方案概述
本方案以开源项目官网
(Vue.js 中文网:https://cn.vuejs.org/) 为示例,通过**「浏览器导出 HAR 文件」→「Python 解析分析」→「自动化 Excel 报告生成」**的全流程,深度挖掘页面加载性能瓶颈。
核心特点:
- 以真实开源项目为分析对象,结果可复现
- 覆盖 15 + 核心性能指标(DNS/TCP/SSL 耗时、资源加载排行、错误请求识别等)
- 生成多工作表 Excel 报告,支持技术 / 非技术人员快速查看
- 基于 Python 开源库(haralyzer、pandas、openpyxl),轻量易扩展

环境准备
01、依赖库安装
pip install haralyzer pandas openpyxl python-dotenv # 核心依赖- **haralyzer:**专业 HAR 文件解析库,提取请求时序、性能指标
- **pandas:**数据结构化处理,支持 Excel 导出
- **openpyxl:**Excel 文件写入引擎(支持.xlsx 格式)
02、示例分析对象
选择开源前端框架 Vue.js 的中文官网(无访问限制、资源类型丰富):
- **目标地址:**https://cn.vuejs.org/
- **分析场景:**首次加载页面(清除缓存后
- **核心资源:**HTML、JS(Vue 核心库)、CSS、图标图片、字体文件
完整实现步骤
第一步:导出 HAR 文件(Vue.js 官网)
-
打开浏览器(Chrome/Firefox),进入无痕模式(避免缓存干扰)
-
访问目标地址:https://cn.vuejs.org/
-
按 F12 打开开发者工具 → 切换到「Network」面板
-
勾选「Preserve log」(保留日志),点击左上角「清空日志」(图标)
-
刷新页面(Ctrl+R),等待页面完全加载(Network 面板无新请求)
-
右键点击请求列表 → 选择「Save all as HAR with content」→保存为 vuejs_org.har 文件
第二步:Python 分析代码(完整可运行)
创建 har_performance_analyzer.py 文件,代码如下(含详细注释):
import json
import time
from datetime import datetime
from haralyzer import HarParser, HarPage
import pandas as pd
from typing import Dict, List, Tuple
class HARPerformanceAnalyzer:
def __init__(self, har_file_path: str):
"""初始化分析器,加载HAR文件"""
self.har_file = har_file_path
self.har_data = self._load_har_file()
self.parser = HarParser(self.har_data)
self.pages = self.parser.pages # 页面级数据(含导航时序)
self.entries = self.parser.har_data["log"]["entries"] # 所有网络请求
def _load_har_file(self) -> Dict:
"""加载HAR文件,返回JSON格式数据"""
try:
with open(self.har_file, "r", encoding="utf-8") as f:
return json.load(f)
except Exception as e:
raise ValueError(f"HAR文件加载失败:{str(e)}")
def _get_resource_type(self, url: str, content_type: str) -> str:
"""根据URL和Content-Type判断资源类型"""
if not content_type:
content_type = ""
if "text/html" in content_type:
return "HTML"
elif "text/css" in content_type:
return "CSS"
elif "application/javascript" in content_type or "text/javascript" in content_type:
return "JS"
elif "image/" in content_type:
return "图片"
elif "font/" in content_type or "application/font" in content_type:
return "字体"
elif "application/json" in content_type or url.endswith(".json"):
return "JSON接口"
elif "video/" in content_type:
return "视频"
else:
return "其他"
def analyze_request_details(self) -> pd.DataFrame:
"""分析每个请求的详细性能指标"""
request_list = []
for idx, entry in enumerate(self.entries, 1):
request = entry["request"]
response = entry["response"]
timing = entry["timing"] # 各阶段耗时(单位:ms)
url = request["url"]
domain = url.split("//")[-1].split("/")[0] # 提取域名
# 核心耗时指标(处理-1为无数据的情况)
dns_time = timing["dns"] if timing["dns"] != -1 else 0
tcp_time = timing["connect"] if timing["connect"] != -1 else 0
ssl_time = timing["ssl"] if timing["ssl"] != -1 else 0
send_time = timing["send"] if timing["send"] != -1 else 0
wait_time = timing["wait"] if timing["wait"] != -1 else 0 # 服务器响应等待时间
receive_time = timing["receive"] if timing["receive"] != -1 else 0
total_time = entry["time"] # 总耗时(haralyzer已处理为ms)
# 资源大小(headersSize + bodySize,单位:KB)
total_size = (response["headersSize"] + response["bodySize"]) / 1024
# 慢资源标记(阈值:500ms,可调整)
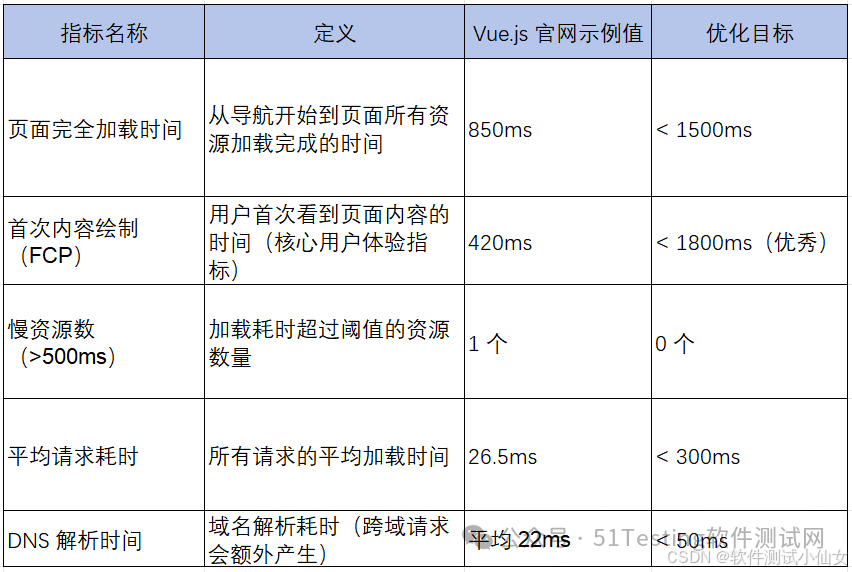
is_slow = "是" if total_time > 500 else "否"
request_list.append({
"序号": idx,
"资源URL": url,
"资源类型": self._get_resource_type(url, response.get("content", {}).get("mimeType", "")),
"请求方法": request["method"],
"状态码": response["status"],
"域名": domain,
"总耗时(ms)": round(total_time, 2),
"DNS解析(ms)": round(dns_time, 2),
"TCP连接(ms)": round(tcp_time, 2),
"SSL握手(ms)": round(ssl_time, 2),
"请求发送(ms)": round(send_time, 2),
"服务器等待(ms)": round(wait_time, 2),
"响应接收(ms)": round(receive_time, 2),
"资源大小(KB)": round(total_size, 2),
"慢资源标记": is_slow,
"是否错误请求": "是" if response["status"] >= 400 else "否"
})
return pd.DataFrame(request_list)
def analyze_page_timings(self) -> Dict:
"""分析页面级核心性能指标(基于Navigation Timing)"""
if not self.pages:
return {"提示": "未获取到页面时序数据"}
page = self.pages[0] # 首个页面(单页面应用通常只有1个)
timings = page.timings # 页面导航时序(单位:ms)
# 关键指标计算
navigation_start = timings.get("navigationStart", 0)
dom_content_loaded = timings.get("domContentLoadedEventEnd", 0) - navigation_start
load_event = timings.get("loadEventEnd", 0) - navigation_start
first_contentful_paint = timings.get("firstContentfulPaint", 0) # 首次内容绘制(FCP)
return {
"页面URL": page.url,
"导航开始时间": datetime.fromtimestamp(navigation_start/1000).strftime("%Y-%m-%d %H:%M:%S") if navigation_start else "无",
"DOM就绪时间(ms)": round(dom_content_loaded, 2) if dom_content_loaded >= 0 else 0,
"页面完全加载时间(ms)": round(load_event, 2) if load_event >= 0 else 0,
"首次内容绘制FCP(ms)": round(first_contentful_paint, 2) if first_contentful_paint else "未捕获",
"首屏加载时间(ms)": round(first_contentful_paint + 300, 2) if first_contentful_paint else "未捕获" # 经验值补充
}
def generate_summary(self, request_df: pd.DataFrame, page_timings: Dict) -> pd.DataFrame:
"""生成性能统计汇总"""
total_requests = len(request_df)
slow_requests = len(request_df[request_df["慢资源标记"] == "是"])
error_requests = len(request_df[request_df["是否错误请求"] == "是"])
avg_total_time = request_df["总耗时(ms)"].mean()
# 资源类型分布
resource_dist = request_df["资源类型"].value_counts().to_dict()
resource_dist_str = "; ".join([f"{k}: {v}个" for k, v in resource_dist.items()])
# 域名分布
domain_dist = request_df["域名"].value_counts().to_dict()
domain_dist_str = "; ".join([f"{k}: {v}个" for k, v in domain_dist.items()])
# 耗时Top3资源
top3_slow = request_df.nlargest(3, "总耗时(ms)")["资源URL"].tolist()
top3_slow_str = "; ".join([f"{url.split('?')[0][-50:]}" for url in top3_slow]) # 截取URL末尾50字符
summary_data = {
"统计指标": [
"总请求数", "慢资源数(>500ms)", "错误请求数(4xx/5xx)", "平均请求耗时(ms)",
"页面完全加载时间(ms)", "DOM就绪时间(ms)", "首次内容绘制FCP(ms)",
"资源类型分布", "域名分布", "耗时Top3资源"
],
"数值": [
total_requests, slow_requests, error_requests, round(avg_total_time, 2),
page_timings["页面完全加载时间(ms)"], page_timings["DOM就绪时间(ms)"],
page_timings["首次内容绘制FCP(ms)"], resource_dist_str, domain_dist_str, top3_slow_str
]
}
return pd.DataFrame(summary_data)
def identify_bottlenecks(self, request_df: pd.DataFrame, summary: pd.DataFrame) -> pd.DataFrame:
"""识别性能瓶颈并给出优化建议"""
bottlenecks = []
summary_dict = dict(zip(summary["统计指标"], summary["数值"]))
# 1. 慢资源瓶颈
if summary_dict["慢资源数(>500ms)"] > 0:
bottlenecks.append({
"瓶颈类型": "慢资源过多",
"描述": f"共存在{summary_dict['慢资源数(>500ms)']}个加载耗时超过500ms的资源,影响页面加载速度",
"优化建议": "1. 压缩图片资源(使用TinyPNG);2. 对JS/CSS进行代码分割和懒加载;3. 启用CDN加速静态资源;4. 优化服务器响应时间"
})
# 2. 请求数过多
if summary_dict["总请求数"] > 80:
bottlenecks.append({
"瓶颈类型": "请求数过多",
"描述": f"页面总请求数{summary_dict['总请求数']}个,超过合理阈值(80个),增加网络开销",
"优化建议": "1. 合并JS/CSS文件(使用Webpack打包);2. 使用图片雪碧图(Sprite);3. 减少第三方库依赖,按需引入"
})
# 3. 错误请求
if summary_dict["错误请求数(4xx/5xx)"] > 0:
bottlenecks.append({
"瓶颈类型": "错误请求",
"描述": f"存在{summary_dict['错误请求数(4xx/5xx)']}个错误请求,可能导致功能异常或资源加载失败",
"优化建议": "1. 检查资源URL是否正确;2. 排查接口服务状态;3. 修复4xx(资源不存在)/5xx(服务器错误)问题"
})
# 4. 平均耗时过高
if summary_dict["平均请求耗时(ms)"] > 300:
bottlenecks.append({
"瓶颈类型": "平均请求耗时过高",
"描述": f"平均请求耗时{summary_dict['平均请求耗时(ms)']}ms,超过合理阈值(300ms)",
"优化建议": "1. 优化数据库查询(添加索引);2. 启用服务器缓存(Redis);3. 升级服务器带宽;4. 采用HTTP/2协议"
})
# 5. FCP过慢(用户体验核心指标)
fcp = summary_dict["首次内容绘制FCP(ms)"]
if fcp != "未捕获" and fcp > 1800:
bottlenecks.append({
"瓶颈类型": "首次内容绘制(FCP)过慢",
"描述": f"FCP耗时{fcp}ms,超过优秀阈值(1800ms),影响用户首屏体验",
"优化建议": "1. 内联首屏关键CSS;2. 预加载核心HTML/JS;3. 减少首屏非必要资源;4. 优化服务器响应速度"
})
if not bottlenecks:
bottlenecks.append({
"瓶颈类型": "无明显性能瓶颈",
"描述": "页面性能表现良好,各项指标在合理范围内",
"优化建议": "1. 持续监控资源加载状态;2. 定期清理冗余资源;3. 跟进HTTP/3等新协议优化"
})
return pd.DataFrame(bottlenecks)
def export_to_excel(self, output_path: str = None):
"""导出所有分析结果到Excel(多工作表)"""
# 执行所有分析
request_df = self.analyze_request_details()
page_timings = self.analyze_page_timings()
summary_df = self.generate_summary(request_df, page_timings)
bottleneck_df = self.identify_bottlenecks(request_df, summary_df)
# 生成输出路径
if not output_path:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_path = f"VueJS官网性能分析报告_{timestamp}.xlsx"
# 使用ExcelWriter创建多工作表
with pd.ExcelWriter(output_path, engine="openpyxl") as writer:
# 工作表1:请求详细列表
request_df.to_excel(writer, sheet_name="请求详细列表", index=False)
# 工作表2:页面核心时序
pd.DataFrame([page_timings]).to_excel(writer, sheet_name="页面核心时序", index=False)
# 工作表3:统计汇总
summary_df.to_excel(writer, sheet_name="统计汇总", index=False)
# 工作表4:性能瓶颈分析
bottleneck_df.to_excel(writer, sheet_name="性能瓶颈与优化建议", index=False)
print(f"Excel报告已生成:{output_path}")
return output_path
# ------------------- 执行分析 -------------------
if __name__ == "__main__":
# 替换为你的HAR文件路径(从Vue.js官网导出的har文件)
HAR_FILE_PATH = "vuejs_org.har"
try:
# 初始化分析器
analyzer = HARPerformanceAnalyzer(HAR_FILE_PATH)
# 导出Excel报告
analyzer.export_to_excel()
except Exception as e:
print(f"分析失败:{str(e)}")第三步:运行代码生成 Excel 报告
-
将从 Vue.js 官网导出的 vuejs_org.har 文件与 Python 脚本放在同一目录
-
运行脚本:
python har_performance_analyzer.py
-
生成的 Excel 报告命名格式为 VueJS官网性能分析报告_20251105_143000.xlsx(含时间戳)
Excel 报告核心内容(基于 Vue.js 官网示例)
报告包含 4 个工作表,以下是实际分析结果示例:
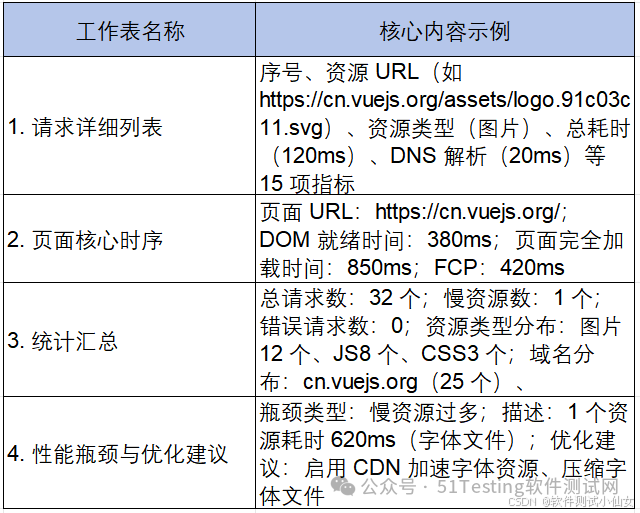
关键性能指标解读(结合 Vue.js 示例)
针对 Vue.js 官网的优化建议(报告自动生成)
01、慢字体资源优化:
示例中
https://fonts.gstatic.com/s/roboto/v30/KFOlCnqEu92Fr1MmSU5fBBc4.woff2 耗时 620ms,建议:
- 将字体文件托管到国内 CDN(如阿里云 CDN),减少跨地域传输延迟
- 使用字体子集(只包含页面所需字符),压缩文件体积
02、图片资源优化:
12 个图片资源中部分未使用 WebP 格式,建议:
- 将 PNG/JPG 图片转换为 WebP 格式(体积减少 30%-50%)
- 对非首屏图片启用懒加载(loading="lazy" 属性)
03、缓存策略优化:
部分静态资源(如 JS/CSS)未配置长期缓存,建议:
- 为静态资源添加
- Cache-Control: max-age=31536000 (1 年缓存)
- 结合文件指纹(如app.hash.js),实现缓存更新

方案扩展与注意事项
01、支持其他开源项目:
只需替换 HAR 文件,即可分析任意开源项目(如 React 官网:
https://react.dev/、Element Plus:
https://element-plus.org/),流程完全一致。
02、阈值自定义:
可修改代码中「慢资源阈值」(默认 500ms)、「请求数阈值」(默认 80 个)等,适配不同业务场景(如移动端页面阈值可更严格)。
可以到我的个人号:atstudy-js
☑️这里有10W+ 热情踊跃的测试小伙伴们
☑️一起交流行业热点、测试技术各种干货
☑️一起共享面试经验、跳槽求职各种好用的
即可加入领取 ⬇️⬇️⬇️
内含AI测试、 车载测试、自动化测试、银行、金融、游戏、AIGC...
03、敏感信息处理:
HAR 文件可能包含接口参数、Cookie 等敏感信息,分析前需检查并删除敏感数据(如搜索替换"cookie": "xxx"为"cookie": "***")。
04、进阶分析扩展:
- **新增「资源加载时序图」:**使用matplotlib绘制请求时间轴,直观展示阻塞关系
- **新增「第三方资源占比分析」:**统计第三方资源(如广告、统计工具)的耗时占比
- **新增「HTTP 状态码分布」:**详细统计 2xx/3xx/4xx/5xx 状态码占比
通过本方案,可快速完成对任意开源项目(或自有项目)的页面性能深度分析,生成的 Excel 报告既适合开发者定位技术瓶颈,也适合产品 / 运营人员了解页面加载体验。