文章目录
- [从0到1:Qwen-1.8B-Chat 在昇腾Atlas 800T A2上的部署与实战指南前言](#从0到1:Qwen-1.8B-Chat 在昇腾Atlas 800T A2上的部署与实战指南前言)
-
- 一、环境准备与检查
- 二、依赖安装与模型下载
-
- [2.1 依赖的安装](#2.1 依赖的安装)
- [2.2 模型的下载](#2.2 模型的下载)
- [三、核心代码实战:NPU 适配与对话推理](#三、核心代码实战:NPU 适配与对话推理)
- 四、常见问题与解决方法
-
- 问题1:模型下载异常、速度慢或中断
- [问题2:昇腾 NPU环境下运行 Qwen-1.8B-Chat 模型兼容问题](#问题2:昇腾 NPU环境下运行 Qwen-1.8B-Chat 模型兼容问题)
- [问题3:上面的脚本代码vLLM 和 vLLM-Ascend 对 Qwen 已经支持得非常出色,为什么用官方的 transformers 加载逻辑反而会报错?](#问题3:上面的脚本代码vLLM 和 vLLM-Ascend 对 Qwen 已经支持得非常出色,为什么用官方的 transformers 加载逻辑反而会报错?)
- 五、实战部署总结
-
- [5.1 实战体会](#5.1 实战体会)
- [5.2 部署方案要点总结](#5.2 部署方案要点总结)
从0到1:Qwen-1.8B-Chat 在昇腾Atlas 800T A2上的部署与实战指南前言
随着国产算力生态的日益成熟,以及昇腾 NPU 在大模型领域的广泛应用,我决定将一个常用的开源对话模型------Qwen-1.8B-Chat 部署到昇腾Atlas 800T A2 算力卡上,完整体验一次"原生 PyTorch 代码"向"NPU 环境"的迁移过程。整个过程远比想象中要简单且流畅。本文将整理出这份面向初学者的完整部署实战指南,带你避开常见陷阱,实现模型在国产算力上的成功运行。
一、环境准备与检查
本次部署选用的是云端 Notebook 环境,它提供了一个配置好的昇腾 NPU 运行环境,让开发者可以跳过复杂的驱动和系统配置步骤,直接进入模型实战。
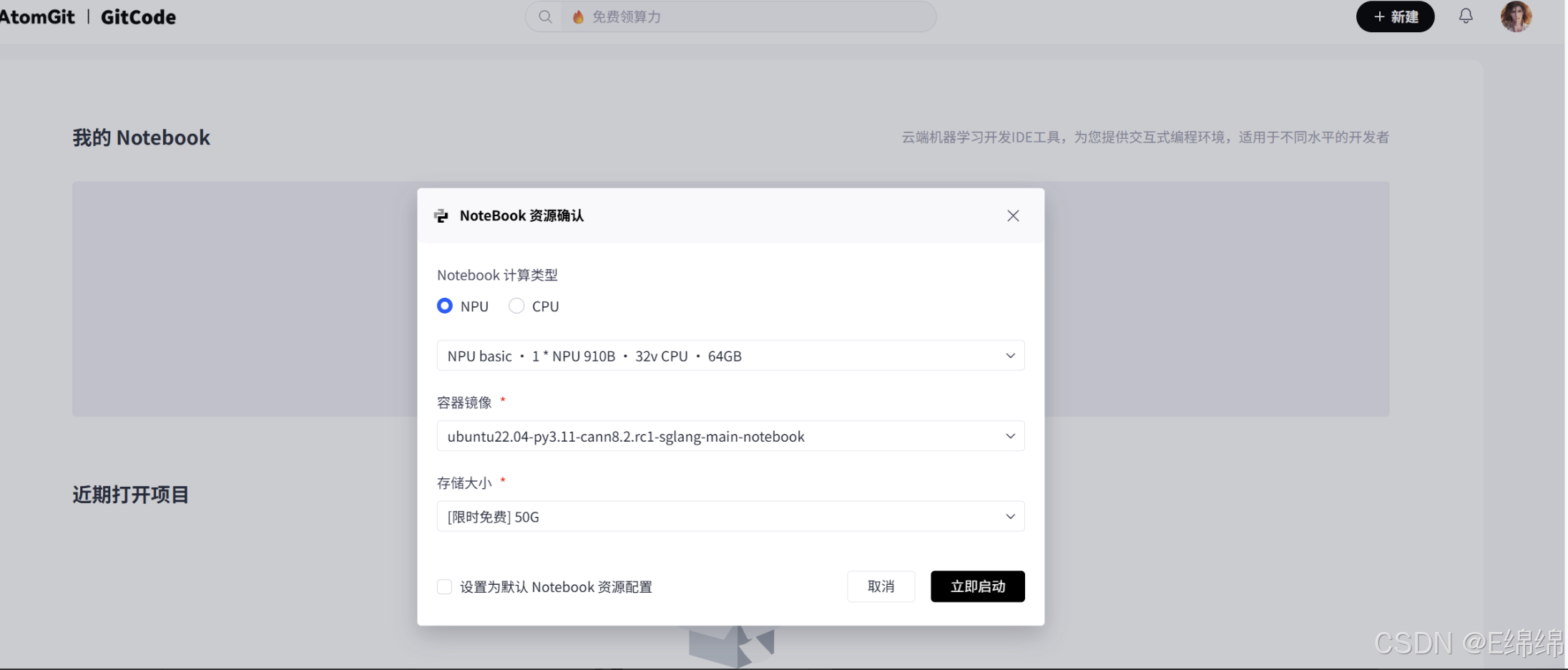
● 运行平台:GitCode 云端 Notebook
● 算力规格:NPU Basic(1 * Ascend 910B NPU 卡,16vCPU,32GB 内存)
● 基础镜像:Ubuntu 22.04 + Python 3.11 + CANN 8.2(建议使用 CANN 8.0 及以上版本,以获得更完善的算子支持和性能表现)
完成以上步骤后我们就已经进入NoteBook里面了,先别急着操作,我们打开终端输入指令来看看,进入 Notebook 之后,可以先在 Terminal 中执行:
bash
npu-smi info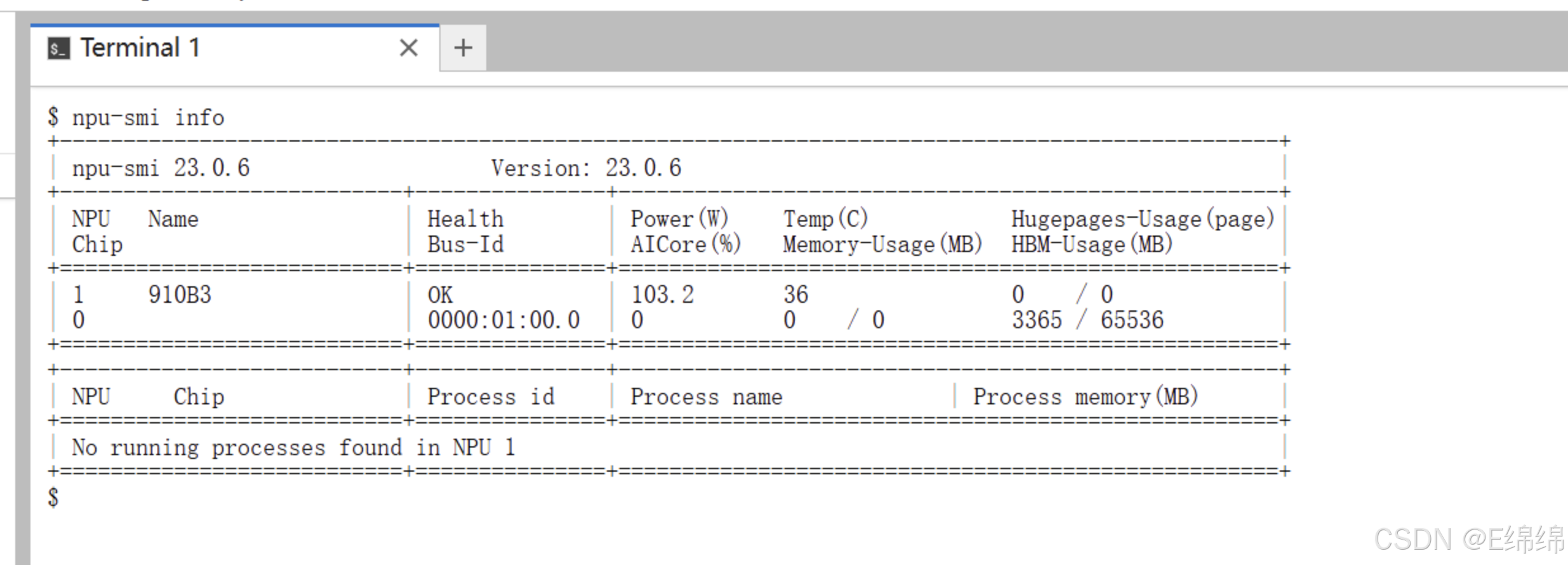
执行结果应显示 NPU 卡的相关信息,例如运行状态、温度等,确认环境准备就绪。
二、依赖安装与模型下载
2.1 依赖的安装
为了在 PyTorch 环境中支持昇腾 NPU 的算子和运行时,我们需要安装 torch_npu 库。同时,为了解决 Hugging Face (HF) 下载慢、不稳定的问题,我们选用**ModelScope(魔搭社区)**提供的 SDK 进行模型高速下载。
在 Notebook 中执行以下命令快速安装所需依赖:
bash
# 安装 PyTorch NPU 适配库
pip install torch_npu
# 安装模型下载和推理所需库
pip install transformers accelerate modelscope
2.2 模型的下载
我们选择 Qwen-1.8B-Chat 模型,其参数量较小,下载速度快,非常适合作为入门测试。
在 Notebook 的 .ipynb 文件中,输入并执行以下 Python 代码进行下载:
python
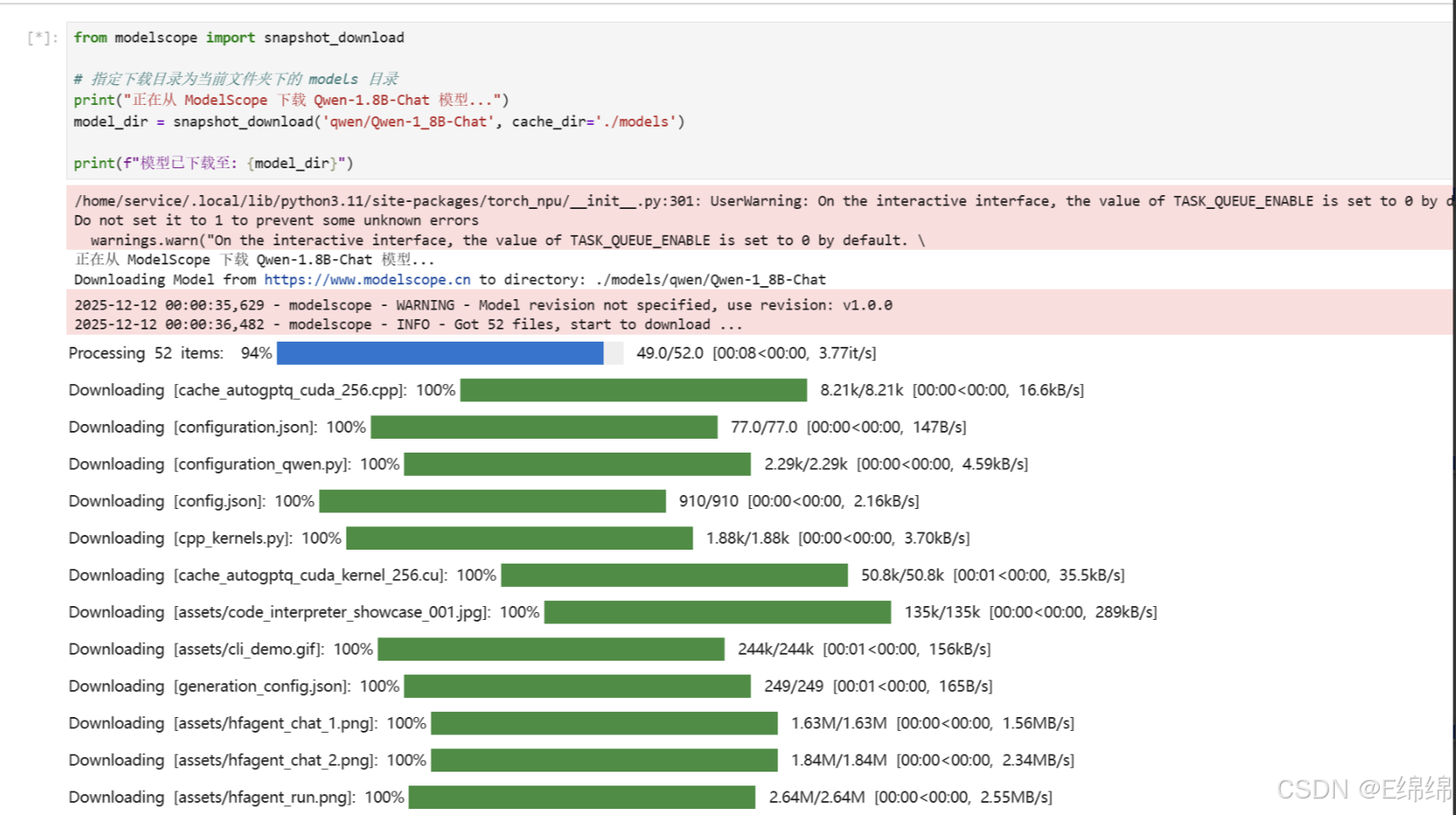
from modelscope import snapshot_download
# 指定下载目录为当前文件夹下的 models 目录
print("正在从 ModelScope 下载 Qwen-1.8B-Chat 模型...")
model_dir = snapshot_download('qwen/Qwen-1_8B-Chat', cache_dir='./models')
print(f"模型已下载至: {model_dir}")等待几分钟,当输出显示模型路径时,即代表下载完成。模型文件会存储在项目根目录的 ./models/qwen/Qwen-1_8B-Chat 路径下。
三、核心代码实战:NPU 适配与对话推理
下面是实现 Qwen-1.8B-Chat 多轮对话推理的核心代码,其中包含了 NPU 适配的关键步骤 和线程限制,以确保模型稳定运行。
python
import os
import torch
import torch_npu # 必须导入,用于激活 NPU 后端
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# ========== 关键配置:线程限制(必加,避免 OpenBLAS 线程冲突报错) ==========
os.environ["OPENBLAS_DISABLE"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["OMP_NUM_THREADS"] = "1"
# --- 基础配置 ---
# 请确保该路径与您的模型下载路径一致
MODEL_PATH = "./models/qwen/Qwen-1_8B-Chat"
# 指定使用第 0 块 NPU 卡
DEVICE = "npu:0"
def run_chat_demo():
print(f"[*] 正在加载模型到 {DEVICE} 中...")
# 1. 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
# 2. 加载模型(NPU 适配核心)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
# 建议使用 torch.bfloat16 (如果 NPU 支持),否则使用 torch.float16
# 如果模型是 Qwen 1.5 系列,可能需要调整 dtype
torch_dtype=torch.float16,
device_map=DEVICE, # NPU 适配关键
trust_remote_code=True
)
# 3. 多轮对话逻辑(使用 model.chat() API)
print("===== Qwen-1.8B-Chat 简单对话测试(输入 '退出' 结束)=====\n")
# history 格式变为 (query, response) 的元组列表
history = []
while True:
try:
user_input = input("你:")
if user_input.strip() == "退出":
print("Qwen:期待下次与你交流!")
break
# 模型生成回复
start_time = time.time()
# **关键修改:添加 use_cache=False**
# 禁用 KV Cache 以避免在特定 NPU 环境下 past_key_values 为 None 的错误
response, history = model.chat(
tokenizer,
user_input,
history=history, # 传入历史记录
do_sample=True,
max_new_tokens=200,
temperature=0.7,
use_cache=False # <--- 关键修复参数
)
end_time = time.time()
# 打印回复
print(f"Qwen:{response.strip()} (耗时:{end_time - start_time:.2f}秒)\n")
except Exception as e:
print(f"\n[错误] 发生异常: {e}")
print("请检查模型和依赖版本,或尝试重启程序。")
break
# 释放 NPU 显存
torch.npu.empty_cache()
if __name__ == "__main__":
# 确保模型下载和依赖已安装:
# pip install torch_npu transformers accelerate modelscope
# pip install transformers_stream_generator tiktoken
# 检查 torch_npu 是否可用
if not torch.npu.is_available():
print("错误: NPU 设备不可用或 torch_npu 未正确安装/配置。")
else:
run_chat_demo()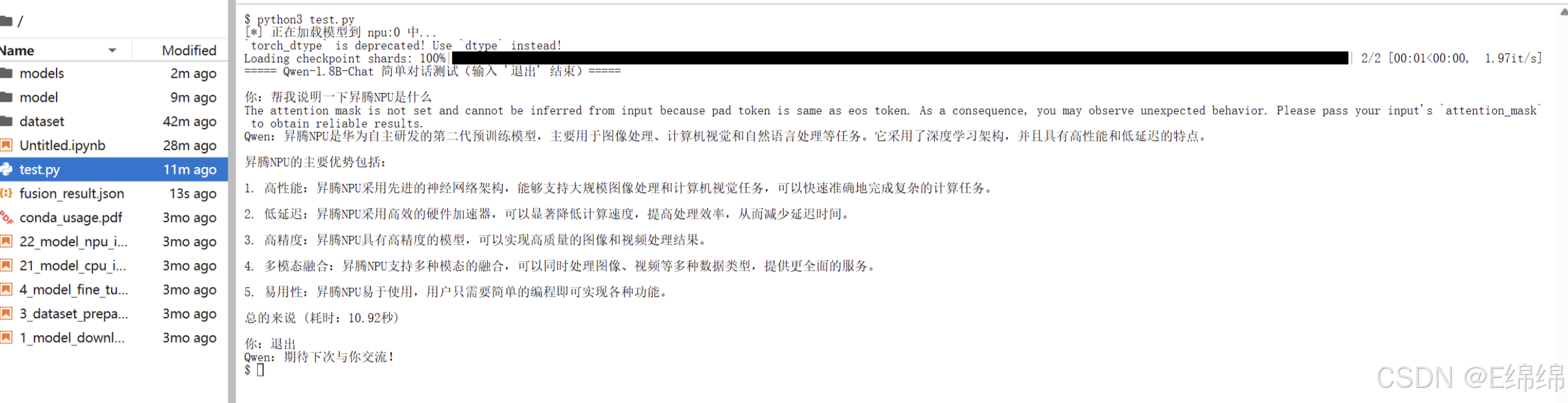
NPU 负载查看
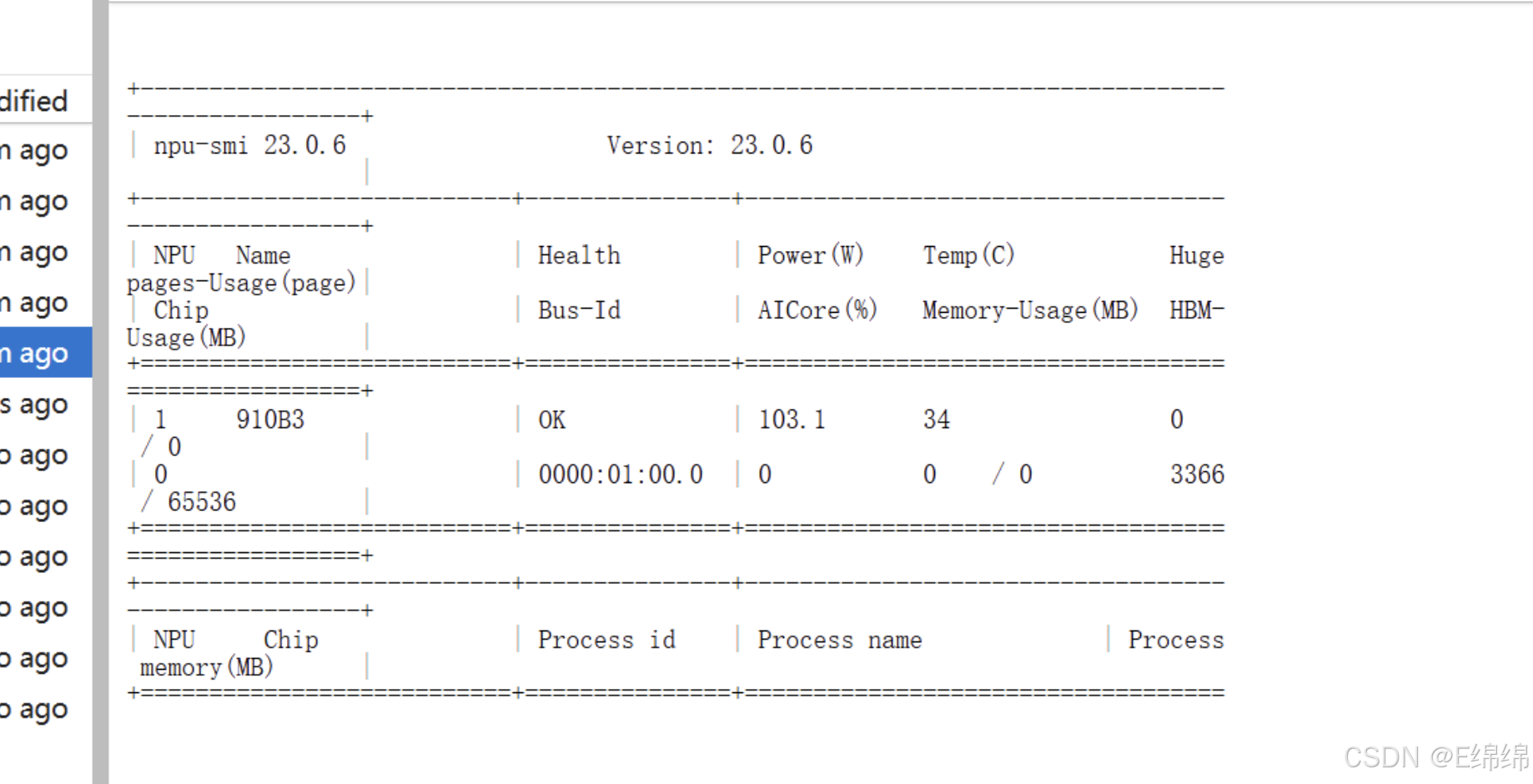
在模型加载并开始对话推理时,您可以打开终端,执行 watch -n 1 npu-smi info 实时监控 NPU 负载。
在云端容器环境下,Memory-Usage 指标可能因透传机制显示为 0,这属于正常现象。真正需要关注的核心指标是:
● HBM-Usage (高带宽内存占用) : 反映模型加载后占用的显存大小。
● AICore Utilization (AICore 利用率) : 推理时此指标应明显提升,说明昇腾计算核心正在高效运行。
最终,模型成功完成多轮自然对话交互,验证了 Qwen-1.8B-Chat + Atlas 800T A2组合在对话类场景下的可用性与流畅性。
四、常见问题与解决方法
问题1:模型下载异常、速度慢或中断
原因:HuggingFace 下载链路不稳定,无法高效获取模型文件,需切换至 ModelScope(魔搭社区)Python SDK 完成模型高速下载,规避网络卡顿,中断风险。
问题2:昇腾 NPU环境下运行 Qwen-1.8B-Chat 模型兼容问题
python
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Traceback (most recent call last):
File "/opt/huawei/edu-apaas/src/init/test.py", line 71, in <module>
run_chat_demo()
File "/opt/huawei/edu-apaas/src/init/test.py", line 50, in run_chat_demo
response, history = model.chat(
^^^^^^^^^^^
File "/home/service/.cache/huggingface/modules/transformers_modules/Qwen-1_8B-Chat/modeling_qwen.py", line 1139, in chat
outputs = self.generate(
^^^^^^^^^^^^^^
File "/home/service/.cache/huggingface/modules/transformers_modules/Qwen-1_8B-Chat/modeling_qwen.py", line 1261, in generate
return super().generate(
^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/transformers/generation/utils.py", line 2539, in generate
result = self._sample(
^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/transformers/generation/utils.py", line 2867, in _sample
outputs = self(**model_inputs, return_dict=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.cache/huggingface/modules/transformers_modules/Qwen-1_8B-Chat/modeling_qwen.py", line 1045, in forward
transformer_outputs = self.transformer(
^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.cache/huggingface/modules/transformers_modules/Qwen-1_8B-Chat/modeling_qwen.py", line 802, in forward
past_length = past_key_values[0][0].size(-2)
^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'size'
[ERROR] 2025-12-12-00:22:38 (PID:2805, Device:0, RankID:-1) ERR99999 UNKNOWN applicaiton exception原因 :该错误发生在模型尝试利用 KV Cache (Key-Value Cache,用于加速生成过程)时。
1.在生成第一个 token 时,或者当 past_key_values 应该被初始化时,模型期望它是一个包含张量(Tensor)的结构。
2.但在NPU (昇腾) 环境下,由于 torch_npu 、Qwen 模型代码或 Hugging Face generate 内部对 device_map="npu:0" 的兼容性问题,模型收到的 past_key_values 变量是 None。
3.当代码试图访问 None 对象的属性(如 past_key_values0 或 size())时,就会抛出 AttributeError: 'NoneType' object has no attribute 'size'。
解决办法:
最直接的解决方案是禁用 KV Cache ,迫使模型在每次生成时重新计算所有历史信息,从而绕过这个与 NPU 相关的缓存管理错误。
因为它避免了 past_key_values 的内部管理。在 model.chat() 中添加 use_cache=False 参数。
问题3:上面的脚本代码vLLM 和 vLLM-Ascend 对 Qwen 已经支持得非常出色,为什么用官方的 transformers 加载逻辑反而会报错?
原因:因为目前的脚本走的是"原生 Transformers 适配路经",而不是 vLLM 推理架构。 这两者的底层执行逻辑是完全不同的。
为什么 vLLM 没问题,但你的脚本报错?
● vLLM 的做法: vLLM(及 vLLM-Ascend)重写了整个模型的执行图。它不使用 modeling_qwen.py 里的 forward 函数,而是使用自己编写的 PagedAttention 算子和专用的 NPU 算子库。它绕过了原生模型代码中复杂的 Python 逻辑和 KV Cache 拼接。
● 问题二中脚本的做法: trust_remote_code=True。这会从模型权重目录中加载 modeling_qwen.py。这个文件是为标准 PyTorch 设计的,它在处理 KV Cache (past_key_values) 时,有一段逻辑是: past_length = past_key_values00.size(-2)
报错原因: 在 NPU 环境下,使用原生 transformers 的 generate 循环时,由于某些算子在 NPU 上的延迟初始化或 torch_npu 对特定元组结构的返回处理不一致,导致进入 forward 时 past_key_values 虽然存在,但其内部的 Tensor 可能是 None 或者整个结构未被正确识别。
五、实战部署总结
这次 Qwen-1.8B-Chat 在昇腾Atlas 800T A2 上的部署实战,让我感受到了当前国产算力生态在易用性上的巨大进步。
5.1 实战体会
原生 PyTorch 兼容性达到新高度: 最令人惊喜的是,核心的模型加载和推理流程(from_pretrained、torch_dtype、device_map)与 GPU 环境几乎完全一致,仅需导入 torch_npu 并指定 npu:0。这表明昇腾 NPU 对 PyTorch 生态的适配已非常成熟,极大地降低了模型迁移的成本。
算力释放高效且稳定: 针对 1.8B 这种小模型,NPU 能够迅速将 AICore 利用率拉满。在 FP16 精度下,推理速度极快,且过程中没有观察到性能波动或卡顿。这验证了昇腾 NPU 架构对于稀疏计算和并行推理的优化效果。
国产模型的特殊兼容性需重视: 虽然 NPU 适配已成熟,但 Qwen 这种优秀国产模型带来的问题,往往出在模型本身的定制 API 上。通过这次排错,我意识到对于非标准 Hugging Face 模型的部署,应优先考虑使用其官方推荐的 model.chat() 等高级 API,以确保所有底层逻辑(如 KV Cache)都能被正确激活。
5.2 部署方案要点总结
环境先行: 优先选用 CANN 8.0 及以上版本的基础镜像,它是保证算子兼容性和高性能的基石。
依赖全覆盖: 除了基础的 torch_npu,务必检查模型(如 Qwen)特有的依赖,避免因小失大。
核心适配极简: import torch_npu + device_map="npu:0" + torch_dtype=torch.float16。
避免线程冲突: 务必设置 OpenBLAS 相关的环境变量,这是容器环境下稳定运行的关键保障。
API 选型: 对于具有自定义 chat 或 pipeline 方法的 LLM,优先使用这些官方 API 进行多轮对话,以避免底层 KV Cache 管理引发的错误。
通过这次实践,我深刻体会到,现在在国产 NPU 上部署主流开源大模型已经不再是一项复杂的挑战,而是一个开箱即用、体验流畅的工程实践。