1.用 APISIX 双网关对接 Nacos 注册的商品服务 v1/v2,实现按 header 灰度 20% 流量并全程 JWT 鉴权热更新。
第一步:安装基础依赖
安装Java 11(若未装) sudo apt install -y openjdk-11-jdk # 安装Maven(若未装) sudo apt install -y maven # 验证版本 java -version # 输出openjdk 11.x即可 mvn -v # 输出Maven 3.x即可
安装etcd
下载
下载etcd v3.5.10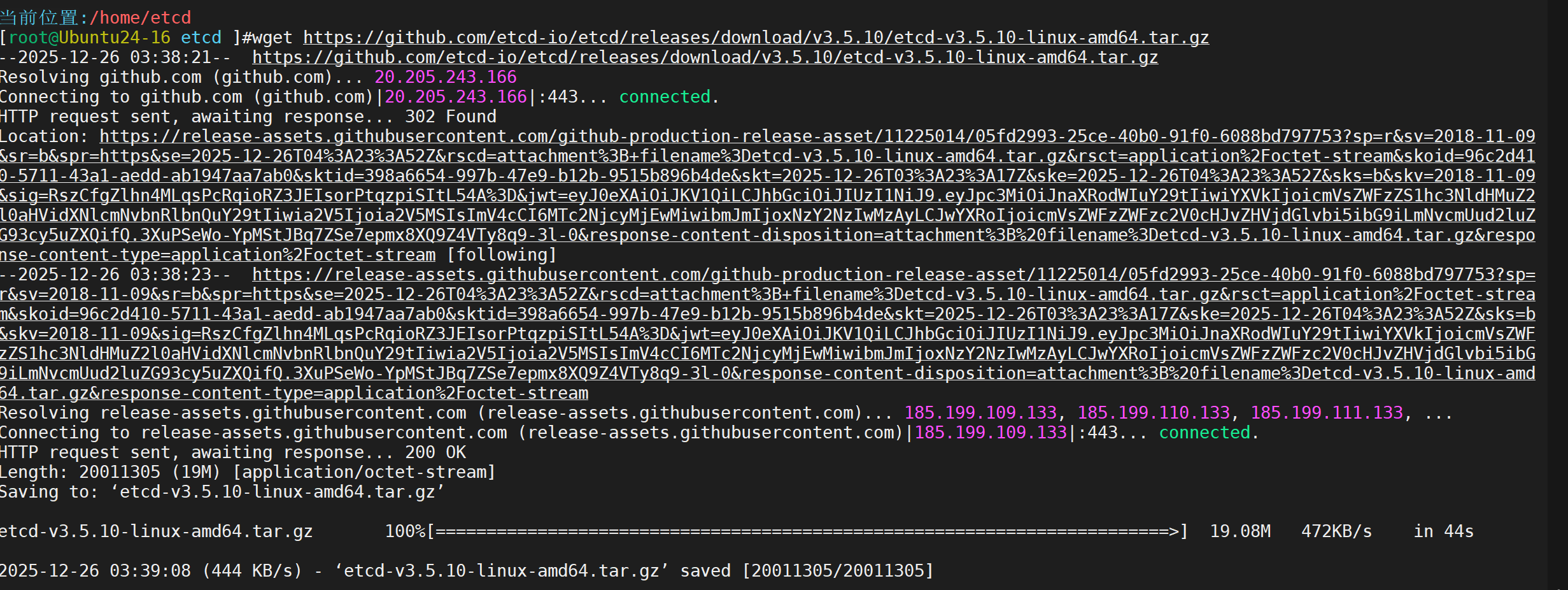
解压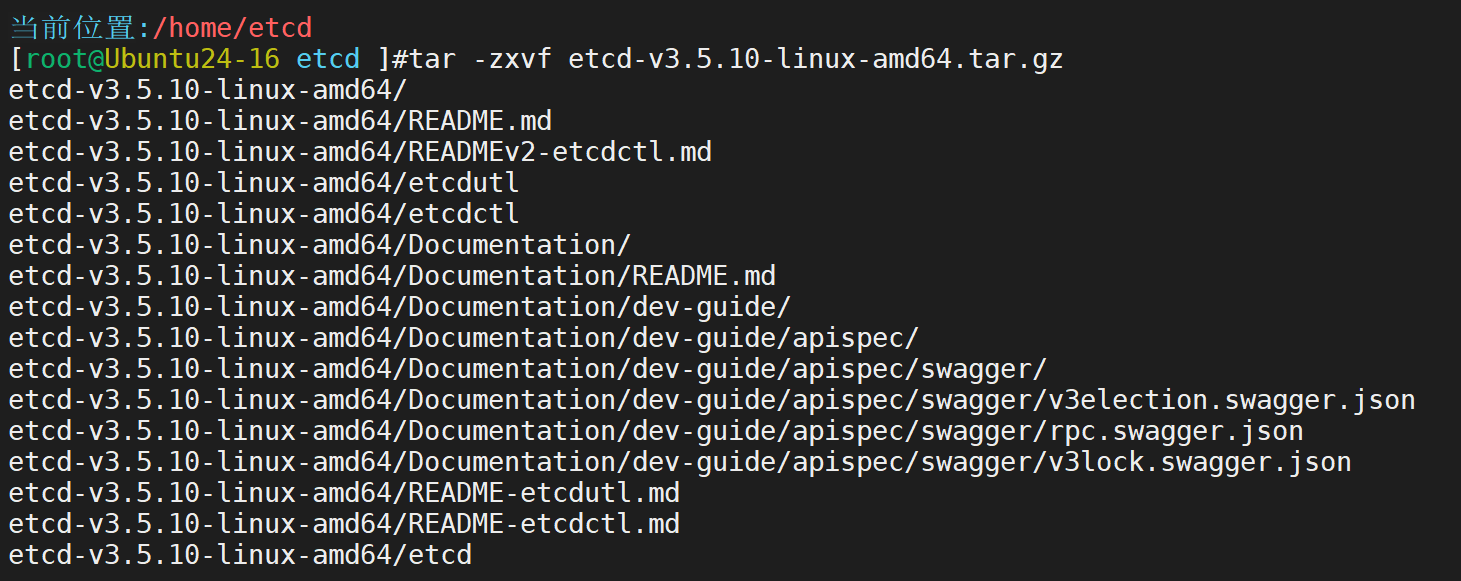
将etcd和etcdctl复制到系统bin目录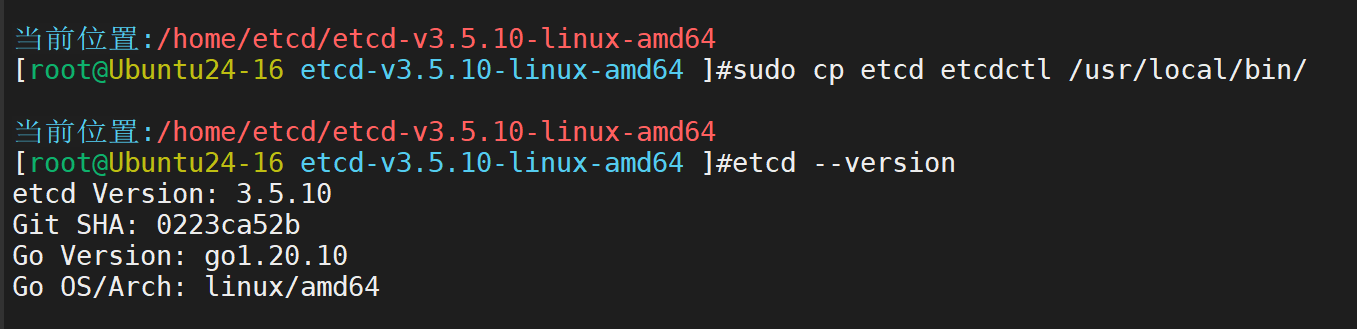
配置 etcd 为 systemd 服务(开机自启)
-
创建 etcd 配置目录和数据目录:
sudo mkdir -p /var/lib/etcd /etc/etcd
-
创建 systemd 服务文件:
sudo vim /etc/systemd/system/etcd.service
粘贴以下内容(配置单机 etcd):
[Unit]
Description=etcd key-value store
Documentation=https://github.com/etcd-io/etcd
After=network.target
[Service]
User=root
Type=notify
ExecStart=/usr/local/bin/etcd \
--name default \
--data-dir /var/lib/etcd \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://127.0.0.1:2379 \
--allow-none-authentication=true
Restart=always
RestartSec=10s
LimitNOFILE=4096
[Install]
WantedBy=multi-user.target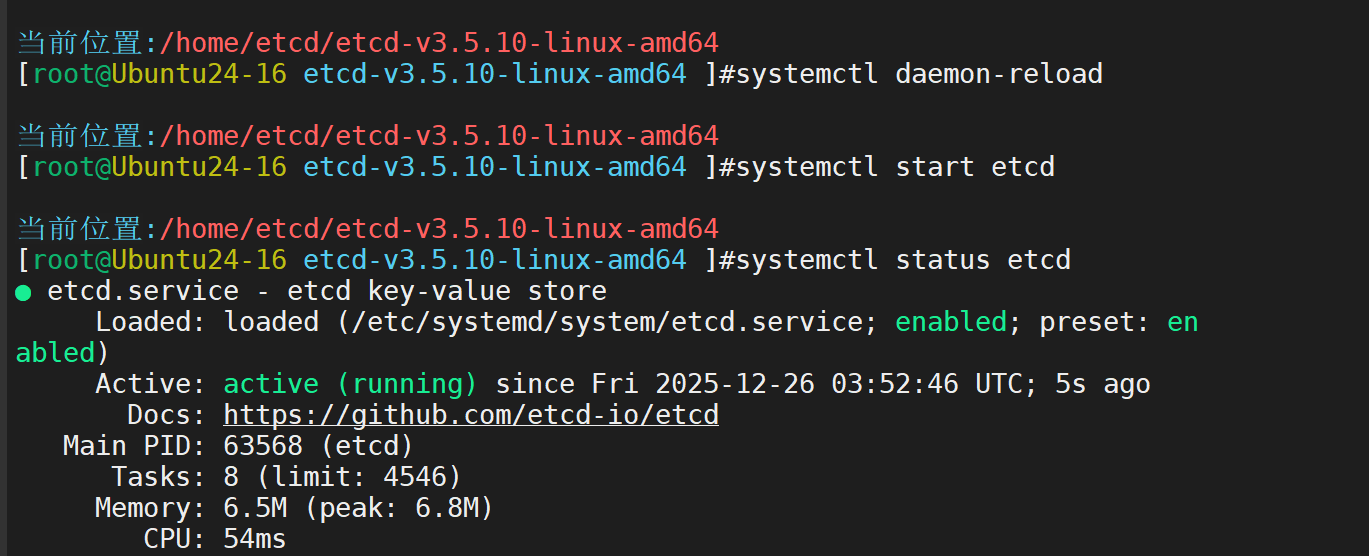
安装 Nacos 单机版
创建专属目录

下载
wget https://archive.apache.org/dist/nacos/nacos-server/2.3.0/nacos-server-2.3.0.tar.gz
解压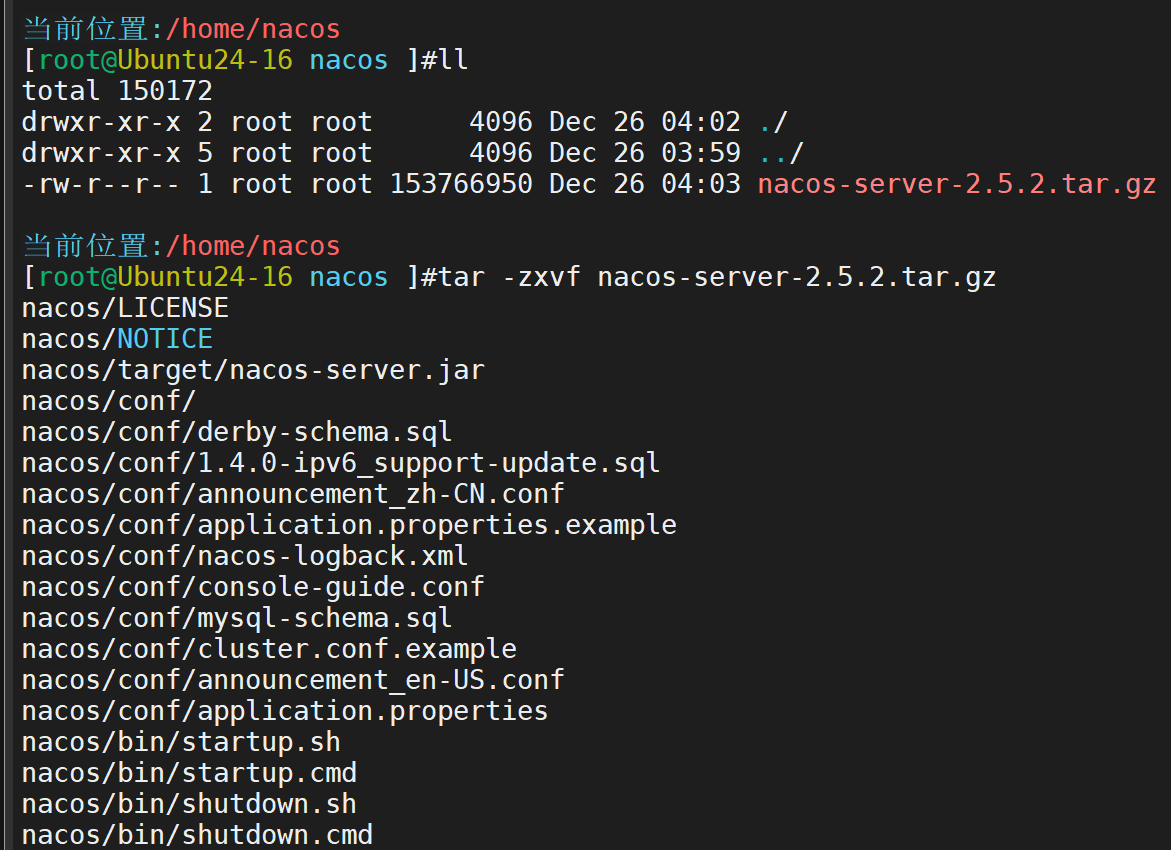
下载好后进行启动

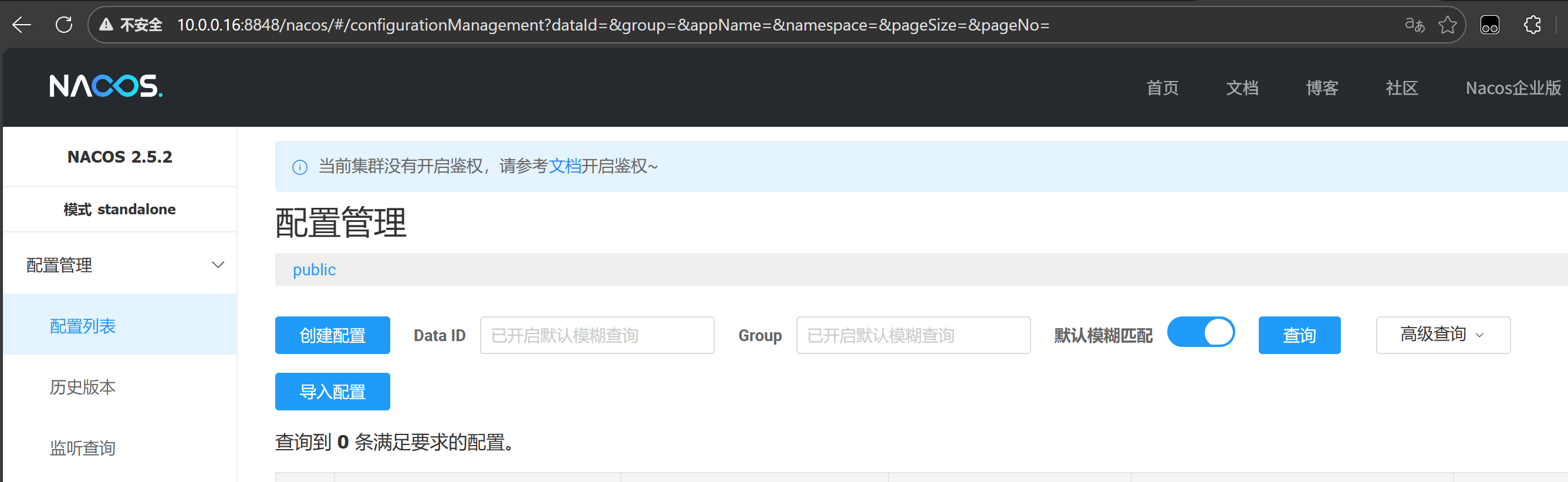
登录网页查看
安装 APISIX
安装 APISIX 依赖
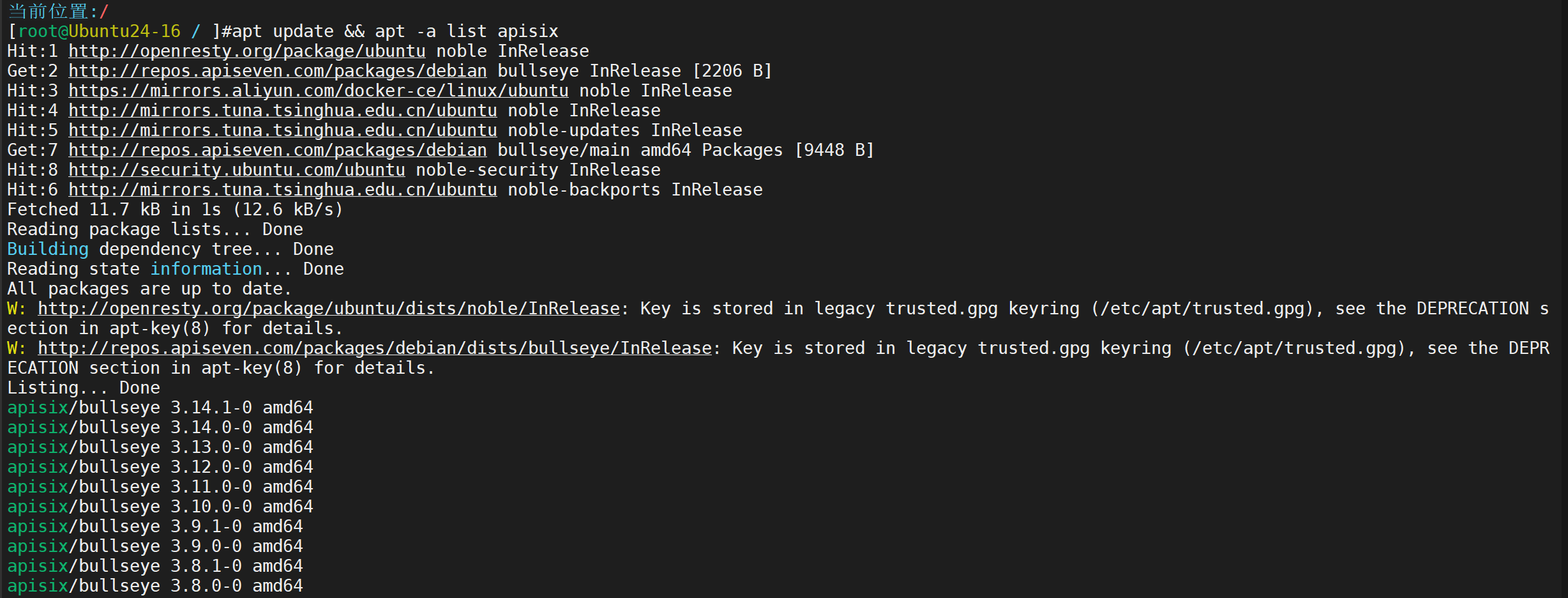
装仓库

看看版本
安装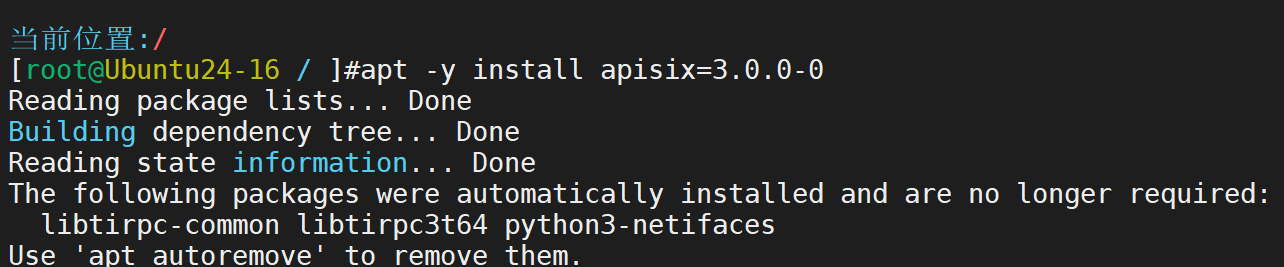
查看状态
实验开始
初始化
用 Admin API 创建两个 upstream,从 Nacos 拉取服务
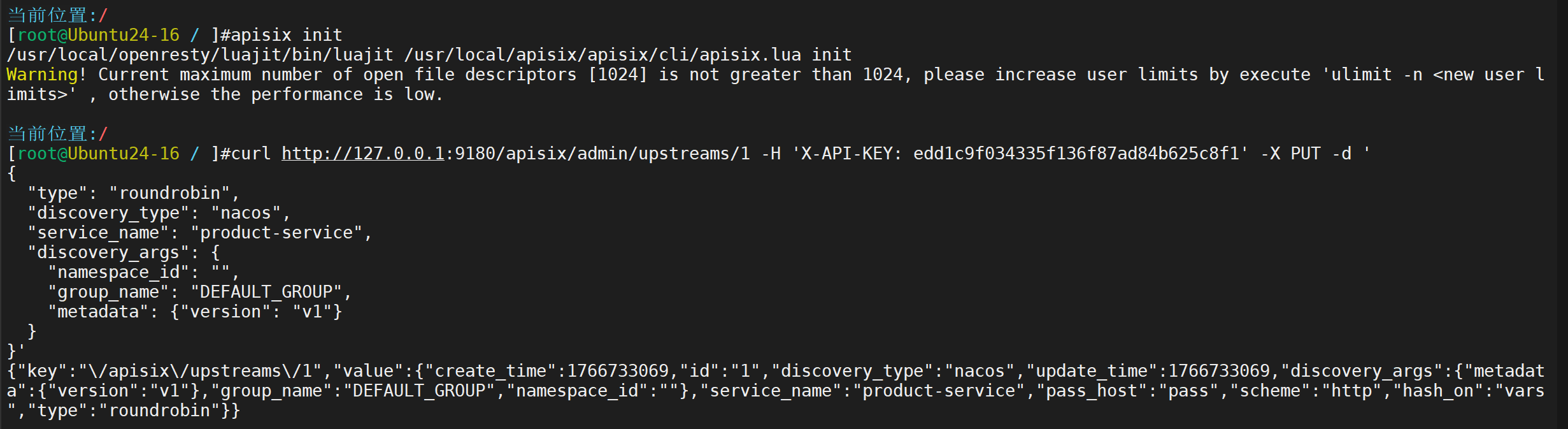
创建 v2 upstream
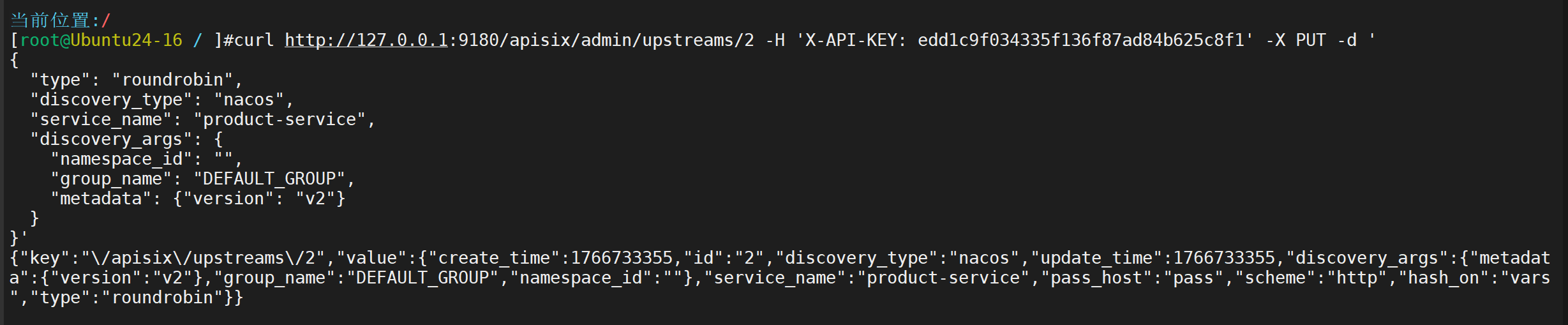
验证是否发现

配置 Route(灰度流量 + JWT 鉴权
先创建 consumer

创建 route

测试实验
-
生成 JWT(用 consumer 密钥): text
curl http://127.0.0.1:9080/apisix/plugin/jwt/sign?key=user-key -i # 返回 JWT token -
测试正常流量(到 v1,无灰度): text
curl http://127.0.0.1:9080/product/ -H "Authorization: Bearer your-jwt-token"- 预期:Product v1(无 X-Canary header,全到 v1)。
-
测试灰度流量(20% 到 v2):
- 重复请求带 header:curl http://127.0.0.1:9080/product/ -H "Authorization: Bearer your-jwt-token" -H "X-Canary: true"
- 统计多次请求:约 20% 返回 Product v2(随机权重)。
- 无 JWT:返回 401 Unauthorized。
-
监控:用 tail -f /usr/local/apisix/logs/access.log 看流量路由。
-
热更新测试:改 JWT secret 后,新签发 token 用新 secret,旧 token 失效(热生效)。
2.把 Nginx+Tomcat 的访问/异常日志、系统与中间件指标、接口心跳全送进 ES 热-温-冷三节点集群,在 Kibana 一分钟内定位模拟 OOM 全链路证据。
实验需要四台主机
基础配置
# 1. 更新系统
sudo apt update && sudo apt upgrade -y
# 2. 关闭swap(ES强烈要求)
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 3. 提高系统限制
sudo tee /etc/sysctl.d/99-elasticsearch.conf <<EOF
vm.max_map_count=262144
fs.file-max=655360
EOF
sudo sysctl -p /etc/sysctl.d/99-elasticsearch.conf
sudo tee /etc/security/limits.d/99-elasticsearch.conf <<EOF
* soft nofile 655360
* hard nofile 655360
* soft nproc 4096
* hard nproc 4096
EOF
# 4. 设置主机名(根据上面表格改)
sudo hostnamectl set-hostname app-node # 13这台改app-node,其他类似
# 5. 配置hosts解析(所有4台都执行相同内容)
sudo tee -a /etc/hosts <<EOF
10.0.0.13 app-node
10.0.0.100 es-hot
10.0.0.101 es-warm
10.0.0.103 es-cold
EOF
# 6. 重启使主机名生效
sudo reboot第二步:10.0.0.13(app-node)安装 Nginx + Tomcat + Beats
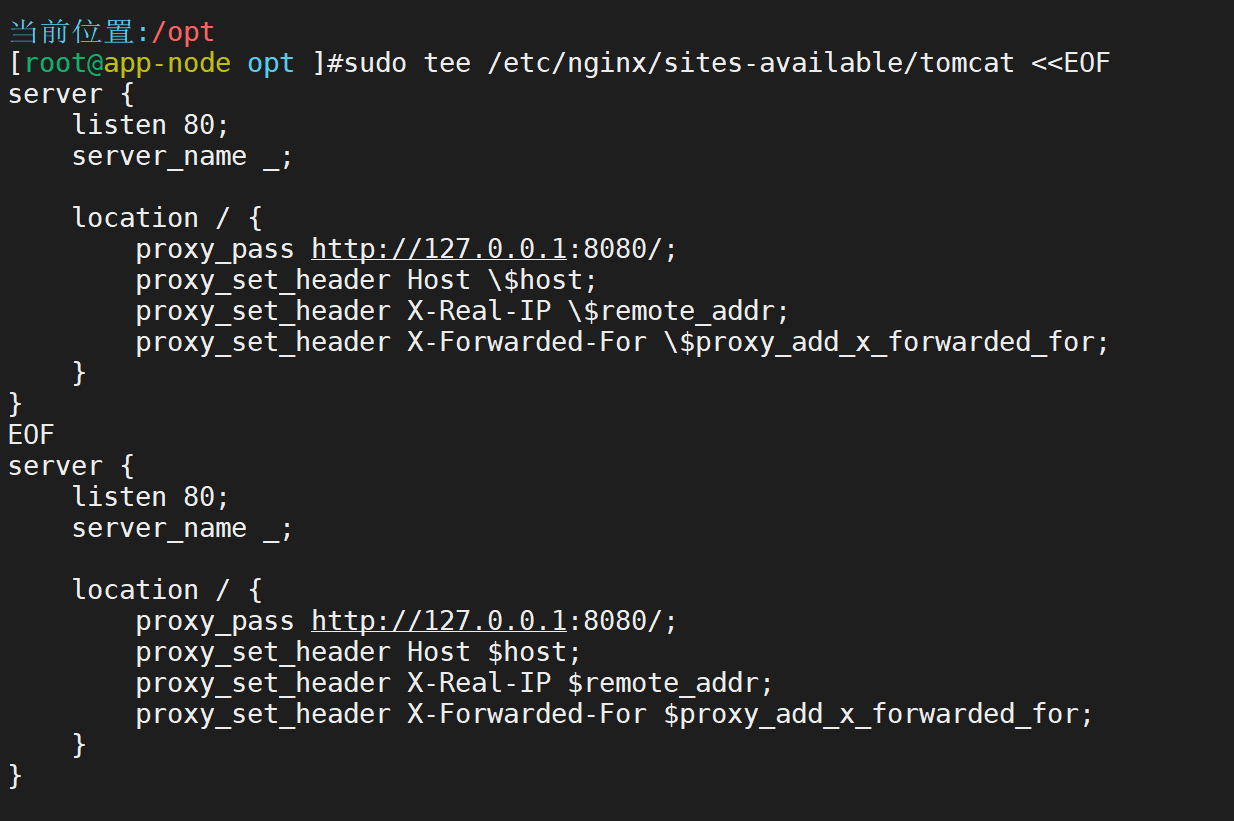
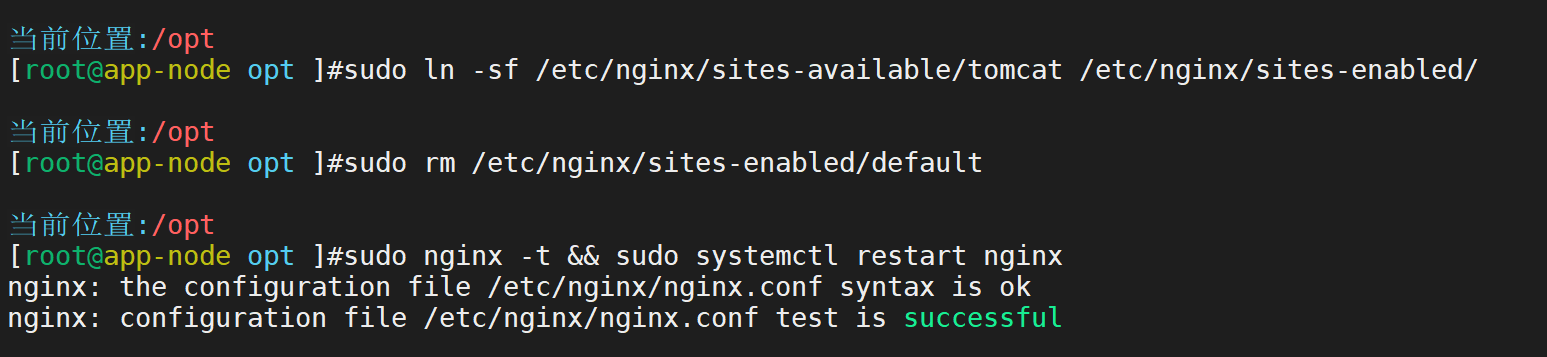
安装nginx并开启


下载并安装Tomcat 10

关联并赋权

配置Tomcat开启访问日志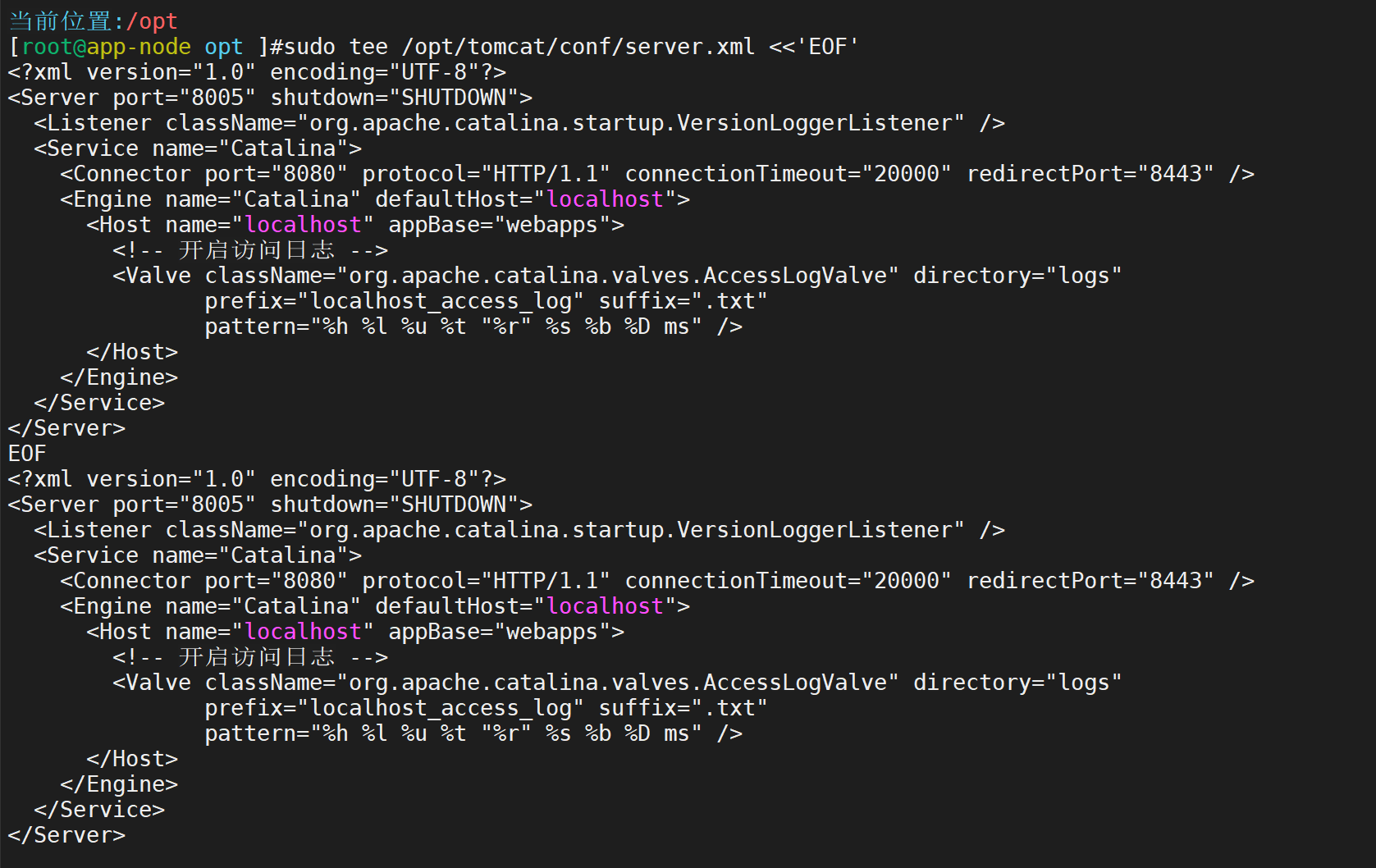
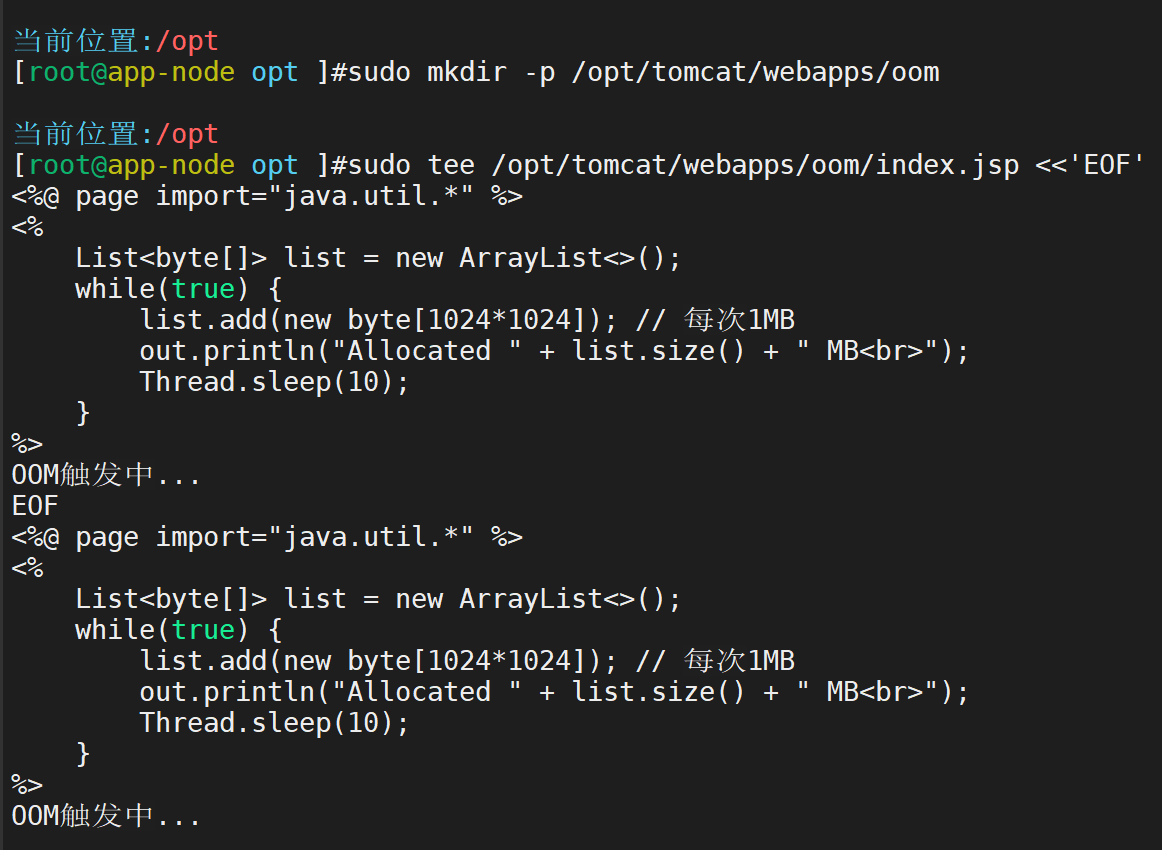
部署一个简单Web应用
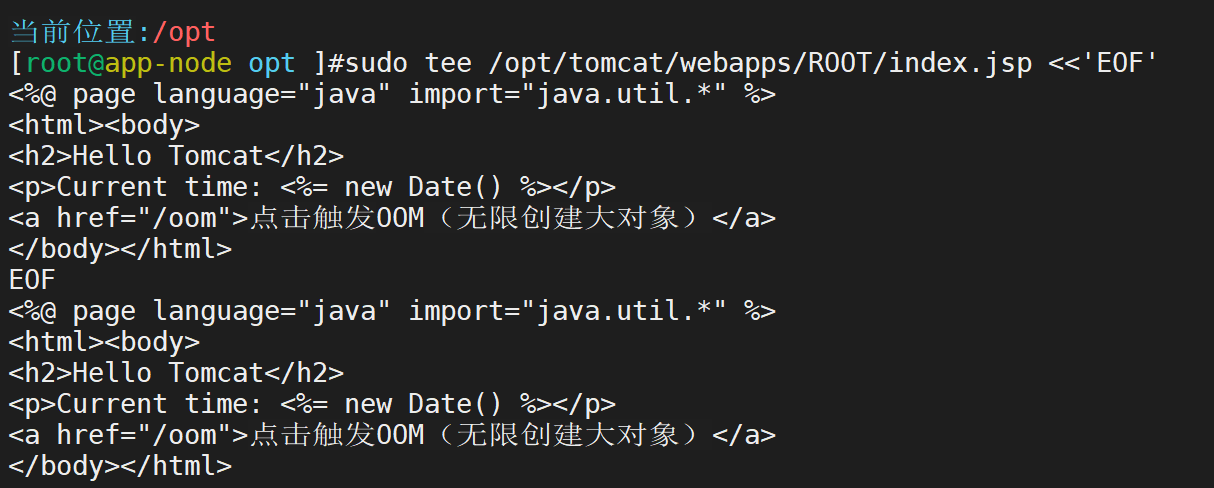
创建触发页面
配置nginx反向代理
启动tomcat

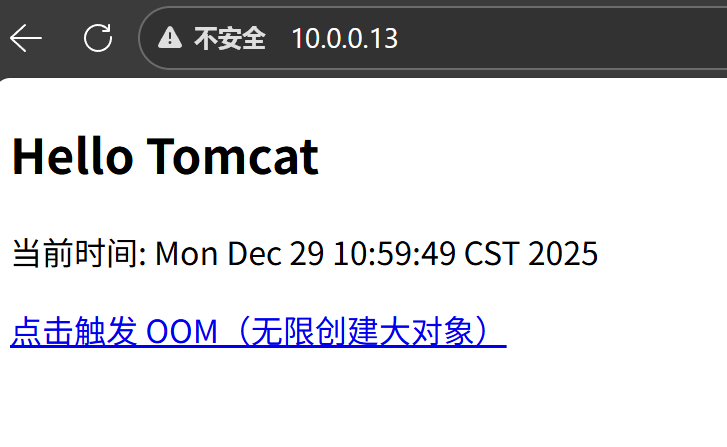
网页查看
第三步:安装Beats
添加Elastic官方源
安装Filebeat、Metricbeat、Heartbeat
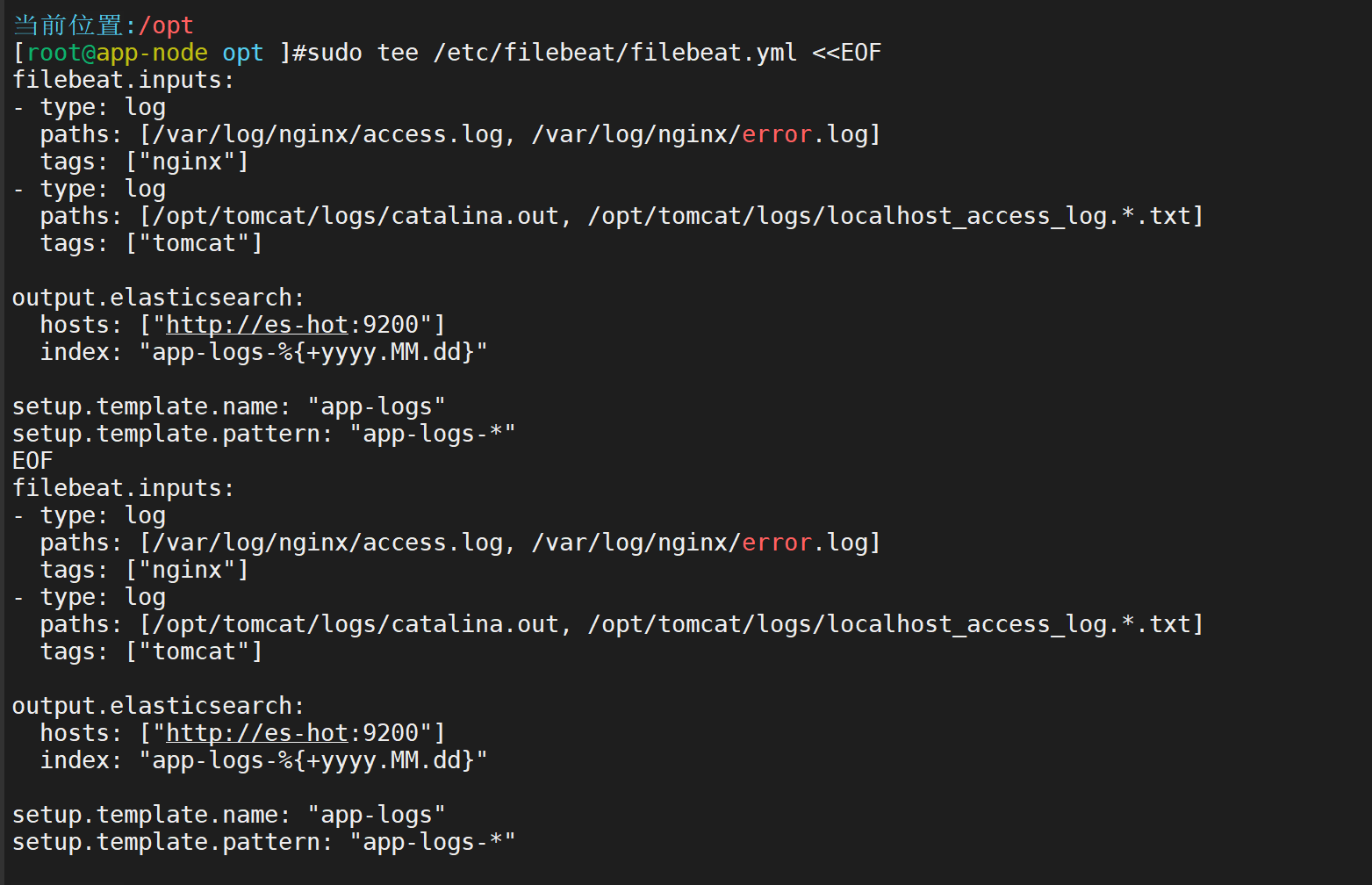
Filebeat采集Nginx和Tomcat日志
Metricbeat采集系统和Tomcat指标(用Jolokia简单方式)
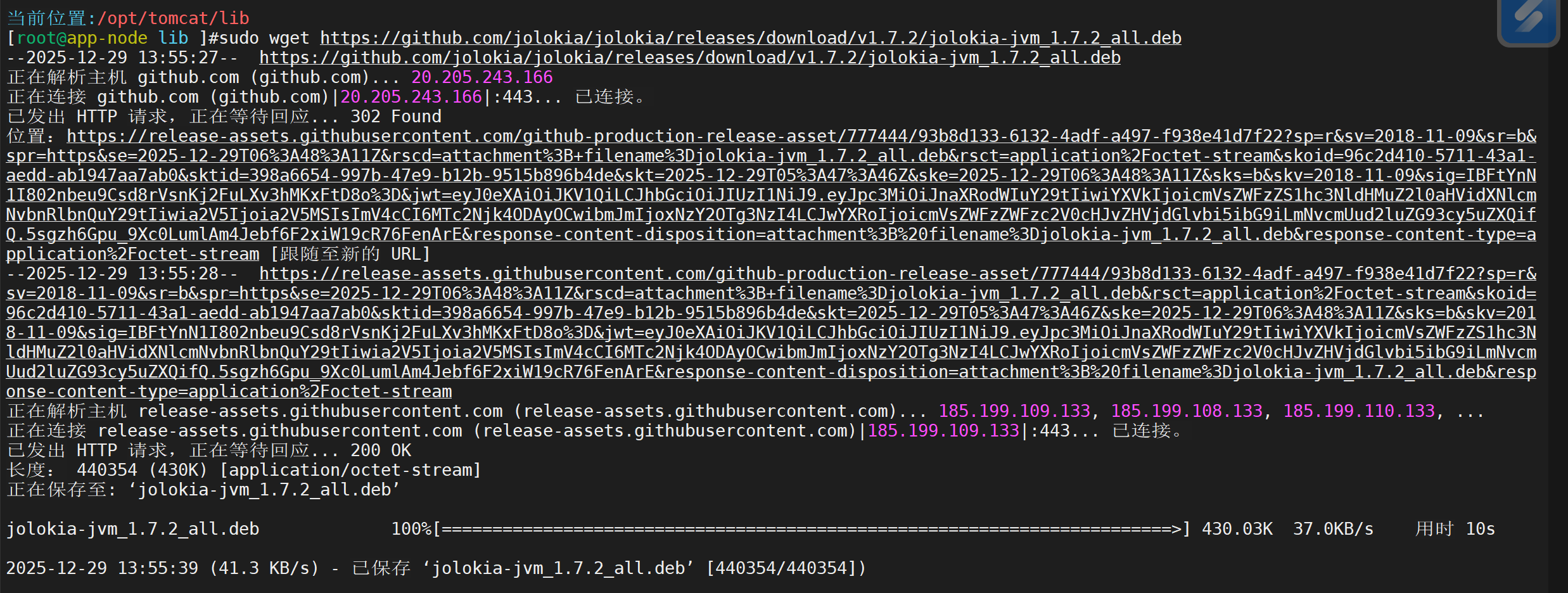
先在Tomcat启用Jolokia(下载jar放lib)

配置Metricbeat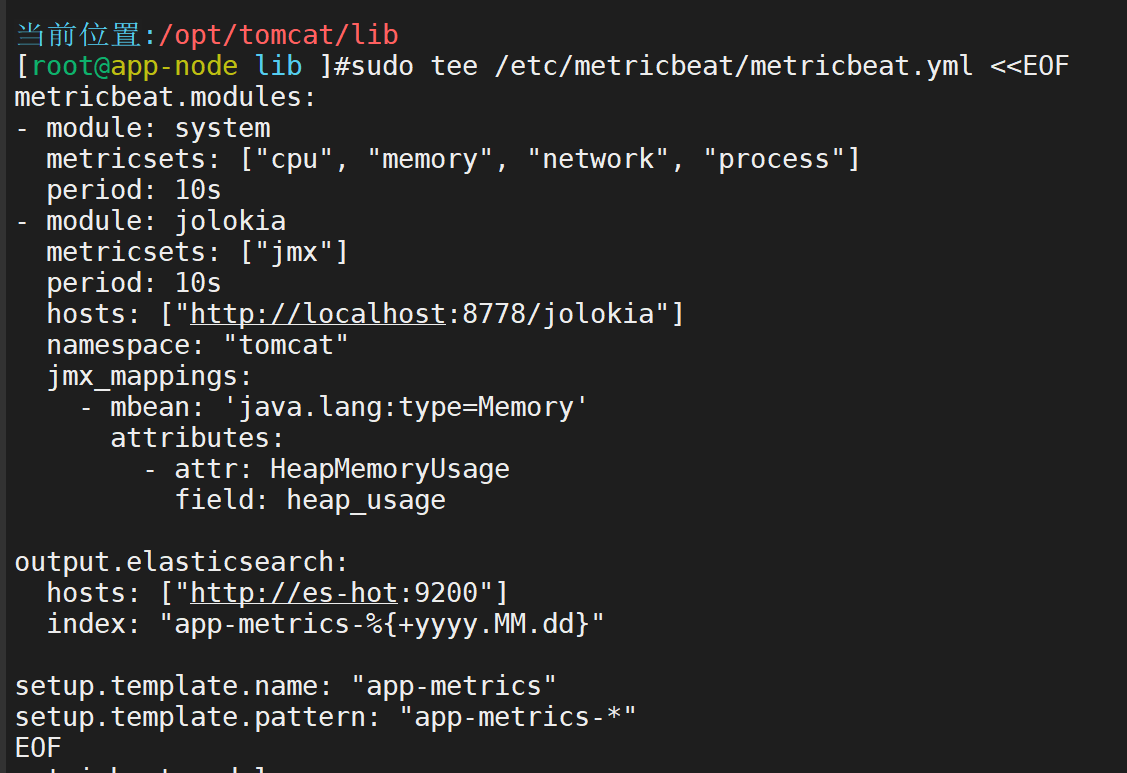
Heartbeat监控接口心跳
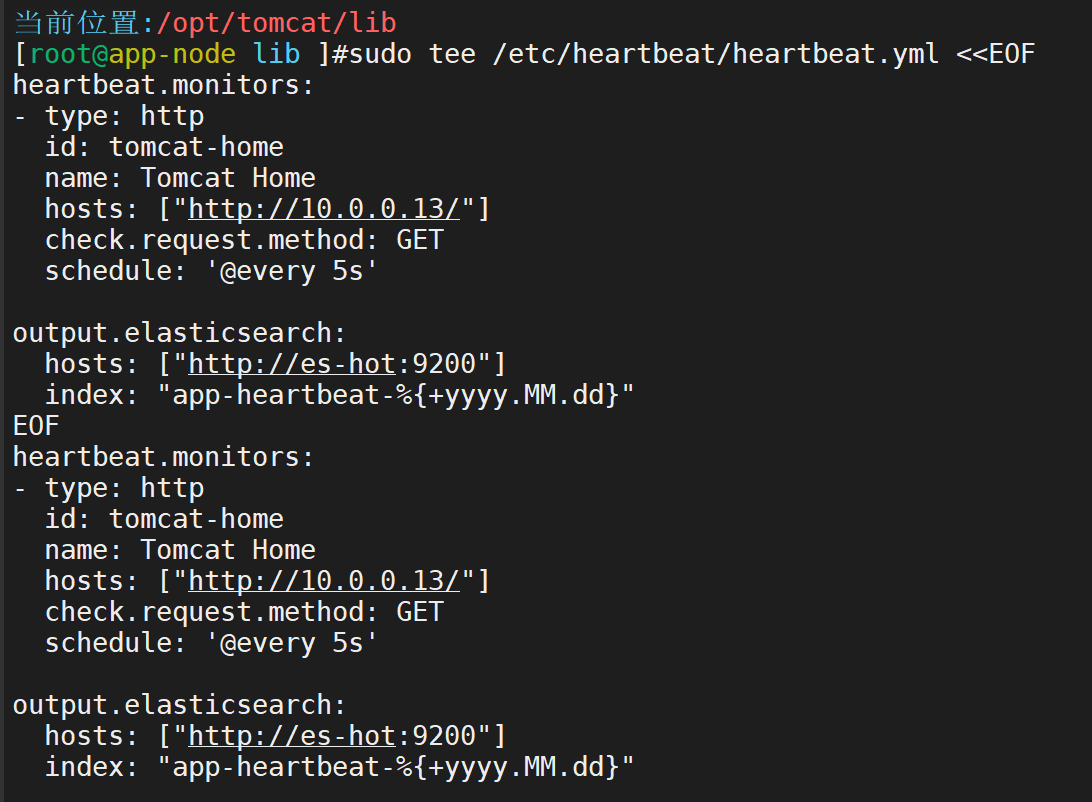
启动所有Beats

三台ES节点安装与配置(100、101、103)
安装Elasticsearch 8.x
修改配置文件(每台不同部分见下面) sudo vim /etc/elasticsearch/elasticsearch.yml
es-hot (10.0.0.100) 配置:
cluster.name: elk-lab-cluster
node.name: es-hot
network.host: 0.0.0.0
discovery.seed_hosts: ["es-hot", "es-warm", "es-cold"]
cluster.initial_master_nodes: ["es-hot"]
node.roles: ["master", "data_hot", "ingest"]
# Hot节点建议更多内存和更快磁盘
xpack.security.enabled: false # 学习用先关闭安全es-warm (10.0.0.101) 配置
cluster.name: elk-lab-cluster
node.name: es-warm
network.host: 0.0.0.0
discovery.seed_hosts: ["es-hot", "es-warm", "es-cold"]
node.roles: ["data_warm"]
xpack.security.enabled: falsees-cold (10.0.0.103) 配置
cluster.name: elk-lab-cluster
node.name: es-cold
network.host: 0.0.0.0
discovery.seed_hosts: ["es-hot", "es-warm", "es-cold"]
node.roles: ["data_cold"]
xpack.security.enabled: false然后均执行:sudo systemctl enable --now elasticsearch
第五步:在es-hot安装Kibana
sudo apt install kibana -y
sudo tee /etc/kibana/kibana.yml <<EOF
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://es-hot:9200"]
EOF
sudo systemctl enable --now kibana第六步:配置ILM策略(热-温-冷自动迁移)
在Kibana → Stack Management → Index Lifecycle Policies → Create policy
名称:app-lifecycle
- Hot phase:Rollover at 500MB or 1d
- Warm phase:After 2d → move to warm nodes, set replica=1
- Cold phase:After 7d → move to cold nodes
- Delete phase:After 30d(可先不设)
保存后,在Kibana → Index Management → Index Templates → Create template
创建三个模板(logs、metrics、heartbeat),分别把ILM policy设为app-lifecycle
或者直接用命令(在es-hot执行):
curl -X PUT "http://localhost:9200/_ilm/policy/app-lifecycle" -H 'Content-Type: application/json' -d'
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "500mb",
"max_primary_shard_size": "500mb",
"max_age": "1d"
}
}
},
"warm": {
"min_age": "2d",
"actions": {
"allocate": {
"require": { "data": "warm" }
}
}
},
"cold": {
"min_age": "7d",
"actions": {
"allocate": {
"require": { "data": "cold" }
}
}
}
}
}
}'第七步:模拟OOM并在Kibana快速定位全链路
- 浏览器访问 http://10.0.0.13/oom/index.jsp → 开始疯狂分配内存
- 几秒到几十秒后Tomcat OOM崩溃,catalina.out出现java.lang.OutOfMemoryError
- Heartbeat检测到服务down
打开Kibana → Discover
创建几个查询(一分钟内完成):
- 查询1:tags: "tomcat" AND "OutOfMemoryError" → 看到异常日志
- 查询2:tags: "nginx" 时间范围同上 → 看到大量访问/oom的请求
- 查询3:索引app-metrics-* → JVM heap_usage 暴涨到100%
- 查询4:索引app-heartbeat-* → 看到up → down
- 在Stack Management → Indices → 查看索引shard已迁移到warm/cold节点
3.双机房各 4 节点 MinIO 集群通过 MC 配置 site replication 实现 200 GB 小文件双活同步,并演示磁盘故障自愈、定时备份及 Prometheus 复制延迟告警。
机房IP 地址主机名建议角色
Site A10.0.0.20minio-a1MinIO 节点 1
Site A10.0.0.21minio-a2MinIO 节点 2
Site A10.0.0.22minio-a3MinIO 节点 3
Site A10.0.0.23minio-a4MinIO 节点 4 + Prometheus
Site B10.0.0.24minio-b1MinIO 节点 1
Site B10.0.0.25minio-b2MinIO 节点 2
Site B10.0.0.26minio-b3MinIO 节点 3
Site B10.0.0.27minio-b4MinIO 节点 4
第一步:所有 8 台主机通用准备
每台执行以下命令(作为 root 或用 sudo):
# 1. 更新系统
apt update && apt upgrade -y
# 2. 设置主机名(根据表格改,例如 minio-a1)
hostnamectl set-hostname minio-a1
# 3. 配置 /etc/hosts 解析(所有 8 台都添加相同内容,便于域名访问)
tee -a /etc/hosts <<EOF
10.0.0.20 minio-a1
10.0.0.21 minio-a2
10.0.0.22 minio-a3
10.0.0.23 minio-a4
10.0.0.24 minio-b1
10.0.0.25 minio-b2
10.0.0.26 minio-b3
10.0.0.27 minio-b4
EOF
# 4. 安装 MinIO 二进制(最新版,替换为当前日期的 RELEASE 标签)
wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
mv minio /usr/local/bin/
# 5. 安装 MC (MinIO Client)
wget https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x mc
mv mc /usr/local/bin/
# 6. 创建存储目录(模拟 4 驱动器,每个节点用 loopback 或实际分区)
for i in {1..4}; do mkdir -p /data${i}; done
chown -R $USER:$USER /data*
# 7. 重启生效
reboot第二步:配置 Site A 集群(10.0.0.20-23)
在每台 Site A 主机上创建 MinIO 服务文件,并启动独立 4 节点分布式集群(纠删码模式,默认 EC:4)。
# 创建 systemd 服务文件
tee /etc/systemd/system/minio.service <<EOF
[Unit]
Description=MinIO
Documentation=https://min.io/docs/minio/linux/index.html
Wants=network-online.target
After=network-online.target
[Service]
WorkingDirectory=/usr/local/
User=root
Group=root
EnvironmentFile=-/etc/default/minio
ExecStart=/usr/local/bin/minio server \
--address ":9000" \
--console-address ":9001" \
http://minio-a{1...4}/data{1...4}
StandardOutput=journal
StandardError=inherit
SyslogIdentifier=minio
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# 创建环境变量文件(替换为你的访问密钥)
tee /etc/default/minio <<EOF
MINIO_ROOT_USER=minioadmin
MINIO_ROOT_PASSWORD=minioadmin123
MINIO_VOLUMES="http://minio-a{1...4}/data{1...4}"
EOF
# 启动服务
systemctl daemon-reload
systemctl enable --now minio
# 检查状态
systemctl status minio
mc alias set sitea http://10.0.0.20:9000 minioadmin minioadmin123
mc admin info sitea重复在 21-23 上(VOLUMES 相同,确保所有节点看到相同配置)。访问 http://10.0.0.20:9001 登录 Console,确认集群有 4 节点。
第三步:配置 Site B 集群(10.0.0.24-27)
类似第二步,但主机名为 minio-b{1...4},别名设为 siteb。
# 服务文件类似,改 VOLUMES 为 http://minio-b{1...4}/data{1...4}
# 环境文件类似
# 启动并检查
mc alias set siteb http://10.0.0.24:9000 minioadmin minioadmin123
mc admin info siteb第四步:通过 MC 配置 Site Replication(双活同步)
基于 MinIO 官方文档,实现 Active-Active 站点复制。
在 Site A 创建同步桶:mc mb sitea/sync-bucket --with-versioning
配置站点复制(在任意一台执行,mc 已设 alias):
添加 Site A 和 Site B 到 MC
mc admin replicate add sitea siteb
验证状态
mc admin replicate info sitea
mc admin replicate info siteb
为特定桶启用双向桶复制(Active-Active):
mc replicate add sitea/sync-bucket \
--remote-bucket http://10.0.0.24:9000/sync-bucket \
--arn arn:minio:replication::sitea:sync-bucket \
--replicate "delete,delete-marker,existing-objects,replica-metadata-sync" \
--priority 1
# 对 Site B 反向配置
mc replicate add siteb/sync-bucket \
--remote-bucket http://10.0.0.20:9000/sync-bucket \
--arn arn:minio:replication::siteb:sync-bucket \
--replicate "delete,delete-marker,existing-objects,replica-metadata-sync" \
--priority 1
# 验证
mc replicate ls sitea/sync-bucket现在两个站点会双向同步 sync-bucket 中的对象。
第五步:生成 200GB 小文件并演示双活同步
在任意一台(例如 10.0.0.20)生成文件并上传。
# 生成 200,000 个 1MB 文件(总 200GB),用脚本
mkdir /tmp/small-files
for i in {1..200000}; do dd if=/dev/urandom of=/tmp/small-files/file${i}.dat bs=1M count=1; done
# 上传到 Site A
mc cp --recursive /tmp/small-files/ sitea/sync-bucket/
# 监控同步到 Site B(用 watch)
watch mc ls siteb/sync-bucket
# 验证同步完成(比较对象数)
mc ls --recursive sitea/sync-bucket | wc -l
mc ls --recursive siteb/sync-bucket | wc -l上传后,从 Site B 下载一个文件验证一致性。演示双活:在 Site B 修改/删除一个文件,检查 Site A 同步。
第六步:演示磁盘故障自愈
MinIO 使用纠删码 (EC) 自动自愈。
模拟磁盘故障(在 minio-a1 上停掉一个磁盘):
mv /data1 /data1.bak # 模拟故障
systemctl restart minio
检查集群状态(在 Console 或):
mc admin info sitea # 看到一个驱动器 down,集群 degraded 但可用
自愈演示
替换"坏"磁盘
mkdir /data1 # 新磁盘
chown USER:USER /data1
systemctl restart minio
监控自愈
watch mc admin heal sitea/ --recursive
自愈完成后,集群恢复 green 状态。重复上传文件验证数据完整。
第七步:定时备份
用 MC mirror + cron 定时备份 sync-bucket 到本地或另一个桶
创建备份桶
mc mb sitea/backup-bucket
配置 cron 任务
crontab -e
添加:0 0 * * * mc mirror sitea/sync-bucket sitea/backup-bucket --overwrite --remove
手动测试
mc mirror sitea/sync-bucket sitea/backup-bucket --overwrite --remove
第八步:配置 Prometheus 复制延迟告警
在 Site A 的 minio-a4 (10.0.0.23) 上安装 Prometheus,监控 replication latency。
安装 Prometheus
apt install prometheus -y
配置 MinIO 暴露指标
MINIO_PROMETHEUS_AUTH_TYPE=public
配置 Prometheus scrape
scrape_configs:
- job_name: 'minio-sitea'
static_configs:
- targets: '10.0.0.20:9000', '10.0.0.21:9000', '10.0.0.22:9000', '10.0.0.23:9000'
metrics_path: /minio/v2/metrics/cluster
- job_name: 'minio-siteb'
static_configs:
- targets: '10.0.0.24:9000', '10.0.0.25:9000', '10.0.0.26:9000', '10.0.0.27:9000'
metrics_path: /minio/v2/metrics/cluster
添加告警规则
groups:
- name: minio-replication
rules:
- alert: HighReplicationLatency
expr: minio_replication_avg_latency_ms > 500 # 延迟 > 500ms 告警
for: 5m
labels:
severity: warning
annotations:
summary: "Replication latency high on {{ $labels.instance }}"
description: "Average replication latency is {{ $value }} ms"
演示告警
手动上传大文件或模拟延迟,访问 Prometheus UI http://10.0.0.23:9090/alerts 查看告警触发。