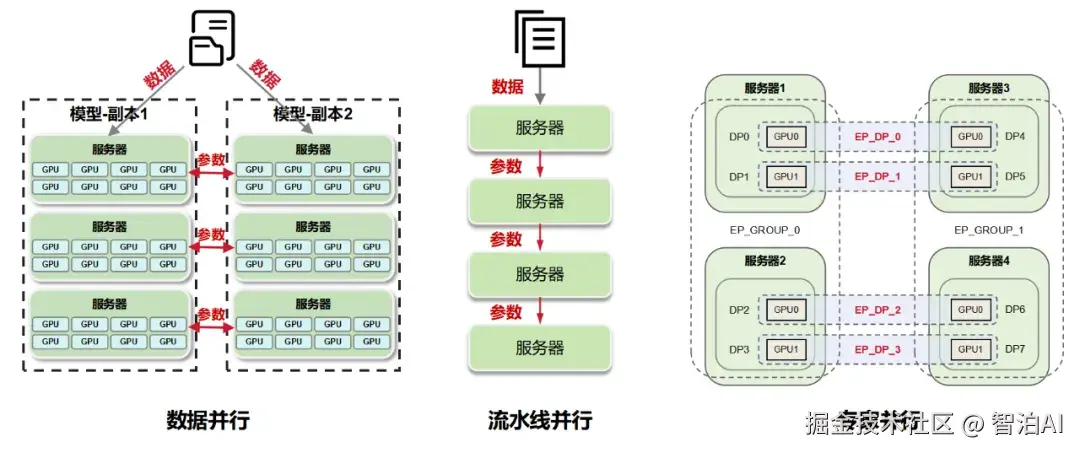
其核心理念极为直接:每个GPU均保存一份完整的模型副本,训练数据则被切分为若干小批次(mini-batch),每个批次独立分配至不同GPU并行运算。
在数据并行框架下,大模型的训练流程如下:
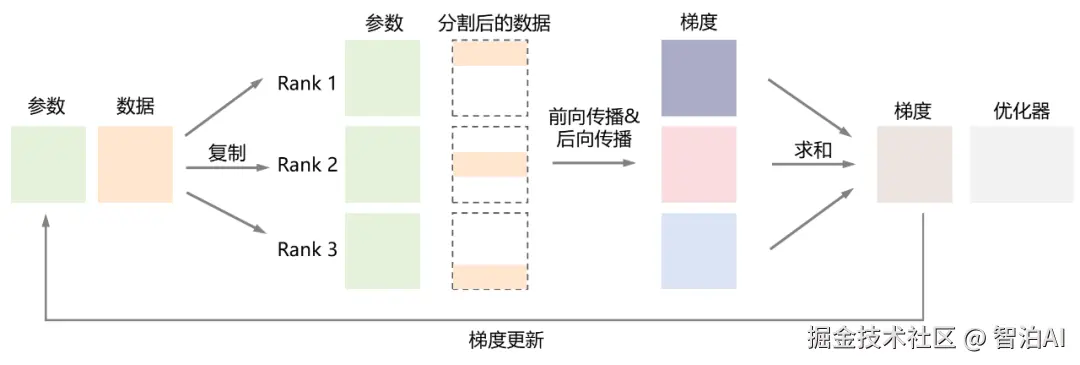
将训练数据均匀分割,分发至多个并行运行的GPU(Worker)上;
每个GPU均持有完全相同的模型架构与参数副本,独立执行前向传播与反向传播,独立计算局部梯度;
各Worker GPU通过节点间通信,采用All-Reduce机制,将本地梯度聚合至一个中心化GPU(Server);
Server GPU对收拢的所有梯度执行求和或均值运算,生成全局梯度;
Server GPU将全局梯度通过broadcast广播方式,同步回传至每一个Worker GPU,用于更新本地模型权重;更新完成后,所有Worker的模型参数实现严格一致。
随后,该流程循环迭代,直至训练任务完成。
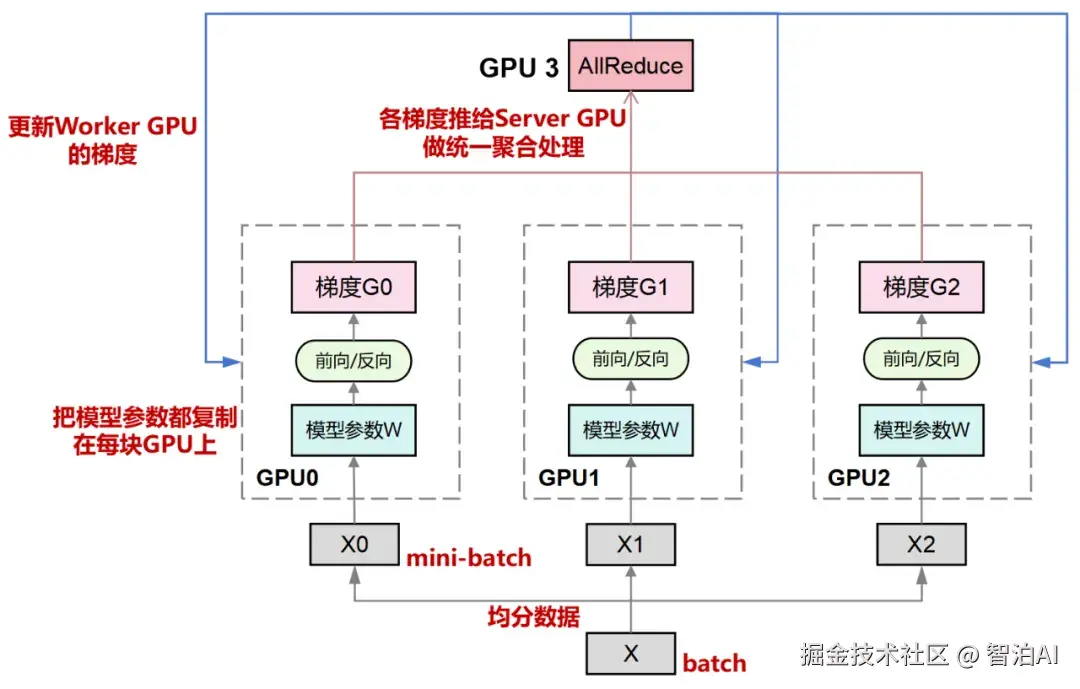
All-Reduce 是人工智能领域中一个广为人知的概念,其字面含义为"全(All)-规约(Reduce)",指对各个节点上的数据执行聚合操作(如求和、取最大值),并将聚合后的结果广播至所有节点。
数据并行 的主要优势在于其架构实现相对简洁,能有效提升大规模数据训练的效率,尤其在数据规模远超模型参数量的场景下表现突出。
数据并行 的局限性体现在显存消耗上:每个 GPU 均需加载完整的模型副本,随着模型参数规模持续扩大,所需显存随之增长,极易突破单张 GPU 的显存容量上限。
数据并行 的通信成本同样显著:各 GPU 间需高频同步模型参数或梯度信息;模型参数量越大、参与训练的 GPU 数量越多,通信负担越重。
例如,在 FP16 精度下,千亿参数模型的单次梯度同步需传输约 2TB 数据。
二、ZeRO
这里要插播一个关键概念------ZeRO(Zero Redundancy Optimizer,零冗余优化器)。
在传统数据并行训练中,每个GPU都完整保存模型的全部副本,导致显存消耗巨大。那么,有没有办法让每个GPU仅持有模型的一部分呢?
当然可以。这正是ZeRO的核心思想:将模型副本中的优化器状态、梯度与参数进行分布式切分,从而显著降低单卡内存负担。
ZeRO共包含三个递进阶段:
ZeRO-1:仅对优化器状态进行分片
ZeRO-2:在ZeRO-1基础上,进一步切分梯度
ZeRO-3:全面切分优化器状态、梯度与参数(显存效率最高)
通过下面的图和表,可以看得更明白些:
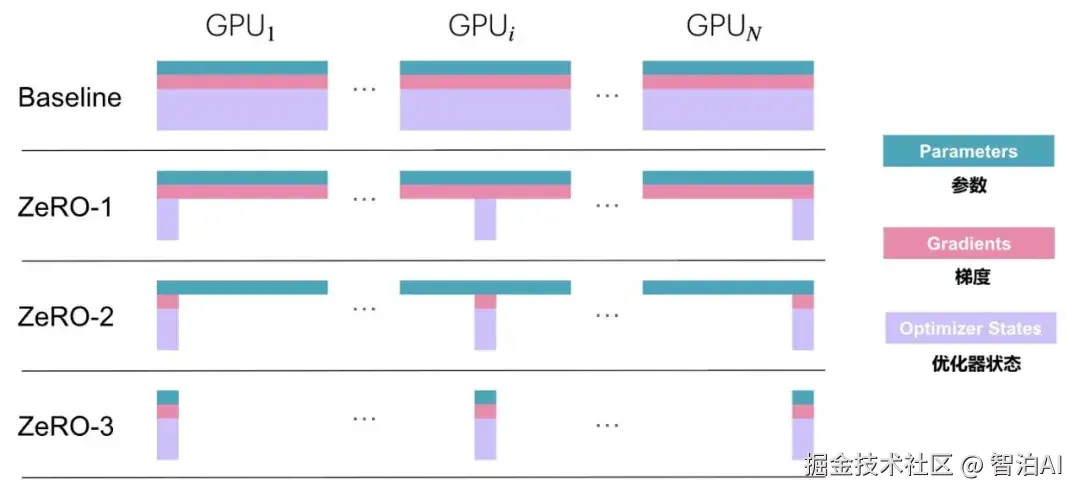
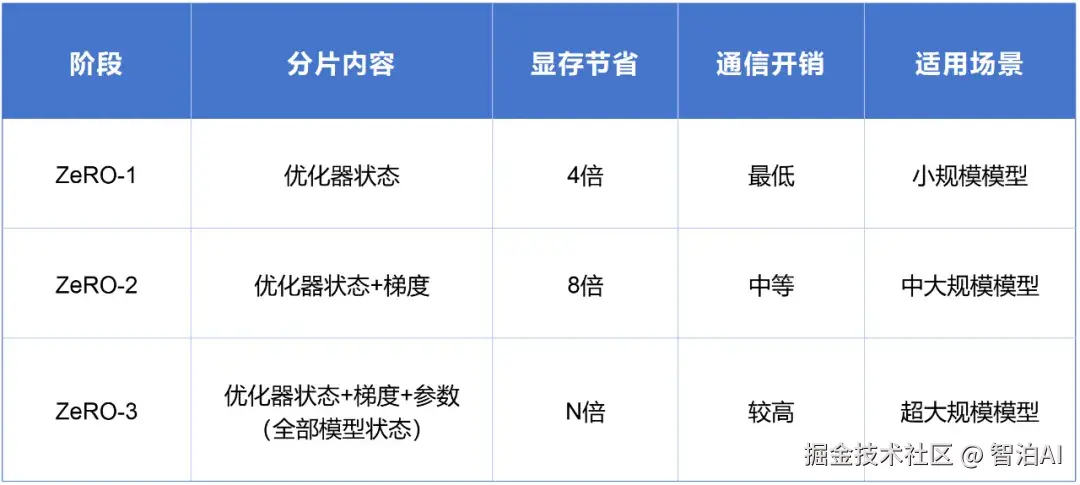
根据实测数据,当使用1024块GPU训练万亿级参数模型时,ZeRO-3将单卡显存占用从7.5TB大幅压缩至7.3GB。
数据并行(DP)的进阶形态为DDP(分布式数据并行)。
传统DP主要适用于单机多卡环境,而DDP则兼具单机与多机部署能力,其核心在于Ring-AllReduce通信机制。
该技术由百度率先提出,能有效缓解数据并行场景下因服务器节点导致的通信负载不均衡问题。
三、PP(流水线并行)
再来看看模型并行。
之前讲过数据并行,是将数据切分成多个分片。而模型并行,顾名思义,是把模型本身拆分成若干部分,由不同的 GPU 分别执行各自负责的模块。
(提示:当前业界对"模型并行"这一术语的界定尚不统一,部分文献中甚至直接用"张量并行"来指代它。)
至于流水线并行,则是把模型的各层------无论是单层还是连续的多层------分布到不同 GPU 上,数据按层序依次传递,形成类似流水线的并行处理流程。
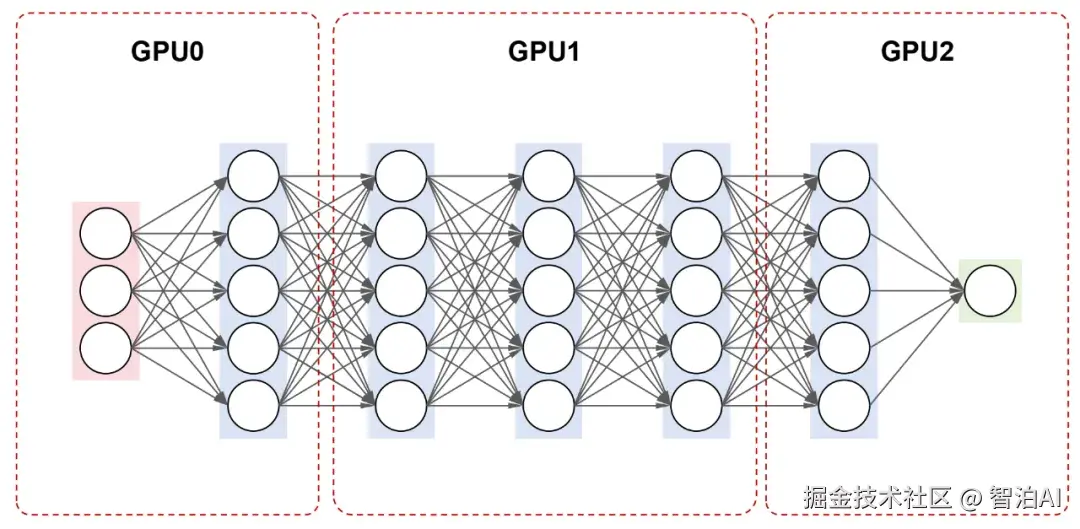
对于一个包含7层的神经网络,可将第12层分配至第一个GPU,第35层部署在第二个GPU,第6~7层置于第三个GPU;训练过程中,数据依序在各GPU间传递处理。
表面上,流水并行似乎呈现串行特性------每个GPU必须等待前序GPU完成计算后才能启动,由此可能引发显著的GPU资源闲置。
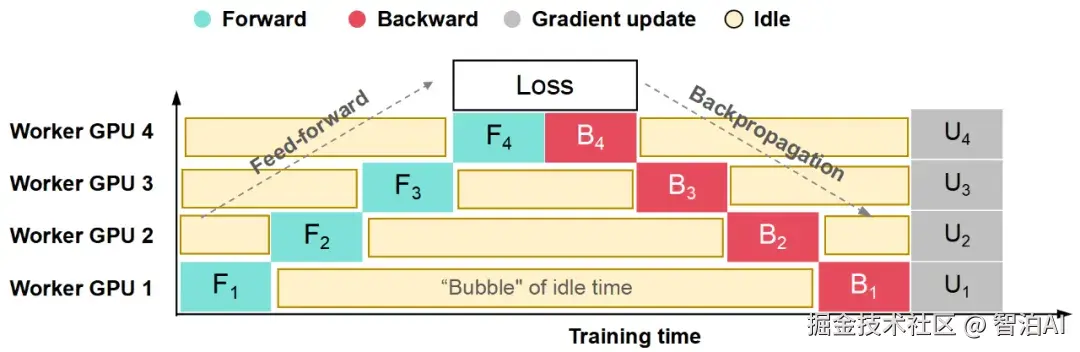
图中以黄色标识的区域即为 Bubble(气泡)时间。Bubble 越密集,表明 GPU 处于等待状态(即空闲)的时间越长,导致计算资源利用率下降。
为缓解此现象,可将单个 mini-batch 进一步划分为多个 micro-batch。
当 GPU 0 完成对当前 micro-batch 的计算后,无需等待,立即启动下一 micro-batch 的处理流程,从而有效缩短空闲间隙。
该优化策略的可视化效果如下图(b) 所示。
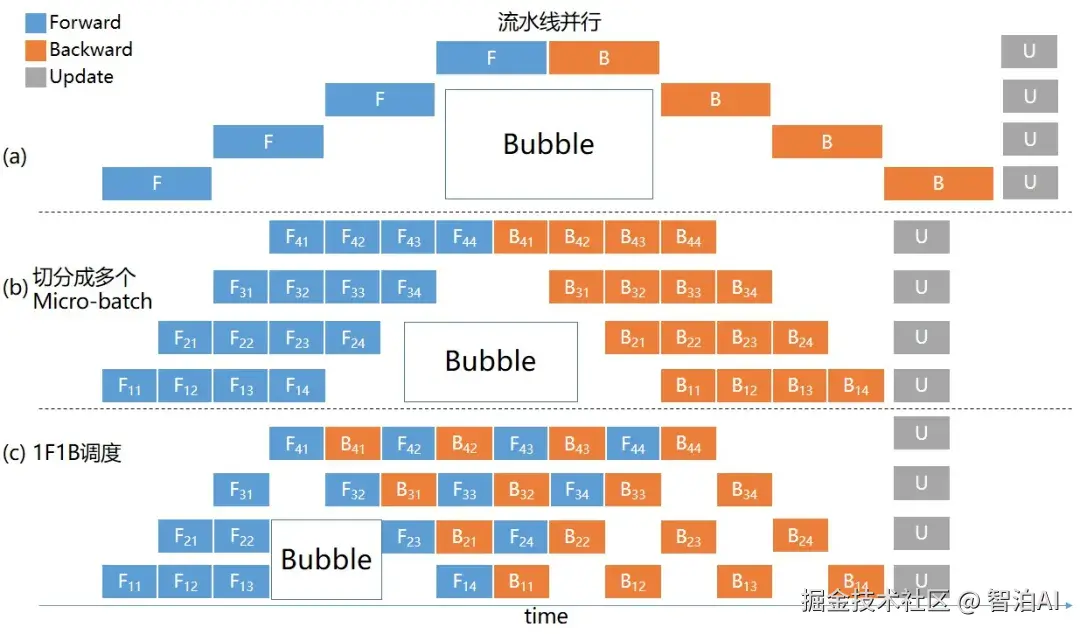
在完成一个 micro-batch 的前向计算后,立即调度对应的反向计算,从而提前释放部分显存空间,用于加载后续数据,进而提升整体训练效率,如上图(c)所示。
上述策略可有效显著降低流水线并行中的 Bubble 时间。
在流水线并行框架下,必须对任务调度与数据传输实施精准控制,否则将引发流水线停滞,并进一步加剧 Bubble 时间的产生。
四、 TP(张量并行)
模型并行的另一种形式称为张量并行。
若流水线并行是将模型逐层进行垂直拆分,那么张量并行则是对单层内部的特定运算实施横向切分。
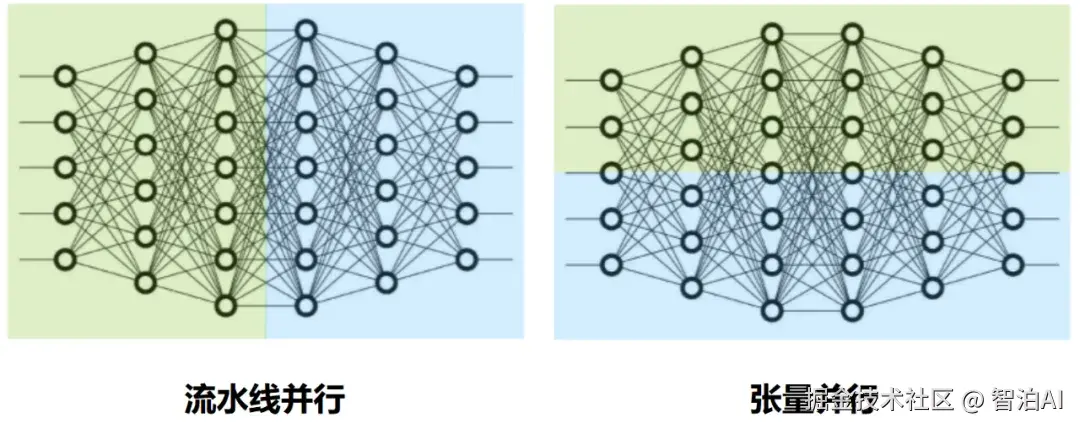
张量并行是一种将模型中的张量(如权重矩阵)依据维度划分至多个GPU上并行计算的策略。
其切分机制主要包含两种:行切分(Row Parallelism),即权重矩阵沿行方向分割;以及列切分(Column Parallelism),即权重矩阵沿列方向分割。
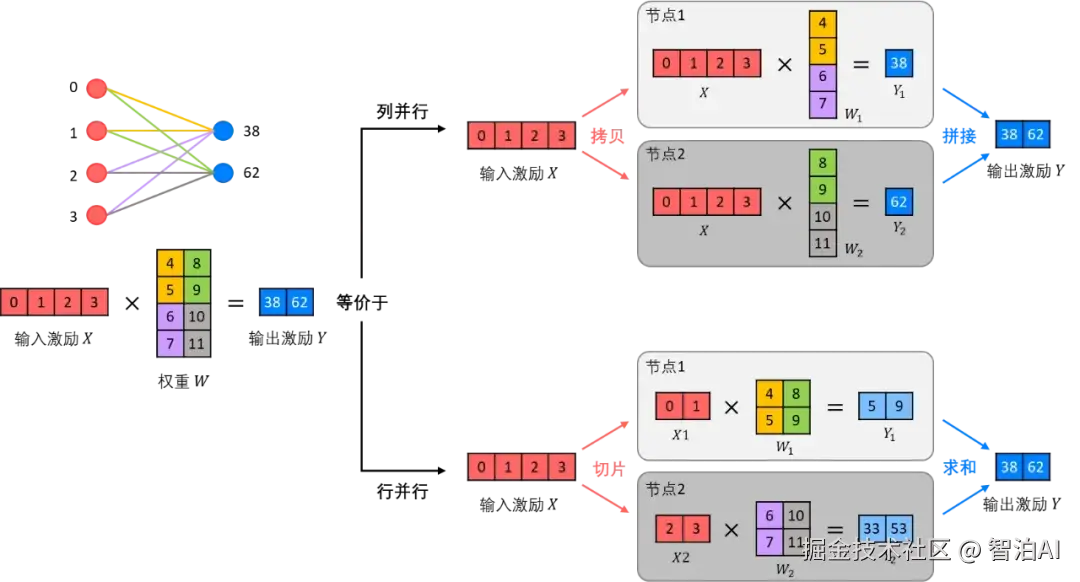
每个节点处理切分后的子张量。最后,通过集合通信操作(如All-Gather或All-Reduce)来合并结果。
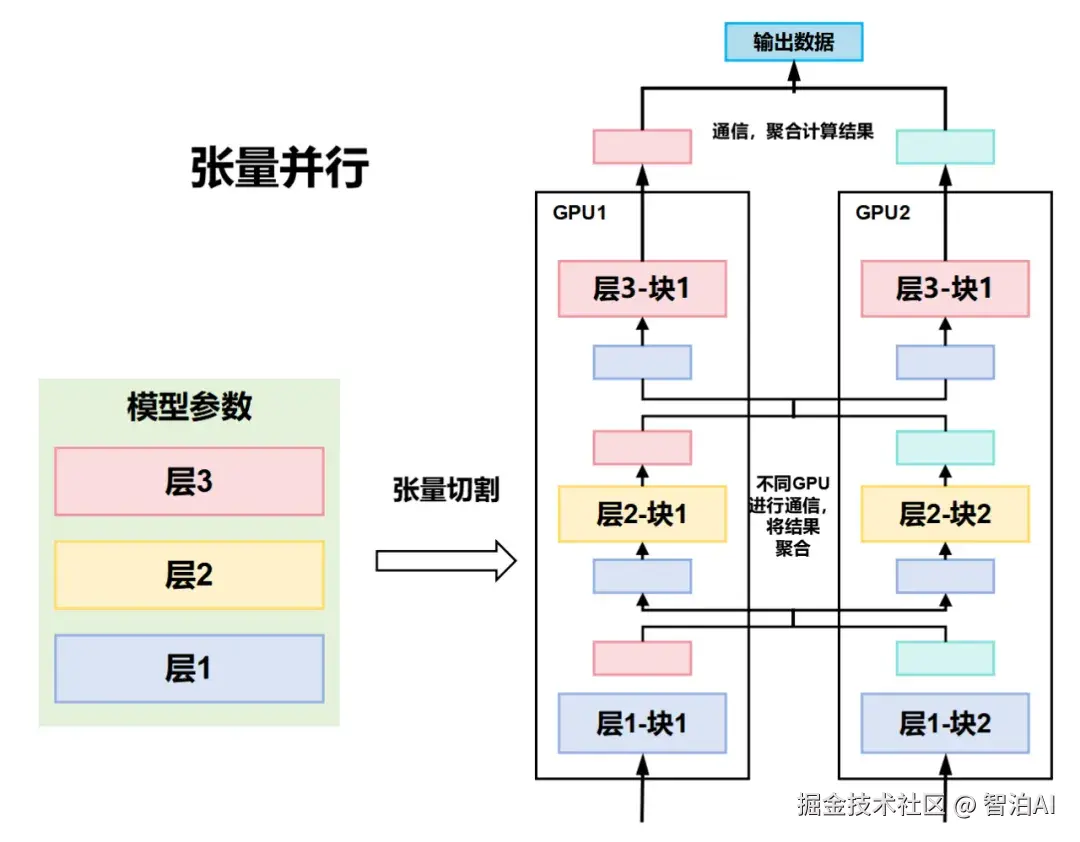
张量并行的优势在于应对单个张量规模过大的场景,能有效降低单节点的内存压力。
张量并行的局限在于,随着切分维度的增加,节点间的通信成本显著上升;同时,其工程实现难度较高,需精心规划张量切分策略与通信协调机制。
数据并行、流水线并行、张量并行的简单对比:
五、专家并行
2025年初,随着DeepSeek的走红,一个术语也随之迅速升温------MoE(Mixture of Experts,混合专家模型)。
MoE模型的精髓在于"多个专家层"与"路由网络(门控网络)"的协同运作。
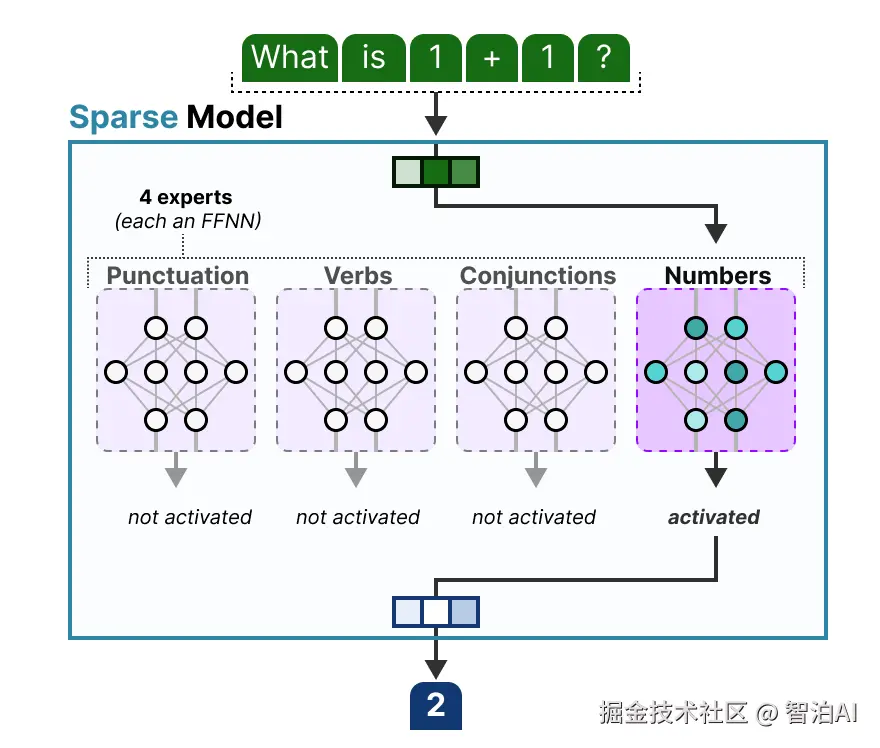
专家层中,每位专家专精于处理某一类token(如语法、语义等)。路由网络依据输入token的特征,动态筛选出少数专家进行激活处理,其余专家保持休眠状态。
MoE通过明确的任务分工与按需调度算力,显著提升了模型的整体运行效率。
专家并行(Expert Parallelism)是MoE(混合专家模型)中的一种并行计算范式,其核心在于将各专家(子模型)部署于不同的GPU节点,从而实现计算负载的分布式承载,优化资源利用率。
相较于传统并行方式,专家并行的根本差异在于:输入数据需经由动态路由机制分发至对应的专家,这一过程引发全节点范围内的数据重分配。
待所有专家完成处理后,必须将分布在各节点的输出结果,严格按照原始输入序列进行重组与归位。
这种跨设备的数据交换模式,被定义为All-to-All通信。
专家并行机制易受负载不均的制约:若某专家接收的token数量超出其处理容量,将导致部分Tokens无法及时处理,进而形成系统瓶颈。
因此,构建高效、均衡的门控机制与专家选择策略,是成功部署专家并行架构的核心前提。
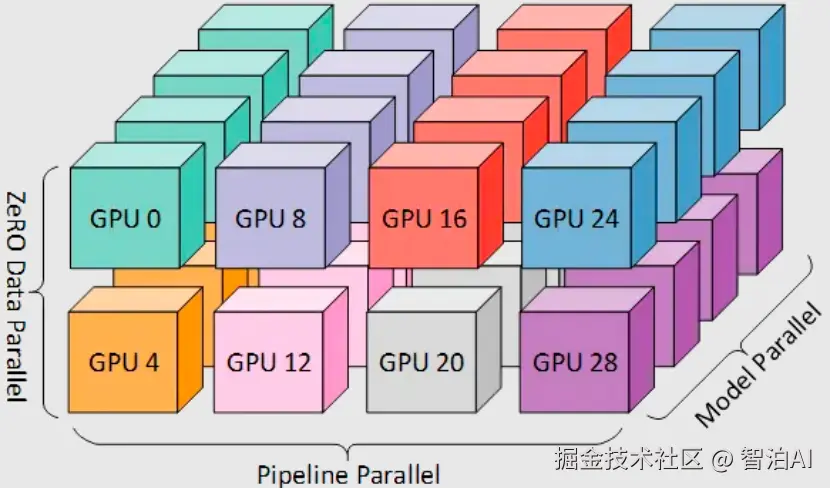
六、混合并行
在实际部署中,尤其是在训练参数规模达万亿级别的超大规模模型时,单一并行方式几乎从不独立使用,取而代之的是融合多种机制的混合并行架构(即协同运用多种并行技术)。
例如:
数据并行 + 张量并行:数据并行负责分发训练批次,张量并行则分解单个样本的巨型张量运算。
流水线并行 + 专家并行:流水线并行将模型按层切分,专家并行则对每一层内的稀疏专家模块进行独立划分。
更进一步的优化形态是 3D并行,即通过"数据并行 + 张量并行 + 流水线并行"的三维协同拆分,实现计算负载的立体化均衡,已成为当前万亿级模型训练的标准化范式。
最后
以上就是关于DP、PP、TP、EP等并行训练方式的介绍。
并行计算的复杂性远超表面所见,前述内容仅触及皮毛。然而在实际工程中,开发者无需深究底层实现机制。
得益于 DeepSpeed(微软开源,支持3D并行+ZeRO内存优化)、Megatron-LM(NVIDIA开源,3D并行的标杆)、FSDP 等成熟开源框架,大语言模型的训练已可直接高效开展。
不同并行策略呈现出迥异的通信模式。要最大化训推效率,集群的整体架构与网络规划,必须精准匹配各类并行方式的流量特征。
数据并行:因需高频同步梯度参数,对网络带宽构成持续高压,必须保障链路具备支撑海量梯度数据瞬时吞吐的能力,否则通信瓶颈将直接拖慢训练节奏。
流水线并行:模型分段在多台服务器间流水线式推进,节点间依赖紧密,宜集中部署于同一叶脊网络的叶节点(leaf)下,以最小化跨机通信延迟。
张量并行:通信开销极高,数据切分频繁,最佳实践是将计算负载集中于单台服务器内的多个 GPU 之间,利用高速互联总线降低通信开销。
专家并行:各专家模块分布于不同 GPU,其间需频繁交换中间激活值,其通信强度由专家数量与交互频次共同决定,必须精细设计 GPU 互联拓扑与数据通路。
综上,在 GPU 单卡算力逼近物理极限的当下,唯有从并行计算的架构与网络层面持续深挖,方能突破性能瓶颈,释放算力集群的真正潜能。