作者:昇腾实战派
0 背景介绍
智谱GLM4.5、GLM4.6模型推理性能优化,本文提供量化权重导出方法,使用工具是msmodelslim。
1 环境准备
1.1 获取浮点权重
模型权重链接:
https://modelscope.cn/models/ZhipuAI/GLM-4.5
https://modelscope.cn/models/ZhipuAI/GLM-4.6
1.2 版本配套
1.2.1 硬件版本
| 组件 | 版本 |
|---|---|
| 硬件环境 | 910B(8卡) |
1.2.2 软件版本
| 组件 | 版本 |
|---|---|
| HDK | Ascend HDK 25.0.rc1.1 |
| CANN | 8.2.RC1 |
| msmodelslim | 803a9b266 |
| 模型 | GLM4.5/GLM4.6 |
1.2.3 镜像准备
采用8.2.RC1的CANN,镜像可下载quay.io中的v0.10.2rc1的A2版本,下载后确认CANN版本。
bash
docker run -it -d --net=host --shm-size=1g \
--privileged \
--name glm4_5_360b_w8a8 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /home:/home \
9bthinking:latest \ #换成对应镜像名
bash1.3 安装Python第三方库
bash
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py1.4 升级transformers
bash
pip install transformers==4.54.01.5 安装msmodelslim
bash
git clone https://gitee.com/ascend/msit.git
git checkout 803a9b266
# 进入到msit/msmodelslim的目录,运行安装脚本
cd msit/msmodelslim
bash install.sh2 适配modelslim
由于当前量化方案工具需要额外适配,参照Qwen3的方法进行修改,一共涉及两个__init__.py文件,一个glm4moe.py文件。
修改 msit/msmodelslim/msmodelslim/pytorch/llm_ptq/model/
在其目录下 新建一个 glm4moe
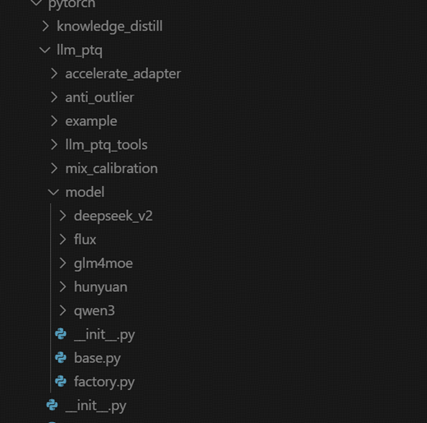
在glm4moe文件夹中 新建 init.py 、glm4moe.py,内容仿照 qwen3中的代码写入以下内容
2.1 新建__init__.py
python
# -*- coding: utf-8 -*-
# Copyright (c) 2025-2025 Huawei Technologies Co., Ltd.
# #
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# #
# http://www.apache.org/licenses/LICENSE-2.0
# #
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
__all__ = ['Glm4moeAdapter']
from .glm4moe import Glm4moeAdapter2.2 新建glm4moe.py
python
# Copyright Huawei Technologies Co., Ltd. 2025-2025. All rights reserved.
from typing import List, Any, Dict, Optional, Type, TYPE_CHECKING
import torch
import torch.nn as nn
from transformers import PreTrainedModel
from msmodelslim.pytorch.llm_ptq.model.base import ModelAdapter, ModelAdapterRegistry
if TYPE_CHECKING:
from msmodelslim.pytorch.llm_ptq.anti_outlier.config import AntiOutlierConfig
@ModelAdapterRegistry.register("glm4_moe")
@ModelAdapterRegistry.register("glm4moe")
class Glm4moeAdapter(ModelAdapter):
def __init__(self, model: PreTrainedModel):
super().__init__(model)
self.is_moe = "moe" in self.model.config.model_type
self.num_attention_heads, self.num_key_value_heads = self._init_num_attention_heads()
def get_norm_linear_subgraph(self,
cfg: 'AntiOutlierConfig',
dummy_input: Optional[torch.Tensor] = None,
norm_class: Optional[List[Type[nn.Module]]] = None):
"""获取Norm->Linear子图"""
norm_linear = {}
layer_num = self.model.config.num_hidden_layers
# 校验layer_num是否过大或过小
if layer_num < 1 or layer_num > 999:
raise ValueError(f"The number of hidden layers({layer_num}) is invalid. It must be between 1 and 999.")
for layer in range(layer_num):
input_layernorm = 'model.layers.' + str(layer) + '.input_layernorm'
q_proj = 'model.layers.' + str(layer) + '.self_attn.q_proj'
k_proj = 'model.layers.' + str(layer) + '.self_attn.k_proj'
v_proj = 'model.layers.' + str(layer) + '.self_attn.v_proj'
o_proj = 'model.layers.' + str(layer) + '.self_attn.o_proj'
norm_linear[v_proj] = [o_proj]
norm_linear[input_layernorm] = [q_proj, k_proj, v_proj]
if not self.is_moe:
post_layernorm = 'model.layers.' + str(layer) + '.post_attention_layernorm'
gate_proj = 'model.layers.' + str(layer) + '.mlp.gate_proj'
up_proj = 'model.layers.' + str(layer) + '.mlp.up_proj'
down_proj = 'model.layers.' + str(layer) + '.mlp.down_proj'
norm_linear[up_proj] = [down_proj]
norm_linear[post_layernorm] = [gate_proj, up_proj]
return norm_linear
def modify_smooth_args(self,
cfg: 'AntiOutlierConfig',
norm_name: str,
linear_names: str,
args: List[Any],
kwargs: Dict[str, Any]):
# 针对该模型进行m4量化时,需要对特定层开启偏移
if cfg.anti_method == 'm4':
is_shift = False
if 'norm' in norm_name:
is_shift = True
kwargs['is_shift'] = is_shift
kwargs['alpha'] = cfg.alpha
# 针对qwen3模型,需要对num_attention_heads和num_key_value_heads进行修改
if cfg.anti_method == 'm4' and 'num_attention_heads' in kwargs:
kwargs['num_attention_heads'] = [self.num_attention_heads, self.num_key_value_heads]
return args, kwargs
def _init_num_attention_heads(self):
num_attention_heads = None
num_key_value_heads = None
attention_heads_keys = ["num_attention_heads", "n_head", "num_heads"]
key_value_heads_keys = ["num_key_value_heads"]
for key in attention_heads_keys:
if hasattr(self.model.config, key):
num_attention_heads = getattr(self.model.config, key)
for key in key_value_heads_keys:
if hasattr(self.model.config, key):
num_key_value_heads = getattr(self.model.config, key)
if not num_attention_heads:
raise ValueError(
f"the config of model must have num_attention_heads, n_head or num_heads, \
please check or modify the config file"
)
return num_attention_heads, num_key_value_heads2.3 修改__init__.py
修改msit/msmodelslim/msmodelslim/pytorch/llm_ptq/model/init.py
python
__all__ = ['ModelAdapter', 'ModelAdapterRegistry']
from .base import ModelAdapter, ModelAdapterRegistry
from .deepseek_v2 import DeepseekV2Adapter
from .hunyuan import HunyuanLargeAdapter, HunyuanVideoAdapter
from .qwen3 import Qwen3Adapter
from .flux import FluxAdapter
from .glm4moe import Glm4moeAdapter2.4 重装msmodelslim
进入到msit/msmodelslim的目录,运行安装脚本
bash
cd msit/msmodelslim
bash install.sh3 量化
3.1 量化方案
- MOE层使用动态量化,其他层使用静态量化。
- 精度考虑,回退down_proj层和o_proj层

3.2 新建glm4_moe_w8a8.py
在msit/msmodelslim/example/Qwen3-MOE中新建glm4_moe_w8a8.py文件,内容如下:
python
# Copyright (c) Huawei Technologies Co., Ltd. 2025-2025. All rights reserved.
import os
import sys
import argparse
import functools
import json
from unittest.mock import patch
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
current_directory = os.path.dirname(os.path.abspath(__file__))
parent_directory = os.path.abspath(os.path.join(current_directory, '..', ".."))
sys.path.append(parent_directory)
from example.common.security.path import get_valid_read_path, get_write_directory
from example.common.security.type import check_number
from example.common.utils import SafeGenerator, cmd_bool
from msmodelslim.tools.copy_config_files import copy_config_files, modify_config_json
from msmodelslim.pytorch.llm_ptq.anti_outlier import AntiOutlierConfig, AntiOutlier
from msmodelslim.pytorch.llm_ptq.llm_ptq_tools import Calibrator, QuantConfig
from msmodelslim.tools.logger import set_logger_level
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', type=str, help="The path of float model and tokenizer"),
parser.add_argument('--save_path', type=str, help="The path to save quant model"),
parser.add_argument('--layer_count', type=int, default=0, help="Layer count when loading model")
parser.add_argument('--anti_dataset', type=str, default="./anti_prompt_50.json",
help="The calib data for anti outlier")
parser.add_argument('--calib_dataset', type=str, default="./calib_prompt_50.json",
help="The calib data for calibration")
parser.add_argument('--batch_size', type=int, default=4, help="Batch size for anti and calibration")
parser.add_argument('--mindie_format', action="store_true", help="Enable only mindie config save")
parser.add_argument('--trust_remote_code', type=cmd_bool, default=False)
return parser.parse_args()
def custom_hook(model_config):
model_config["quantize"] = "w8a8_dynamic"
def get_calib_dataset_batch(model_tokenizer, calib_list, batch_size, device="npu"):
calib_dataset = []
calib_list = [calib_list[i:i + batch_size] for i in range(0, len(calib_list), batch_size)]
for calib_data in calib_list:
inputs = model_tokenizer(calib_data, return_tensors='pt', padding=True).to(device)
calib_dataset.append(
[value.to(device) for key, value in inputs.data.items() if isinstance(value, torch.Tensor)])
return calib_dataset
def main():
args = parse_args()
set_logger_level("info")
model_path = args.model_path
batch_size = args.batch_size
save_path = get_write_directory(args.save_path, write_mode=0o750)
check_number(batch_size, int, 1, 16, "batch_size")
safe_generator = SafeGenerator()
config = safe_generator.get_config_from_pretrained(model_path=model_path,
trust_remote_code=args.trust_remote_code)
num_layer = config.num_hidden_layers
if args.layer_count < 0 or args.layer_count > num_layer:
raise ValueError(
f"Invalid value for parameter layer_count: {args.layer_count}."
f"Must be between 0 and {num_layer}."
)
# Set layer count to 0 means use all layers, otherwise it will only use the first layer_count layers
config.num_hidden_layers = args.layer_count if args.layer_count != 0 else config.num_hidden_layers
# Disable use cache because we don't need to use cache, otherwise it will use too much device memory then cause OOM
config.use_cache = False
tokenizer = safe_generator.get_tokenizer_from_pretrained(model_path=model_path,
config=config,
trust_remote_code=args.trust_remote_code,
use_fast=True,
add_eos_token=True)
model = safe_generator.get_model_from_pretrained(model_path=model_path,
config=config,
trust_remote_code=args.trust_remote_code,
device_map={
"model.embed_tokens": 0,
"model.layers": "cpu",
"model.norm": "cpu",
"lm_head": 0,
},
torch_dtype="auto",
attn_implementation='eager')
#keys_46 = [k for k in model.state_dict() if k.startswith('model.layers.46.')]
#print(keys_46)
anti_dataset_path = get_valid_read_path(args.anti_dataset, "json", is_dir=False)
calib_dataset_path = get_valid_read_path(args.calib_dataset, "json", is_dir=False)
with open(anti_dataset_path, "r") as file:
anti_prompt = json.load(file)
with open(calib_dataset_path, "r") as file:
calib_prompt = json.load(file)
anti_dataset = get_calib_dataset_batch(tokenizer, anti_prompt, batch_size, model.device)
dataset_calib = get_calib_dataset_batch(tokenizer, calib_prompt, batch_size, model.device)
with torch.no_grad():
anti_config = AntiOutlierConfig(w_bit=8,
a_bit=8,
anti_method='m4',
dev_type='npu',
dev_id=model.device.index)
anti_outlier = AntiOutlier(model, calib_data=anti_dataset, cfg=anti_config)
anti_outlier.process()
disable_names = []
for ids in range(config.num_hidden_layers):
if ids in [0,1,2]:
disable_names.append(f"model.layers.{ids}.mlp.down_proj")
disable_names.append(f"model.layers.{ids}.self_attn.o_proj")
quant_config = QuantConfig(
a_bit=8,
w_bit=8,
disable_names=disable_names,
dev_type='npu',
dev_id=model.device.index,
act_method=1,
pr=1.0,
w_sym=True,
mm_tensor=False,
)
calibrator = Calibrator(model,
quant_config,
calib_data=dataset_calib,
disable_level="L0",
mix_cfg={"*.mlp.*": "w8a8_dynamic", "*": "w8a8"})
calibrator.run()
if args.mindie_format:
quant_model_description_json_name = "quant_model_description_w8a8_dynamic.json"
else:
quant_model_description_json_name = "quant_model_description.json"
save_type = "safe_tensor" if args.mindie_format else "ascendV1"
calibrator.save(save_path,
json_name=quant_model_description_json_name,
safetensors_name="quant_model_weight_w8a8_dynamic.safetensors",
save_type=[save_type],
part_file_size=4)
custom_hooks = {
'config.json': functools.partial(modify_config_json, custom_hook=custom_hook)
}
copy_config_files(input_path=model_path, output_path=save_path, quant_config=quant_config,
mindie_format=args.mindie_format, custom_hooks=custom_hooks)
if __name__ == "__main__":
# torch_npu will fork a new process to init,
# it's lazy_init will fail after we load a big model,so we need to init it here
torch_npu.npu.init()
# Invoke main process
main()3.3 修改transformers代码
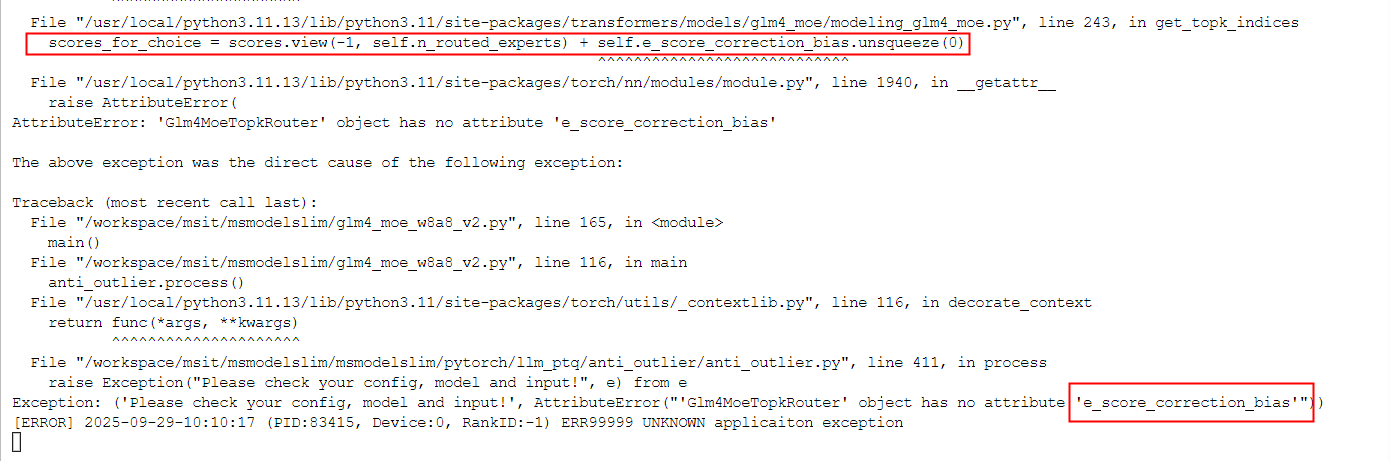
上述量化后报错,需修改transformers中代码,解决量化时缺少score参数权重的问题
pip show transformers
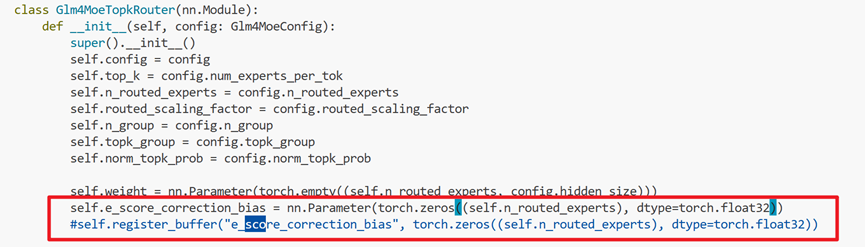
文件路径:transformers/models/glm4_moe/modeling_glm4_moe.py
修改Glm4MoeTopkRouter类中代码self.e_score_correction_bias = nn.Parameter(torch.zeros((self.n_routed_experts), dtype=torch.float32))
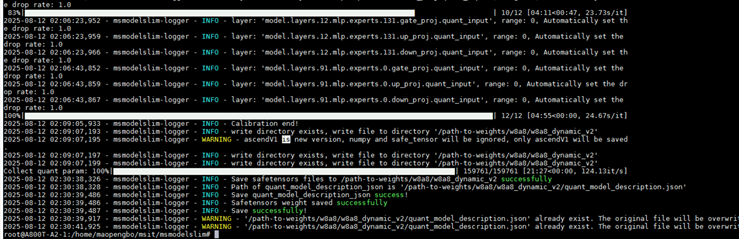
3.4 执行脚本转量化权重
bash
python glm4_moe_w8a8.py --model_path "/home/weight" --save_path /home/glm4.5_w8a8_dynamic_v2/ --trust_remote_code True权重量化完成
3.5 权重量化后处理
3.5.1合并config.json
quant_model_description.json中的quantization_config合并到config.json中
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import json
import sys
import argparse
# 直接指定路径
INPUT_DIR = "/GLM360B/glm4.5_w8a8_dynamic_v2" # 修改为你的模型目录
OUTPUT_FILE = "/GLM360B/glm4.5_w8a8_dynamic_v2/config.json" # 修改为你想要的输出文件路径
def merge_configs():
"""
合并配置文件:
1. 从quant_model_description.json读取内容
2. 将内容合并到config.json的quantization_config部分
3. 保存文件config.json
"""
# 构建文件路径
config_path = os.path.join(INPUT_DIR, "config.json")
quant_desc_path = os.path.join(INPUT_DIR, "quant_model_description_w8a8.json")
# 检查文件存在
if not os.path.exists(config_path):
print(f"错误: 配置文件不存在: {config_path}")
return False
if not os.path.exists(quant_desc_path):
print(f"错误: 量化描述文件不存在: {quant_desc_path}")
return False
try:
# 读取config.json
with open(config_path, 'r', encoding='utf-8') as f:
config_data = json.load(f)
# 读取quant_model_description_w8a8.json
with open(quant_desc_path, 'r', encoding='utf-8') as f:
quant_desc_data = json.load(f)
# 确保config.json有quantization_config字段
if "quantization_config" not in config_data:
config_data["quantization_config"] = {}
# 合并配置
config_data["quantization_config"].update(quant_desc_data)
# 确保有必要的字段
if "moe_quantize" not in config_data:
config_data["moe_quantize"] = "w8a8_dynamic"
# 保存新配置文件
with open(OUTPUT_FILE, 'w', encoding='utf-8') as f:
json.dump(config_data, f, indent=4)
print(f"成功: 配置已合并并保存到 {OUTPUT_FILE}")
return True
except Exception as e:
print(f"错误: 处理配置文件时发生异常: {str(e)}")
return False
def main():
# 执行合并
success = merge_configs()
if not success:
sys.exit(1)
if __name__ == "__main__":
main()执行脚本python configmerge.py
3.5.2 拷贝template文件
将原始文件中的template文件拷贝到量化权重中:
pyton
cp chat_template.jinja /GLM360B/glm4.5_w8a8_dynamic_v2/4 MTP权重拷贝(可选)
在msit/msmodelslim/example/DeepSeek/文件夹下参考add_safetensors.py将mtp权重拷贝至量化权重目录,完成后还需将config.json修改为新的quantization_config(包含mtp),例如:
python
from add_safetensors import add_safetensors
add_safetensors(org_paths="/home/z00694760/GLM-4.5", target_dir="/home/z00694760/glm4.5_w8a8_with_float_mtp", safetensors_prefix="mtp_float",
max_file_size_gb=5, prefix="model.layers.92.")