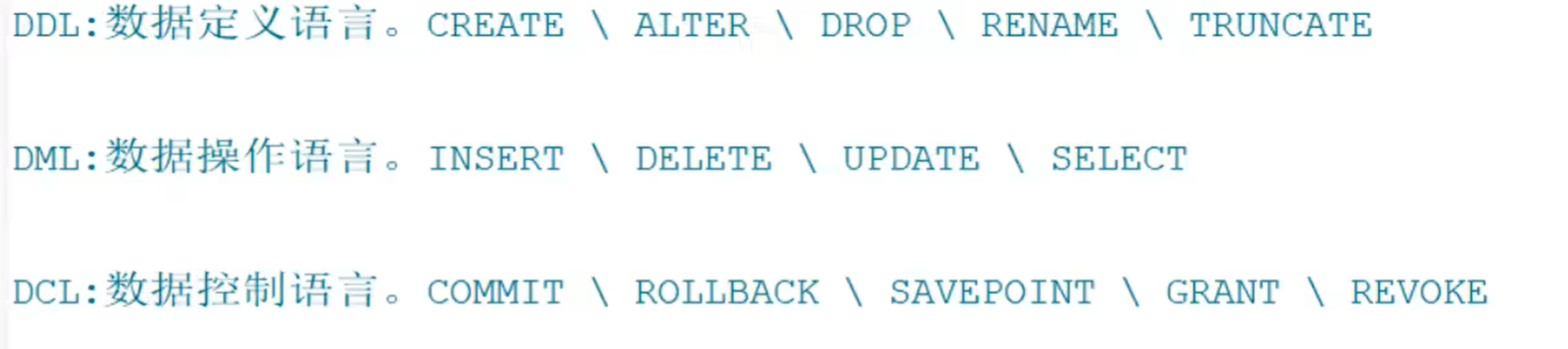
SQL分类:

SQL的规则和规范:
基本规则:
1.SQL可以写在一行或多行。为了提高可读性,各子句分行写,必要时使用缩进
2.每条命令以;或\g或\G结束
3.关键字不能被缩进,也不能被分行
4.关于标点符号:
必须保证所有(),"",{}都是成对出现的
必须使用英文格式下的半角输入方式
字符串型和日期时间类型可以用单引号(' ')表示
列的别名,尽量使用双引号(" "),而且不建议省略as

注释:
单行注释:#
和C语言和Java不一样,SQL的单行注释是#
多行注释:/*
*/
多行注释是和Java一样的

数据的导入:

方式二:直接使用navicat中的导入,然后导入文件
基本SELECT语句:
#SELECT语句
SELECT 1 + 1,2*3;
#FROM DUAL;#这个dual是伪表,就是为了保持这个SELECT 字段1,字段2,......FROM 表名的结构。
*:表中所有的字段(或列)
#SELECT语句
SELECT 1 + 1,2*3;
#FROM DUAL;#这个dual是伪表,就是为了保持这个SELECT 字段1,字段2,......FROM 表名的结构。
# *:表中所有的字段(或列)
SELECT * FROM dbtest1;
# 如果想看具体的字段,就写出来
SELECT dbtest1_
FROM dbtest1;
列的别名:

去除重复行:

使用distinct关键字

空值参与运算:

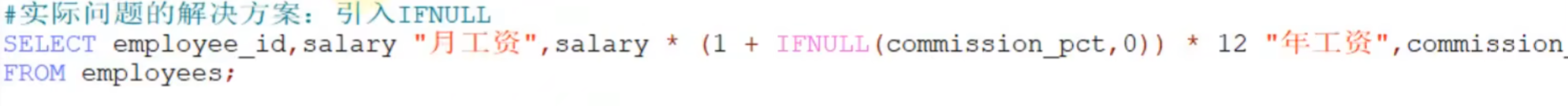
着重号:

如果表名和关键字同名了,就要使用着重号
查询常数:

就是把这个单引号中的当成常数,给每条数据都赋上这个值

显示表结构:

使用describe关键字,或者DESC
过滤数据:

使用where关键字,后面写的作为筛选条件,而且where一定要写在from后面,紧挨着FORM

字符串用' ',这点和Java不一样
课后练习:
#基本的SELCET语句练习
#计算十二个月的工资
SELECT employee_id,last_name,salary * 12 * IFNULL(commission,0) AS "ANNUAL SALARY"
FROM employees;
#查询employees表中去除重复的jod_id后的数据
SELECT DISTINCT job_id
FROM employees;
#查询工资大于12000的员工姓名和工资
SELECT last_name,salary
FROM employees
WHERE salary > 12000;
#查询员工号为176的员工的姓名和部门号
SELECT last_name,department_id
FROM employees
WHERE employee_id = 176;
#显示departments的结构,并查询其中的全部数据
DESC departments
SELECT *
FROM employees;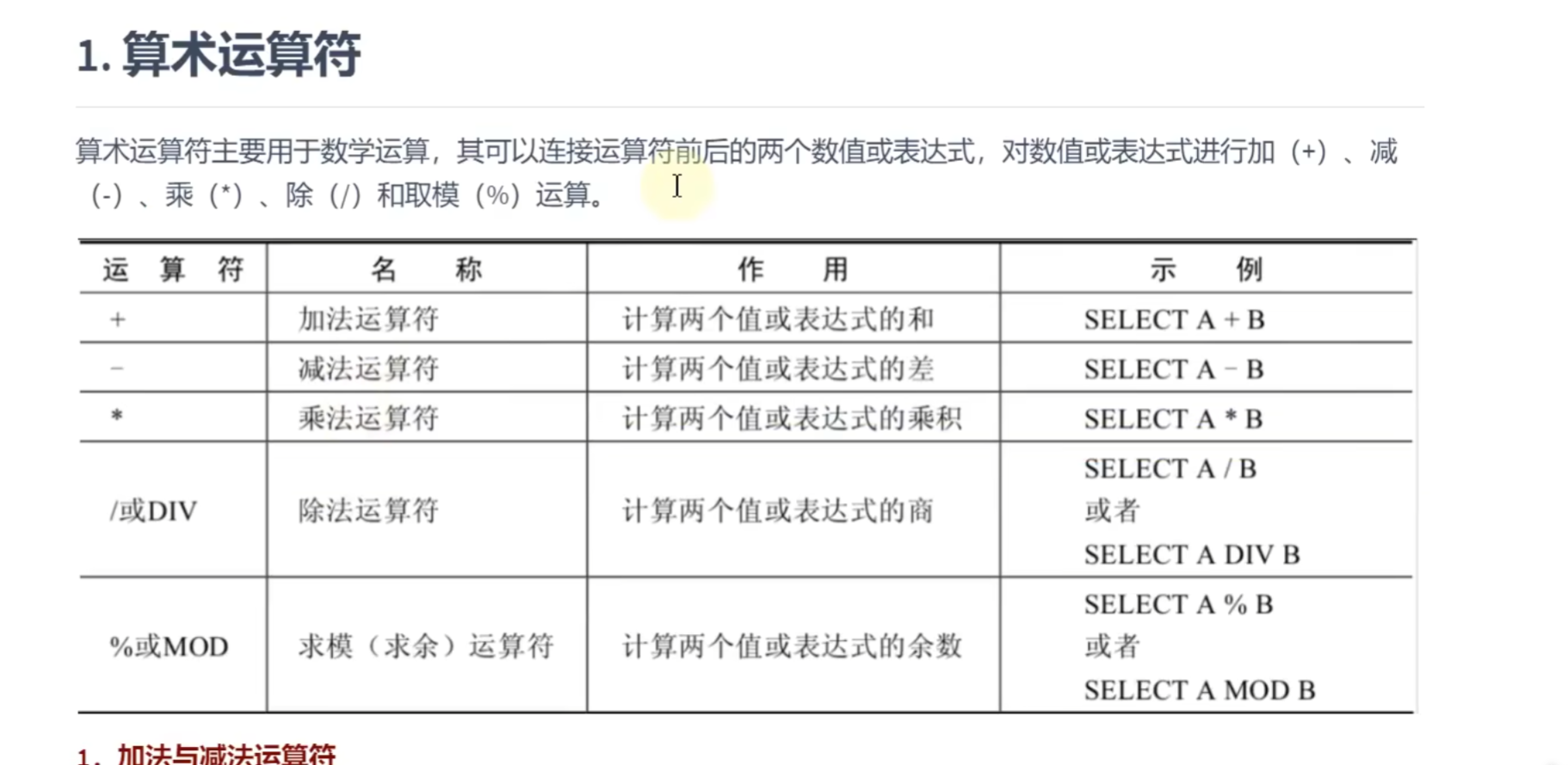
加减:


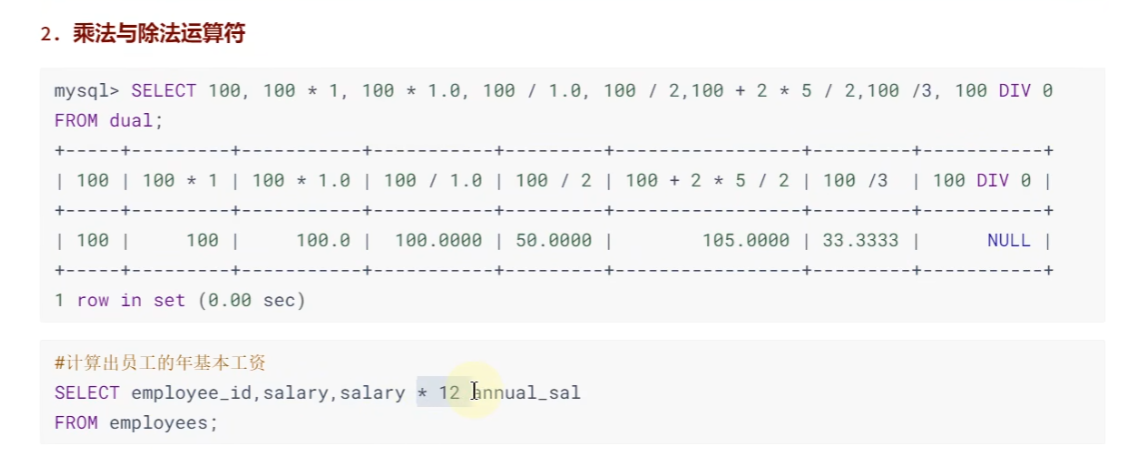
乘除:

取模:
取模得到的结果和分母位置上的符号相同,负号结果就是负的,正号就是正的
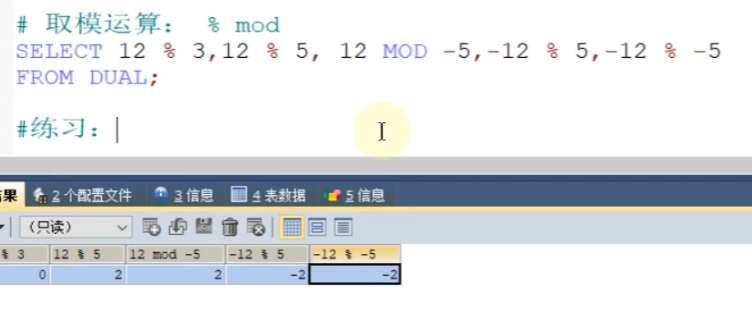
比较运算符:

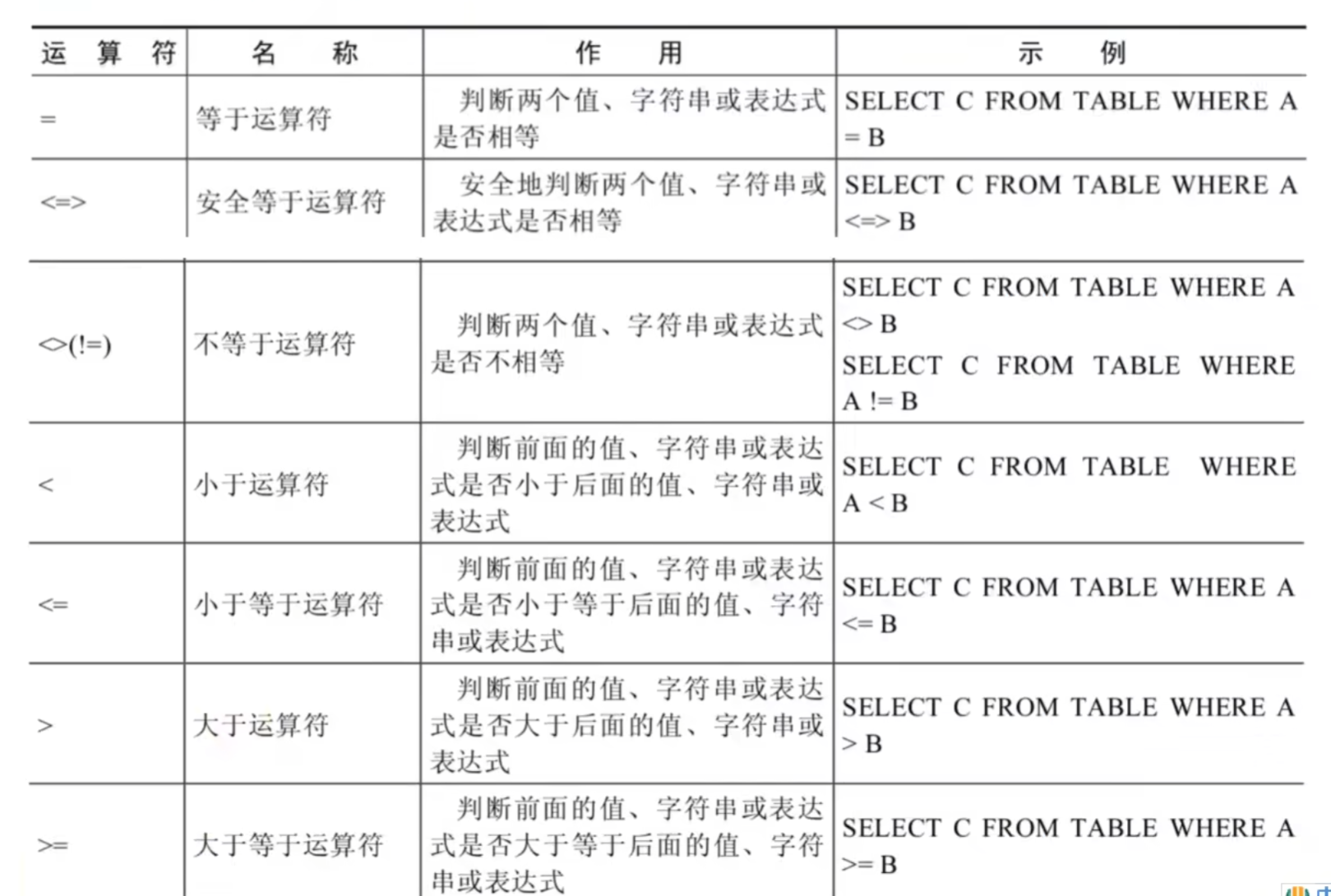
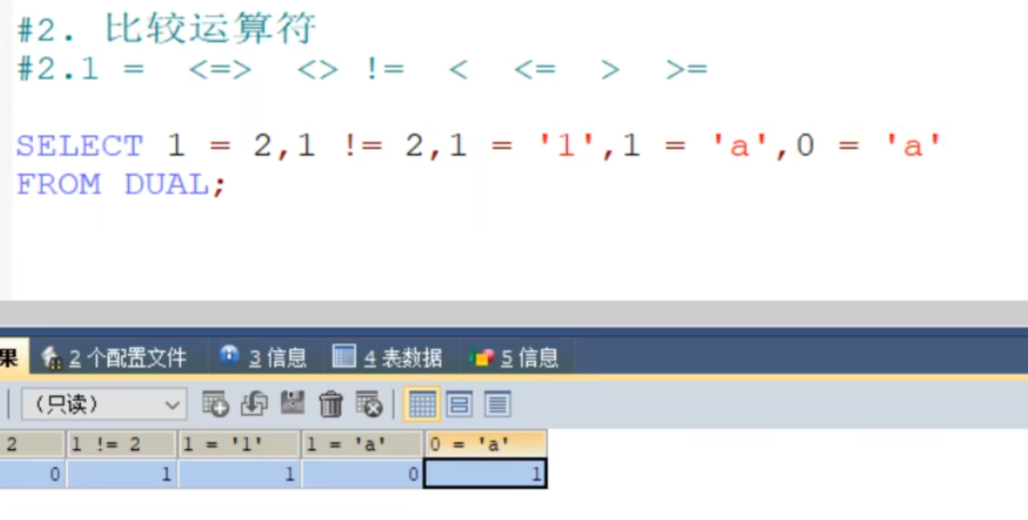
MySQL中真就是1,假就是0。
字符串和数字比较的时候会隐式转换成数字;如果转换不成功,就当成0.
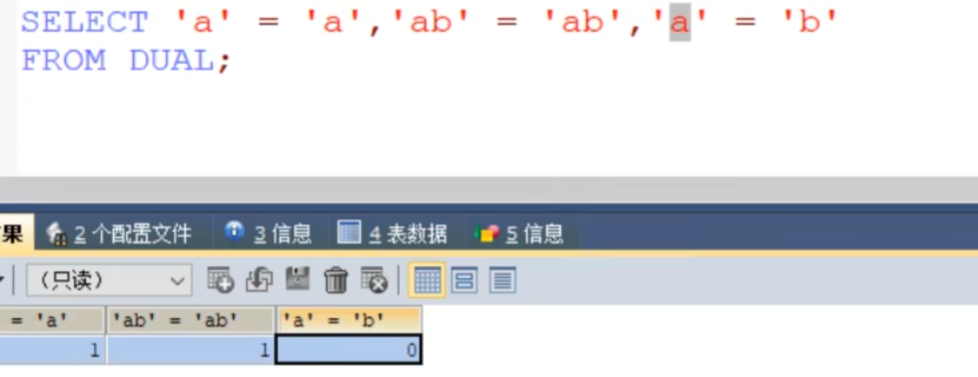
如果纯粹是字符串中字母和字母比较,那就直接用ASCII码比
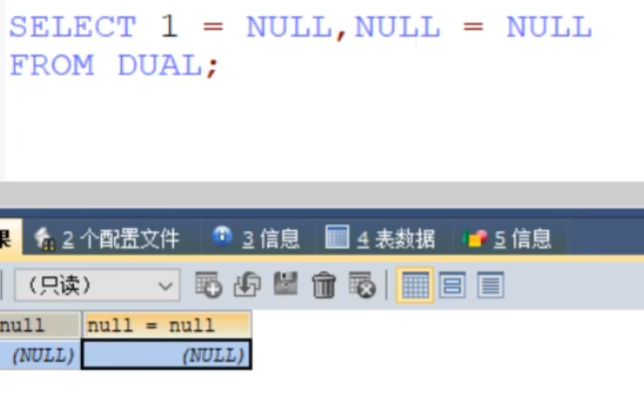
只要有null参与,结果就是null
安全等于:

非符号类型的比较运算符:
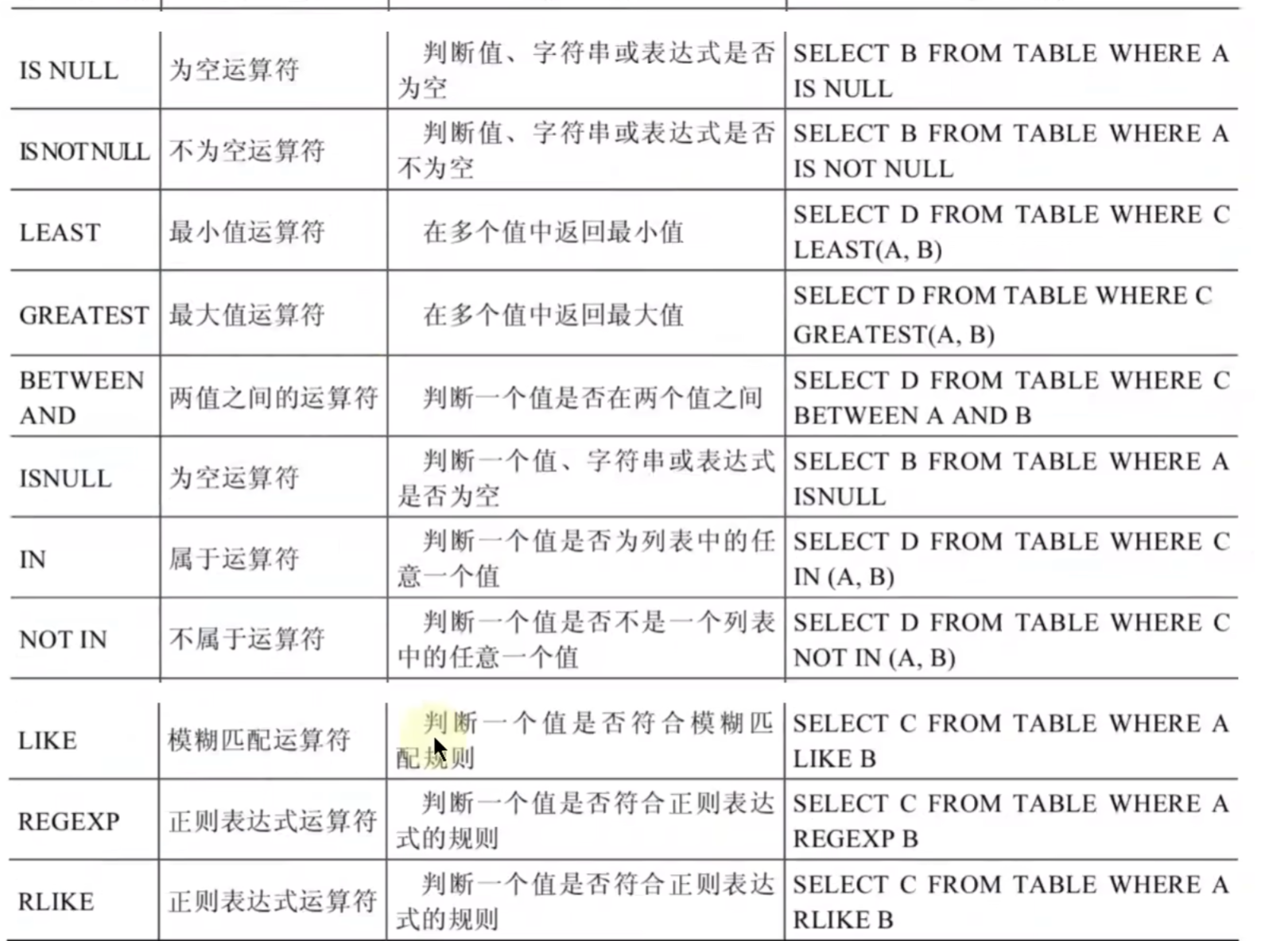
测试:
# IS NULL;ISNULL;IS NOT NULL
#IS NULL就是判断结果是null值的
#练习:查询表中commission_pct为null的数据有哪些
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NULL;
#IS NOT NULL就是判断结果不是Null值的
#练习:查询表中commission_pct不为null的数据有哪些
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
# ISNULL和IS NULL的效果差不多
#LEAST()和GREATEST()
#least()是最小,greateset()是最大
SELECT LEAST('a','d','c'),GREATEST('c','g','f','y')
FROM DUAL;
#BETWEEN...AND:取一个区间
#查询工资在6000到8000的员工信息
SELECT employee_id,first_name,last_nane,salary
FROM employees
WHERE salary between 6000 AND 8000;#必须小的在前,大的在后
#查询工资不在6000到8000的员工信息
SELECT employee_id,fist_name,last_name,salary
FROM employees
WHERE salary NOT between 6000 AND 8000;
#IN和NOT IN :IN是找值等于这个条件的信息,NOT IN就是找值不等于这个条件的信息
#查询部门为10,20,30部门的员工信息
SELECT last_name,salary,department_id
FROM employees
#WHERE department_id IN 10 OR department IN 20 OR department_id IN 30;
WHERE department_id IN (10,20,30);
# LIKE:模糊查询:查找达到某个条件的值
#查找名字里含有'a'的员工信息
# %:代表不确定个数的字符(0个,1个,多个),意思就是含有a的这条信息中,a前面有%代表a前面可以有不确定个数的字符,后面同理
SELECT last_name,salary,department_id
FROM employees
WHERE last_name LIKE '%a%';
#查找名字以a开头的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE 'a%';# a前面没有%,代表包含a的这条信息的前面没有不确定个数的字符,即以a开头
#查询名字里第二个字符是'a'的员工信息
# _:一个下划线代表一个不确定的字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_a%';
# 查询第2个字符是_且第三个字符是'a'的员工信息
# 这个需要使用转义字符:\
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%';
# REGEXP \ RLIKE:正则表达式
逻辑运算符:
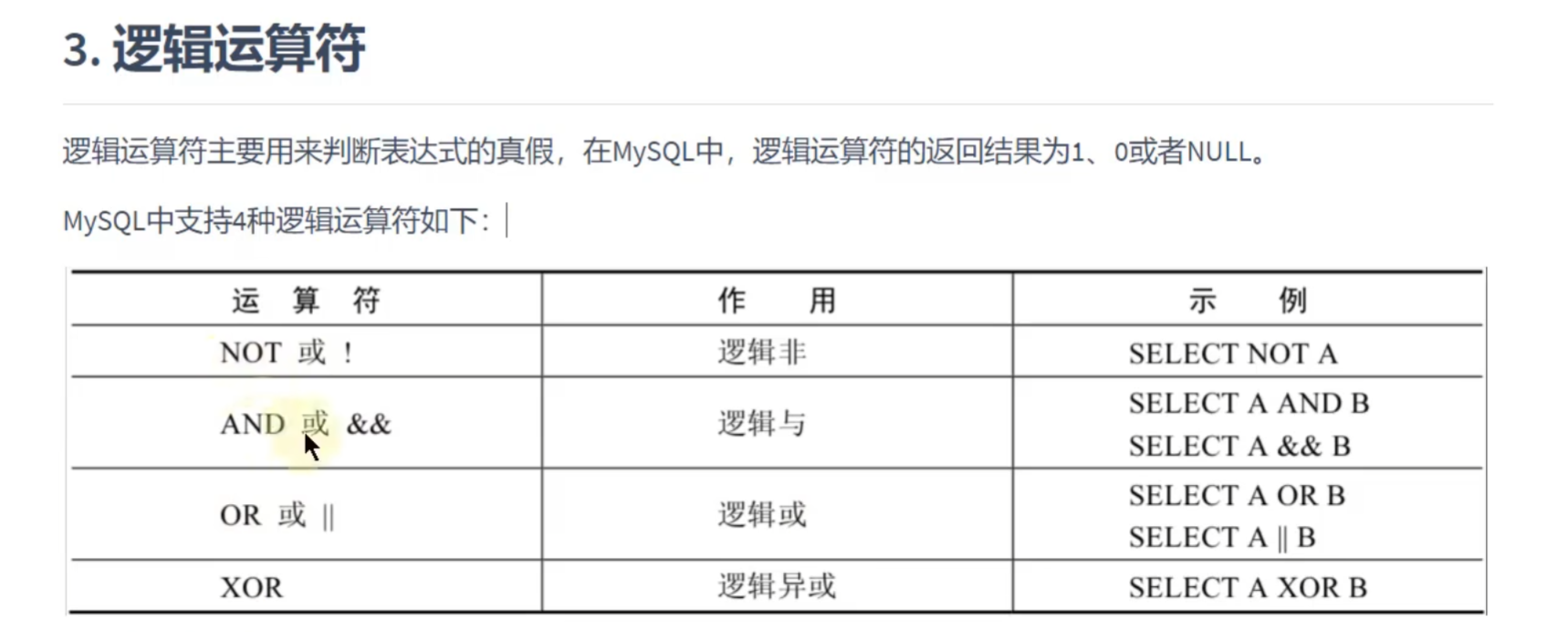
异或就是:两边都是1,那就是0;两边不一样,那就是1
和Java基本一样

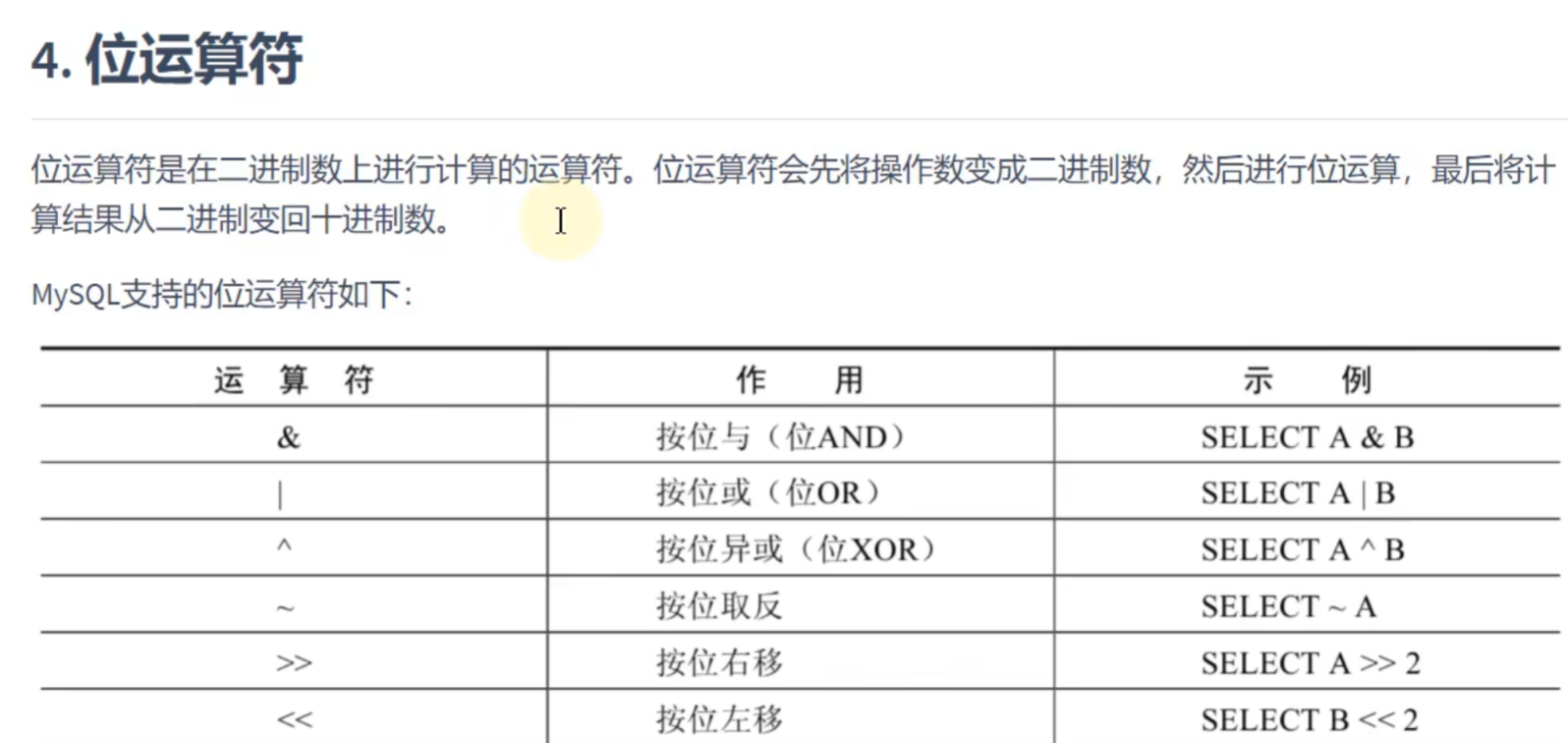
位运算符:
课后练习:
# 选择工资不在5000到12000的员工的姓名和工资
SELECT salary
FROM employees
WHERE salary NOT BETWEEN 5000 AND 12000;
# 查询在20或50号部门工作的员工姓名和部门号
SELECT first_name,department
FROM employees
# WHERE department IN (20,50);
WHERE department = 20 || department = 50;
# 选择公司中没有管理者的员工姓名及job_id
SELECT first_name,job_id
FROM employees
WHERE manager_id IS NULL;
# 选择公司中有奖金的员工姓名,工资和奖金级别
SELECT first_name,salary,commission_pct
FROM employee
WHERE commission_pct IS NOT NULL;
# 选择员工姓名的第三个字母是a的员工姓名
SELECT first_name
FROM employees
WHERE first_name LIKE '__a%';
# 选择姓名中有字母a和k的员工姓名
SELECT first_name
FROM employees
WHERE first_name LIKE '%a%' AND first_name LIKE '%K%';
# 选择表中以名字以e结尾的员工信息
SELECT first_name
FROM employees
WHERE first_name LIKE '%e';
# 显示出表中部门编号在80-100之间的姓名,工种
SELECT last_name,job_id
FROM employees
WHERE department BETWEEN 80 AND 100;
# 显示出表employees的manager_id 是100,101,110的员工姓名,工资,管理者id
SELECT last_name,salary,manager_id
FROM employees
WHERE manager_id IN (100,101,110);排序:
如果没有使用排序操作,默认情况下,查询返回的数据是按照添加数据的顺序显示的

可以使用列的别名进行排序,也就是说列的别名可以用在order by里,但是列的别名不能和WHERE一起用
WHERE要写在FORM之后,ORDER BY之前
# 使用 ORDER BY 对查询到的数据进行排序操作
# 升序:ASC
# 降序:DESC
# 练习:按照salary从高到低(降序)的顺序显示员工信息
SELECT salary,employee_id,last_name
FROM employees
ORDER BY salary DESC;#如果order by后没有显示指明排序的方式的话,则默认按照升序排列
#可以使用列的别名,进行排序
SELECT salary,employee_id,salary * 12 AS annual_sal
FROM employees
ORDER BY annual_sal ASC;
# 但是where中不能使用列的别名
# 强调格式:WHERE要写在FORM之后,ORDER BY之前二级排序:
在一级排序后,如果还有排序要求,就要用二级排序
#二级排序,用逗号隔开后接着写
#练习:显示员工信息,按照department_id降序排序,salary升序排序
SELECT department_id,salary,first_name
FROM employees
ORDER BY department_id DESC,salary ASC;分页:
使用LIMIT关键字
#分页
# 每页显示20条记录
SELECT employee_id,last,first_name
FROM employees
LIMIT 0,20;#此时显示第二页
#第一个0代表和第一条数据的偏移量,第二个20代表这一页想显示多少条数据
# 显示第二页数据
SELECT employee_id,last,first_name
FROM employees
LIMIT 20,20;
# 显示第三页数据
SELECT employee_id,last,first_name
FROM employees
LIMIT 40,20;
#显示第n页的数据
# 公式:LIMIT (n-1) * 该页想显示的数据量,该页想显示的数据量;结构声明顺序:
# 结构声明:WHERE...ORDER BY ...LIMIT 的声明顺序
#先写FORM 再写WHERE 再写ORDER BY 再写LIMIIT
SELECT employee_id,salary,department_id
FROM employees
WHERE salary > 6000
ORDER BY salary DESC
#LIMIT 0,10;
#或者
LIMIT 10;练习
# 练习:表里有107条数据,只想显示32,33条数据
SELECT employees_id,salary,last_name
FROM employees
LIMIT 31,2;
# 练习:查询员工表中工资最高的员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC
LIMIT 0,1;MySQL8.0新特性:

排序与分页的课后练习:

SELECT last_name,department_id,salary * 12 AS annual salary
FROM employees
ORDER BY annual salary DESC,last_name ASC;
SELECT last_name,department_id,salary
FROM employees
WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC
LIMIT 20,20;
SELECT last_name,department_id,salary,email
FROM employees
WHERE email LIKE '%e%'
ORDER BY LENGTH(email) DESC,dempartment_id ASC;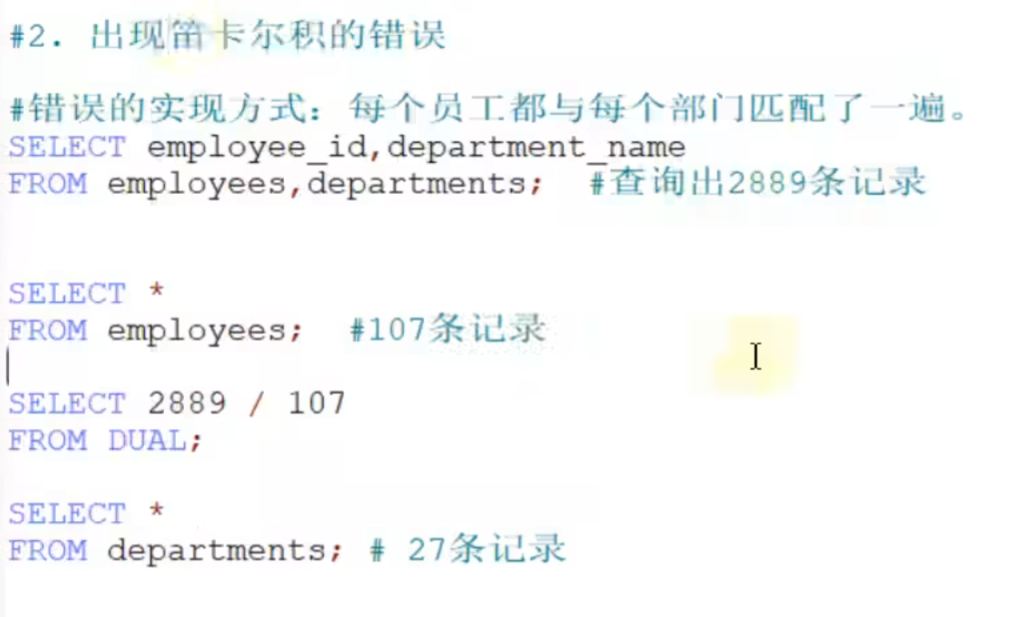
错误原因:缺少多表的连接条件
多表查询的正确方式,需要有连接条件:
# 多表的查询如何实现
# 要有连接条件
SELECT employee_id,department_id
FROM employees
WHERE employees.department_id = departments._department_id;#连接条件,员工表中员工的部门号等于部门表中的部门号小结:

为了避免笛卡尔积,在WHERE中加入有效的连接条件
多表查询其他需要注意的点:
# 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表
SELECT employee_id,department_name,employees.department_id
FROM employees,departments
WHERE employees.department_id = departments.department_id;
#5 可以给表起别名,在SELECT和WHERE使用表的别名
SELECT empmloyees.employees_id,departments.department_name,enployees.department_id
FROM empmloyees AS emp,departments AS dept #而且起了别名就必须用,不然会报错
WHERE emp.department_id = dep.department_id;练习:
# 练习:查询员工的employee_id,last_name,department_name,city
SELECT employee_id,last_name,department_name,city
FROM employees e,department d,locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.locaiton_id;
# 如果有n个表实现了多表的查询,就需要n-1个连接条件多表查询的分类:
自连接:把一个物理表当成两个逻辑表来使用,通过表别名来区分。本质上就是把一个表的数据拆成两个逻辑表来处理
内连接:只返回两个表中关联字段匹配的结果(交集)
外连接:分为左外连接,右外连接,满外连接
左外连接:除了返回两个表的交集,同时也会返回左表中不满足条件的记录
右外连接:和左外连接同理,除了返回两个表的交集,还会返回右表中不满足条件的记录
满外连接:就是全都包含
非等值连接:
# 非等值连接
SELECT e.last_name,e.salary,j.grade_level
FROM employee e,job_grade j
WHERE e.salary >= j.lowest_sal AND e.salary <= j.hightest_sal;自连接:(前面写的例子都是非自连接)
# 自连接
# 练习:查询员工id,员工姓名以及管理者id,管理者姓名
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp,emploees mgr
WHERE emp.employee_id = mgr.employee_id;外连接:(上面写的都是内连接)

如果是右外连接就要在左边补+,左外连接就要在右边补+
SQL92语法是使用+实现外连接的写法,但是MySQL不支持这种语法
SQL99语法中是使用JOIN...ON的方式实现外连接,MySQL支持这种写法
先看SQL99语法实现内连接:


SQL99语法实现外连接:
# SQL99语法外连接练习
# 查询所有员工的last_name,department_name信息
# 注意:涉及到所有,全部这些字眼的时候就要注意是否要用外连接
# 左外连接
SELECT last_name,department_id
FROM employee e LEFT JOIN department d
ON e.department_id = d.department_id;
# 右外连接
SELECT last_name,department_id
FROM employee e RIGHT JOIN department d
ON e.department_id = d.department_id左外连接是以左表为驱动表,保留左表所有信息,如果右表没有匹配的信息,就NULL补充
右表外连接同理
满外连接:

MySQL虽然不支持满外连接,但还是有这种满外连接的需求,所以要用别的方法。
UNION的使用:

取并集
UNIONALL的使用:
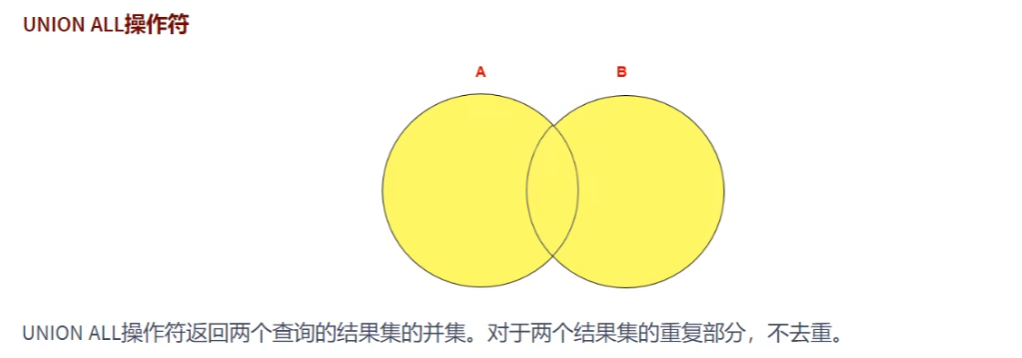
unionall就是把两个表整个拿下来,不去重
unionall的效率比union的高,因为union还要去重
通过unionall和union的使用,就可以实现SQL中的七种JOIN操作
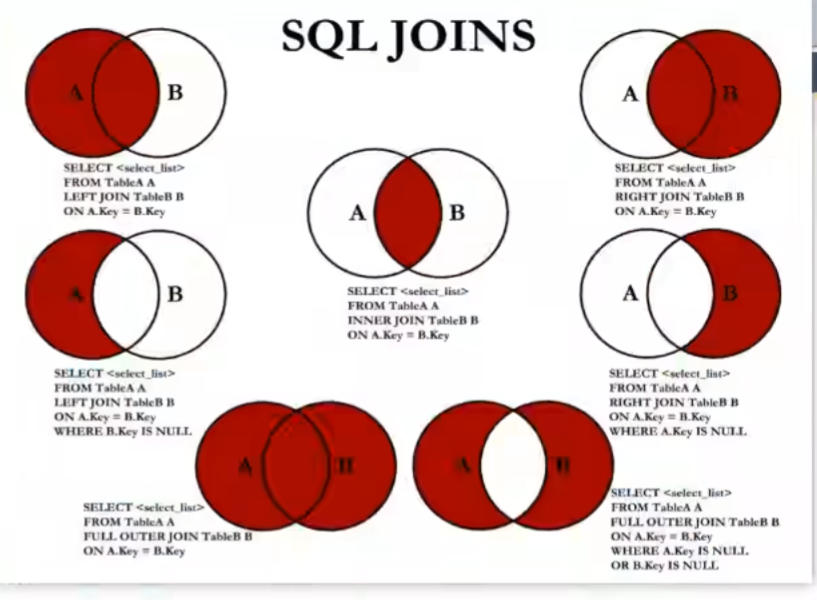
测试:
# 中图:内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
# 左上图 左外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;
#右上图,右外连接
#和左外连接同理
# 左中图,
SELECT employee_id,department_name
FROM employee e LEFT JOIN department d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL;
# 右上图
SELECT employee_id,department_name
FROM employees e RIGHT JOIN department d
ON e.department_id = d.department_id;
# 左中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN department d
ON e.department_id = d.department_id
WHERE d.deparatment_id IS NULL;
# 右中图
SELECT employee_id,department_name
FROM employees e RIGHT JOIN department d
ON e.department_id = d.department_id
WHERE e.deparatment_id IS NULL;
# 左下图:满外连接
SELECT employee_id,department_id
FROM employees e LEFT JOIN department_id
ON e.department_id = d.department_id #左上图
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL; #右中图
# 右下图
# 就是左中图和右中图union allSQL99语法新特性:
自然连接:

所有相同的字段
USING的使用:

使用USING后,会自动去两个表中寻找这个指定的相同的属性
课后习题:

# 1
# 多表查询的时候,最好指明是那个表中的数据
SELECT e.last_name,e.deparment_id,d.deparment_name
FROM enokitees e LEFT JOIN departments s
ON e.department_id = d.department_id;
# 2
SELECT e.job_id,d.location_id
FROM employee e RIGHT d = d.deparment_id
ON e.department_id = d.department_id
WHERE d.deparment_id = 90 ;
# 3
SELECT e.last_name,d.department_name,d.location_id,l.city
FROM employees e LEFT JOIN department d
ON e.department_id = d.department_id
LEFT JOIN locations l
ON d.location_id = l.location_id
WHERE e.bouns IS NOT NULL;
# 4
SELECT e.last_name,e.job_id,d.department_id,d.department_name
FROM employees e LEFT JOIN department d
ON e.department_id = d.department_id
LEFT JOIN location l
ON d.location_id = l.location_id
WHERE e.city = 'Toronto' ;
# 5
SELECT e.department_name,d.location_id,e.first_name,e.job_id,e.salary
FROM department d JOIN employees e
ON d.department_name = e.department_name
JOIN location l
ON d.location_id = l.location_id;
WHERE e.department_name = 'Executive';
# 6
SELECT e.employee_id,e.first_name,m.manager_name,m.manager_id
FROM employees e LEFT JOIN employees m
ON e.manafer_id = m.employee_id;
# 7
SELECT d.department_name,e.department_name
FROM employees e RIGHT JOIN department d
ON e.department_name = d.department_name
WHERE e.department_name IS NULL;
# 8
SELECT department_name
FROM department d RIGHT JOIN location l
ON d.locations_name = l.locations_name
WHERE d.location_name IS NULL;
# 9
SELECT e.employee_name,e.employee_id,e.salary,d.department_name
FROM department d RIGHT JOIN employees e
ON d.employee_name = e.employee_name
WHERE d.department_name = 'Sales'
OR d.department_name = 'IT';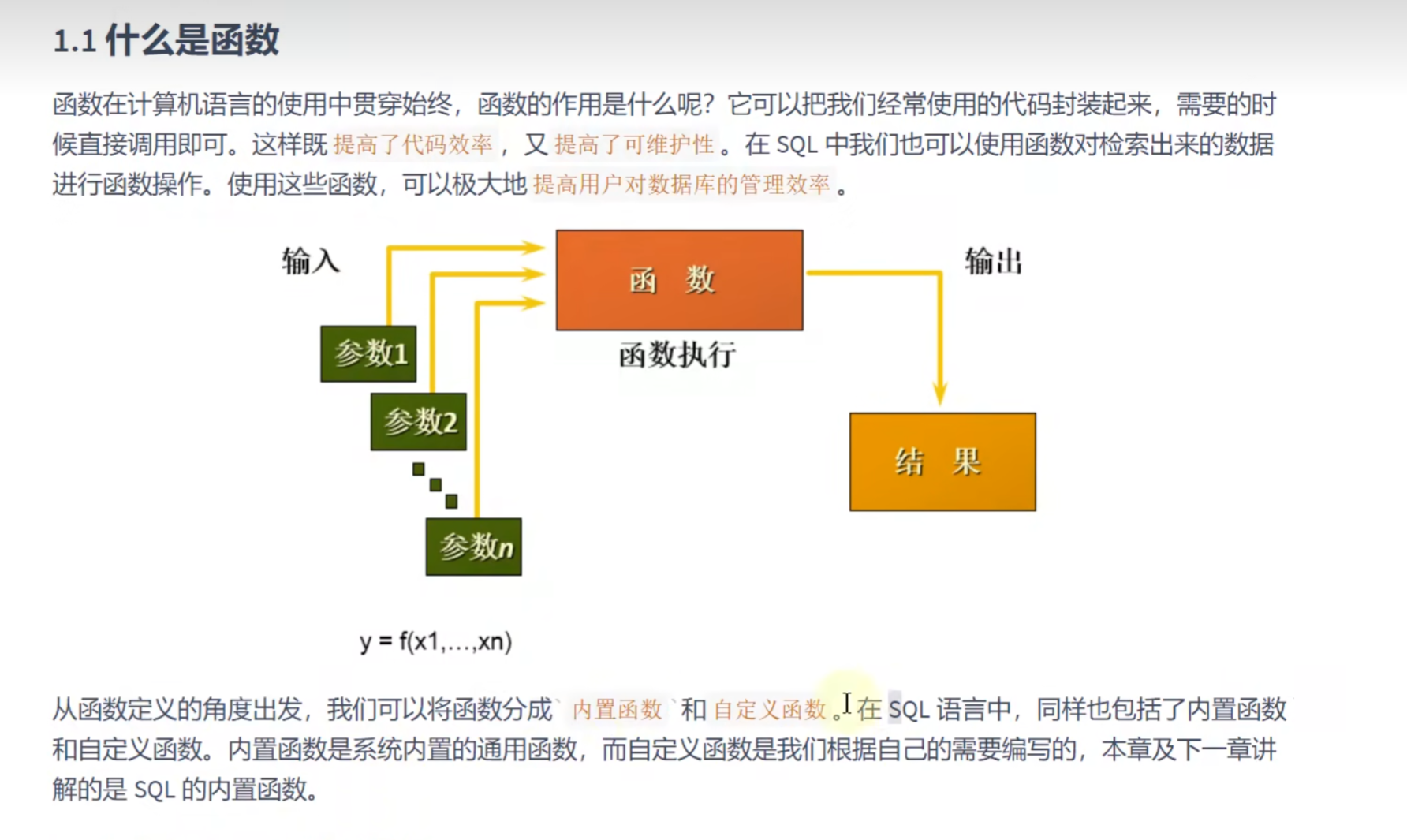
内置函数和自定义函数

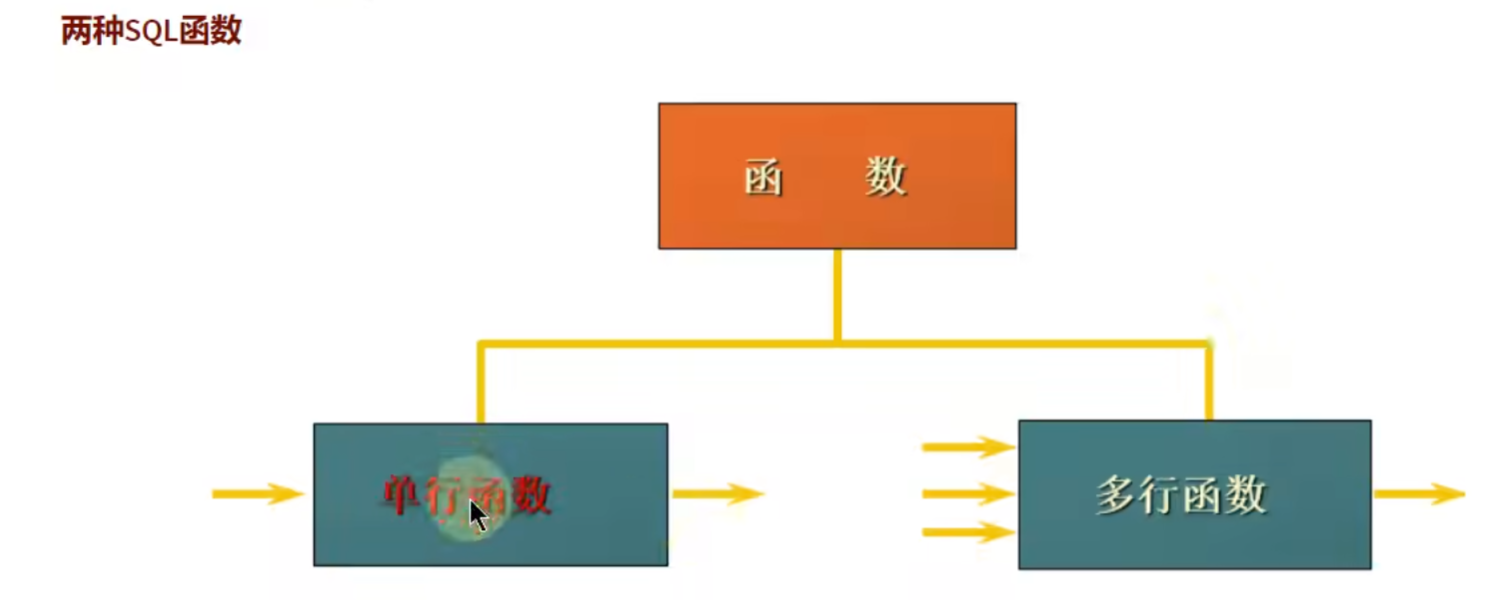
单行函数:进去一行,出来一行
多行函数:进去多行,出来一行

单行函数里的
数值函数:

# 函数测试
# CEIL()天花板函数,得到的就是比一个浮点数大的最小整数
# FLOOR()地板函数,得到的就是比一个浮点数小的最大整数
SELECT CEIL(32.32),FLOOR(32.32) #CEIL函数得到的结果是33,floor得到的结果是32
FROM DUAL;
# MOD()取余函数
# RAND():得到一个随机的0到1的数
# RAND(带参数):返回一个随机的0到1的数,如果参数一样,那得到的随机数也是一样的
# 四舍五入
# ROUND(x):传统的四舍五入
SELECT ROUND(123.5565); #得到的结果是124
# ROUND(x,y):四舍五入,但是保留y位小数
SELECT ROUND(123.456,-1); # 负数就往前y位四舍五入,这个返回的结果是120
# TRUNCATE(x,y):不管是几,都直接截断。y还是保留几位小数的意思
SELECT TRUNCATE(123.956,1);# 这个返回结果是123.9
SELECT TRUNCATE(123.956,0);# 这个返回的结果是123
# 单行函数可以嵌套
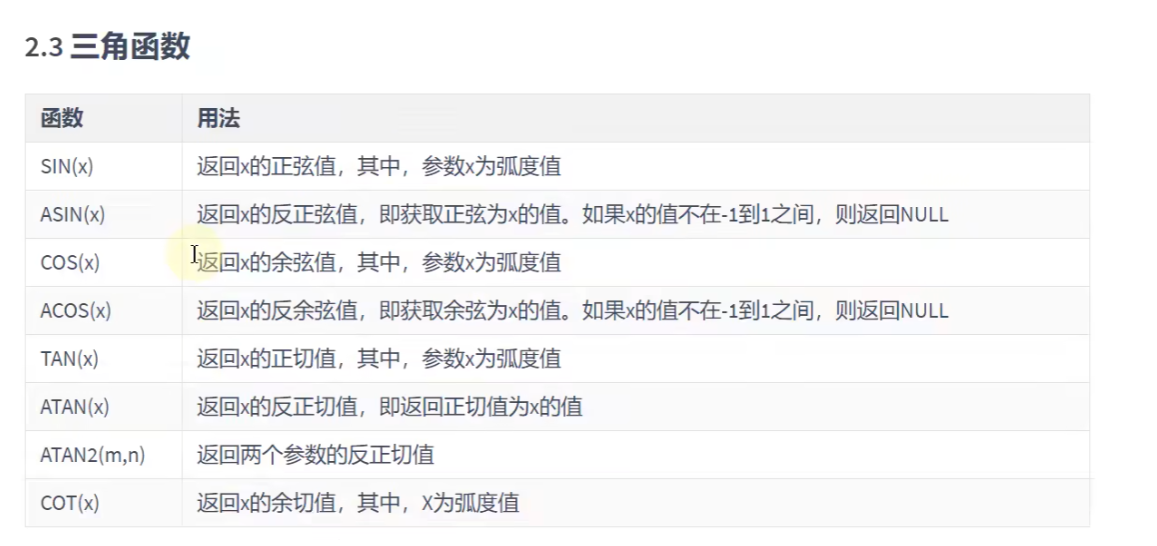
SELECT TRUNCATE(ROUND(123.456,2),0); #123三角函数:
# 三角函数
# SIN()返回的是sin值
SELECT SIN(RADIANS(30));# 0.49999999999999994
SELECT DEGREES(ASIN(1));# 90
# ASIN()得到的就是函数图像里x的值,比如1对应的x值就是二分之Π,然后通过degrees转化为角度指数与对数:
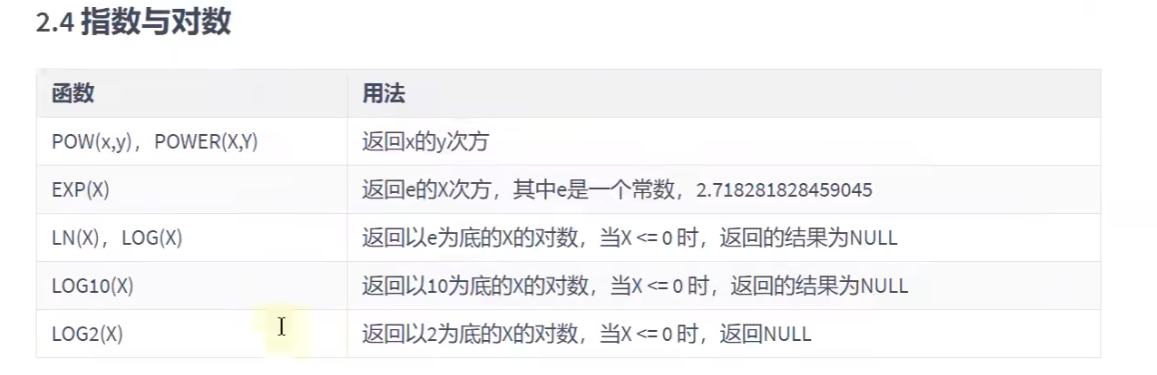
这个就不测了,不难
进制间的转换:
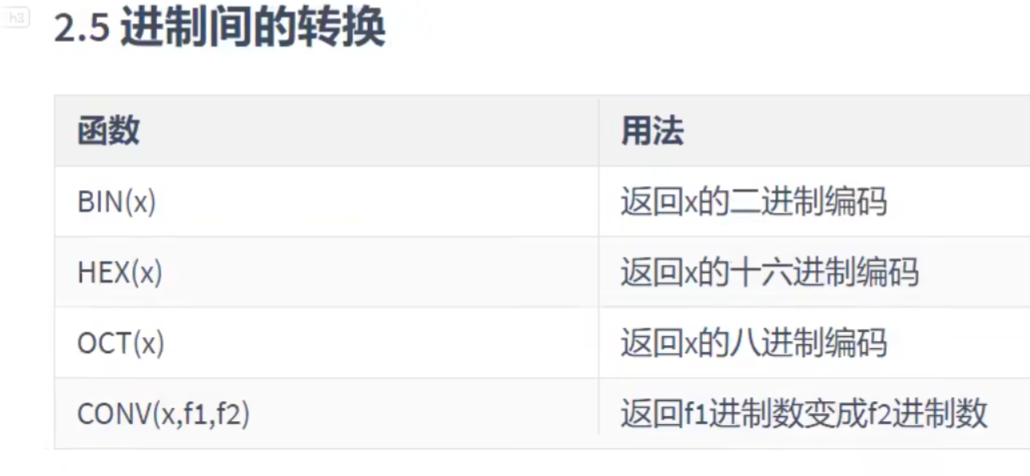
B(计导,二进制)D(十进制)O(八进制)H(十六进制)
这个也不测了,不难
字符串函数:
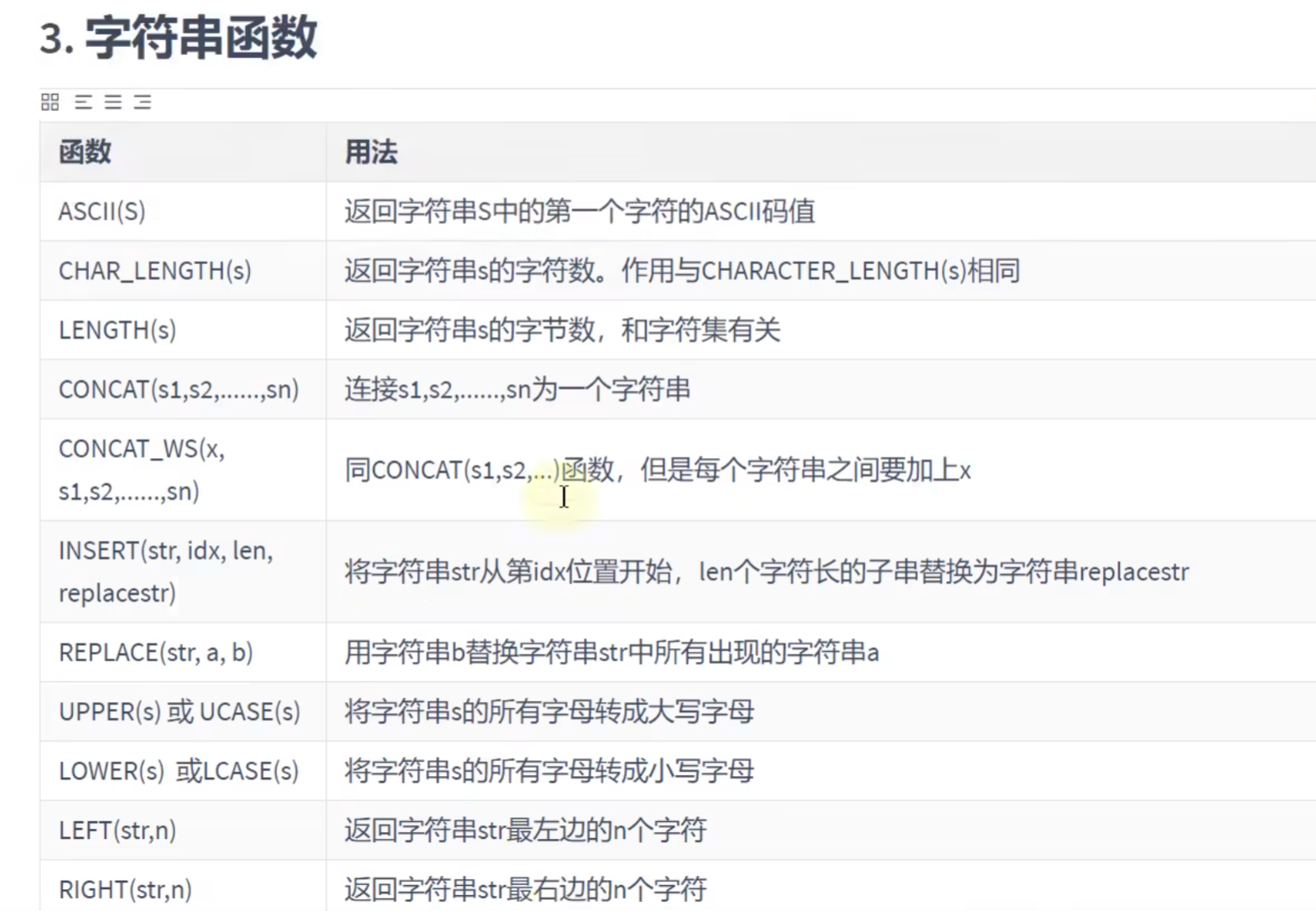
# 字符串函数
# ASCII() 返回的是存储的第一个字母的ASCII码值
SELECT ASCII('Aaswdgfhbfas');# 65
# CHAR_LENGTH():返回字符串个数
SELECT CHAR_LENGTH('董诗豪是我儿');#6
# LENGTH():这个返回的是字节数,和字符集有关
SELECT LENGTH('hello'),LENGTH('董诗豪是我儿');#5,18.
# CONCAT():就是连接操作,不测了
# CONCAT_WS():每个连接中间用分隔符
SELECT CONCAT_WS('_','董','诗','豪','是','我','儿');#董_诗_豪_是_我_儿
# INSERT('str',x,y,'str1'):用str1插入str中,从x的索引位置开始,替换后续y长度的内容
# 注意:MySQL的索引位置是从1开始的
SELECT INSERT('董234567',2,6,'诗豪是我儿');# 董诗豪是我儿
# REPLACE(str,x,y):替换:在str中,用y替换x的内容,如果x找不到就替换失败
SELECT REPLACE('董诗豪11111','11111','是我儿');#董诗豪是我儿
# UPPER():大写
# LOWER():小写,这俩不测了,就是把字符串全部大写或者小写
#LEFT(str,n):返回str左边n个字符
#RIGHT(str,n):返回str右边n个字符,这俩也不测了
# LPAD(str,x,'n'):右对齐:str的内容一起占用x个长度,如果长度不够,就在左边补n的内容,直到达到x的长度。如果n是空格,就能实现右对齐的效果
# RPAD(str,x,'n'):左对齐:同理,str的内容一起占用x个长度,如果长度不够,就在右边补n的内容,知道达到x的长度。如果n是空格,就能实现左对齐的效果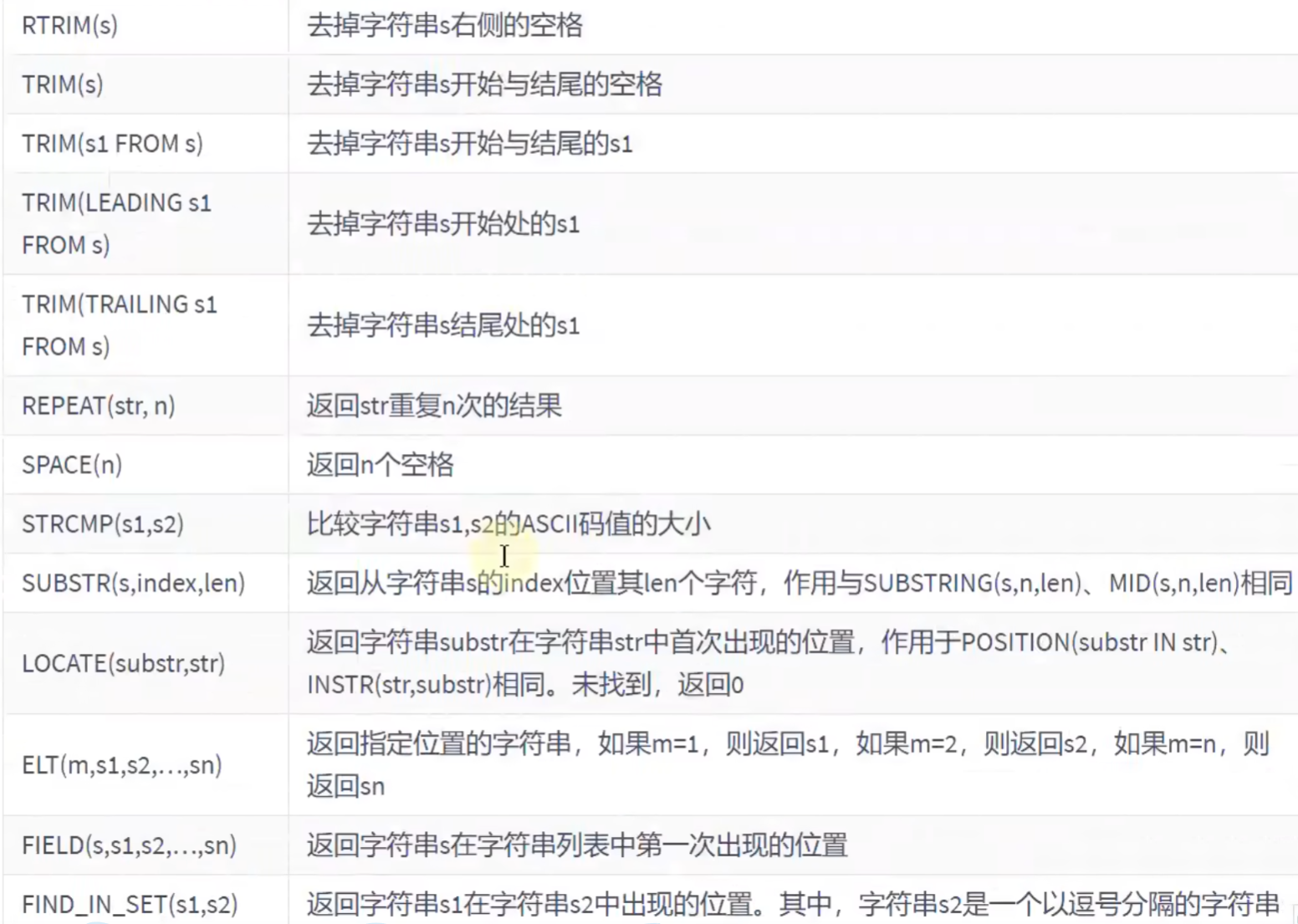
# TRIM(s):去掉s开始与结尾的空格
# LTRIM(s):去掉s左侧的所有空格
# RTEIM(S):去掉s右侧的所有空格
SELECT TRIM(' XxxaiAyanami ');#XxxaiAyanami
#另外那俩就不测了
# TRIM(x FROM s):去除s首尾的x
SELECT TRIM('Asuka' FROM 'AsukaXxxaiAyanamiAsuka');#XxxaiAyanami
# TRIM(LEADING s1 FROM s):去除字符串s左侧的s1
# TRIM(TRAILING s1 FROM s):去除s右侧的s1。这俩也不测了,和上面道理一样
# STRCMP(s1,s2):比较字符串s1和s2的ASCII码大小
SELECT STRCMP('avc','abc');#1 #返回1就是前面大,返回2就是后面的大
#SUBSTR(s,index,len)
SELECT SUBSTR('董诗豪是我儿',4,3);# 是我儿
SELECT LOCATE('我儿','董诗豪是我儿');# 5# 前面写的是子字符串,后面写的是字符串
# ELT():返回指定的字符串的索引位置的子字符串
SELECT ELT(4,'董','诗','豪','是','我','儿');
# FIELD(s,s1,s2,...,sn):返回字符串s再字符串列表中第一次出现的位置
SELECT FIELD('是','董','诗','豪','是','我','儿');#4
#FIND_IN_SET(S1,S2):返回字符串s1在字符串s2中出现的位置,其中,字符串·s2是一个以逗号分隔的字符串
SELECT FIND_IN_SET('DD','AA,DD,FF'); # 2日期,时间类:
获取日期,时间
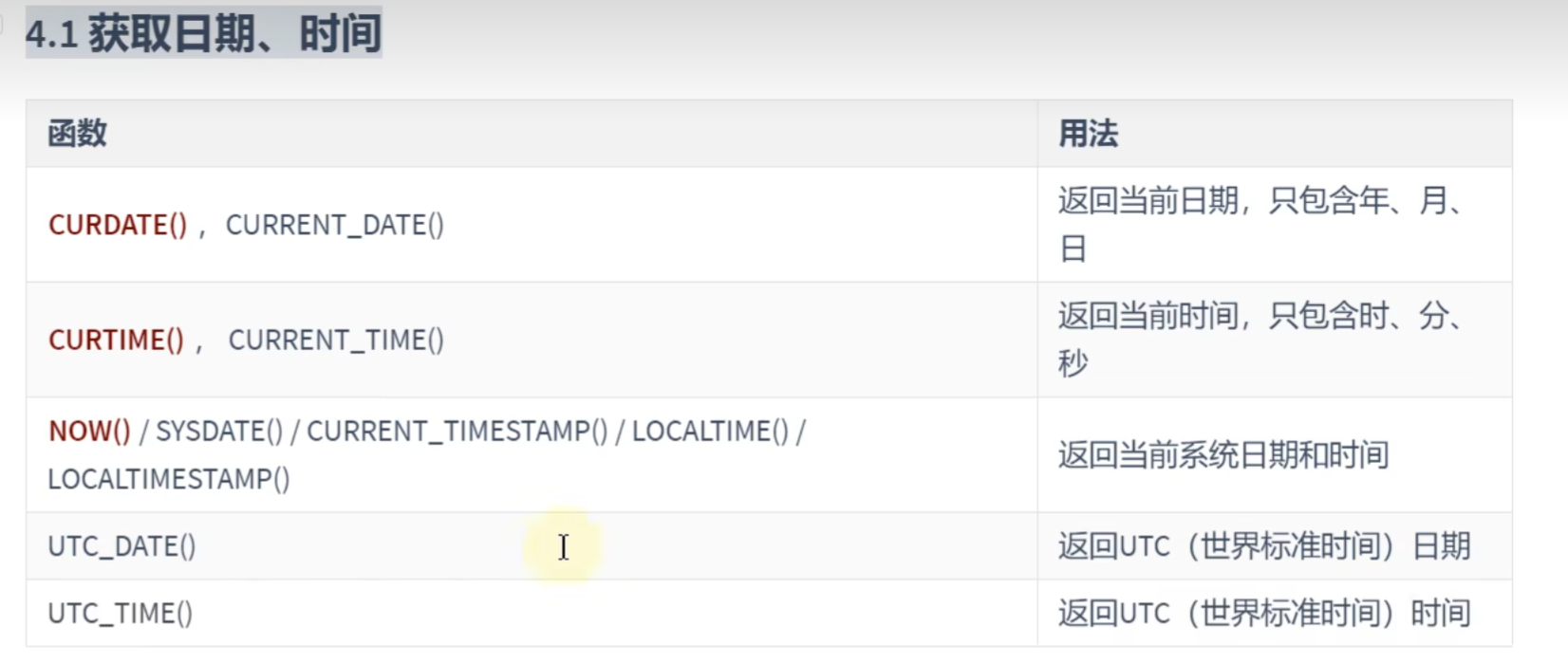
# 日期,时间类的
# 1.获取日期,时间
# CURDATE(),CURRENT_DATE():返回当前日期,只包含年月日
SELECT CURRENT_DATE();
# CURTIME(),CURRENT_TIME():返回当前时间,只包含时,分,秒
SELECT CURTIME();
# NOW()/SYSDATE()/CURRENT_TIMESTAMP()/LOCALTIME()/LOCALTIMESTAMP():返回当前年月日时分秒
SELECT NOW();日期与时间戳之间的转换:
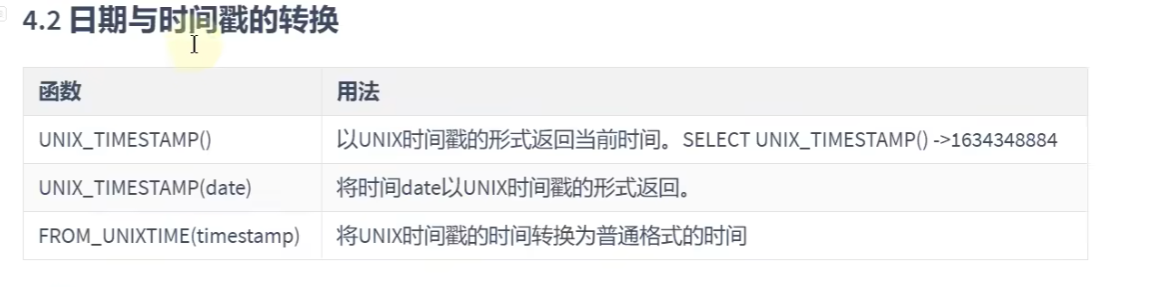
# 日期和时间戳的转换
SELECT UNIX_TIMESTAMP();#返回当前时间的时间戳
SELECT UNIX_TIMESTAMP('2015,1,1');#1420041600# 返回指定时间的时间戳
SELECT FROM_UNIXTIME('1420041600');# 返回时间戳的年月日信息获取星期:
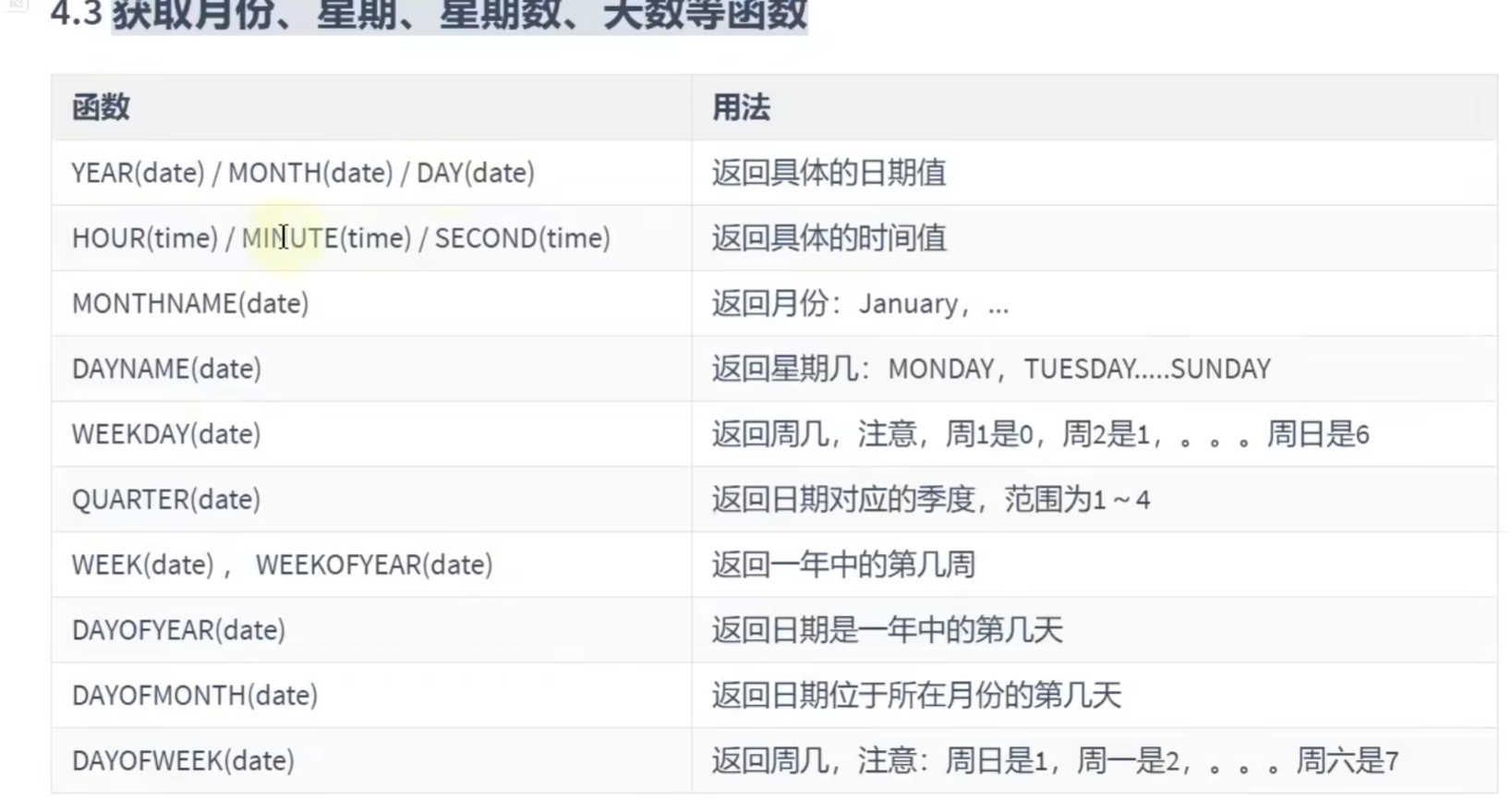
# 获取月份,星期,星期数,天数等信息
SELECT YEAR(CURRENT_DATE()),MONTH(CURRENT_DATE()),DAY(CURRENT_DATE()),HOUR(CURTIME()),MINUTE(NOW()),SECOND(SYSDATE());
日期的操作函数:

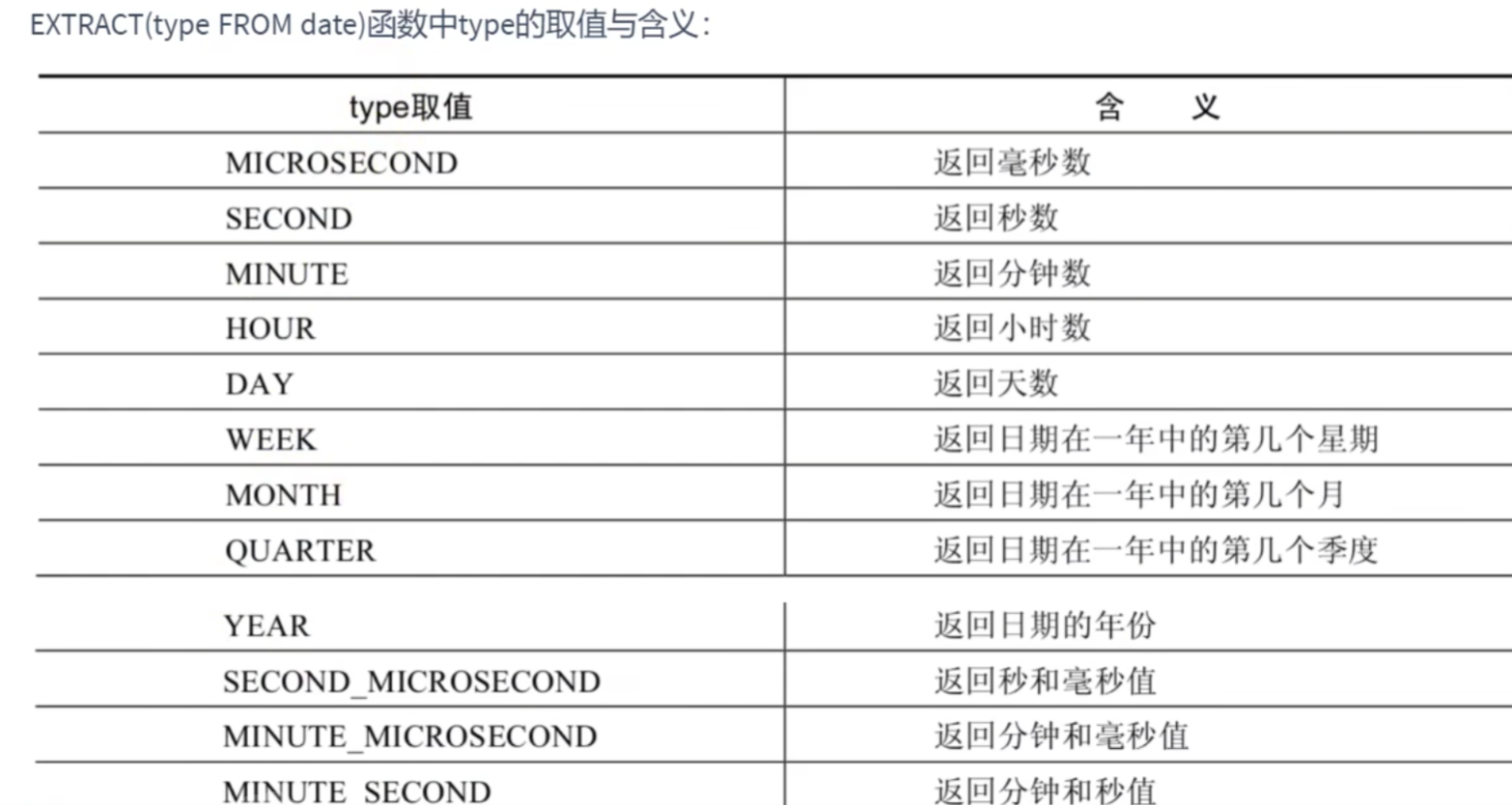
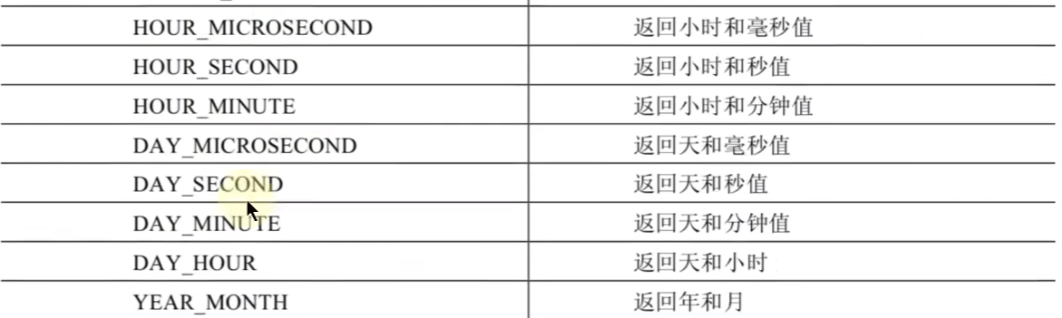
# 日期的操作函数
SELECT EXTRACT(MINUTE FROM NOW()),EXTRACT(DAY FROM NOW())就是替换括号里的字段就行,不难
时间和秒钟的转换函数:
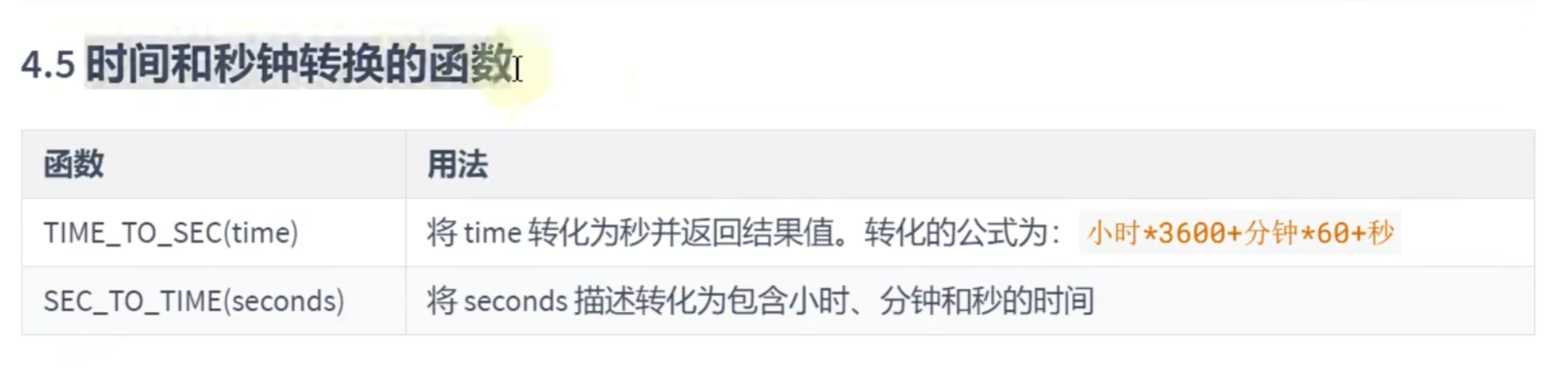
# 时间和秒钟转换的函数
SELECT TIME_TO_SEC(NOW());
SELECT SEC_TO_TIME(72042);计算日期和时间的函数:
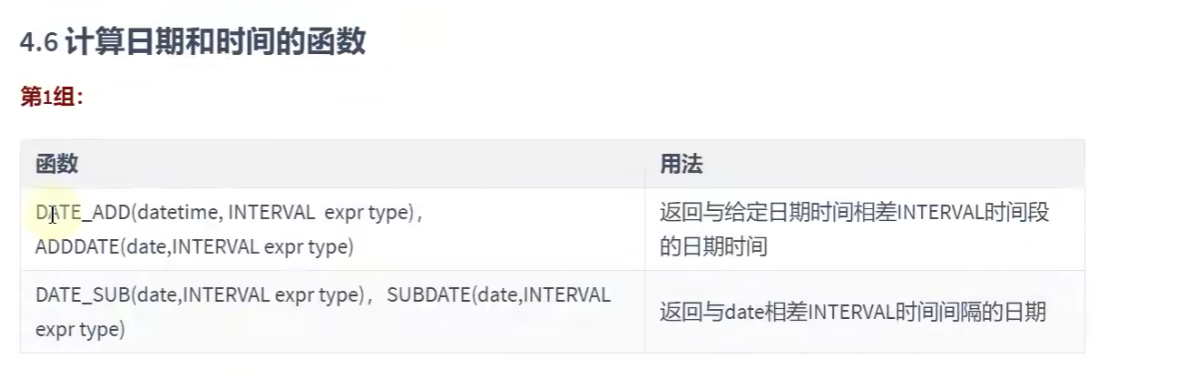
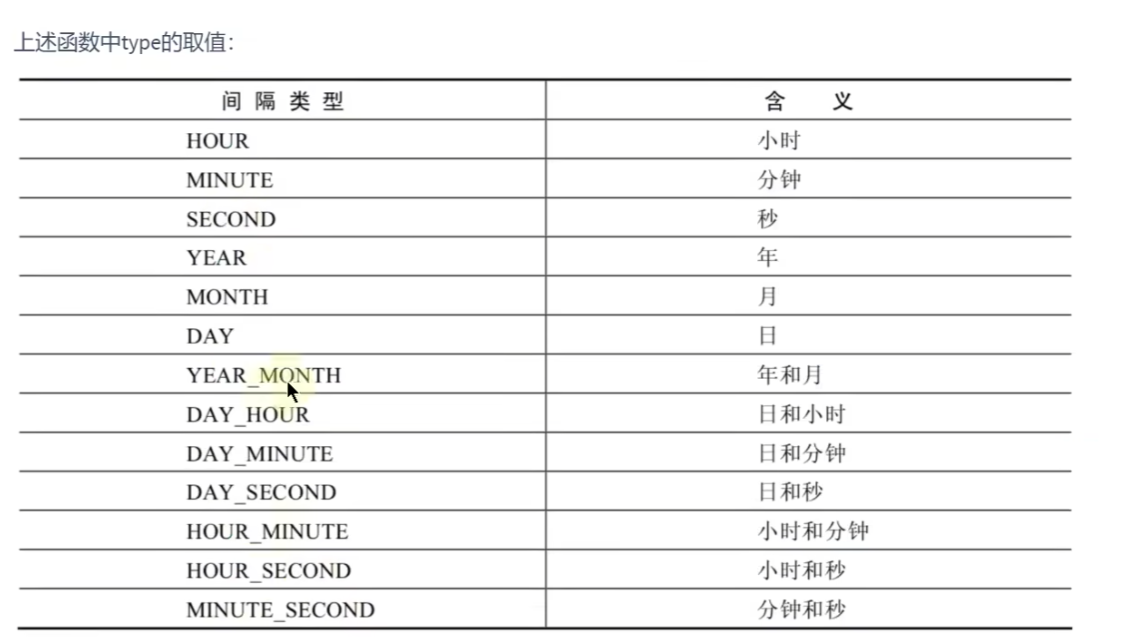
# 计算时间和日期的函数
select DATE_ADD(NOW(),INTERVAL 2 YEAR); # 在选择的年份中上2年#2027-12-17 20:05:07
SELECT DATE_SUB(NOW(),INTERVAL 1 YEAR);# ADD是加,SUB是减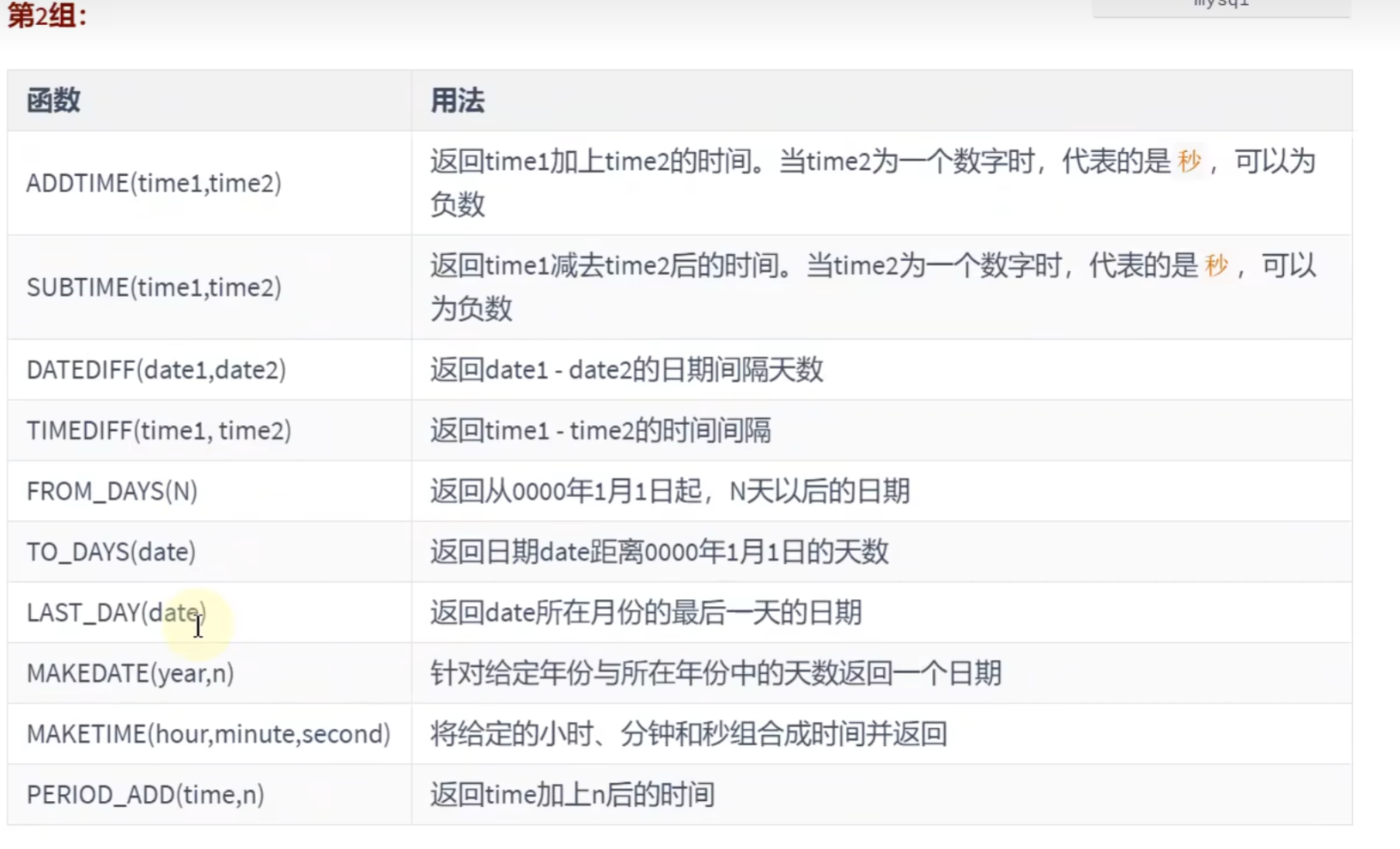

日期的格式化和解析;
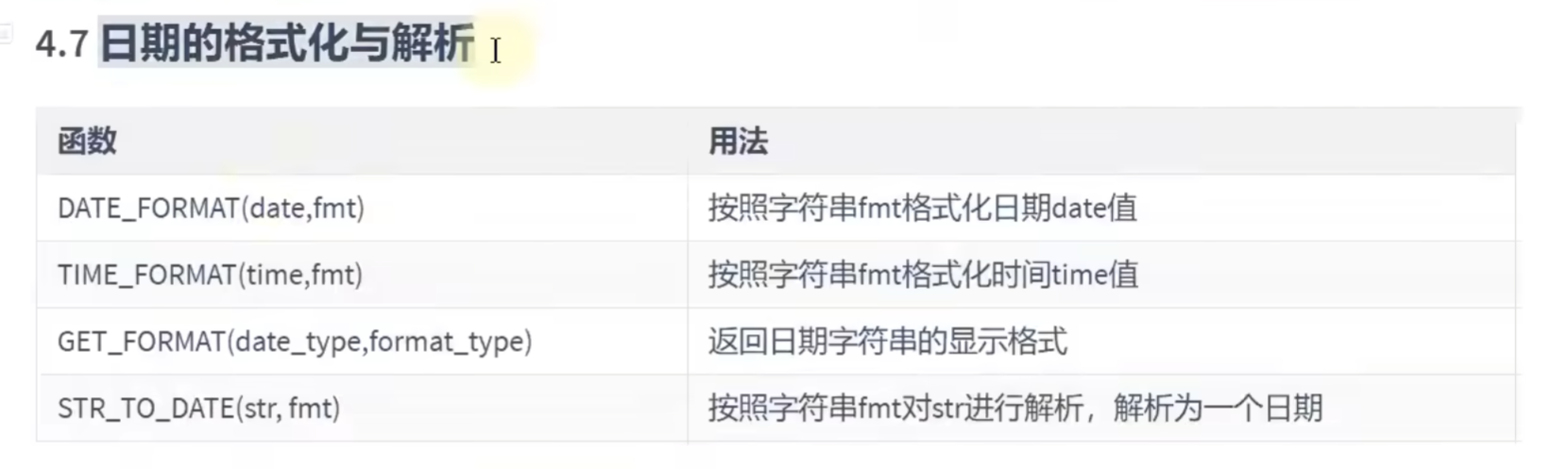
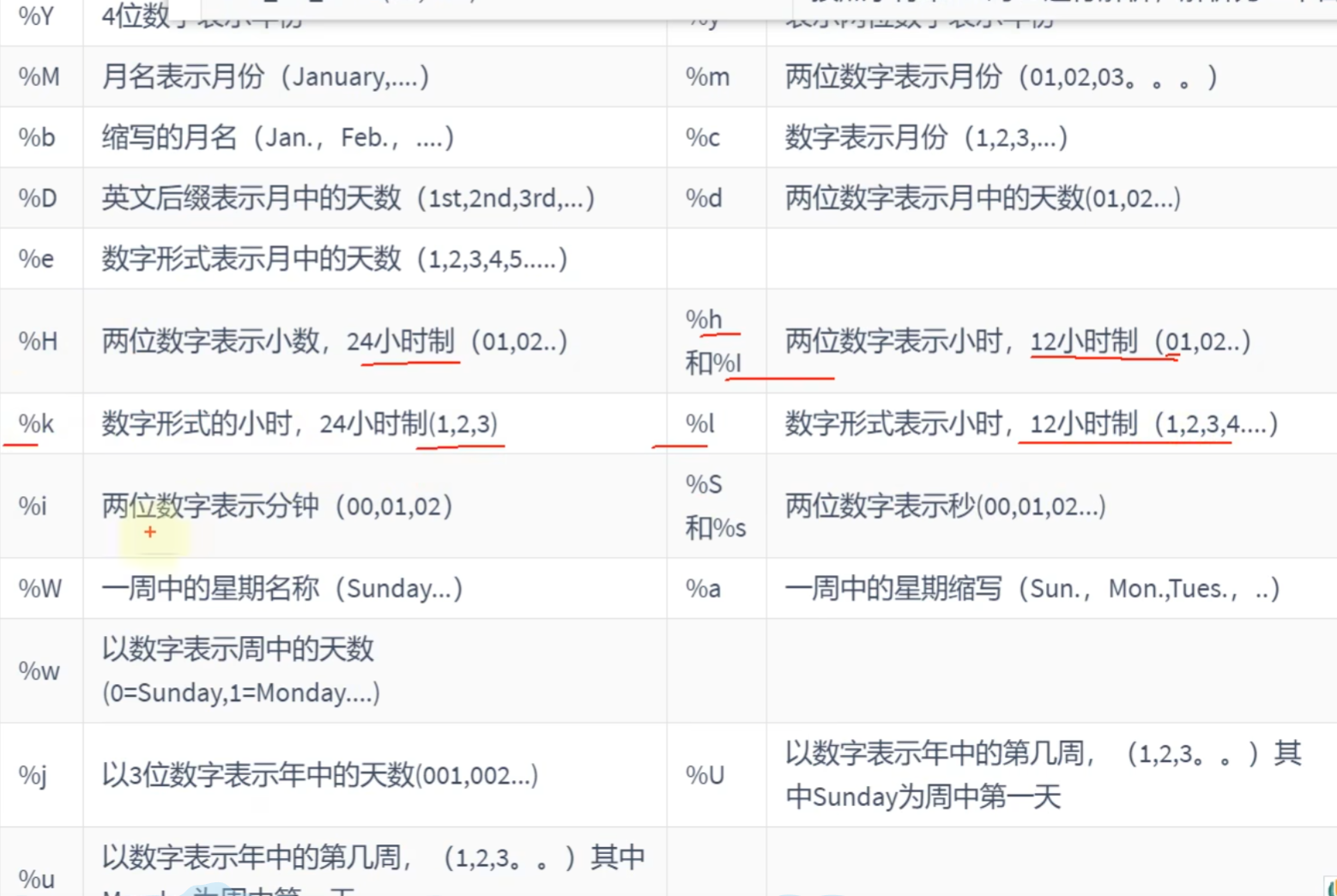
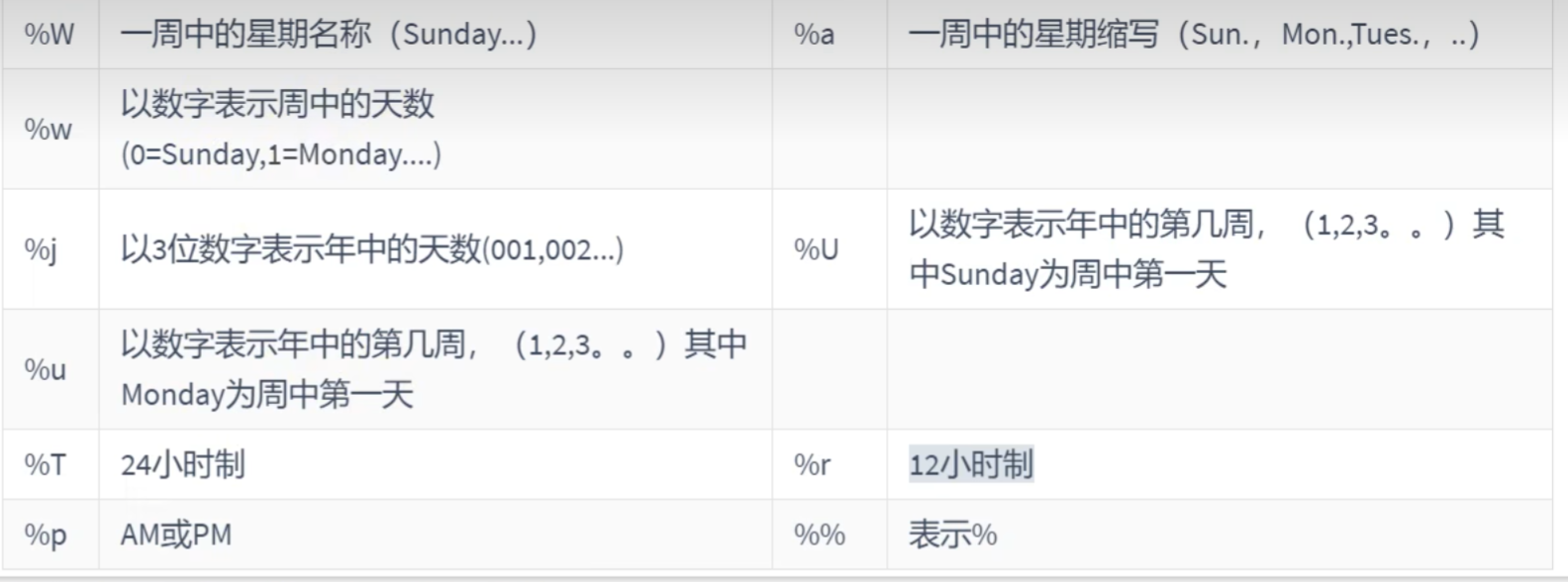
# 日期的格式化和解析:
# 格式化:
SELECT DATE_FORMAT(NOW(),'%Y,%M,%D,%H:%i:%s')#2025,December,17th,20:26:04
# 解析:
SELECT STR_TO_DATE('2025,December,17th,20:26:04','%Y,%M,%D,%H:%i:%s')#2025-12-17 20:26:04
# 解析和格式化的格式要一致,不然识别不出来流程控制函数:

# 流程控制函数:
# IF(expr1,expr2,expr3);exper1是true的话,就执行expr2,否则就是expr3
SELECT last_name,salary,IF(age > 35,'高龄待 退休','继续当牛马')
FROM DUAL;
# IFNULL(value1,value2):如果value1不为null,返回value1,否则返回value2;
SELECT last_name,salary,CASE WHEN salary >= 15000 THEN '高新'
WHEN salary >= 3000 THEN '牛马'
ELSE '丸辣' END AS '工资表'
FROM DUAL;
# CASE WHEN ....THEN相当于Java中的if else if else
SELECT salary,CASE department_id
WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
END AS detail
FROM employees;
# CASE .... WHEN ... THEN...WHEN...THEN相当于Java中的switch ... case...加密解密函数:
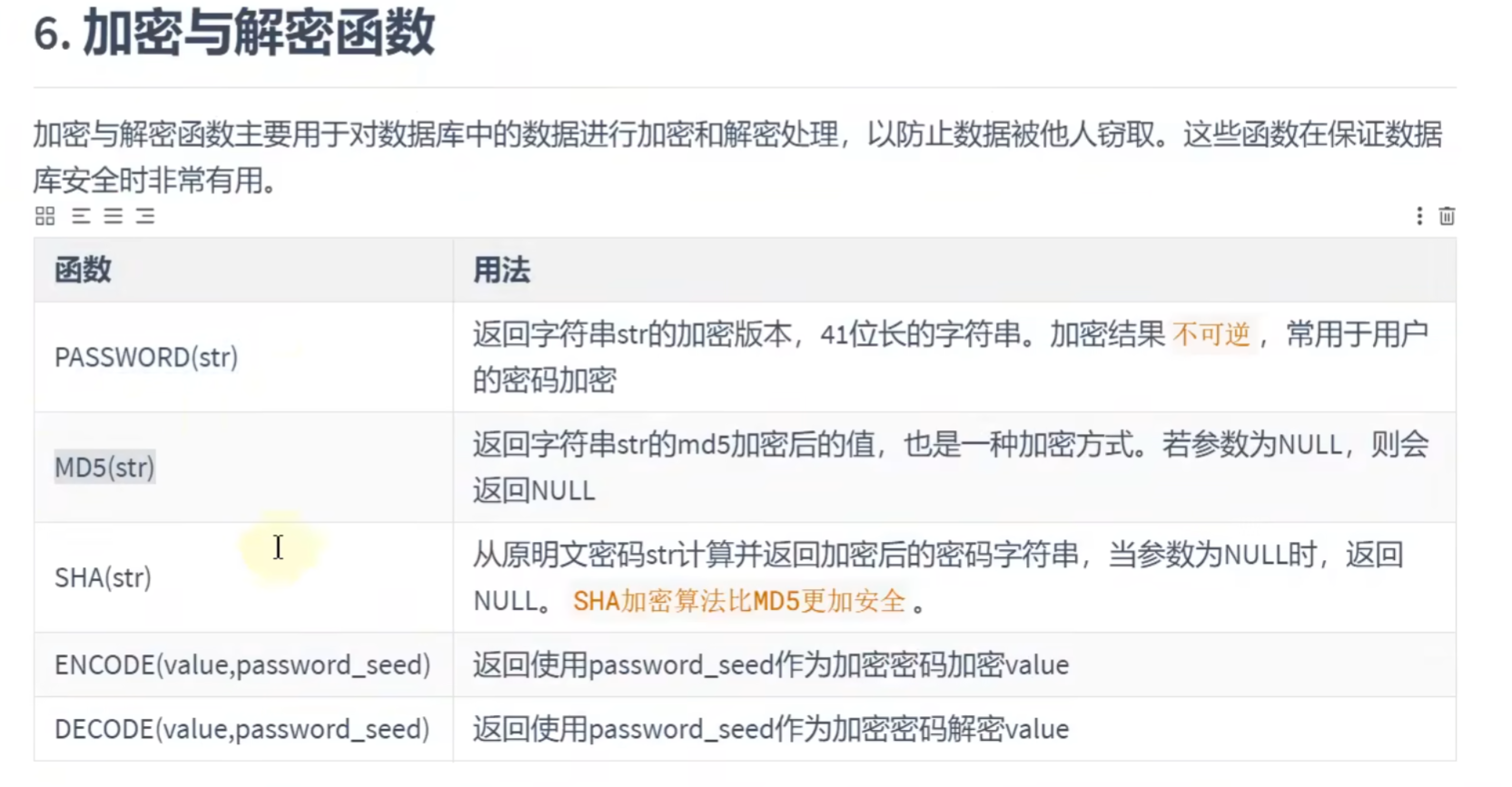
# 加密解密函数
# SELECT PASSWORD('mysql');# password这个函数 mysql8.0已经弃用
SELECT MD5('mysql'),SHA('mysql'); #这两个加密算法不可逆,意思就是只能把明文加密为暗文,不能把暗文解密为明文;
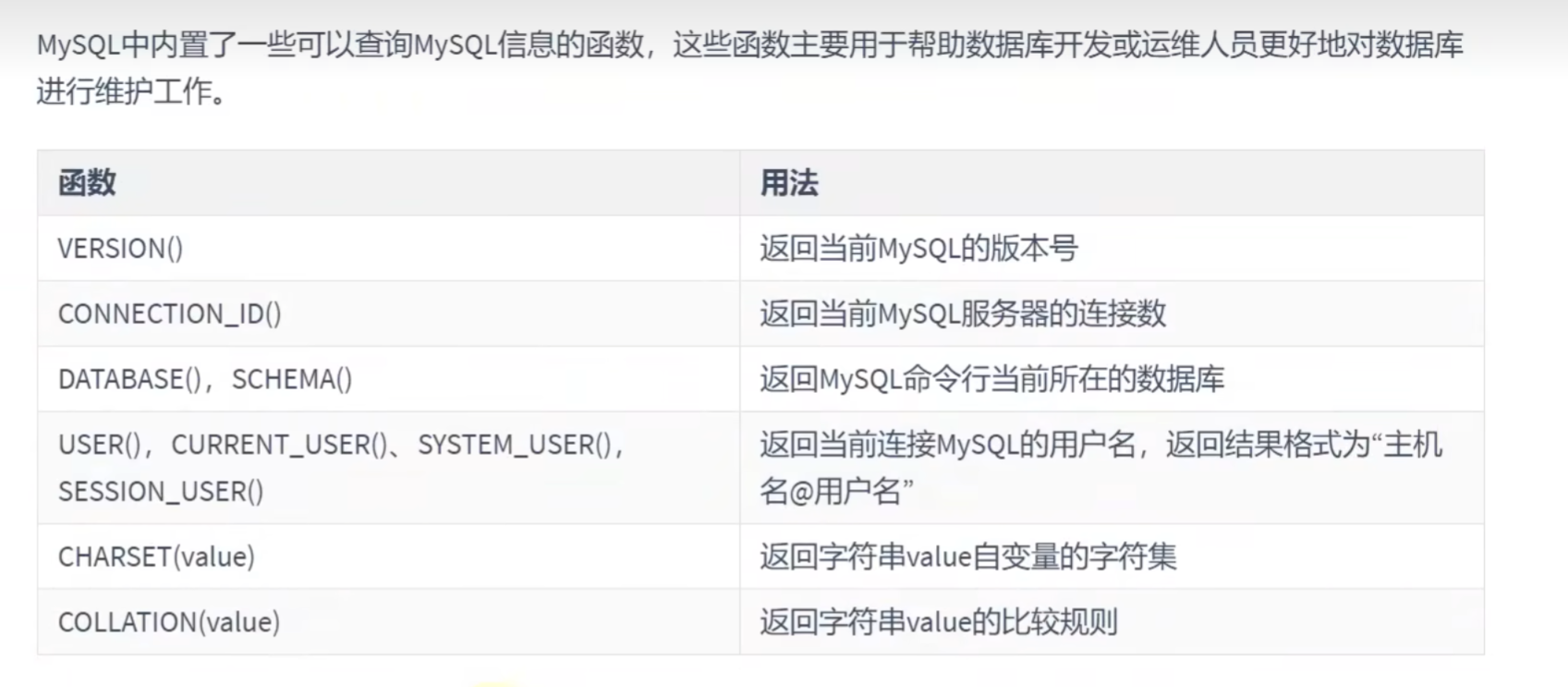
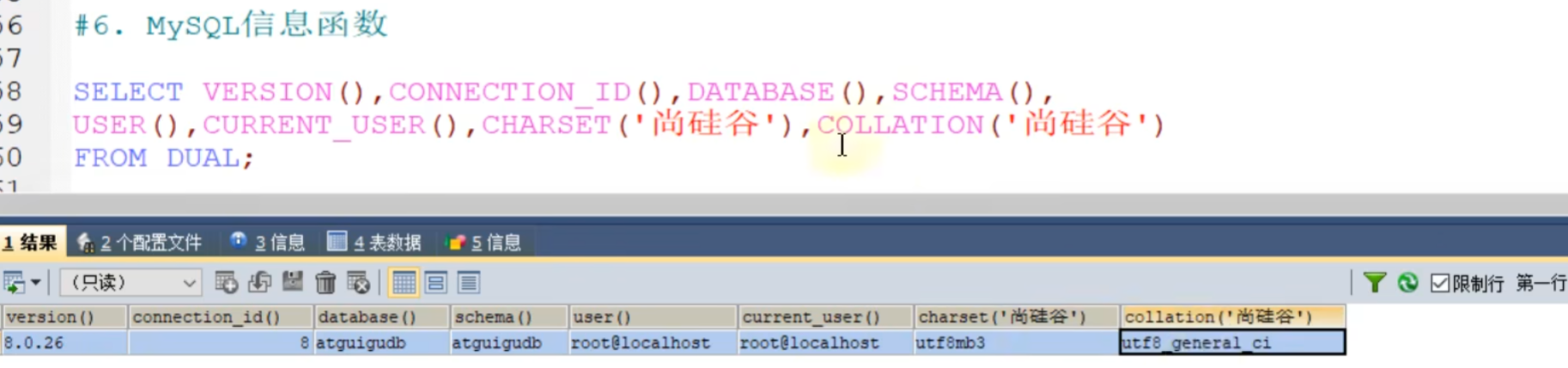
# ENCODE()和DECODE()这两个加密解密函数,在mysql8.0中也被弃用了MySQL信息函数:
其他函数:

课后练习:
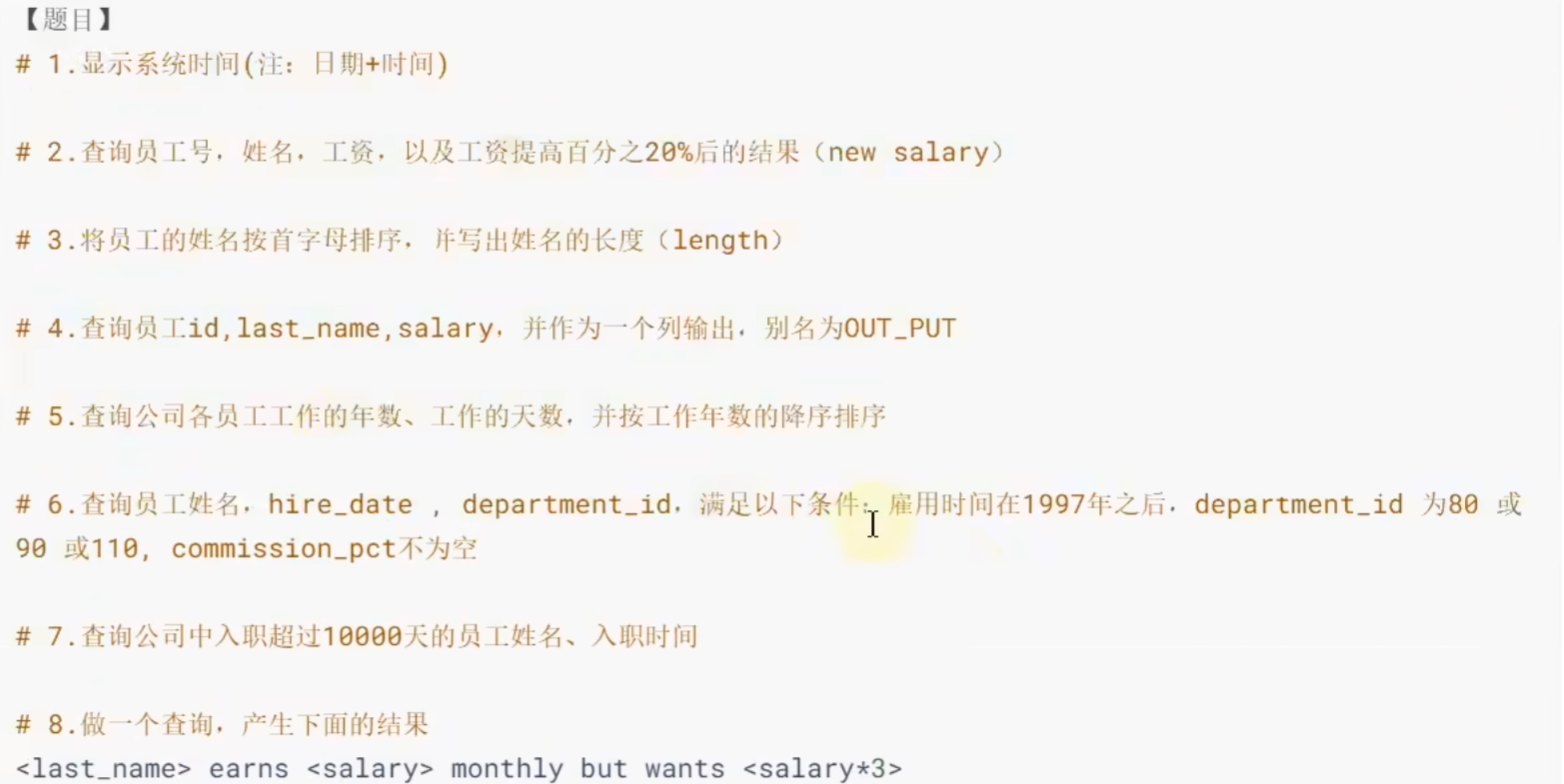
# 课后练习:
#1
SELECT NOW();
# 2
SELECT employee_id,first_name,salary, salary * 1.2 AS new salary
FROM DUAL;
# 3
SELECT last_name,LENGTH(last_name)
FROM employees
ORDER BY last_name ASC;
# 4
SELECT CONCAT(employee_id,last_name,salary) AS OUT_PUT
FROM employees;
# 5
SELECT employee_id,TIMEDIFF(CURDATE(),hire_date) AS workdays,TIMEDIFF(CURDATE(),hire_date)/365 AS workyears
FROM employees
ORDER BY workyears DESC;
# 6
SELECT last_name,hire_date,department_id
FROM employees
WHERE #使用格式化 date_format(hire_date,'%Y-%m-%d') >= '1997-01-01' 显示转换操作,格式化
hire_date >= STR_TO_DATE('1997-01-01','%Y-%m-%d') # 使用解析,字符串转换成2日期
AND department_id IN (80,90,110)
AND commission_pct IS NOT NULL;
# 7
SELECT last_name,hire_date
FROM employees
WHERE DATEDIFF(CURDATE(),hire_date) >= 10000;
# 8
SELECT CONCAT(last_name,'earns',salary,'monthly but wnats',salary * 3)
FROM employees;什么是聚合函数:
常用的聚合函数类型:

count:
1. 基本语法
COUNT(*)
统计表中所有行的数量,包括 NULL 值
SELECT COUNT(*) FROM users;
COUNT(column_name)
统计指定列中非 NULL 值的数量
SELECT COUNT(email) FROM users; -- 只统计 email 不为 NULL 的行
COUNT(DISTINCT column_name)
统计指定列中不同值的数量(去重)
SELECT COUNT(DISTINCT department) FROM employees;
2. 各种用法的区别
|--------------------------|--------------|-------------|
| 用法 | 说明 | 是否包含 NULL |
| COUNT(*) | 统计所有行数 | ✅ 包含 NULL 行 |
| COUNT(1) | 统计所有行数 | ✅ 包含 NULL 行 |
| COUNT(column) | 统计该列非 NULL 值 | ❌ 不包含 NULL |
| COUNT(DISTINCT column) | 统计不同非 NULL 值 | ❌ 不包含 NULL |
#常用的聚合函数:
#AVG/SUM:平均数和总和,只适用于数值类型的变量。SUM计算总和的时候会自动过滤null值
SELECT AVG(salary),SUM(salary)
FROM employees;
# MAX/MIN 最大值和最小值,这个可以适用于数值类型,字符串类型,日期类型
SELECT MAX(salary),MIN(salary)
FROM employees;
# COUNT:
#作用1:计算指定字段在查询结果中出现的个数
# 作用2:可以用来查询表格的行数,count(*)
# 如果要使用count计算具体的字段,那么count只会计算非null的- 性能考虑
COUNT(*) vs COUNT(column)
COUNT(*) 通常最快,MySQL 会进行优化
COUNT(column) 需要检查该列是否为 NULL
COUNT(1) vs COUNT(*)
在现代 MySQL 版本中,两者性能基本相同
COUNT(*) 是标准 SQL,推荐使用
GROUP BY:
# GROUP BY :按照某个字段进行分组
#使用一个列进行分组
# 查询各个部门的平均工资,最高工资
SELECT department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id;
#使用多个列进行分组
# 查询各个department_id,job_id的平均工资
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
#小结1:select中出现的非组函数的字段必须声明在GROUP BY中
# 但是,GROUP BY中声明语句的字段可以不出现在select中
#小结2: GROUP BY 声明在FROM后面,WHERE后面,ORDER BY 前面,LIMIT前面
HAVING(用来过滤数据的):
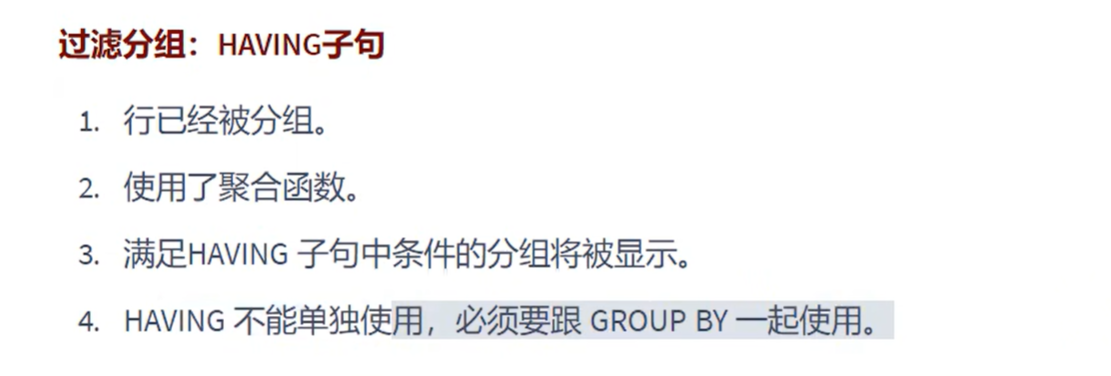
# HAVING(用来过滤数据的)
#一旦过滤条件中使用了聚合函数(GRUOP BY),则必须使用HAVING来替换WHERE,否则会报错
# HAVING必须声明在GROUP BY的后面
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;练习:
# 查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
SELECT department_id,MAX(salary)
FROM employees
WHERE department-id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
# 结论:当过滤条件中有聚合函数时,则次过滤条件必须声明在HAVING中
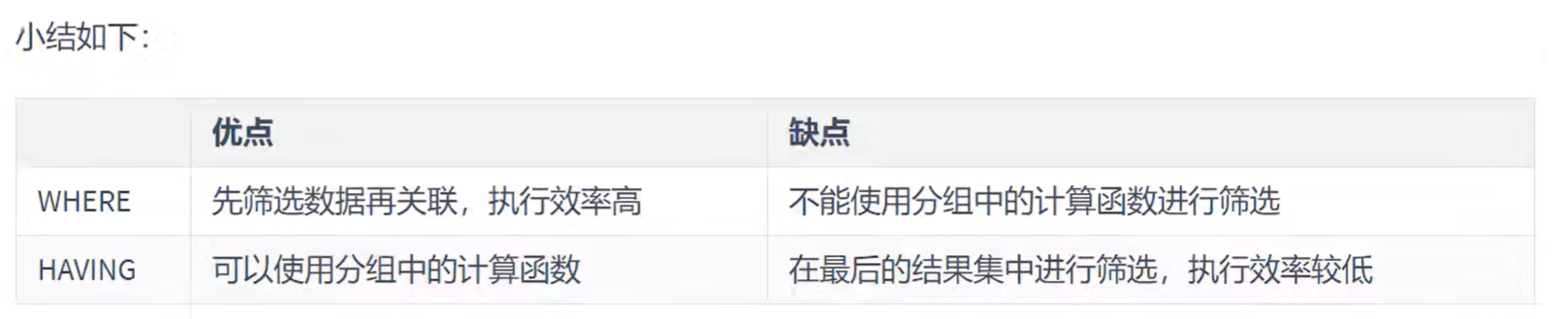
# 当过滤条件中没有聚合函数时,建议把过滤条件写在WHERE中HAVING和WHERE的对比:

SQL底层执行原理:


课后练习:

# 1
#不可以
# 2
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees;
# 3
SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id;
# 4
SELECT job_id,COUNT(*)
FROM employees
GROUP BY job_id;
# 5
SELECT MAX(salary) - MIN(salary) AS DIFFERENCE
FROM employees;
# 6
SELECT MIN(salary),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary) >= 6000;
# 7
SELECT d.department_name,d.location_id,COUNT(employee_id),AVG(salary)
FROM employees e RIGHT JOIN department d
ON e.department_id = d.department_id
GROUP BY department_name,location_id;
# 8
SELECT e.job,e.job_name,d.department_name,MIN(salary)
FROM employees e RIGHT JOIN department d
ON e.department_id = d.department_id
GROUP BY department_name,job_id;其实也可以叫做嵌套查询
引例:


方式三:子查询
# 子查询
#例子:谁的工资比ablel高
SELECT first_name,salary
FROM employees
WHERE salary >(
SELECT last_name,salary
FROM employees
WHERE last_name = 'Ambel'
)称谓:外查询(主查询),内查询(子查询)
子查询的分类方式:
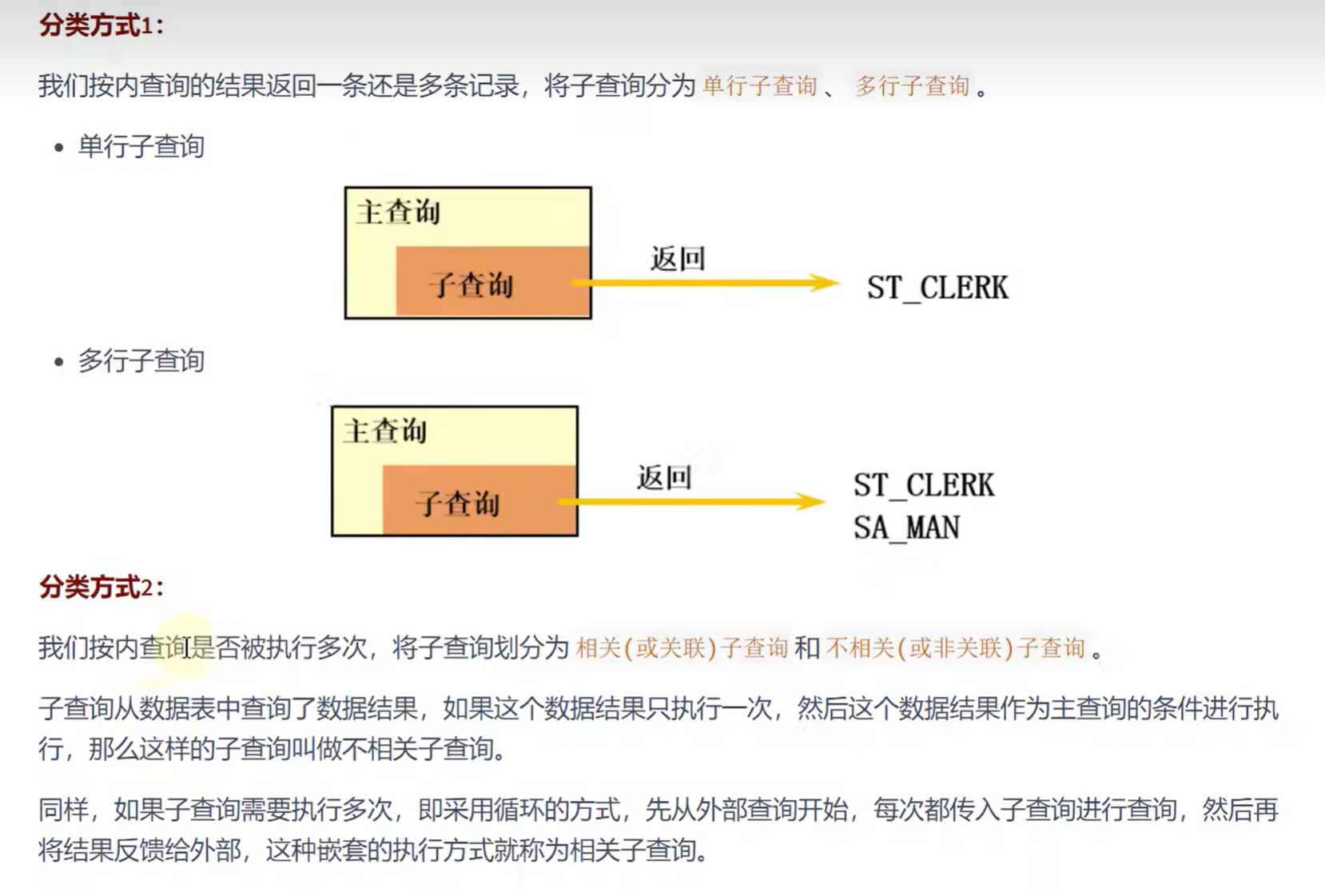
分类方式一:单行子查询,多行子查询
分类方式二:相关子查询,不相关子查询
单行子查询:
单行操作符:
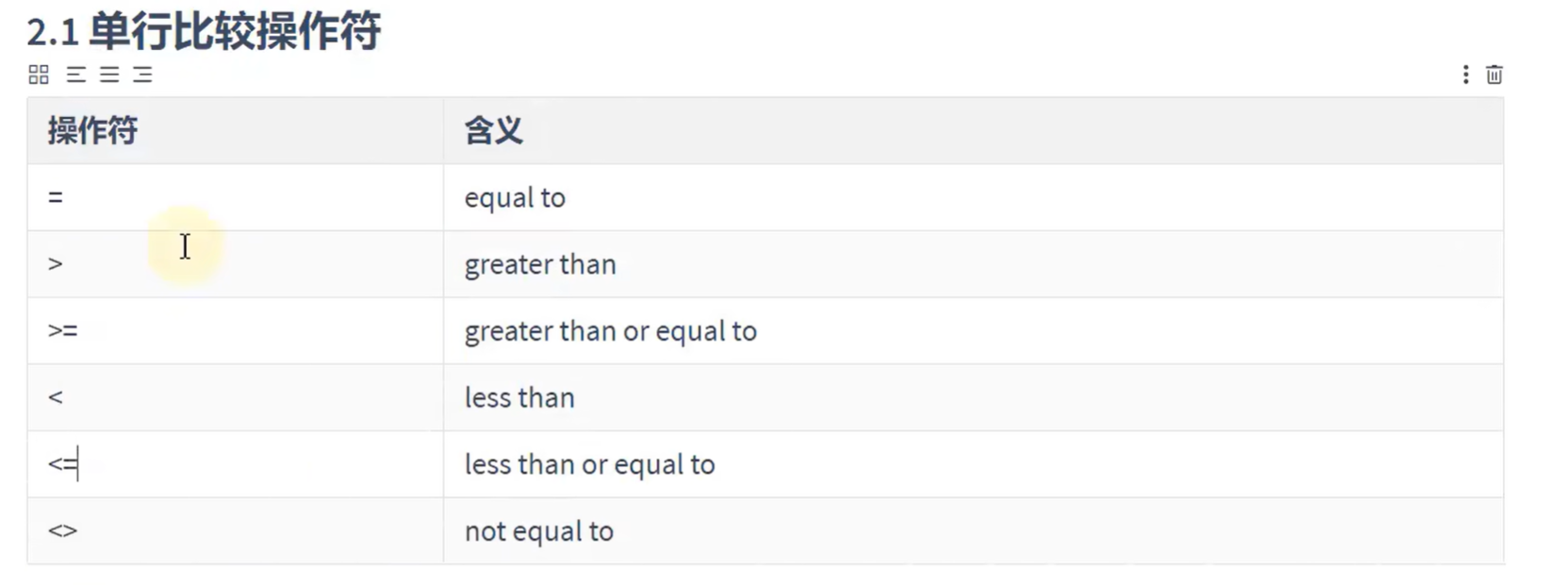
题目1:

SELECT salary,employee_id
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE employee_id = 149
);题目2:
SELECT job_id,salary
FROM employees
WHERE job_id = (
SELECT jopb_id
FROM employees
WHERE employee_id = 141
)
AND
salary > (
SELECT salary
FROM employees
WHERE employee_id = 143
);题目3:

SELECT job_id,last_name,salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);题目4:

SELECT employee_id,manager_id,department_id
FROM employees
WHERE manager_id = (
SELECT manager_id
FROM employees
WHERE manager_id = 141
)
AND department_id = (
SELECT department_id
FROM employees
WHERE department_id = 141
)
AND employee_id != 141;HAVING中的子查询:
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
);CASE中的子查询
题目:显示员工的employee_id,last_name,location.其中如果员工的department_id与location_id是1800的departmnet_id相同,则location_为'Canada',其余为'USA'
SELECT employees_id,last_name,CASE department_id WHEN (SELECT department_id,FROM departments,WHERE location = 1800) THEN
'Canada'
ELSE
'USA'
END AS 'location'
FROM employees;子查询中的空值问题:
如果子查询的结果是空值,那子查询就不会返回任何值,主查询也就不会有结果
非法使用子查询:
如果多行子查询使用了单行子查询的负号,那就是非法使用子查询
多行子查询:
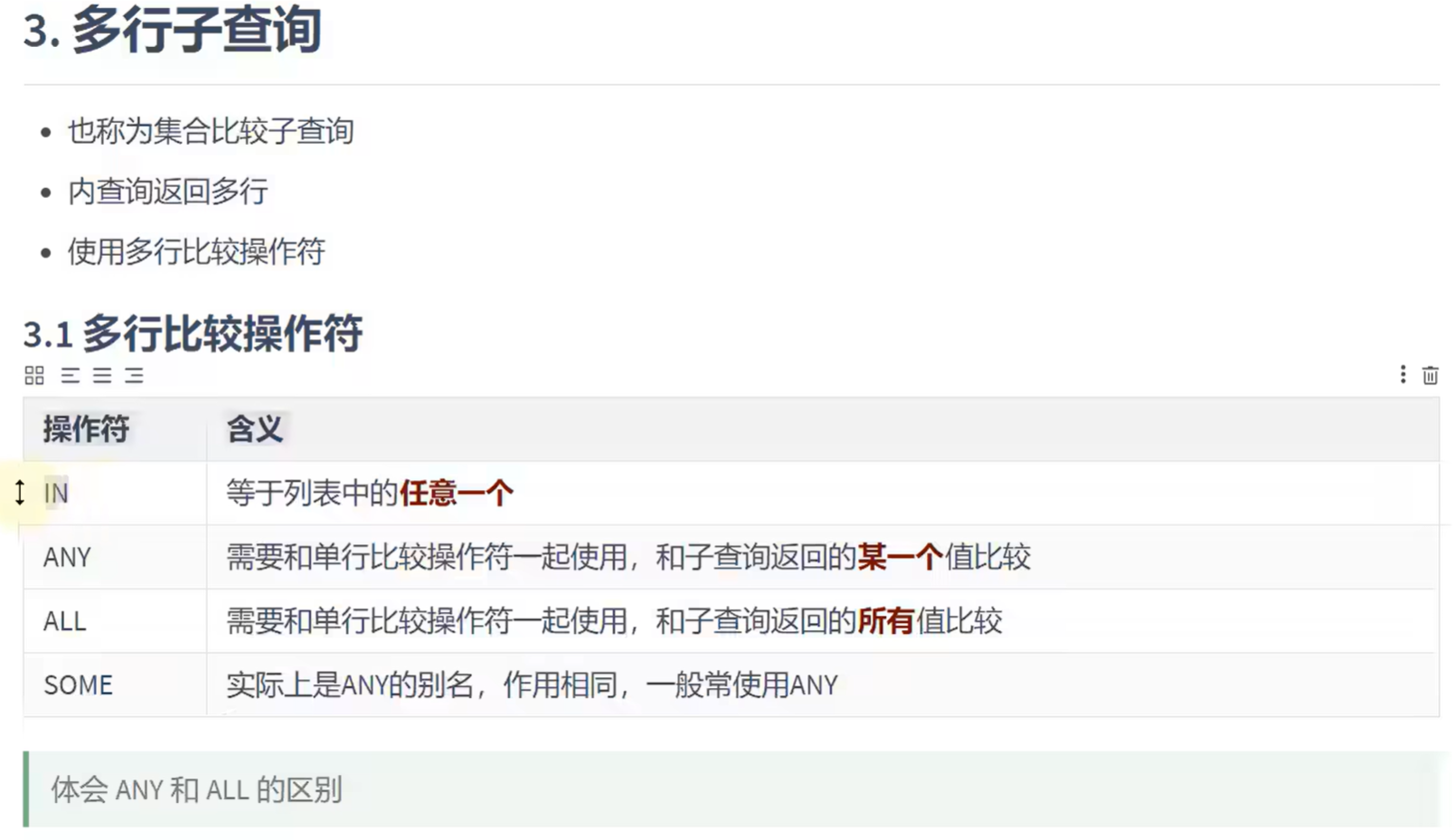
IN举例:

ANY/ALL

SELECT employye_id,first_name,job_id,salary
FROM employees
WHERE salary < ANY (
SELECT salary
FROM employees
WHERE departmnet_name = 'IT_PROG'
)
AND departmnet_name != 'IT_PROG';

SELECT departmnet_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) t_sal_avg
);空值问题:
如果多行查询中有一个结果是空值,那么返回值就是空值,这个时候就要判断这个null值是否是符合条件的值,如果不是,就要使用where筛掉
相关子查询:
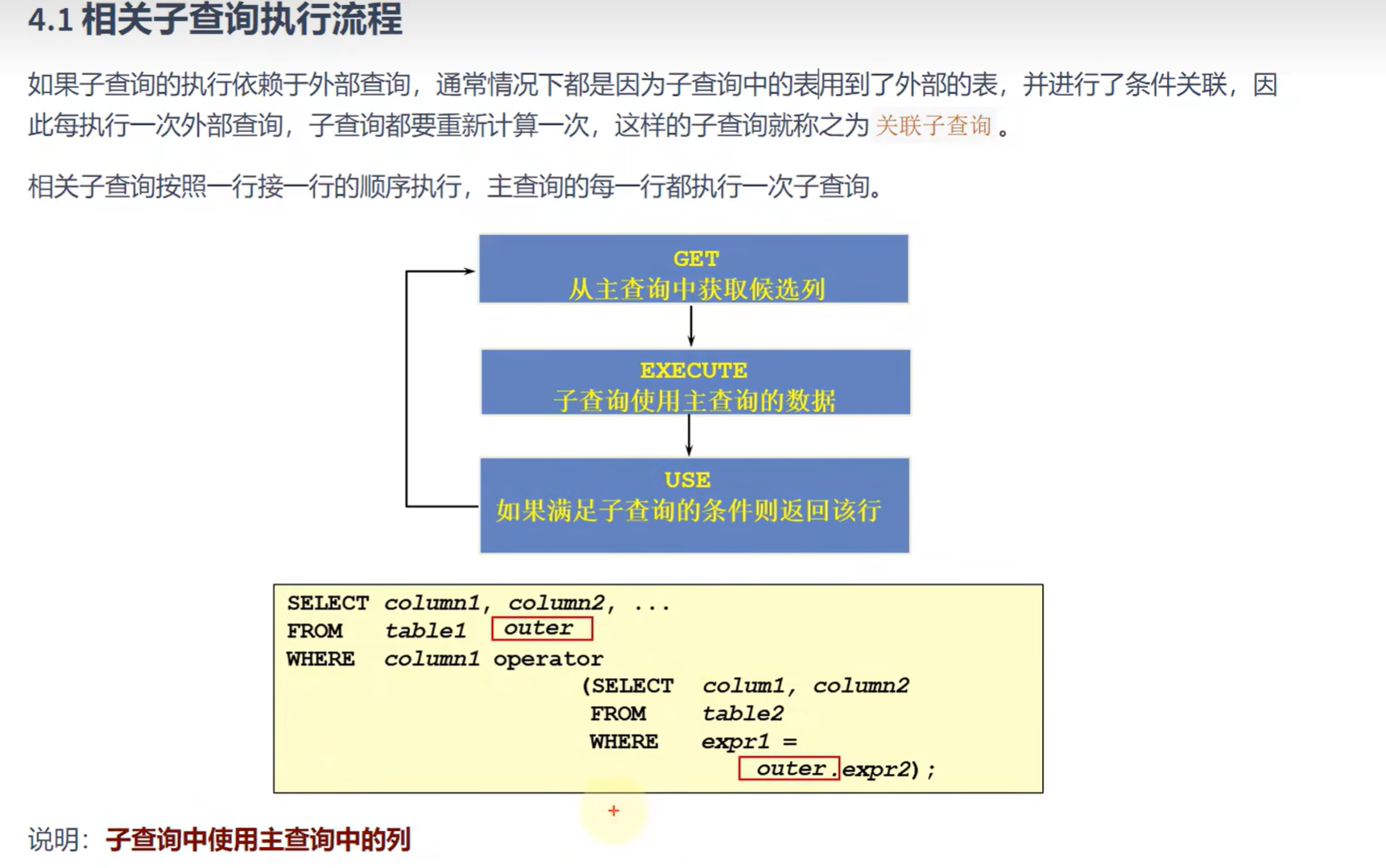
执行流程(逐步拆解)
我们用一个经典的例子来说明:"查找薪资高于其所在部门平均薪资的员工"。
假设有 employees 表,包含 employee_id, name, salary, department_id 等字段。
SQL 语句:
sql
SELECT e1.name, e1.salary, e1.department_id
FROM employees e1
WHERE e1.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e1.department_id -- 关键!子查询引用了外层查询的列);
执行过程如下:
步骤 1:从主查询(外层查询)开始执行
数据库首先执行 FROM employees e1,准备扫描 employees 表(别名为 e1)的每一行。
步骤 2:取出一行候选数据
假设数据库取出第一行数据,我们称它为 当前行 R1。例如:(name='张三', salary=8000, department_id=10)。
步骤 3:执行子查询(依赖于当前行)
数据库将当前行 R1 中的值(这里是 department_id = 10)传递给子查询。
现在,子查询变成一个可以执行的独立查询:
sql
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = 10; -- 使用从主查询传入的值 10
数据库执行这个查询,计算部门 10 的平均薪资。假设结果为 6500。
步骤 4:进行条件判断
主查询的 WHERE 子句现在可以求值:e1.salary > 子查询结果。
对于当前行 R1:8000 > 6500 为 TRUE。
步骤 5:决定是否输出当前行
因为条件为真,所以当前行 R1(张三)被纳入最终结果集。
步骤 6:重复循环
数据库回到 步骤 2,获取主查询的下一行(例如 R2:(name='李四', salary=6000, department_id=10))。
再次执行 步骤 3:将 department_id = 10 传入子查询,计算部门平均薪资(仍然是 6500)。
执行 步骤 4:6000 > 6500 为 FALSE。
执行 步骤 5:此行(李四)被过滤掉,不输出。
这个过程会 循环重复,直到主查询(e1表)的每一行都被处理完毕。对于每一行,子查询都可能被执行一次。
题目1:

SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
);
题目二:

SELECT employee_id,salary
FROM employees e
ORDER BY (
SELECT department_id
FROM departments d
WHERE e.department_id = d.department_id
);小结论:在select语句中,除了order by和LIMIT之外,其他地方都可以使用子查询
练习:

SELECT employee_id,job_id,last_name
FROM employees e
WHERE 2 < (
COUNT(*)
FROM job_history j
WHERE e.employee_id = j.employee_id
);EXISTS和NOT EXISTS关键字:

题目一:

SELECT employee_id,job_id,last_name,department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.employee_id = e2.manager_id
);题目二:

SELECT department_id,department_name
FROM department d
WHERE NOT EXISTS (
SELECT department_id,department_name
FROM employees e
WHERE e.department_id = d.department_id
);课后练习:


# 子查询的课后练习
# 1
SELECT last_name,salary
FROM employees e1
WHERE department_id = (
SELECT first_name
FROM emoloyees e2
WHERE e2.first_name = 'Z'
);
# 2
SELECT employee_id,first_name,salary
FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees
);
# 3
SELECT last_name,job_id,salary
FROM employees e1
WHERE salary > ALL(
SELECT salary
FROM employees e2
WHERE e2.job_id = 'SA_MAN'
);
# 4
SELECT employee_id,last_name
FROM employees
WHERE department_id IN (
SELECT DISTINCT department_id
FROM employees
WHERE last_name LIKE '%u%'
);
# 5
SELECT employee_id
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id = 1700
)
# 6
SELECT last_name,salary
FROM employees
WHERE manager_id IN (
SELECT manager_id
FROM employee
WHERE first_name = King
);
# 7
SELECT last_name,salary
FROM employees
WHERE salary = (
MIN(salary)
FROM employees
)
# 8查询平均工资最低的部门信息
#方式一:
SELECT *
FROM departments
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
HAVING department_id = (
SELECT MIN(min_avg_sal)
FROM (
SELECT AVG(salary) min_avg_sal
FROM employees
GROUP BY department_id
) t_avg_sal;
)
);
#方式二
SELECT d.*
FROM departments d,(
SELECT departmend_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal
LIMIT 0,1
) t_avg_sal
WHERE d.department_id = t_avg_sal.employement_id;
# 9查询平均工资最低的部门信息,以及该部门的平均工资
SELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.department_id) avg_sal
FROM departments
WHERE department_id = (
SELECT department_id
FROM employees
WHERE AVG(salary) = (
SELECT MIN(avg_sal)
FROM(
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) t_avg_sal
)
)
# 10 查询平均工资最高的job信息
SELECT *
FROM jobs
WHERE job_id = (
SELECT job_id
FROM employees
GROUP BY job_id
HAVING AVG(salary) = (
SELECT MAX(avg_sal)
FROM(
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY job_id
)t_avg_sal
)
)
# 11查询平均工资高于公司平均工资的部门有哪些
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING AVG(salary) > (
SELECT AVG(salary)
FROM employees
)
# 13 各个部门中,最高工资中的最低工资的那个部门的最低工资是多少
#方式一:
SELECT MIN(salary)
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY departmemt_id
HAVING MAX(salary) = (
SELECT MIN(max_salary)
FROM(
SELECT MAX(salary) max_salary
FROM employees
GROUP BY department_id
) min_max_sal
)
)
#方式二
SELECT MIN(salary)
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY departmemt_id
HAVING MAX(salary) <= ALL(
SELECT MAX(salary) max_salary
FROM employees
GROUP BY department_id
)
)
#方式三
SELECT MIN(salary)
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY departmemt_id
HAVING MAX(salary) = (
SELECT MAX(salary) max_sal
FROM employees
GROUP BY department_id
ORDER BY max_sal ASC
LIMIT 0,1
)
)
#方式四
SELECT MIN(salary)
FROM employees e,(
SELECT department_id,MAX(salary) max_sal
FROM employees
GROUP BY department_id
ORDER BY max_sal ASC
LIMIT 0,1) t_max_sal
WHERE e.department_id = t_max_sal.department_id;
# 14查询平均工资最高部门的manager信息
#方式一
SELECT last_name,department_id,eamil,salary
FROM employees
WHERE employees IN (
SELECT manager_id
FROM employees
WHERE department_id = (
SELECT depatment_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MAX(avg_sal)
FROM(
SELECT AVG(salary) avg_sal
FROM employees
ORDER BY department_id
) t_avg_sal
)
)
);
#方式三
SELECT last_name,department_id,eamil,salary
FROM employees
WHERE employee_id IN(
SELECT DISTINCT manager_id
FROM employee e,(
SELECT department_id,AVG(salary) AS avg_sal
FROM empolyees
GROUP BY employee_id
ORDER BY avg_sal ASC
LIMIT 0,1
)t_avg_sal
WHERE e.department_id = t_avg_sal.department_id);
# 15 查询部门号,其中不包括job_id是'ST_CLERK'的部门号
#方式一:
SELECT department_id
FROM employees
WHERE job_id NOT IN(
SELECT DISTINCT department_id
FROM employees
WHERE job_id = 'ST_CLERK';
)
#方式二:
SELECT department_id
FROM departments
WHERE NOT EXISTS (
SELECT *
FROM eployees e
WHERE e.department_id = d.department_id
AND e.job_id = 'ST_CLERK'
);
# 16 选择所有没有管理者的员工的last_name
SELECT last_name
FROM employees emp
WHERE NOT EXISTS (
SELECT manager_id
FROM employees mgr
WHERE emp.manager_id = mgr.employee_id
)
# 17查询员工号,姓名,雇佣时间,工资,其中员工的管理者为'De Haan'
SELECT employee_id,first_name,hire_date,salary
FROM employees emp
WHERE manager_id IN (
SELECT employee_id
FROM employees mgr
WHERE last_name = 'De Haan'
);
# 18 查询各部门中工资比本部门平均工资高的员工的员工号,姓名和工资
# 方式一
SELECT last_name,salary,department_id
FROM employees e1
WHERE salalry > (
SELECT AVG(salary)
FROM employees e2
WHERE department_id = e1.department_id
)
# 方式二
SELECT e.last_name,e.salary,e.department_id
FROM employees e, (
SELECT department_id,AVG(salary) avg_sal
FROM employees e2
GROUP BY department_id
)t_avg_sal
WHERE e.department_id = t_avg_sal.department_id
AND e.salary > t_avg_sal.avg_sal
# 19 查询每个部门下的部门人数大于5的部门名称
SELECT employee_name
FROM departments d
WHERE 5 < (
SELECT COUNT(*)
FROM employees e
WHERE d.department_id = e.department_id
);
# 20 查询每个国家下的部门个数大于2的国家编号
SELECT country_id
FROM locations l
WHERE 2 < (
SELECT COUNT(*)
FROM departments d
WHERE l.location_id = d.location_id
);
标识符命名规则:

创建和管理数据库
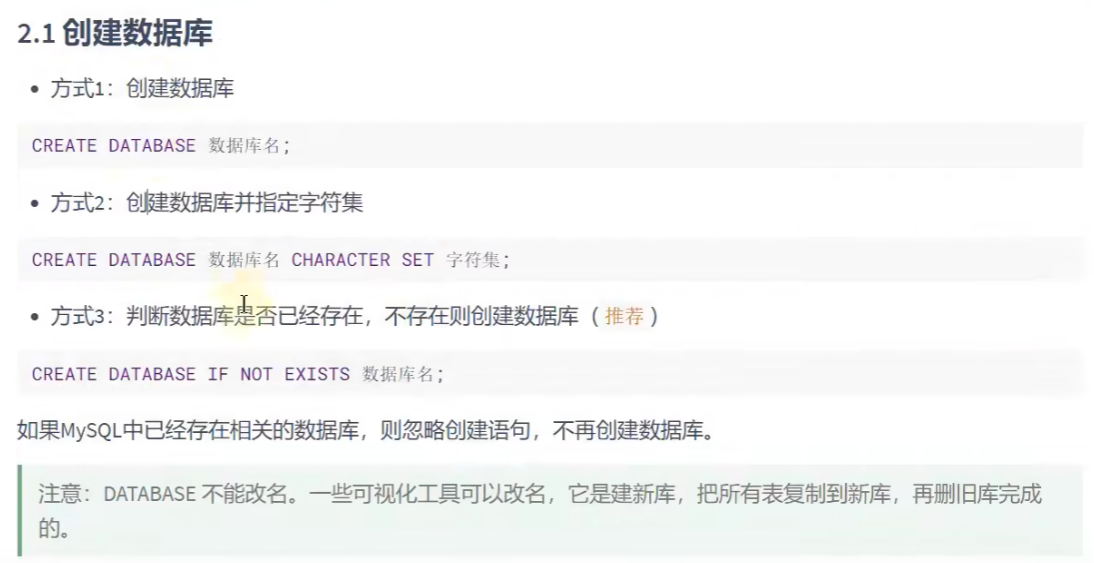
# 1.创建数据库
# 方式一
CREATE DATABASE mytest1; # 用这种方式创建数据库使用的是默认字符集utf8bm4
# 方式二
CREATE DATABASE mytest2 CHARACTER SET 'gbk';# 用这种方式就指定了字符集、
SHOW CREATE DATABASE mytest2;
# 方式三(推荐这种创建方法) 如果要创建的数据库已经存在,那就会创建不成功,但是不会报错
CREATE DATABASE IF NOT EXISTS mytest2 CHARACTER SET 'gbk';
# 如果要创建的数据库不存在,那就创建成功
CREATE DATABASE IF NOT EXISTS mytest3 CHARACTER SET 'utf8';使用数据库
# 使用数据库
# show,查看当前连接中的数据库都有哪些
SHOW DATABASES;
# use,切换数据库
USE dbtest1;
SHOW TABLES;
# 查看当前使用的数据库
SELECT DATABASE() FROM DUAL;
# 查看指定数据库下保存的表
SHOW TABLES FROM mysql;修改数据库
# 删除数据库
DROP DATABASE mytest3;
# 推荐这种方式=,如果数据库存在,则删除成功,如果不存在,则删除失败,但不会报错
DROP DATABASE IF EXISTS mytest3;创建表:
MySQL中的数据类型

常用的数据类型:
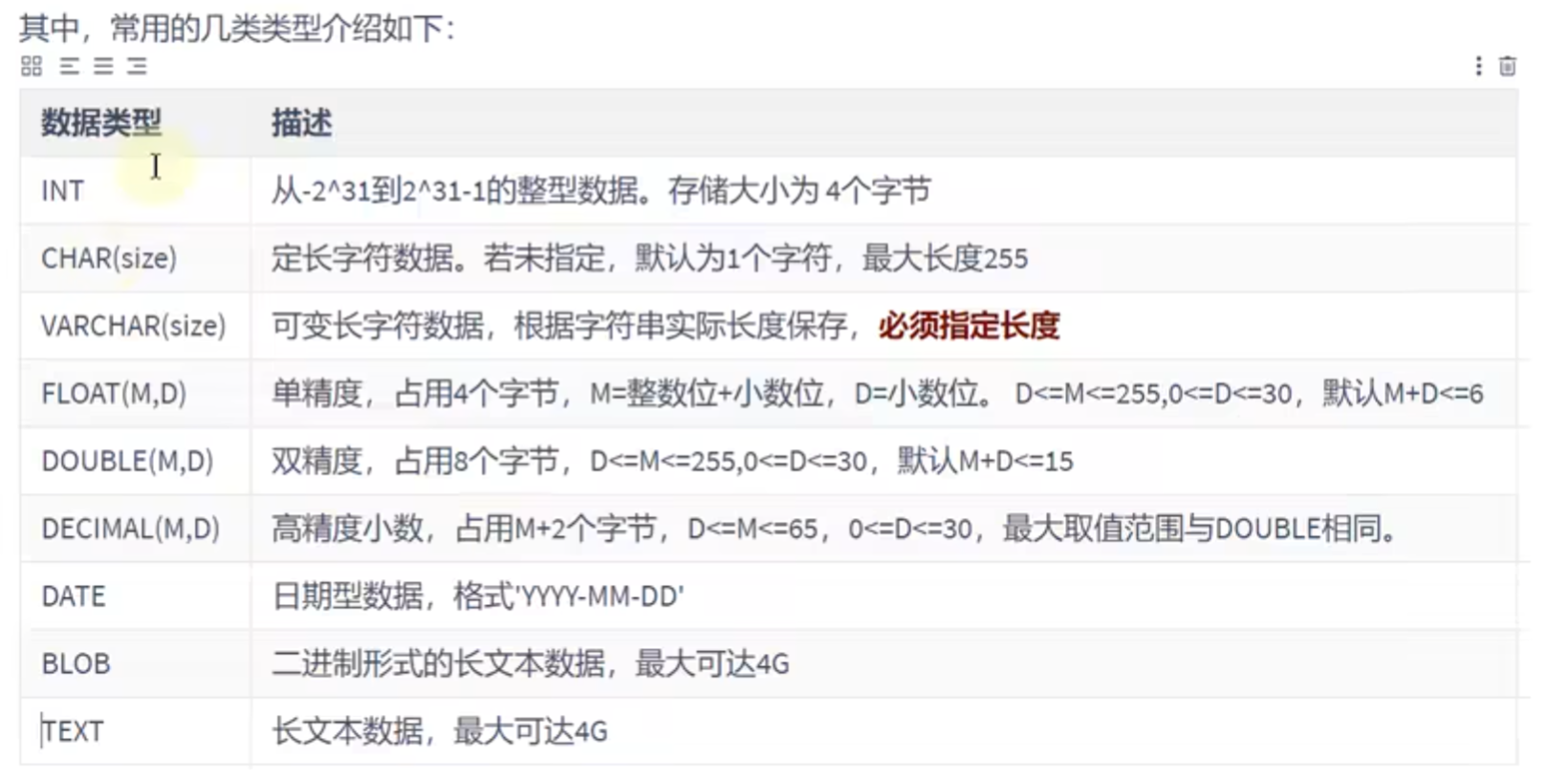
创建表:
# 创建数据表
SHOW CREATE DATABASE dbtest1;
# 方式一
CREATE TABLE IF NOT EXISTS myemp1( # 需要用户有创建表的权限
id INT,
emp_name VARCHAR(15), # 使用varchar来定义字符串,必须在使用varchar时指明其长度
hire_date DATE
);
# 查看表结构
DESC myemp1;
# 查看创建表的语句结构
SHOW CREATE TABLE myemp1;# 如果创建表时没有指明使用的字符集,则默认使用表所在的数据库的字符集
# 方式二:基于现有的表去创建表,同时导入数据
CREATE TABLE myemp2
AS
SELECT employee_id,last_name,salary
FROM employees;
# 这样创建表就会把根据表的信息导入
# 说明1:查询语句中字段的别名,可以作为新创建表的字段的名称
CREATE TABLE myemp3
AS
SELECT e.employee_id emp_id,e.last_name lname, d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;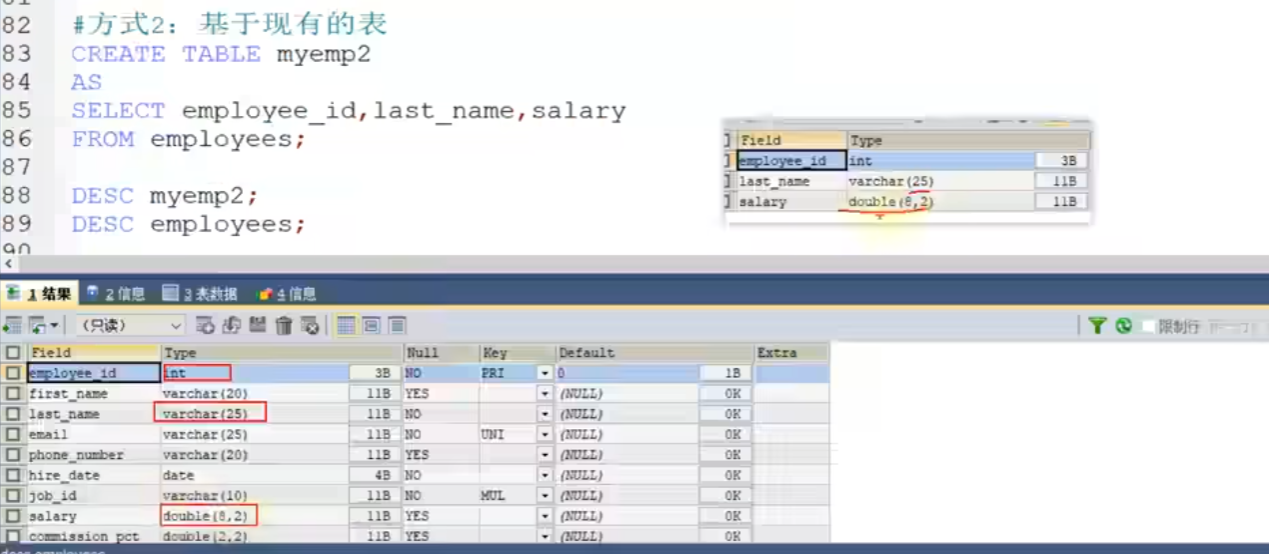
练习:
# 练习1:创建一个表employees_copy,实现对employees表的复制,包括表数据
CREATE TABLE employees_copy
AS
SELECT *
FROM employees;
# 练习2:创建一个表employees_blank,实现对employees表的复制,但是不包括表数据
CREATE TABLE employees_blank
AS
SELECT *
FROM employees
WHERE 1 = 2;#这样子就没有符合条件的信息,所以就没有数据修改表
注意每次修改前都要使用alter,不然会报错
#修改表 -->ALTER TABLE
#添加一个字段 -->用add
ALTER TABLE myemp1
ADD salary DOUBLE(10,2)
DESC myemp1;
ALTER TABLE myemp1
ADD phone_number VARCHAR(20) FIRST;
ALTER TABLE myemp1
ADD 车牌号 VARCHAR(20) AFTER id;
#修改一个字段:数据类型,长度,默认值 -->用modify
ALTER TABLE myemp1
MODIFY emp_name VARCHAR(25);
#重命名一个字段-->用change
ALTER TABLE myemp1
CHANGE 给我擦皮鞋 我要验牌法国口音 DOUBLE(20,15);# 注意这个不能改变数据类型,但是能改变长度
#删除一个字段
ALTER TABLE myemp1
DROP COLUMN 我要验牌法国口音;重命名表
# 重命名表-->使用rename
RENAME TABLE myemp1
TO myemp11;
# 方式二(推荐上面的那种方法)
ALTER TABLE myemp11
RENAME TO myemp12;删除表
# 删除表-->使用drop
DROP TABLE IF EXISTS myemp12;清空表
# 清空表-->只是删除表中的所有数据,但是表结构还是存在的
SELECT *
FROM employees_copy
TRUNCATE TABLE employees_copy;
MySQL命名规范:


课后练习:
练习一:
第十单元练习
# 1 创建数据库test01_office,指明字符集为utf8.并在次数据库下执行下述操作
CREATE DATABASE IF NOT EXISTS test01_office CHARACTER SET 'utf8';
USE test01_office;
# 2创建表dept01(id,NAME)
CREATE TABLE IF NOT EXISTS dept01(
id INT,
`NAME` VARCHAR(25)
)
# 3将表departments中的数据插入新表dept02中
CREATE TABLE IF NOT EXISTS dept02
AS
SELECT *
FROM atguigudb.departments;#(这个表在我们这里没有,假设有这个表的话)
# 4.创建表emp01
CREATE TABLE IF NOT EXISTS emp01(
id INT,
first_name VARCHAR(25),
last_name VARCHAR(25),
dept_id INT
);
# 5.将列last_name的长度增加到50
DESC emp01
ALTER TABLE emp01
MODIFY last_name VARCHAR(50);
# 6.根据表employees创建emp02
CREATE TABLE IF NOT EXISTS emp02
AS
SELECT *
FROM atguigudb.employees;#(同样的,假设这个表存在,且这个表是存在于atguigudb这个数据库下的)
# 7.删除表emp01
DROP TABLE emp01;
# 8.将表emp02重命名为emp01
RENAME TABLE emp02
TO emp01;
# 9.在表dept02和emp01中添加新列test_column,并检查所做的操作
ALTER TABLE emp01
ADD test_column VARCHAR(10);
ALTER TABLE dept02
ADD test_column VARCHAR(10);
# 10.直接删除表emp01中的列department_id
ALTER TABLE emp01
DROP COLUMN department_id;练习二:
# 练习二
# 1.创建数据库test02_market
CREATE DATABASE IF NOT EXISTS test02_market CHARACTER SET 'utf8';
USE test02_market;
# 2.创建数据表customers
CREATE TABLE IF NOT EXISTS customers(
c_num INT,
c_name VARCHAR(50),
c_contact VARCHAR(50),
c_city VARCHAR(50),
c_birth DATE
);
SHOW TABLES;
# 3.将c_contact 字段移动到c_birth字段后面
ALTER TABLE customers
MODIFY c_contact VARCHAR(50) AFTER c_birth;
DESC customers;
# 4.将c_name字段数据类型改为varchar(70)
ALTER TABLE customers
MODIFY c_name VARCHAR(70);
# 5.将c_contact字段改名为c_phone
ALTER TABLE customers
CHANGE c_contact c_phone VARCHAR(50);
# 6.增加c_gender字段到c_name后面,数据类型为char(1)
ALTER TABLE customers
ADD c_gender CHAR(1)
AFTER c_name;
# 7.将表名改为customers_info
RENAME TABLE customers
TO customers_info;
DESC customers_info;
# 8.删除字段c_city
ALTER TABLE customers_info
DROP COLUMN c_city;练习三:
# 练习三
# 1.创建数据库tset03_company
CREATE DATABASE IF NOT EXISTS test03_company CHARACTER SET 'utf8';
USE test03_company;
# 2.创建表offices
CREATE TABLE IF NOT EXISTS offices(
officeCode INT,
city VARCHAR(30),
address VARCHAR(50),
country VARCHAR(50),
postalCode VARCHAR(25)
)
# 3.创建表employees
CREATE TABLE IF NOT EXISTS employees(
empNum INT,
lastName VARCHAR(50),
firstName VARCHAR(50),
mobile VARCHAR(25),
`code` INT,
jobTitle VARCHAR(50),
birth DATE,
note VARCHAR(255),
sex VARCHAR(5)
);
# 4.将表employees的mobile字段修改到code字段后面
ALTER TABLE employees
MODIFY mobile VARCHAR(20) AFTER `code`;
# 5,将表employees的birth字段改名为birthday
ALTER TABLE employees
CHANGE birth birthday DATE;
# 6.修改sex字段,数据类型为char(1)
ALTER TABLE employees
MODIFY sex CHAR(1);
# 7.删除字段node
ALTER TABLE employees
DROP COLUMN note;
# 8.增加字段名favoriate_activity,数据类型为varchar(100)
ALTER TABLE employees
ADD favoriate_activity VARCHAR(100);
# 9.将表employees的名称修改为employees_info
RENAME TABLE employees
TO employees_info;1.插入数据

CREATE TABLE IF NOT EXISTS emp1(
id INT,
`name` VARCHAR(15),
hire_date DATE,
salary DOUBLE(10,2)
);
# 添加数据方式一
# 1.
INSERT INTO emp1
VALUES(1,'妄汐霜','1999-10-1',20000);# 加入字段的顺序要和表中的字段的顺序相同
# 2
INSERT INTO emp1(id,hire_date,salary,`NAME`) # 指明添加的字段的顺序,然后添加字段就按照这个顺序来添加
VALUES(2,'4099-10-1',10000000,'妄竹');
SELECT *
FROM emp1;
# 3 同时插入多组数据
INSERT INTO emp1(id,hire_date,salary,`NAME`)
VALUES
(4,'1999-8-21',1213,'水仙花'),
(5,'2111-12-1',12312,'茉莉花');
# 添加数据方式二:将查询的结果插入到表中
INSERT INTO emp1(id,salary,hire_date,`NAME`)
# 查询语句
SELECT employee_id,salary,hire_date,last_name # 查询的字段要和添加的字段的顺序对应
FROM employees
WHERE department_id IN (50,60);
#说明:用这种方式添加数据时,要确保查询出来的数据的表的字段的长度要比添加进表的字段的长度要小
#如果查询出来的字段的长度会大于添加进的表的长度,那么可能就会添加失败2,更新数据
# 更新数据
# update set where
UPDATE emp1
SET hire_date = CURDATE()
WHERE `NAME` = '妄竹';
SELECT *
FROM emp1;
# 同时修改一条数据的多个字段
UPDATE emp1
SET hire_date = CURDATE(),salary = 100000
WHERE `NAME` = '妄竹';3.删除数据
# 删除数据 delete from ......where
DELETE FROM emp1
WHERE id = 2;MySQL8新特性:计算列


综合练习:
1.创建数据库test01_library
CREATE DATABASE IF NOT EXISTS test01_library CHARACTER SET 'utf8';
USE test01_library;
# 2创建表books
CREATE TABLE IF NOT EXISTS books(
id INT,
`name` VARCHAR(50),
`authors` VARCHAR(100),
price FLOAT,
pubdate YEAR,
note VARCHAR(100),
num INT
);
# 3向books表中添加数据
# 1.不指定字段名称,插入第一条数据
INSERT INTO books
VALUES(1,'Tal of AAA','Dicks',23,'1995','novel',11);
# 2.指定所有字段名称,插入第二条数据
INSERT INTO books(id,`NAME`,`authors`,price,pubdate,note,num)
VALUES(2,'EmmaT','Jane llura',35,'1993','joke',22);
# 3.同时插入多条记录(剩下的所有记录)
INSERT INTO books(id,`NAME`,`authors`,price,pubdate,note,num)
VALUES
(3,'Story of Jane','Jane Tim',40,'2001','novel',0),
(4,'Lovey Day','George Byron',20,'2005','novel',30),
(5,'Old land','Honore Blade',30,'2010','law',0),
(6,'The Battle','Upton Sara',30,'1999','medicine',40),
(7,'Rose Hood','Richard haggard',28,'2008','cartoon',28);
SELECT *
FROM books;
# 4.将小说类型的书的价格都增加5
UPDATE books
SET price = price + 5
WHERE note = 'novel';
# 5.将名称为EmmaT的数的价格改为40,并将说明改为drama
UPDATE books
SET price = 40,note = 'drama'
WHERE `name` = 'EmmaT';
# 6删除库存为0的记录
DELETE FROM books
WHERE num = 0;
# 7.统计书名中包含a字母的书
SELECT `NAME`
FROM books
WHERE `NAME` LIKE '%a%';
# 8.统计书名中包含a字母的书的数量和库存总量
SELECT COUNT(*),SUM(num)
FROM books
WHERE `NAME` LIKE '%a%';
# 9.找出'novel'类型的书,按照价格降序排序
SELECT *
FROM books
WHERE note ='novel'
ORDER BY price DESC;
# 10.查询图书的信息,按照库存量降序排序,如果库存量相同的按照note升序排列
SELECT *
FROM books
ORDER BY num DESC,note ASC;
# 11.按照note分类统计书的数量
SELECT note,COUNT(*)
FROM books
GROUP BY note;
# 12.按照note分类统计数的库存量,显示库存量超过30本的
SELECT note,SUM(num)
FROM books
GROUP BY note
HAVING SUM(num) > 30;
# 13.查询所有图书,每页显示5本,显示第二页
SELECT *
FROM books
LIMIT 5,5;
# 14.按照note分类统计书的库存量,显示库存量最多的
SELECT note,SUM(num)
FROM books
GROUP BY note
ORDER BY SUM(num) DESC
LIMIT 0,1;
# 15.查询书名达到10个字符的书,不包括里面的空格
SELECT `NAME`
FROM books
WHERE CHAR_LENGTH(REPLACE(`NAME`,' ','')) >= 10;
# 16.查询书名和类型,其中note值为novel显示小说,law显示法律,madicine显示医药,cartoon显示卡通,joke显示笑话
SELECT `NAME`,note,CASE note
WHEN 'novel' THEN '小说'
WHEN 'law' THEN '法律'
WHEN 'madicine' THEN '医药'
WHEN 'cartoon' THEN '卡通'
WHEN 'joke' THEN '笑话'
ELSE "其他"
END "类型"
FROM books;
# 17.查询书名,库存,其中num值超过30本的,显示滞销,大于0并低于10的,显示畅销,为0的显示无货
SELECT `NAME`,num ,CASE WHEN num > 30 THEN '滞销'
WHEN num > 0 AND num < 10 THEN '畅销'
WHEN num = 0 THEN '无货'
ELSE '正常'
END "显示状态"
FROM books;
# 18.统计每一种note的库存量,并合计总量
SELECT IFNULL(note,'库存总量') AS note,SUM(num)
FROM books
GROUP BY note WITH ROLLUP;
# 19.统计每一种note的数量,并合计总量
SELECT IFNULL(note,'库存总量') AS note, COUNT(*)
FROM books
GROUP BY note WITH ROLLUP;
# 20.统计库存量前三名的图书
SELECT *
FROM books
ORDER BY num DESC
LIMIT 0,3;
# 21.找出最早版本的一本书
SELECT *
FROM books
ORDER BY pubdate ASC
LIMIT 0,1;
# 22.找出novel中价格最高的一本书
SELECT *
FROM books
WHERE note = 'novel'
ORDER BY price DESC
LIMIT 0,1;
# 23.找出书名中字数最多的一本书,不包含空格
SELECT *
FROM books
ORDER BY CHAR_LENGTH(REPLACE(`NAME`,' ','')) DESC
LIMIT 0,1;课后练习:
练习1:
# 1.创建数据库dbtest11
CREATE DATABASE IF NOT EXISTS dbtest11 CHARACTER SET 'utf8';
USE dbtest11;
# 2.创建表my_employees,users
CREATE TABLE my_employees(
id INT(10),
first_name VARCHAR(10),
last_name VARCHAR(10),
userid VARCHAR(10),
salary DOUBLE(10,2)
);
CREATE TABLE users(
id INT,
userid VARCHAR(10),
department_id INT
)
# 3.显示表结构
DESC my_employees;
DESC users;
# 4.向my_employees表中插入下列数据
INSERT INTO my_employees(id,first_name,last_name,userid,salary)
VALUES
(1,'patel','Ralph','Rpatel',895),
(2,'Dancs','Betty','Bdancs',860),
(3,'Biri','Ben','Bbiri',1100),
(4,'Newman','Chad','Cnewman',750),
(5,'Ropeburn','Audrey','Aropebur',1550);
SELECT * FROM my_employees;
# 5.向users表中插入数据
INSERT INTO users
VALUES
(1,'Rpatel',10),
(2,'Bandcs',10),
(3,'Bbiri',20),
(4,'Cnewman',30),
(5,'Aropebur',40);
SELECT * FROM users;
# 6.将3号员工的last_name修改为'drelxer'
UPDATE my_employees
SET last_name = 'drelxer'
WHERE id = 3;
# 7.将所有工资少于900的员工的工资修改为1000
UPDATE my_employees
SET salary = 1000
WHERE salary < 900;
# 8.将userid为Bbiri的user表和my_employees表的记录全部删除
DELETE FROM my_employees
WHERE userid = 'Bbiri';
DELETE FROM users
WHERE userid = 'Bbiri';
#方式二
DELETE m,u
FROM my_employees m
JOIN users u
ON m.userid = u.userid
WHERE m.userid = 'Bbiri';
# 9.删除my_employees,users表中所有数据
DELETE FROM my_employees;
DELETE FROM users;
# 11.清空表my_employees
TRUNCATE TABLE my_employees;练习2:
# 练习2:
#1.使用现有数据库dbtest11
USE dbtest11;
#2.创建表格pet
CREATE TABLE IF NOT EXISTS pet(
`name` VARCHAR(20),
`owner` VARCHAR(20),
species VARCHAR(20),
sex CHAR(1),
birth YEAR,
death YEAR
);
#3.添加记录
INSERT INTO pet(`NAME`,`Owner`,species,sex,birth,death)
VALUES
('Fluffy','harold','Cat','f','2003','2010'),
('Claws','gwen','Cat','m','2004',NULL),
('Buffy',NULL,'Dog','f','2009',NULL),
('Fang','benny','Dog','m','2000',NULL),
('bowser','diane','Dog','m','2003','2009'),
('Chirpy',NULL,'Bird','f','2008',NULL);
SELECT *
FROM pet;
#4.添加字段:主人的生日 owner_birth date类型
ALTER TABLE pet
ADD owner_birth DATE;
#5.将名称为Claws的猫的主人改为kevin
UPDATE pet
SET `owner` = 'kevin'
WHERE `NAME` = 'Claws' AND species = 'Cat';
#6.将没有死的狗的主人改为duck
UPDATE pet
SET owner = 'duck'
WHERE death IS NULL AND species = 'Dog';
#7.查询没有主人的宠物的名字
SELECT `NAME`
FROM pet
WHERE `Owner` IS NULL;
#8.查询已经死了的cat的姓名,主人,以及去世时间
SELECT `NAME`,`Owner`,death
FROM pet
WHERE death IS NOT NULL;
#9.删除已经死亡的狗
DELETE FROM pet
WHERE death IS NOT NULL AND species = 'Dog';练习3:
# 练习3
#1.使用dbtest11
USE dbtest11
#2.创建表employee,并添加数据、
CREATE TABLE IF NOT EXISTS employee(
id INT,
`name` VARCHAR(20),
sex CHAR(1),
tel VARCHAR(25),
addr VARCHAR(35),
salary DOUBLE(10,2)
);
SELECT * FROM employee;
INSERT INTO employee
VALUES
(10001,'张一一','男','13456789000','仙女座右旋臂',1001.58),
(10002,'刘小红','女','134543129000','银河系长城系右城3',1201.21),
(10003,'李四','男','0756542345','人马座头角三',1004.11),
(10004,'刘小强','男','243455654234','大角星地底三层',1501.23),
(10005,'王艳','女','1324576554','蓝百星',12405.16);
#3.查出薪资在1200-1300之间的员工的信息
SELECT *
FROM employee
WHERE salary > 1200 AND salary < 1300;
#4.查询出姓刘的员工的工号,姓名,家庭住址
SELECT id,`NAME`,addr
FROM employee
WHERE `NAME` LIKE '%刘%';
#5.将李四的家庭住址改为蓝百姓归墟
UPDATE employee
SET addr = '蓝白星归墟'
WHERE `NAME` = '李四';