摘要
尽管通用检测器取得了成功,小目标检测仍然具有挑战性。通用检测器在小目标上性能急剧下降,主要是由于极其有限的像素导致的弱表征。为了解决这个问题,我们提出了一种即插即用的架构来增强这些微弱的区域。我们首次从像素级信息量的角度来利用待增强的区域。具体来说,我们通过最小化信息熵损失来对整个图像像素的特征信息进行建模,生成一个信息图,以无监督的方式有侧重地突出弱激活区域。为了更有效地辅助上述阶段,使其更关注小目标,我们接下来引入了位置高斯分布图,它使用高斯混合分布进行显式建模,其中每个高斯分量的参数取决于目标实例标签的位置和大小,并作为进一步特征增强的监督信号。以信息图为先验知识指导,我们构建了一个多尺度位置高斯分布图预测模块,在训练过程中同时调制信息图和分布图,使其聚焦于小目标。在三个公共小目标数据集上进行的大量实验证明了我们的方法优于当前最先进的竞争对手。
1. 引言
基于深度学习的架构极大地推动了通用目标检测的发展 27, 32, 34。然而,在检测小目标时,它们的性能急剧下降 8。根据AI-TOD基准的定义 44,小目标按像素数量分类:超小(2-8像素)、微小(8-16像素)和小型(16-32像素)。考虑到小目标在现实世界场景中的普遍性(例如,交通监控 24、海上救援 56 和野生动物种群评估 19),缩小小目标检测与通用目标检测之间的差距至关重要。
已经有一些开创性的努力来解决这一挑战。一种突出的方法是尺度感知特征融合 ,它构建层次化的特征表征 12, 22, 25, 26, 31, 38, 49。这种方法利用网络在不同深度的特征来检测相应尺度的目标,并且深层和浅层特征之间的融合弥补了较低和较高金字塔层级之间的空间-语义鸿沟,从而增强了小目标检测。另一种方法强调使用注意力机制突出目标区域 23, 29, 50, 52, 55。受人类视觉系统启发 3, 9,基于注意力的方法通过建模特征图的重要性权重来过滤无关信息并突出小目标。

尽管现有方法部分缓解了这个问题,但当小目标像素数量极其有限时,它们仍然无效。我们认为,先前的方法忽视了一个根本性挑战:极度有限像素下的小目标表征较弱。与正常大小的目标不同,具有有限像素的小目标表征在连续的神经网络下采样过程中持续减弱,最终导致特征激活被抑制。下采样造成的信息丢失对小目标来说是极其致命的,这导致了极其微弱且难以区分的表征。如图1(b)所示,通用检测器中小目标的表征微弱,几乎与背景无法区分。因此,即使通过尺度感知特征融合丰富了小目标特征,其内在的弱表征仍然难以进行精确检测。此外,依赖于启发式注意力图生成的基于注意力的方法,常常因为小目标的稀疏像素而失效,使得背景在局部块中占据主导。因此,从这种弱区域派生的注意力图变得不可靠,导致次优的检测结果。
基于上述讨论,我们认为增强那些因信息丢失而难以区分的区域对于检测小目标至关重要 。为了实现这一点,我们提出了一种新颖的即插即用框架用于特征增强。受信息论启发 37,我们首先通过最小化信息熵损失(这是所有像素编码代价的反映)无监督地估计整个图像的像素级信息量。生成的信息图突出了显著区域,其中显著目标比平滑的背景拥有更多的信息量,显示了待增强的关注区域。为了使信息图更关注小目标,我们引入了位置高斯分布图,它通过高斯混合分布建模,其中每个高斯分量的参数根据实例标签的位置和大小进行调整。该分布图能够捕捉显著目标,其中小目标的像素强度高于一般目标,从而增加对小目标增强的关注度。我们将信息图先验与多尺度特征结合,以有监督的方式预测分布图,同时在训练过程中调制信息图和分布图以聚焦于小目标。如图1所示,我们的信息图和预测的分布图成功地识别并增强了关键的信息丢失区域,使得小目标表征变得显著。在三个数据集上的大量实验验证了我们方法的优越性。我们的主要贡献如下:
- 我们首次从像素级信息量的角度来增强小目标的弱表征。通过以无监督方式最小化信息熵损失来捕获有侧重点的信息图。
- 以信息图作为先验指导,我们利用多尺度特征来预测位置高斯分布图,进一步突出小目标。
- 所提出的方法可以灵活地集成到任何类似FPN的检测器中。实验结果证明了我们即插即用模块的持续增益及其相对于现有最先进方法的优越性。
2. 相关工作
2.1. 通用目标检测
基于锚框的检测器。基于锚框的检测器预定义了覆盖不同尺度和长宽比的锚框,并通过标签分配策略训练网络来调整和细化锚框。具体来说,它们可以细分为单阶段方法(如YOLOV3 33, SSD 27, RetinaNet 35)和两阶段方法(如Faster R-CNN34, Cascade R-CNN5, Cascade RPN42)。
无锚框检测器。无锚框检测器直接使用中心点或关键点来预测目标位置,这有效缓解了预定义锚框的超参数敏感性问题。FCOS40 和 FoveaBox18 以中心点方式预测边界框。另一种范式是通过关键点定位目标。代表性工作是CornerNet 20, Grid R-CNN 28, ExtremeNet 57 和RepPoints 51。
2.2. 小目标检测
面向样本的策略。Kisantal等人 17 对小目标图像进行过采样,并通过复制粘贴小目标来增强它们。NWD-RKA 47 用归一化Wasserstein距离和基于排名的分配策略替换了标准标签分配策略IoU。RFLA 48 测量高斯感受野与真实边界框之间的相似性,以缓解小目标正样本不足的问题。
尺度感知方法。FPN 25 构建了特征级金字塔用于多尺度学习,促进了小目标检测的显著改进。BiFPN 38 采用加权的双向特征金字塔架构来促进多尺度融合。DetectoRS 31 通过引入额外的反馈连接和可切换的空洞卷积进一步发展了它。Gong等人 12 引入了融合因子来控制FPN中两个相邻层之间的信息流,减轻了小目标的学习负担。
基于注意力的框架。注意力机制被用来过滤不重要区域并增加对小目标的关注。KB-RANN 52 利用注意力机制以迭代方式细化关键特征。SCRDet 50 引入了通道注意力和像素注意力网络来联合探索小目标。AFF-SSD 29 设计了一个双路径注意力模块来筛选特征信息,提高了一阶段方法的检测性能。
模仿学习算法。模仿学习的核心是利用大实例的高质量特征来提升小目标的低质量表征。Perceptual GAN 21 和 MT-GAN 1 从生成对抗网络 13 中汲取灵感,为小目标生成超分辨率表征。另一类努力 16, 46, 53 旨在借助相似性度量来缩小大实例和小实例在特征空间中的距离。
先前的方法常常忽视因信息丢失导致的弱表征所带来的性能限制。最近的工作SR-TOD 6 使用原始图像减去复原图像创建的差异图来识别受信息丢失影响的区域。
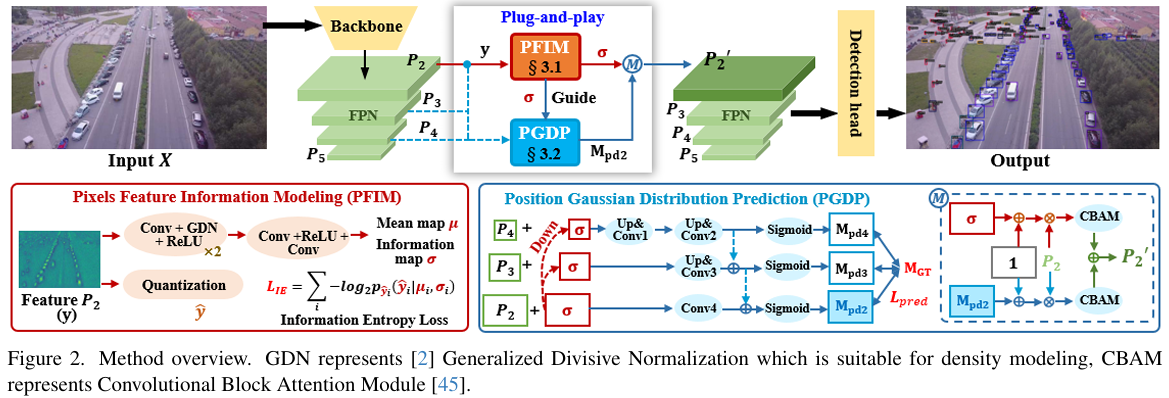
图 2. 方法概述。GDN代表2中的广义可分归一化,适用于密度建模。CBAM代表卷积块注意力模块45。
然而,它严重依赖于复原图像的质量,并且其下采样过程进一步减少了差异图的信息。相比之下,在信息熵理论和分布图建模的支持下,我们的方法直接在特征图层面识别信息丢失区域,展示了更优越的性能。
3. 方法
概述 。如图 图 2\mathbf{图\,2}图2 所示,给定输入 XXX,从 P2P_{2}P2 到 P5P_{5}P5 构建特征金字塔。增强应用于主要处理小目标的 P2P_{2}P2。首先,对 P2P_{2}P2 进行量化以估计其信息图 σ\sigmaσ,显著目标拥有更多信息量。然后,在 σ\sigmaσ 的先验知识指导下,使用 P2P_{2}P2 到 P4P_{4}P4 来预测位置高斯分布图 Mpd2M_{p d_{2}}Mpd2,同时辅助 σ\sigmaσ 使其更关注小目标。在 σ\sigmaσ 和 Mpd2M_{p d_{2}}Mpd2 增强了 P2P_{2}P2 的信息丢失区域之后,它们将分别流经注意力模块,最后合并得到 P2′P_{2}^{'}P2′。作为 P2P_{2}P2 的替代,P2′P_{2}^{'}P2′ 将被送入检测头执行检测任务。
3.1. 像素特征信息建模
神经网络中的下采样过程导致目标信息随着网络深度增加而丢失,这对于像素占用量有限的小目标尤为有害。因此,增强信息丢失区域对于改进小目标检测至关重要。为此,我们从信息量的新角度强调需要增强的显著区域。具体来说,对于概率为 p(x)p(x)p(x) 的信号,信息量定义如下 41:
I(x)=−log2p(x)I(x)=-\log_{2}p(x)I(x)=−log2p(x)
假设信号特征表征高度有序且紧凑,特征内显著且信息丰富的片段通常具有较低的出现概率。根据香农熵理论 37, 39,信号特征的信息量与其分布密切相关。对于离散化元素流 y^\hat{y}y^,实际边缘分布 m(y^)m(\hat{y})m(y^) 与其近似 py^(y^)p_{\hat{y}}(\hat{y})py^(y^) 之间的交叉熵反映了编码 y^\hat{y}y^ 的码率成本下界(在通信系统中通常以比特为单位测量):
R=Ey^∼m−log2py\^(y\^)=H(m)+DKL(m∣∣py^)R=\mathbb{E}{\hat{\boldsymbol{y}}\sim m}-\\log_{2}p_{\\hat{\\boldsymbol{y}}}(\\hat{\\boldsymbol{y}})=H(m)+D{K L}(m||p_{\hat{\boldsymbol{y}}})R=Ey^∼m−log2py\^(y\^)=H(m)+DKL(m∣∣py^)
其中 H(⋅)H(\cdot)H(⋅) 表示熵函数,DKL(⋅)D_{K L}(\cdot)DKL(⋅) 表示KL散度函数。当建模 py^(y^)p_{\hat{y}}(\hat{y})py^(y^) 与边缘分布 m(y)m(y)m(y) 完美匹配时,编码成本 RRR 最小化,因为平均信息量降至最低。在通信系统中,为了实现对存储和传输的最小编码成本,会将更多的编码资源分配给具有更多信息量的显著且信息丰富的片段,而具有较高出现概率的片段由于其信息量较少而编码成本较低。
给定输入图像 X ∈ RH×W×3\boldsymbol{X}\,\in\,\mathbb{R}^{H\times W\times3}X∈RH×W×3 以及来自FPN的底层特征 P2^∈RH4×W4×C\hat{P_{2}}\in\mathbb{R}^{\frac{H}{4}\times\frac{W}{4}\times C}P2^∈R4H×4W×C(记为 yyy),其中包含更多信息量的像素通常对应于显著区域,因为显著区域的出现概率通常低于平滑背景。因此,我们利用像素信息量来识别和增强这些显著区域以进行后续检测。通过基于良好估计的分布最小化整体编码成本,网络自适应地将更多成本分配给显著区域,而平滑背景区域成本较低。这种整体编码成本优化过程有效地挖掘了空间结构并减少了空间冗余。
我们首先估计 yyy 的分布。为了用有限数量的编码比特对特征 yyy 进行编码,使用量化 QQQ 将连续特征变量离散化,得到离散特征图 y^\hat{y}y^。这种量化在一定程度上减少了像素级冗余。为了使量化函数可微,在训练过程中应用了加性均匀噪声 U(−12,12)\mathcal{U}(-\textstyle\frac{1}{2},\frac{1}{2})U(−21,21) 2:
y^=Q(y)=y+U(−12,12)\hat{y}=Q(y)=y+\mathcal{U}(-\frac{1}{2},\frac{1}{2})y^=Q(y)=y+U(−21,21)
y^\hat{y}y^ 的分布通过一个完全分解的密度模型来估计,其中每个像素元素 y^i\hat{y}{i}y^i 被独立建模为一个具有均值 μi\mu{i}μi 和标准差 σi\sigma_{i}σi 的高斯分布:
py^(y^∣μ,σ)=∏i(N(μi,σi2)∗U(−12,12))(y^i)p_{\hat{y}}(\hat{y}|\mu,\sigma)=\prod_{i}(\mathcal{N}(\mu_{i},\sigma_{i}^{2})*\mathcal{U}(-\frac{1}{2},\frac{1}{2}))(\hat{y}_{i})py^(y^∣μ,σ)=i∏(N(μi,σi2)∗U(−21,21))(y^i)
其中均值图 μ ∈ RH4×W4×C\mu\,\in\,\mathbb{R}^{\frac{H}{4}\times\frac{W}{4}\times C}μ∈R4H×4W×C 和尺度图 σ ∈\sigma\,\inσ∈ RH4×W4×C\mathbb{R}^{\frac{H}{4}\times\frac{W}{4}\times C}R4H×4W×C 是使用CNN参数估计模块从底层特征图预测得到的,如图2所示。由于CNN在预测高斯分布时具有局部感受野能力,我们的像素级建模配备了局部结构信息。我们将高斯密度与单位均匀分布进行卷积,这已被证明在将估计分布与未知的实际边缘分布匹配方面是有效的 30。
确定编码分布后,每个元素 y^i\hat{y}_{i}y^i 的似然可以通过概率密度函数下的分箱面积获得:
py^i(y^i∣μi,σi)=(N(μi,σi2)∗U(−12,12))(y^i)=∫y^i−12y^i+12N(y∣μi,σi2) dy=F(y^i+12−μiσi)−F(y^i−12−μiσi)\begin{aligned}{p_{\hat{y}{i}}(\hat{y}{i}|\mu_{i},\sigma_{i})}&{{}=(\mathcal{N}(\mu_{i},\sigma_{i}^{2})*\mathcal{U}(-\frac{1}{2},\frac{1}{2}))(\hat{y}{i})}\\ {}&{{}=\int{\hat{y}{i}-\frac{1}{2}}^{\hat{y}{i}+\frac{1}{2}}\mathcal{N}(y|\mu_{i},\sigma_{i}^{2})\,d y}\\ {}&{{}=F(\frac{\hat{y}{i}+\frac{1}{2}-\mu{i}}{\sigma_{i}})-F(\frac{\hat{y}{i}-\frac{1}{2}-\mu{i}}{\sigma_{i}})}\end{aligned}py^i(y^i∣μi,σi)=(N(μi,σi2)∗U(−21,21))(y^i)=∫y^i−21y^i+21N(y∣μi,σi2)dy=F(σiy^i+21−μi)−F(σiy^i−21−μi)
其中 FFF 表示标准正态高斯分布的累积分布函数。
最后,元素 y^i\hat{y}_{i}y^i 的编码成本通过负对数似然计算:
Ry^i=−log2py^i(y^i∣μi,σi)R_{\hat{y}{i}}=-\log{2}p_{\hat{y}{i}}(\hat{y}{i}|\mu_{i},\sigma_{i})Ry^i=−log2py^i(y^i∣μi,σi)
信息熵损失 LIE\mathcal{L}_{I E}LIE 定义为所有元素编码成本之和,它是特征信息平均量的反映:
LIE=∑iRy^i\mathcal{L}{I E}=\sum{i}R_{\hat{y}_{i}}LIE=i∑Ry^i
我们最小化信息熵损失 LIE\mathcal{L}{I E}LIE 来自适应地捕获具有更多信息量的区域,例如小目标。如图3(a)所示,预测的均值图 μ\muμ 通常接近 y^\hat{y}y^,以最小化信息熵损失。对于平滑背景,输出的似然高于显著目标区域,表明后者包含更多信息量并产生更高的编码成本。显著区域输出较大的 σ\sigmaσ,需要更多比特编码。相反,背景区域有较小的 σ\sigmaσ,导致编码比特数较少,随机性较低。因此,预测的尺度图 σ\sigmaσ 与信息量图(由式(6)计算)正相关,并突出了潜在的待增强显著区域。尽管尺度图 σ\sigmaσ 在视觉上更显著,但由于信息量图是直接的优化目标(见图3(b))。因此,我们将尺度图 σ\sigmaσ 视为信息量(本文默认记作信息图 σ\sigmaσ)的更好表示,并通过 σ\sigmaσ 来细化特征图 P2P{2}P2 以增强显著区域,公式如下:
σ=Mean(σ), y1=y⊗(1+σ)\sigma=M e a n(\sigma),\;\;\;y_{1}=y\otimes(1+\sigma)σ=Mean(σ),y1=y⊗(1+σ)
其中 MeanMeanMean 表示沿通道维度的平均操作,⊗\otimes⊗ 表示逐像素乘法。注意,使用 1+σ1+\sigma1+σ 是为了保留特征图 P2P_{2}P2 中有用的上下文信息,防止其受到 σ\sigmaσ 中接近零的值的影响。
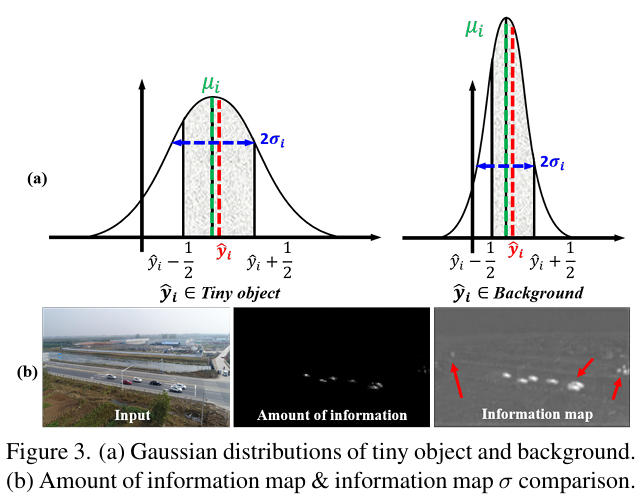
图 3. (a) 小目标和背景的高斯分布 (b) 信息量图与信息图 \\sigma 的对比。
3.2. 位置高斯分布预测
位置高斯分布图 。为了有效地使信息图精确定位小目标,我们在区域级别引入了位置高斯分布图。小目标检测的真实分布图遵循两个原则:1) 前景-背景区分(前景具有更高的值),和 2) 小目标与一般目标的区分(小目标具有相对更高的值)。
我们采用高斯混合分布来对特征图进行建模并突出目标位置,如图4所示。给定包含 NNN 个目标实例的输入 XXX,我们将生成的真实值图的大小设置为与 P2P_{2}P2 的维度 (HΔ×WΔ×1)(\frac{H}{\it\Delta}\times\frac{W}{\it\Delta}\times1)(ΔH×ΔW×1) 相匹配以降低计算成本。假设目标的主体位于其标注边界框的中心 43, 48,特征图分布中的每个高斯分量定义为一个二维高斯分布 (μibox,Σibox)(\mathbf{\mu}{i}^{b o x},\mathbf{\Sigma}{i}^{b o x})(μibox,Σibox),其中边界框中心作为均值向量,边长的平方作为协方差矩阵:
μibox=xiyi,Σibox=wi200hi2\mathbf{\mu}{i}^{b o x}=\left\\begin{matrix}{x_{i}}\\\\ {y_{i}}\\end{matrix}\\right,\mathbf{\Sigma}{i}^{b o x}=\left\\begin{matrix}{w_{i}\^{2}}\&{0}\\\\ {0}\&{h_{i}\^{2}}\\end{matrix}\\rightμibox=xiyi,Σibox=wi200hi2
其中 (xi,yi,wi,hi)(x_{i},y_{i},w_{i},h_{i})(xi,yi,wi,hi) 表示第 iii 个边界框在 P2P_{2}P2 中的位置。如图?4所示,在高斯混合分布图 中,密集、大目标的区域表现出混乱的显著特征,而小目标的峰值明显高于一般目标,这引入了噪声并增加了学习负担。为了创建一个更清晰、易于训练的分布图,我们根据每个标注框的面积,使用缩放因子 αi\alpha_iαi 来细化协方差矩阵。遵循 44 中的目标定义,对于超小(2-8像素)、微小(8-16像素)、小型(16-32像素)和一般目标,缩放因子分别设置为 4、6、8 和 10,公式如下:
μibox=xiyi,Σibox=(wiαi)200(hiαs)2\mathbf{\mu}{i}^{b o x}=\left\\begin{matrix}{x_{i}}\\\\ {y_{i}}\\end{matrix}\\right,\mathbf{\Sigma}{i}^{b o x}=\left\\begin{matrix}{(\\frac{w_{i}}{\\alpha_{i}})\^{2}}\&{0}\\\\ {0}\&{(\\frac{h_{i}}{\\alpha_{\\it s}})\^{2}}\\end{matrix}\\rightμibox=xiyi,Σibox=(αiwi)200(αshi)2
特征图 P2P_{2}P2 的最终高斯混合分布通过组合每个高斯分量得到:
f(p)=1N∑i=1NN(p∣μibox,Σibox)f(p)=\frac{1}{N}\sum_{i=1}^{N}\mathcal{N}(p|\pmb{\mu}{i}^{b o x},\pmb{\Sigma}{i}^{b o x})f(p)=N1i=1∑NN(p∣μibox,Σibox)
其中 ppp 表示 P2P_{2}P2 中的像素位置。为了进一步突出前景-背景对比度,我们将 f(p)f(p)f(p) 乘以 NNN,并使用阈值 tht hth 对分布图进行后处理(超过 tht hth 的位置增加 0.50.50.5)以获得最终的真实位置高斯分布图 MGTM_{G T}MGT。此过程简化为:
th=1∣S∣∑p∈SN⋅f(p)MGT=(Sign(N⋅f(p)−th)+1)×0.25+N⋅f(p)\begin{aligned}{}&{{}t h=\frac{1}{|S|}\sum_{p\in S}N\cdot f(p)}\\ {M_{G T}=(S i g n}&{{}(N\cdot f(p)-t h)+1)\times0.25+N\cdot f(p)}\end{aligned}MGT=(Signth=∣S∣1p∈S∑N⋅f(p)(N⋅f(p)−th)+1)×0.25+N⋅f(p)
其中 SSS 是特征图中所有像素位置的集合,SignSignSign 是数学符号函数。
如图 图 4,{\mathrm{图~4,}}图 4, 所示,设计的位置高斯分布图有效地捕捉了图像显著性,其中密集的小目标被赋予了相对更高的值。因此,该图可以作为增强那些否则会被弱激活的小目标表征的指导。
预测 。我们在有监督的情况下从多尺度特征预测位置高斯分布图,并以从像素特征信息建模模块导出的信息图 σ\sigmaσ 为指导。在 σ\sigmaσ 指导下的预测过程可以同时调制信息图和分布图以聚焦微小目标,两者都为增强弱表征提供了关注区域。考虑到FPN不同层级上不同的语义和空间细节,我们使用 P2, P3P_{2},\,P_{3}P2,P3 和 P4P_{4}P4 来预测该图。整体预测网络结构如图 HHH 2所示,更多细节见补充材料。具体来说,结合来自 σ\sigmaσ 的先验信息量,我们将信息图 σ\sigmaσ 添加到每个特征层级作为预测网络的输入,其中 σ\sigmaσ 被相应地降采样。输入为 P4+14σ,P3+12σ,P2⋅+σP_{4}+{\\textstyle{\\frac{1}{4}}}\\sigma,P_{3}+{\\textstyle{\\frac{1}{2}}}\\sigma,\\stackrel{\\cdot}{P_{2}}+\\sigmaP4+41σ,P3+21σ,P2⋅+σ,其中 14\textstyle{\frac{1}{4}}41 和 12\textstyle{\frac{1}{2}}21 表示降采样。一系列卷积和转置卷积层 54(除了 P2P_{2}P2 分支外)分别执行特征提取和可学习的上采样。值得注意的是,我们通过从更深层的侧输出(Sigmoid之前)到更浅层的跳跃连接来合并特征,以帮助定位显著区域并细化复杂的预测图 14。然后每个分支预测位置高斯分布图,得到 Mpd2, Mpd3M_{p d_{2}},\ M_{p d_{3}}Mpd2, Mpd3 和 Mpd4M_{p d_{4}}Mpd4。该过程简化为:Mpd4,Mpd3,Mpd2 = ϕ(inputs)M_{p d_{4}},M_{p d_{3}},M_{p d_{2}}\,=\,\phi(i n p u t s)Mpd4,Mpd3,Mpd2=ϕ(inputs),其中 ϕ\phiϕ 表示参数化的多尺度预测网络。
我们对三个侧输出预测应用深度监督,它们与真实位置高斯分布图大小相同:
Lpred=∑i=24MSEweighted(Mpdi,MGT)\mathcal{L}{p r e d}=\sum{i=2}^{4}M S E_{w e i g h t e d}(M_{p d_{i}},M_{G T})Lpred=i=2∑4MSEweighted(Mpdi,MGT)
其中 MSEweightedM S E_{w e i g h t e d}MSEweighted 表示加权均方误差损失。为了解决前景-背景不平衡问题,我们将超过阈值 tht hth 的目标区域的权重设置为 10(背景为 0.10.10.1),以强调正像素。
总的来说,结合信息图 σ\sigmaσ 使得特征信息能够有效地调制分布图预测,同时优化 Lpred\mathcal{L}_{p r e d}Lpred 有助于生成能更好识别信息丰富的小目标区域的更好信息图 σ\sigmaσ。
类似于信息图,Mpd2M_{p d_{2}}Mpd2 用于增强小目标表征:
y2=y⊗(1+Mpd2)y_{2}=y\otimes(1+M_{p d_{2}})y2=y⊗(1+Mpd2)
增强后的特征 y1y_1y1 和 y2y_{2}y2 被送入卷积块注意力模块 (CBAM) 45 以进一步关注重要区域,从而实现对特征的全局探索。两个具有注意力的特征通过逐元素相加进行融合,形成增强后的特征图 P2′˙\dot{P_{2}^{'}}P2′˙。替代 P2P_{2}P2 的 P2′P_{2}^{'}P2′ 将作为新特征金字塔的一部分被送入检测头进行下游任务。
3.3. 损失函数
不失一般性,我们将原始检测网络损失统一为 Ldet\mathcal{L}_{d e t}Ldet,包括回归损失和分类损失。总损失函数表示为:
L=Ldet+λ1LIE+λ2Lpred\mathcal{L}=\mathcal{L}{d e t}+\lambda{1}\mathcal{L}{I E}+\lambda{2}\mathcal{L}_{p r e d}L=Ldet+λ1LIE+λ2Lpred
其中 λ1\lambda_{1}λ1 和 λ2\lambda_{2}λ2 是平衡超参数。
4. 实验
4.1. 评估设置
数据集。实验在三个小目标检测数据集上进行:VisDrone2019 11, AI-TOD 44 和 AI-TODv247。VisDrone2019 包含 10 个类别和 10,209 张高分辨率(2,000 × 1,500)的无人机图像,这些图像是在不同角度拍摄的多种城市场景中捕获的,包含大量小目标实例。AI-TOD 包含 28,036 张航拍图像和涵盖 8 个类别的 700,621 个标注实例,平均实例大小为 12.8 像素。AI-TODv2 是一个改进版本,包含 752,745 个实例,平均实例大小减小到 12.7 像素。
实现细节 。实验使用 PyTorch 和 MMDetection 7 实现,所有模型均在单个 NVIDIA RTX 4090 GPU 上训练。我们遵循 SR-TOD 6 的实验设置。默认情况下,使用在 ImageNet 36 上预训练的 ResNet50-FPN 25 进行特征提取。模型使用 SGD 优化器进行优化,动量为 0.9,权重衰减为 0.0001,批大小为 2。训练共进行 12 个周期,初始学习率为 0.005,在第 8 和第 11 个周期衰减。λ1\lambda_{1}λ1 和 λ2\lambda_{2}λ2 分别设置为 0.01 和 1.0。消融实验和分析在 VisDrone2019 上使用 DetectoRS 31 进行。
评估指标 。我们遵循 AI-TOD 基准 44 的评估指标,包括平均精度 (AP), AP0.5, AP0.75, APvt(A P),\,A P_{0.5},\,A P_{0.75},\,A P_{v t}(AP),AP0.5,AP0.75,APvt(超小)、APt(微小)和 APsA P_{s}APs(小型)。
4.2. 与最先进方法的比较
在 VisDrone2019 上的比较 。我们在 VisDrone2019 上将我们的方法与最先进的方法进行比较,如表 1 所示,得出几个关键观察结果:1) 将我们的方法作为即插即用组件集成到基线检测器中,一致地提高了检测性能,其中 Faster R-CNN 在 APt 上的增益最为显著,达到 5.8 点。在具有挑战性的 APvtA P_{v t}APvt 指标上,增益达到 3.4 点,凸显了我们方法在小目标上的优势。2)当与 RFLA 结合时,我们的方法在所有指标上都优于所有现有方法,实现了最高的 APvtA P_{v t}APvt 为 7.4,比下一个最佳竞争对手高出 2 点。3)与我们的方法类似,SR-TOD 使用差异图进行特征增强。然而,我们的方法实现了更大的整体改进,因为差异图仅捕获了部分信息丢失区域,这证明了我们的方法在识别信息丢失区域方面的优越性。4) RFLA 通过优化标签分配来解决小目标检测,我们的结果表明,标签分配和特征表征两方面的改进都能显著提升性能,这表明在未来研究中结合这些策略的潜力。
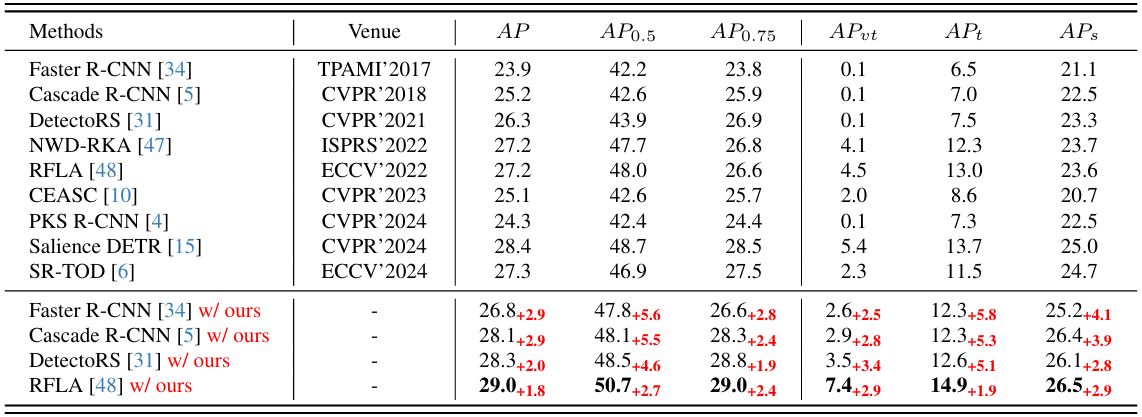
表 1. VisDrone2019 上的实验结果。结果的右下角表示相对于其基线的增益。
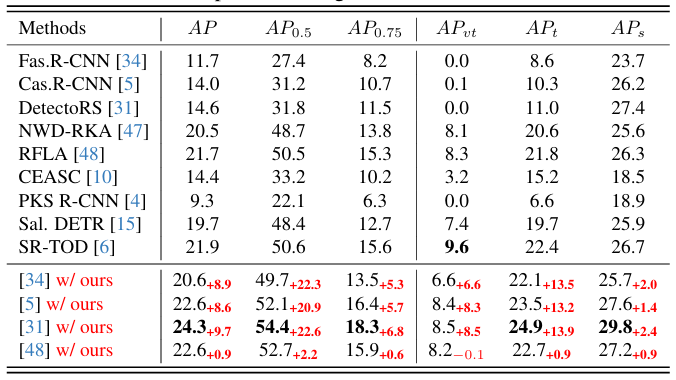
在 AI-TOD 和 AI-TODv2 上的比较 。我们还在 AI-TOD 和 AI-TODv2 上评估我们的方法以评估其泛化能力。表 2 中所示的 AI-TOD 结果表明,几乎所有模型都优于基线,最大增益为 22.6 点。我们的方法与 DetectoRS 集成,在所有指标上(除了 APvtA P_{v t}APvt 排名第二)都取得了最佳性能。类似地,如表 3 所示,AI-TODv2 上的结果与 AI-TOD 上的结果相似,我们的最佳方法在所有指标上都显著优于竞争对手。这些实验进一步验证了我们方法在小目标检测中的有效性。
4.3. 消融研究
提出的模块 。我们通过逐步应用我们提出的两个组件(像素特征信息建模和位置高斯分布预测)来增强信息丢失区域,以验证它们的有效性。如表 444 所示,每个组件相对于基线都提高了性能,当两者结合时观察到进一步的增益。这表明这些组件在捕捉信息丢失区域以增强特征表征方面相互补充。
不同的分布建模方法 。我们研究了建模真实分布图的各种策略。具体来说,我们使用固定的缩放因子 α=1\alpha{=}1α=1 来细化协方差矩阵,与我们方法中使用的依赖于实例大小的缩放因子形成对比。此外,我们基于真实边界框构建了一个二值掩码,其中背景值为 0,边界框内为 1。我们还利用自注意力生成权重分布图。如表 5 所示,所有方法的性能都低于我们的方法。固定缩放因子导致小目标的峰值过高,增加了网络的学习负担。二值掩码方法过于简单,并引入了无关的背景噪声,导致次优性能。由有限像素下的自注意力生成的权重分布图容易受到无关背景的干扰,导致小目标的性能下降。相比之下,我们平滑的分布图有效地突出了显著特征而没有噪声,从而产生了更优的结果。
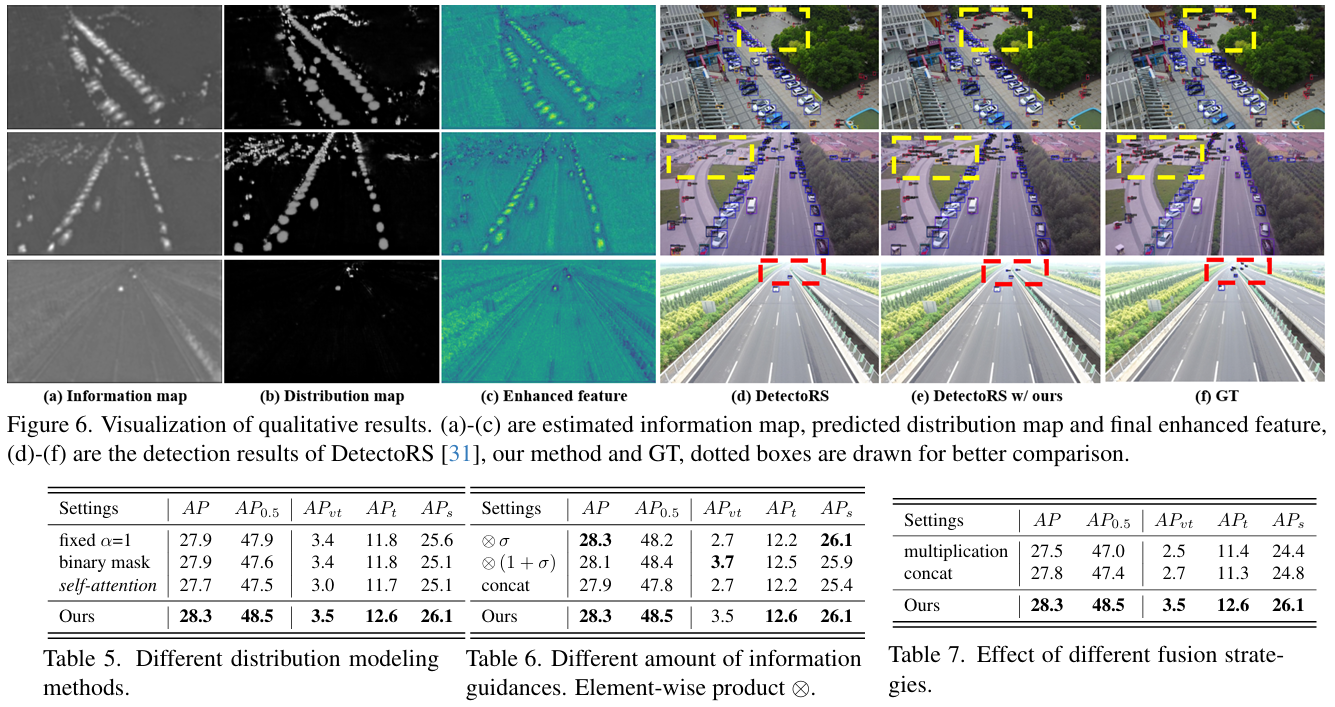
不同的先验指导 。如表 6 所示,我们使用信息图 σ\sigmaσ 通过多种方法指导分布图的预测:将输入特征乘以 σ\sigmaσ、乘以 (1+σ)(1+\sigma)(1+σ) 以及将输入特征与 σ\sigmaσ 拼接。虽然乘以 σ\sigmaσ 在 APA PAP 和 APsA P_{s}APs 上获得了最佳性能,但其他指标显示出显著下降,这主要是因为在 σ\sigmaσ 接近 0 的区域丢失了有用的上下文信息。拼接方法引入了噪声,因为金字塔特征(捕获空间和语义信息)和 σ\sigmaσ(表示信息量)具有不同的含义。乘以 (1+σ)(1+\sigma)(1+σ) 的性能与我们的方法相似,我们采用逐元素相加是因为其简单性。
不同的融合策略 。我们探索了两种增强特征 y1y_1y1 和 y2y_{2}y2 的各种融合策略,包括逐元素乘法和拼接。如表 7 所示,逐元素相加被证明是最有效的融合方法,因为它能互补特征并防止信息丢失。相比之下,逐元素乘法和拼接都会导致性能下降。逐元素乘法通过放大或缩小特征值引起非线性变化,导致关键信息丢失。此外,由于两种增强特征高度相似,拼接会引入冗余并增加网络复杂性。
4.4. 进一步分析
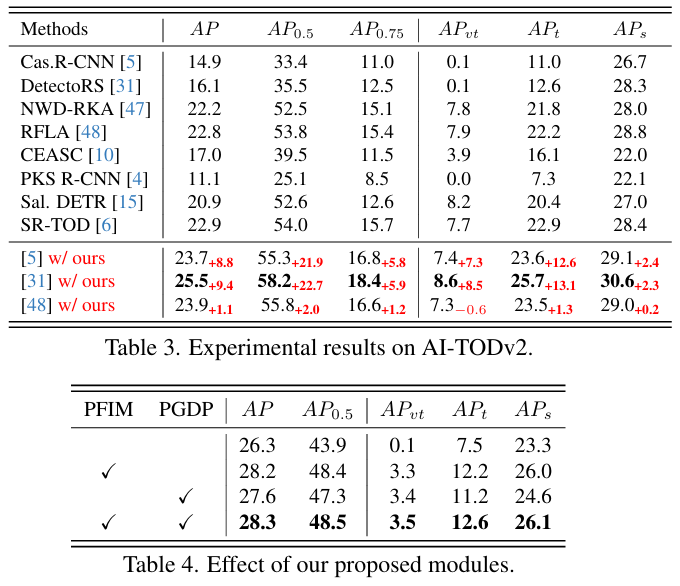
像素特征信息建模分析 。我们分析了像素特征信息建模模块在捕获具有高信息量的显著目标方面的有效性。首先,我们在图 6(a){\mathrm{6(a)}}6(a) 中可视化了估计的信息图 σ\sigmaσ,它清楚地捕获了目标的空间结构。由于具有更高的信息量,物体的空间结构变得更加突出,这证实了使用信息图 σ\sigmaσ 增强特征的有效性。为了说明像素特征信息建模模块如何通过不同的高斯分布捕获空间结构,我们在图 5 中可视化了特征图 P2P_{2}P2(记为 yyy)及其归一化版本(通过 y^−μσ\frac{\hat{y}-\mu}{\sigma}σy^−μ 计算)。由于归一化特征图的每个元素都遵循标准高斯分布,结构显得模糊且无序,这表明特征冗余被移除,并且空间结构被建模的分布有效地捕获。
我们采用通信系统 37 中比特每像素 (bpp) 的概念来更好地理解信息熵损失在模块中的作用。Bpp 定义为每个像素的平均编码成本,即信息熵损失 LIE\mathcal{L}_{I E}LIE 除以总像素数。如图 5 所示,似然图中小目标处的值远低于背景,表明更高的编码成本(见式(9))和更多的信息。因此,密集场景的 bpp 高于稀疏场景,其值分别为 0.5629 和 0.0811。我们根据图像中实例数量定义密集级别,每增加 40 个实例提升一个级别。每个密度区间的平均 bpp 绘制在图 7 中,显示出总体上升趋势,与我们的分析一致。这支持了信息熵损失在捕获具有高信息量的显著目标方面的有效性。
位置高斯分布图分析 。我们在图 6(b) 中可视化了预测的分布图,其中目标和背景清晰分离,小目标的值明显大于一般目标。信息图和分布图都突出了待增强的区域,指导特征改进。因此,图 6© 中的增强特征 P2′P_{2}^{'}P2′ 变得更加清晰。此外,如图 6(d)-(f) 所示,我们的方法通过在虚线框内检测到更多具有挑战性的小目标,优于基线通用检测器,这证明了我们的特征增强对于小目标的有效性。

图 4. 位置高斯分布图的生成流程。GT 以灰度模式显示以便清晰查看。
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/27b379d1266f4efa89d8e67a313db2fb.png)
5. 结论
本文介绍了一种基于像素级特征信息来增强小目标检测中弱区域的新方法。我们以无监督方式最小化信息熵损失以生成有侧重点的信息图,其中较高的值对应于具有更多信息量的显著区域。然后,为了使信息图突出小目标,我们在信息图的指导下以有监督方式预测位置高斯分布图。使用这两个注意力图,我们增强了先前难以区分的微小目标特征,在三个数据集上的实验结果验证了我们方法的有效性。
6. 致谢
本工作部分得到江西省科技项目 (20232ACC01007)、吉安市科技项目 (20233TGV06020)、国家自然科学基金 (62373293, 62463189, 62403189)、江西省自然科学基金 (20242BAB20050) 和吉安市科技计划自然科学基金 (20244018591) 的资助。
参考文献
1 Yancheng Bai, Yongqiang Zhang, Mingli Ding, and Bernard Ghanem. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European conference on computer vision (ECCV), pages 206-221, 2018. 2
2 Johannes Ballé, Valero Laparra, and Eero P Simoncelli. Density modeling of images using a generalized normalization transformation. arXiv preprint arXiv:1511.06281, 2015. 3
3 Ali Borji and Laurent Itti. State-of-the-art in visual attention modeling. IEEE transactions on pattern analysis and machine intelligence, 35(1):185-207, 2012. 1
4 Xinhao Cai, Qiuxia Lai, Yuwei Wang, Wenguan Wang, Zeren Sun, and Yazhou Yao. Poly kernel inception network for remote sensing detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27706-27716, 2024. 6, 7
5 Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6154-6162, 2018. 2, 6, 7
6 Bing Cao, Haiyu Yao, Pengfei Zhu, and Qinghua Hu. Visible and clear: Finding tiny objects in difference map. arXiv preprint arXiv:2405.11276, 2024. 2, 6, 7
7 Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019. 9
8 Gong Cheng, Xiang Yuan, Xiwen Yao, Kebing Yan, Qinghua Zeng, Xingxing Xie, and Junwei Han. Towards large-scale small object detection: Survey and benchmarks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 1
9 Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 1
10 Bowei Du, Yecheng Huang, Jiaxin Chen, and Di Huang. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13435-13444, 2023. 6, 7
11 Dawei Du, Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Lin, Qinghua Hu, Tao Peng, Jiayu Zheng, Xinyao Wang, Yue Zhang, et al. Visdrone-det2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF international conference on computer vision workshops, pages 0-0, 2019. 6
12 Yuqi Gong, Xuehui Yu, Yao Ding, Xiaoke Peng, Jian Zhao, and Zhenjun Han. Effective fusion factor in fpn for tiny object detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1160-1168, 2021. 1, 2
13 Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014. 2
14 Qibin Hou, Ming-Ming Cheng, Xiaowei Hu, Ali Borji, Zhuowen Tu, and Philip HS Torr. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3203-3212, 2017. 5
15 Xiuquan Hou, Meiqin Liu, Senlin Zhang, Ping Wei, and Badong Chen. Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17574-17583, 2024. 6, 7
16 Jung Uk Kim, Sungjune Park, and Yong Man Ro. Robust small-scale pedestrian detection with cued recall via memory learning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3050-3059, 2021. 2
17 Mate Kisantal. Augmentation for small object detection. arXiv preprint arXiv:1902.07296, 2019. 2
18 Tao Kong, Fuchun Sun, Huaping Liu, Yuning Jiang, Lei Li, and Jianbo Shi. Foveabox: Beyound anchor-based object detection. IEEE Transactions on Image Processing, 29:7389-7398, 2020. 2
19 Satish Kumar, Bowen Zhang, Chandrakanth Gudavalli, Connor Levenson, Lacey Hughey, Jared A Stabach, Irene Amoke, Gordon Ojwang, Joseph Mukeka, Stephen Mwiu, et al. Wildlife mapper: Aerial image analysis for multi-species detection and identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12594-12604, 2024. 1
20 Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), pages 734-750, 2018. 2
21 Jianan Li, Xiaodan Liang, Yunchao Wei, Tingfa Xu, Jiashi Feng, and Shuicheng Yan. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1222-1230, 2017. 2
22 Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6054-6063, 2019. 1
23 Yangyang Li, Qin Huang, Xuan Pei, Yanqiao Chen, Licheng Jiao, and Ronghua Shang. Cross-layer attention network for small object detection in remote sensing imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14:2148-2161, 2020. 1
24 Cheng-Jian Lin and Jyun-Yu Jhang. Intelligent traffic-monitoring system based on yolo and convolutional fuzzy neural networks. IEEE Access, 10:14120-14133, 2022. 1
25 Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117-2125, 2017. 1, 2, 6
26 Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8759-8768, 2018. 1
27 Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I 14, pages 21-37. Springer, 2016. 1, 2
28 Xin Lu, Buyu Li, Yuxin Yue, Quanquan Li, and Junjie Yan. Grid r-cnn. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1363-1372, 2019. 2
29 Xiaocong Lu, Jian Ji, Zhiqi Xing, and Qiguang Miao. Attention and feature fusion ssd for remote sensing object detection. IEEE Transactions on Instrumentation and Measurement, 70:1-9, 2021. 1, 2
30 David Minnen, Johannes Ballé, and George D Toderici. Joint autoregressive and hierarchical priors for learned image compression. Advances in neural information processing systems, 31, 2018. 4
31 Siyuan Qiao, Liang-Chieh Chen, and Alan Yuille. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10213-10224, 2021. 1, 2, 6, 7, 8
32 J Redmon. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. 1
33 Joseph Redmon. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 2
34 Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence, 39(6):1137-1149, 2016. 1, 2, 6
35 T-YLPG Ross and GKHP Dollar. Focal loss for dense object detection. In proceedings of the IEEE conference on computer vision and pattern recognition, pages 2980-2988, 2017. 2
36 Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211-252, 2015. 6
37 Claude Elwood Shannon. A mathematical theory of communication. The Bell system technical journal, 27(3):379-423, 1948. 2, 3, 8
38 Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10781-10790, 2020. 1, 2
39 MTCAJ Thomas and A Thomas Joy. Elements of information theory. Wiley-Interscience, 2006. 3
40 Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: Fully convolutional one-stage object detection. In Proc. Int. Conf. Computer Vision (ICCV), 2019. 2
41 Hu Kuo Ting. On the amount of information. Theory of Probability & Its Applications, 7(4):439-447, 1962. 3
42 Thang Vu, Hyunjun Jang, Trung X Pham, and Chang Yoo. Cascade rpn: Delving into high-quality region proposal network with adaptive convolution. Advances in neural information processing systems, 32, 2019. 2
43 Jinwang Wang, Wen Yang, Heng-Chao Li, Haijian Zhang, and Gui-Song Xia. Learning center probability map for detecting objects in aerial images. IEEE Transactions on Geoscience and Remote Sensing, 59(5):4307-4323, 2020. 4
44 Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, and Gui-Song Xia. Tiny object detection in aerial images. In 2020 25th international conference on pattern recognition (ICPR), pages 3791-3798. IEEE, 2021. 1, 5, 6
45 Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), pages 3-19, 2018. 3, 5
46 Jialian Wu, Chunluan Zhou, Qian Zhang, Ming Yang, and Junsong Yuan. Self-mimic learning for small-scale pedestrian detection. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2012-2020, 2020. 2
47 Chang Xu, Jinwang Wang, Wen Yang, Huai Yu, Lei Yu, and Gui-Song Xia. Detecting tiny objects in aerial images: A normalized wasserstein distance and a new benchmark. ISPRS Journal of Photogrammetry and Remote Sensing, 190:79-93, 2022. 2, 6, 7
48 Chang Xu, Jinwang Wang, Wen Yang, Huai Yu, Lei Yu, and Gui-Song Xia. Rfla: Gaussian receptive field based label assignment for tiny object detection. In European conference on computer vision, pages 526-543. Springer, 2022. 2, 4, 6, 7
49 Chenhongyi Yang, Zehao Huang, and Naiyan Wang. Querydet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 13668-13677, 2022. 1
50 Xue Yang, Jirui Yang, Junchi Yan, Yue Zhang, Tengfei Zhang, Zhi Guo, Xian Sun, and Kun Fu. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8232-8241, 2019. 1, 2
51 Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9657-9666, 2019. 2
52 Kai Yi, Zhiqiang Jian, Shitao Chen, and Nanning Zheng. Feature selective small object detection via knowledge-based recurrent attentive neural network. arXiv preprint arXiv:1803.05263, 2018. 1, 2
53 Xiang Yuan, Gong Cheng, Kebing Yan, Qinghua Zeng, and Junwei Han. Small object detection via coarse-to-fine proposal generation and imitation learning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6317-6327, 2023. 2
54 Matthew D Zeiler, Graham W Taylor, and Rob Fergus. Adaptive deconvolutional networks for mid and high level feature learning. In 2011 international conference on computer vision, pages 2018-2025. IEEE, 2011. 5
55 Fan Zhang, Licheng Jiao, Lingling Li, Fang Liu, and Xu Liu. Multiresolution attention extractor for small object detection. arXiv preprint arXiv:2006.05941, 2020. 1
56 Hangyue Zhao, Hongpu Zhang, and Yanyun Zhao. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 233-238, 2023. 1
57 Xingyi Zhou, Jiacheng Zhuo, and Philipp Krahenbuhl. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 850-859, 2019. 2