随着互联网的快速发展,网络数据已成为重要的信息资源。我们需要通过网络来补充和完善知识库知识。
网络数据采集(Web Scraping)是指从网页中提取有用信息的过程。Python 凭借其丰富的库(如 Requests、BeautifulSoup、Scrapy 、selenium 等),成为网络数据采集的首选工具。
爬虫(crawler)也经常被称为网络蜘蛛 (spider),是按照一定的规则自动浏览网站并获取所需信息的机器人程序(自动化脚本代码),被广泛的应用于互联网搜索引擎和数据采集。
基本工作流程
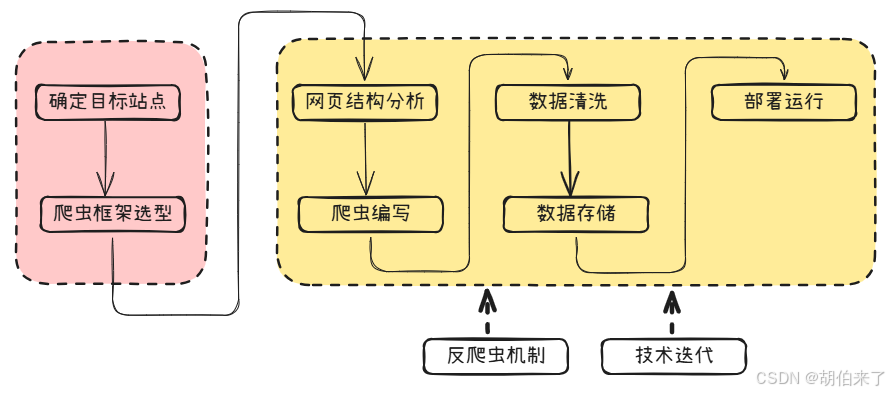
-
确定目标网站
在进行全网数据采集之前,首先需要确定目标网站。可以选择一些常见的搜索引擎、社交媒体等平台进行数据采集。对于一些需要登录才能访问的网站,可以使用
Selenium等工具模拟登录。 -
选择合适的爬虫框架
选择合适的爬虫框架可以大大提高数据采集效率。常用的爬虫框架有
Scrapy、Beautiful Soup、Requests等。其中Scrapy是一个功能强大且灵活的爬虫框架,支持异步处理和分布式部署;Beautiful Soup则是一个HTML/XML解析器,可以方便地从HTML中提取数据;Requests则是一个HTTP库,可以方便地发送HTTP请求和处理响应。 -
分析网页结构
在进行数据采集之前,需要对目标网站的网页结构进行分析。可以使用
Chrome浏览器的开发者工具或Firebug等工具查看网页源代码,并确定需要采集的数据所在的位置和标签。 -
编写爬虫程序
在确定目标网站和分析网页结构之后,可以开始编写爬虫程序。首先需要根据目标网站的
robots.txt文件了解其爬取规则,然后根据自己的需求编写相应的爬虫程序。在编写过程中,需要注意反爬虫机制,可以设置User-Agent、Referer等HTTP头信息来模拟浏览器行为,以及使用代理IP技术来规避IP封禁。 -
数据清洗和存储
在完成数据采集之后,需要对采集到的数据进行清洗和整理。可以使用
pandas等库将数据转换为DataFrame格式,并进行数据清洗、去重、缺失值处理等操作。最后可以选择将数据存储到文件或数据库中。 -
多线程和分布式部署
随着数据量的增加,单线程爬虫程序已经无法满足需求。可以使用多线程或协程技术来提高爬虫程序的效率。同时,分布式部署也是一个不错的选择,可以使用
Redis等工具来实现分布式爬虫。 -
反爬虫机制
为了防止被目标网站封禁
IP,需要注意反爬虫机制。可以使用随机User-Agent、延时请求、代理IP等技术来规避反爬虫机制。同时也需要注意不要频繁地请求同一个页面,以免给服务器造成过大的负担。 -
常见问题和解决方案
在进行数据采集时,常常会遇到各种问题,如网页乱码、无法获取数据等。这时候可以使用一些常见的解决方案,如设置编码方式、使用正则表达式等技术。
基本网络请求 - Requests
requests 是 Python 中最流行的 HTTP 客户端库,以简洁的 API 设计和强大的功能著称。帮我们轻松打开与外部世界交互的大门,无论是获取网页内容、与 API 交互,还是处理各种网络请求,requests 都能以它简洁而强大的方式为我们提供服务。
requests 模块是 Python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作。
request 构造方法
-
输入参数
-
method: 指定Http的请求方法,可能值:GET,OPTIONS,HEAD,POST,PUT,PATCH, orDELETE。 -
url: 指定请求的链接地址。 -
params: 【可选 】dict类型,请求参数字典,该参数值通过Query的方式传入 。 -
data:【可选 】dict类型,请求参数字典,该参数值通过Body的方式传入。 -
json:【可选 】序列化的JSON格式对象,该参数值通过Body的方式传入。 -
headers:【可选 】dict类型,设置请求头参数。 -
cookies: 【可选 】dict或CookieJar类型, 设置请求的Cookie。 -
files: 【可选 】dict类型,其中字典的键是上传的参数名,键的值是一个上传文件对象或者上传文件元组:可以是二元组(filename, fileobj)或三元组(filename, fileobj, content_type)或四元组(filename, fileobj, content_type, custom_headers);其中content_type的值为custom_headers,用来定义上传内容类型,附加到请求头的content_type中。 -
auth: 【可选 】 设置认证方法,以便启用Basic或Digest或 其他自定义的认证方法。 -
timeout: 【可选 】float或 一个三元组(connect timeout, read timeout)定义请求的超时时间。 -
allow_redirects:【可选 】bool类型,是否允许重定向,True为允许,默认为True。 -
proxies: 【可选 】dict类型,设置代理地址。 -
verify: 【可选 】bool或str类型;如果是布尔值,它确定我们是否验证服务器的TLS证书;如果是字符串,它必须是使用的CA bundle的路径。默认为True -
stream: 【可选 】bool型;如果设为False,响应将以流的方式下载。 -
cert: 【可选 】str类型或元组。如果是str类型,则表示指向SSL客户端证书文件路径;如果是原则,则是键值对(('cert', 'key'))。
-
-
输出参数
Response对象实例
get 方法
-
输入参数
-
url: 指定请求的链接地址。 -
params: 【可选 】dict类型,请求参数字典,该参数值通过Query的方式传入 。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
options 方法
-
输入参数
-
url: 指定请求的链接地址。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
head 方法
-
输入参数
-
url: 指定请求的链接地址。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
post 方法
-
输入参数
-
url: 指定请求的链接地址。 -
data:【可选 】dict类型,请求参数字典,该参数值通过Body的方式传入。 -
json:【可选 】序列化的JSON格式对象,该参数值通过Body的方式传入。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
put 方法
-
输入参数
-
url: 指定请求的链接地址。 -
data:【可选 】dict类型,请求参数字典,该参数值通过Body的方式传入。 -
json:【可选 】序列化的JSON格式对象,该参数值通过Body的方式传入。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
patch 方法
-
输入参数
-
url: 指定请求的链接地址。 -
data:【可选 】dict类型,请求参数字典,该参数值通过Body的方式传入。 -
json:【可选 】序列化的JSON格式对象,该参数值通过Body的方式传入。 -
kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
-
输出参数
Response对象实例
delete 方法
-
输入参数
url: 指定请求的链接地址。kewargs: 【可选 】dict类型,参数键值对,可选的参数参见构造方法中的输入参数。
-
输出参数
Response对象实例
应用案例
请求
假定我们要请求的链接是 https://latest.news.com,则:
import requests
from lxml import etree
res = requests.get("https://latest.news.com", headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"
})内容抽取
请求成功后,我们来提取响应头:
for head in res.headers:
print(head, ":", res.headers[head])结果:
Date : Mon, 02 Jun 2025 04:30:18 GMT
Content-Type : text/html
Transfer-Encoding : chunked
Connection : keep-alive
Server : nginx
Content-Encoding : gzip
X-Via : 1.1 PS-CZX-01gfA163:7 (Cdn Cache Server V2.0), 1.1 PS-CZX-01YIQ141:12 (Cdn Cache Server V2.0), 1.1 PS-TSN-01fNz95:16 (Cdn Cache Server V2.0)
x-ws-request-id : 683d28da_PS-TSN-01fNz95_17318-41841现在,我们开始来处理页面内容,数显将获取到响应重新编码(访问的站点返回的内容使用 gb2312 编码):
res_text = res.text.encode(res.encoding).decode("gb2312")
root = etree.HTML(res_text)解码后获取如下内容体(节选):
<html lang="en">
<head>
<meta charset="gb2312">
<title>
社会_
新闻频道_中国青年网
</title>
...
</head>
<body>
...
<ul>
<li>
<div class="title_txt">
<p class="title">
<a href="//news.youth.cn/sh/202506/t20250601_16034915.htm" target="_blank">这些年轻人去小镇当"戏漂"</a>
</p>
<span class="date fr">2025-06-01</span>
</div>
</li>
<li>
<div class="title_txt">
<p class="title">
<a href="//news.youth.cn/sh/202506/t20250601_16034914.htm" target="_blank">37个北大学生打造游戏:在鲜活的近现代史中感悟青春</a>
</p>
<span class="date fr">2025-06-01</span>
</div>
</li>
<li>
<div class="title_txt">
<p class="title">
<a href="//news.youth.cn/sh/202506/t20250601_16034913.htm" target="_blank">扰乱市场秩序 加大患病风险 警惕披上"甜蜜外衣"的五彩香烟</a>
</p>
<span class="date fr">2025-06-01</span>
</div>
</li>
<li>
<div class="title_txt">
<p class="title">
<a href="//news.youth.cn/sh/202505/t20250531_16034386.htm" target="_blank">河北武邑县一化工企业车间发生煮洗釜爆炸 已致5死2伤</a>
</p>
<span class="date fr">2025-05-31</span>
</div>
</li>
</ul>
...
</body>
</html>为了方便,对返回的内容做了处理,只留下我们要操作的部分。现在我们来读取页面标题:
# 获取标题
print("标题:", root.xpath('//title/text()'))输出:
标题: ['\n 社会_\n 新闻频道_中国青年网\n ']接着,我们来读取新闻列表:
news = root.xpath('//p[@class="title"]/a')
for item in news:
print("新闻标题:", item.text)
print("新闻链接:", item.get("href"))输出:
新闻标题: 这些年轻人去小镇当"戏漂"
新闻链接: //news.youth.cn/sh/202506/t20250601_16034915.htm
新闻标题: 37个北大学生打造游戏:在鲜活的近现代史中感悟青春
新闻链接: //news.youth.cn/sh/202506/t20250601_16034914.htm
新闻标题: 扰乱市场秩序 加大患病风险 警惕披上"甜蜜外衣"的五彩香烟
新闻链接: //news.youth.cn/sh/202506/t20250601_16034913.htm
新闻标题: 河北武邑县一化工企业车间发生煮洗釜爆炸 已致5死2伤