RNN模型构建
目录
1.RNN概念
2.RNN模型构建
RNN(循环神经网络)*是一种专门设计用于处理* 序列数据 的深度学习模型,其核心特点是通过循环连接在时间维度上传递信息,从而能够 "记住" 之前的输入内容。
一、RNN(循环神经网络)
循环神经网络(Recurrent Neural Network, RNN)
- 原理:引入循环连接,捕捉序列信息。
- 公式:
ht=σ(Whhht−1+Wxhxt+bh)h_t = \sigma(W_{hh} h_{t-1} + W_{xh} x_t + b_h)ht=σ(Whhht−1+Wxhxt+bh)
yt=σ(Whyht+by)y_t = \sigma(W_{hy} h_t + b_y)yt=σ(Whyht+by)
RNN具有记忆能力:上一时刻隐层的状态参与到了这个时刻的计算过程中
容易出现梯度消失问题,无法捕捉长期依赖。
所以RNN主要用于序列数据的处理
循环神经网络就是我们对之前的线性层进行复用
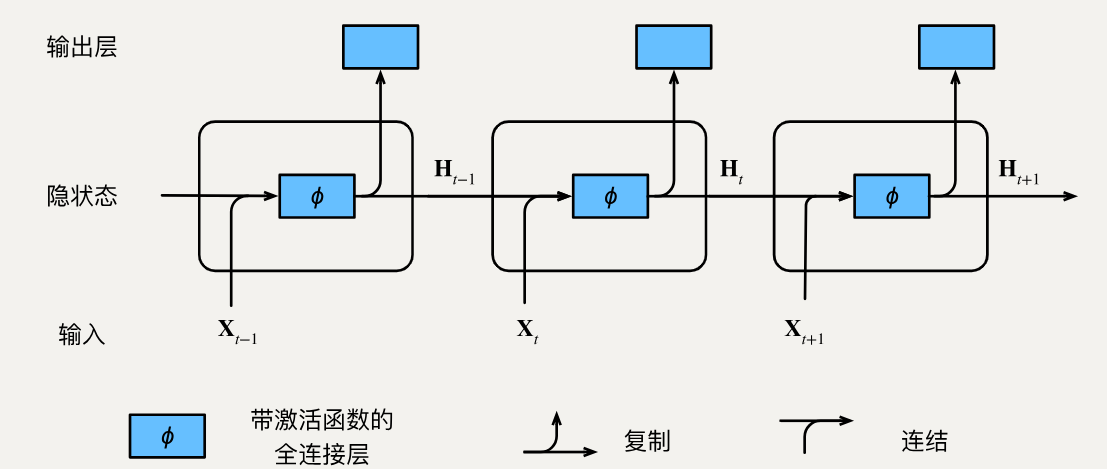
循环神经网络在三个相邻时间步的计算逻辑。 在任意时间步t,隐状态的计算可以被视为:
- 拼接当前时间步t的输入和前一时间步t-1的隐状态Ht−1\mathbf{H}_{t-1}Ht−1;
- 将拼接的结果送入带有激活函数ϕ\phiϕ的全连接层。 全连接层的输出是当前时间步t的隐状态Ht\mathbf{H}_tHt。
在本例中,模型参数是Wxh\mathbf{W}{xh}Wxh和Whh\mathbf{W}{hh}Whh的拼接, 以及bh\mathbf{b}hbh的偏置。
Ht=ϕ(XtWxh+Ht−1Whh+bh).\mathbf{H}t = \phi(\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}{hh} + \mathbf{b}_h).Ht=ϕ(XtWxh+Ht−1Whh+bh).
当前时间步t的隐状态Ht\mathbf{H}tHt 将参与计算下一时间步t+1t+1t+1的隐状态Ht+1\mathbf{H}{t+1}Ht+1。 而且Ht\mathbf{H}_tHt还将送入全连接输出层, 用于计算当前时间步t的输出Ot\mathbf{O}_tOt。
我们刚才提到,隐状态中XtWxh+Ht−1Whh\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}{hh}XtWxh+Ht−1Whh的计算, 相当于Xt\mathbf{X}tXt和Ht−1\mathbf{H}{t-1}Ht−1的拼接与Wxh\mathbf{W}{xh}Wxh和Whh\mathbf{W}{hh}Whh的拼接的矩阵乘法。
我们的目标是根据过去的和当前的词元预测下一个词元, 因此我们将原始序列移位一个词元作为标签
为了简化后续部分的训练,我们考虑使用 字符级语言模型(character-level language model), 将文本词元化为字符而不是单词
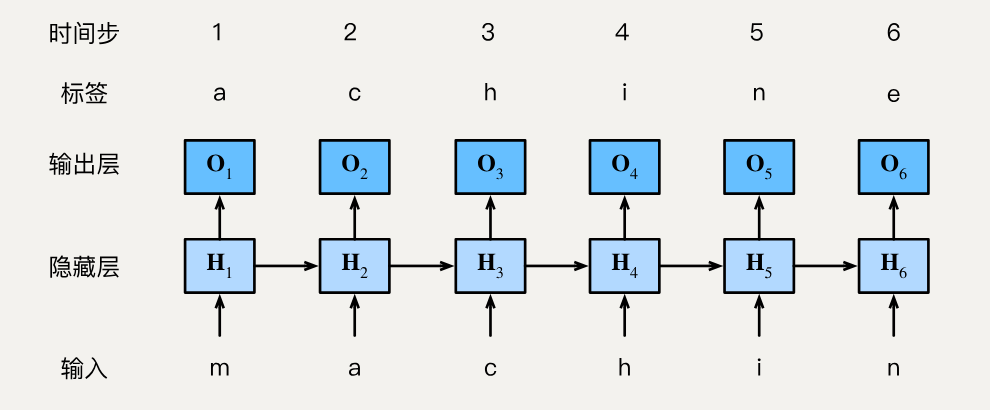
在训练过程中,我们对每个时间步的输出层的输出进行softmax操作, 然后利用交叉熵损失计算模型输出和标签之间的误差。
由于隐藏层中隐状态的循环计算,第3个时间步的输出O3\mathbf{O}_3O3 由文本序列"m""a"和"c"确定。 由于训练数据中这个文本序列的下一个字符是"h", 因此第3个时间步的损失将取决于下一个字符的概率分布, 而下一个字符是基于特征序列"m""a""c"和这个时间步的标签"h"生成的。
在实践中,我们使用的批量大小为n>1, 每个词元都由一个d维向量表示。 因此,在时间步t输入Xt\mathbf X_tXt将是一个n×dn\times dn×d矩阵
二、RNN模型构建
在构建模型之前, 我们需要准备数据:
http://www.nathanwebsite.com:880/file_resources.zip
我们先固定随机性, 使训练可复现:
python
import numpy as np
import torch
def seed_everything(seed=42):
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything()接下来, 我们需要利用RNN构建诗词生成模型
数据处理
字符级别的模型
数据样本:我,们,都,是,同,样,的,人
模型训练学习:
- 给模型输入数据
<BOS>,学会预测出我 - 给模型输入数据我,学会预测出们
- 给模型输入数据们,学会预测出都
- 给模型输入数据都,学会预测出是
- 给模型输入数据是,学会预测出同
- 给模型输入数据同,学会预测出样
- 给模型输入数据样,学会预测出的
- 给模型输入数据的,学会预测出人
- 给模型输入数据人,学会预测出
<EOS>
输入数据-标签数据
<BOS>寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。
寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。<EOS>
我们先导入文件(前面放着的网址下载下来解压缩即可)并且对文件里面的内容进行处理:
python
import re
poems = []
with open('poems.txt', 'r', encoding='utf-8') as f:
for line in f:
cleaned_line = re.sub(r'\[|\]', '', line.strip())
cleaned_line = re.sub(r'。{2,}', '。', cleaned_line)
poems.append(cleaned_line)
poems = [poem for poem in poems if len(poem) > 24]
len(poems), poems[:10]我们导入文件之后, 我们可以发现原文件里面有多余的句号(有些句子里面, 后面有两个句号的情况), 还有我们需要把中括号去掉, 每一个中括号代表一首诗, 那我们就把每一首诗都作为一个item在列表里面。
运行结果:
text
(60420,
['寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。',
'晚霞聊自怡,初晴弥可喜。日晃百花色,风动千林翠。池鱼跃不同,园鸟声还异。寄言博通者,知予物外志。',
'一朝春夏改,隔夜鸟花迁。阴阳深浅叶,晓夕重轻烟。哢莺犹响殿,横丝正网天。珮高兰影接,绶细草纹连。',
'夏律昨留灰,秋箭今移晷。峨嵋岫初出,洞庭波渐起。桂白发幽岩,菊黄开灞涘。运流方可叹,含毫属微理。',
'寒惊蓟门叶,秋发小山枝。松阴背日转,竹影避风移。提壶菊花岸,高兴芙蓉池。欲知凉气早,巢空燕不窥。',
'爽气浮丹阙,秋光澹紫宫。衣碎荷疏影,花明菊点丛。袍轻低草露,盖侧舞松风。散岫飘云叶,迷路飞烟鸿。',
'砌冷兰凋佩,闺寒树陨桐。别鹤栖琴里,离猿啼峡中。落野飞星箭,弦虚半月弓。芳菲夕雾起,暮色满房栊。',
'山亭秋色满,岩牖凉风度。疏兰尚染烟,残菊犹承露。古石衣新苔,新巢封古树。历览情无极,咫尺轮光暮。',
'秦川雄帝宅,函谷壮皇居。绮殿千寻起,离宫百雉余。连薨遥接汉,飞观迥凌虚。云日隐层阙,风烟出绮疏。',
'岩廊罢机务,崇文聊驻辇。玉匣启龙图,金绳披凤篆。韦编断仍续,缥帙舒还卷。对此乃淹留,欹案观坟典。'])我们可以发现有60420首诗。
由于字符是无法参与数学计算的,所以我们需要把字符映射为数值
构建字符级词表 {}
有两个映射字典
字符-索引 {'我':1}
索引-字符 {1:'我'}
词表大小是多少呢?
有多少个不相同的字符+特殊词元=词表大小
我们先记录特殊词元:
python
# 特殊词元
PAD_TOKEN = '<pad>'
BOS_TOKEN = '<bos>'
EOS_TOKEN = '<eos>'
UNK_TOKEN = '<unk>'
special_tokens = [PAD_TOKEN, BOS_TOKEN, EOS_TOKEN, UNK_TOKEN]我们进行词频统计:
python
word_freq = {}
for poem in poems:
# 每一首诗词
for char in poem:
# 每一个字符
word_freq[char] = word_freq.get(char, 0) + 1
sorted_chars = sorted(word_freq.items(), key=lambda x: x[1],
reverse=True) # x:(我,200)
sorted_chars[:10]结果:
python
[(',', 208997),
('。', 206442),
('不', 22854),
('人', 18429),
('山', 14515),
('风', 14093),
('无', 13640),
('一', 13204),
('日', 13196),
('云', 12300)]我们对统计的结果, 对词出现的次数进行排序, 从大到小排:
python
sorted_chars = [char for char, _ in sorted_chars]
sorted_chars[:10]结果:
python
[',', '。', '不', '人', '山', '风', '无', '一', '日', '云']刚才我们说过, 有多少个不相同的字符+特殊词元=词表大小, 所以我们需要把特殊字符也加进去, 变成词表:
python
vocab = special_tokens + sorted_chars
vocab[:10]运行结果:
python
['<pad>', '<bos>', '<eos>', '<unk>', ',', '。', '不', '人', '山', '风']接下来我们分别创建字典表(字符转索引和索引转字符的字典表):
字符转索引字典表:
python
char_to_idx = {char: i for i, char in enumerate(vocab)}
char_to_idx['人'] # 运行结果: 7索引转字符的字典表:
python
idx_to_char = {i: char for i, char in enumerate(vocab)}
idx_to_char[7] # 运行结果: '人'接下来我们总结信息:
python
vocab_size = len(vocab)
PAD_IDX = char_to_idx[PAD_TOKEN]
BOS_IDX = char_to_idx[BOS_TOKEN]
EOS_IDX = char_to_idx[EOS_TOKEN]
UNK_IDX = char_to_idx[UNK_TOKEN]
print('词汇表大小:', vocab_size)
print('PAD_IDX:', PAD_IDX)
print('BOS_IDX:', BOS_IDX)
print('EOS_IDX:', EOS_IDX)
print('UNK_IDX:', UNK_IDX)
print('字符转数值映射示例:', dict(list(char_to_idx.items())[:10]))
print('数值转字符映射示例:', dict(list(idx_to_char.items())[:10]))结果:
text
词汇表大小: 7487
PAD_IDX: 0
BOS_IDX: 1
EOS_IDX: 2
UNK_IDX: 3
字符转数值映射示例: {'<pad>': 0, '<bos>': 1, '<eos>': 2, '<unk>': 3, ',': 4, '。': 5, '不': 6, '人': 7, '山': 8, '风': 9}
数值转字符映射示例: {0: '<pad>', 1: '<bos>', 2: '<eos>', 3: '<unk>', 4: ',', 5: '。', 6: '不', 7: '人', 8: '山', 9: '风'}构建数据集
我们求出最大序列长度:
python
max_seq_length = max(len(poem) for poem in poems) + 1
print('最大序列长度:', max_seq_length)结果:
text
97最大序列程度, 也就是这么多诗词里面长度最长的诗词, 长度是97。
我们构建一个函数, 用于处理序列,将字符转换为数值,并添加BOS、EOS、PAD等特殊字符:
python
import torch
def prepare_sequence(seq: str,
char_to_idx: dict,
max_length: int = None,
add_bos: bool = True,
add_eos: bool = True):
"""
处理序列,将字符转换为数值,并添加BOS、EOS、PAD等特殊字符。
Args:
seq (str): 输入序列,字符列表。
char_to_idx (dict): 字符到数值的映射字典。
max_length (int, optional): 序列的最大长度。如果为None,则使用序列的实际长度。
add_bos (bool, optional): 是否在序列开头添加BOS字符。
add_eos (bool, optional): 是否在序列结尾添加EOS字符。
Returns:
torch.Tensor: 处理后的序列,数值列表。
"""
if add_bos:
seq = [BOS_TOKEN] + list(seq)
if add_eos:
seq = list(seq) + [EOS_TOKEN]
idxs = [char_to_idx.get(char, UNK_IDX) for char in seq]
if max_length is not None:
if len(idxs) < max_length:
idxs = idxs + [PAD_IDX] * (max_length - len(idxs))
else:
idxs = idxs[:max_length]
return torch.tensor(idxs, dtype=torch.long)函数的参数列表:
seq (str): 输入序列,字符列表。
char_to_idx (dict): 字符到数值的映射字典。
max_length (int, optional): 序列的最大长度。如果为None,则使用序列的实际长度。
add_bos (bool, optional): 是否在序列开头添加BOS字符。
add_eos (bool, optional): 是否在序列结尾添加EOS字符。
python
if len(idxs) < max_length:
idxs = idxs + [PAD_IDX] * (max_length - len(idxs))这段代码指的是判断当前的诗词的长度是否是最大的诗词, 如果不是那当前诗词的长度肯定比最大的诗词长度要短, 具体短多少呢, 那就是最大诗词长度减去当前诗词的长度, 就是具体相差多少长度。PAD_IDX就是占位符, 我们需要把短的诗词通过占位符, 也和最大诗词长度一样, 因为我们模型训练的时候, 数据是需要诗词长度都一样(向量的长度一致), 所以这里代码需要这样操作。
随后我们再创建训练样本,将诗歌转换为数值列表:
python
def create_train_samples(poems: list,
char_to_idx: dict,
max_length: int | None = None):
"""
创建训练样本,将诗歌转换为数值列表。
Args:
poems (list): 诗歌列表,每个元素是一个字符串。
char_to_idx (dict): 字符到数值的映射字典。
max_length (int, optional): 序列的最大长度。如果为None,则使用序列的实际长度。
Returns:
list: 训练样本列表,每个元素是一个torch.Tensor。
"""
inputs = []
targets = []
for poem in poems:
input_seq = prepare_sequence(poem, char_to_idx, max_length, True,
False)
target_seq = prepare_sequence(poem, char_to_idx, max_length, False,
True)
inputs.append(input_seq)
targets.append(target_seq)
return torch.stack(inputs), torch.stack(targets)函数的参数列表:
poems (list): 诗歌列表,每个元素是一个字符串。
char_to_idx (dict): 字符到数值的映射字典。
max_length (int, optional): 序列的最大长度。如果为None,则使用序列的实际长度。
然后我们就需要创建训练样本了:
python
inputs, targets = create_train_samples(poems,
char_to_idx,
max_length=max_seq_length)
print('特征张量数据集形状:', inputs.shape)
print('目标张量数据集形状:', targets.shape)
print('示例特征:', inputs[0])
print('示例目标:', targets[0])结果:
text
特征张量数据集形状: torch.Size([60420, 97])
目标张量数据集形状: torch.Size([60420, 97])
示例特征: tensor([ 1, 57, 184, 347, 1193, 557, 4, 21, 389, 152, 60, 84,
5, 157, 9, 443, 356, 196, 4, 201, 111, 161, 18, 621,
5, 210, 126, 55, 146, 173, 4, 212, 1718, 231, 86, 476,
5, 1217, 372, 157, 310, 43, 4, 781, 88, 1415, 595, 16,
5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0])
示例目标: tensor([ 57, 184, 347, 1193, 557, 4, 21, 389, 152, 60, 84, 5,
157, 9, 443, 356, 196, 4, 201, 111, 161, 18, 621, 5,
210, 126, 55, 146, 173, 4, 212, 1718, 231, 86, 476, 5,
1217, 372, 157, 310, 43, 4, 781, 88, 1415, 595, 16, 5,
2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0])接下来, 我们可以把刚才写的那两个函数写到同一个类里面去:
python
from torch.utils.data import Dataset, DataLoader
class PoemDataset(Dataset):
def __init__(self, poems: list, char_to_idx: dict, idx_to_char: dict,
max_length: int):
self.poems = poems
self.char_to_idx = char_to_idx
self.idx_to_char = idx_to_char
self.max_length = max_length
def __len__(self):
return len(self.poems)
def __getitem__(self, index):
poem = self.poems[index]
input_seq = self.prepare_sequence(poem, add_bos=True, add_eos=False)
target_seq = self.prepare_sequence(poem, add_bos=False, add_eos=True)
return input_seq, target_seq
def prepare_sequence(self,
seq: str,
add_bos: bool = True,
add_eos: bool = True):
"""
处理序列,将字符转换为数值,并添加BOS、EOS、PAD等特殊字符。
Args:
seq (str): 输入序列,字符列表。
add_bos (bool, optional): 是否在序列开头添加BOS字符。
add_eos (bool, optional): 是否在序列结尾添加EOS字符。
Returns:
torch.Tensor: 处理后的序列,数值列表。
"""
if add_bos:
seq = [BOS_TOKEN] + list(seq)
if add_eos:
seq = list(seq) + [EOS_TOKEN]
idxs = [self.char_to_idx.get(char, UNK_IDX) for char in seq]
if self.max_length is not None:
if len(idxs) < self.max_length:
idxs = idxs + [PAD_IDX] * (self.max_length - len(idxs))
else:
idxs = idxs[:self.max_length]
return torch.tensor(idxs, dtype=torch.long)接下来, 我们需要创建诗词的数据集:
python
dataset = PoemDataset(poems, char_to_idx, idx_to_char, max_seq_length)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True)
len(dataloader)结果:
python
237我们这边采用批量加载。
接下来, 我们随便取一个示例来验证:
python
# 提取一个示例来检查验证
examples = enumerate(dataloader) # [(0,[特征,标签]),()]
batch_idx, (example_data, example_targets) = next(examples)
batch_idx, example_data.shape, example_targets.shape结果:
text
(0, torch.Size([256, 97]), torch.Size([256, 97]))由于我们DataLoader里面的参数batch_size为256, 每个诗词的长度都是97(前面有提到原因, 就是写prepare_sequence函数的那个地方)。
我们看一下第一个特征数据长啥样:
python
example_data[0]运行结果:
text
tensor([ 1, 2182, 1190, 79, 4, 1358, 14, 1060, 5, 101, 12, 1805,
4, 252, 13, 128, 5, 304, 52, 510, 4, 78, 275, 220,
5, 124, 159, 895, 4, 944, 330, 2042, 5, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0])我们设置设备, 就是让GPU去跑(没有GPU就用CPU):
python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device结果:
text
device(type='cuda')我们接下来需要开始构建RNN模型:
RNN模型
- 构建嵌入层:将离散的字符索引转为连续的向量表示,字符嵌入到多维数学空间去
- 可学习的,让模型来在训练中学习这些token之间的关系和潜在信息 参数 维度转换
- vocab_size: 词汇表大小 7487
- embedding_dim: 嵌入维度 256
- 构建RNN层:处理序列数据,捕获序列中的时间依赖关系
- input_size: 输入维度 256 embedding_dim
- hidden_size: 隐藏层维度 512
- num_layers: 层数 2
- batch_first: 是否将批次维度放在第一维 True
- 构建全连接层:将RNN的输出映射到词汇表大小,用于预测下一个字符
- in_features: 输入维度 512 hidden_size
- out_features: 输出维度 7487 vocab_size
定义超参数已经早停耐心值:
python
# 超参数
embedding_dim = 256
hidden_dim = 512
num_layers = 2
dropout = 0.3
learning_rate = 0.001
epochs = 300
# 早停耐心值
sample_every = 20开始建模:
python
from torch import nn
class PoemRNN(nn.Module):
def __init__(self,
vocab_size,
embedding_dim,
hidden_dim,
num_layers,
batch_first=True,
dropout=0.3) -> None:
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim,
hidden_dim,
num_layers,
batch_first=batch_first,
dropout=dropout)
self.fc = nn.Linear(hidden_dim, vocab_size)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
def forward(self, x, hidden):
embedded = self.embedding(x)
output, hidden = self.rnn(embedded, hidden)
output = self.fc(output)
return output, hidden
def init_hidden(self, batch_size):
return torch.zeros(self.num_layers, batch_size,
self.hidden_dim).to(device)实例化模型:
python
model = PoemRNN(vocab_size,
embedding_dim,
hidden_dim,
num_layers,
dropout=dropout).to(device)
model结果:
text
PoemRNN(
(embedding): Embedding(7487, 256)
(rnn): RNN(256, 512, num_layers=2, batch_first=True, dropout=0.3)
(fc): Linear(in_features=512, out_features=7487, bias=True)
)我们看看模型的参数状况:
python
for name, param in model.named_parameters():
if param.requires_grad:
print(f'{name}:{param.numel()}')运行结果:
text
embedding.weight:1916672
rnn.weight_ih_l0:131072
rnn.weight_hh_l0:262144
rnn.bias_ih_l0:512
rnn.bias_hh_l0:512
rnn.weight_ih_l1:262144
rnn.weight_hh_l1:262144
rnn.bias_ih_l1:512
rnn.bias_hh_l1:512
fc.weight:3833344
fc.bias:7487最后看一下模型的总参数:
python
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print('模型总参数:', total_params)运行结果:
text
模型总参数: 6677055我们分析一下参数:
我们逐层拆解模型参数的计算方法、含义与一个数值例子(使用 notebook 中的超参:vocab_size=7487, embedding_dim=256, hidden_dim=512, num_layers=2)。
embedding(nn.Embedding(vocab_size, embedding_dim))- 参数数:vocab_size * embedding_dim
- 作用:每个 token id 对应一个长度为
embedding_dim的向量(查表),用于把离散索引映射成连续向量。 - 例子:7487 * 256 = 1,916,672
rnn(nn.RNN(embedding_dim, hidden_dim, num_layers, ...))- PyTorch 的标准(单向)RNN 每层有四组参数:
weight_ih_l{k}(hidden×input),weight_hh_l{k}(hidden×hidden),bias_ih_l{k}(hidden),bias_hh_l{k}(hidden)。 - 第0层 input_size =
embedding_dim,第 l>0 层 input_size =hidden_dim。 - 每层参数总计 = hidden*(input + hidden) + 2hidden = hidden(input + hidden + 2)。
- 整体 RNN 参数 = 第一层(hidden*(embedding_dim+hidden_dim+2)) + (num_layers-1)hidden(hidden_dim+hidden_dim+2)。
- 例子(num_layers=2):
- 层0:512*(256 + 512 + 2) = 394,240
- 层1:512*(512 + 512 + 2) = 525,312
- RNN 总计 = 394,240 + 525,312 = 919,552
- PyTorch 的标准(单向)RNN 每层有四组参数:
fc(nn.Linear(hidden_dim, vocab_size))- 参数数:hidden_dim * vocab_size(权重) + vocab_size(偏置)
- 作用:把 RNN 在每个时间步的 hidden 输出映射为对 vocab 上每个字符的未归一化分数(logits),用于 softmax 预测下一个字符。
- 例子:512*7487 + 7487 = 3,840,831
- 总参数(示例)
- Embedding 1,916,672 + RNN 919,552 + FC 3,840,831 ≈ 6,677,055 参数(可训练参数总数)
- 额外说明(含在
model.named_parameters()中看到的名字)embedding.weight:查表矩阵(vocab×embed)rnn.weight_ih_l0,rnn.weight_hh_l0,rnn.bias_ih_l0,rnn.bias_hh_l0, ...:RNN 各层的权重/偏置fc.weight,fc.bias:线性层权重与偏置- 运行时形状:RNN 输出 (batch, seq_len, hidden_dim) →
fc产出 logits (batch, seq_len, vocab_size)。 init_hidden返回的隐藏状态形状为(num_layers, batch_size, hidden_dim)(不计入模型参数)。
我们的RNN模型构建的部分就到此结束了, 我们下一篇文章会将如何训练与测试模型, 以及让模型写出古诗来。
以上就是RNN模型构建的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步。学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大。人生路漫漫, 白鹭常相伴!!!