背景
大模型(Large Language Models, LLM)能力的不断提升推动了大模型智能体(Agents)的发展。大模型智能体是能够感知环境、规划任务和执行行动的智能实体。与仅对用户输入做出响应的传统人工智能模型不同,当前的大模型智能体能接入各种工具、记忆、知识源,在与环境互动的过程中反思自身并自我进化。进一步地,基于大模型的多智能体系统(Multi-Agent Systems, MAS)也随之出现,能够利用多个智能体的集体智慧与技能。相比单智能体系统,多智能体系统能更加有效地模拟复杂的现实世界环境,在诸多社会领域中具有更强的应用潜力,如多学科会诊、人工智能操作系统(AIOS)等。
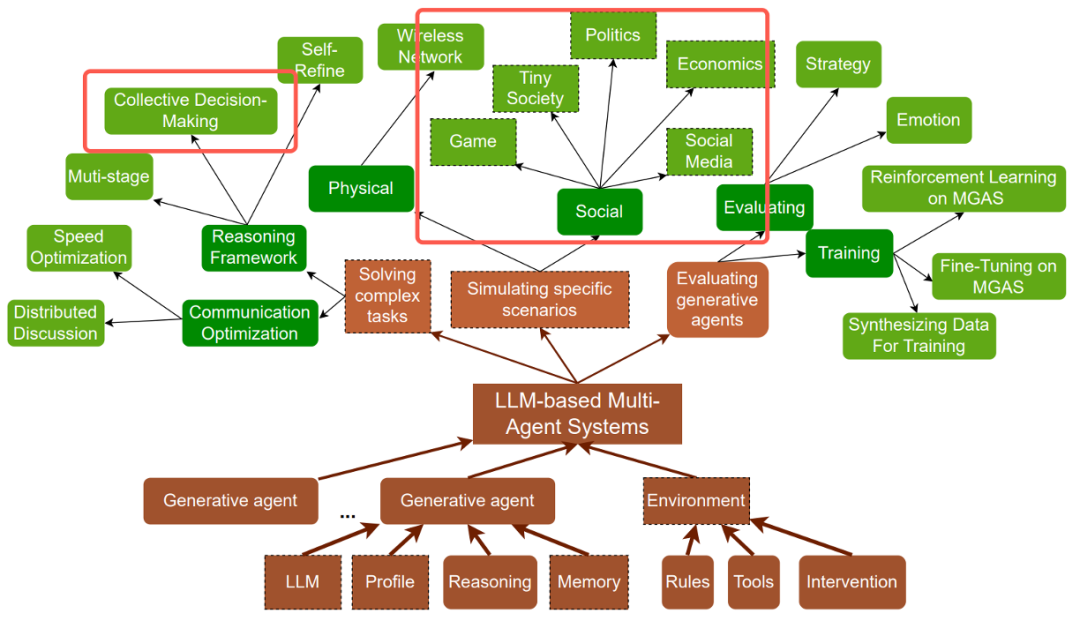
然而,基于大模型的多智能体系统也具有更多的故障模式。级联的智能体之间容易发生错误传播与扩散现象,对多智能体的整体性能提出了考验。因此,本文将探讨可能存在的错误模式,以及现有的故障定位方法。
故障模式
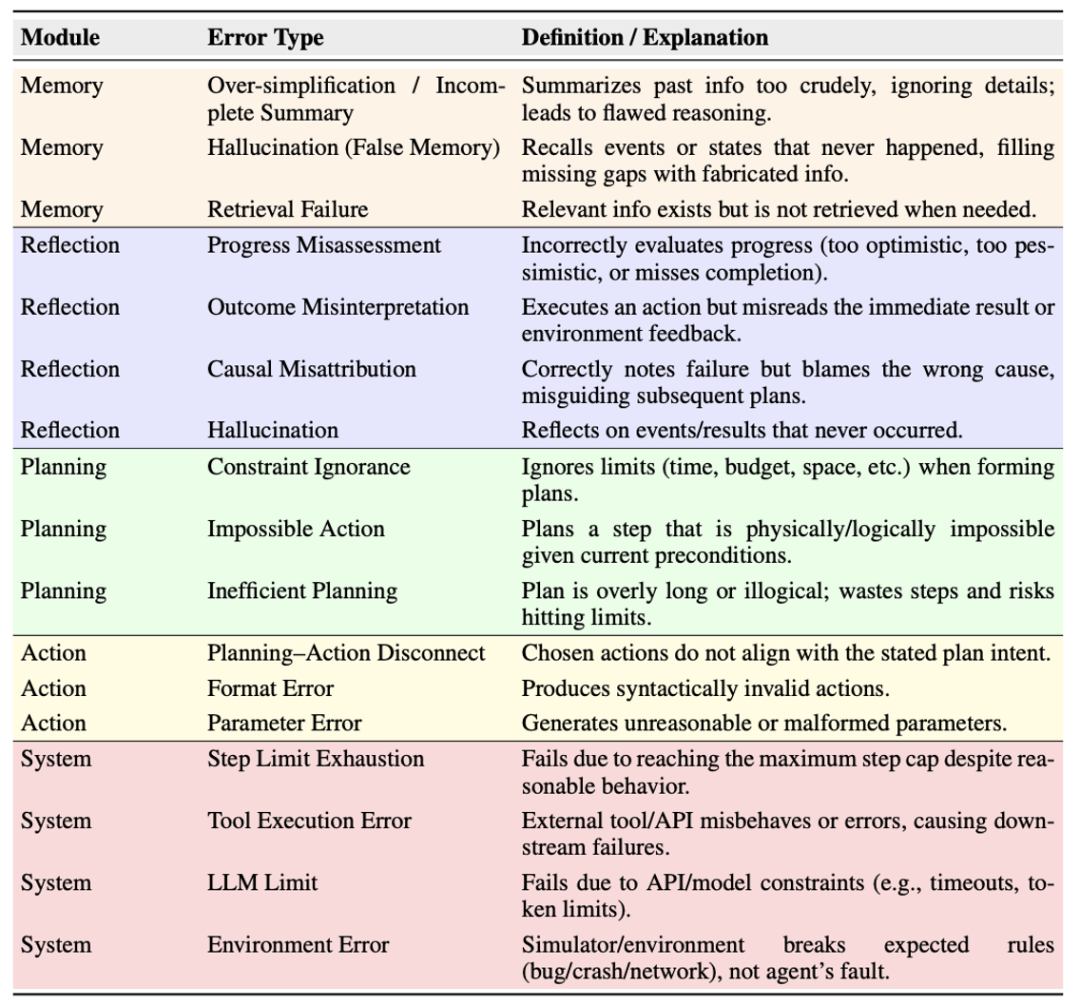
AgentErrorTaxonomy
Zhu 等人从 ALFWorld、WebShop 和 GAIA 收集了 500 条多智能体系统的失败轨迹。他们发现,错误传播是多智能体系统可靠性的主要瓶颈。错误通过级联扩散到后续步骤中时会扭曲推理并加剧误判,最终破坏整个轨迹。基于这个发现,作者将重复出现的故障总结为五个模块并构建了智能体错误分类学 AgentErrorTaxonomy。前四个类别为大模型智能体的各类操作,包括记忆、反思、规划、行动,最后一项为系统级的故障模式。
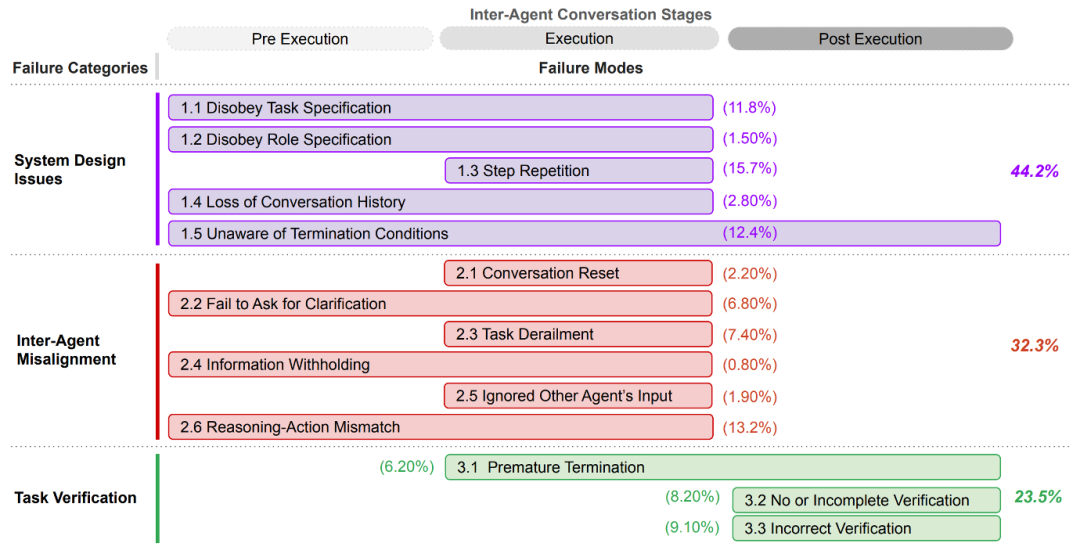
MAST
Cemri 等人基于五种开源框架所产生的轨迹,结合六名标注者构建了多智能体故障分类学 Multi-Agent System Failure Taxonomy(MAST)。不同于 AgentErrorTaxonomy,MAST 更多从智能体系统的角度出发探讨相关故障。其中,系统设计(System Design)类问题主要源于多智能体架构本身的缺陷,而非单个模型的推理能力不足,例如智能体没有遵守任务、角色的系统指令,智能体动作步骤的忽视、重复等。而智能体间的不对齐(Inter-Agent Misalignment)则导致了智能体的通信故障,包括信息传输过程中的忽视、丢失等问题。此外,由于轨迹可能过长,中间步骤缺乏正确性评估以及对错误的任务校验(Task Verification)同样可能导致错误。
作者发现,大量的故障并非源于底层模型的能力问题,而是源于系统设计问题。例如,不合理的通信协议或模糊的角色分工导致了错误的传播。此时,智能体很难准确地评估其它智能体的信息需求。因此,需要增强智能体的上下文推理能力与社会推理能力,防止出现智能体拥有解决问题所需的关键信息,但未能将其有效传递给负责执行的智能体的信息扣留(Information Withholding)问题。
故障定位
任务定义:对于最终出错的多智能体行动轨迹,定位故障的根源,包括确定导致任务失败的智能体(Agent-Level),以及决定性的错误发生的步骤位置(Step-Level)。
通过以上的故障归因任务定义,可以将现有的故障定位方法大致分为三类,分别为基于大模型判官的方法、基于轨迹内信息挖掘的方法与基于多个轨迹联合比对的方法:
基于大模型判官的方法
基于大模型的判官(LLM-as-a-Judge)是一种典型的故障定位方法。考虑到构建大量专家注释的多智能体轨迹数据用于监督微调成本昂贵,并且智能体在缺乏外部反馈的情况下难以知道自己是否犯错以及犯了什么错误,Men 等人采用奖励模型提供步骤级别的奖励来评估智能体行为,如下图所示。奖励模型可以用于评估整个轨迹的好坏,以及辅助步骤级的搜索以探索更高的得分路径,是一种即插即用的方法。
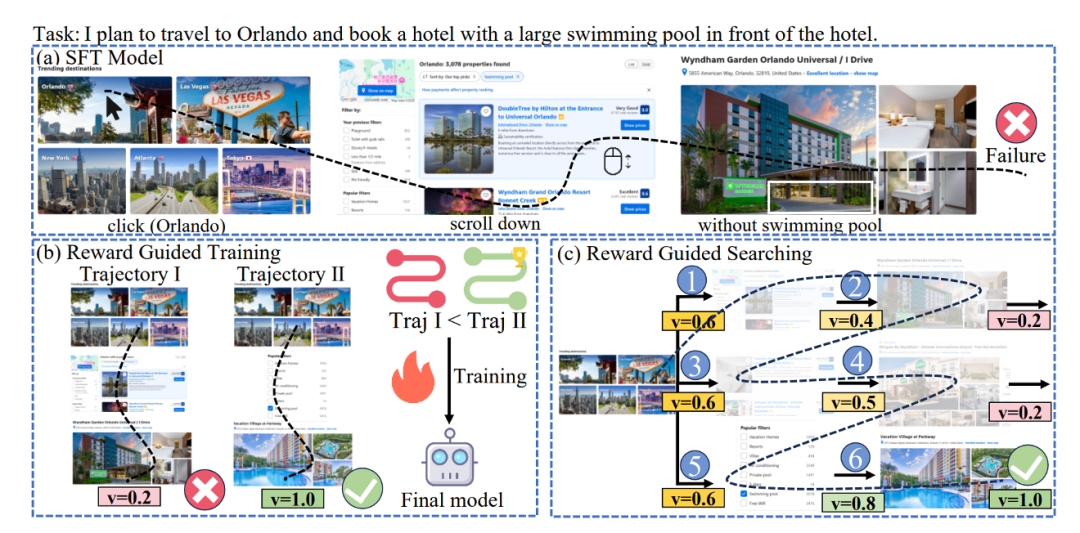
然而,即便是具备强大推理能力的 SOTA 模型,在处理长轨迹的因果推理时也经常失败。因此,为大模型判官合成用于微调的训练数据是自然的想法。Zhang 等人采用了两种方式合成轨迹。首先,采用反事实回放(Counterfactual Replay)技术处理失败轨迹,系统从第一步开始,依次将每一步的智能体行为替换为理想的正确行为,并重新模拟后续所有步骤。一旦在某一步替换后,任务结果由失败转为成功,该步骤即被自动标注为决定性错误的发生点。同时,系统采用程序化故障注入(Programmatic Fault Injection)技术处理成功的执行轨迹,系统在其中选择一个关键步骤,通过修改代码返回值、颠倒逻辑判断等方式引入一个错误,从而生成一个失败且具有准确根源步骤的合成样本。
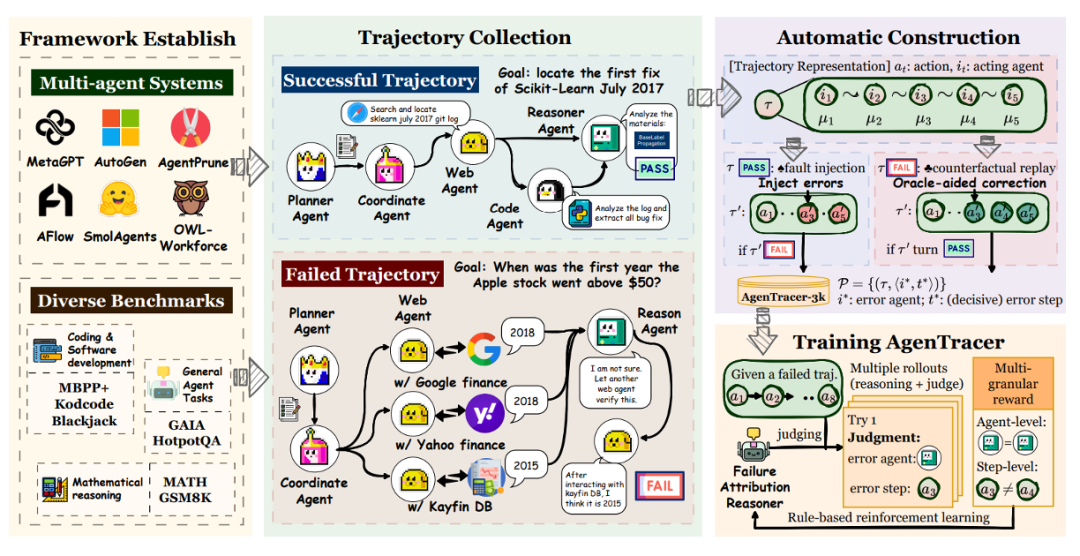
在构建了合成轨迹后,作者采用GRPO训练大模型判官,其中奖励函数设计包含格式奖励、智能体级别奖励(是否判断对智能体)与步骤级别奖励(与预测步骤同真实步骤间的距离相关)。

基于轨迹内信息挖掘的方法
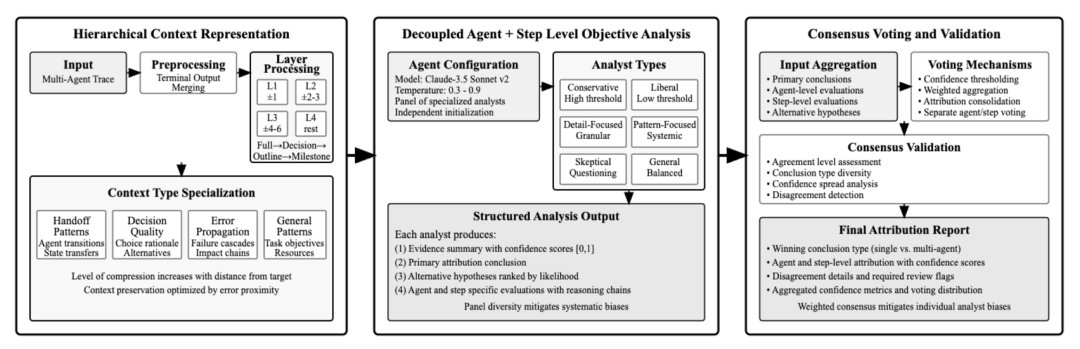
Banerjee 等人10认为,传统的故障归因方法通常将针对步骤的分析限制在其直接的邻居上,带来了严重的局限性。这个狭窄的分析窗口无法捕捉到远程依赖关系,例如错误会在多个步骤中传播、错误在数个步骤后显现等现象。因此,作者设计了Immediate Context Layer、Local Context Layer、Distant Context Layer、Global Context Layer共四个不同粒度的摘要和压缩分层,用于为每个步骤捕捉不同长度的依赖关系。同时,作者引入了用于归因的多智能体框架,通过分层的上下文评估完整的交互轨迹。最终,通过多智能体投票机制确保故障归因反映了集体智慧。
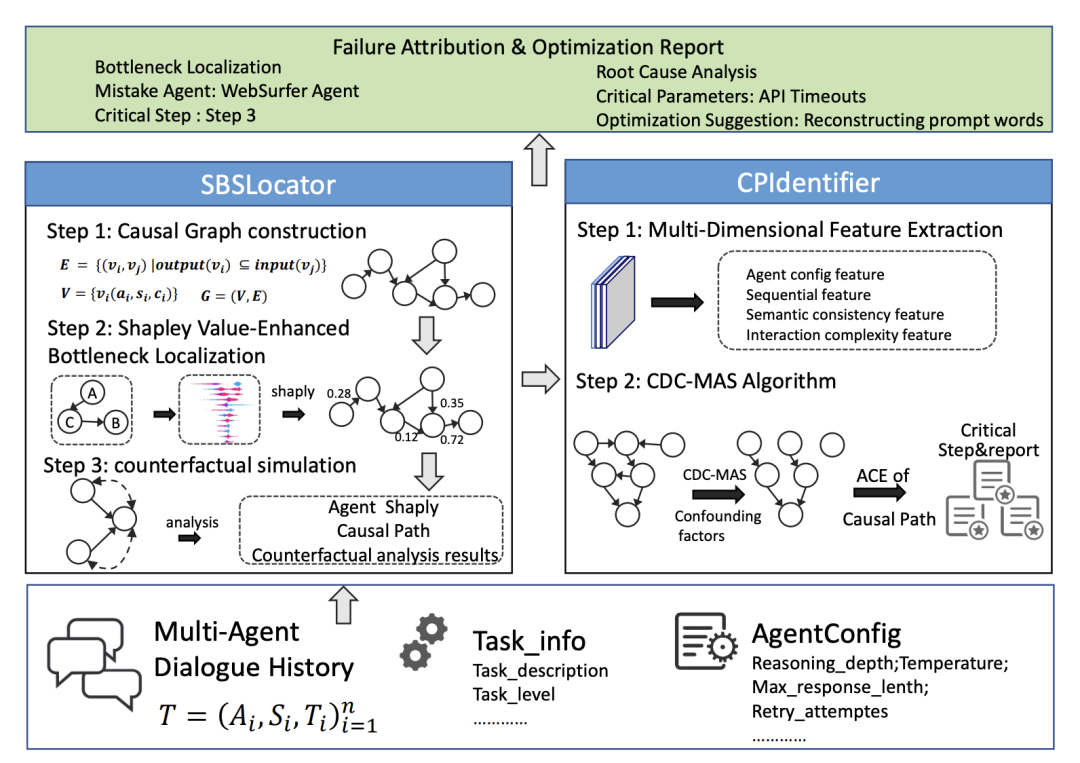
Ma 等人11引入了第一个基于多粒度因果推断的多智能体故障归因框架。在智能体级别,作者将信息传输方向进行倒置来构建正确的性能因果图,以追溯故障根源。此外,作者引入了博弈论中的Shapley值来量化每个代理在复杂协作中的系统重要性,涉及父节点的输入质量、智能体的自身能力。在找到了瓶颈智能体后,作者设计了一套分阶段的因果发现算法从高维特征中发现因果结构并预测关键步骤。
基于多个轨迹联合比对的方法
Yu 等人12认为,尽管多智能体故障轨迹存在表面差异,但同时也经常以类似的结构模式重复出现。基于这个假设,作者提出了一个轻量级的、无需训练的框架 CORRECT。作者从错误特征、错误上下文、启发式规则三个维度捕获并提取错误 schema。经过对错误 schema 的聚类后为每个聚类生成一个代表性错误模式。对于在线的故障定位请求,通过语义相似性搜索为错误轨迹从构建的错误模式库中检索前k个相关模式,这些潜在相关的错误模式将提供给探测大模型用于导出故障检测的结果。

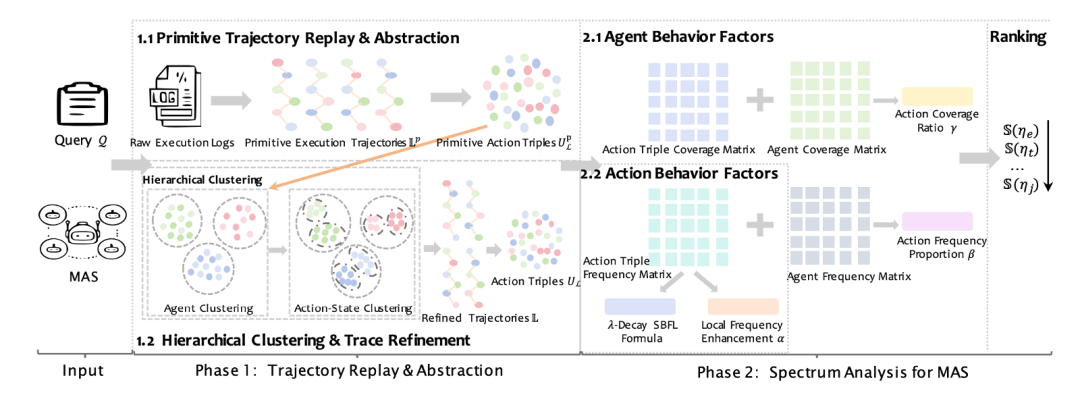
Ge 等人13观察到,失败轨迹中的错误决定性状态和动作也经常在重复执行任务时重复出现。因此,可以从多智能体系统的多次rollout变化中估计每个智能体动作导致失败的可能性。基于该想法,作者提出了第一种基于频谱的多智能体系统故障归因方法,它通过系统的轨迹重放(replay)和抽象,结合频谱分析来进行归因。具体而言,对给定的故障日志查询Q,作者重放k次独立运行的轨迹以收集相应的执行日志。这些日志中的每条记录将通过大模型进行语义解析,从而转换为规范的(动作,行为,状态)三元组。对这些三元组,系统根据其涉及的智能体索引进行分组,并提示大模型按照(动作,状态)的语义相似性进行抽象与进一步聚类。当聚类完成时,用相应的聚类代表替换每个原始三元组,以整合语义上等效的行为。最后,作者借鉴传统软件工程中的谱故障定位方法,构建覆盖矩阵、频率矩阵与结果向量,以计算每个(动作,行为,状态)三元组的可疑度得分,排名第一的三元组即为归因结果。
总结与讨论
本次分享讨论了大模型多智能体系统的故障归因工作,介绍了故障模式与故障定位方法。对这类任务,笔者具有如下改进思路:
-
在数据集层面,可以尝试向更复杂的步骤(例如生成大段代码)以及更困难、专业的场景(如医学、数据库领域)方向进行数据收集与构建,以研究多智能体系统在更具挑战性任务上的错误模式。同时,可以在具身 VLA 等场景(开放的动作空间、更困难的步骤监督)开展研究。
-
在方法层面,需要研究归因模型的鲁棒性与可扩展性,避免为不同类型的场景分别构建大量的合成轨迹。如何使现有的强推理模型适配于故障检测任务,让检测的经验能跨轨迹积累与使用将成为重要的研究方向。
参考文献
1: Chen et al. "A Survey on LLM-based Multi-Agent System: Recent Advances and New Frontiers in Application." arXiv preprint arXiv:2412.17481 (2024).
2: Chen et al. "RareAgents: Autonomous Multi-disciplinary Team for Rare Disease Diagnosis and Treatment." arXiv preprint arXiv:2412.12475 (2024).
3: Mei et al. "AIOS: LLM Agent Operating System." COLM (2025).
4: Zhu et al. "Where LLM Agents Fail and How They can Learn From Failures." arXiv preprint arXiv:2509.25370 (2025).
5: Cemri et al. "Why Do Multi-Agent LLM Systems Fail?" Biometrika NeurIPS Track on Datasets and Benchmarks (2025).
6: Zhang et al. "Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems." ICML (2025).
7: Li et al. "LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods." arXiv preprint arXiv:2412.05579 (2024).
8: Men et al. "Agent-RewardBench: Towards a Unified Benchmark for Reward Modeling across Perception, Planning, and Safety in Real-World Multimodal Agent." arXiv preprint arXiv:2506.21252 (2025).
9: Zhang et al. "AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?" arXiv preprint arXiv:2509.03312 (2025).
10: Banerjee et al. "Where Did It All Go Wrong? A Hierarchical Look into Multi-Agent Error Attribution." NeurIPS (2025).
11: Ma et al. "Automatic Failure Attribution and Critical Step Prediction Method for Multi-Agent Systems Based on Causal Inference." AAAI (2026).
12: Yu et al. "CORRECT: COndensed eRror RECognition via knowledge Transfer in multi-agent systems." arXiv preprint arXiv:2509.24088 (2025).
13: Ge et al. "Who is Introducing the Failure? Automatically Attributing Failures of Multi-Agent Systems via Spectrum Analysis." arXiv preprint arXiv:2509.13782 (2025).