微服务容错设计:Sentinel 全局异常处理与 Feign 降级策略的边界权衡
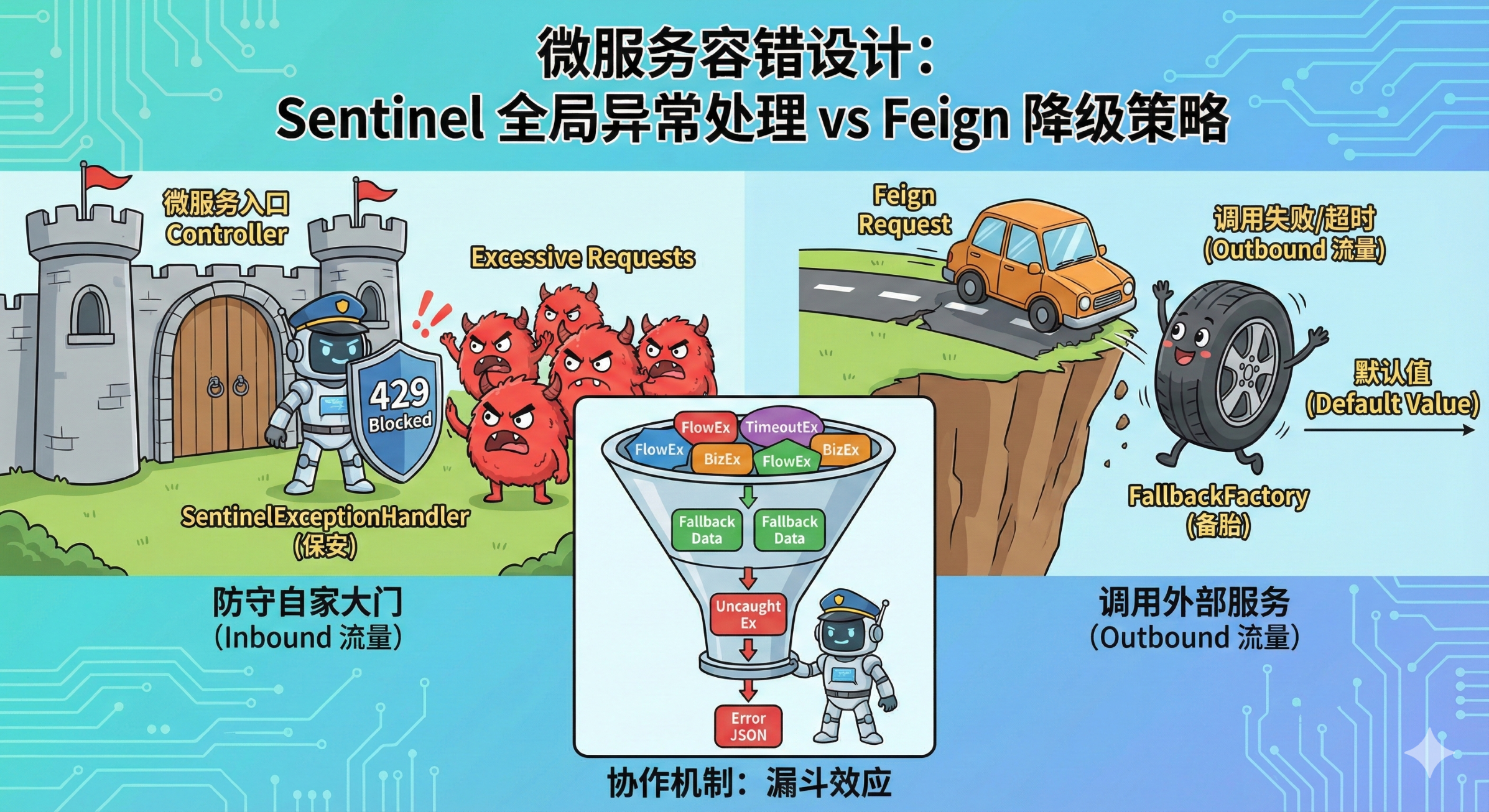
在 Spring Cloud Alibaba 的实战落地中,Sentinel 和 Feign 的整合几乎是标配。但在异常处理的环节,我发现团队成员经常对两个概念产生混淆:SentinelExceptionHandler(全局异常处理) 和 UserClientFallbackFactory(Feign 降级工厂)。
很多人的疑问在于:"既然 FallbackFactory 已经拦截了异常并降级了,那还需要全局异常处理器干什么?它们的功能不是重复了吗?"
或者更进一步的误解:"FallbackFactory 是不是只捕获 Sentinel 抛出的 DegradeException(降级异常)?"
这篇文章将从源码和架构设计的角度,彻底厘清这两者的职责边界与协作模式。
一、 纠正认知:FallbackFactory 是"全能兜底",而非"降级专用"
首先要纠正一个常见的误区:不要被 DegradeException(熔断降级异常)这个名字误导。
在 Feign 的执行链条中,FallbackFactory 扮演的是一个 Catch-All(全量捕获) 的角色。只要 Feign 的调用过程中出现了异常,都会进入 create(Throwable throwable) 方法。
这个 throwable 包含但不限于以下三类:
- Sentinel 阻断异常 :
FlowException(限流)DegradeException(熔断)ParamFlowException(热点参数)AuthorityException(授权规则)
- Java 基础设施异常 :
java.net.SocketTimeoutException(网络超时)java.io.IOException(IO 错误)
- 业务/远程异常 :
- 远程服务返回 HTTP 500 导致的
FeignException。
- 远程服务返回 HTTP 500 导致的
代码实战: 在 Fallback 中,我们通常需要通过 instanceof 来判断具体原因,但无论原因如何,最终目的是返回兜底数据,保证流程不中断。
java
@Component
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
// 1. 区分异常类型仅仅为了打日志或做监控
if (throwable instanceof FlowException) {
log.error("【被限流】并发过高");
} else if (throwable instanceof TimeoutException) {
log.error("【超时】网络抖动");
} else {
log.error("【其他异常】", throwable);
}
// 2. 核心动作:吞掉异常,返回"空对象"或"默认值"
// 这意味着上层业务感知不到发生了异常
return new User();
}
};
}
}二、 核心差异:保安 vs 备胎
既然 Fallback 都能处理,为什么还需要 SentinelExceptionHandler?因为它们防御的阵地完全不同。
我们可以用一个形象的比喻:
- SentinelExceptionHandler (Web层) 是**"保安"**:负责把守大门。如果外部请求太猛,直接把人拒之门外(返回 429)。
- UserClientFallbackFactory (Feign层) 是**"备胎"**:负责内部维稳。如果我调用的下游服务挂了,立马换上备用方案(返回默认值),确保我自己的业务不崩。
1. 场景 A:防守自家大门(Inbound 流量)
触发点 :前端请求你的 OrderController。 规则 :配置在 OrderController 的 URL 上。
如果你的服务被限流,请求还没进到业务逻辑就被 Sentinel 拦截。此时,Feign 根本没机会执行。 结果 :BlockException 直接抛出,由 SentinelExceptionHandler 捕获,返回 JSON 格式的错误提示(如 "系统繁忙,请稍后")。
2. 场景 B:调用外部服务(Outbound 流量)
触发点 :你的 Service 内部执行 userClient.findById()。 规则:配置在 Feign 接口上。
如果调用失败(无论是被限流还是网络超时),Feign 内部会捕获异常并转交给 FallbackFactory。 结果 :Fallback 返回一个 new User() 对象。你的 Service 拿到的是一个合法的对象,代码继续往下执行。
三、 协作机制:漏斗效应
大家最关心的逻辑冲突问题:"异常到底去哪了?"
这其实是一个漏斗过滤 的过程。FallbackFactory 是第一道滤网,ExceptionHandler 是最后一道大坝。
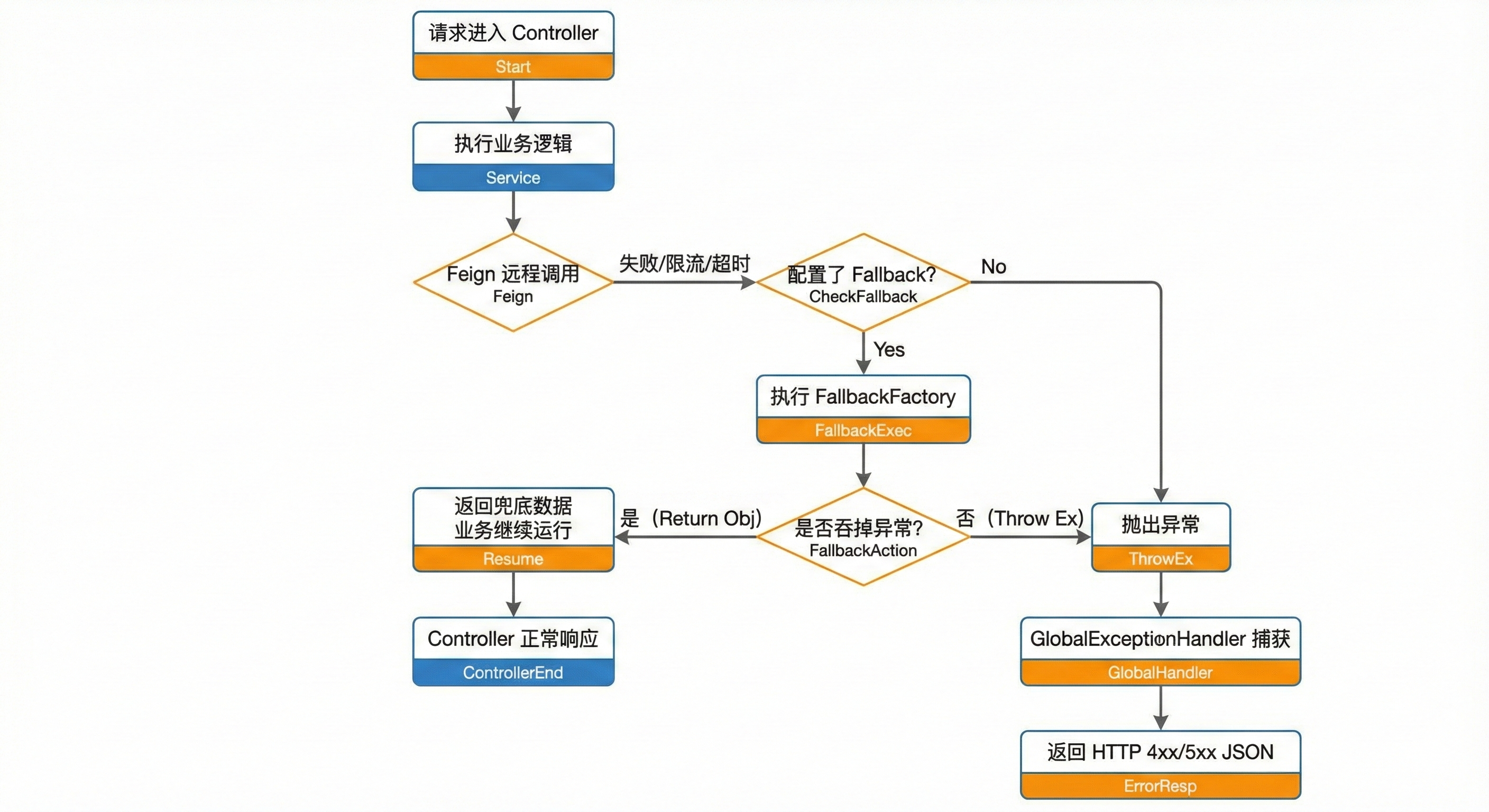
关键结论:
- 被吞掉的异常 :如果
FallbackFactory正常处理并返回了对象,那么异常在 Service 层就被"消化"了。Controller 拿到的是正常数据,ExceptionHandler根本感知不到异常的存在。 - 漏网之鱼 :如果没配 Fallback,或者 Fallback 内部显式抛出了异常(
throw new RuntimeException(e)),异常才会穿透 Service 层,最终被全局异常处理器捕获。
四、 决策建议
在实际工程中,如何权衡这两者的使用?
- 对内调用(Feign)优先降级 : 对于依赖性的内部调用(如查询用户信息、积分信息),尽量使用
FallbackFactory返回默认值(如空用户、0积分)。因为我们不希望仅仅因为"查不到头像"这种次要功能的失败,导致整个"下单流程"回滚。 - 对外接口(Controller)必须报错 : 对于前端直接调用的接口,如果触发限流,必须使用
ExceptionHandler返回明确的 429 状态码。绝对不能默默返回一个空 JSON,否则前端会误以为请求成功,导致用户困惑。 - 区分"可降级"与"不可降级"异常 : 在
FallbackFactory中,对于FlowException(限流)或TimeoutException可以降级;但对于某些关键性的业务错误(如数据库约束异常),建议在 Fallback 中重新抛出,交给全局异常处理来报警和中断事务。
理解了"保安"与"备胎"的区别,你就能在微服务复杂的调用链中,构建出既有韧性(Resilience)又有明确反馈(Feedback)的健壮系统。