文章目录
- [类人脑的另一种计算 ------大语言模型large-lauguage-model](#类人脑的另一种计算 ——大语言模型large-lauguage-model)
类人脑的另一种计算 ------大语言模型large-lauguage-model
第三章节:基础名词说完啦,去看一个模型的生命周期
AI大模型整个流程中训练到推理要三个过程
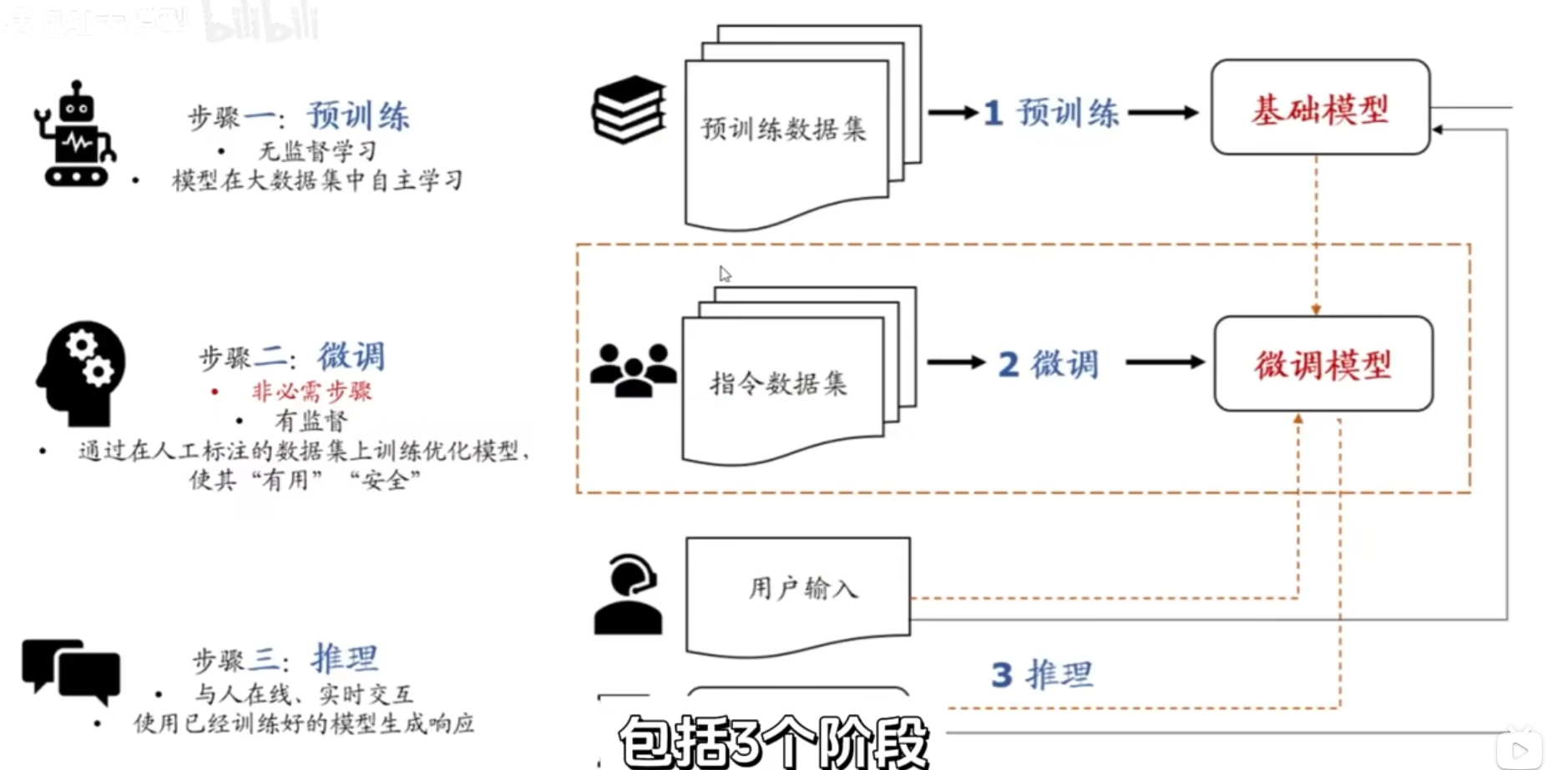
一、预训练
通过海量通用文本预训练,学习语言的通用规律(语法、语义、逻辑、常识),并把这些规律固化成模型参数,为后续具体任务提供 "通用语言能力
通过预训练的模型叫做基座模型,每个词的embedding以及这个词的qkv向量就在此时训练出来。
预训练流程:
- 给他一大堆一大堆的文章让他自己去读
比如gpt3这个基座模型有多个互联网文本做一个语料库学习:维基百科、书籍、文章等等等等
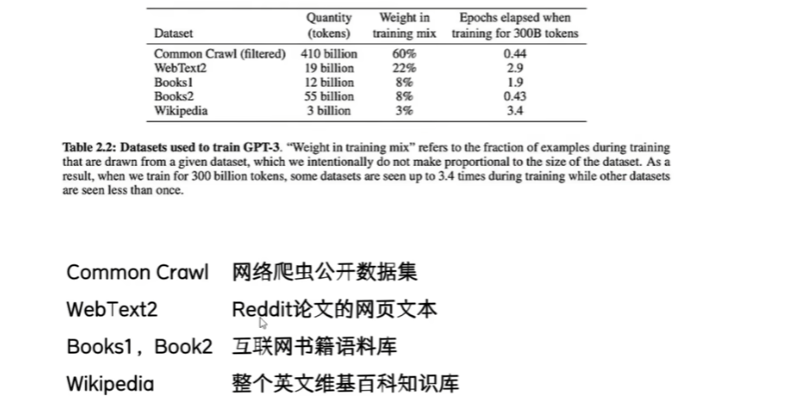
- 大模型把句子拆开、通过"分词器"拆分Token,把一句话分成多个Token(),逐个理解词的的意思。
不同模型的"分词器"不同,拆分出的Token也不一样。
一个token可以是一个词、半个词、一个标点符号、甚至是经常一起出现的多个词的一小段话。用token ID表达这个token
Token的拆分很重要,它会直接影响模型的性能,在这些token的基础上进行一个计算和推理
大模型处理文本的过程:先把句子拆成字,再理解每个字的意思,最后理解整句话的逻辑。只不过大模型的"拆字"和"理解",是通过"Tokenization→Token ID→向量"这三个步骤完成的。
- Token ID:给Token"编个号"
模型无法直接处理文本,只能处理数字。
Token ID只是一个"索引",没有任何语义。
- 向量:给Token"注入语义"
真正让模型"理解"语义的。
再次转化 Token ID转换成一个"语义向量",这个向量就像一个"语义坐标",能体现Token的含义。
例子:
比如"猫"和"狗"的Embedding向量,在空间中距离很近,因为它们都是"宠物";"猫"和"汽车"的向量距离很远,因为语义差异大。这样一来,模型通过计算向量之间的距离,就能判断两个Token的语义关联------这就是大模型"理解"语言的核心。
无监督:并不会知道,所以大模型只能分类(在未加标签情况下试图找到它的隐藏结构)
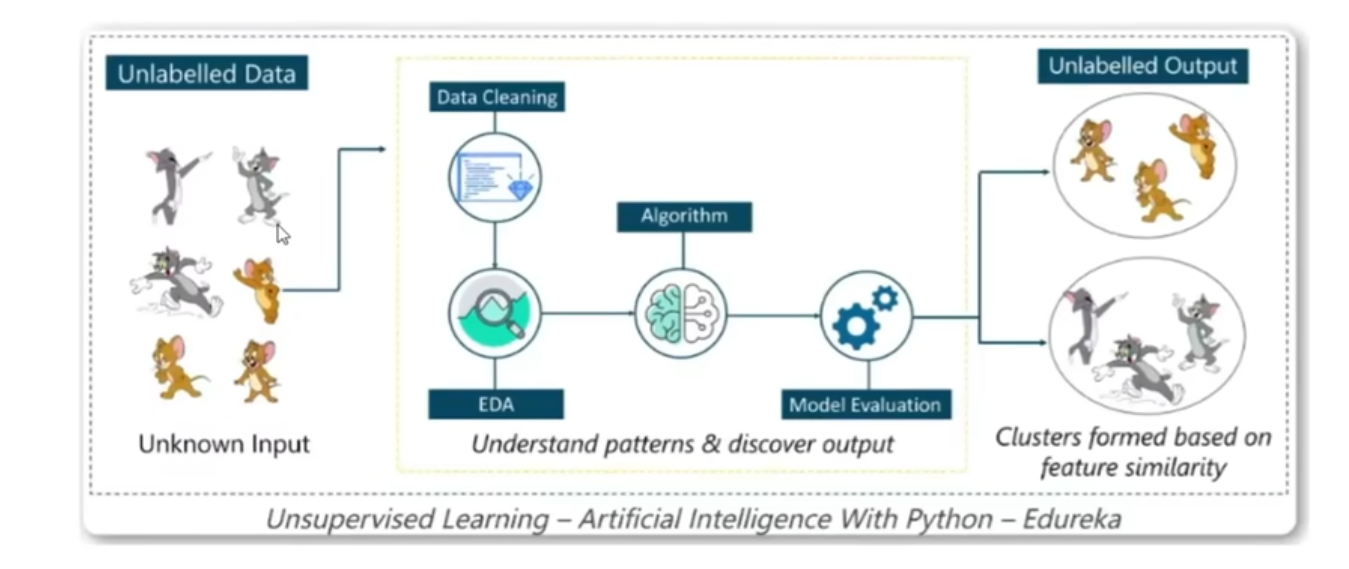
所以在无监督学习中:大模型会自行学习人类语言中的语法语义,了解表达结构和模式,有了大量无监督学习后就可以进行根据上文对下文的预测,具体就是:模型会根据看到的一部分文本然后基于上限文的常识去预测下一个token,然后比较正确答案和他的预测,模型再更新权重,随着见过的文本越多,生成也就越好,预训的结果就是得到一个基座模型,基座模型和gpt背后和人对话的模型还是有很大差别的
二、微调
基座模型此时还并不擅长对话,需要对它进行进一步的微调(会修改模型内部的一些参数,让模型更加适合特定的一个任务)
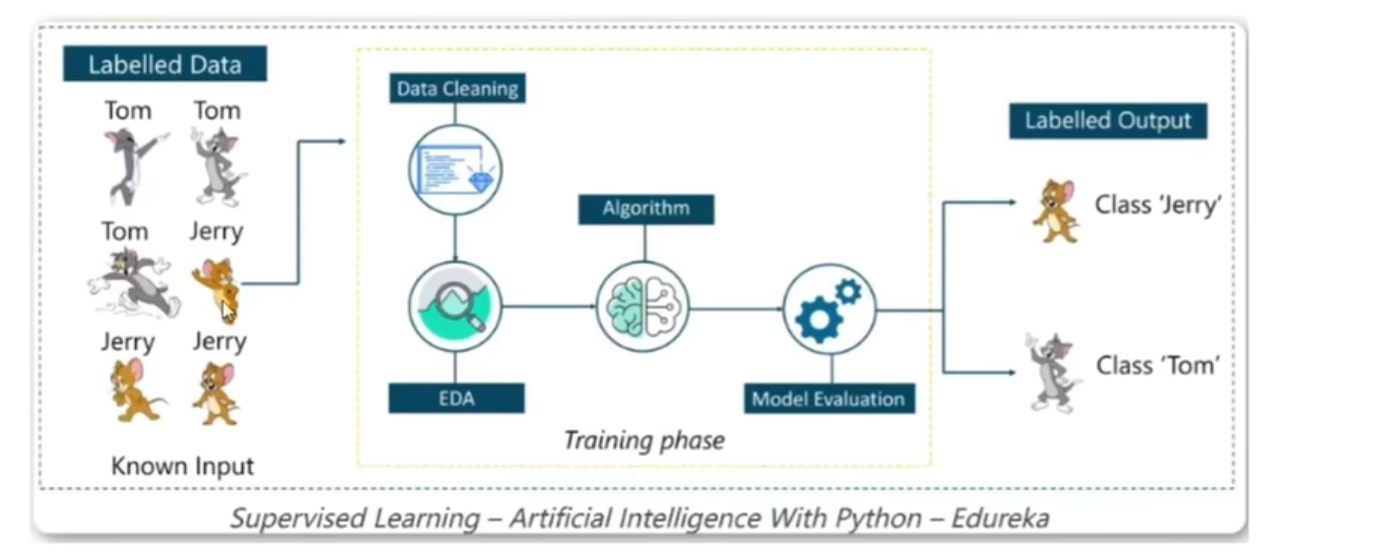
微调部分为监督学习,如使用深度神经网络(Transformer)去理解文本,在理解文本过程中将输入的文本设为x,预测的下一个词设为y
再通过前面说的线性回归、逻辑回归
计算这一层预测值对比正确值的均方误差、损失值,后通过链式法则、反向传播实现梯度下降,并不断更新模型参数的权重,使之预测概率越来越准。
也可以考虑培养侧重点,侧重模型功能方向、是多看对话数据还是多看代码功能。
三、推理
用户输入一句话,把这一句话切成多个token然后作为入参,推测出下一个词
再把下一个词合并到一句话的末尾再切成多个token然后作为入参,推测出下一个词
重复多次。。。
最后推测下一个词是结束符号。结束(可控制)
微调之后可以进行强化学习:让模型在环境中采取行动,并获得结果反馈,从反馈中继续学习,从而在特定情况中采取最佳行动反馈