继完成 Langchain-Chatchat 的完整部署与各类部署坑点排查后,本次将聚焦项目落地核心环节 ------API 接口实操应用。Langchain-Chatchat 作为轻量化、高易用性的大模型应用框架,其封装的标准化 API 是实现模型能力对接业务系统、完成二次开发的关键。本文将系统化梳理框架各类核心 API 的调用方式、参数配置、请求规范及工具调用等实操要点,清晰拆解接口使用中的核心逻辑与常见问题,为开发者快速打通模型部署与业务应用链路提供实操指引,助力高效实现大模型能力的落地复用。

1 环境安装
环境安装这里就不赘述,两种方法Langchain-Chatchat安装可以看这里:
NLP 部署实操:Langchain-Chatchat 完整部署教程与踩坑记录
2 启动方式
执行命令 python chatchat/cli.py start --help 可查看完整的启动参数说明,对应截图如下:
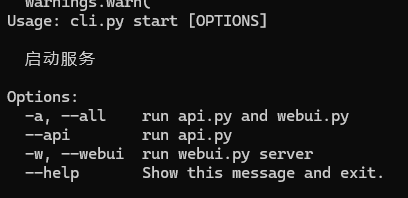
框架支持全服务启动、单独启动 WebUI、单独启动 API 服务三种方式,对应命令如下:
shell
# 启动webui和api
python chatchat/cli.py start -a
python chatchat/cli.py start --all
# 单独启动webui
python chatchat/cli.py start -w
python chatchat/cli.py start --webui
# 单独启动api服务
python chatchat/cli.py start --api3 API调用方式
Langchain-Chatchat 封装了多场景的标准化 API 接口,适配纯对话、工具调用、知识库检索、联网搜索等核心业务需求,以下为各类场景的完整调用示例。
3.1 纯 LLM 对话
适用于无需工具、知识库加持的基础问答场景,支持流式 / 非流式返回,同时兼容requests原生请求与openai-sdk两种调用方式,灵活适配不同开发习惯。
python
base_url = "http://127.0.0.1:7861/chat"
data = {
"model": "qwen1.5-chat",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": "请用100字左右的文字介绍自己"},
],
"stream": True,
"temperature": 0.7,
}
# 方式一:使用 requests
import requests
response = requests.post(f"{base_url}/chat/completions", json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
print(line, end="", flush=True)
# 方式二:使用 openai sdk
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
for r in resp:
print(r)3.2 Agent 对话
依托框架的 Agent 能力,可实现计算器、天气查询等工具联动,调用时需先获取平台所有可用工具列表,再随请求传入工具集,由大模型自主判断并调用对应工具,完成复杂任务求解。
python
base_url = "http://127.0.0.1:7861/chat"
tools = list(requests.get(f"http://127.0.0.1:7861/tools").json()["data"])
data = {
"model": "qwen1.5-chat",
"messages": [
{"role": "user", "content": "37+48=?"},
],
"stream": True,
"temperature": 0.7,
"tools": tools,
}
import requests
response = requests.post(f"{base_url}/chat/completions", json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
print(line)3.3 知识库对话(LLM 自动解析参数)
适配轻量化的知识库问答场景,指定工具为本地知识库检索后,框架将自动解析请求参数,无需手动配置检索阈值、召回数量,快速实现知识库内容问答。
python
base_url = "http://127.0.0.1:7861/chat"
data = {
"messages": [
{"role": "user", "content": "如何提问以获得高质量答案"},
],
"model": "qwen1.5-chat",
"tool_choice": "search_local_knowledgebase",
"stream": True,
}
import requests
response = requests.post(f"{base_url}/chat/completions", json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
print(line)3.4 知识库对话(手动传入参数)
适用于精细化的知识库检索场景,可手动配置召回条数、相似度阈值等核心参数,精准把控检索效果,满足高定制化的业务问答需求。
python
base_url = "http://127.0.0.1:7861/chat"
data = {
"messages": [
{"role": "user", "content": "如何提问以获得高质量答案"},
],
"model": "qwen1.5-chat",
"tool_choice": "search_local_knowledgebase",
"stream": True,
}
import requests
response = requests.post(f"{base_url}/chat/completions", json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
print(line)3.5 本地知识库问答
针对已创建的本地知识库,可通过专属接口实现定向问答,直接绑定指定知识库名称,实现数据隔离与专属检索,适配多知识库并行使用的业务场景。
python
base_url = "http://127.0.0.1:7861/knowledge_base/local_kb/samples"
data = {
"model": "qwen2-instruct",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": "如何高质量提问?"},
],
"stream": True,
"temperature": 0.7,
"extra_body": {
"top_k": 3,
"score_threshold": 2.0,
"return_direct": True,
},
}
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
for r in resp:
print(r)3.6 临时文件对话
支持上传文件生成临时知识库并完成问答,需传入文件上传接口返回的knowledge_id,实现无本地知识库创建的轻量化文档问答,适配临时文件解析、单次文档咨询场景。
python
# knowledge_id 为 /knowledge_base/upload_temp_docs 的返回值
base_url = "http://127.0.0.1:7861/knowledge_base/temp_kb/{knowledge_id}"
data = {
"model": "qwen2-instruct",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": "如何高质量提问?"},
],
"stream": True,
"temperature": 0.7,
"extra_body": {
"top_k": 3,
"score_threshold": 2.0,
"return_direct": True,
},
}
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
for r in resp:
print(r)3.7 搜索引擎问答
对接主流搜索引擎实现联网检索,支持必应、DuckDuckGo 等引擎切换,突破大模型知识库时效性限制,适配实时资讯查询、热点问题解答等场景。
python
engine_name = "bing" # 可选值:bing, duckduckgo, metaphor, searx
base_url = f"http://127.0.0.1:7861/knowledge_base/search_engine/{engine_name}"
data = {
"model": "qwen2-instruct",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": "如何高质量提问?"},
],
"stream": True,
"temperature": 0.7,
"extra_body": {
"top_k": 3,
"score_threshold": 2.0,
"return_direct": True,
},
}
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
for r in resp:
print(r)4 注册自己的工具
4.1 服务端定义
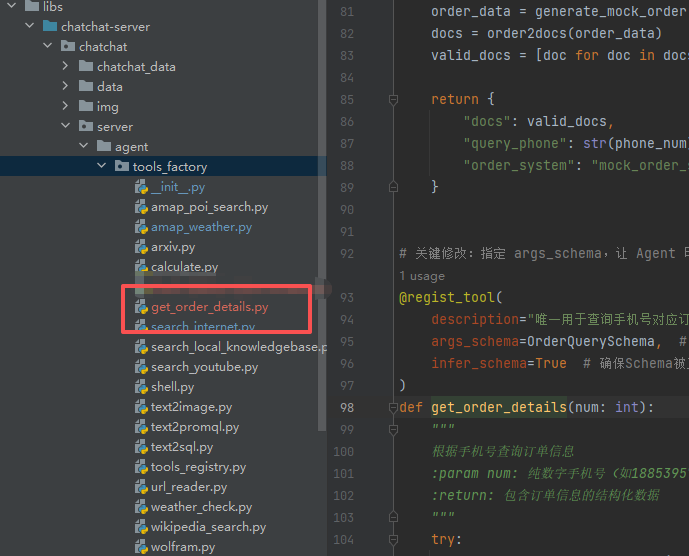
找到Langchain-Chatchat\libs\chatchat-server\chatchat\server\agent\tools_factory目录底下,定义自己的函数,如下图所示:
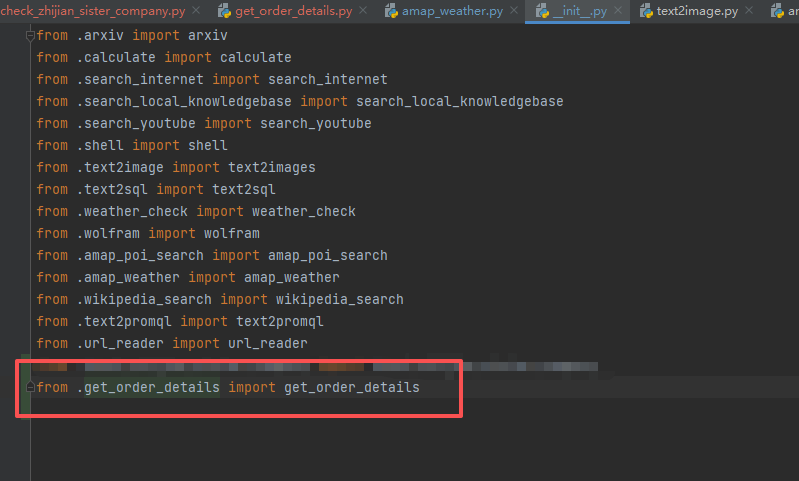
4.2 注册工具
需要在Langchain-Chatchat\libs\chatchat-server\chatchat\server\agent\tools_factory\__init__.py文件中注册你刚才定义的函数:
4.2 测试
使用3.2 的方法调用代码可以看到函数已经注册进去:

5 常见报错与解决方案
File "F:\PyPro\Langchain-Chatchat\libs\chatchat-server\chatchat\server\utils.py", line 432, in get_OpenAIClient assert platform_info, f"cannot find configured platform: {platform_name}" AssertionError: cannot find configured platform: None
解决办法:将model改成你下载后的模型:
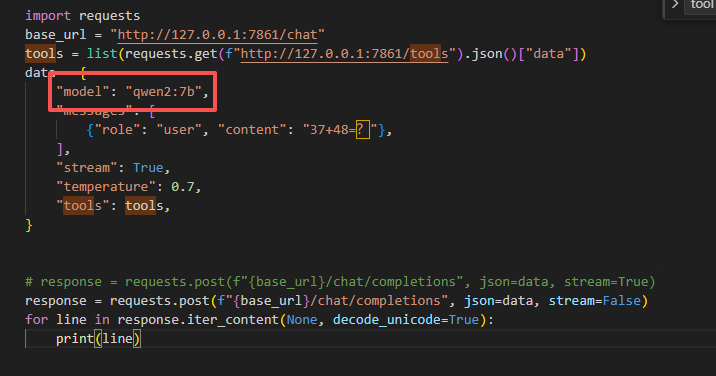
解决办法:请求参数中填写的model名称,必须与本地已下载、已配置的模型名称完全一致,截图示例如下:
总结
本文围绕 Langchain-Chatchat 的 API 接口使用展开实操讲解,从服务启动、多场景调用到报错排查,完整覆盖了框架 API 应用的核心流程。该框架的 API 设计兼容 OpenAI 规范,同时提供了原生请求与 SDK 调用两种方式,适配不同开发场景;其丰富的接口能力可满足纯对话、工具调用、知识库问答、联网检索等业务需求,极大降低了大模型落地的开发成本。开发者只需根据业务场景选择对应接口,搭配正确的参数配置,即可快速实现大模型能力的业务集成,高效完成项目落地。